
Setiap AI web scraper terlihat bagus saat demo produk. Lalu Anda arahkan ke situs nyata yang dilindungi Cloudflare, dan alat itu malah menampilkan halaman challenge sambil dengan penuh percaya diri bilang ia menemukan 47 listing produk.
Selama beberapa bulan terakhir, saya mengevaluasi alat scraping untuk tim kami di Thunderbit. Kesenjangan antara performa demo dan keandalan di produksi adalah sumber frustrasi terbesar yang terus saya lihat di komunitas. Seorang pengguna Reddit merangkumnya dengan tepat: Dengan hanya untuk kategori web scraping, ditambah puluhan ekstensi Chrome, vendor API, dan marketplace actor, paradoks pilihan benar-benar nyata. Jadi saya menguji 12 di antaranya.
Artikel ini mengevaluasi 12 alat AI web scraper berdasarkan kriteria produksi: penanganan anti-bot, skalabilitas, kualitas output terstruktur, efisiensi biaya, dukungan situs dinamis, dan fleksibilitas untuk developer. Bukan daftar fitur. Bukan screenshot marketing. Hanya apa yang benar-benar berfungsi setelah demo selesai.
Mengapa Kebanyakan AI Web Scraper Gagal Setelah Demo
Pola kegagalannya mudah ditebak. Situs marketing sebuah alat menampilkan ekstraksi kolom yang rapi dari halaman daftar produk sederhana. Anda memasangnya, mencobanya di situs e-commerce yang dilindungi, lalu mendapat salah satu dari ini:
- Respons
200 OKyang berisi halaman challenge Cloudflare, bukan data asli - Hasil bersih untuk 5 halaman pertama, lalu gagal diam-diam atau baris yang terhalusinasi
- Ekstraksi sempurna hari ini, selector rusak minggu depan setelah update tata letak kecil
Ini bukan kasus pinggiran. Ini hal yang umum.
Seperti yang : "Scraper mengembalikan 200 dengan halaman challenge Cloudflare, agen Anda mencoba menalar isinya, malah berhalusinasi, dan Anda bahkan tidak tahu kenapa."
Akar masalahnya ada pada arsitektur. Kebanyakan demo menyorot lapisan parsing pada halaman publik yang bersih, sementara pekerjaan nyata gagal di lapisan fetching. Situs produksi menambahkan proteksi bot, rendering dinamis, halaman detail bertingkat, infinite scroll, status login, perbedaan locale, dan tata letak yang berubah.
Sebuah alat bisa terlihat hebat di product tour, lalu tetap runtuh dalam alur kerja pelanggan serius pertama.
Itulah mengapa artikel ini menilai setiap alat dari sudut pandang kesiapan produksi, bukan daftar fitur. Enam kriteria yang saya gunakan:
| Kriteria | Mengapa Penting |
|---|---|
| Penanganan anti-bot/CAPTCHA | Situs terlindungi gagal bahkan sebelum kualitas ekstraksi relevan |
| Skalabilitas di luar demo | Job batch dan run paralel mengungkap batas operasional |
| Kualitas output terstruktur | Pengguna butuh JSON/CSV bersih, bukan HTML mentah yang harus dibersihkan manual |
| Efisiensi token/biaya | Ekstraksi AI bisa lebih mahal daripada scraping itu sendiri |
| Dukungan situs dinamis/berat JS | Halaman modern butuh DOM yang sudah dirender, bukan HTML statis |
| Fleksibilitas no-code vs API | Tim sales dan engineer data punya kebutuhan yang berbeda |
Kalau Anda ingin gambaran pasar tingkat tinggi tentang bagaimana web scraping berubah dalam dua tahun terakhir, pembicaraan Browserless ini bagus untuk memberi konteks sebelum Anda membandingkan alat satu per satu.
Di Mana AI Benar-Benar Membantu dalam Pipeline Scraping (dan Di Mana Tidak)
Mitos yang masih bertahan di pasar ini adalah bahwa istilah "AI web scraper" berarti AI menangani semuanya dari ujung ke ujung. Konsensus komunitas justru sangat jelas: . Pendapat blak-blakan seorang pengguna: "Anda memakai AI untuk membaca screenshot halaman web. Anda tidak memakai AI untuk menulis kode scraper itu sendiri."
Pipeline scraping punya tiga lapisan yang berbeda, dan nilai AI sangat bervariasi di tiap lapisan:
Crawling dan Fetching: Lapisan Infrastruktur
Di sinilah request terjadi: proxy, browser headless, manajemen sesi, pemecahan CAPTCHA, retry. AI hampir tidak membantu apa pun di sini. Anda tetap butuh pool proxy, browser fingerprinting, dan infrastruktur unblocking. Inilah bagian yang paling sering gagal duluan di produksi.
Parsing dan Ekstraksi: Saat AI Bersinar
Begitu Anda punya konten halaman yang bersih, AI unggul mengubah HTML tak terstruktur menjadi field terstruktur. Ekstraksi berbasis skema, deteksi field adaptif, dan penanganan variasi tata letak tanpa selector XPath yang rapuh adalah titik kuat AI dalam scraping.
Post-Processing: Pelabelan, Penerjemahan, Pengelompokan
Setelah ekstraksi, AI memberi nilai tambah dengan mengelompokkan produk, menerjemahkan teks, menormalkan nomor telepon, atau meringkas deskripsi. Cocok, tetapi hanya jika data yang diekstrak memang sudah benar.
Berikut cara 12 alat ini dipetakan ke tiga lapisan tersebut:
| Alat | Crawling/Fetching | Parsing/Ekstraksi | Post-Processing | Deskripsi Terbaik |
|---|---|---|---|---|
| Thunderbit | Kuat | Kuat | Kuat | AI scraper no-code full-stack |
| Octoparse | Kuat | Sedang | Rendah | Scraper visual berbasis aturan dengan infrastruktur cloud |
| Browse AI | Sedang | Sedang | Sedang | Platform robot cloud yang fokus pada monitoring |
| Firecrawl | Sedang | Kuat | Rendah-Sedang | API ekstraksi untuk developer |
| Apify | Kuat | Sedang-Kuat | Sedang | Marketplace actor dan orkestrasi |
| Gumloop | Sedang | Sedang | Kuat | Otomasi workflow dengan node scraper |
| Bright Data | Sangat Kuat | Sedang | Rendah-Sedang | Stack infrastruktur enterprise |
| Bardeen | Sedang | Sedang | Kuat | Otomasi browser untuk workflow GTM |
| Diffbot | Rendah-Sedang | Sangat Kuat | Sedang | Ekstraksi terlatih plus knowledge graph |
| ScrapingBee | Kuat | Rendah-Sedang | Rendah | API fetching dan unblocking |
| Instant Data Scraper | Rendah | Sedang (halaman sederhana) | Rendah | Scraper cepat berbasis heuristik di browser |
| ParseHub | Sedang | Sedang | Rendah | Scraper visual desktop untuk interaksi kompleks |
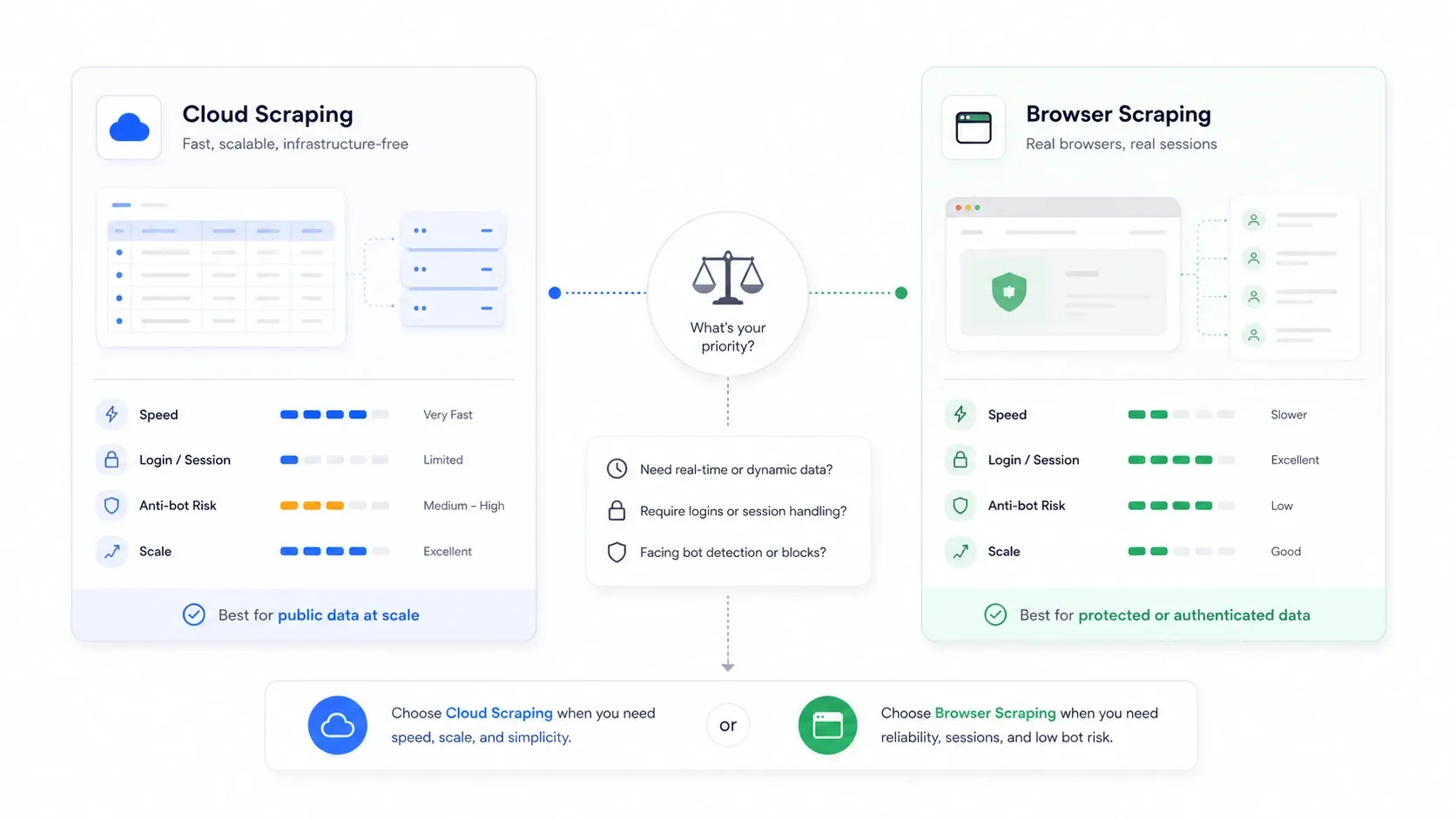
Cloud Scraping vs. Browser Scraping: Pilihan yang Tidak Dijelaskan Siapa Pun
Ini adalah keputusan arsitektural yang paling sering diabaikan oleh artikel roundup, padahal sering kali lebih penting daripada alat apa yang Anda pilih.
Cloud scraping berarti server jarak jauh mengambil halaman untuk Anda. Browser scraping berarti ekstraksi terjadi di sesi browser Anda sendiri, menggunakan cookie, IP, dan status autentikasi Anda.
| Skenario | Mode yang Lebih Baik | Mengapa |
|---|---|---|
| Situs e-commerce publik dan listing dalam volume besar | Cloud | Paralelisme lebih cepat dan tidak tergantung bottleneck mesin lokal |
| Situs yang memerlukan login atau autentikasi | Browser | Memakai cookie sesi asli Anda |
| Situs yang menghukum IP data center | Browser | Tampak seperti traffic pengguna normal |
| Job monitoring besar yang berulang | Cloud | Penjadwalan dan kontinuitas lebih mudah |
| Job satu kali yang rapuh dan sensitif anti-bot | Browser | Lebih mudah melihat apa yang benar-benar dirender situs |
Dari sisi ekonomi, ini juga penting. Laporan State of Web Scraping 2026 dari Apify menemukan bahwa dari tahun ke tahun, dan melaporkan pengeluaran infrastruktur yang lebih tinggi. Anti-bot bukan hanya masalah teknis. Ini juga masalah anggaran.
Kebanyakan alat hanya menawarkan satu mode. Berikut rinciannya:
| Alat | Cloud | Browser | Keduanya |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (lokal) | ✅ |
| Browse AI | ✅ | Hanya setup | — |
| Firecrawl | ✅ | API untuk interaktif | — |
| Apify | ✅ | ✅ (via actor) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Terbatas (halaman publik) | ✅ | Parsial |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (berbayar) | ✅ (desktop) | ✅ |
12 AI Web Scraper dalam Sekilas
Berikut perbandingan utama dari 12 alat tersebut:
| Alat | Paling Cocok Untuk | Tier Gratis | Cloud/Browser | Akses API | Penjadwalan Scraping | Penanganan Anti-Bot |
|---|---|---|---|---|---|---|
| Thunderbit | Tim non-teknis | ✅ (6 halaman) | Keduanya | ✅ | ✅ | Kuat |
| Octoparse | Scraping yang banyak template | ✅ (terbatas) | Keduanya | ✅ | ✅ | Sedang-Kuat |
| Browse AI | Monitoring perubahan | ✅ (terbatas) | Utamanya cloud | ✅ | ✅ | Sedang |
| Firecrawl | Pipeline ekstraksi developer | ✅ (1.000 kredit/bulan) | Cloud plus API browser | ✅ | Tidak | Sedang |
| Apify | Tim developer plus marketplace | ✅ (penggunaan gratis $5) | Keduanya | ✅ | ✅ | Kuat dengan add-on |
| Gumloop | Otomasi workflow | ✅ (5.000 kredit/bulan) | Keduanya | ✅ | ✅ | Sedang |
| Bright Data | Akses data enterprise | Trial / kredit | Keduanya | ✅ | Eksternal | Sangat Kuat |
| Bardeen | Otomasi browser sales dan ops | ✅ (100 kredit) | Browser-first | Terbatas | ✅ | Sedang-Rendah |
| Diffbot | API ekstraksi terstruktur | ✅ (10.000 kredit) | Cloud | ✅ | Tidak | Rendah untuk fetching / tinggi untuk ekstraksi |
| ScrapingBee | Fetching dan unblocking untuk developer | ✅ (1.000 kredit) | Cloud | ✅ | Tidak | Kuat |
| Instant Data Scraper | Scrape sekali pakai gratis | ✅ (gratis sepenuhnya) | Hanya browser | Tidak | Tidak | Rendah |
| ParseHub | Workflow visual kompleks | ✅ (5 proyek) | Desktop plus cloud | ✅ | ✅ (berbayar) | Sedang |
1. Thunderbit
adalah AI web scraper yang kami bangun khusus untuk tim non-teknis yang membutuhkan data berkualitas produksi tanpa menulis kode atau mengelola infrastruktur. Alur utamanya benar-benar dua klik: AI Suggest Fields membaca halaman dan mengusulkan kolom, lalu Scrape menjalankan ekstraksi dalam mode cloud atau browser.
Yang membedakannya dari scraper no-code lain adalah arsitekturnya. Thunderbit memisahkan urusan crawling seperti infrastruktur cloud, rotasi proxy, penanganan anti-bot, dan rendering JavaScript dari ekstraksi AI yang membaca HTML dan menghasilkan kolom terstruktur. Ini sesuai dengan pola yang direkomendasikan para ahli, yaitu "scraper dulu, LLM belakangan", tetapi dikemas dalam workflow ekstensi Chrome yang benar-benar bisa dipakai tim sales dan ops.
Kekuatan Utama
- Cloud dan browser scraping dalam satu antarmuka. Pindah mode sesuai apakah situs target bersifat publik atau memerlukan sesi autentikasi Anda. Mode cloud menangani hingga 50 halaman secara paralel.
- AI membaca ulang struktur halaman setiap kali. Tidak perlu maintenance XPath. Saat situs mengubah tata letaknya, Thunderbit menyesuaikan otomatis pada run berikutnya.
- Subpage scraping. AI mengunjungi halaman detail yang terhubung dan memperkaya tabel data utama tanpa konfigurasi manual.
- Field AI Prompts. Pelabelan, penerjemahan, dan pengelompokan kustom saat ekstraksi, bukan sebagai langkah post-processing terpisah.
- Ekspor gratis ke Google Sheets, Excel, Airtable, dan Notion.
- Template scraper instan untuk situs populer seperti Amazon, Zillow, dan LinkedIn.
- Penjadwalan dengan bahasa natural. Cukup katakan "scrape setiap Senin jam 9 pagi" dan alat akan mengubahnya menjadi jadwal berulang.
- Open API dengan endpoint Distill dan Extract, pemrosesan batch hingga 100 URL, serta concurrency yang dipublikasikan dari 2 pada versi gratis hingga 50 pada Pro 1.
Hal yang Bisa Ditingkatkan
- Tier gratis memang sengaja dibuat kecil.
- Pengalaman no-code masih sangat berpusat pada ekstensi Chrome. Developer yang ingin workflow hanya API perlu memakai Open API secara terpisah.
- Bukan alat yang tepat jika kebutuhan utama Anda adalah infrastruktur proxy mentah tanpa ekstraksi.
Harga
Tier gratis tersedia. Paket no-code mulai dari $9/bulan bila ditagih tahunan atau $15/bulan jika ditagih bulanan untuk Starter. Harga API terpisah: gratis sekali pakai 600 unit, lalu $16/bulan tahunan untuk Starter API dan $40/bulan tahunan untuk Pro 1 API. Lihat dan .
Paling cocok untuk: Tim sales, e-commerce, dan operasional yang membutuhkan data web terstruktur tanpa dukungan engineering.
2. Octoparse
adalah pembuat workflow visual untuk web scraping dengan pustaka template bawaan yang besar. Alat ini sudah cukup lama hadir sehingga infrastrukturnya matang di cloud, dan bekerja baik untuk pagination pada situs yang terstruktur dan bisa diprediksi.
Kekuatan Utama
- Template scraping bawaan yang sangat banyak untuk situs populer
- Ekstraksi cloud dengan run terjadwal
- Rotasi IP dan pemecahan CAPTCHA sebagai add-on berbayar
- Akses API di paket yang lebih tinggi
Hal yang Bisa Ditingkatkan
- Kemampuan AI lebih ringan dibanding alat native-LLM. Saran field masih lebih banyak bergantung pada template daripada pembacaan adaptif.
- Tata letak yang kompleks atau tidak biasa membutuhkan penyesuaian manual yang signifikan di editor visual.
- Kurva belajarnya menjadi lebih curam saat Anda butuh logika kondisional atau workaround anti-blocking.
Harga
Tersedia paket gratis selamanya. Harga di pusat bantuan resmi saat ini mengarah ke Standard mulai $75/bulan bila ditagih tahunan dan Professional mulai $208/bulan bila ditagih tahunan, sementara beberapa halaman lokal dan jalur upgrade menampilkan ekuivalen bulanan yang lebih tinggi. Poin pentingnya: harga Octoparse sekarang memadukan langganan dengan add-on berbayar seperti residential proxy dan pemecahan CAPTCHA.
Paling cocok untuk: Analis dan tim ops yang melakukan scraping situs terstruktur dan ramah template dalam skala sedang.
3. Browse AI
adalah platform no-code berbasis cloud yang terutama dibangun untuk memantau perubahan situs dari waktu ke waktu, seperti harga kompetitor, ketersediaan stok, dan pembaruan konten. Scraping adalah bagian dari produk ini, tetapi pembeda utamanya adalah sistem monitoring dan alert yang berulang.
Kekuatan Utama
- Deteksi perubahan dan alert bawaan
- Perekam robot no-code dengan setup klik-dan-pilih
- Robot bawaan untuk situs populer
- Dukungan premium proxy pada paket yang lebih tinggi
Hal yang Bisa Ditingkatkan
- Harga berbasis kredit cepat menjadi mahal saat memantau halaman detail dalam skala besar
- Kurang menarik untuk ekstraksi sekali jalan skala besar dibanding alat API-first
- Penanganan anti-bot berada di level sedang; beberapa situs tetap memerlukan premium proxy atau workaround
Harga
Akun gratis tersedia. Paket berbayar mulai sekitar $19/bulan bila ditagih tahunan untuk Starter, dengan tier kredit dan monitoring yang lebih tinggi di atasnya.
Paling cocok untuk: Tim yang membutuhkan monitoring berkelanjutan terhadap harga kompetitor, perubahan konten, atau level stok, bukan ekstraksi massal satu kali.
4. Firecrawl
adalah API yang berfokus pada developer untuk mengubah halaman web menjadi Markdown bersih atau JSON terstruktur. Alat ini terutama berada di lapisan ekstraksi dan sangat cocok untuk tim yang membangun pipeline RAG atau memasukkan konten web ke LLM.
Kekuatan Utama
- Kualitas output Markdown yang sangat baik untuk workflow LLM lanjutan
- API bersih dengan scrape, crawl, map, search, extract, dan aksi browser
- Mendukung pemrosesan batch
- Concurrency dari 2 pada versi gratis hingga 100 pada Growth
Hal yang Bisa Ditingkatkan
- Tidak ada antarmuka no-code dan memerlukan kemampuan developer
- Ada dukungan proxy dan anti-bot bawaan, tetapi Firecrawl tidak diposisikan seperti vendor unblocking khusus
- Tidak ada scheduler pihak pertama untuk job berulang
- Kurang hemat biaya bagi non-developer yang hanya ingin spreadsheet data
Harga
Paket gratis menyertakan 1.000 kredit per bulan. Paket berbayar mulai $16/bulan tahunan untuk Hobby dan naik dengan lebih banyak kredit, concurrency, dan penggunaan browser. Sesi browser ditagihkan terpisah dalam kredit.
Paling cocok untuk: Developer yang membangun pipeline LLM, sistem RAG, atau workflow ekstraksi kustom yang membutuhkan Markdown atau JSON bersih dari halaman web.
5. Apify
adalah platform dengan marketplace actor scraping bawaan plus alat untuk membangun actor kustom. Anggap saja ini sebagai lapisan orkestrasi tempat Anda memilih atau membangun scraper spesialis untuk situs tertentu, lalu menjadwalkan dan mengelolanya melalui API terpadu.
Kekuatan Utama
- Marketplace actor besar dengan scraper buatan komunitas untuk ratusan situs
- API dan SDK yang kuat untuk developer
- Manajemen proxy dan penjadwalan bawaan
- Terintegrasi dengan banyak alat downstream
Hal yang Bisa Ditingkatkan
- "No-code" hanya setengah benar begitu Anda keluar dari marketplace dan butuh logika kustom
- Keandalan actor bergantung pada pemeliharaan komunitas
- Harga bisa melonjak karena biaya komputasi, actor, dan proxy bertumpuk
Harga
Tier gratis mencakup $5 kredit platform per bulan. Paket berbayar mulai $39/bulan untuk Starter, dengan tier yang lebih besar di atasnya.
Paling cocok untuk: Tim developer yang menginginkan workflow scraping yang dapat dipakai ulang dan dijadwalkan dengan ekosistem solusi bawaan yang besar.
6. Gumloop
adalah platform otomasi workflow no-code yang menyertakan node web scraping. Nilai utamanya bukan scraping saja. Melainkan menghubungkan ekstraksi ke LLM, Google Sheets, CRM, dan alat lain dalam satu kanvas visual.
Kekuatan Utama
- Pembuat workflow visual drag-and-drop
- Mengintegrasikan scraping dengan LLM dan alat bisnis downstream dalam satu alur
- Paket gratis saat ini dipromosikan dengan 5.000 kredit/bulan
- Penjadwalan berbasis waktu untuk workflow berulang
- Mode scraping dasar dan Web Agent interaktif mencakup alur sederhana maupun yang lebih kaya
Hal yang Bisa Ditingkatkan
- Mesin scraping kurang tangguh dibanding alat AI web scraper khusus
- Anti-bot dan kedalaman proxy lebih terbatas dibanding vendor spesialis
- Batas concurrency dan trigger lebih ketat pada paket gratis
- Tidak ideal untuk scraping skala besar ber-volume tinggi sebagai use case utama
Harga
Paket gratis tersedia. Gumloop menggabungkan struktur lama Solo dan Team menjadi paket Pro pada akhir 2025, dan pesan publik sejak itu lebih berfokus pada kredit gratis yang lebih besar serta tier berbayar yang terkonsolidasi, bukan harga yang berpusat pada scraper.
Paling cocok untuk: Tim yang ingin scraping menjadi salah satu langkah dalam workflow otomatis yang lebih luas: scrape, analisis, lalu kirim ke alat bisnis.
Jika Anda ingin melihat seperti apa workflow ekstraksi native AI dalam praktik sebelum membaca sisa daftar ini, walkthrough Thunderbit ini adalah demo produk yang paling relevan untuk tim non-teknis.
7. Bright Data
adalah stack infrastruktur kelas enterprise dalam daftar ini. Jika masalah Anda adalah "Saya tidak bisa melewati proteksi bot di situs ini apa pun yang saya coba," Bright Data mungkin jawabannya, tetapi itu datang bersama kompleksitas dan harga enterprise yang sepadan.
Kekuatan Utama
- Jaringan proxy terdepan di industri untuk residential, data center, dan IP mobile
- Web Unlocker untuk anti-bot dan bypass CAPTCHA
- Scraping Browser dengan unblocking bawaan
- Dataset yang sudah dikumpulkan bisa dibeli
- Kontrol programatik penuh via API dan SDK
Hal yang Bisa Ditingkatkan
- Tidak dirancang untuk pengguna non-teknis
- Harga mencerminkan positioning enterprise
- Ekstraksi AI bukan alasan utama membeli platform ini
Harga
Browser API mulai dari $8/GB bayar sesuai pemakaian, dengan tarif per GB lebih rendah pada komitmen bulanan yang lebih besar. Produk Bright Data lain seperti Unlocker, Scraper API, dataset, dan pool proxy memakai unit harga yang berbeda.
Paling cocok untuk: Tim data enterprise yang perlu scraping situs yang sangat dilindungi dalam skala besar dan memiliki staf teknis untuk mengelola infrastrukturnya.
8. Bardeen
adalah alat otomasi browser yang berfokus pada klik, pengisian formulir, dan scraping dengan ekstraksi data berbasis AI di atasnya. Paling tepat dipahami sebagai alat workflow GTM yang kebetulan juga melakukan scraping, bukan alat scraping yang kebetulan dipakai untuk GTM.
Kekuatan Utama
- Otomasi gaya playbook yang intuitif dengan scraping sebagai salah satu langkah
- Scraper resmi yang dipelihara tim Bardeen untuk situs populer
- Integrasi kuat dengan CRM, Google Sheets, Slack, dan alat bisnis lainnya
- Cocok untuk workflow scraping lead, enrichment, dan ekspor ke CRM
Hal yang Bisa Ditingkatkan
- Arsitektur browser-first membatasi scraping tanpa pengawasan dalam volume tinggi
- Cloud scraping hanya berjalan pada halaman publik, bukan yang terkunci
- Penanganan anti-bot terutama bergantung pada apa yang sudah disediakan sesi browser Anda
- Ekstraksi AI bisa kesulitan pada tata letak halaman yang kompleks atau tidak standar
Harga
Paket gratis mencakup 100 kredit bulanan. Dokumentasi dukungan publik merujuk pada harga legacy $15/bulan Pro untuk pengguna lama, sementara paket komersial Bardeen saat ini lebih berorientasi enterprise dan workflow daripada harga scraper kelas bawah yang klasik.
Paling cocok untuk: Tim sales dan ops yang membutuhkan scraping sebagai bagian dari workflow otomasi browser yang lebih luas.
9. Diffbot
menggunakan computer vision dan NLP untuk membaca halaman web seperti manusia, lalu mengeluarkan data terstruktur untuk artikel, produk, diskusi, dan organisasi. Ini adalah salah satu API ekstraksi berkualitas tertinggi yang tersedia jika halaman Anda cocok dengan model pra-latihnya.
Kekuatan Utama
- Model ekstraksi pra-latih untuk artikel, produk, diskusi, dan lainnya
- Knowledge Graph dengan miliaran entitas untuk enrichment data
- Kualitas output terstruktur yang sangat kuat pada tipe halaman yang didukung
- API developer yang jelas dengan batas rate yang dipublikasikan
Hal yang Bisa Ditingkatkan
- Tidak ada antarmuka no-code
- Tidak ada crawling bawaan, manajemen proxy, atau penanganan anti-bot
- Mahal untuk tim kecil
- Kurang fleksibel pada tipe halaman non-standar dibanding extractor berbasis schema-prompt
Harga
Paket gratis mencakup 10.000 kredit. Startup adalah $299/bulan untuk 250.000 kredit, dan Plus adalah $899/bulan untuk 1.000.000 kredit.
Paling cocok untuk: Tim developer yang membutuhkan ekstraksi terstruktur dengan akurasi tinggi dari tipe halaman standar dan bersedia menangani fetching secara terpisah.
10. ScrapingBee
adalah API web scraping yang berfokus pada lapisan fetching dan unblocking. Anda mengirimkan URL, lalu alat ini menangani proxy, rendering browser headless, dan pertahanan anti-bot, kemudian mengembalikan HTML atau data yang diekstrak secara opsional.
Kekuatan Utama
- Rotasi proxy bawaan dan penanganan anti-bot
- Dukungan rendering JavaScript
- REST API sederhana
- Endpoint scraping Google Search
- Concurrency yang dipublikasikan berdasarkan paket
Hal yang Bisa Ditingkatkan
- Fitur ekstraksi AI terbatas
- Tidak ada antarmuka no-code
- Tidak ada penjadwalan atau monitoring bawaan
- Respons
200dengan halaman pemblokiran tetap bisa dihitung sebagai request berhasil
Harga
Paket gratis mencakup 1.000 kredit API. Paket berbayar mulai $49/bulan dan meningkat seiring concurrency serta volume request yang lebih besar.
Paling cocok untuk: Developer yang terutama membutuhkan fetching halaman yang andal melewati pertahanan anti-bot dan akan menangani ekstraksi dengan kode sendiri atau alat terpisah.
11. Instant Data Scraper
adalah ekstensi Chrome gratis dengan lebih dari 1.000.000 pengguna yang secara otomatis mendeteksi pola data di halaman dan memungkinkan Anda mengekspor ke CSV atau Excel. Tidak ada saran field AI dalam pengertian LLM. Alat ini memakai deteksi pola berbasis heuristik.
Kekuatan Utama
- Sepenuhnya gratis, tanpa perlu akun
- Deteksi data satu klik pada banyak halaman listing dan tabel
- Menangani pagination pada beberapa situs
- Hambatan masuk sangat rendah
- Masih dipelihara, dengan pembaruan Chrome Web Store pada 2026
Hal yang Bisa Ditingkatkan
- Tidak ada saran field atau pelabelan data berbasis AI
- Tidak ada cloud scraping, penjadwalan, atau API
- Kesulitan dengan tata letak kompleks, konten dinamis, dan situs berat JS
- Tidak ada penanganan anti-bot di luar apa yang sudah bisa dimuat browser Anda
- Ekspor terbatas ke CSV dan Excel
Harga
Gratis. Selamanya.
Paling cocok untuk: Siapa pun yang butuh scrape cepat sekali jalan pada halaman listing sederhana dan tidak ingin membuat akun atau membayar apa pun.
12. ParseHub
adalah aplikasi desktop dengan antarmuka visual klik-dan-pilih untuk membangun proyek scraping. Alat ini bisa menangani data bertingkat yang kompleks, konten yang dimuat AJAX, infinite scroll, dan interaksi dropdown yang sering luput oleh ekstensi yang lebih sederhana.
Kekuatan Utama
- Antarmuka selector visual untuk mendefinisikan aturan ekstraksi
- Menangani data bertingkat, dropdown, infinite scroll, dan konten AJAX
- Tier gratis hingga 5 proyek
- Ekspor ke JSON, CSV, dan Excel
- Penjadwalan cloud dan rotasi IP pada paket berbayar
Hal yang Bisa Ditingkatkan
- Workflow hanya desktop, tanpa kenyamanan ekstensi browser
- Kecepatan eksekusi lebih lambat dibanding alat native cloud
- Proyek bisa rusak saat tata letak situs berubah karena tidak ada lapisan AI yang membaca ulang
- Kemampuan AI terbatas dan terasa lebih seperti scraper visual generasi lama
Harga
Paket gratis tersedia dengan 5 proyek dan 200 halaman per run. Paket berbayar mulai $189/bulan dengan penjadwalan, rotasi IP, dan batas yang lebih tinggi.
Paling cocok untuk: Pengguna non-teknis yang perlu scraping situs interaktif kompleks dan bersedia meluangkan waktu untuk setup workflow visual.
Cara Memulai AI Web Scraper dalam 5 Langkah
Setiap alat dalam daftar ini punya alur onboarding yang berbeda. Saya akan memakai Thunderbit sebagai contoh konkret karena paling cocok dengan niat pencarian "saya cuma perlu ini bekerja di halaman nyata".
Langkah 1: Instal dan Navigasi
Instal dan buka halaman yang ingin Anda scrape: daftar produk, direktori, atau portal properti.
Langkah 2: Biarkan AI Mengusulkan Field Data Anda
Klik AI Suggest Fields. AI membaca halaman saat ini dan mengusulkan nama kolom serta tipe data. Pada halaman produk, misalnya, alat ini bisa menyarankan Nama Produk, Harga, Rating, URL Gambar, dan Deskripsi.
Langkah 3: Sesuaikan Field dengan Prompt AI
Atur kolom jika default-nya belum pas. Tambahkan Field AI Prompts untuk transformasi kustom seperti "terjemahkan deskripsi ke bahasa Spanyol", "kelompokkan sebagai Elektronik, Rumah, atau Fashion", atau "ambil hanya harga numeriknya".
Langkah 4: Pilih Mode Cloud atau Browser lalu Scrape
Pilih cloud scraping untuk situs publik atau browser scraping untuk target yang autentikasinya sudah tersimpan atau yang sangat dilindungi. Lalu klik Scrape.
Langkah 5: Ekspor Data ke Mana Saja
Ekspor hasil ke Google Sheets, Excel, Airtable, atau Notion. Ekspor gratis.
Bagaimana Jika Tata Letak Situs Berubah?
Ini adalah keunggulan utama ekstraktor native AI dibanding alat berbasis aturan. Scraper tradisional seperti ParseHub dan workflow Octoparse yang lebih lama bergantung pada selector XPath atau path CSS. Saat situs memperbarui struktur HTML-nya, selector tersebut rusak dan Anda harus konfigurasi ulang secara manual.
Ekstraktor berbasis AI seperti Thunderbit membaca ulang struktur halaman setiap kali. Artinya tidak perlu maintenance XPath dan tidak ada selector rapuh. AI menyesuaikan perubahan tata letak secara otomatis pada run berikutnya.
Scraping Terjadwal dan Akses API: Fitur Pengguna Mahir yang Jarang Diulas
Scrape sekali jalan cocok untuk riset. Use case produksi seperti monitoring harga, pembaruan daftar prospek, dan pelacakan stok memerlukan ekstraksi berulang serta akses programatik. Fitur ini memisahkan mainan dari alat kerja.
Dukungan Penjadwalan
| Alat | Penjadwalan Native | Catatan |
|---|---|---|
| Thunderbit | ✅ | Setup dengan bahasa natural |
| Octoparse | ✅ | Run cloud terjadwal |
| Browse AI | ✅ | Fitur inti produk |
| Firecrawl | ❌ | Pakai cron eksternal |
| Apify | ✅ | Ekspresi cron penuh |
| Gumloop | ✅ | Trigger workflow berbasis waktu |
| Bright Data | Eksternal | Biasanya diorkestrasi lewat sistem pelanggan |
| Bardeen | ✅ | Penjadwalan playbook |
| Diffbot | ❌ | API-first, orkestrasi eksternal |
| ScrapingBee | ❌ | Hanya API |
| Instant Data Scraper | ❌ | Alat browser manual |
| ParseHub | ✅ (berbayar) | Fitur premium |
Perbandingan API Developer
| Alat | Sinyal Concurrency atau Rate | Model Harga |
|---|---|---|
| Thunderbit | 2 → 50 concurrent | Berbasis kredit |
| Firecrawl | 2 → 100 concurrent | Berbasis kredit |
| Apify | Bergantung paket | Unit komputasi |
| Gumloop | Concurrency workflow terbatas paket | Berbasis kredit |
| Diffbot | 5 panggilan/menit → 25 panggilan/detik | Berbasis kredit |
| ScrapingBee | 10 → 200 concurrent | Kredit API |
| Bright Data | Browser API mengiklankan request concurrent tak terbatas | Berbasis GB |
Jika use case Anda lebih teknis dan Anda sedang menentukan seberapa banyak infrastruktur yang ingin Anda miliki sendiri, walkthrough Firecrawl ini adalah pendamping yang berguna dan berfokus pada eksekusi untuk melengkapi perbandingan produk di atas.
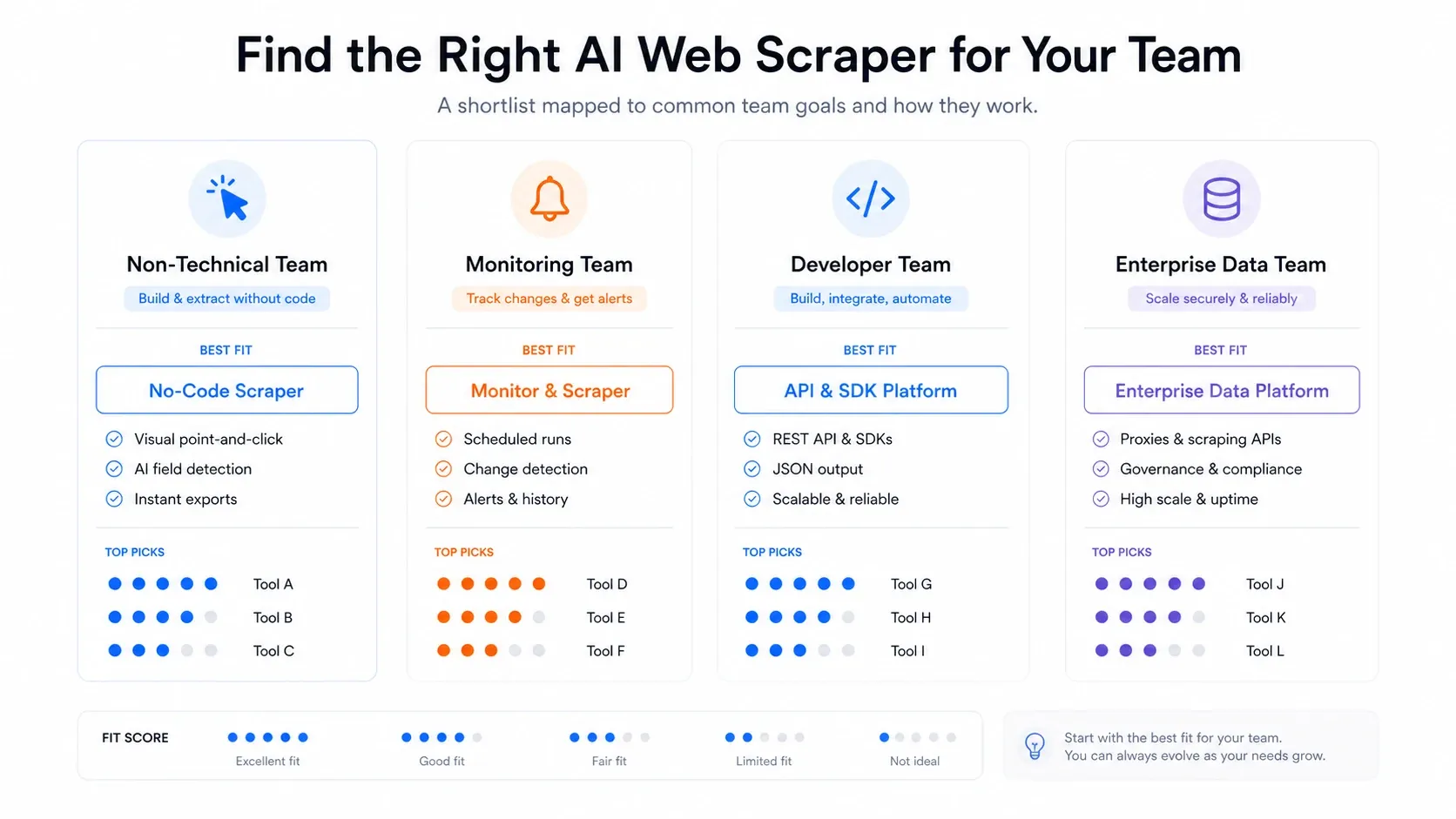
Cara Memilih AI Web Scraper yang Tepat
Setelah menguji semua 12 alat, inilah cara saya akan memutuskan:
- Tim non-teknis yang butuh data cepat: Mulai dengan Thunderbit. Workflow dua klik, ekspor gratis, dan toggle browser-cloud menutup sebagian besar kebutuhan scraping bisnis tanpa dukungan engineering.
- Butuh monitoring dan alert berkelanjutan: Browse AI dibuat khusus untuk ini. Bukan extractor sekali pakai yang paling kuat, tetapi deteksi perubahannya adalah fitur kelas utama.
- Developer yang membangun pipeline LLM: Firecrawl untuk ekstraksi Markdown atau JSON, atau Diffbot untuk ekstraksi terstruktur pra-latih. Padukan salah satunya dengan ScrapingBee atau Bright Data jika Anda butuh penanganan anti-bot serius di lapisan fetching.
- Butuh marketplace scraper bawaan: Apify punya ekosistem actor terbesar. Hanya saja, bersiaplah untuk maintenance ketika actor rusak.
- Target enterprise berskala besar dan sangat dilindungi: Bright Data. Tidak ada yang menandingi infrastruktur proxy-nya, tetapi sesuaikan anggaran dan staf teknis Anda.
- Ingin scraping sebagai bagian dari otomasi yang lebih besar: Gumloop atau Bardeen, tergantung apakah Anda mengotomasi workflow atau tugas GTM berbasis browser.
- Hanya butuh scrape gratis yang cepat: Instant Data Scraper. Setup nol, biaya nol, kompleksitas nol, tetapi juga penjadwalan nol, AI nol, dan cloud nol.
- Situs interaktif kompleks dengan dropdown dan AJAX: ParseHub masih lebih baik daripada kebanyakan ekstensi untuk kasus ini, meski beban maintenance tetap nyata.
Kesimpulan
Pasar AI web scraper pada 2026 dipenuhi alat yang terlihat mengesankan di demo dan mengecewakan di produksi. Kesenjangan antara "berfungsi di screenshot marketing" dan "berfungsi di situs e-commerce yang dilindungi pada pukul 3 pagi sesuai jadwal" adalah tempat sebagian besar pembeli membuang waktu dan uang.
Wawasan utama dari evaluasi semua 12 alat ini sederhana: lapisan fetching masih bagian yang paling sulit. AI unggul dalam ekstraksi dan post-processing, tetapi tidak menggantikan infrastruktur proxy, penanganan anti-bot, atau manajemen sesi. Alat terbaik entah menyelesaikan kedua lapisan, seperti Thunderbit dan Bright Data, atau jujur tentang lapisan mana yang mereka tangani, seperti Firecrawl untuk ekstraksi dan ScrapingBee untuk fetching.
Jika Anda ingin melihat seperti apa AI web scraper siap produksi tanpa menulis kode, . Tier gratisnya cukup untuk menguji alur kerja penuh di halaman nyata. Jika kebutuhan Anda lebih berorientasi developer, padukan API ekstraksi dengan layanan fetching khusus dan hindarkan diri Anda dari frustrasi karena mengharapkan satu alat melakukan semuanya.
FAQ
Mengapa kebanyakan AI web scraper gagal di situs nyata setelah sebelumnya bekerja baik di demo?
Demo biasanya menampilkan ekstraksi pada halaman yang bersih dan tidak dilindungi. Situs nyata menambahkan proteksi Cloudflare, rendering JavaScript dinamis, pagination, kebutuhan login, dan tata letak yang sering berubah. Kebanyakan alat menangani lapisan parsing dan ekstraksi dengan baik, tetapi tidak punya infrastruktur yang kuat untuk lapisan fetching.
Apa perbedaan cloud scraping dan browser scraping, dan kapan saya harus memakai masing-masing?
Cloud scraping memakai server jarak jauh untuk mengambil halaman, sehingga lebih cepat, paralel, dan skalabel. Browser scraping berjalan di sesi browser Anda sendiri dan lebih cocok untuk situs yang sudah terautentikasi atau yang memakai deteksi bot agresif. Thunderbit adalah salah satu dari sedikit alat yang menawarkan kedua mode dalam antarmuka yang sama.
Bisakah saya memakai AI web scraper untuk tugas berulang seperti monitoring harga?
Bisa, tetapi hanya jika alatnya mendukung scraping terjadwal. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen, dan ParseHub pada paket berbayar semuanya menawarkan penjadwalan.
AI web scraper mana yang terbaik jika saya tidak punya kemampuan coding?
Thunderbit menawarkan jalur tercepat menuju data yang bisa dipakai untuk pengguna non-teknis. Instant Data Scraper sepenuhnya gratis tetapi terbatas pada halaman sederhana. Browse AI dan Octoparse menawarkan antarmuka visual dengan setup yang lebih banyak. ParseHub kuat untuk situs interaktif yang kompleks, tetapi kurva belajarnya lebih curam.
Berapa biaya sebenarnya untuk AI web scraping kelas produksi?
Rentangnya lebar. Instant Data Scraper gratis. Thunderbit, Firecrawl, dan Browse AI menawarkan titik masuk gratis dengan paket berbayar murah. Alat kelas menengah seperti Octoparse, ParseHub, dan ScrapingBee bisa berjalan dari sekitar $49 hingga $189 per bulan. Solusi enterprise seperti Bright Data dan Diffbot dimulai jauh lebih tinggi.