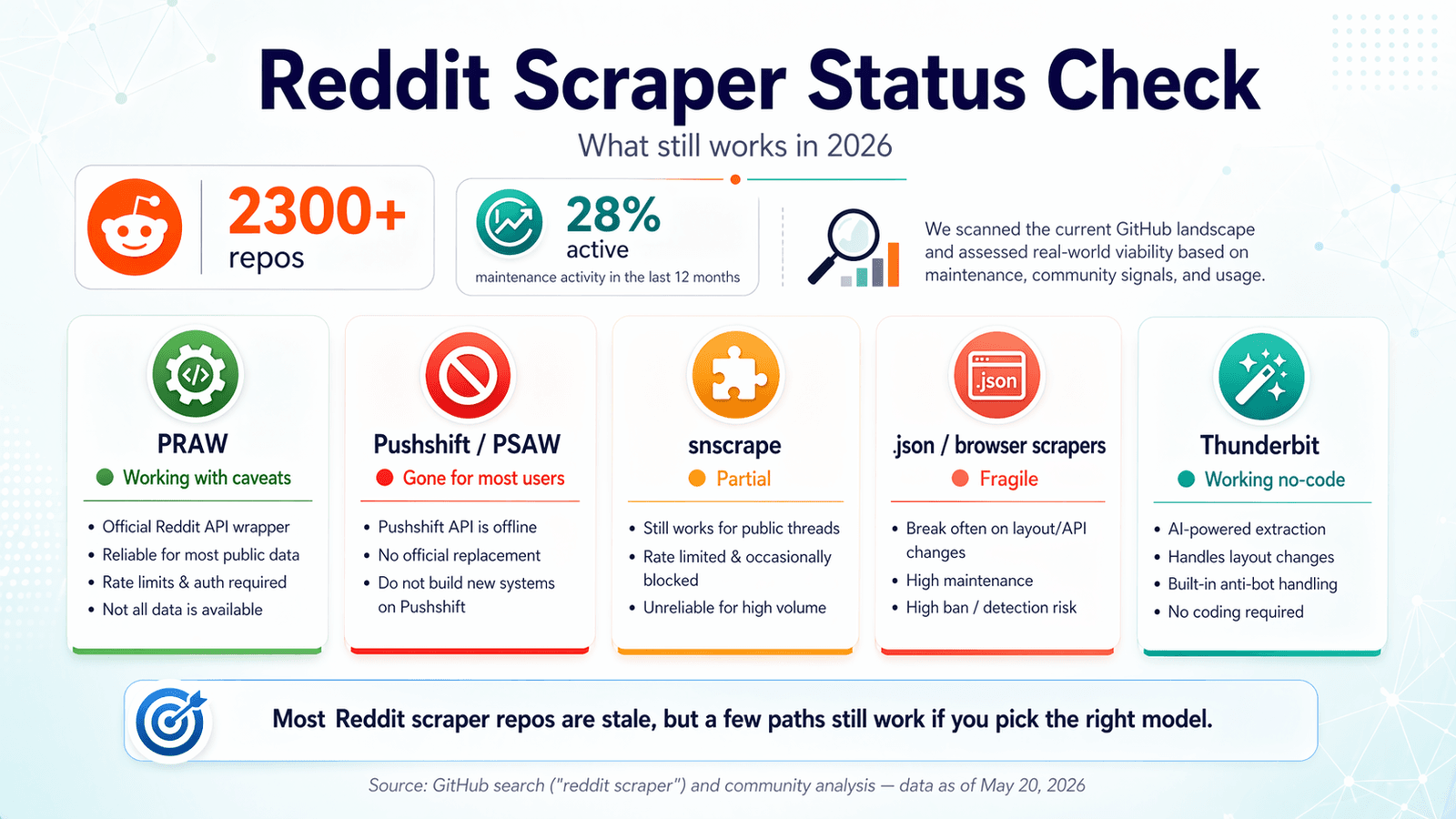
GitHubissa näkyy tällä hetkellä yli . Kuulostaa runsaudensarvelta. Juju on siinä, että vain noin 28 %:lla näkyy mitään ylläpitotoimintaa viimeisten kahdentoista kuukauden aikana. Olen viettänyt viime viikot penkoen näitä repoja, testaten päätepisteitä, lukien issue-jonoja ja vertaillen Redditin omia käytäntöpäivityksiä. Tavoite: säästää sinut siltä, että kloonaat repon, painit OAuthin kanssa ja huomaat keskiyöllä, että koko paketti hajosi hiljaa vuonna 2024. Reddit-scraper GitHub -kenttä vuonna 2026 on hautausmaa hyvistä aikomuksista, jonka seassa on vain muutama aidosti hyödyllinen työkalu. Tämä opas käy läpi, mikä toimii edelleen, mikä hajosi, milloin koodi kannattaa ohittaa kokonaan ja miten pysyt Redditin yhä tiukemman valvonnan oikealla puolella. Jos etsit oikopolkua, on no-code-vaihtoehto, jonka rakensimme juuri tällaisia tilanteita varten — mutta olen rehellinen myös siitä, missä koodipohjaiset ratkaisut ovat edelleen järkevämpiä.
Mikä on Reddit Scraper GitHub -repo (ja miksi niin moni on rikki)
"reddit scraper github" -repo on tyypillisesti avoimen lähdekoodin Python- (tai joskus JavaScript-) projekti, joka automatisoi postausten, kommenttien, käyttäjätietojen tai median hakemisen Redditistä. Ne jakautuvat yleensä neljään leiriin:
- API-wrapperit (kuten PRAW): käyttävät Redditin virallista API:a, vaativat OAuthin ja toimivat Redditin sääntöjen mukaan.
- Pushshift/PSAW-pohjaiset työkalut: hyödyntivät Pushshiftin valtavaa Reddit-arkistoa historialliselle datalle.
- Julkiset
.json-päätepistescraperit: lisäävät Redditin URL-osoitteeseen.json-päätteen tai kutsuvat julkisia päätepisteitä ilman tunnistautumista. - Selaimeen perustuvat scraperit: käyttävät Playwrightia, Seleniumia tai selainlaajennuksia Reddit-sivujen lataamiseen ja renderöidyn sisällön poimimiseen.
Miksi niin moni hajosi? Kolme syytä.
- Redditin API-hinnoittelu uudistettiin rajusti kesällä 2023. Ilmaiset API-rajat putosivat . Suurempi kaupallinen käyttö maksaa nyt 0,24 dollaria per 1 000 API-kutsua. Moni repo rakennettiin maailmaan, jossa API-yhteys oli käytännössä rajaton — ja se maailma on poissa.
- Pushshiftin julkinen pääsy suljettiin. Pushshift oli historiallista Reddit-tutkimusta varten keskeinen perusta. Kun Reddit rajoitti sen käyttöä, valtava osa "historiallisista scrapers" -repoista menetti pääasiallisen tietolähteensä. Osa README-tiedostoista saa työkalut yhä näyttämään elossa olevilta, mutta kulissien takainen riippuvuus on tavallisilta käyttäjiltä poissa.
- Reddit kiristi sekä politiikkaa että valvontaa. Vuoden 2024 robots.txt-päivitys, vuoden 2025 ja maaliskuun 2026 viestivät kaikki, ettei Reddit enää pidä massakaappausta harmittomana taustameluna. Se on jopa .
Yhteenveto: hae "reddit scraper github", niin saat satoja osumia. Viimeisimmän commitin päivämäärät ja avoimien issueiden määrä kertovat aivan toisen tarinan.
Reddit Scraper GitHub -tilanne vuonna 2026: mikä toimii edelleen
Useimmat kilpailevat artikkelit on kirjoitettu vuonna 2023 tai 2024, eikä niitä ole päivitetty sen jälkeen. Foorumikäyttäjät törmäävät jatkuvasti virheisiin repossa, joka toimi vielä vuosi sitten — erään käyttäjän huokaus, "Keep running into Reddit API limitation error :\ Any ideas how I can get past this?" on käytännössä vuoden 2026 Reddit-scraper-kokemus tiivistettynä yhteen lauseeseen.
Tein tuoreustarkistuksen, vahvistettuna huhtikuussa 2026. Tässä mitä löysin.
PRAW: virallinen Python-wrapper
Tila: ✅ Toimii edelleen, varauksin.
(Python Reddit API Wrapper) on edelleen luotettavin avoimen lähdekoodin perusta Redditin scrappaamiseen. Sitä ylläpidetään aktiivisesti — 4 099 tähteä, viimeisin push 20. huhtikuuta 2026, vain 6 avointa issuea, ja (julkaistu lokakuussa 2024).
Vahvuudet: virallinen, hyvin dokumentoitu, abstrahoi suuren osan Redditin API:n monimutkaisuudesta.
Vuoden 2026 rajoitukset:
- Tiukemmat OAuth-vaatimukset. Tarvitset rekisteröidyn Reddit-sovelluksen ja hyväksytyn käyttötapauksen kuvauksen.
- Pienemmät rate limitit vuodesta 2024 lähtien (100 kyselyä/min OAuthilla, 10 ilman).
- Kova noin 1 000 postauksen listauskatto on yhä voimassa. Yhteisöketjut r/redditdevissä ja Stack Overflow'ssa vahvistavat: yhtä listauspäätepistettä kohden.
PRAW on turvallisin vaihtoehto, jos voit pysyä API:n asettamissa raameissa.
Se ei kuitenkaan ole enää vapaan muotoinen massascraper.
Jos haluat käytännönläheisen läpikäynnin virallisen API-reitin käytöstä, tämä opas sopii hyvin tähän kohtaan:
Pushshift / PSAW: arkisto, joka pimeni
Tila: ❌ Julkinen pääsy on poissa.
oli aiemmin Pushshiftin suosituin Python-wrapper, ja Pushshift oli ennen helpoin reitti historiallisten Reddit-tietojen saamiseen. Vuonna 2026 repo on arkistoitu, README sanoo kirjaimellisesti "THIS REPOSITORY IS STALE", ja viimeaikaisissa avoimissa issueissa on helmiä kuten "Pushshift.io UNABLE to connect" sekä "The code not working. Possibly due to pushshift api."
Akateeminen pääsy voi yhä olla mahdollinen tiettyjen kanavien kautta, mutta kaikille, jotka etsivät tänään "reddit scraper github" -ratkaisua, Pushshift/PSAW ei ole käyttökelpoinen vaihtoehto. Jos tarvitset syvää historiallista Reddit-dataa, sinun täytyy selvittää hyväksytty akateeminen datan käyttö tai lisensoitu reitti.
snscrape (Reddit-moduuli): osittainen ja epäluotettava
Tila: ⚠️ Osittainen — ajoittaisia katkoksia, pääosin ilman ylläpitoa.
illa on 5 337 tähteä, mutta viimeisin push on 15. marraskuuta 2023. README sanoo yhä, että Reddit-scrapetus toimii "via Pushshift". Avoimia Reddit-aiheisia issueita ovat mm. "Error reddit scraping" ja "Reddit scraper returns no submissions before 2022-11-03", eikä viimeaikaista merkittävää korjaustoimintaa ole näkynyt.
Se voi toimia pieniin, kertaluonteisiin ajoihin joissain ympäristöissä, mutta tuotantoon tai toistuviin ajoihin sitä ei voi pitää luotettavana. Käsittele sitä perintötyökaluna.
Playwright- ja .json-päätepistescraperit: kiertotie, joka toimii joskus
Tila: ✅ Toimii, mutta hauras.
Ajatus on yksinkertainen: käytä headless-selainta (Playwright, Puppeteer) Reddit-sivujen lataamiseen ja renderöidyn sisällön scrappaamiseen, tai lisää Redditin URL-osoitteeseen .json, jotta saat jäsenneltyä dataa ilman virallista API:a.
Vahvuudet: API-avainta ei tarvita, voi kiertää 1 000 postauksen katon, pääsee käsiksi renderöityyn sisältöön.
Heikkoudet: hajoaa, kun Reddit muuttaa etupään asettelua tai JSON-rakennetta, voi laukaista bottiestoja ja vaatii enemmän teknistä käyttöönottoa. Omissa testeissäni tänä kuukautena suorat pyynnöt Redditin julkisiin .json-päätepisteisiin palauttivat 403-vastauksia. Se ei tarkoita, että kaikki ympäristöt blokattaisiin, mutta se tarkoittaa, ettei .json-oikotietä kannata enää olettaa "vain toimivaksi".
Repo kuten on tässä yllättävän rehellinen: README varoittaa käyttäjiä käyttämään "rotating proxies" -ratkaisua, muuten Reddit saattaa lahjoittaa sinulle IP-banin. Se on käytännössä huhtikuun 2026 tarina yhdessä lauseessa.
Jos arvioit selainautomaatioon perustuvaa kiertotietä, tämä Playwright-opas sopii hyvin alla olevan osion rinnalle:
Thunderbit: tekoälypohjainen selainscraping (ei koodia, ei API-avainta)
Tila: ✅ Toimii — mukautuu sivumuutoksiin automaattisesti.
toimii täysin eri tavalla. Se on , joka käyttää tekoälyä Reddit-sivujen lukemiseen, ehdottaa kenttiä (postauksen otsikko, kirjoittaja, ylä-äänet, aikaleima, URL jne.) ja poimii jäsennellyn datan kahdella klikkauksella. Ei OAuth-käyttöönottoa, ei API-avaimen rekisteröintiä, ei Python-ympäristöä, ei riippuvuuksien hallintaa. Tekoäly lukee sivun aina uudelleen, joten kun Reddit muuttaa asetteluaan, Thunderbit mukautuu automaattisesti eikä hajoa hiljaa.
Vienti CSV:ään, Google Sheetsiin, Airtableen tai Notioniin on ilmainen. Tukee sivutusta ja alasivujen scrappausta (esim. subredditin listaus, sitten jokaiselle postaukselle siirtyminen kommenttien hakemiseksi). Niille, jotka haluavat Reddit-dataa ilman GitHub-repon ylläpitämistä, tämä on vähiten kitkaa aiheuttava reitti.
(Täysi avoimuus: rakensimme Thunderbitin itse, joten minulla on tietysti vinouma — mutta olen selkeä myös siitä, missä koodipohjaiset ratkaisut ovat myöhemmin edelleen järkevämpiä.)
Vertailutaulukko tilannekatsauksesta
| Työkalu / kategoria | Toimiiko edelleen (huhtikuu 2026)? | Vaatiiko API-avaimen? | Huomautukset |
|---|---|---|---|
| PRAW | ✅ Kyllä, varauksin | Kyllä (OAuth) | Parhaiten ylläpidetty avoimen lähdekoodin perusta. Rate limitit ja 1k-postauskatto rajoittavat. |
| Pushshift / PSAW | ❌ Ei (useimmille käyttäjille) | Ei sovellu | Julkinen pääsy poissa. Repo arkistoitu. |
| snscrape (Reddit-moduuli) | ⚠️ Osittain / epäluotettava | Ei | Dokumentoi yhä Redditin "via Pushshift". Ylläpito pysähtynyt vuonna 2023. |
| .json / julkisen päätepisteen scraperit | ⚠️ Osittain | Ei | Voi toimia, mutta suorat pyynnöt blokataan yhä useammin. Riippuu proxystä. |
| Playwright / selain-scraperit | ✅ Kyllä, mutta hauras | Yleensä ei | Käytännöllisin no-API DIY-kiertotie. Sivumuutokset ja bottitarkistukset ovat yhä tärkeitä. |
| Thunderbit | ✅ Kyllä | Ei | Tekoäly-/selaintyönkulku. Ei OAuthia, ei selektoreita. Paras valinta ei-kehittäjille. |
Rate limitit, 1 000 postauksen katto ja mikä oikeasti auttaa
Tämä on suurin kipukohta kaikille, jotka käyttävät reddit scraper github -projektia. Foorumiketjut ovat täynnä turhautumista: "tired of runs dying halfway through because of rate limits", "Why am I only getting around 1,000 items?" Kaksi keskeistä rajoitetta ovat Redditin API-rate limitit (pyynnöt minuutissa) ja noin 1 000 postauksen listauskatto (API palauttaa vain viimeisimmät noin 1 000 postausta yhtä listauspäätepistettä kohden).
Rate limit -hallinnan parhaat käytännöt
Redditin nykyinen julkinen perusraja: . Näin käsittelet sitä käytännössä:
- Eksponentiaalinen takaisinkytkentä. Jos saat rate-limit-vastauksen, odota ja yritä uudelleen pitemmän viiveen jälkeen joka kerta (1 s, 2 s, 4 s, 8 s…). Älä vain pommita päätepistettä.
- Lue
X-Ratelimit-Remaining-otsakkeet. Redditin API-vastaukset sisältävät otsakkeita, jotka kertovat, montako pyyntöä sinulla on jäljellä ja milloin ikkuna nollautuu. Tahdista pyynnöt näiden arvojen mukaan, älä arvailulla. - Vaihtele user-agentteja. Jotkut reposuositukset ehdottavat tätä havaitsemisen välttämiseksi. Se voi auttaa, mutta käytä sitä eettisesti — älä yritä sillä kiertää bännäyksiä, jotka olet ansainnut.
- Lokita kaikki. Lisää lokitus API-vastauksille, rate-limit-otsakkeille ja virheille. Kun scraper kuolee klo 2 yöllä, lokit ovat paras ystäväsi.
1 000 postauksen katon kiertäminen
Uskottavin kiertotie API:n noin 1 000 kohteen listauskatolle on aikaväliin pilkkominen:
- Kysy yksi aikajakso
before- jaafter-aikaleimaparametreilla. - Siirrä ikkunaa eteen- (tai taakse-) päin.
- Toista.
- Poista duplikaatit postauksen ID:n perusteella.
Tämä ei ole eleganttia, mutta rehellisempää kuin väittää, että yksi pyyntösilmukka voisi hakea mielivaltaista historiaa listauspäätepisteestä. Aidosti historiallista dataa varten tarvitset hyväksytyn akateemisen pääsyn tai lisensoidun reitin — Pushshift ei ole enää oletusvastaus.
Selaimeen perustuva scrapetus (Playwright tai Thunderbit) kiertää tämän katon kokonaan, koska se scrappaa sivulla renderöidyn sisällön, ei sitä mitä API palauttaa. Thunderbitin sivutusominaisuus antaa sinun klikata sivuja läpi ja kerätä dataa niin monelta sivulta kuin tarvitset.
Duplikaattien poisto ja virheiden palautuminen
Useimmat reddit scraper github -repos eivät käsittele duplikaattien poistoa tai virheiden palautumista valmiina ominaisuutena. Käyttäjät valittavat suoraan, ettei "none had deduping, rate limit avoidance after errors, checking if files are already downloaded." Tee näin:
- Duplikaattien poisto: hashaa jokaisen postauksen ID (tai ID + sisältö). Tallenna nähdyt hashit yksinkertaiseen SQLite-tietokantaan tai jopa tekstitiedostoon. Ennen lisäystä tarkista, onko hash jo olemassa. Tämä on erityisen tärkeää, kun pilkot aikavälejä tai ajat epäonnistuneita ajoja uudelleen.
- Virheiden palautuminen: tallenna eteneminen checkpoint-tiedostoon joka N:n tietueen jälkeen. Jos ajo epäonnistuu, käynnistä uudelleen viimeisestä checkpointista alusta aloittamisen sijaan. Näin 3 tunnin työ, joka kaatuu tunnin kohdalla, muuttuu 1 tunnin jatkettavaksi ajoksi.
Miten eri lähestymistavat käsittelevät näitä rajoitteita

| Lähestymistapa | Rate-limitin käsittely | >1k postausta? | Automaattinen duplikaattien poisto? | Virheiden palautuminen? |
|---|---|---|---|---|
| PRAW (raaka) | Manuaalinen (sleep/retry) | ❌ (API-katto) | ❌ | ❌ |
| PRAW + aikaväliin pilkkominen | Manuaalinen | ✅ (kiertotie) | ❌ | ❌ (ellei lisätty erikseen) |
| Playwright .json -scrapetus | Ei sovellu (ei API:a) | ✅ | ❌ | ❌ |
| Thunderbit (selainscraping) | Sisäänrakennettu (tekoälyn tahdistus) | ✅ (sivutus) | Ei sovellu (visuaalinen tarkistus) | Sisäänrakennettu |
Milloin Reddit Scraper GitHub -repo ei ole vastaus: no-code-reitti
Useimmat reddit scraper github -artikkelit olettavat, että hallitset Pythonin. Mutta moni Reddit-scraping-ratkaisuja hakeva on markkinoija, myyntiedustaja, tutkija tai indie-founderi, joka ei kirjoita Pythonia päivittäin. Tälle yleisölle GitHub-repo tuo piilokuluja:
- OAuth-tunnisteiden ja Redditin kehittäjäsovelluksen käyttöönotto
- Python-virtuaaliympäristöjen ja riippuvuusristiriitojen hallinta
- Hämärien virheilmoitusten debuggaus, kun PRAW:n sisäosat muuttuvat
- API-avaimen mitätöitymisen käsittely, jos Reddit päättää, ettei käyttötapaustasi ole hyväksytty
- Skriptin ylläpito joka kerta, kun Reddit muuttaa jotain
Nämä eivät ole hypoteeseja. -repossa on 2 563 tähteä ja 107 avointa issuea. Viimeaikaisia raportteja ovat mm. "Struggling to install", "PRAW module error" ja "Exception not allowing to even authenticate."
Käytä GitHub-repoa, jos...
- Tarvitset räätälöityä scrapping-logiikkaa (esim. tietyn kommenttipuun läpikäynti, oma NLP-putkisto).
- Haluat integroida olemassa olevaan Python-dataputkeen.
- Sinun täytyy scrapata erittäin suurella skaalalla ja omalla tallennuksella (tietokanta, data warehouse).
- Olet valmis ylläpitämään koodia ja käsittelemään rikkovia muutoksia.
Käytä no-code-työkalua, jos...
- Tarvitset Reddit-dataa nopeasti — minuuteissa, etkä tuntien käyttöönoton jälkeen.
- Et halua hallita API-avaimia, OAuth-sovelluksia tai Python-ympäristöjä.
- Haluat viedä datan suoraan taulukoihin, Notioniin tai Airtableen välitöntä käyttöä varten.
- Haluat työkalun mukautuvan automaattisesti, kun Redditin asettelu muuttuu.
Thunderbit istuu suoraan no-code-luokkaan. Käyttäjät voivat kahdella klikkauksella tekoälyn ehdottamilla kentillä, viedä tiedot ilmaiseksi CSV:hen/Google Sheetsiin/Airtableen/Notioniin ja käsitellä sivutusta ilman koodia. Selainpohjainen scrapetus tarkoittaa, ettei OAuth-käyttöönottoa eikä API-avaimen rekisteröintiä tarvita.
Pikakävely: Redditin scrappaus Thunderbitillä (vaihe vaiheelta)
- Asenna .
- Siirry Reddit-sivulle, jonka haluat scrapata (subreddit, hakutulokset, käyttäjäprofiili).
- Napsauta "AI Suggest Fields". Thunderbit lukee sivun ja ehdottaa sarakkeita — postauksen otsikko, kirjoittaja, ylä-äänet, aikaleima, URL jne.
- Säädä kenttiä tarvittaessa ja napsauta sitten "Scrape".
- Tarkista datataulukko. Halutessasi voit napsauttaa "Scrape Subpages" ja vierailla jokaisella postauksella hakeaksesi kommentit tai lisätiedot.
- Vie haluamaasi kohteeseen: Google Sheets, Excel, Airtable, Notion, CSV tai JSON.
Kaksi minuuttia. Nolla riviä koodia. Jos haluat nähdä sen toiminnassa, katso .
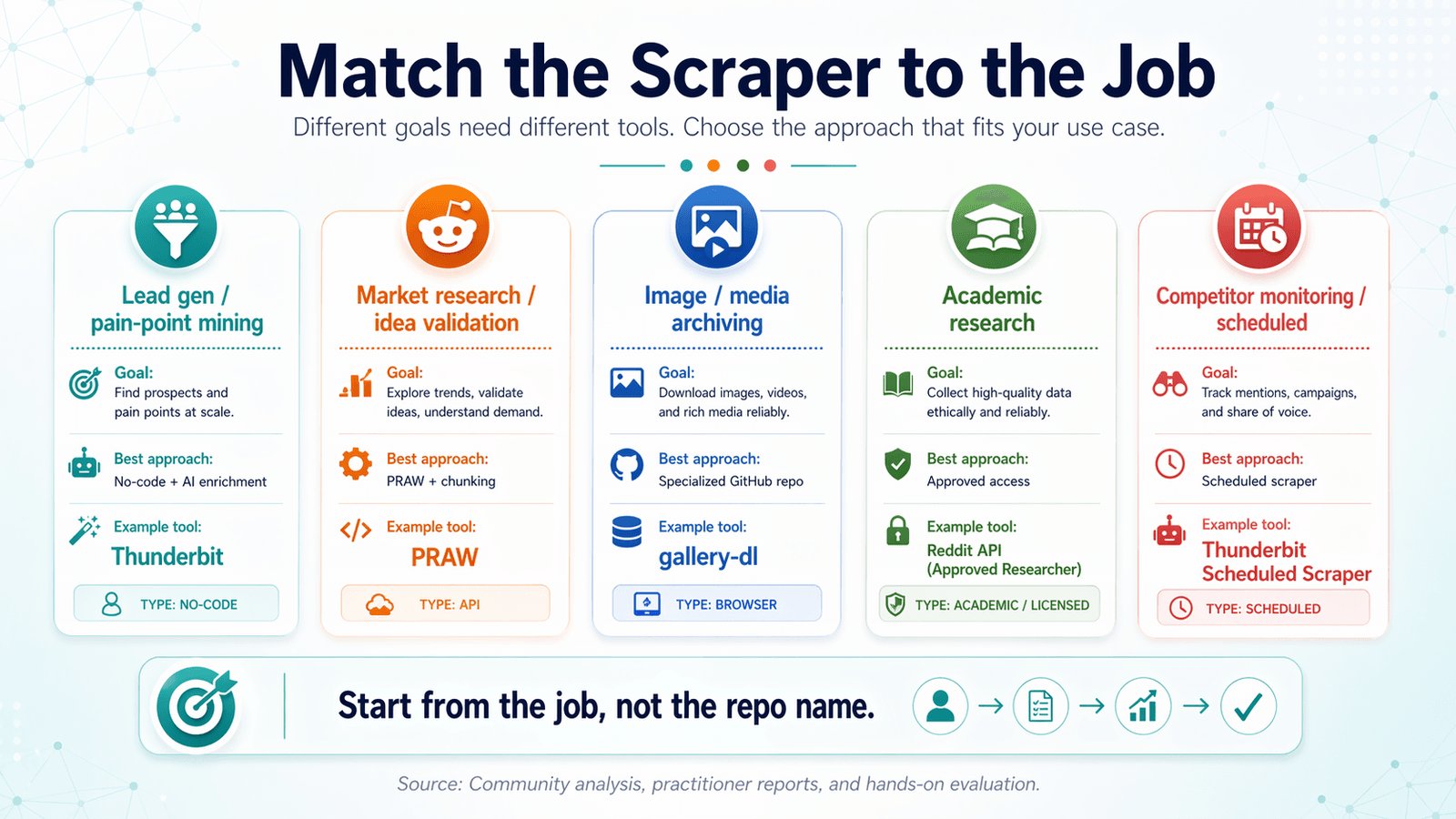
Sovita Reddit-scraper tehtävään: käyttötapaus-päätösmatriisi
Useimmat reddit scraper github -artikkelit järjestävät asiat työkalun mukaan. Se on väärä lähestymistapa.
Lähde liikkeelle tavoitteestasi ja päättele siitä oikea työkalu.
Liidien generointi ja kipupisteiden kartoitus
Mitä tarvitset: postaukset + kommentit avainsanaseulonnalla, tekoälytagit/-luokittelu, vienti CRM-valmiissa muodossa.
Paras lähestymistapa: no-code-scraper tekoälyrikastuksella.
Suositeltu työkalu: (tekoälyluokittelu + vienti Google Sheetsiin/Airtableen CRM-tuontia varten).
Esimerkkityönkulku: scrappaa subredditistä postaukset, joissa mainitaan tietty kipupiste. Käytä Thunderbitin Field AI Promptia tunnelman luokitteluun tai aiheiden taggaamiseen. Vie tiedot myyntitiimin Airtableen tai Google Sheetiin.
Markkinatutkimus ja idean validointi
Mitä tarvitset: suuren volyymin postausotsikot + pisteet, subreddit-tason trendidata.
Paras lähestymistapa: PRAW aikaväliin pilkkomisella volyymia varten tai Thunderbit nopeisiin poimintoihin.
Esimerkki: r/SaaS:n tai r/startupsin scrappaaminen trendiaiheiden ja ylä-äänikaavojen löytämiseksi viimeisten 90 päivän ajalta.
Kuvien ja median arkistointi
Mitä tarvitset: median URL-osoitteet, duplikaattien poisto, ajastetut ajot.
Paras lähestymistapa: erikoistunut GitHub-repo (esim. ) + cron-jobi.
Huom: duplikaattien poisto on tässä tärkeää — sama kuva postataan usein useisiin subredditeihin.
Akateeminen tutkimus ja historiallinen data
Mitä tarvitset: historiallista dataa, täydet kommenttipuut, suuret aineistot.
Paras lähestymistapa: hyväksytty akateeminen pääsy tai lisensoitu datakanava. Pushshift ei ole enää yleiskäyttöinen ratkaisu.
Todellisuustarkistus: tämä on vuoden 2026 vaikein käyttötapaus Pushshift-rajoitusten ja Redditin tiukentuneen datapolitiikan vuoksi.
Kilpailijaseuranta ja ajastettu scrapetus
Mitä tarvitset: toistuvat scrapit tietyin väliajoin, muutosten havaitseminen.
Paras lähestymistapa: Thunderbitin (kuvaile aikaväli suomeksi, syötä URL:t, napsauta Schedule) tai cron + skripti koodipohjaisille käyttäjille.
Käyttötapaus-päätösmatriisi
| Käyttötapaus | Mitä tarvitset | Paras lähestymistapa | Esimerkkityökalu |
|---|---|---|---|
| Liidien generointi / kipupisteiden kartoitus | Postaukset + kommentit, avainsanaseulonta, tekoälytagit | No-code-scraper + tekoälyrikastus | Thunderbit |
| Markkinatutkimus / idean validointi | Suuren volyymin postausotsikot + pisteet, subreddit-tason data | PRAW + aikaväliin pilkkominen tai Thunderbit | PRAW tai Thunderbit |
| Kuvien/median arkistointi | Median URL-osoitteet, duplikaattien poisto, ajastetut ajot | Erikoistunut GitHub-repo + cron | bulk-downloader-for-reddit |
| Akateeminen tutkimus | Historiallinen data, täydet kommenttipuut | Hyväksytty akateeminen pääsy tai Playwright | Pushshiftin akateeminen API (jos käytettävissä) |
| Kilpailijaseuranta / ajastettu | Toistuvat scrapit, muutosten havaitseminen | Scheduled Scraper | Thunderbit Scheduled Scraper tai cron + skripti |
Miten arvioit minkä tahansa Reddit Scraper GitHub -repon ennen kuin sitoudut siihen
Ennen kuin kloonaat repon ja aloitat debuggaamisen, aja tämä 5 minuutin terveystarkistus. Se säästää sinulta tunteja.
5 minuutin repon terveystarkistus
- Viimeisin commit-päivä. Jos siitä on yli 6 kuukautta, etene varoen. Redditin API-muutokset ovat usein.
- Avoimien ja suljettujen issueiden suhde. Suuri määrä vastaamattomia issueita on varoitusmerkki. Tarkista, mainitsevatko viimeaikaiset issueet auth-virheitä, 403-vastauksia tai Pushshiftin katkoja.
- LICENSE-tiedosto. Tarkista, onko sitä. Ei lisenssiä = juridisesti epäselvä (lisää tästä alla).
- Riippuvuudet. Ovatko vaaditut kirjastot ajan tasalla? Käyttääkö se vanhentuneita paketteja?
requirements.txt, jossa on paljon kiinnitettyjä vuoden 2022 versioita, on varoitusmerkki. - README:n laatu. Selittääkö se käyttöönoton selkeästi? Onko mukana esimerkkejä? Huono dokumentaatio = enemmän debuggausta sinulle.
- Tähdet vs. forkaukset vs. viimeaikainen toiminta. Paljon tähtiä mutta vähän viimeaikaista toimintaa voi tarkoittaa, että projekti oli suosittu, mutta on nyt hylätty. Vertaa tähtiä
pushed_at-päivämäärään.
Nopea esimerkki: lla on 364 tähteä — vaikuttaa ensi silmäyksellä uskottavalta. Mutta repo on arkistoitu ja README sanoo "THIS REPOSITORY IS STALE."
Tähdet eivät yksin kerro kaikkea.
Vinkkejä, joilla saat enemmän irti Reddit Scraper GitHub -asetuksestasi
Jos päätät mennä koodireittiä, tässä miten säästät hermojasi.
Käytä aina virtuaaliympäristöä
Virtuaaliympäristö pitää scraperin riippuvuudet erillään, jotta ne eivät törmää muihin Python-projekteihin. Yksi komento: python -m venv venv ja aktivoi se ennen kuin asennat mitään. Tämä on perushygieniaa, mutta olen nähnyt tarpeeksi GitHub-issueita otsikolla "module not found" tietääkseni, että toisto kannattaa.
Säilytä tunnistetiedot turvallisesti
Älä koskaan kovakoodaa Reddit API:n client ID:tä tai salaista avainta skriptiin. Käytä ympäristömuuttujia tai .env-tiedostoa ja lisää .env .gitignoreen. Jos pusket tunnisteet vahingossa GitHubiin, kierrätä ne heti — botit skannaavat paljastuneita API-avaimia.
Lokita kaikki
Lisää lokitus API-vastauksille, rate-limit-otsakkeille ja virheille. Kun jokin hajoaa, lokit ovat ero sen välillä, että "tiedän tarkalleen mitä tapahtui" ja "en tiedä miksi se pysähtyi".
Ajoita ja automatisoi harkiten
Jos ajat toistuvia scrapeja, käytä cronia (Linux/Mac) tai Task Scheduleriä (Windows) — mutta seuraa epäonnistumisia. Cron-jobi, joka epäonnistuu hiljaa kaksi viikkoa, on pahempi kuin ei automaatiota lainkaan.
Vaihtoehto: Thunderbitin antaa sinun kuvata aikavälin suomeksi ilman cron-syntaksia.
Reddit-scrappauksen juridiset ja eettiset parhaat käytännöt
Tämä ei ole heitetty vastuuvapauslauseke. Reddit on valvonut ehtojaan aggressiivisesti vuoden 2023 API-muutoksista lähtien, ja henkilötietojen scrappaamiseen liittyy todellista juridista riskiä.
Tässä se, millä oikeasti on merkitystä.
Redditin käyttöehdot: mitä ne oikeastaan sanovat
Redditin (päivitetty 31. maaliskuuta 2026 asti) kieltää nimenomaisesti pääsyn palveluihin, haun tai datan keräämisen automaattisin keinoin, ellei se ole sallittua ehtojen tai erillisen sopimuksen perusteella. ja lisäävät yksityiskohtia: Reddit voi valvoa ja auditoida kehittäjien käyttöä, muuttaa tai lopettaa pääsyn ja estää pääsyn pysyvästi liiallisen tai väärinkäyttävän käytön vuoksi. Kaupallinen käyttö edellyttää yleensä nimenomaista hyväksyntää.
Maaliskuun 2026 menee pidemmälle: hyväksyntä vaaditaan ennen Reddit-datan hakemista API:n kautta, hyväksymätön kaupallistaminen ja AI-/datankaivu-käyttö ovat kiellettyjä, ja valvontatoimia voivat olla tokenien peruutus, sovellusten tai tilien jäädytys sekä niihin liittyvien bottien tai domainien sulkeminen.
robots.txt:n noudattaminen
Redditin nykyinen on poikkeuksellisen rajoittava:
1User-agent: *
2Disallow: /Se on täysi kielto kaikille automatisoiduille user agent -ohjelmille. Se viittaa myös . Tämä on paljon tiukempi kuin sallivat robots.txt-mallit, joita jotkut kehittäjät yhä olettavat vanhojen web-scraping-normien perusteella.
Paras käytäntö: tarkista robots.txt aina ennen scrappausta, vaikka työkalusi ei pakottaisi sitä automaattisesti.
Henkilötiedot ja yksityisyys (GDPR/CCPA)
Jos scrappaat käyttäjänimiä, postaushistoriaa tai mitään henkilöön yhdistettävää tietoa, (EU) ja CCPA (Kalifornia) voivat soveltua. Paras käytäntö: anonymisoi tai aggregoi henkilötiedot ennen tallentamista. Älä rakenna yksittäisten käyttäjien profiileja ilman laillista perustetta.
GitHub-repon lisenssi: tarkista ennen kuin rakennat päälle
Monet reddit scraper github -repos käyttävät MIT- tai Apache-lisenssiä (sallivia), mutta osassa ei ole lainkaan lisenssitiedostoa — mikä juridisesti tarkoittaa "all rights reserved". Ennen kuin forkkaat, muokkaat tai rakennat repon päälle, tarkista aina LICENSE-tiedosto. Ei lisenssiä = juridisesti epäselvä, oli tähtiä kuinka paljon tahansa.
Valvonta on todellista vuosina 2025–2026
Redditin valvontatarina ei päättynyt vuonna 2023. Reddit teki vuonna 2025 valituksen Anthropicia vastaan väittäen luvattomasta Reddit-sisällön scrappauksesta/käytöstä, ja ajoi myös Reddit v. SerpApi -asiaa loppuvuonna 2025. Nämä ovat merkkejä siitä, että Reddit on valmis oikeudellisiin toimiin, ei vain teknisiin estoihin.
Oikean Reddit Scraper GitHub -lähestymistavan valitseminen vuonna 2026
Reddit scraper github -maisema on muuttunut rajusti vuodesta 2023. Useimmat repos ovat vanhentuneita. Rate limitit ja 1 000 postauksen katto ovat todellisia rajoitteita. Pushshift on poissa tavallisilta käyttäjiltä. Ja Redditin käytäntöpino on sekä selkeämpi että tiukemmin valvottu kuin koskaan.
Lyhyesti:
- PRAW on yhä luotettavin avoimen lähdekoodin perusta, jos voit hyväksyä Redditin API-rajoitukset ja haluat rakentaa omaa logiikkaa.
- Pushshift/PSAW ei ole enää yleiskäyttöinen ratkaisu.
- snscrapeen Reddit-moduuli on perintötyökalu ja epäluotettava.
- .json- ja julkisen päätepisteen scraperit ovat hauraita ja usein estettyjä vuonna 2026.
- Selaimeen perustuvat työkalut — olipa kyse Playwright-repoista tai no-code-vaihtoehdoista kuten — ovat käytännöllisin reitti monille käyttäjille, erityisesti ei-kehittäjille.
Lähde liikkeelle käyttötapauksesta, älä työkalusta. Aja 5 minuutin repon terveystarkistus ennen kuin sitoudut mihinkään GitHub-projektiin.
Ja jos haluat mieluummin ohittaa käyttöönoton ja aloittaa Redditin scrappaamisen minuuteissa, .
UKK
Mitkä ovat parhaat avoimen lähdekoodin Reddit-scraperit GitHubissa vuonna 2026?
on edelleen luotettavin API-wrapperi, ja sitä ylläpidetään aktiivisesti sekä dokumentaatio on hyvä. on uskottava, ylläpidetty PRAW:n päälle rakennettu CLI-työkalu. Playwright-pohjaiset scraperit toimivat ei-API-scrappaukseen, ja snscrapeen Reddit-moduuli toimii osittain mutta on suurelta osin ilman ylläpitoa. Tarkista aina viimeisin commit-päivä ja avoimet issuet ennen minkään repon käyttöä — suurin osa GitHubin on vanhentuneita.
Onko Redditin scrappaus laillista?
Julkisesti saatavilla olevan datan scrappaus sijoittuu juridisesti harmaalle alueelle, mutta Redditin omat ehdot ovat rajoittavat. , , , ja kaikki vastustavat luvattomaa massascrappausta. Scrapatun datan kaupallinen jälleenjakelu voi vaatia Redditin nimenomaista lupaa. Jos scrappaat henkilötietoja, GDPR ja CCPA voivat myös soveltua.
Miten pääsen Redditin API-rate limitien ohi?
Käytä eksponentiaalista takaisinkytkentää, seuraa X-Ratelimit-Remaining-otsakkeita ja harkitse aikaväliin pilkkomista toimiaksesi rajoissa. Selaimeen perustuva scraping (Playwright tai ) kiertää API-rate limitit, koska se scrappaa renderöityjä sivuja, mutta siihen liittyy omat huomionsa (sivun latausnopeus, bottiesto). Ei ole mitään taikatemppua, joka poistaisi rate limitit kokonaan — ne pakotetaan palvelinpuolella.
Voinko scrapata Redditiä ilman API-avainta?
Kyllä. Playwright-pohjaiset scraperit ja .json-URL-kikka eivät vaadi API-avaimia. ei myöskään vaadi API-avainta, koska se scrappaa selaimen kautta. Vaihtokaupat: .json-päätepisteitä estetään yhä useammin (403 monissa ympäristöissä huhtikuussa 2026), ja selainpohjainen scraping on hitaampaa ja resurssi-intensiivisempää kuin API-kutsut.
Mitä Pushshiftille tapahtui Reddit-scrappauksessa?
Pushshiftin julkinen API-pääsy poistettiin Redditin datalisenssimuutosten jälkeen, jotka alkoivat vuonna 2023. -wrapperi on arkistoitu ja vanhentunut. Rajoitettua akateemista pääsyä voi olla saatavilla hyväksyttyjen kanavien kautta, mutta useimmille "reddit scraper github" -hakijoille Pushshift ei ole enää käyttökelpoinen vaihtoehto. Jos tarvitset syvää historiallista Reddit-dataa, tutki Redditin hyväksymiä akateemisia tai lisensoituja datareittejä.
Lue lisää