

Verkko on täynnä arvokasta dataa — olitpa myynnissä, verkkokaupassa tai markkinatutkimuksessa, web scraping on salainen ase liidien hankintaan, hintaseurantaan ja kilpailija-analyysiin. Mutta tässä on koukku: mitä useampi yritys hyödyntää scrapingia, sitä kovemmin verkkosivustot torjuvat sitä. Muutos on todellinen: vuoden 2024 ppc.land-analyysi havaitsi, että yli kolmannes tuhannesta suurimmasta sivustosta estää jo pelkästään OpenAI:n crawlerin — ja laajempi työkalupakki, johon kuuluvat IP-estot, CAPTCHA:t ja selainjäljen tunnistus, on nyt pikemminkin sääntö kuin poikkeus.
Jos olet joskus katsonut Python-skriptisi pyörivän sulavasti 20 minuuttia — ja sitten törmänneen seinään täynnä 403-virheitä — tiedät, että tämä on ihan oikeasti turhauttavaa.
Olen työskennellyt vuosia SaaS:n ja automaation parissa, ja olen nähnyt omin silmin, miten scraping-projektit voivat muuttua yhdessä hetkessä tyyliin ”vau, tämä on helppoa” ja seuraavassa ”miksi minut estetään joka paikassa?”. Mennään siis käytännön tasolle: käyn läpi, miten web scraping tehdään Pythonilla ilman estetyksi joutumista, jaan parhaat tekniikat ja koodiesimerkit, ja näytän, milloin kannattaa harkita AI-pohjaisia vaihtoehtoja kuten Thunderbit. Olitpa Python-ammattilainen tai vasta raapimassa kasaan tuloksia (sanaleikki tarkoitettu), tästä saat työkalupakin luotettavaan, estottomaan datan poimintaan.
Mitä web scraping ilman estetyksi joutumista Pythonilla tarkoittaa?
Ytimeltään web scraping ilman estetyksi joutumista tarkoittaa datan poimimista verkkosivustoilta tavalla, joka ei laukaise niiden anti-bot-suojauksia. Python-maailmassa kyse on paljon muustakin kuin requests.get()-silmukan kirjoittamisesta — kyse on sulautumisesta joukkoon, oikeiden käyttäjien jäljittelystä ja pysymisestä askeleen edellä tunnistusjärjestelmiä.
Miksi Python? Python on suosituin kieli web scrapingiin — kiitos sen selkeän syntaksin, valtavan ekosysteemin (esim. requests, BeautifulSoup, Scrapy, Selenium) ja joustavuuden, joka riittää kaikkeen pikaskripteistä hajautettuihin crawlereihin. Suosio tuo kuitenkin mukanaan hintansa: monet anti-bot-järjestelmät on nykyään viritetty tunnistamaan Python-pohjaisia scraping-kuvioita.
Jos siis haluat scrapata luotettavasti, sinun täytyy mennä perusasioita pidemmälle. Se tarkoittaa sitä, että ymmärrät, miten sivustot tunnistavat botteja — ja miten voit olla niitä nokkelampi ylittämättä eettisiä tai juridisia rajoja.
Miksi estojen välttäminen on tärkeää Python-web scraping -projekteissa
Estetyksi joutuminen ei ole vain tekninen pikkuharmi — se voi kaataa kokonaisia liiketoimintaprosesseja. Jaetaan asia osiin:
| Käyttötapaus | Estetyksi joutumisen vaikutus |
|---|---|
| Liidien hankinta | Puutteelliset tai vanhentuneet prospektilistat, menetetty myynti |
| Hintaseuranta | Kilpailijoiden hintamuutokset jäävät huomaamatta, heikommat hinnoittelupäätökset |
| Sisällön yhdistäminen | Aukkoja uutis-, arvostelu- tai tutkimusdatan keruussa |
| Markkinatiedustelu | Sokeat pisteet kilpailija- tai toimialaseurannassa |
| Kiinteistölistaukset | Epätarkat tai vanhentuneet kohdetiedot, menetetyt mahdollisuudet |
Kun scraper estetään, et menetä vain dataa — käytät turhaan resursseja, altistat itsesi mahdollisille compliance-ongelmille ja saatat tehdä huonoja päätöksiä puutteellisen tiedon pohjalta. Maailmassa, jossa 79 % yrityksistä käyttää web scrapingia liidien hankintaan, luotettavuus on kaikki kaikessa.
Miten verkkosivustot tunnistavat ja estävät Python-web scrapereita
Verkkosivustot ovat kehittyneet todella taitaviksi bottien tunnistamisessa. Tässä yleisimmät anti-scraping-suojaukset, joihin törmäät (Medium, Bright Data):
- IP-osoitteiden musta lista: Liikaa pyyntöjä samasta IP:stä? Estoon.
- User-Agent- ja header-tarkistukset: Pyynnöt, joista puuttuvat otsikot tai joissa on geneeriset otsikot (kuten Pythonin oletusarvoinen
python-requests/2.25.1), erottuvat joukosta. - Rate limiting: Liian monta pyyntöä lyhyessä ajassa laukaisee hidastuksen tai eston.
- CAPTCHA:t: ”Todista, että olet ihminen” -palapelit, joita botit eivät (helposti) ratkaise.
- Käyttäytymisanalyysi: Sivustot seuraavat robottimaisia kuvioita — esimerkiksi saman napin klikkaamista täsmälleen samoilla väleillä.
- Honeypotit: Piilotetut linkit tai kentät, joihin vain botit osuvat.
- Selainjäljen tunnistus: Tietojen kerääminen selaimestasi ja laitteestasi automaatiotyökalujen tunnistamiseksi.
- Eväste- ja sessioseuranta: Botit, jotka eivät käsittele evästeitä tai sessioita oikein, merkitään epäilyttäviksi.
Ajattele tätä kuin lentokentän turvatarkastusta: jos näytät, toimit ja liikut kuten kaikki muutkin, pääset läpi vaivatta. Jos paikalle saavut trenssitakissa ja aurinkolaseissa, lisäkysymyksiä on luvassa.
Olennaiset Python-tekniikat web scrapingiin ilman estetyksi joutumista
Siirrytään itse asiaan: miten estot oikeasti kierretään, kun scrappaat Pythonilla. Tässä ovat ydintekniikat, jotka jokaisen scraperin kannattaa tuntea:

Proxyjen ja IP-osoitteiden kierrätys
Miksi se on tärkeää: Jos kaikki pyyntösi tulevat samasta IP:stä, olet helppo kohde IP-estolle. Proxyjen kierrätys jakaa pyynnöt useiden IP-osoitteiden kesken, jolloin estäminen on paljon vaikeampaa.
Näin teet sen Pythonissa:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ... lisää proxya
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# käsittele vastaus
Voit käyttää maksullisia proxy-palveluja (kuten residential- tai rotating proxyja) saadaksesi lisää luotettavuutta (ScrapingBee).
User-Agentin ja omien headerien asettaminen
Miksi se on tärkeää: Pythonin oletusarvoiset otsikot huutavat ”botti”. Jäljitä oikeita selaimia asettamalla user-agent ja muut otsikot.
Esimerkkikoodi:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Kierrätä user-agenteja lisähuomaamattomuuden vuoksi (ZenRows).
Pyyntöjen ajoituksen ja kuvioiden satunnaistaminen
Miksi se on tärkeää: Botit ovat nopeita ja ennustettavia; ihmiset ovat hitaita ja satunnaisia. Lisää viiveitä ja vaihtele navigointia.
Python-vinkki:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # odota 2–7 sekuntia
Voit myös satunnaistaa klikkauspolkuja ja vierityskuvioita, jos käytät Seleniumia.
Evästeiden ja sessioiden hallinta
Miksi se on tärkeää: Monet sivustot vaativat evästeitä tai session tunnisteita sisällön avaamiseen. Botit, jotka jättävät nämä huomiotta, estetään.
Näin hallitset niitä Pythonissa:
import requests
session = requests.Session()
response = session.get(url)
# session käsittelee evästeet automaattisesti
Monimutkaisempiin kulkuihin voit käyttää Seleniumia evästeiden tallettamiseen ja uudelleenkäyttöön.
Ihmismäisen käytöksen simulointi headless-selaimilla
Miksi se on tärkeää: Jotkin sivustot käyttävät JavaScriptiä, hiiren liikettä tai vieritystä todellisten käyttäjien signaaleina. Headless-selaimet kuten Selenium tai Playwright voivat jäljitellä näitä toimintoja.
Esimerkki Seleniumilla:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Tämä auttaa kiertämään käyttäytymisanalyysin ja dynaamisen sisällön (ScrapingBee).
Edistyneet strategiat: CAPTCHA:iden ja honeypottien kiertäminen Pythonissa
CAPTCHA:t on suunniteltu pysäyttämään botit heti alkuunsa. Vaikka jotkin Python-kirjastot pystyvät ratkaisemaan yksinkertaisia CAPTCHA-tehtäviä, useimmat vakavat scraperit tukeutuvat kolmannen osapuolen palveluihin (kuten 2Captcha tai Anti-Captcha), jotka ratkaisevat ne maksua vastaan (Medium).
Esimerkkaintegraatio:
# Pseudokoodia 2Captcha API:n käyttöön
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Odota ratkaisua ja lähetä sitten pyyntösi mukana
Honeypotit ovat piilotettuja kenttiä tai linkkejä, joihin vain botit törmäävät. Vältä klikkaamasta tai lähettämästä mitään, mikä ei näy oikeassa selaimessa (ZenRows).
Kestävien request-headerien suunnittelu Python-kirjastoilla
User-agentin lisäksi voit kierrättää ja satunnaistaa muitakin otsikoita, kuten Referer, Accept, Origin jne., jotta sulautuminen joukkoon paranee entisestään.
Scrapyn kanssa:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Lisää otsikoita
}
}
Seleniumilla: Käytä selainprofiileja tai laajennuksia headerien asettamiseen tai injektoi ne JavaScriptin kautta.
Pidä header-listasi ajan tasalla — kopioi oikeita selainpyyntöjä selaimen DevToolsilla inspiraation lähteeksi.
Kun perinteinen Python-scraping ei riitä: anti-bot-teknologian nousu
Tosiasia on tämä: mitä suositummaksi scraping tulee, sitä kovemmin myös anti-bot-suojaukset kehittyvät. Suurimmat sivustot estävät nykyään muutakin kuin ilmiselvät botit — myös kehittyneet headless-selaimet ja kierrätetyt proxyt. AI-pohjainen tunnistus, dynaamiset pyyntörajat ja selainjäljen tunnistus tekevät jopa edistyneille Python-skripteille yhä vaikeammaksi pysyä huomaamatta (Medium).
Joskus, vaikka koodisi olisi kuinka nokkelaa, törmäät silti seinään. Silloin kannattaa harkita toista lähestymistapaa.
Thunderbit: AI Web Scraper -vaihtoehto Python-scrapingille
Kun Python tulee rajalleen, Thunderbit astuu kuvaan no-code, AI-pohjaisena web scraperina, joka on rakennettu liiketoimintakäyttäjille — ei vain kehittäjille. Sen sijaan, että taistelisit proxyjen, headerien ja CAPTCHA:iden kanssa, Thunderbitin AI-agentti lukee sivuston, ehdottaa parhaat poimittavat kentät ja hoitaa kaiken alasivujen navigoinnista datan vientiin.
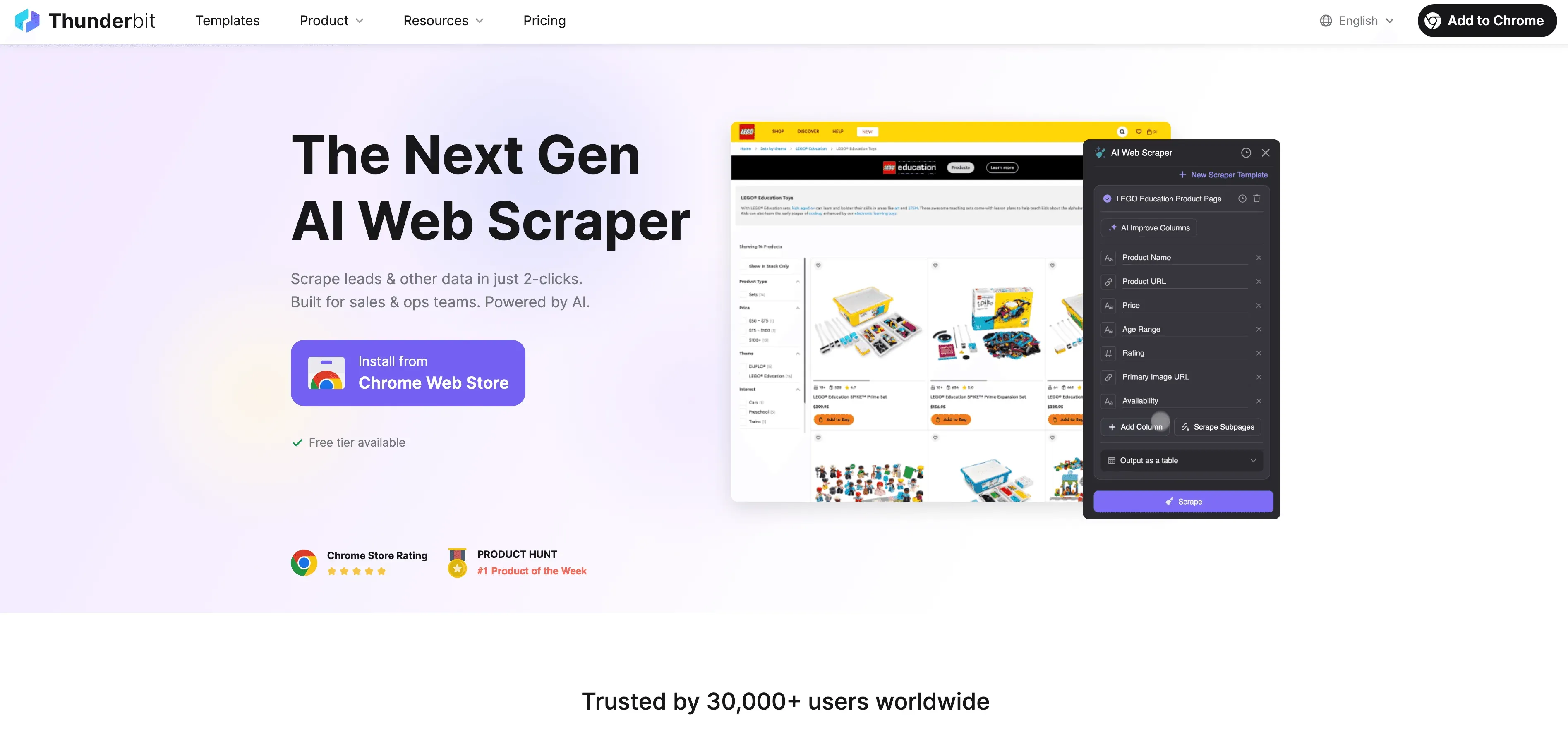
Mikä tekee Thunderbitista erilaisen?
- AI-kenttäehdotukset: Napsauta ”AI Suggest Fields”, ja Thunderbit skannaa sivun, suosittelee sarakkeita ja jopa luo poimintaohjeet.
- Alasivujen scraping: Thunderbit voi käydä jokaisella alasivulla (kuten tuotesivuilla tai LinkedIn-profiileissa) ja rikastaa taulukkosi automaattisesti.
- Cloud- tai selain-scraping: Valitse nopein vaihtoehto — pilvi julkisille sivustoille, selain kirjautumisen takana oleville sivuille.
- Ajoitettu scraping: Aseta kerran ja unohda — Thunderbit voi scrapata aikataulun mukaan, joten datasi pysyy aina tuoreena.
- Välittömät templatet: Suosituilla sivustoilla (Amazon, Zillow, Shopify jne.) Thunderbit tarjoaa yhden klikkauksen templateja — ei käyttöönottoa.
- Ilmainen datan vienti: Vie Exceliin, Google Sheetiin, Airtableen tai Notioniin — ilman lisämaksuja.
Thunderbitiin luottaa yli 100 000 käyttäjää maailmanlaajuisesti, eikä sinun tarvitse kirjoittaa riviäkään koodia.
Poimi dataa miltä tahansa sivustolta AI:n avulla Get Started Free
Miten Thunderbit auttaa käyttäjiä välttämään estoja ja automatisoimaan datan poimintaa
Thunderbitin AI ei vain matki ihmisen käyttäytymistä — se mukautuu jokaiseen sivustoon reaaliajassa, mikä vähentää estetyksi joutumisen riskiä. Näin:
- AI mukautuu ulkoasumuutoksiin: Vähemmän uudelleentyötä, kun sivusto päivittää designiaan — sinun ei tarvitse palata säätämään selektoreita joka viikko.
- Alasivujen ja sivutuksen käsittely: Thunderbit seuraa linkkejä ja sivutettuja listoja puolestasi, aivan kuin ihminen klikkailisi ne läpi.
- Pilvipoiminta erissä: Aja tehtävät Thunderbitin pilvestä eikä läppäriltäsi, eräkoot suunnitelman mukaan (katso hinnoittelusivu nykyisille rajoille).
- Vähemmän ylläpidettävää koodia: Sinun ei tarvitse jahdata rikkoutuneita selektoreita keskellä yötä, kun sivusto muuttuu; AI lukee sivun uudelleen.
Syvempään katsaukseen, katso Kuinka scrapeata mikä tahansa sivusto AI:n avulla.
Python-scraping vs. Thunderbit: kumpi kannattaa valita?
Laitetaan ne rinnakkain:
| Ominaisuus | Python-scraping | Thunderbit |
|---|---|---|
| Käyttöönottoaika | Keskitaso–korkea (skriptit, proxyt jne.) | Matala (2 klikkausta, AI hoitaa loput) |
| Tekninen osaaminen | Koodausta tarvitaan | Ei koodausta |
| Luotettavuus | Vaihtelee (helppo rikkoa) | Korkea (AI mukautuu muutoksiin) |
| Estojen riski | Keskitaso–korkea | Matala (AI jäljittelee käyttäjää, mukautuu) |
| Skaalautuvuus | Vaatii räätälöityä koodia/pilviasennusta | Sisäänrakennettu pilvi- ja eräscraping |
| Ylläpito | Usein (sivumuutokset, estot) | Vähäinen (AI säätää automaattisesti) |
| Vientivaihtoehdot | Manuaalinen (CSV, tietokanta) | Suoraan Sheetiin, Notioniin, Airtableen, CSV:hen |
| Kustannus | Ilmainen (mutta aikaa vievä) | Ilmainen taso, maksulliset paketit skaalaan |
Milloin käyttää Pythonia:
- Tarvitset täyden hallinnan, räätälöityä logiikkaa tai integraation muihin Python-työnkulkuihin.
- Scrappaat sivustoja, joissa on vain vähän anti-bot-suojauksia.
Milloin käyttää Thunderbitia:
- Haluat nopeutta, luotettavuutta ja nollakäyttöönoton.
- Scrappaat monimutkaisia tai usein muuttuvia sivustoja.
- Et halua säätää proxyjen, CAPTCHA:iden tai koodin kanssa.
Kokeile Thunderbit AI Web Scraperia ilmaiseksi
Vaiheittainen opas: web scraping ilman estetyksi joutumista Pythonissa
Käydään läpi käytännön esimerkki: tuotetiedon scraping mallisivustolta anti-blocking-parhaita käytäntöjä soveltaen.
1. Asenna tarvittavat kirjastot
pip install requests beautifulsoup4 fake-useragent
2. Valmistele skripti
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Korvaa omilla URL-osoitteillasi
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Poimi data tästä
print(soup.title.text)
else:
print(f"Estetty tai virhe osoitteessa {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Satunnainen viive
3. Lisää proxyjen kierrätys (valinnainen)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Lisää proxya
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...koodi jatkuu
4. Käsittele evästeet ja sessiot
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...koodi jatkuu
5. Vianetsintävinkit
- Jos näet paljon 403/429-virheitä, hidasta pyyntöjäsi tai kokeile uusia proxya.
- Jos törmäät CAPTCHA:ihin, harkitse Seleniumia tai CAPTCHA-ratkaisupalvelua.
- Tarkista aina sivuston
robots.txtja käyttöehdot.
Yhteenveto ja tärkeimmät opit
Web scraping Pythonilla on tehokasta — mutta estetyksi joutuminen on jatkuva riski, kun anti-bot-teknologia kehittyy. Paras tapa välttää estot? Yhdistä tekniset parhaat käytännöt (proxyjen kierrätys, fiksut headerit, satunnaiset viiveet, sessioiden hallinta ja headless-selaimet) ja terve kunnioitus sivustojen sääntöjä ja etiikkaa kohtaan.
Mutta joskus edes parhaat Python-kikat eivät riitä. Silloin kuvaan astuvat AI-työkalut kuten Thunderbit — no-code, suunniteltu käsittelemään ulkoasumuutoksia ja sivutusta, jotka kaatavat jäykät skriptit, ja tarkoitettu liiketoimintakäyttäjille, jotka eivät halua viettää iltojaan Selenium-ajon vahtina.
Haluatko nähdä, miten helppoa scraping voi olla? Lataa Thunderbitin Chrome-laajennus ja kokeile itse — tai tutustu blogiimme saadaksesi lisää scraping-vinkkejä ja oppaita.
Poimi dataa joutumatta estetyksi
Usein kysytyt kysymykset
1. Miksi verkkosivustot estävät Python-web scrapereita?
Verkkosivustot estävät scrapereita suojatakseen dataansa, estääkseen palvelimen ylikuormitusta ja pysäyttääkseen automatisoidut botit palveluidensa väärinkäytöltä. Python-skriptit on helppo huomata, jos ne käyttävät oletusotsikoita, eivät käsittele evästeitä tai lähettävät liian monta pyyntöä liian nopeasti.
2. Mitkä ovat tehokkaimmat tavat välttää estot Pythonilla scrapatessa?
Käytä kierrätettyjä proxya, aseta realistinen user-agent ja otsikot, satunnaista pyyntöjen ajoitus, hallitse evästeitä/sessioita ja simuloi ihmismäistä käytöstä työkaluilla kuten Selenium tai Playwright.
3. Miten Thunderbit auttaa välttämään estoja verrattuna Python-skripteihin?
Thunderbit käyttää AI:ta mukautuakseen sivustojen ulkoasuihin, jäljitelläkseen ihmisen selaamista ja käsitelläkseen alasivuja ja sivutusta automaattisesti. Se vähentää estojen riskiä sulautumalla joukkoon ja päivittämällä toimintatapansa reaaliajassa — ilman koodausta tai proxya.
4. Milloin minun pitäisi käyttää Python-scrapingia ja milloin AI-työkalua kuten Thunderbitia?
Käytä Pythonia, kun tarvitset räätälöityä logiikkaa, integraation muuhun Python-koodiin tai scrappaat yksinkertaisia sivustoja. Käytä Thunderbitia nopeaan, luotettavaan ja skaalautuvaan scrapingiin — erityisesti silloin, kun sivustot ovat monimutkaisia, muuttuvat usein tai estävät skriptejä aggressiivisesti.
5. Onko web scraping laillista?
Web scraping on laillista julkisesti saatavilla olevan datan osalta, mutta sinun on kunnioitettava kunkin sivuston käyttöehtoja, tietosuojakäytäntöjä ja sovellettavia lakeja. Älä koskaan scrapea arkaluonteista tai yksityistä dataa, ja tee scraping aina eettisesti ja vastuullisesti.
Valmis scrappaamaan fiksummin, ei kovemmin? Kokeile Thunderbitia ja jätä estot taaksesi.
Lue lisää:
- Google Newsin scrapaaminen Pythonilla: vaihe vaiheelta -opas
- Rakenna hintaseuranta Best Buy -työkalulla Pythonia käyttäen
- 14 tapaa tehdä web scraping joutumatta estetyksi
- 10 parasta vinkkiä siihen, miten välttää esto web scrapingaessa
Kokeile AI Web Scraperia Get Started Free




