
Jotkut keräilee postimerkkejä. Toiset taas lenkkareita. Mutta jos teet myyntiä, markkinointia, verkkokauppaa tai operaatioita vuonna 2025, sun “kokoelma” on todennäköisesti jotain vähän… digitaalisempaa: verkkodataa. Eikä mitään pientä näpertelyä – yritykset käyttävät verkkodatan keräämiseen keskimäärin 5 miljoonaa dollaria vuodessa, ja web-scraping on jo ihan peruskauraa lähes kaikissa tiimeissä strategiasta asiakaspalveluun ().
Kun kysyntä on lähtenyt kunnolla laukalle, kaksi nimeä pomppaa esiin melkein jokaisessa python scraper -oppaassa ja dataprojektissa: playwright ja selenium. Molemmat syntyivät selainten automaatiotyökaluiksi testausta varten, mutta nykyään ne on monelle se runko, jolla web muutetaan siistiksi, rakenteiseksi dataksi. Ja tässä se pointti: valinta ei ole mikään pikku tekninen makuasia, vaan käytännön päätös siitä, mikä työkalu palvelee parhaiten just sun web-scraping-tarpeita. Ja jos et ole kehittäjä – tai haluat tulokset nopeasti – on olemassa vielä helpompi reitti (vinkki: siihen ei kuulu yhtäkään Python-riviä). Puretaan homma auki.
Testaustyökaluista web-scrapingin työjuhdiksi: mitä Playwright ja Selenium ovat?
Aloitetaan taustasta. selenium on ollut kuvioissa jo vuodesta 2004 ja on selainten automaation “vanha kunnon luottotyökalu”. Se tehtiin alun perin QA-testaajille, ja sillä voi ohjata Chromea, Firefoxia ja jopa Internet Exploreria (jos kaipaat elämääsi pientä jännitystä). playwright taas tuli mukaan vuonna 2020 Microsoftin tukemana, modernimmalla otteella selainten automaatioon – ajattele sitä Seleniumin nuorempana ja nopeampana sisaruksena.
Molemmilla voi kirjoittaa skriptejä (usein Pythonilla), jotka avaavat selaimen, siirtyvät sivuille, klikkaavat nappeja, täyttävät lomakkeita ja – meille tärkeimpänä – poimivat dataa. Vaikka juuret on automaattisessa testauksessa, niistä on tullut web-scrapingin selkäranka kaikkeen hintaseurannasta liidien keruuseen (). Eikä tämä ole enää vain devien juttu: yhä useampi liiketoimintakäyttäjä yrittää rakentaa omia scrapaajia – tai vähintään testailee.
Mutta kun tavoitteena on datan keruu, prioriteetit muuttuu. Testikattavuus ei ole ykkönen, vaan datan luotettava saanti, blokkausten välttäminen ja se, ettei viikonloppu pala Python-virheiden metsästykseen. Tässä kohtaa Playwrightin ja Seleniumin erot alkaa oikeasti näkyä.
Keskeiset erot: Playwright vs. Selenium web-scrapingissa

Mennään suoraan ytimeen: sekä playwrightilla että seleniumilla voi scrapata sivustoja, mutta ne loistaa eri tilanteissa.
- selenium on konkari. Se toimii lähes kaikilla selaimilla ja monilla kielillä, yhteisö on valtava, ja se sopii hyvin vanhempien, staattisten sivujen scrapaamiseen, kun rakenne on ennustettava.
- playwright on moderni tulokas. Se on tehty tämän päivän dynaamisille, JavaScript-painotteisille sivustoille, ja siinä on valmiita työkaluja kirjautumisiin, pop-uppeihin, loputtomaan scrollaukseen ja muuhun. Se on myös nopeampi ja usein helpompi ottaa käyttöön, erityisesti Python-käyttäjille.
Mutta ei mennä pelkällä mutulla – katsotaan ominaisuudet rinnakkain.
Ominaisuuksien vertailu: Playwright vs. Selenium
| Ominaisuus | Selenium | Playwright |
|---|---|---|
| Kielituki | Python, Java, C#, JS, Ruby, ym. | Python, JS/TS, Java, C# |
| Selaintuki | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Käyttöönoton vaativuus | Vaatii selainajurin, manuaalista säätöä | Yksi komento asentaa kaiken |
| Nopeus/suorituskyky | Hitaampi, raskaampi resursseille | 40–50% nopeampi, async/rinnakkaisuus sisäänrakennettuna |
| Dynaamisen sisällön käsittely | Manuaaliset odotukset, enemmän koodia | Automaattiset odotukset, toimii hyvin JS-sivuilla |
| Botinesto/huomaamattomuus | Helpommin tunnistettavissa, vaatii lisäosia | Sisäänrakennettu stealth, jäljittelee käyttäjää paremmin |
| Debuggaustyökalut | Perustaso (Selenium IDE, kuvakaappaukset) | Inspector, videotallennus, codegen |
| Yhteisö ja tuki | Erittäin suuri ja kypsä, paljon ohjeita | Kasvaa nopeasti, modernit dokumentit, aktiivinen kehitys |
| Python-scraper-työnkulku | Enemmän asennusta ja boilerplatea | Sujuvampi, vähemmän koodia, helpompi aloittelijalle |
Oikea valinta: milloin Playwright ja milloin Selenium web-scrapingiin?
Kumpi kannattaa valita seuraavaan web-scraping-projektiin? Tässä mun näkemys vuosien automaatiotyön ja tiimien datatarpeiden pohjalta.
- selenium on hyvä valinta, jos:
- Scrapaamasi sivusto on “vanhan koulukunnan” – staattista HTML:ää, vähän JavaScriptiä, ei erikoisia pop-uppeja.
- Tarvitset tukea erikoisille selaimille (terveiset, Internet Explorer) tai integraatioita legacy-järjestelmiin.
- Haluat ison yhteisön turvan ja loputtomasti StackOverflow-vastauksia.
- Selenium on sinulle jo tuttu testausprojekteista.
- playwright kannattaa, jos:
- Sivusto on moderni, dynaaminen ja JavaScriptiä täynnä (verkkokaupat, some, tai mikä tahansa, joka saa läppärin tuulettimen huutamaan).
- Tarvitset kirjautumisen, välilehtien klikkailua, loputonta scrollausta tai pop-upien käsittelyä.
- Haluat päästä nopeasti liikkeelle – vähemmän asennusta ja vähemmän koodia.
- Olet kyllästynyt kirjoittamaan
time.sleep(5)joka paikkaan ja haluat työkalun hoitavan ajoituksen.
Yksinkertainen nyrkkisääntö: jos Seleniumilla ensimmäinen yritys on täynnä “miksi tämä ei lataudu?” -hetkiä, on yleensä aika kokeilla Playwrightia.
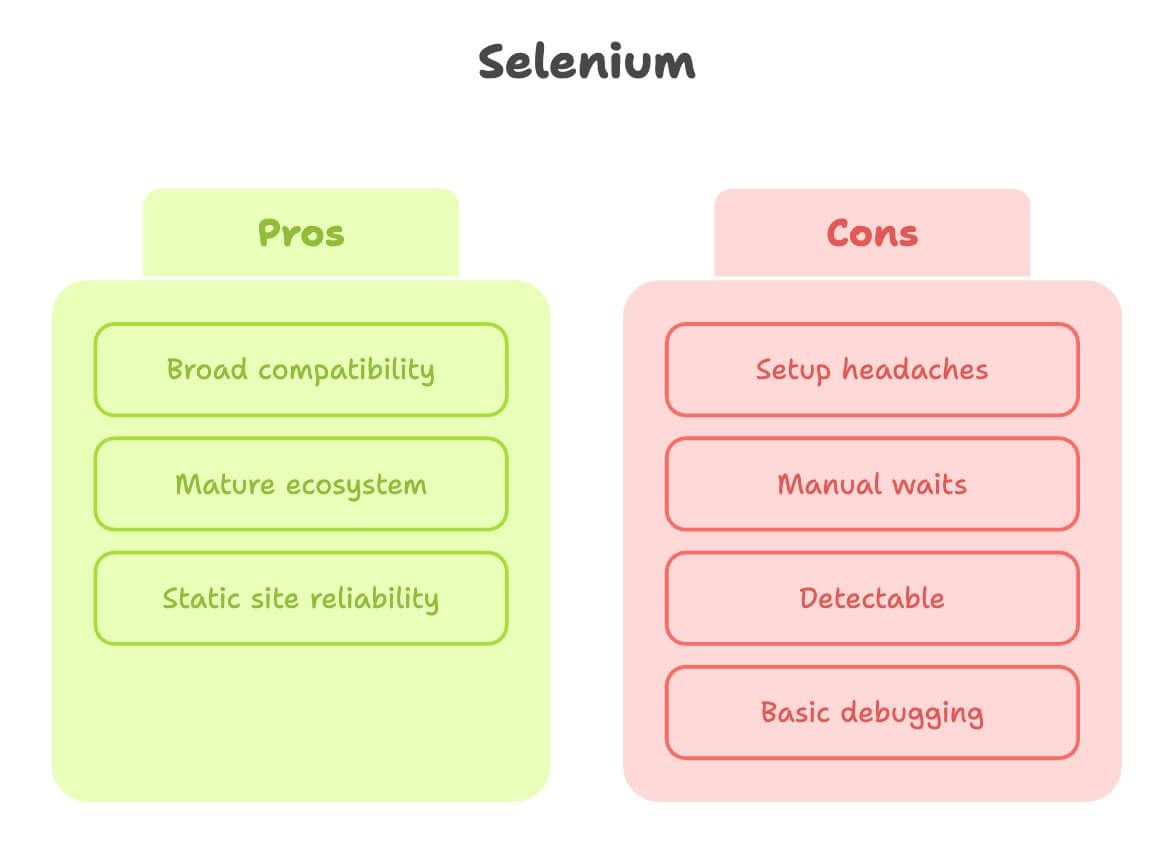
Selenium web-scrapingissa: vahvuudet ja rajoitteet
Annetaan Seleniumille ansaittu kunnia. Se on selainten automaation klassikko, ja monissa scraping-töissä se toimii oikein hyvin.
Vahvuudet:
- Laaja yhteensopivuus: Toimii lähes kaikilla selaimilla ja monilla ohjelmointikielillä.
- Kypsä ekosysteemi: Paljon oppaita, Q&A:ta ja lisäosia.
- Erinomainen staattisille sivuille: Kun sivu ei muutu paljoa, Selenium on todella vakaa.
Rajoitteet:
- Asennusvaiva: Sinun pitää ladata ja konfiguroida selainajuri (kuten ChromeDriver) ja pitää se ajan tasalla. Aloittelijat jumittuvat usein tähän ().
- Manuaaliset odotukset: Dynaaminen sisältö tarkoittaa paljon eksplisiittisiä odotuksia – tai pahimmillaan satunnaisia sleeppejä.
- Helpompi tunnistaa: Monet sivustot tunnistavat Selenium-ohjatun selaimen ja blokkaavat, etenkin pilvipalvelimilla.
- Debuggaus on perustasoa: Ei sisäänrakennettua videotallennusta tai interaktiivista inspectoria.
Yhteenveto: Selenium on loistava yksinkertaisille ja vakaille sivuille – mutta modernien, interaktiivisten sivujen kanssa se voi tuntua kivireen vetämiseltä ylämäkeen.
Playwright web-scrapingissa: vahvuudet ja rajoitteet
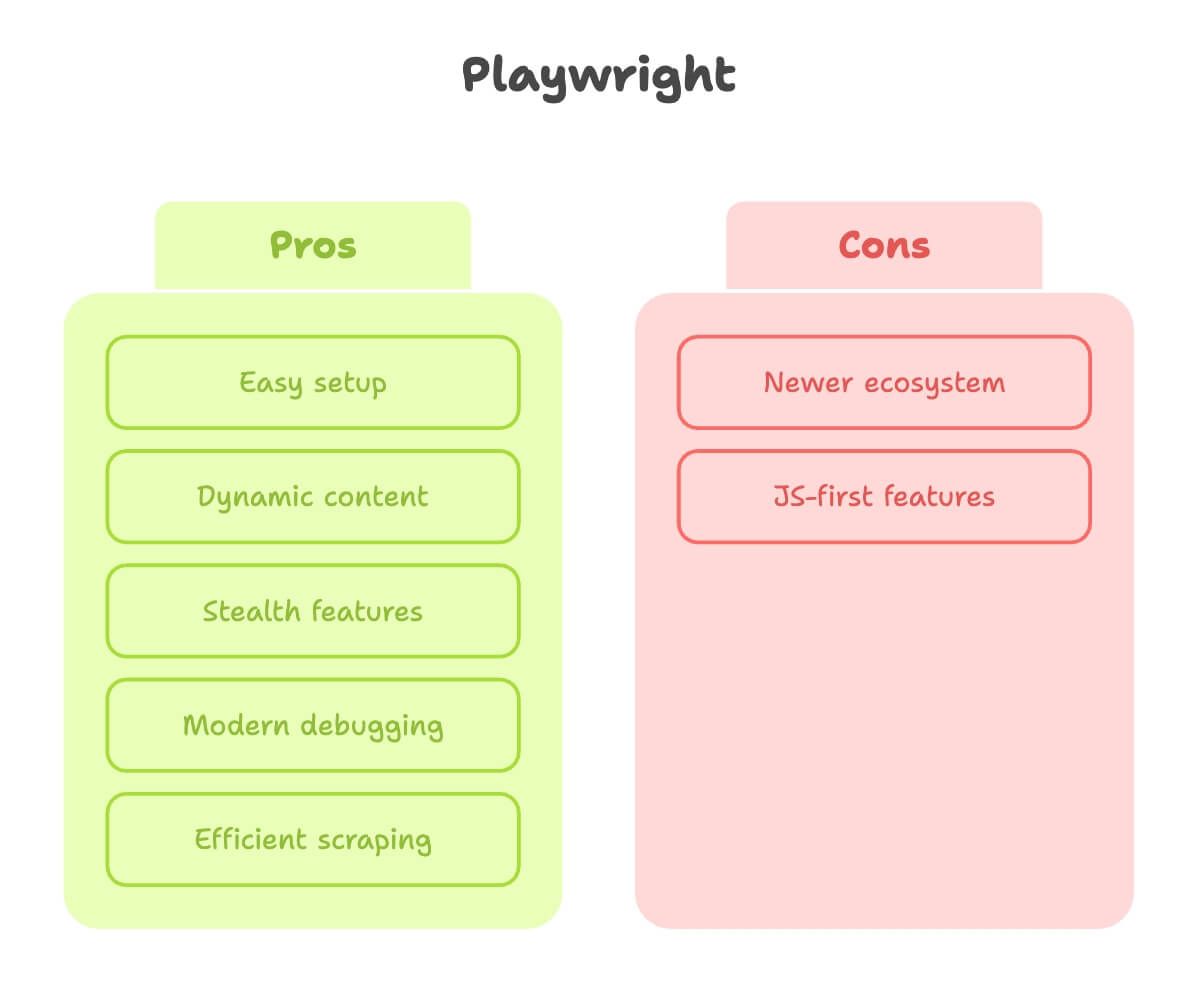
Sitten playwright. Kun on käyttänyt molempia, Playwright tuntuu siltä kuin se olisi tehty ihmisille, jotka on oikeasti kärsineet web-scrapingin parissa.
Vahvuudet:
- Helppo käyttöönotto: Yksi pip-asennus, yksi komento, ja homma toimii. Ei ajurirumbaa.
- Dynaamisen sisällön tuki: Odottaa elementtejä automaattisesti, joten sinun ei tarvitse arvailla, milloin sivu on valmis ().
- Stealth-ominaisuudet: Jäljittelee oikeaa käyttäjää paremmin, tukee useita konteksteja (hyvä, kun scrapaataan useana “käyttäjänä” yhtä aikaa).
- Moderni debuggaus: Inspector, videotallennus ja jopa koodin generointi manuaalisista klikkauksista.
- Nopeampi ja tehokkaampi: Erityisesti, kun scrapaataan paljon sivuja tai ajetaan rinnakkain.
Rajoitteet:
- Uudempi ekosysteemi: Oppaita on hieman vähemmän, vaikka ero kaventuu nopeasti.
- Osa ominaisuuksista on JS-edellä: Suurin osa toimii Pythonilla, mutta joskus dokumentaatio on parempi JavaScript-puolella.
Lopputulos: Playwright on oma ykkösvalintani, kun sivusto on edes vähän dynaaminen tai kun haluan tulokset nopeasti ilman asennus- ja säätötaistelua.
Botineston kiertäminen: kumpi Python-scraper pärjää paremmin moderneilla sivustoilla?
Puhutaan siitä, mihin tämä usein lopulta kaatuu: blokatuiksi tulemisesta. web-scrapingissa vaikeinta ei monesti ole koodi, vaan se, ettei sivusto lyö ovea kiinni.
- selenium: Oletuksena helpompi tunnistaa. Sivustot näkee
webdriver-lipun, headless-user agentit ja muut tunnusmerkit. Kiertokeinoja on (kuten undetected-chromedriver), mutta ne vaatii lisäsäätöä ja on jatkuvasti askeleen jäljessä botintorjuntaa (). - playwright: Sisältää valmiita stealth-ominaisuuksia, kuten automaation sormenjälkien piilottamista, useita selainkonteksteja ja käyttäjämäisempiä odotuksia. Ei taikuutta, mutta usein vähemmän blokkeja heti alussa.
Rehellinen totuus: kumpikaan ei ole täysin immuuni. Jos scrapaaminen on “korkean panoksen” hommaa (esim. sneaker-dropit tai lipunmyyntisivut), tarvitset silti proxyt, IP-kierron ja mahdollisesti CAPTCHA-ratkaisut. Playwright tekee siitä vain vähän vähemmän tuskaista.
Kehittäjäkokemus: asennus, oppimiskynnys ja debuggaus
Miltä aloittaminen oikeasti tuntuu – etenkin, jos olet aloittelija tai haluat vain saada työn valmiiksi ilman Python-tohtorintutkintoa?
- selenium:
- Asennus: Asenna Python, asenna Selenium, lataa oikea selainajuri, lisää PATHiin, ja toivo että versiot osuvat kohdilleen. (Useampi jumittuu ajuriin kuin itse scrapaamiseen.)
- Oppimiskynnys: Materiaalia on paljon, mutta mukana on myös legacy-koodia ja vanhentuneita ohjeita.
- Debuggaus: Paljolti printtejä ja kuvakaappauksia. Selenium IDE on olemassa, mutta se on melko perus.
- playwright:
- Asennus:
pip install playwright, sittenplaywright install. Valmista. - Oppimiskynnys: Modernit dokumentit, paljon esimerkkejä, ja API tuntuu “inhimillisemmältä” – elementtejä voi hakea tekstin, roolin tai placeholderin perusteella.
- Debuggaus: Inspectorilla voit käydä skriptin läpi vaiheittain, seurata selainta ja tallentaa videoita scraping-ajoista ().
- Asennus:
Jos haluat nähdä tuloksia nopeasti ja käyttää vähemmän aikaa asennukseen ja vianhakuun, Playwright vie selvästi voiton. Selenium on hyvä, jos sen koukerot ovat jo tuttuja tai tarvitset sen laajaa yhteensopivuutta.
Vaihe vaiheelta: ensimmäinen Python web-scraper Playwrightilla tai Seleniumilla
Käydään läpi, miltä scrapaajan rakentaminen näyttää kummallakin – ilman koodia, pelkät vaiheet.
Playwright (Python):
- Asenna Playwright ja selaimet:
pip install playwright+playwright install - Käynnistä selain: Avaa Chromium, Firefox tai WebKit (headless tai näkyvänä).
- Siirry sivulle:
page.goto("<https://example.com>") - Odota sisältöä: Playwright odottaa elementtejä automaattisesti.
- Poimi data: Käytä “ihmisystävällisiä” selektoreita (kuten
get_by_text,locator("span.price")). - Hoida sivutus tai alasivut: Kierrä sivuja tai klikkaa linkkejä – Playwrightilla rinnakkaisajo on helppoa.
- Vie data: Tallenna CSV:ksi, Exceliin tai tietokantaan.
- Debuggaa: Käytä Inspectoria tai videotallennusta, jos jokin menee pieleen.
Selenium (Python):
- Asenna Selenium:
pip install selenium - Lataa selainajuri: (esim. ChromeDriver Chromelle) ja lisää PATHiin.
- Käynnistä selain: Avaa Chrome, Firefox tai muu selain.
- Siirry sivulle:
driver.get("<https://example.com>") - Odota sisältöä: Lisää manuaaliset odotukset (
WebDriverWait) tai “onnea matkaan” -tyylillätime.sleep. - Poimi data:
find_elementtaifind_elements(CSS/XPath-selektorit). - Hoida sivutus tai alasivut: Kierrä URL:eja tai klikkaa nappeja, mutta ajoitus ja navigointi jäävät pitkälti sinun vastuullesi.
- Vie data: Tallenna CSV:ksi, Exceliin tai tietokantaan.
- Debuggaa: Enimmäkseen käsin – seuraa selainta, tulosta HTML:ää tai ota kuvakaappauksia.
Huomaatko eron? Playwright on modernien sivujen kanssa selvästi “plug and play” -henkisempi.
Koodin tuolle puolen: no-code web-scraping Thunderbit AI Web Scraperilla
Ollaan rehellisiä: kaikki ei halua ryhtyä Python-velhoksi vain saadakseen taulukon tuotehinnoista tai listan liideistä. Ehkä olet myynnissä, markkinoinnissa, kiinteistöalalla tai operaatioissa ja haluat datan – heti. Tässä kohtaa astuu mukaan.
Thunderbitin perustajana olen nähnyt läheltä, miten moni liiketoimintakäyttäjä haluaa skipata koodauksen ja mennä suoraan asiaan. Siksi rakensimme , jolla voit scrapata lähes minkä tahansa sivuston kahdella klikkauksella – ei Pythonia, ei ajureita, ei debuggausta.
Näin Thunderbit toimii
- Avaa sivusto, josta haluat kerätä dataa.
- Klikkaa “AI Suggest Fields”. Thunderbitin tekoäly analysoi sivun ja ehdottaa kenttiä (kuten tuotteen nimi, hinta, kuva, arvosana).
- Klikkaa “Scrape”. Saat heti rakenteisen datataulukon.
- Vie Exceliin, Google Sheetsiä, Airtableen, Notioniin, CSV:ksi tai JSONiksi. Valmista.
Ei selektorien säätöä, ei yritystä ja erehdystä, ei koodia. Yhtä helppoa kuin noutoruoan tilaaminen (ja rehellisesti usein nopeampaa kuin ruoan odottelu).
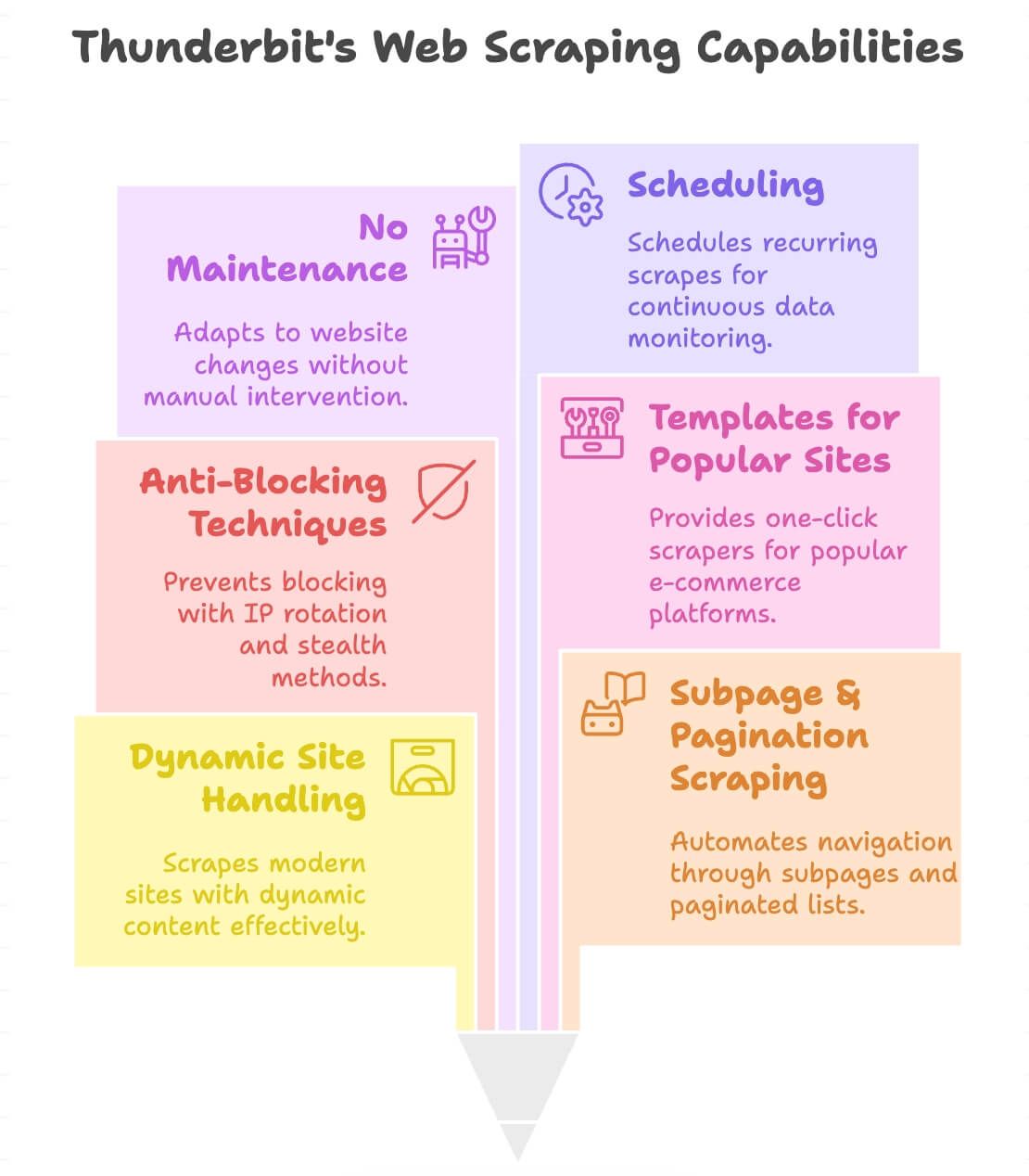
Mikä tekee Thunderbitistä erilaisen?
- Toimii dynaamisilla sivuilla: Scrapaa modernit verkkokaupat, hakemistot ja myös sivut, joissa on loputon scrollaus tai pop-uppeja.
- Alasivut ja sivutus: Klikkaa automaattisesti tuotesivuille tai sivutettuihin listoihin ja kerää kaiken tarvittavan.
- Sisäänrakennettu blokkausten vähennys: Taustalla IP-kierto ja stealth-tekniikat, jolloin blokkausriski pienenee.
- Valmiit mallit suosittuihin sivustoihin: Yhden klikkauksen scrapaajat Amazonille, eBaylle, Shopifylle, Zillow’lle ja muille ().
- Ei ylläpitoa: Jos sivusto muuttuu, Thunderbitin tekoäly mukautuu – scrapaajaa ei tarvitse kirjoittaa uusiksi.
- Ajastus: Aseta toistuvat ajot jatkuvaan seurantaan (esim. päivittäiset hintatarkistukset).
- Tukee 34 kieltä: Scrapaa ja käännä dataa lähes mistä tahansa.
Ja paras osa: sun ei tarvitse tietää mitään HTML:stä, CSS:stä tai Pythonista. Jos osaat käyttää selainta, osaat käyttää Thunderbitia.
Mikä web-scraping-ratkaisu sopii sinulle?
Lopuksi nopea päätösopas:
| Tilanteesi | Paras työkalu |
|---|---|
| Scrapaus staattiselta, yksinkertaiselta sivulta; asennus ei haittaa | Selenium |
| Scrapaus modernilta, dynaamiselta sivulta; haluat tulokset nopeasti | Playwright |
| Tarvitset tukea legacy-selaimille tai -kielille | Selenium |
| Haluat helpon asennuksen, modernin debuggaamisen ja vähemmän koodia | Playwright |
| Et ole kehittäjä; haluat datan heti, ilman koodia ja asennusta | Thunderbit |
| Tarvitset useiden sivujen/alasivujen scrapausta tai ajastuksia | Thunderbit |
| Haluat viedä suoraan Exceliin, Sheetsiä, Notioniin, Airtableen | Thunderbit |
| Inhoat Python-virheiden debuggaamista | Thunderbit |
Jos olet kehittäjä tai tykkäät koodin näpertelystä, Playwright ja Selenium on molemmat tehokkaita. Mutta jos tavoite on saada data taulukkoon mahdollisimman nopeasti, Thunderbit säästää helposti tunteja – jopa päiviä.
Yhteenveto: nopea ja luotettava web-scraping – omalla tyylilläsi
web-scrapingista on tullut valtavirtaa, eikä syyttä: yritykset tarvitsee dataa pärjätäkseen – ja mieluiten heti. playwright ja selenium on kasvanut vaatimattomista testityökaluista tärkeiksi scraping-kehyksiksi, joilla on omat vahvuutensa. Selenium on varma valinta staattisille sivuille ja legacy-ympäristöihin; Playwright on moderni ja nopea vaihtoehto dynaamisille, interaktiivisille sivuille.
Mutta tässä mun rehellinen neuvo vuosien SaaS-, automaatio- ja AI-kokemuksella: jos et tee tätä koodauksen ilosta, älä tuhlaa aikaa ajureihin, selektoreihin ja botineston kikkailuun. siirryt “tarvitsen tämän datan” -tilasta “tässä on Excel-tiedosto” -tilaan minuuteissa – ei päivissä.
Olitpa Python-ammattilainen tai liiketoimintakäyttäjä, joka haluaa vain tulokset, löytyy ratkaisu, joka sopii sun tarpeisiin – ja kärsivällisyyteen. Testaa, mikä istuu omaan työnkulkuun, ja muista: paras scrapaaja on se, joka toimittaa tarvitsemasi datan mahdollisimman vähällä vaivalla.
Ja jos joskus huomaat debuggaavasi Selenium-ajurivirhettä kello 02:00, muista – Thunderbit on yhä täällä, valmiina scrapaamaan kahdella klikkauksella.
Haluatko oppia lisää no-code-scrapingista, tekoälypohjaisesta datan poiminnasta ja siitä, miten Thunderbit voi auttaa tiimiäsi? Tutustu tai aloita käyttö jo tänään.
P.S. Jos et vieläkään ole varma, mitä työkalua käyttää, tai haluat nähdä Thunderbitin käytännössä, piipahda demoja, vinkkejä ja satunnaista web-scraping-huumoria varten. (Kyllä, meillä on niitä.)
Lisälukemista: