

“Voit saada dataa ilman informaatiota, mutta et voi saada informaatiota ilman dataa.” — Daniel Keys Moran*
Tuoreimpien arvioiden mukaan internetissä on yli 1,5 miljardia verkkosivustoa, ja uusia sivuja ilmestyy päivittäin noin 2 miljoonaa. Tämä valtava datameri sisältää arvokkaita oivalluksia päätöksenteon tueksi, mutta mukana on yksi koukku: noin 80 % siitä on jäsentämätöntä, joten sitä pitää käsitellä ennen kuin siitä on hyötyä. Siksi web scraping -työkalut ovat niin tärkeitä kaikille, jotka haluavat hyödyntää verkossa olevaa dataa.
Jos web scraping on sinulle uutta, termit kuten web components ja HTML voivat kuulostaa vähän pelottavilta. Mutta tekoälyn aikakaudella nämä haasteet on paljon helpompi voittaa. Tämän päivän tekoälypohjaiset scraping-työkalut auttavat pääsemään alkuun ilman syvällistä teknistä osaamista. Niillä dataa voi kerätä ja käsitellä nopeasti, eikä koodaustaitoja tarvita.
Parhaat web scraping -työkalut ja ohjelmistot
- Thunderbit helppokäyttöiseen AI web scraperiin, joka tuottaa parhaat tulokset
- Browse AI reaaliaikaiseen seurantaan ja massadataan poimintaan
- Bardeen AI koodittomaan automaatioon ja laajoihin sovellusintegraatioihin
- Web Scraper visuaalisempaan ja ammattilaismaisempaan web scrapingiin
- Octoparse tehokkaaseen koodittomaan scrapingiin ilman IP-estojen ja bottitunnistuksen kanssa painimista
- Diffbot edistyneeseen tekoälypohjaiseen data extraction API:in ja knowledge graphiin
Kokeile tekoälyä web scrapingissa
Kokeile! Voit klikata, tutkia ja ajaa työnkulun samalla kun katsot.
Miten web scraping toimii?
Web scrapingissa on pohjimmiltaan kyse datan nappaamisesta verkkosivuilta. Annetaan työkalulle joukko ohjeita, ja se käy hakemassa tekstin, kuvat tai muun tarvitsemasi tiedon verkkosivulta taulukkoon. Siitä on hyötyä ihan kaikkeen hintaseurannasta verkkokaupoissa tutkimusdatan keräämiseen tai vaikkapa vain hyvän Excel-taulukon tai Google Sheets -taulukon rakentamiseen.
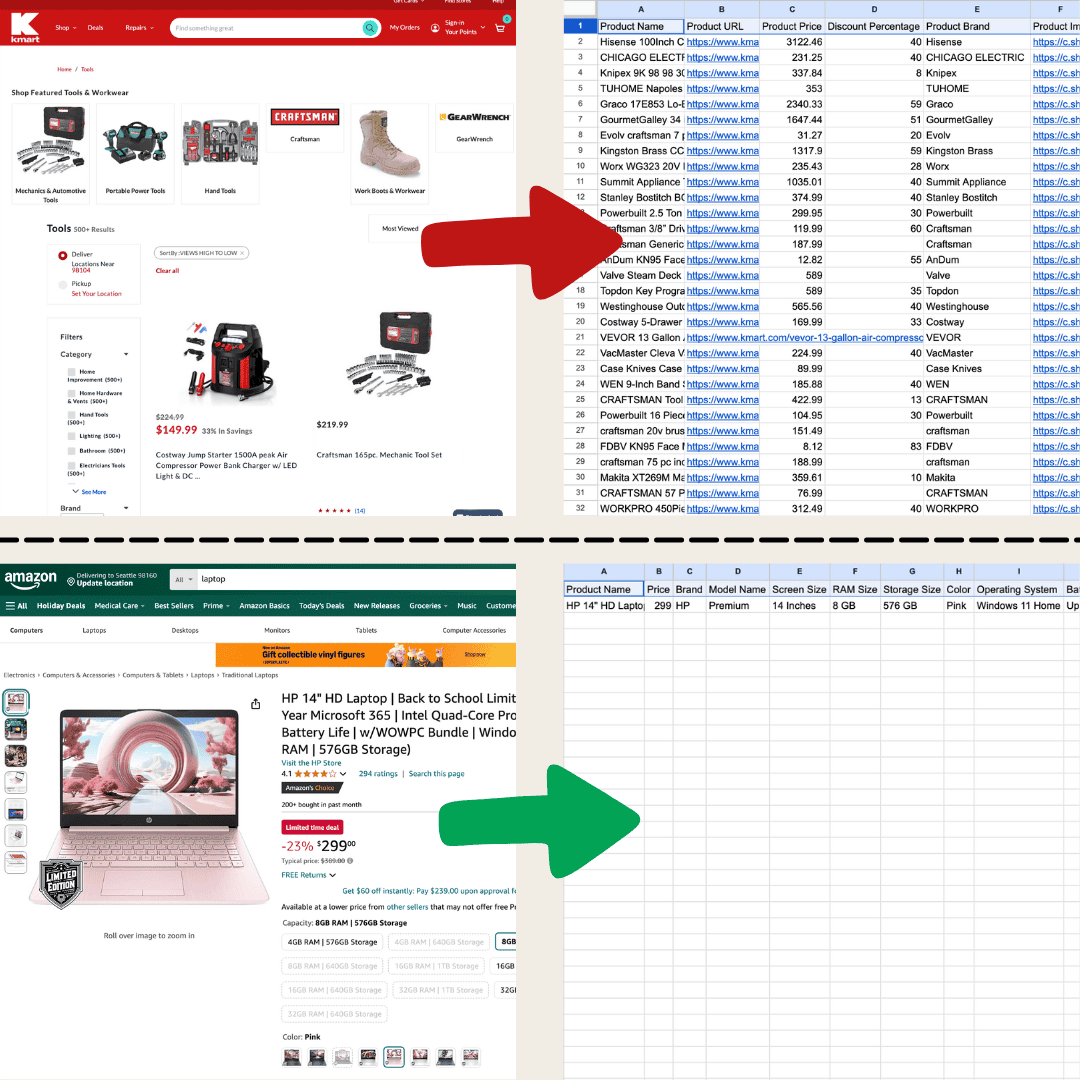 Tein tämän Thunderbitillä käyttäen AI Web Scraperia.
Tein tämän Thunderbitillä käyttäen AI Web Scraperia.
Tapoja on useita. Yksinkertaisimmillaan voisit vain kopioida ja liittää tiedot itse, mutta jos dataa on paljon, se on työlästä. Siksi useimmat käyttävät yhtä kolmesta tavasta: perinteisiä web scrapereita, AI web scrapereita tai omaa koodia.
Perinteiset web scraperit toimivat määrittelemällä tarkat säännöt siitä, mitä dataa poimitaan sivun rakenteen perusteella. Voit esimerkiksi asettaa ne hakemaan tuotenimiä tai hintoja tietyistä HTML-tageista. Ne toimivat parhaiten sivustoilla, jotka eivät muutu kovin usein, koska pienikin ulkoasun muutos tarkoittaa, että scraperia pitää säätää.
 Perinteisen scraperin opettelu vie pitkään, ja käyttöönotto vaatii todennäköisesti kymmeniä klikkauksia.
Perinteisen scraperin opettelu vie pitkään, ja käyttöönotto vaatii todennäköisesti kymmeniä klikkauksia.
Poimi dataa miltä tahansa verkkosivustolta tekoälyllä Get Started Free
AI web scraperit tarkoittavat käytännössä sitä, että ChatGPT lukee koko verkkosivuston ja poimii sitten sisällön tarpeesi mukaan. Se voi hoitaa datan poiminnan, kääntämisen ja tiivistämisen samaan aikaan. Ne käyttävät luonnollisen kielen käsittelyä sivuston rakenteen analysointiin ja ymmärtämiseen, joten ne selviävät sivumuutoksista joustavammin. Jos sivustolla järjestellään osioita vähän uudelleen, AI web scraper voi ehkä mukautua ilman, että sinun tarvitsee kirjoittaa mitään uusiksi. Siksi ne sopivat hyvin ylläpitoa vaativille sivustoille tai monimutkaisemmille rakenteille.
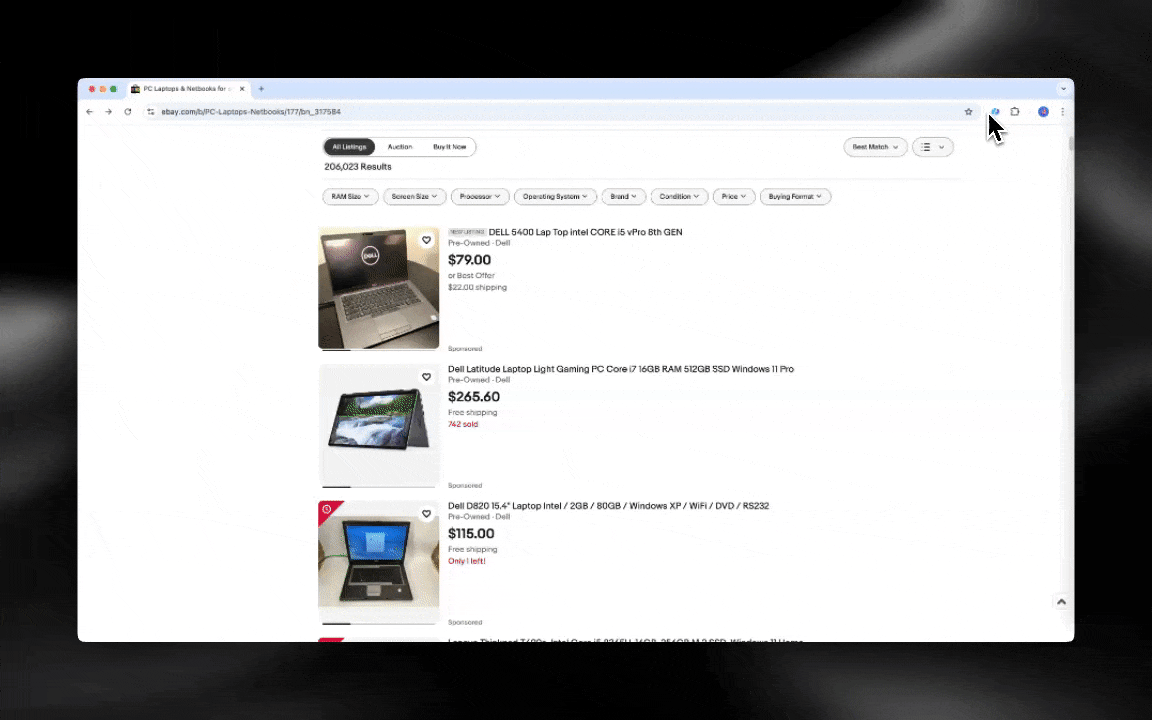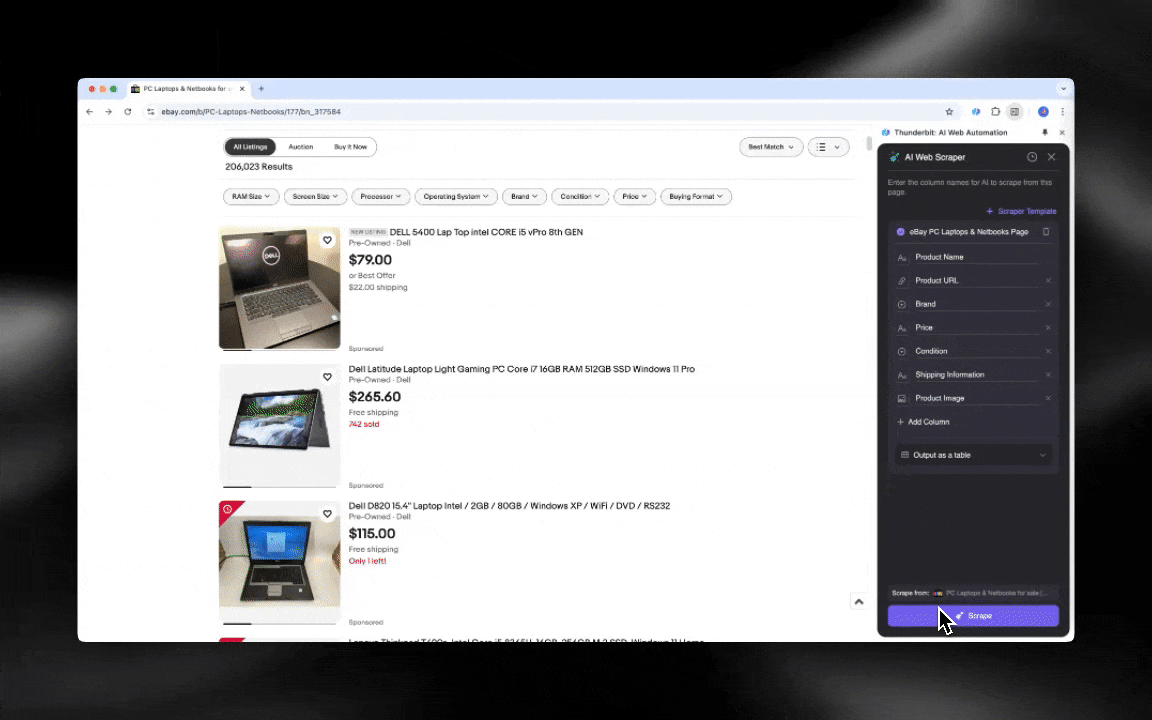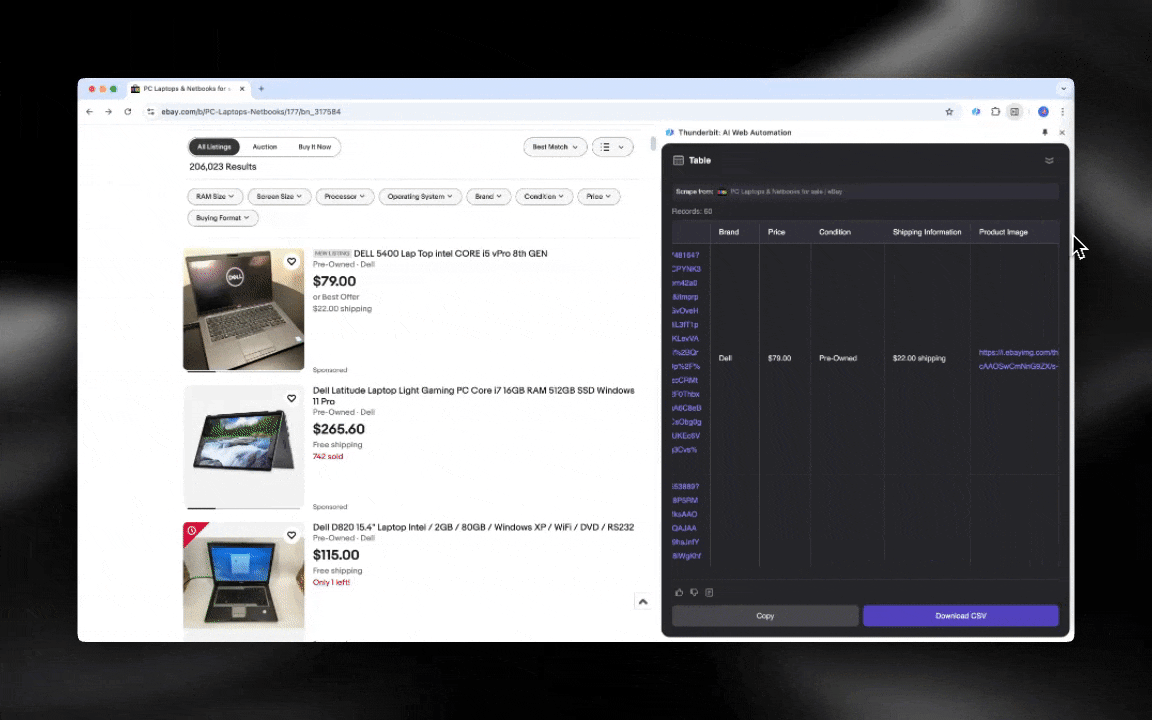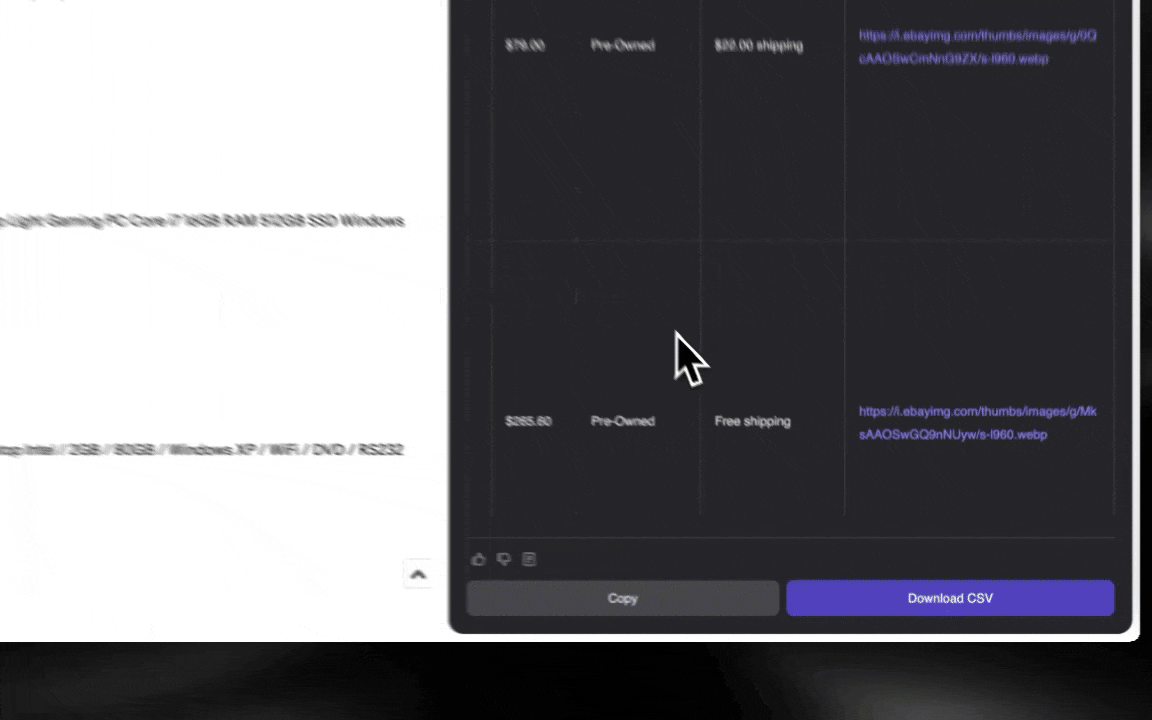 AI web scraper on helppo ottaa käyttöön ja antaa yksityiskohtaista dataa vain muutamalla klikkauksella!
AI web scraper on helppo ottaa käyttöön ja antaa yksityiskohtaista dataa vain muutamalla klikkauksella!
Kumpi kannattaa valita? Se riippuu. Jos koodin säätäminen tuntuu luontevalta tai sinun pitää kerätä suuria määriä dataa suositulta sivustolta, perinteiset scraperit voivat olla erittäin tehokkaita. Mutta jos olet vasta aloittamassa web scrapingia tai haluat työkalun, joka joustaa sivuston muutosten mukana, AI web scraper on yleensä parempi valinta. Tarkista alla oleva taulukko tarkempia tilanteita varten!
| Tilanne | Paras valinta |
|---|---|
| Kevyt scraping sivuilla kuten hakemistot, verkkokaupat tai mikä tahansa sivusto, jossa on lista | AI Web Scraper |
| Sivulla on alle 200 riviä dataa, ja scraperin rakentaminen perinteisellä web scraperilla vie liian kauan | AI Web Scraper |
| Poimittava data pitää saada tiettyyn muotoon ladattavaksi muualle. Esimerkiksi yhteystietojen poiminta HubSpotiin lataamista varten. | AI Web Scraper |
| Laajasti käytetyt sivustot mittakaavassa, kuten kymmenet tuhannet Amazonin tuotesivut tai Zillow'n kohdelistaukset. | Perinteinen Web Scraper |
Parhaat web scraping -työkalut ja ohjelmistot yhdellä silmäyksellä
| Työkalu | Hinnoittelu | Keskeiset ominaisuudet | Plussat | Miinukset |
|---|---|---|---|---|
| Thunderbit | Alkaen 9 $/kk, ilmainen taso saatavilla | AI web scraper, tunnistaa ja muotoilee datan automaattisesti, tukee useita formaatteja, yhden klikkauksen vienti, helppokäyttöinen käyttöliittymä. | Kooditon, AI-tuki, integraatiot kuten Google Sheetsin kanssa | Suurimittainen scraping voi olla hidasta, edistyneet ominaisuudet voivat maksaa enemmän |
| Browse AI | Alkaen 48,75 $/kk, ilmainen taso saatavilla | Kooditon käyttöliittymä, reaaliaikainen seuranta, massadata poiminta, työnkulkuintegraatiot. | Helppokäyttöinen, integroituu Google Sheetsiin ja Zapieriin | Monimutkaiset sivut tarvitsevat lisäasetuksia, massascraaping voi aiheuttaa aikakatkaisuja |
| Bardeen AI | Alkaen 60 $/kk, ilmainen taso saatavilla | Kooditon automaatio, integraatiot yli 130 sovellukseen, MagicBox muuntaa tehtävät työnkuluiksi. | Laajat integraatiot, skaalautuu yrityksille | Jyrkkä oppimiskäyrä uusille käyttäjille, käyttöönotto vie aikaa |
| Web Scraper | Ilmainen paikalliseen käyttöön, 50 $/kk pilveen | Visuaalinen tehtävien luonti, tukee dynaamisia sivustoja (AJAX/JavaScript), pilviscraping. | Toimii hyvin dynaamisilla sivustoilla | Paras käyttöönotto vaatii teknistä osaamista |
| Octoparse | Alkaen 119 $/kk, ilmainen taso saatavilla | Kooditon scraping, sivun elementtien automaattinen tunnistus, pilviscraping ajastetuilla tehtävillä, mallikirjasto yleisille sivustoille. | Tehokkaat ominaisuudet dynaamisille sivustoille, kestää rajoituksia | Monimutkaiset sivut vaativat opettelua |
| Diffbot | Alkaen 299 $/kk | Data extraction API, no-rule API, NLP jäsentämättömälle tekstille, laaja knowledge graph. | Vahva tekoälypohjainen poiminta, laajat API-integraatiot, suurimittainen scraping | Oppimiskäyrä ei-teknisille käyttäjille, käyttöönotto vie aikaa |
Paras web scraper tekoälyn aikakaudella
Thunderbit
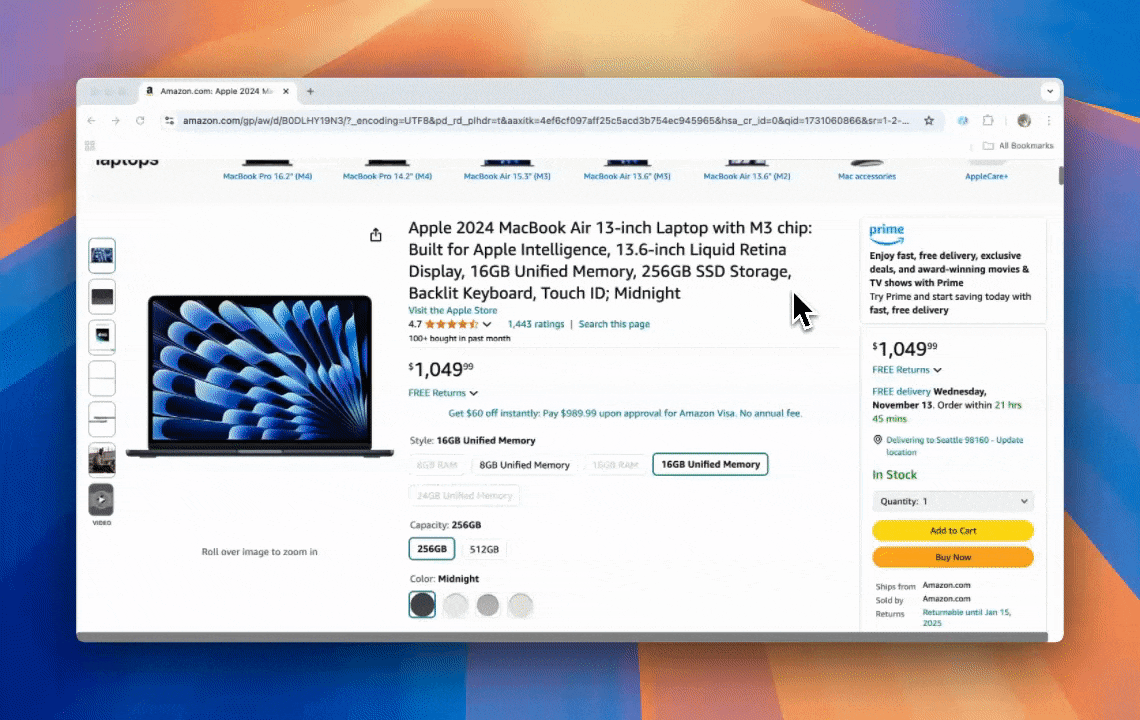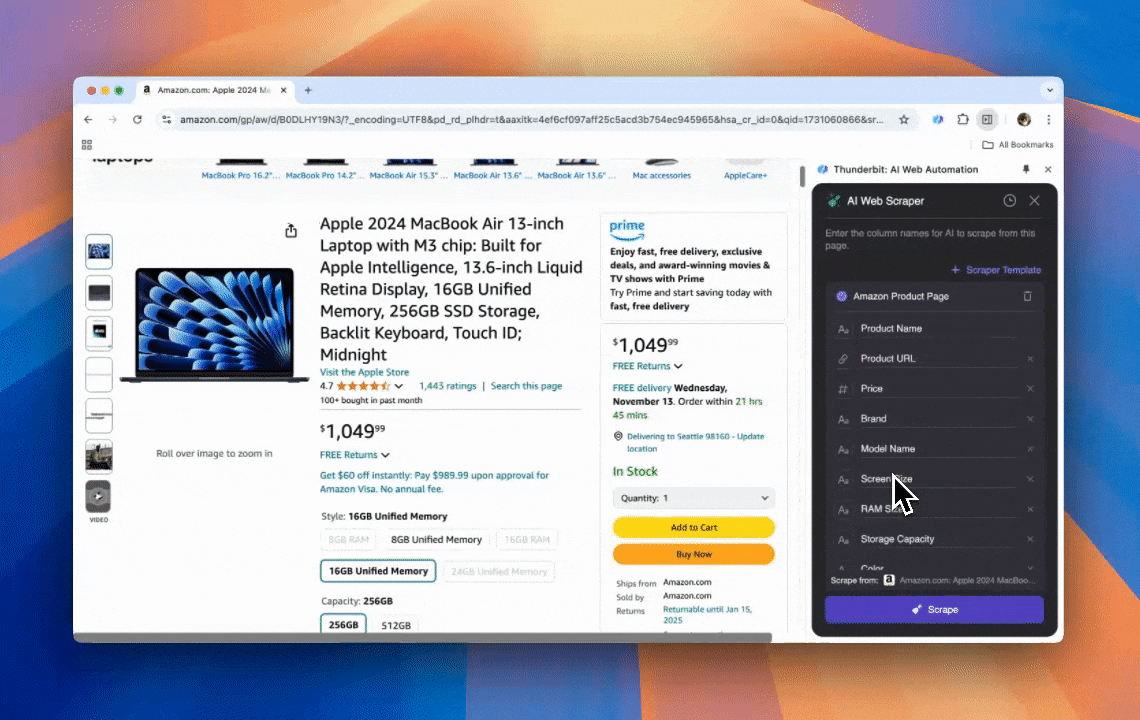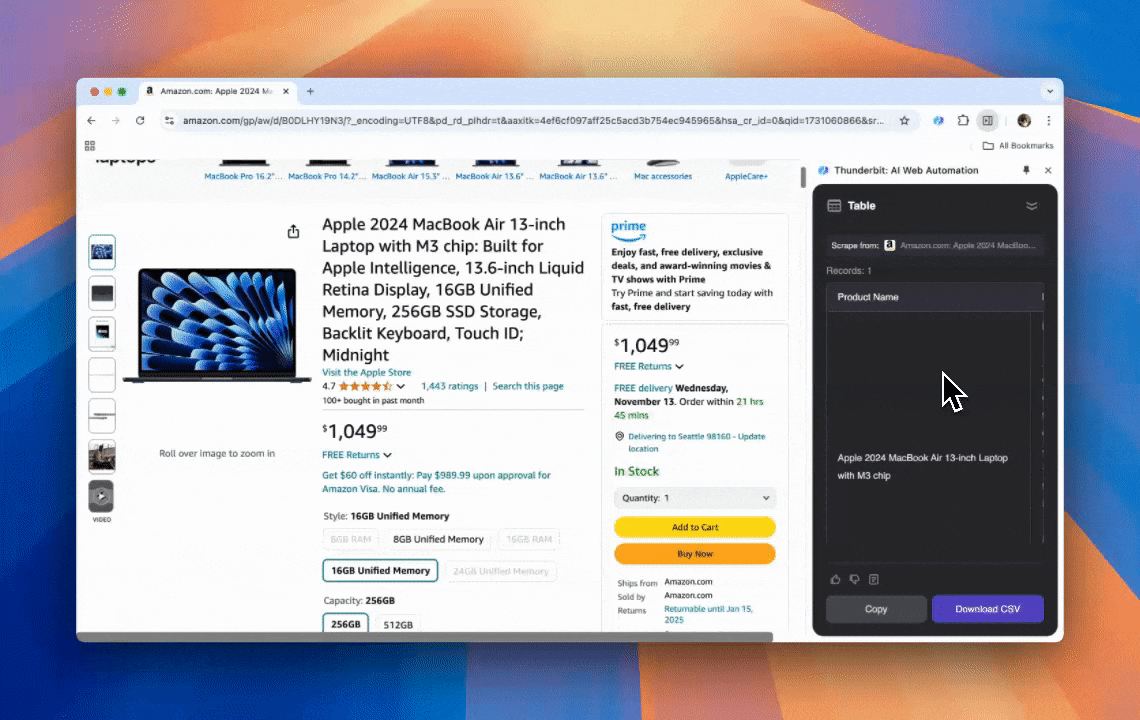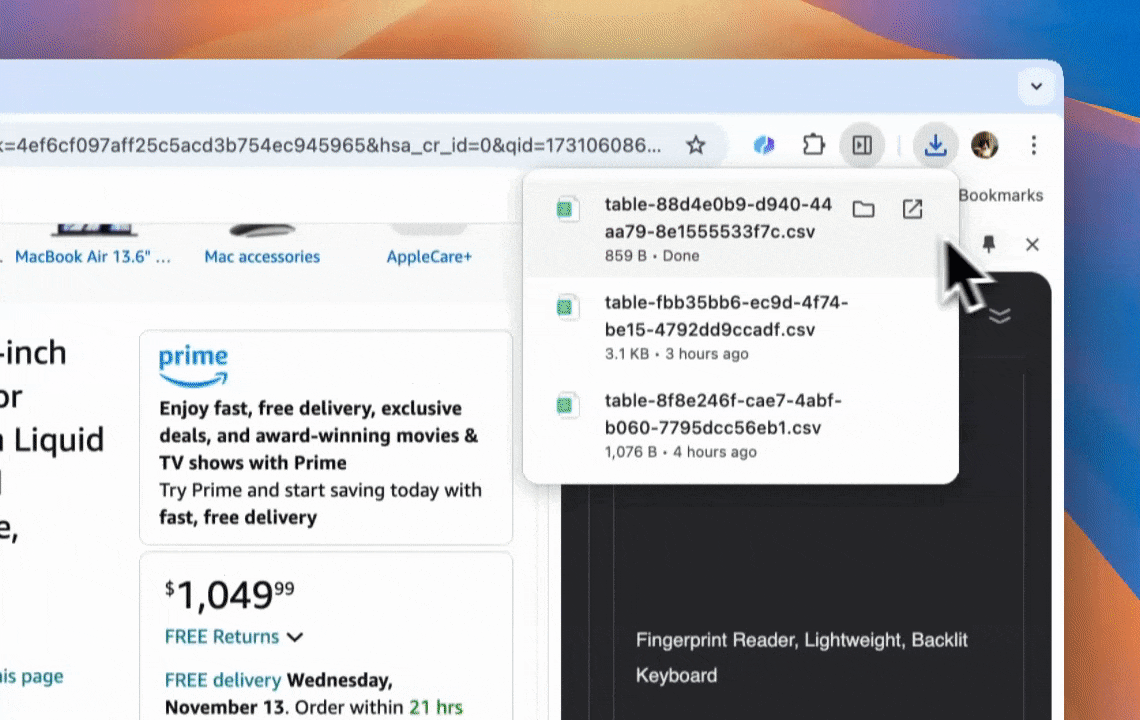
Thunderbit on tehokas ja helppokäyttöinen AI web automation -työkalu, jonka avulla myös ilman koodaustaitoja olevat käyttäjät voivat poimia ja järjestää dataa helposti. Thunderbitin Chrome-laajennuksella sen AI Web Scraper tekee datan poiminnasta suoraviivaista — käyttäjät voivat hakea verkkodataa nopeasti ilman, että heidän tarvitsee käsitellä web-elementtejä manuaalisesti tai rakentaa erillisiä scrapereita eri sivurakenteille.
Keskeiset ominaisuudet
- Tekoälyn tuoma joustavuus: Thunderbitin AI Web Scraper tunnistaa ja muotoilee verkkodatan automaattisesti, joten CSS-valitsijoita ei tarvita.
- Helpoin scraping-kokemus: Sinun tarvitsee vain klikata “AI suggest column” ja sitten sivulla “Scrape”. Siinä kaikki.
- Tuki erilaisille datamuodoille: Thunderbit voi poimia URL-osoitteita ja kuvia sekä näyttää kerätyn datan useissa formaateissa.
- Automatisoitu datankäsittely: Thunderbitin AI voi muotoilla dataa lennossa, myös tiivistää, luokitella ja kääntää sitä tarvittuun muotoon.
- Helppo datan vienti: Vie dataa Google Sheetsiin, Airtableen tai Notioniin yhdellä klikkauksella, mikä tekee datanhallinnasta sujuvaa.
- Helppokäyttöinen käyttöliittymä: Intuitiivinen käyttöliittymä tekee siitä sopivan kaikentasoisille käyttäjille.
Hinnoittelu
Thunderbit tarjoaa porrastettuja paketteja, alkaen 9 dollarista kuukaudessa 5 000 krediitillä. Ylimpään pakettiin asti hinta nousee 199 dollariin 240 000 krediitistä. Vuosipaketissa kaikki krediitit saa kerralla.
Plussat:
- Vahva AI-tuki yksinkertaistaa datan poimintaa ja käsittelyä.
- Kooditon, joten se sopii kaikentasoisille käyttäjille.
- Täydellinen kevyempään scrapingiin, kuten hakemistoihin, verkkokauppoihin ja vastaaviin.
- Hyvät integraatiomahdollisuudet suoriin vientitoimintoihin suosittuihin sovelluksiin.
Miinukset:
- Suurimittainen datan scraping voi viedä aikaa tarkkuuden varmistamiseksi.
- Tietyt edistyneet ominaisuudet voivat vaatia maksullisen tilauksen.
Haluatko lisätietoja? Aloita asentamalla Thunderbit tai katso, miten verkkosivujen scraping onnistuu helposti Thunderbitillä.
Paras web scraper datan seurantaan ja massapoimintaan
Browse AI
Browse AI on tehokas kooditon datanpoimintatyökalu, joka on suunniteltu auttamaan käyttäjiä keräämään ja seuraamaan dataa ilman koodausta. Browse AI:ssa on joitain AI-ominaisuuksia, mutta se ei vielä yllä täyden AI-scrapingin tasolle. Silti se tekee aloittamisesta käyttäjälle paljon helpompaa.
Keskeiset ominaisuudet
- Kooditon käyttöliittymä: Mahdollistaa omien työnkulkujen rakentamisen muutamalla klikkauksella.
- Reaaliaikainen seuranta: Käyttää botteja sivumuutosten seuraamiseen ja päivitetyn tiedon toimittamiseen.
- Massadata poiminta: Pystyy käsittelemään jopa 50 000 tietuetta kerralla.
- Työnkulkuintegraatiot: Yhdistää useita botteja monimutkaisempaa datankäsittelyä varten.
Hinnoittelu
Alkaa 48,75 dollarista kuukaudessa, ja sisältää 2 000 krediittiä. Saatavilla on ilmainen taso, joka tarjoaa 50 krediittiä kuukaudessa perusominaisuuksien kokeiluun.
Plussat:
- Tarjoaa integraatiot Google Sheetsiin ja Zapieriin.
- Valmiit botit helpottavat tavallisia datanpoimintatehtäviä.
Miinukset:
- Monimutkaiset sivut voivat vaatia lisämäärityksiä.
- Massascraapingin nopeus voi vaihdella, mikä johtaa joskus aikakatkaisuihin.
Paras web scraper työnkulkuintegraatioihin
Bardeen AI
Bardeen AI on kooditon automaatiotyökalu, joka on suunniteltu tehostamaan työnkulkuja yhdistämällä erilaisia sovelluksia. Vaikka se käyttää tekoälyä räätälöityjen automaatioiden luomiseen, se ei ole yhtä mukautuva kuin täysiverinen AI scraping -työkalu.
Keskeiset ominaisuudet
- Kooditon automaatio: Käyttäjät voivat rakentaa työnkulkuja klikkaamalla.
- MagicBox: Tehtävät kuvataan tavallisella kielellä, ja Bardeen AI muuntaa ne työnkuluiksi.
- Laajat integraatiot: Toimii yli 130 sovelluksen kanssa, mukaan lukien Google Sheets, Slack ja LinkedIn.
Hinnoittelu
Alkaa 60 dollarista kuukaudessa, ja sisältää 1 500 krediittiä (noin 1 500 datariviä). Ilmainen taso tarjoaa 100 krediittiä kuukaudessa perusominaisuuksien kokeiluun.
Plussat:
- Laajat integraatiot tukevat monenlaisia liiketoiminnan tarpeita.
- Joustava ja skaalautuva kaiken kokoisille yrityksille.
Miinukset:
- Uudet käyttäjät voivat tarvita aikaa koko alustan opetteluun.
- Alkuasetusten määrittäminen voi viedä paljon aikaa.
Paras visuaalinen web scraper kokeneille käyttäjille
Web Scraper
Kyllä, luit oikein: työkalun nimi on "Web Scraper". Web Scraper on suosittu selainlaajennus Chromelle ja Firefoxille, jonka avulla käyttäjät voivat poimia dataa ilman koodausta ja luoda scraping-tehtäviä visuaalisesti. Saatat kuitenkin joutua katsomaan ja opettelemaan muutaman päivän ajan yllä olevia opetusvideoita, jotta hallitset työkalun kunnolla. Jos haluat tehdä scrapingista helpompaa aivoillesi, valitse AI Web Scraper.
Keskeiset ominaisuudet
- Visuaalinen luonti: Käyttäjät voivat määrittää scraping-tehtäviä klikkaamalla web-elementtejä.
- Tuki dynaamisille sivustoille: Pystyy käsittelemään AJAX-pyyntöjä ja JavaScriptiä dynaamisilla sivustoilla.
- Pilviscraping: Tehtävät voi ajastaa Web Scraper Cloudin kautta säännöllistä scrapingia varten.
Hinnoittelu
Ilmainen paikalliseen käyttöön; maksulliset paketit alkavat 50 dollarista kuukaudessa pilviominaisuuksia varten.
Plussat:
- Toimii hyvin dynaamisilla sivustoilla.
- Ilmainen paikalliseen käyttöön.
Miinukset:
- Optimaalinen käyttöönotto vaatii teknistä osaamista.
- Muutosten testaaminen on monimutkaista.
Paras web scraper IP-estojen ja bottitunnistuksen kiertämiseen
Octoparse
Octoparse on monipuolinen ohjelmisto teknisemmille käyttäjille, jotka haluavat kerätä ja seurata tiettyä verkkodataa ilman koodausta. Se sopii erinomaisesti suurten datamäärien tarpeisiin. Octoparse ei nojaa käyttäjän selaimeen toimiakseen, vaan käyttää datanpoistoon pilvipalvelimia. Siksi se voi tarjota erilaisia tapoja ohittaa IP-estot ja tietyt verkkosivustojen bottitunnistukset.
Keskeiset ominaisuudet
- Kooditon käyttö: Käyttäjät voivat luoda scraping-tehtäviä ilman koodia, joten työkalu sopii eri tasoisille käyttäjille.
- Älykäs automaattitunnistus: Se tunnistaa sivun datan automaattisesti, löytää nopeasti poimittavat elementit ja helpottaa käyttöönottoa.
- Pilviscraping: Tukee 24/7-pilvidatan poimintaa sekä ajastettuja scraping-tehtäviä joustavaan datanhakuun.
- Laaja mallikirjasto: Tarjoaa satoja valmiita malleja, joiden avulla suosittujen sivustojen dataan pääsee käsiksi nopeasti ilman monimutkaista käyttöönottoa.
Hinnoittelu
Octoparsen hinnoittelu alkaa 119 dollarista kuukaudessa, ja sisältää 100 tehtävää. Saatavilla on myös ilmainen taso, jossa on 10 tehtävää kuukaudessa perustoimintojen testaamiseen.
Plussat:
- Tehokkaat ominaisuudet tukevat dynaamisten sivustojen scrapingia joustavasti.
- Tarjoaa ratkaisuja scraping-rajoitusten ja dynaamisen sisällön haasteisiin.
Miinukset:
- Monimutkaiset verkkosivurakenteet voivat vaatia enemmän aikaa käyttöönotossa.
- Uudet käyttäjät voivat tarvita aikaa käyttötapojen opetteluun.
Paras web scraper edistyneeseen tekoälypohjaiseen data extraction API:in
Diffbot
Diffbot on edistynyt web-datan poimintatyökalu, joka käyttää tekoälyä muuntaakseen jäsentämättömän verkkosisällön rakenteiseksi dataksi. Tehokkaiden API-rajapintojen ja knowledge graphin avulla Diffbot auttaa käyttäjiä poimimaan, analysoimaan ja hallitsemaan verkosta löytyvää tietoa eri toimialoille ja käyttötarkoituksiin sopivasti.
Keskeiset ominaisuudet
- Data Extraction API: Diffbot tarjoaa no-rule data extraction API:n, jonka avulla käyttäjä voi vain antaa URL-osoitteen ja datan poiminta tapahtuu automaattisesti ilman, että jokaiselle sivustolle pitää määrittää omat säännöt.
- Luonnollisen kielen käsittelyn API: Poimii jäsentämättömästä tekstistä rakenteiset entiteetit, suhteet ja sävyn, mikä auttaa käyttäjiä rakentamaan omia knowledge graphejaan.
- Knowledge Graph: Diffbotilla on yksi suurimmista knowledge grapheista, joka yhdistää laajan määrän entiteettitietoa, mukaan lukien yksilöitä ja organisaatioita koskevat tiedot.
Hinnoittelu
Diffbotin hinnoittelu alkaa 299 dollarista kuukaudessa, ja sisältää 250 000 krediittiä (vastaa noin 250 000 API-pohjaista verkkosivun poimintaa).
Plussat:
- Vahva no-rule data extraction -kyky ja korkea mukautuvuus.
- Laajat API-integraatiot helpottavat liittämistä olemassa oleviin järjestelmiin.
- Tukee suurimittaista scrapingia, joten soveltuu yritystason käyttöön.
Miinukset:
- Alkuasetukset voivat vaatia ei-teknisiltä käyttäjiltä hieman opettelua.
- Käyttäjän täytyy kirjoittaa ohjelma, joka kutsuu APIa.
Mihin scrapersit sopivat?
Jos web scraping on sinulle uutta, tässä on muutamia suosittuja käyttötapauksia, joista on hyvä aloittaa. Moni käyttää scrapereita Amazonin tuotelistauksien hakemiseen, Zillow'n kiinteistötietojen poimintaan tai yritystietojen keräämiseen Google Mapsista. Mutta tämä on vasta alku — voit käyttää Thunderbitin AI Web Scraperia kerätäksesi dataa lähes miltä tahansa verkkosivustolta, virtaviivaistaaksesi tehtäviä ja säästääksesi aikaa päivittäisessä työssäsi. Olipa kyse tutkimuksesta, hintaseurannasta tai tietokantojen rakentamisesta, web scraping avaa lukemattomia tapoja hyödyntää internetin dataa omaksi eduksesi.
Usein kysytyt kysymykset
-
Onko web scraping laillista?
Web scraping on yleensä laillista, mutta siinä on noudatettava sivuston käyttöehtoja ja huomioitava käsiteltävän datan luonne. Tarkista aina asiaankuuluvat käytännöt ja noudata lakeja ja ohjeita.
-
Tarvitsenko ohjelmointitaitoja web scraping -työkalujen käyttöön?
Useimmat tässä esitellyistä työkaluista eivät vaadi ohjelmointitaitoja, mutta työkaluista kuten Octoparse ja Web Scraper voi olla hyötyä, jos käyttäjällä on perustiedot verkkorakenteista ja ohjelmoijan ajattelutapa parhaan hyödyn saamiseksi.
-
Onko olemassa ilmaisia web scraping -työkaluja?
Kyllä, ilmaisia työkaluja kuten BeautifulSoup, Scrapy ja Web Scraper on saatavilla, ja jotkin työkalut tarjoavat myös rajoitetun ilmaisen version.
-
Mitkä ovat yleisiä haasteita web scrapingissa?
Yleisiä haasteita ovat dynaamisen sisällön käsittely, CAPTCHA-tarkistukset, IP-estot ja monimutkaiset HTML-rakenteet. Edistyneet työkalut ja tekniikat pystyvät ratkaisemaan nämä ongelmat tehokkaasti.
Lue lisää:
Käytä tekoälyä työskentelyyn ilman vaivannäköä. Get Started Free




