
Izinkan saya membocorkan rahasia: dulu saya mengira web scraping cuma buat peretas berhoodie atau ilmuwan data yang monitornya lebih banyak daripada akalnya. Tapi sekarang, mengekstrak data dari website sudah jadi hal biasa di dunia bisnis, seperti ngopi pagi—bedanya, untungnya, Anda tidak perlu tahu Python atau minum tiga espresso sebelum siang. Bahkan dengan hadirnya alat AI web scraper, orang yang mengira “HTML” itu sandwich baru di Subway pun bisa menarik data terstruktur dari web yang luas ini.
Kalau Anda pernah mendapati diri sendiri menyalin dan menempel baris-baris informasi produk, prospek penjualan, atau daftar harga ke spreadsheet, Anda tidak sendirian. Hampir 73% perusahaan kini menggunakan web scraping untuk wawasan pasar dan pelacakan kompetitor. Dan dengan proyeksi pasar software web scraping yang mencapai $2,49 miliar pada 2032, jelas bahwa ekstraksi data web bukan lagi milik kalangan teknologi elite saja. Jadi, entah Anda tenaga sales, marketer, atau sekadar orang yang ingin berhenti input data manual, panduan ini cocok untuk Anda. Saya akan memandu Anda dari dasar, membandingkan pendekatan tradisional dan berbasis AI, serta menunjukkan cara memulainya—tanpa perlu hoodie.
Dasar Web Scraper: Apa Artinya Mengambil Data dari Website?
Mari mulai dari yang sederhana. Web scraper adalah alat (atau script, atau ekstensi Chrome) yang secara otomatis mengumpulkan data dari website. Bayangkan seperti magang supercepat yang tidak pernah mengeluh soal tugas berulang. Alih-alih Anda menyalin dan menempel informasi baris demi baris, web scraper mengerjakannya semua dalam hitungan detik, dan bahkan tidak minta istirahat minum kopi.
Ada dua jenis data utama yang akan Anda temui:
- Data terstruktur: Ini adalah data yang rapi dan siap dipakai di spreadsheet—misalnya tabel nama produk, harga, atau email. Datanya tertata, berlabel, dan mudah dianalisis.
- Data tidak terstruktur: Ini adalah “wild west” — posting blog, ulasan, gambar, atau apa pun yang tidak cocok dengan rapi ke dalam baris dan kolom. Sebagian besar proyek web scraping bertujuan mengubah data tidak terstruktur menjadi data terstruktur agar benar-benar bisa digunakan.
Kalau Anda pernah menyalin tabel dari website ke Excel, selamat—Anda sudah melakukan web scraping manual. Sekarang bayangkan melakukannya untuk 10.000 halaman. (Jangan benar-benar lakukan itu. Itulah gunanya web scraper.)
Kenapa Mengambil Data dari Website? Manfaat Utama untuk Bisnis
Jadi, kenapa repot-repot mengambil data sejak awal? Jawaban singkatnya: bisnis berjalan dengan data, dan web adalah database terbesar di dunia. Entah Anda bergerak di sales, marketing, ecommerce, atau properti, ekstraksi data web bisa memberi keunggulan serius.
Berikut beberapa use case bisnis yang paling umum:
| Use Case | Deskripsi | Contoh ROI/Manfaat |
|---|---|---|
| Lead Generation | Mengumpulkan info kontak, email, atau daftar perusahaan dari direktori atau situs sosial | Tim sales menghemat waktu dan menemukan prospek yang lebih berkualitas |
| Pemantauan Harga | Melacak harga kompetitor, stok, atau promosi secara real-time | Peritel menyesuaikan harga secara dinamis, meningkatkan penjualan 4% |
| Riset Pasar | Menggabungkan ulasan, berita, atau sentimen sosial untuk melihat tren | Marketer menyesuaikan kampanye berdasarkan wawasan konsumen real-time |
| Analisis Kompetitor | Memantau katalog produk, peluncuran, atau konten pesaing | Bisnis merespons perubahan pasar lebih cepat |
| Intelijen Properti | Mengambil listing properti, harga, dan ketersediaan | Agen dan investor melihat peluang lebih cepat dari pasar |
Bahkan, 25–30% peritel di Inggris dan Eropa menggunakan strategi dynamic pricing yang didukung scraping harga kompetitor. Dan perusahaan seperti John Lewis dan ASOS telah melihat peningkatan penjualan yang terukur dengan memanfaatkan data web untuk pengambilan keputusan yang lebih cerdas.
Tools Web Scraper Tradisional: Bagaimana Cara Kerjanya?
Mari mundur ke cara “klasik” mengolah data—sebelum AI mulai unjuk gigi. Web scraper tradisional biasanya berupa script (sering ditulis dalam Python) atau ekstensi browser yang mengikuti serangkaian aturan untuk mengambil data yang Anda inginkan.
Begini alur prosesnya biasanya:
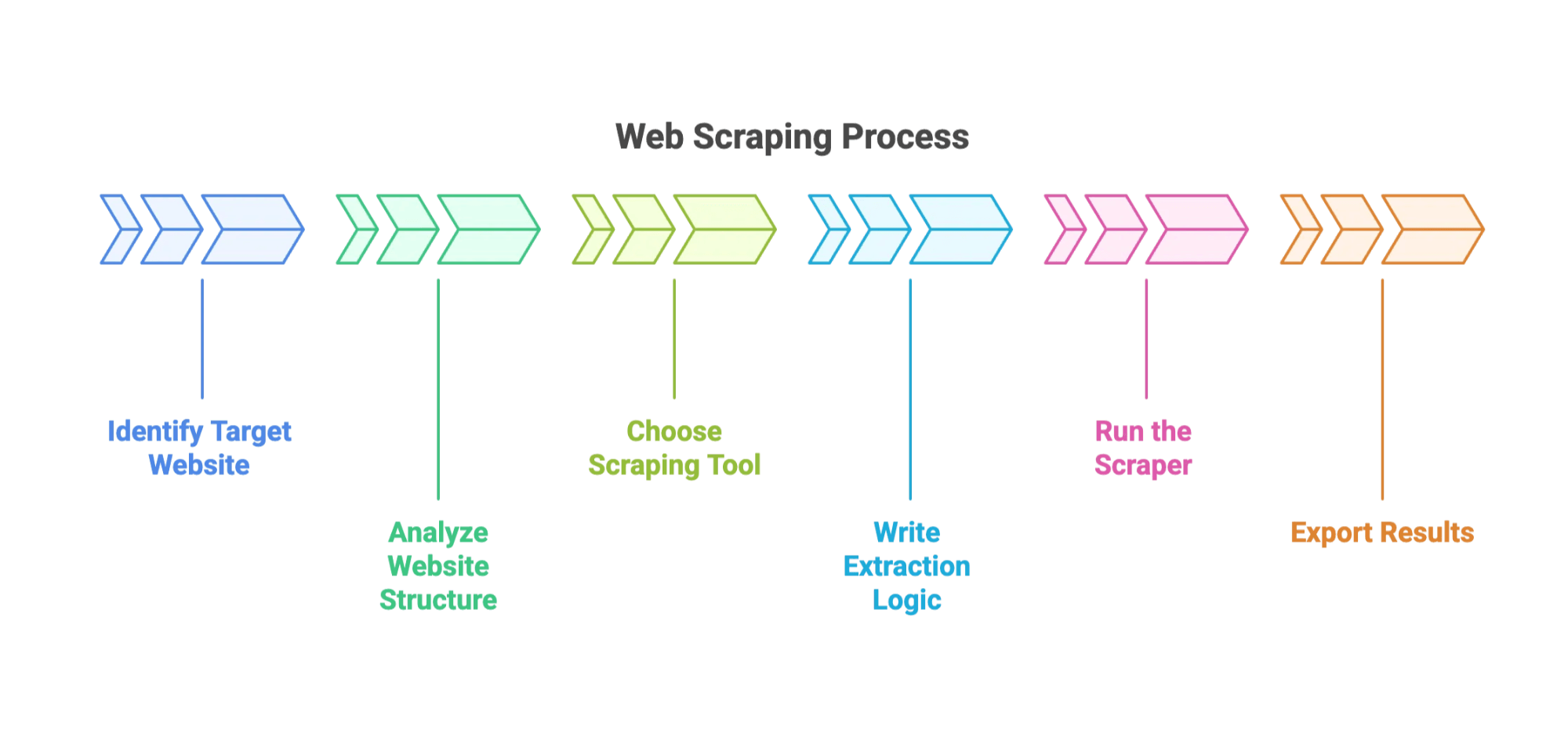
- Identifikasi website target dan field data.
- Analisis struktur website. (Artinya mengutak-atik HTML lewat Developer Tools di browser Anda. Rasanya seperti arkeologi digital.)
- Pilih tool: Opsi populer termasuk BeautifulSoup, Scrapy, atau plugin browser.
- Tulis logika ekstraksi: Beri tahu tool cara menemukan data—biasanya dengan CSS selector atau XPath.
- Jalankan scraper: Lihat bagaimana alat itu mengumpulkan data lintas halaman.
- Ekspor hasil: Biasanya ke CSV, JSON, atau langsung ke Excel.
Langkah demi Langkah: Mengekstrak Data dengan Web Scraper Tradisional
Misalnya Anda ingin mengambil listing produk dari situs ecommerce. Berikut panduan yang ramah untuk pemula:
- Langkah 1: Instal Python dan library BeautifulSoup.
- Langkah 2: Gunakan browser untuk memeriksa halaman produk. Temukan tag HTML yang memuat nama produk dan harga.
- Langkah 3: Tulis script singkat untuk mengambil halaman, mengurai HTML, dan mengekstrak field yang relevan.
- Langkah 4: Lakukan perulangan ke banyak halaman (menangani pagination).
- Langkah 5: Ekspor data ke file CSV.
Kedengarannya sederhana, tapi percayalah—script pertama Anda kemungkinan besar akan rusak setidaknya sekali. (Percobaan pertama saya menghasilkan 500 baris “None” karena saya salah ketik nama class. Waduh.)
Tantangan Umum dengan Solusi Web Scraper Tradisional
Di sinilah mulai rumit:
- Perubahan website: Bahkan perubahan kecil pada tata letak situs bisa merusak scraper Anda. 10–15% scraper rusak setiap minggu karena perubahan.
- Langkah anti-bot: CAPTCHA, pemblokiran IP, dan rate limit bisa menghentikan Anda mendadak. Anda perlu menangani proxy, jeda, dan kadang bahkan menyelesaikan CAPTCHA.
- Butuh keahlian teknis: Anda perlu paham sedikit coding dan HTML/CSS.
- Maintenance: Scraper butuh pemantauan dan pembaruan terus-menerus.
- Data berantakan: Anda akan menghabiskan waktu membersihkan format yang tidak konsisten, nilai yang hilang, atau encoding yang aneh.
Bagi pemula, ini bisa terasa seperti mencoba memanggang kue saat resepnya terus berubah dan oven sesekali mengunci Anda di luar.
Hadirnya AI Web Scraper: Membuat Ekstraksi Data Lebih Mudah Diakses
Ekstrak data dari website apa pun menggunakan AI Get Started Free
Sekarang masuk ke bagian yang seru. AI web scraper sedang mengubah permainan (ups, hampir memakai frasa terlarang). Alih-alih menulis kode atau utak-atik selector, Anda cukup memberi tahu alat ini apa yang Anda inginkan dalam bahasa biasa. AI akan mengurus sisanya.
Thunderbit (itu kami!) adalah contoh bagus dari generasi baru ini. Dengan Thunderbit, Anda bisa mengekstrak data terstruktur dari website apa pun menggunakan bahasa alami—tanpa coding. Entah Anda di bidang sales, marketing, atau ecommerce, Anda bisa mengumpulkan data yang dibutuhkan dalam hitungan menit, bukan hari.
AI Web Scraper Thunderbit: Cara Mempermudah Ekstraksi Data
Izinkan saya menunjukkan bagaimana Thunderbit memudahkan pekerjaan:
- AI Suggest Fields: Cukup klik “AI Suggest Fields” dan Thunderbit membaca website, merekomendasikan nama kolom, bahkan menyarankan cara mengekstrak tiap field.
- Subpage Scraping: Butuh detail lebih? Thunderbit bisa membuka setiap subpage (seperti halaman produk individual) dan memperkaya tabel data Anda secara otomatis.
- Template Instan: Untuk situs populer seperti Amazon atau Zillow, Anda bisa memakai template siap pakai—tanpa setup.
- Ekspor Data Gratis: Ekspor data ke Excel, Google Sheets, Airtable, atau Notion. Unduh sebagai CSV atau JSON. Tanpa biaya tersembunyi.
- Scheduled Scraping: Atur scraping berkala agar data tetap segar—cocok untuk pemantauan harga atau pembaruan lead.
- AI Autofill: Biarkan AI mengisi formulir online untuk Anda (ya, bahkan formulir onboarding vendor 10 halaman itu).
- Email, Phone, dan Image Extractors: Ambil info kontak atau gambar dalam satu klik.
Dan bagian terbaiknya? Anda tidak perlu paham coding sama sekali. Ekstensi Chrome Thunderbit tersedia di sini, dan Anda bisa pelajari lebih lanjut di website resmi kami.
Coba AI Web Scraper Thunderbit Gratis
Membandingkan Solusi Web Scraper Tradisional vs AI
Mari lihat bagaimana kedua pendekatan ini dibandingkan:
| Aspek | Web Scraper Tradisional | AI Web Scraper (Thunderbit) |
|---|---|---|
| Kemudahan Penggunaan | Butuh coding atau setup yang kompleks | Tanpa kode, antarmuka bahasa alami |
| Adaptabilitas | Mudah rusak saat situs berubah | AI menyesuaikan perubahan tata letak secara otomatis |
| Maintenance | Tinggi—perlu pembaruan sering | Rendah—AI menangani sebagian besar perubahan |
| Keahlian Teknis | Memerlukan pengetahuan pemrograman dan HTML | Dirancang untuk pengguna bisnis |
| Kecepatan Setup | Beberapa jam hingga beberapa hari | Beberapa menit |
| Pemrosesan Data | Perlu pembersihan manual | AI membersihkan dan menstrukturkan data otomatis |
| Biaya | Gratis (open source), tetapi investasi waktu tinggi | Paket terjangkau, opsi ekspor gratis |
Bagi kebanyakan pengguna bisnis, terutama pemula, AI web scraper seperti Thunderbit adalah pemenang jelas dalam hal kecepatan, kemudahan, dan keandalan. Tools tradisional masih punya tempat untuk proyek yang sangat kustom atau berskala besar—tetapi untuk 95% use case, AI adalah pilihan terbaik.
Panduan Langkah demi Langkah: Cara Mengambil Data dari Website bagi Pemula
Langkah 1: Tentukan Tujuan Ekstraksi Data Anda
Sebelum mulai, pastikan Anda jelas soal apa yang dibutuhkan. Tanyakan pada diri sendiri:
- Website apa yang ingin saya scrape?
- Field data apa yang penting? (misalnya nama produk, harga, email, telepon)
- Seberapa sering data ini dibutuhkan? (sekali atau berkala?)
Buat daftar periksa. Contohnya: “Saya ingin mengumpulkan nama produk, harga, dan rating dari 5 halaman pertama XYZ.com.”
Langkah 2: Pilih Web Scraper yang Tepat
Ini alur keputusan singkat:
- Nyaman dengan kode dan ingin kontrol penuh? Coba tool tradisional seperti BeautifulSoup atau Scrapy.
- Ingin cepat, mudah, dan tanpa kode? Gunakan AI web scraper seperti Thunderbit.
Kalau Anda belum yakin, mulai saja dengan AI. Nanti Anda selalu bisa mendalami lebih jauh.
Langkah 3: Siapkan dan Jalankan Ekstraksi Data Anda
Pendekatan Tradisional
- Instal tool Anda: Siapkan Python dan library yang diperlukan.
- Periksa website: Gunakan DevTools browser untuk menemukan struktur HTML.
- Tulis script Anda: Tentukan cara menemukan dan mengekstrak setiap field data.
- Uji di satu halaman: Pastikan data yang didapat sudah benar.
- Skalakan: Tambahkan pagination atau loop untuk menjangkau lebih banyak halaman.
- Ekspor data: Simpan sebagai CSV atau JSON.
Pendekatan AI (Thunderbit)
- Instal Ekstensi Chrome Thunderbit: Unduh di sini.
- Buka website target: Masuk ke halaman yang ingin Anda scrape.
- Klik “AI Suggest Fields”: Thunderbit akan membaca halaman dan menyarankan kolom.
- Periksa pratinjau: Pastikan data terlihat benar. Sesuaikan kolom jika perlu.
- Klik “Scrape”: Thunderbit mengumpulkan data untuk Anda.
- Ekspor data: Unduh ke Excel, Google Sheets, Airtable, atau Notion.
Untuk panduan visual, lihat Channel YouTube Thunderbit kami.
Scrape Data Website dengan Thunderbit
Langkah 4: Ekspor dan Gunakan Data Anda
Setelah Anda punya datanya:
- Ekspor ke tool favorit Anda: Excel, Google Sheets, Airtable, Notion, CSV, atau JSON.
- Integrasikan ke alur kerja Anda: Gunakan untuk outreach sales, analisis harga, riset pasar, atau kebutuhan bisnis apa pun.
- Bersihkan dan validasi: Bahkan dengan AI, tetap bijak untuk mengecek sampel data Anda demi akurasi.
Tips Sukses Ekstraksi Data: Hindari Kesalahan Umum
- Periksa ketentuan layanan website: Pastikan Anda memang boleh mengambil data tersebut. Fokus pada info publik dan hindari data pribadi yang sensitif.
- Jangan membebani website: Tambahkan jeda antar permintaan (untuk tool tradisional) atau biarkan Thunderbit yang menanganinya.
- Validasi data Anda: Selalu periksa sampel hasil untuk memastikan akurasi.
- Siapkan diri untuk perubahan: Website terus diperbarui. AI scraper seperti Thunderbit menyesuaikan diri otomatis, tetapi tetap baik untuk memantau perubahan besar.
- Tetap etis: Ambil hanya data yang Anda butuhkan, dan berikan kredit jika Anda menggunakan data tersebut dalam laporan atau publikasi.
Untuk tips lebih lanjut, lihat Apa Itu Data Scraping dan Cara Melakukannya di 2025 dan Cara Mengambil Data dari Website Apa Pun باستخدام AI.
Kesimpulan & Poin Utama
Web scraping sudah jauh berkembang—from zaman script yang dikodekan manual hingga tool bertenaga AI yang ramah pemula saat ini. Perbedaan utamanya?

- Scraper tradisional memberi kontrol, tetapi butuh coding, maintenance, dan kesabaran.
- AI web scraper seperti Thunderbit membuat ekstraksi data bisa diakses semua orang, dengan perintah bahasa alami, pratinjau instan, dan fitur kuat seperti subpage dan scheduled scraping.
Kalau Anda baru mengenal web scraping, jangan takut. Tools sekarang belum pernah semudah ini, dan manfaat bisnisnya sangat nyata. Entah Anda ingin menghasilkan lead, memantau harga, atau sekadar berhenti menyalin dan menempel, AI web scraper adalah sahabat baru Anda.
Jadi, lain kali Anda menatap tumpukan data web yang menggunung, ingat: Anda tidak perlu gelar PhD ilmu komputer—atau bahkan hoodie. Cukup tujuan yang jelas, tool yang tepat, dan mungkin secangkir kopi yang enak.
Siap mencobanya sendiri? Instal Thunderbit dan lihat betapa mudahnya ekstraksi data web.
Tertarik lebih lanjut? Kunjungi Blog Thunderbit untuk pembahasan mendalam tentang scraping Amazon, Google, PDF, dan lainnya. Selamat scraping!
Coba AI Web Scraper Thunderbit Sekarang Get Started Free
FAQ
Q1: Apakah web scraping legal? A: Ya, mengambil data publik umumnya legal di banyak negara. Namun, selalu periksa ketentuan layanan website dan hindari mengambil data sensitif atau pribadi.
Q2: Bisakah saya scrape website yang memerlukan login? A: Bisa, tetapi lebih kompleks dan mungkin melanggar kebijakan situs. Anda memerlukan penanganan sesi atau tools scraping terautentikasi, dan penting untuk meninjau implikasi hukumnya.
Q3: Bagaimana cara mengambil data dari website yang banyak memakai JavaScript? A: Gunakan tools yang mendukung rendering dinamis, seperti headless browser atau AI scraper yang mensimulasikan interaksi manusia dan mem-parsing konten yang dirender JavaScript.
Q4: Apa praktik terbaik agar tidak diblokir? A: Gunakan rate limiting, jeda acak, rotasi user-agent, dan hindari scraping secara agresif. AI-based scraper sering kali menangani strategi ini secara otomatis.
Baca Selengkapnya
-
Memahami Legalitas Web Scraping: Wawasan & Statistik Global Ikhtisar panduan hukum, statistik industri, dan praktik etis terbaik.
-
Laporan State of web scraping 2025 Tren, pertumbuhan pasar, dan peran AI dalam ekstraksi data web (2024–2025).
-
Apa Itu File Robots.txt? Panduan Praktik Terbaik dan Sintaks Pelajari cara menafsirkan file robots.txt untuk membantu scraping yang etis dan legal.




