

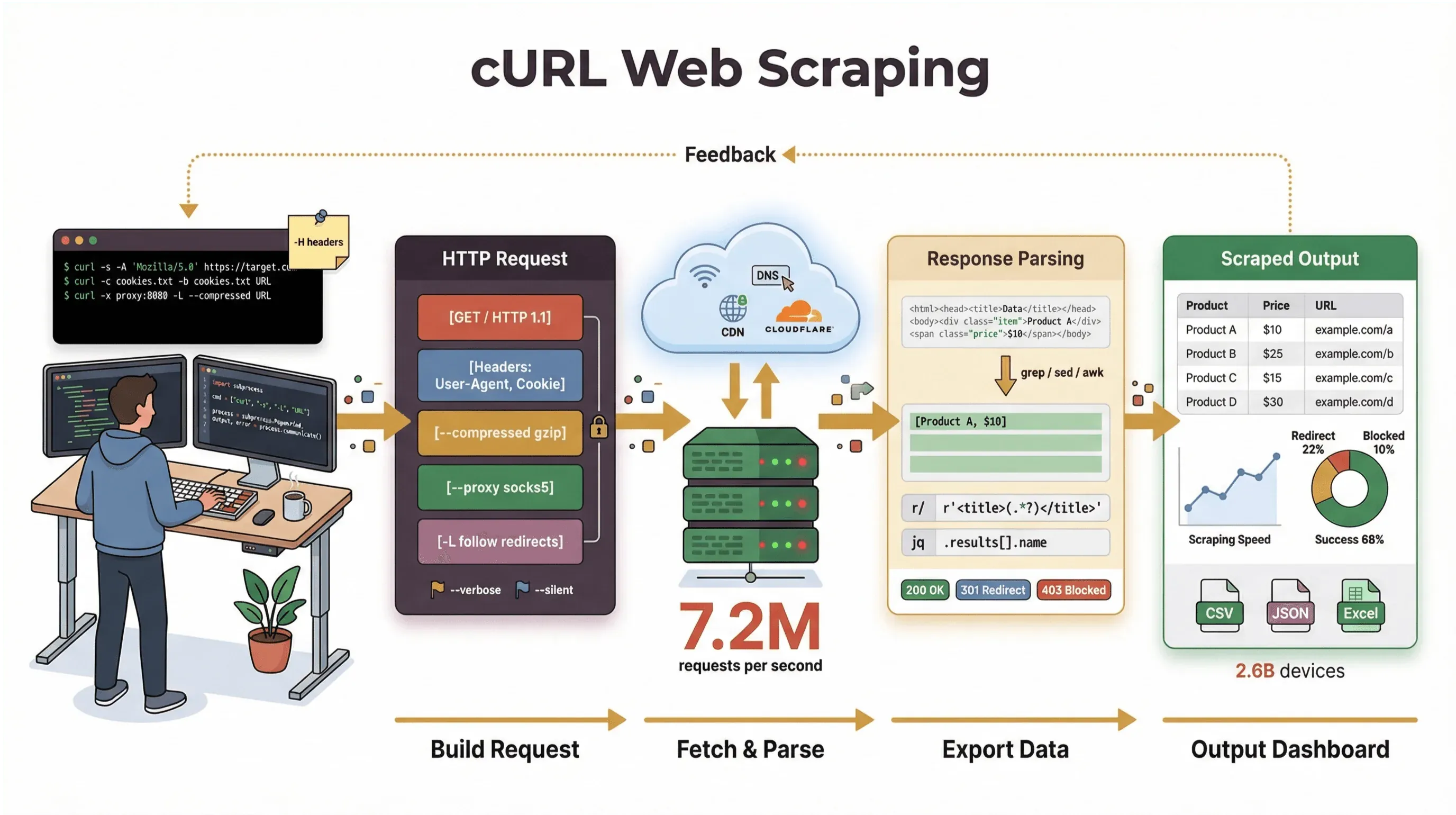
On jotain ajatonta siinä, että avaa päätteen, kirjoittaa yhden komennon ja katsoo, kun raakadata alkaa virrata sisään kuin olisi juuri avannut Matrixin. Kehittäjille ja teknisille tehokäyttäjille cURL on juuri tuo taikasauva: vaatimaton komentorivityökalu, joka pyörii hiljaisesti miljardeissa laitteissa pilvipalvelimista älyjääkaappeihin. Ja vaikka vuosi on 2026 ja tarjolla on paljon näyttäviä no-code- ja AI-kaavintatyökaluja, web-scraping-with-curl on yhä luottovalinta kaikille, jotka arvostavat nopeutta, hallintaa ja skriptattavuutta.
 Olen viettänyt vuosia automaatiotyökaluja rakentaen ja tiimejä web-datan käsittelyssä auttaen, ja tartun yhä cURLiin, kun minun pitää hakea sivu, debugata API tai prototypoida kaavintaprosessi. Tässä oppaassa käyn läpi curl-verkkokaavinnan, joka kattaa sekä perusteet että ammattilaisniksit — mukana oikeita komentoesimerkkejä, käytännön vinkkejä ja rehellinen katsaus siihen, missä cURL loistaa (ja missä se törmää seinään). Ja jos olet enemmän liiketoimintakäyttäjä etkä halua koskea komentoriviin, näytän, miten Thunderbit, meidän AI-pohjainen web scraperimme, vie sinut vaiheesta ”tarvitsen nämä tiedot” vaiheeseen ”tässä on taulukkoni” kahdella klikkauksella — ilman koodia.
Olen viettänyt vuosia automaatiotyökaluja rakentaen ja tiimejä web-datan käsittelyssä auttaen, ja tartun yhä cURLiin, kun minun pitää hakea sivu, debugata API tai prototypoida kaavintaprosessi. Tässä oppaassa käyn läpi curl-verkkokaavinnan, joka kattaa sekä perusteet että ammattilaisniksit — mukana oikeita komentoesimerkkejä, käytännön vinkkejä ja rehellinen katsaus siihen, missä cURL loistaa (ja missä se törmää seinään). Ja jos olet enemmän liiketoimintakäyttäjä etkä halua koskea komentoriviin, näytän, miten Thunderbit, meidän AI-pohjainen web scraperimme, vie sinut vaiheesta ”tarvitsen nämä tiedot” vaiheeseen ”tässä on taulukkoni” kahdella klikkauksella — ilman koodia.
Sukelletaan siis sisään ja katsotaan, miksi cURL on yhä relevantti verkkokaavinnassa vuonna 2026, miten sitä käytetään tehokkaasti ja milloin kannattaa tarttua vieläkin tehokkaampaan työkaluun.
Mikä on cURL? web-scraping-with-curlin perusta
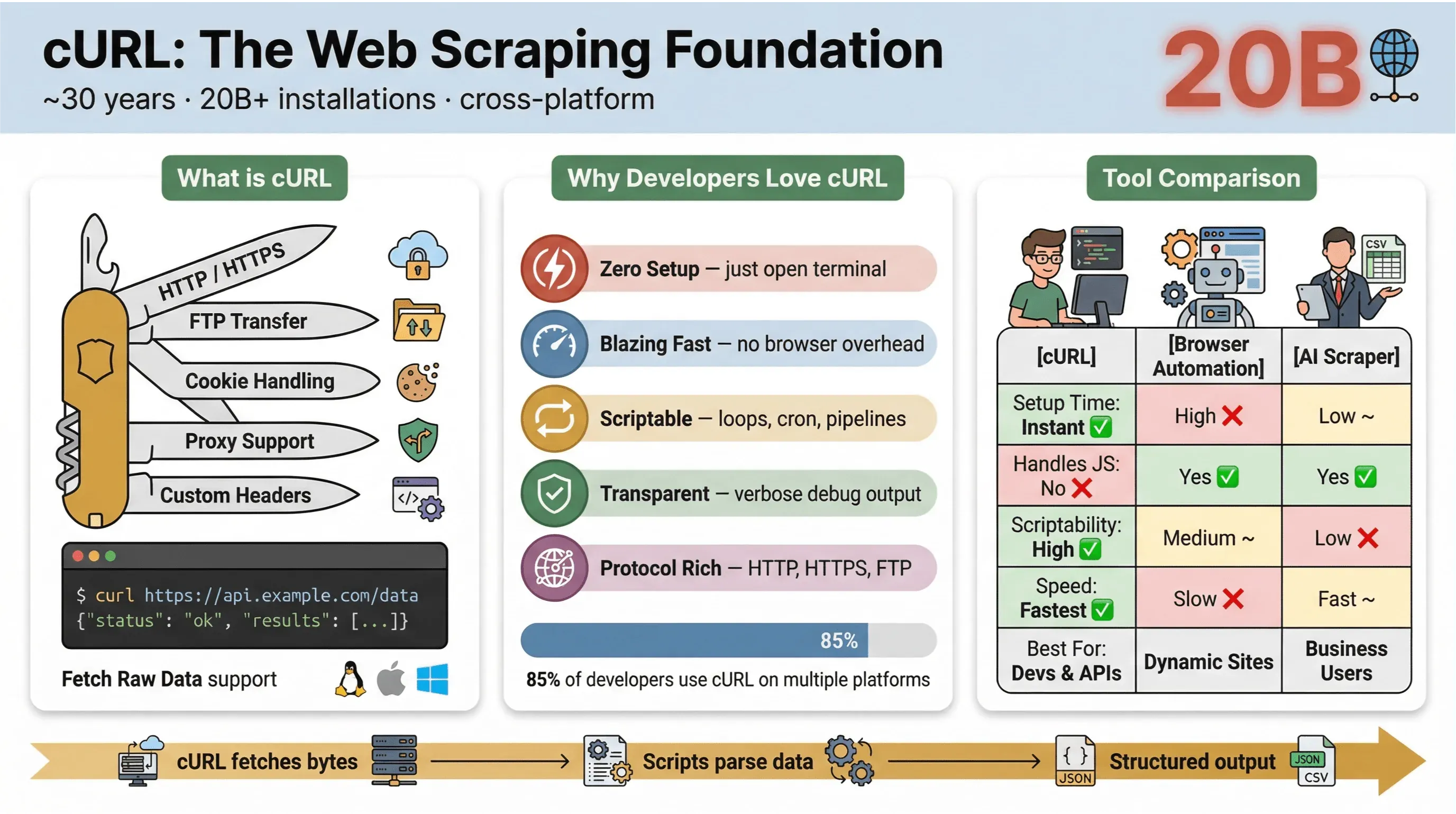
Ytimeltään cURL on komentorivityökalu ja kirjasto tiedonsiirtoon URL-osoitteiden avulla. Se on ollut olemassa lähes 30 vuotta (kyllä, ihan oikeasti), ja sitä on joka puolella — upotettuna käyttöjärjestelmiin, skriptien moottorina ja hoitamassa tiedonsiirtoja hiljaa yli kahdessakymmenessä miljardissa asennuksessa. Jos olet joskus ajanut nopean komennon verkkosivun hakemiseen, API:n testaamiseen tai tiedoston lataamiseen, on hyvin mahdollista, että olet käyttänyt cURLia.
 Tässä syyt, miksi cURL on niin suosittu verkkokaavinnassa:
Tässä syyt, miksi cURL on niin suosittu verkkokaavinnassa:
- Kevyt ja monialustainen: Toimii Linuxissa, macOS:ssä, Windowsissa ja jopa sulautetuissa laitteissa.
- Protokollatuki: Käsittelee HTTP:tä, HTTPS:ää, FTP:tä ja paljon muuta.
- Skriptattava: Täydellinen automaatioon, cron-tehtäviin ja liimakoodiin.
- Ei vaadi käyttäjän vuorovaikutusta: Suunniteltu ei-interaktiiviseen käyttöön — erinomainen eräajoihin ja putkiin.
Mutta ollaanpa tarkkoina: cURLin päätehtävä on hakea raakadataa — HTML:ää, JSONia, kuvia, mitä vain. Se ei pura, renderöi tai jäsennä dataa puolestasi. Ajattele cURLia verkkokaavinnan ”ensimmäisenä mailina”: se tuo sinulle tavut, mutta tarvitset muita työkaluja (kuten Python-skriptejä, grep/sed/awk-työkaluja tai AI web scraperin) muuntaaksesi ne rakenteiseksi tiedoksi.
Jos haluat katsoa viralliset ohjeet, tutustu cURLin HTTP-skriptiohjeeseen.
Miksi käyttää cURLia verkkokaavintaan? (curl web scraping tutorial)
Miksi kehittäjät ja tekniset käyttäjät palaavat yhä uudelleen cURLin pariin verkkokaavinnassa, vaikka uusia työkaluja tulee koko ajan? Tässä, mikä erottaa cURLin muista:
- Minimaalinen käyttöönotto: Ei asennuksia, ei riippuvuuksia — avaa vain pääte ja aloita.
- Nopeus: Hae data heti ilman, että odotat selaimen latautumista.
- Skriptattavuus: Silmukoi URL-osoitteita, automatisoi pyyntöjä ja ketjuta komentoja helposti.
- Protokolla- ja ominaisuustuki: Käsittele evästeitä, välityspalvelimia, uudelleenohjauksia, mukautettuja otsikoita ja paljon muuta.
- Läpinäkyvyys: Näet täsmälleen, mitä tapahtuu yksityiskohtaisen/debug-ulosannon avulla.
Vuoden 2025 cURL-käyttäjäkyselyssä 85,7 % vastaajista kertoi käyttävänsä cURLin komentorivityökalua, ja 96,2 % ilmoitti käyttävänsä sitä Linuxissa — edelleen selvästi cURLin tärkein alusta.
--- Se on yhä HTTP-pyyntöjen, nopeiden datapoimintojen ja ongelmanratkaisun sveitsiläinen linkkuveitsi.
Tässä nopea vertailu cURLin ja muiden kaavintatapojen välillä:
| Ominaisuus | cURL | Selainautomaatio (esim. Selenium) | AI Web Scraper (esim. Thunderbit) |
|---|---|---|---|
| Käyttöönottoaika | Välitön | Korkea | Matala |
| Skriptattavuus | Korkea | Keskitaso | Matala (ei koodia) |
| Käsittelee JavaScriptin | Ei | Kyllä | Kyllä (Thunderbit: selaimen kautta) |
| Eväste-/istuntotuki | Manuaalinen | Automaattinen | Automaattinen |
| Datan jäsentäminen | Manuaalinen (jäsennä myöhemmin) | Manuaalinen (jäsennä myöhemmin) | AI-/mallipohjainen |
| Paras käyttö | Kehittäjät, nopeat poiminnat | Monimutkaiset, dynaamiset sivustot | Liiketoimintakäyttäjät, rakenteinen vienti |
Lyhyesti: cURL on lyömätön, kun haluat nopeasti skriptattavia datapoimintoja — erityisesti staattisille sivuille, API-rajapinnoille tai silloin, kun haluat automatisoida yksinkertaisia työnkulkuja. Mutta heti kun sinun täytyy jäsentää monimutkaista HTML:ää, käsitellä JavaScriptiä tai viedä rakenteista dataa, tarvitset jotain erikoistuneempaa.
Aloitetaan: cURL-verkkokaavinnan peruskomentoesimerkkejä
Lähdetään käytännön puolelle. Näin käytät cURLia perusverkkokaavintatehtäviin vaihe vaiheelta.
Raaka-HTML:n hakeminen cURLilla
Yksinkertaisin käyttötapa: hae verkkosivun HTML.
curl https://books.toscrape.com/
Tämä komento hakee Books to Scrape -sivuston etusivun, joka on julkinen harjoitussivusto verkkokaavintaan. Näet päätteen ikkunassa raakaa HTML-ulostuloa — etsi tageja kuten <title> tai tekstipaloja kuten “In stock.”
Tulosteen tallentaminen tiedostoon
Haluatko tallettaa HTML:n myöhempää jäsentämistä varten? Käytä -o-lippua:
curl -o page.html https://books.toscrape.com/
Nyt sinulla on page.html-tiedosto, jossa on koko HTML-sisältö. Tämä sopii erinomaisesti jatkoanalyysiin tai jäsennykseen muilla työkaluilla.
POST-pyyntöjen lähettäminen cURLilla
Pitääkö lähettää lomake tai asioida API:n kanssa? Käytä -d-lippua POST-pyyntöihin. Tässä esimerkki httpbin -sivustolla, joka on tehty HTTP-testausta varten:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Saat JSON-vastauksen, joka peilaa lähettämäsi datan — erinomainen testaukseen ja prototyyppaukseen.
Otsikoiden tarkastelu ja debuggaus
Joskus haluat nähdä vastauksen otsikot tai debugata pyyntöä:
-
Pelkkä otsikkotieto (HEAD-pyyntö):
curl -I https://books.toscrape.com/ -
Otsikot yhdessä rungon kanssa:
curl -i https://httpbin.org/get -
Yksityiskohtainen/debug-ulosanti:
curl -v https://books.toscrape.com/
Nämä liput auttavat ymmärtämään, mitä kulissien takana tapahtuu — olennaista vianetsinnässä.
Tässä nopea viitettaulukko näille komennoille:
| Tehtävä | Komentoesimerkki | Huomautukset |
|---|---|---|
| Hae HTML | curl URL | Tulostaa HTML:n päätteeseen |
| Tallenna tiedostoon | curl -o file.html URL | Kirjoittaa tulosteen tiedostoon |
| Tarkastele otsikoita | curl -I URL tai curl -i URL | -I vain HEADille, -i sisältää otsikot yhdessä rungon kanssa |
| Lähetä lomakedata | curl -d "a=1&b=2" URL | Lähettää lomakekoodattua dataa |
| Debuggaa pyyntö/vastaus | curl -v URL | Näyttää yksityiskohtaiset pyyntö-/vastaustiedot |
Lisää esimerkkejä löydät cURLin virallisista skriptiohjeista.
Seuraava taso: edistynyt verkkokaavinta cURLilla (web-scraping-with-curl)
Kun perusasiat ovat hallussa, cURL avaa oven edistyneisiin ominaisuuksiin monimutkaisempia kaavintatehtäviä varten.
Evästeiden ja istuntojen käsittely
Monet sivustot tarvitsevat evästeitä kirjautumisistuntojen ylläpitoon tai käyttäjien seuraamiseen. cURLilla voit tallentaa ja käyttää evästeitä uudelleen eri pyyntöjen välillä:
# Tallenna evästeet kirjautumisen jälkeen
curl -c cookies.txt https://example.com/login
# Käytä evästeitä myöhemmissä pyynnöissä
curl -b cookies.txt https://example.com/account
Näin voit jäljitellä selainistuntoja ja päästä kirjautumisen takana oleville sivuille (kunhan mukana ei ole JavaScript-haastetta).
User-Agentin ja mukautettujen otsikoiden väärentäminen
Jotkin sivustot näyttävät erilaista sisältöä User-Agentin tai otsikoiden perusteella. Oletuksena cURL ilmoittaa itsensä muodossa “curl/VERSION”, mikä voi laukaista eston tai vaihtoehtoisen sisällön. Jos haluat jäljitellä selainta:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Voit myös asettaa mukautettuja otsikoita, kuten kieliasetuksia:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Tämä auttaa saamaan saman sisällön, jonka oikea selain näkisi.
Välityspalvelinten käyttäminen verkkokaavinnassa
Tarvitsetko pyyntöjen ohjaamista välityspalvelimen kautta (esimerkiksi maantieteelliseen testaukseen tai IP-estojen kiertämiseen)? Käytä -x-lippua:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Varmista vain, että käytät välityspalvelimia vastuullisesti ja sivuston käyttöehtojen mukaisesti.
Monisivuisen kaavinnan automatisointi
Haluatko kaapia useita sivuja — esimerkiksi sivutettuja tuotelistoja? Käytä yksinkertaista shell-silmukkaa:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Tämä hakee Books to Scrape -luettelon sivut 2–5 ja tallentaa jokaisen omaan tiedostoonsa. (Sivu 1 on etusivu.)
web-scraping-with-curlin rajoitukset: mitä sinun pitää tietää
Vaikka pidän cURLista paljon, se ei ole hopealuoti. Tässä, missä se jää vajaaksi:
- Ei JavaScriptin suoritusta: cURL ei osaa käsitellä sivuja, jotka vaativat JavaScriptiä sisällön renderöintiin tai anti-bot-haasteiden ratkaisemiseen (developers.cloudflare.com).
- Manuaalinen jäsentäminen tarvitaan: Saat raakaa HTML:ää tai JSONia, mutta sinun on jäsennettävä se itse — usein lisäskriptien tai työkalujen avulla.
- Rajoitettu istunnonhallinta: Monimutkaiset kirjautumiset, tokenit tai monivaiheiset lomakkeet voivat muuttua nopeasti sotkuisiksi.
- Ei sisäänrakennettua rakenteistamista: cURL ei muuta verkkosivuja riveiksi, taulukoiksi tai taulukoiksi.
- Altis bot-tunnistukselle: Monet sivustot käyttävät nykyään kehittyneitä bottisuojaa (JavaScript, fingerprinting, CAPTCHA:t), joita cURL ei yksinkertaisesti pysty ohittamaan (datadome.co).
Tässä nopea vertailutaulukko:
| Rajoitus | cURL yksin | Nykyaikaiset kaavintatyökalut (esim. Thunderbit) |
|---|---|---|
| JavaScript-tuki | Ei | Kyllä |
| Datan jäsentäminen | Manuaalinen | Automaattinen (AI/malli) |
| Istunnonhallinta | Manuaalinen | Automaattinen |
| Anti-bot-kiertäminen | Rajoitettu | Kehittynyt (selainpohjainen/AI) |
| Käytön helppous | Tekninen | Ei-tekninen |
Staattisille sivuille ja API-rajapinnoille cURL on loistava. Kun kyse on dynaamisemmasta tai suojatusta sisällöstä, kannattaa siirtyä työkalupinossa ylöspäin.
Thunderbit vs. cURL: paras verkkokaavintatapa ei-teknisille käyttäjille
Puhutaanpa nyt Thunderbit:stä, meidän AI-pohjaisesta web scraper Chrome -laajennuksesta. Jos olet myyntiedustaja, markkinoija tai operatiivinen ammattilainen ja haluat vain saada tiedot verkkosivulta Exceliin, Google Sheetsiin tai Notioniin — koskematta komentoriviin — Thunderbit on tehty sinua varten.
Näin Thunderbit vertautuu cURLiin:
| Ominaisuus | cURL | Thunderbit |
|---|---|---|
| Käyttöliittymä | Komentorivi | Osoita ja klikkaa (Chrome-laajennus) |
| AI-kenttäsuositus | Ei | Kyllä (AI lukee sivun ja ehdottaa sarakkeita) |
| Sivutuksen/alasivujen käsittely | Manuaalinen skriptaus | Automaattinen (AI havaitsee ja kaapii) |
| Datan vienti | Manuaalinen (jäsennä + tallenna) | Suoraan Exceliin, Google Sheetsiin, Notioniin, Airtableen |
| JavaScript-/suojatut sivut | Ei | Kyllä (selainpohjainen kaavinta) |
| Ei koodia vaadita | Ei (vaatii skriptausta) | Kyllä (kuka tahansa voi käyttää) |
| Ilmainen taso | Aina ilmainen | Ilmainen enintään 6 sivulle (10 kokeiluboostilla) |
Thunderbitilla avaat vain laajennuksen, klikkaat “AI Suggest Fields” ja annat AI:n selvittää, mitä dataa pitää poimia. Voit kaapia taulukoita, listoja, tuotetietoja ja jopa vierailla alasivuilla automaattisesti. Sen jälkeen viet datan suoraan suosikkityökaluihisi — ei jäsentämistä, ei päänvaivaa.
Thunderbitiin luottaa yli 100 000 käyttäjää ympäri maailmaa, ja se on erityisen suosittu myynnin, verkkokaupan ja kiinteistöalan tiimeissä, jotka tarvitsevat rakenteista dataa nopeasti.
Kokeile Thunderbit Chrome -laajennusta verkkokaavintaan
Haluatko kokeilla? Lataa Chrome-laajennus tästä.
cURLin ja Thunderbitin yhdistäminen: joustavia verkkokaavintastrategioita
Jos olet tekninen käyttäjä, sinun ei tarvitse valita vain yhtä työkalua. Itse asiassa monet tiimit käyttävät cURLia ja Thunderbitia yhdessä maksimaalisen joustavuuden vuoksi:
- Prototypoi cURLilla: Käytä cURLia testataksesi päätepisteitä nopeasti, tarkastellaksesi otsikoita ja ymmärtääksesi, miten sivusto vastaa.
- Skaalaa Thunderbitilla: Kun tarvitset rakenteista dataa, monisivuista kaavintaa tai toistettavan työnkulun, vaihda Thunderbitiin osoita-ja-klikkaa-poimintaa ja suoraa vientiä varten.
Tässä esimerkkityönkulku markkinatutkimukseen:
- Käytä cURLia muutaman sivun hakemiseen ja HTML-rakenteen tarkasteluun.
- Tunnista haluamasi tietokentät (esim. tuotenimet, hinnat, arvostelut).
- Avaa Thunderbit, klikkaa “AI Suggest Fields” ja anna AI:n määrittää kaavin.
- Kaavi kaikki sivut (mukaan lukien alasivut tai sivutetut listat) ja vie Google Sheetiin.
- Analysoi, jaa ja hyödynnä dataa — ilman manuaalista jäsentämistä.
Tässä nopea päätöstaulukko:
| Tilanne | Käytä cURLia | Käytä Thunderbitia | Käytä molempia |
|---|---|---|---|
| Nopea API:n tai staattisen sivun haku | ✅ | ||
| Tarvitset rakenteista dataa taulukossa | ✅ | ||
| Otsikoiden/evästeiden debuggaus | ✅ | ||
| Dynaamisten/JavaScript-painotteisten sivujen kaavinta | ✅ | ||
| Toistettavan, no-code-työnkulun rakentaminen | ✅ | ||
| Prototypointi ja myöhempi skaalaus | ✅ | ✅ | Hybridityönkulku |
Yleiset haasteet ja sudenkuopat cURLilla tehtävässä verkkokaavinnassa
Ennen kuin lähdet villiintymään cURLin kanssa, puhutaan todellisista haasteista, joihin törmäät:
- Anti-bot-järjestelmät: Monet sivustot käyttävät nykyään kehittyneitä suojausmenetelmiä (JavaScript-haasteet, CAPTCHA:t, fingerprinting), joita cURL ei pysty ohittamaan (developers.cloudflare.com).
- Datan laatuongelmat: HTML:n muutokset, puuttuvat kentät tai epäyhtenäiset asettelut voivat rikkoa skriptisi.
- Ylläpitokuorma: Aina kun sivusto muuttuu, joudut päivittämään jäsennyslogiikkasi.
- Lainsäädäntö ja vaatimustenmukaisuus: Tarkista aina sivuston käyttöehdot, robots.txt ja soveltuvat lait ennen kaavintaa. Se, että data on julkista, ei tarkoita, että sitä saa käyttää vapaasti (calawyers.org, polsinelli.com).
- Skaalausrajat: cURL on loistava pieniin töihin, mutta suurissa kaavintamäärissä sinun täytyy hallita välityspalvelimia, nopeusrajoja ja virheenkäsittelyä.
Vianetsintä- ja yhteensopivuusvinkkejä:
- Aloita aina luvallisista tai demokäyttöön tarkoitetuista sivustoista (kuten Books to Scrape).
- Noudata nopeusrajoja — älä pommita päätepisteitä.
- Vältä henkilötietojen kaavintaa, ellet ole lainmukaisessa asemassa.
- Jos törmäät JavaScript- tai CAPTCHA-seiniin, harkitse selaimessa toimivaa työkalua kuten Thunderbitia.
Vaiheittainen yhteenveto: kuinka kaapia verkkosivustoja cURLilla
Tässä nopea tarkistuslista web-scraping-with-curliin:
- Tunnista kohde-URL(osoitteet): Aloita staattisesta sivusta tai API-päätepisteestä.
- Hae sivu:
curl URL - Tallenna tuloste tiedostoon:
curl -o file.html URL - Tarkastele otsikoita/debuggaa:
curl -I URL,curl -v URL - Lähetä POST-dataa:
curl -d "a=1&b=2" URL - Käsittele evästeitä/istuntoja:
curl -c cookies.txt ...,curl -b cookies.txt ... - Aseta mukautetut otsikot/User-Agent:
curl -A "..." -H "..." URL - Seuraa uudelleenohjauksia:
curl -L URL - Käytä välityspalvelimia (tarvittaessa):
curl -x proxy:port URL - Automatisoi monisivuinen kaavinta: Käytä shell-silmukoita tai skriptejä.
- Jäsennä ja rakenna data: Käytä tarvittaessa lisätyökaluja/skriptejä.
- Siirry Thunderbitiin, kun tarvitset rakenteista, no-code-kaavintaa tai dynaamisia sivuja.
Yhteenveto ja tärkeimmät opit: oikean verkkokaavintatyökalun valinta
Kaavi dataa miltä tahansa verkkosivustolta AI:n avulla Get Started Free
web-scraping-with-curl on yhä tehokas taito teknisille käyttäjille vuonna 2026 — erityisesti nopeisiin datapoimintoihin, prototypointiin ja automaatioon. cURLin nopeus, skriptattavuus ja kaikkialla läsnä oleva tuki tekevät siitä kehittäjän työkalupakin kulmakiven. Mutta kun verkko muuttuu dynaamisemmaksi ja suojatummaksi, ja kun liiketoimintakäyttäjät haluavat rakenteista dataa ilman koodausta, työkalut kuten Thunderbit määrittävät uudelleen sen, mikä on mahdollista.
Tärkeimmät opit:
- Käytä cURLia staattisille sivuille, API-rajapinnoille ja nopeaan prototypointiin — erityisesti silloin, kun haluat täyden hallinnan.
- Siirry Thunderbitiin (tai vastaaviin AI web scrapereihin), kun tarvitset rakenteista dataa, käsittelet dynaamisia/JavaScript-painotteisia sivuja tai haluat no-code- ja liiketoimintaystävällisen työnkulun.
- Yhdistä molemmat maksimaalisen joustavuuden vuoksi: prototypoi cURLilla, skaalaa ja rakenna Thunderbitilla.
- Kaavi aina vastuullisesti — kunnioita sivuston ehtoja, nopeusrajoja ja lain asettamia rajoja.
Haluatko nähdä, kuinka helppoa verkkokaavinta voi olla? Kokeile Thunderbitin ilmaista Chrome-laajennusta ja koe AI-pohjainen tiedonpoiminta itse. Ja jos haluat syventyä lisää, tutustu Thunderbit Blogiin saadaksesi lisää oppaita, vinkkejä ja alan näkemyksiä. Saatat pitää myös näistä:
- Kuinka kaapia mikä tahansa verkkosivusto AI:n avulla
- Kuinka kaapia verkkosivun data Exceliin AI:n avulla
- Mitä on datan kaavinta ja miten se tehdään vuonna 2025
Hyviä kaavintoja — ja olkoon datasi aina puhdasta, rakenteista ja vain komennon tai klikkauksen päässä.
Tutustu Thunderbitin suunnitelmiin skaalautuvaa verkkokaavintaa varten
Usein kysytyt kysymykset
1. Pystyykö cURL käsittelemään JavaScriptillä renderöityjä verkkosivuja?
Ei, cURL ei voi suorittaa JavaScriptiä. Se hakee raaka-HTML:n sellaisena kuin palvelin sen toimittaa. Jos sivu vaatii JavaScriptiä sisällön renderöintiin tai anti-bot-haasteiden ratkaisemiseen, cURL ei pääse käsiksi dataan. Tällaisissa tapauksissa käytä selaimessa toimivia työkaluja kuten Thunderbitia.
2. Miten tallennan cURLin tulosteen suoraan tiedostoon?
Käytä -o-lippua: curl -o filename.html URL. Tämä kirjoittaa vastauksen rungon tiedostoon sen sijaan, että se näkyisi päätteessä.
3. Mitä eroa on cURLilla ja Thunderbitilla verkkokaavinnassa?
cURL on komentorivityökalu raakaverkkodatan hakemiseen — erinomainen teknisille käyttäjille ja automaatioon. Thunderbit on AI-pohjainen Chrome-laajennus, joka on suunniteltu liiketoimintakäyttäjille, jotka haluavat poimia rakenteista dataa miltä tahansa verkkosivustolta, käsitellä dynaamisia sivuja ja viedä tiedot suoraan työkaluihin kuten Exceliin tai Google Sheetiin — ilman koodia.
4. Onko verkkosivustojen kaavinta cURLilla laillista?
Julkisen datan kaavinta on Yhdysvalloissa yleensä laillista viimeaikaisten oikeuden päätösten jälkeen, mutta tarkista aina sivuston käyttöehdot, robots.txt ja soveltuvat lait. Vältä henkilötietojen tai suojattujen tietojen kaavintaa ilman lupaa, ja kunnioita nopeusrajoja sekä eettisiä ohjeita (calawyers.org, polsinelli.com).
5. Milloin minun pitäisi siirtyä cURLista edistyneempään työkaluun kuten Thunderbitiin?
Jos sinun täytyy kaapia dynaamisia/JavaScript-painotteisia sivuja, haluat rakenteista dataa taulukkoon tai suosit no-code-työnkulkua, Thunderbit on parempi valinta. Käytä cURLia nopeisiin, teknisiin tehtäviin; käytä Thunderbitia liiketoimintaystävälliseen, toistettavaan tiedonpoimintaan.
Lisää verkkokaavintavinkkejä ja oppaita löydät Thunderbit Blogista tai YouTube-kanavaltamme.
Kokeile Thunderbit AI Web Scraperia Get Started Free




