

Muutama viikko sitten myyntitiimimme kollega kysyi minulta kysymyksen, jota kuulen jatkuvasti: "Voimmeko kerätä liidejä tästä julkisesta yrityshakemistosta vai haastetaanko meidät oikeuteen?" Hän oli löytänyt kultasuonen potentiaalista dataa suoraan avoimesta verkosta — ei kirjautumista, ei maksumuuria — mutta nopea Google-haku sai hänet vakuuttuneeksi siitä, että hän voisi päätyä rautoihin.
Tällaista huolta on joka puolella. Automatisoitu liikenne muodostaa nykyään arviolta 51 % kaikesta verkkoliikenteestä, web scraping -ohjelmistojen markkinan ennustetaan kasvavan noin 1,08 miljardista dollarista vuonna 2025 3,59 miljardiin dollariin vuoteen 2031 mennessä, ja silti suurin osa verkossa kiertävästä oikeudellisesta neuvonnasta on joko vanhentunutta, liian yksinkertaistettua tai suoraan väärää. Entä vuoden 2022 hiQ v. LinkedIn -tapaus? Lähes jokaisessa artikkelissa sitä käsitellään kuin korkeimman oikeuden ratkaisua, jonka mukaan "kaikki scraping on laillista." (Spoileri: ei ole, eikä se ollut sitä.)
Samaan aikaan vuoden 2024 ja 2025 suuret tapaukset — joissa osapuolina ovat olleet X (entinen Twitter), Meta, Reddit, Google ja AI-yritykset — muokkaavat sääntöjä parhaillaan, eikä juuri kukaan raportoi niistä. Tämä opas kertoo, mitä Yhdysvaltain laki todella sanoo web scrapingista vuonna 2026, erottaa myytit todellisuudesta ja antaa sinulle käytännöllisen rungon sen arviointiin, mitä voit tehdä ja mitä et.

Mitä web scraping on (ja miksi yritykset välittävät siitä)?
Web scraping tarkoittaa automaattisen ohjelmiston käyttöä tiedon keräämiseen verkkosivuilta ja sen järjestämistä jäsenneltyyn muotoon — esimerkiksi taulukoiksi, tietokannoiksi tai CRM-tietueiksi.
Tarkemmin sanottuna scraper käy verkkosivuilla, lukee niiden taustalla olevan HTML:n ja poimii sieltä tietyt tietopisteet — hinnat, nimet, osoitteet, tuotetiedot, mitä ikinä tarvitsetkin — siisteiksi riveiksi ja sarakkeiksi. Se on digitaalinen vastine sille, että palkkaisit jonkun kopioimaan tietoja verkkosivulta Exceliin, paitsi että botti tekee sen minuuttien sijaan sekunneissa.
Web scraping ei ole hakkerointia. Se käsittelee samaa tietoa, jonka kuka tahansa kävijä näkisi selaimessaan.
Eikä se ole mikään kapea kehittäjien temppu. Hakukoneet, hintavertailusivustot, kiinteistöalustat, markkinatutkimuksen hallintapaneelit ja AI-pohjaiset työkalut kaikki nojaavat web crawlingiin ja scrapingiin toimiakseen. Jos olet joskus käyttänyt Googlea, tarkistanut lentojen vertailupalvelua tai selannut Zillow’ta, olet hyötynyt scrapingista.
Yleisimmät liiketoiminnan käyttötapaukset, joihin törmään:
- Liidien hankinta: Yrityshakemistoista poimitaan yritysten nimiä, verkkosivuja, työnimikkeitä tai julkisia yhteystietoja.
- Kilpailijoiden hintaseuranta: Verkkokauppatiimit seuraavat kilpailijoiden SKU-hintoja, saatavuutta ja toimitustietoja.
- Kiinteistöanalytiikka: Julkisten kohdeilmoitusten, hintojen ja markkinatrendien kokoaminen yhteen.
- Tuotetutkimus: Tuotetietojen, arvosanojen, saatavuuden ja kategorioiden poimiminen vähittäiskaupan sivustoilta.
- Markkina-analytiikka: Työpaikkailmoitusten, myymäläavausten, uutisvihjeiden tai julkisten taloustietojen seuraaminen.
Itse tekniikka on neutraali. Oikeudellinen arvio riippuu siitä, miten dataan pääset käsiksi ja mitä teet sillä sen jälkeen.
Onko web scraping laillista Yhdysvalloissa? Lyhyt vastaus
Yhdysvalloissa ei ole liittovaltion lakia, joka kieltäisi web scrapingin suoraan. Julkisesti saatavilla olevan datan kerääminen on yleensä sallittua.
Mutta — ja tämä on iso mutta — laillisuus riippuu useista tekijöistä: datan tyypistä, siitä miten siihen pääset käsiksi, hyväksyitkö käyttöehdot, sisältyykö dataan henkilötietoja ja mitä aiot tehdä sillä.
Suurin hämmennyksen lähde foorumeilla, Reddit-ketjuissa ja jopa laki-blogeissa? Ihmiset sekoittavat käsitteet "laiton" ja "verkkosivun käyttöehtojen vastainen." Nämä ovat hyvin eri asioita. Verkkosivun sääntöjen rikkominen voi johtaa IP-estoon tai tilin sulkemiseen. Liittovaltion lain rikkominen voi johtaa oikeusjuttuun tai harvinaisissa tapauksissa rikossyytteeseen. Useimmat scrapingista seuraavat ongelmat ovat selvästi siviilioikeudellisia.
Loppuosa tästä artikkelista purkaa auki keskeiset lait, merkittävät oikeustapaukset (mukaan lukien vuoden 2024 ja 2025 tapaukset, joista melkein kukaan ei puhu) sekä käytännöllisen päätösmallin, jota voit oikeasti käyttää.
Kolme erilaista "laittoman" muotoa: rikosoikeudellinen, siviilioikeudellinen ja käyttöehtorikkomus
On aika oikaista web scraping -lain suurin väärinkäsitys. Kun joku kysyy "onko web scraping laitonta?", hän niputtaa yleensä yhteen kolme täysin erilaista riskiluokkaa. Niiden erottaminen muuttaa koko keskustelun.

| Vastuun tyyppi | Mikä sen laukaisee | Mahdollinen seuraamus | Vakavuus |
|---|---|---|---|
| Rikosoikeudellinen (CFAA) | Datasta käsiksi pääsy autentikointisuojan takana ilman lupaa, petos, tunnistetietojen väärinkäyttö | Liittovaltion syyte, sakot, vankeus | 🔴 Vakava — mutta tavallisessa yritysscrapingissa erittäin harvinainen |
| Siviilioikeudellinen kanne | Tekijänoikeusrikkomus, irtaimeen kohdistuva luvaton tunkeutuminen, sopimusrikkomus, liikesalaisuuden väärinkäyttö, yksityisyysrikkomukset | Rahalliset vahingonkorvaukset, kieltotuomio, datan poistaminen | 🟡 Merkittävä |
| Käyttöehtorikkomus | Browsewrap- tai clickwrap-käyttöehtojen rikkominen | Tilin päättäminen, IP-esto, cease-and-desist, mahdollinen siviilikanne | 🟢 Matala–kohtalainen |
Oikeusministeriön vuoden 2022 CFAA-syytepolitiikka toteaa nimenomaisesti, että tavalliset käyttöehtorikkomukset — kuten valeprofiilin luominen tai verkkosivun sääntöjen rikkominen — eivät yksinään riitä liittovaltion rikossyytteeseen. Tämä on merkittävää.
Käytännön johtopäätös: jos olet myyntitiimi, joka kerää julkisia yrityslistauksia, tai verkkokauppatiimi, joka seuraa kilpailijoiden hintoja, kyse on lähes varmasti siviilioikeudellisen riskin hallinnasta, ei rikosoikeudellisesta vaarasta. Se ei tarkoita, että sääntöjä voi sivuuttaa, mutta sen pitäisi rauhoittaa hermoja.
Keskeiset Yhdysvaltain lait, jotka koskevat web scrapingia
Yhdysvalloissa web scrapingiin kytkeytyy neljä oikeudellista peruspilaria, ja kukin niistä käsittelee eri osaa kokonaisuudesta.
Computer Fraud and Abuse Act (CFAA)
CFAA (18 U.S.C. § 1030) kirjoitettiin alun perin tietokonehakkeroinnin torjumiseksi. Vuosien varrella siitä tuli scraping-kanteiden vakiolaki, yleensä perustuen väitteeseen, että scraper pääsi verkkosivulle "ilman lupaa."
Sitten tuli Van Buren v. United States. Korkein oikeus totesi, että henkilö "ylittää valtuutetun pääsyn" CFAA:n tarkoittamalla tavalla vain silloin, kun hän käyttää tietokoneen alueita — tiedostoja, kansioita, tietokantoja — joihin hänellä ei ole oikeutta. Pelkkä sen tiedon väärinkäyttö, jonka näkemiseen on muuten lupa, ei riitä.
Scrapingiin liittyvät vaikutukset:
- Pienempi CFAA-riski: Julkiset verkkosivut, jotka ovat kaikkien saavutettavissa ilman kirjautumista. Ei porttia, ei ongelmaa "luvattomasta pääsystä".
- Suurempi CFAA-riski: Data kirjautumisen, maksumuurin, pääsytunnisteiden, istunnon manipuloinnin tai peruutetun käyttöoikeuden takana.
hiQ v. LinkedIn -tapaus (jota puretaan tarkemmin alla) vahvisti tämän julkisen datan osalta. Mutta CFAA on vain yksi osa kokonaisuutta.
Tekijänoikeuslaki ja DMCA
Yhdysvaltain tekijänoikeuslaki suojaa alkuperäistä luovaa ilmaisua — artikkeleita, valokuvia, videoita, luovia tuotekuvauksia — mutta ei raakaa faktaa. Korkeimman oikeuden Feist-ratkaisu on tässä merkkitapaus: faktat kuten nimet, osoitteet ja puhelinnumerot eivät ole tekijänoikeudella suojattavia, vaikka niiden kokoamiseen olisi käytetty paljon työtä.
Scrapatun datan riskitasot:
| Mitä poimit | Tekijänoikeusriski | Miksi |
|---|---|---|
| Hinnat, tuotenimet, osoitteet, päivämäärät, tekniset tiedot | Pienempi | Nämä ovat faktoja |
| Kokonaiset artikkelit, valokuvat, videot, luovat arviot | Suurempi | Nämä ovat ilmaisullisia teoksia |
| Kuratoidut tietokannat, rankingit, toimitukselliset taksonomiat | Keskisuuri–korkea | Valinta ja järjestely voivat olla suojattuja |
| Maksumuurin tai DRM:n suojaama sisältö | Korkea | Tekijänoikeus + pääsynhallintaongelmat |
DMCA:n kiertämisen kielto (17 U.S.C. § 1201) lisää vielä yhden tason: teknisten suojausten kiertäminen (maksumuurit, DRM, tietyt bottisuojausjärjestelmät) tekijänoikeudella suojatun sisällön saamiseksi voi synnyttää vastuun, vaikka et kopioisi itse sisältöä lainkaan. Tätä testataan aggressiivisesti vuosien 2025–2026 tapauksissa, mukaan lukien Google v. SerpApi, jossa Google väittää DMCA-rikkomuksia SearchGuard-bottisuojansa kiertämisestä.
Myös fair use on tärkeä — transformatiivinen käyttö (datan analysointi, kokoaminen tai sen päälle rakentaminen sen sijaan, että sen vain julkaisee uudelleen) on yleensä turvallisempaa kuin jonkun toisen sisällön kopiointi ja uudelleenjulkaisu.
Sopimusoikeus: käyttöehdot (browsewrap vs. clickwrap)
Monet verkkosivut sisällyttävät käyttöehtoihinsa scrapingin vastaisia ehtoja — mutta niiden täytäntöönpanokelpoisuus riippuu täysin siitä, miten kohtasit nämä ehdot.
| Sopimustyyppi | Täytäntöönpanokelpoisuus | Mitä se tarkoittaa scrapereille |
|---|---|---|
| Clickwrap (klikkaat "Hyväksyn") | Vahva | Tuomioistuimet panevat nämä johdonmukaisesti täytäntöön. Scrapingin vastaiset ehdot voivat tukea siviilikanteita. |
| Sign-in wrap (ilmoitus kirjautumisen lähellä) | Tapauskohtainen | Riippuu siitä, kuinka näkyvä ilmoitus oli. |
| Browsewrap (linkki alatunnisteessa) | Heikompi | Tuomioistuimet suhtautuvat epäillen, jos käyttäjällä ei ollut todellista tietoa ehdoista. |
| Tili-/API-ehdot | Vahvempi | Sisäänkirjautuneena tehty scraping tai API:n väärinkäyttö on selvästi riskialttiimpaa. |
Meta v. Bright Data -tapauksessa (2024) oikeus katsoi, etteivät Metan ehdot kattaneet uloskirjautuneena tehtyä julkista scrapingia sillä tavalla kuin Meta väitti — eikä Bright Dataa ollut osoitettu käyttäneen kirjautuneita tilejä kyseiseen julkiseen scrapingiin. Se on olennainen ero.
Käytännön neuvo: jos et ole koskaan kirjautunut sisään, et ole koskaan klikannut "Hyväksyn" ja keräät vain julkisia sivuja, browsewrap-rajoituksia on verkkosivun vaikeampi panna sinua vastaan täytäntöön. Tarkista kuitenkin käyttöehdot aina ennen scrapingia, erityisesti jos olet luonut tilin.
Yhdysvaltain osavaltioiden tietosuojalait (CCPA ja muut)
Jos keräämäsi data sisältää henkilötietoja — nimiä, sähköposteja, puhelinnumeroita, sijaintitietoja — osavaltioiden tietosuojalait voivat tulla sovellettaviksi. Ja tämä sääntelyverkko kasvaa nopeasti. IAPP laski 19 voimaan tullutta kattavaa osavaltioiden tietosuojalak ia vuoden 2025 puoliväliin mennessä, ja MultiState raportoi 20 osavaltiosta, joissa kattavat tietosuojalait olivat voimassa vuonna 2026.
Useimmissa näistä laeista on poikkeuksia "julkisesti saatavilla olevalle" henkilötiedolle, mutta määritelmät vaihtelevat. Lisäksi jatkokäyttö — kuten datan myyminen, jakaminen tai profilointi — voi silti synnyttää velvoitteita, vaikka alkuperäinen keruu olisi vapautettu.
| Osavaltion laki | Voimaantulo | Kattaako scrapatun PII:n? | Opt-out-vaatimus | Sakkotaso |
|---|---|---|---|---|
| CCPA/CPRA (Kalifornia) | 2020/2023 | Kyllä | Myynnin/jakamisen opt-out; GPC tunnustetaan | $2,663–$7,988/rikkomus (2025 tarkistus) |
| CPA (Colorado) | 2023 | Kyllä | Yleinen opt-out/GPC heinäkuusta 2024 | Siviilioikeudelliset seuraamukset harhaanjohtavaa liiketoimintaa koskevan sääntelyn puitteissa |
| CTDPA (Connecticut) | 2023 | Kyllä | OOPS/GPC tammikuusta 2025 | Jopa 5 000 $ tahallisesta rikkomuksesta |
| VCDPA (Virginia) | 2023 | Kyllä | Opt-out-oikeus | Jopa 7 500 $/rikkomus |
| TDPSA (Texas) | 2024 | Kyllä | Yleinen opt-out tammikuusta 2025 | Jopa 7 500 $/rikkomus |
| + 8 muuta säädetty vuoteen 2026 mennessä | Vaihtelee | Vaihtelee | Vaihtelee | Vaihtelee |
Muita säädettyjä lakeja on muun muassa Utahissa, Oregonissa, Montanassa, Delawaressa, Iowassa, Nebraskassa, New Hampshiressa, New Jerseyssä, Tennessee’ssä, Minnesotassa, Marylandissa, Indianassa, Kentuckyssa ja Rhode Islandissa. Alabama sääti lain, joka tuli voimaan 1. toukokuuta 2027.
Yrityskäyttäjille, jotka keräävät tuotetietoja, yrityslistauksia tai markkinadataa — ei-PII:tä, faktuaalista tietoa — tietosuojariski on huomattavasti pienempi. Thunderbitin kaltaiset työkalut keskittyvät jäsennellyn datan poimintaan julkisilta sivuilta (tuotedata, yrityshakemistot, kiinteistöilmoitukset), mikä osuu matalimman riskin scraping-kategoriaan.
Merkittävät web scraping -tapaukset: aikajana vuosilta 2000–2026
Tässä kohtaa mielestäni useimmat tämän aiheen oppaat jäävät vajaiksi. Lähes jokainen artikkeli pysähtyy hiQ v. LinkedIniin (2022) ja jättää huomiotta ratkaisut, jotka muokkaavat scraping-lakia juuri nyt. Tässä koko aikajana:
| Tapaus | Vuosi | Keskeinen ratkaisu | Vaikutus scrapeereihin |
|---|---|---|---|
| eBay v. Bidder's Edge | 2000 | Alustava kieltomääräys irtaimeen kohdistuvan luvattoman tunkeutumisen perusteella; crawlerin kuormitus palvelimille oli olennainen | ⚠️ Suurivolyyminen scraping, joka kuormittaa palvelimia, voi synnyttää siviilioikeudellista vastuuta |
| Facebook v. Power Ventures | 2016 | CFAA-vastuu cease-and-desist -ilmoituksen jälkeen ja edelleen tapahtuneen pääsyn vuoksi Facebookin järjestelmien kautta | ⚠️ C&D + kirjautunut/portin takainen käyttö on korkean riskin toimintaa |
| Van Buren v. US | 2021 | CFAA:n "ylittää valtuutetun pääsyn" edellyttää pääsyä kiellettyihin tietokoneen alueisiin | ✅ Supisti CFAA:n soveltamisalaa merkittävästi |
| hiQ v. LinkedIn | 2022 | Julkisen datan käyttö ei ollut CFAA-rikkomus (alustava kieltomääräys, myöhemmin sovinto) | ✅ Julkinen data ≠ "luvaton pääsy" — mutta ei lopullinen ratkaisu |
| Meta v. Bright Data | 2024 | Bright Data voitti summaarisessa tuomiossa Metan sopimusteoriaa vastaan uloskirjautuneen julkisen scrapingin osalta | ✅ Ehdot eivät välttämättä sido uloskirjautunutta scrapingia ilman hyväksyntää |
| X Corp. v. Bright Data | 2024 | Toukokuussa monet vaatimukset hylättiin; marraskuun määräys hylkäsi scrapingiin/myyntiin perustuvat vaatimukset | ✅ Julkisen datan kopiointiväitteet heikkenivät |
| Compulife v. Newman/Rutstein | 2024–2025 | Liikesalaisuusvastuu vakuutustarjousdatan massapoiminnasta; cert denied helmi 2025 | ⚠️ Julkiselta näyttävä data voi silti olla suojattu tietokanta |
| Reddit v. Perplexity/SerpApi/Oxylabs/AWMProxy | 2025–2026 | Väittää teollisen mittakaavan epäsuoraa scrapingia Googlen tulosten kautta | ⚠️ AI-aikakauden tapaukset kohdistuvat datan toimitusketjuihin |
| Google v. SerpApi | 2025–2026 | DMCA §1201 -vaatimukset väitetystä bottisuojauksen kiertämisestä | ⚠️ Testaa, ovatko bottisuojausjärjestelmät DMCA:n tarkoittamia pääsynhallintoja |
Kehityssuunta on selvä: tuomioistuimet suojaavat yhä useammin pääsyä julkiseen dataan CFAA:n näkökulmasta, mutta tekijänoikeus-, sopimus-, yksityisyys-, liikesalaisuus- ja infrastruktuuriväitteet ovat edelleen täysin itsenäisiä riskejä. Ja AI:n kouluttamisen aalto luo kokonaan uusia oikeudellisia kysymyksiä.
Oikaistaan väärinkäsitykset: mitä hiQ v. LinkedIn oikeasti ratkaisi
Tämä on web scraping -lain väärin ymmärretyin tapaus. Olen nähnyt sitä siteerattavan blogikirjoituksissa, Reddit-ketjuissa ja jopa oikeudellisissa yhteenvedoissa todisteena siitä, että "julkinen web scraping on laillista." Se ei ole noin yksinkertaista.
Tässä mitä oikeasti tapahtui:
Mitä hiQ ratkaisi: Ninth Circuit vahvisti alustavan kieltomääräyksen — väliaikaisen määräyksen — joka esti LinkedIniä estämästä hiQ:n julkisten LinkedIn-profiilien scrapingia. Oikeus totesi, että julkisesti saatavilla olevan datan käyttö todennäköisesti ei rikkonut CFAA:ta. Avainsana: todennäköisesti. Lähde: hiQ Labs v. LinkedIn, Ninth Circuit.
Mitä hiQ ei vahvistanut:
- Yleistä oikeutta scrapata mitä tahansa julkista verkkosivua
- Lopullista ratkaisua asiakysymyksestä — korkein oikeus kumosi ja palautti asian Van Burenin jälkeen, Ninth Circuit vahvisti uudelleen, ja sitten tapaus sovittiin loppuvuonna 2022 ilman lopullista tuomioistuimen ratkaisua
- Raportoituun sovintoon sisältyi 500 000 dollaria, kieltomääräys sekä datan ja ohjelmiston tuhoamisvelvoitteet
Miksi tämä merkitsee sinulle: hiQ on rohkaiseva ennakkotapaus julkisen datan scrapeereille. Se viestii, että tuomioistuimet suhtautuvat epäillen alustoihin, jotka yrittävät rakentaa yksityisiä monopoleja datasta, jota ne eivät omista. Mutta se ei ole oikeudellinen takuu. Muut vaatimukset — tekijänoikeus, sopimus, yksityisyys, liikesalaisuudet — jäivät koskaan ratkaisematta. Van Burenin jälkeen CFAA-maisema on selkeämpi, mutta hiQ:n varaan yksinään rakentaminen olisi virhe.
Tämän ymmärtäminen erottaa toisistaan asiantuntevan riskienhallinnan ja toiveajattelun.
Voinko scrapata tämän laillisesti? Käytännöllinen päätöspuu
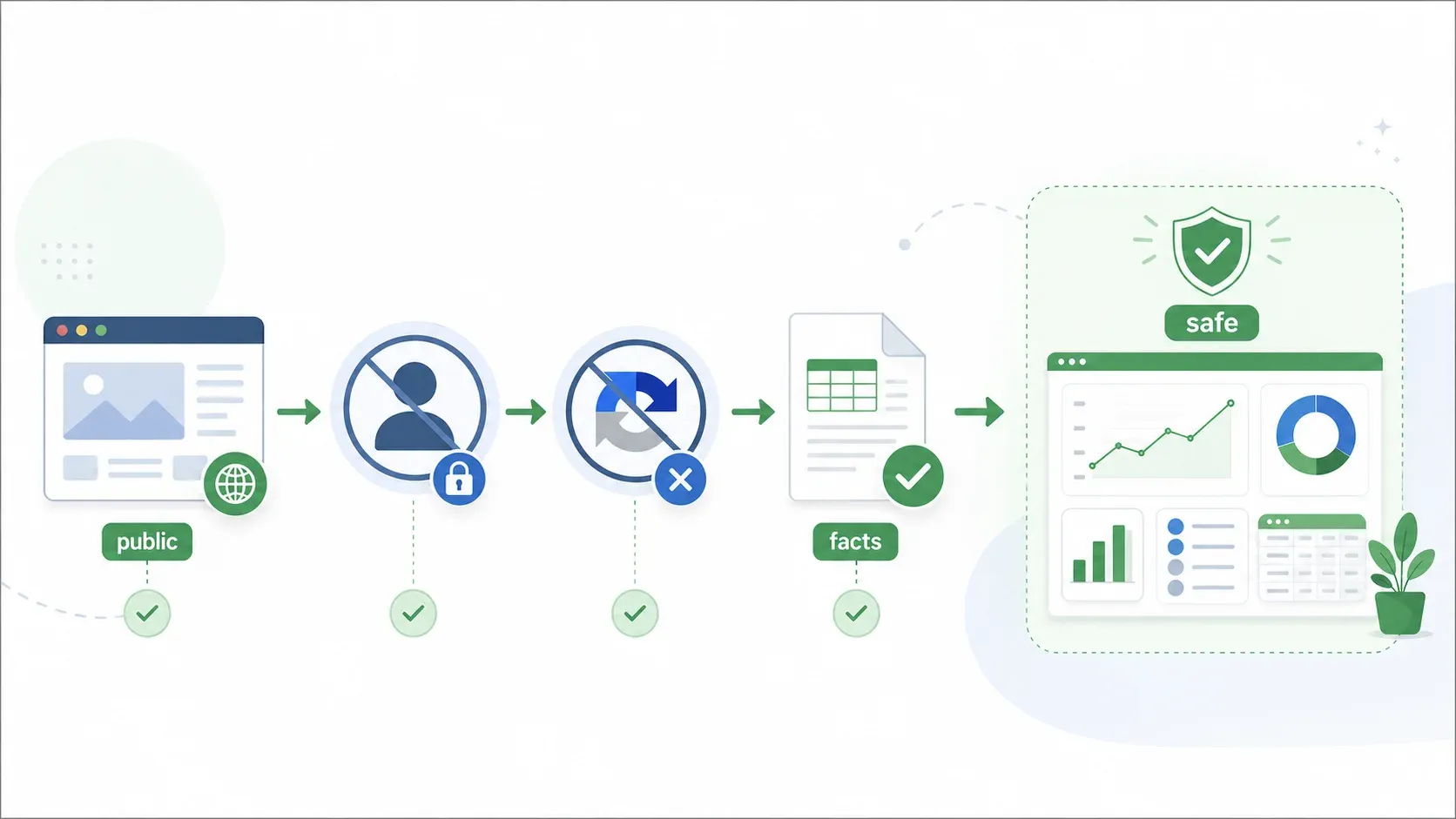
Scrapingin laillisuus tuntuu usein "harmaalta alueelta" — kuulen sen jatkuvasti. Joten lisää oikeusteoriaa enempää, tässä päätösmalli, jota voit oikeasti käyttää. Viisi kysymystä mihin tahansa scraping-projektiin:
1. Onko data julkisesti saatavilla (kirjautumista ei vaadita)?
- Jos EI → Korkeampi CFAA-riski. Pyydä lupa tai oikeudellinen arvio ennen jatkamista.
- Jos KYLLÄ → Siirry kysymykseen 2.
2. Kiertäätkö mitään teknisiä esteitä (CAPTCHA, IP-estot, käyttörajat, maksumuurit)?
- Jos KYLLÄ → Mahdollisia DMCA- ja CFAA-ongelmia. Pysähdy tai vie asia lakineuvontaan.
- Jos EI → Siirry kysymykseen 3.
3. Hyväksyitkö clickwrap-käyttöehdot, jotka kieltävät scrapingin?
- Jos KYLLÄ → Siviilioikeudellisen sopimusrikkomuksen riski. Harkitse, onko data saatavilla jostain muualta, tai pyydä lupa.
- Jos EI → Siirry kysymykseen 4.
4. Sisältyykö dataan henkilötietoja (PII)?
- Jos KYLLÄ → Tarkista CCPA ja sovellettavat osavaltioiden tietosuojalait. Varmista, että käyttötarkoitus on lainmukainen ja että kunnioitat opt-out-oikeuksia.
- Jos EI → Siirry kysymykseen 5.
5. Mitä teet datalla?
- Tekijänoikeudella suojatun sisällön kaupallinen uudelleenjulkaisu (kokonaiset artikkelit, valokuvat, videot) → Tekijänoikeusriski.
- Transformatiivinen analyysi, sisäinen tutkimus tai faktadatan käyttö (hinnat, tekniset tiedot, listaukset) → Yleensä pienempi riski.
Jos päädyt alueelle "julkiset sivut, ei kiertämistä, ei clickwrapia, ei PII:tä, faktadataa sisäiseen analyysiin", olet matalimman riskin kategoriassa. Juuri tätä työnkulkua Thunderbit on suunniteltu varten — jäsennellyn, faktuaalisen datan poimintaan julkisilta verkkosivuilta, kuten tuotelistauksista, yrityshakemistoista ja kiinteistödatalle, ja sen vientiin Exceliin, Google Sheetiin, Airtableen tai Notioniin omaa analyysiäsi varten.
Tallenna tämä päätöspuu. Se ei korvaa lakimiestä, mutta säästää sinut monelta turhalta paniikilta.
AI-koulutus ja web scraping: uusi oikeudellinen rajapinta

AI on lisännyt scraping-lakiin aivan uuden monimutkaisuuden tason. Datan kerääminen suurten kielimallien, kuvageneraattorien ja muiden AI-järjestelmien kouluttamiseen on nyt merkittävä oikeudellinen taistelukenttä — eikä tuomioistuimilla ole vielä vastausta keskeisiin kysymyksiin.
Tilanne on tällä hetkellä tämä:
| Tapaus | Tila (2026) | Keskeinen kysymys |
|---|---|---|
| NYT v. OpenAI/Microsoft | Käynnissä. Keskeiset tekijänoikeusvaatimukset sallittiin jatkaa huhtikuussa 2025; todistelu- ja aineistoriidoissa mukana yli 20 miljoonaa ChatGPT-lokia. | Onko scrapatun uutisaineiston käyttäminen koulutuksessa fair usea vai tekijänoikeusrikkomus? |
| Bartz v. Anthropic | Tuomari Alsup katsoi, että tietyt koulutuskäytöt olivat fair usea, mutta piratoidun lähdeaineiston hankinta ei ollut. Raportoitu sovinto: noin 1,5 miljardia dollaria. | Koulutus voi olla transformatiivista, mutta piratismilla hankittu lähdekopiointi on erillinen ongelma. |
| Thomson Reuters v. Ross | Delaware'n tuomioistuin hylkäsi fair use -puolustuksen, kun Westlaw'n headnoteja käytettiin kilpailevan oikeustutkimustuotteen rakentamiseen. | Suorat korvaavat tuotteet kohtaavat suuremman tekijänoikeusriskin. |
| Getty v. Stability AI | Ison-Britannian tapaus suosi suurelta osin Stabilityä vuonna 2025; Yhdysvaltain tapaus on yhä vireillä. | Kuvien koulutukseen liittyvä lainsäädäntö on edelleen avoin. |
Yhdysvaltain tekijänoikeusviraston vuoden 2025 AI-raportti lisää hyödyllistä tarkennusta: laajoihin ja monipuolisiin aineistoihin kouluttaminen voi usein olla transformatiivista, mutta piratismilla hankitun lähdeaineiston kopiointi ja käyttötavat, jotka kilpailevat suoraan tekijänoikeuden haltijoiden markkinoiden kanssa, ovat paljon heikompi perusta fair use -argumentille.
Useimmille tämän artikkelin lukeville yrityskäyttäjille ero on suoraviivainen: datan scraping omaa analyysiä tai liiketoimintaa varten (liidit, hintaseuranta, markkinatutkimus) on aivan eri oikeudellinen eläin kuin datan scraping AI-mallin kouluttamiseen ja kaupallistamiseen. Edellinen sisältää pienemmän tekijänoikeusriskin. Jälkimmäinen on se alue, jossa suuret oikeusjutut tällä hetkellä käydään.
Kuinka scrapata dataa vastuullisesti (parhaat käytännöt liiketoimintatiimeille)
Lakia on jo riittävästi. Tässä on, miten dataa voi oikeasti scrapeata ilman, että tiimillesi syntyy oikeudellista päänvaivaa.
Pysy julkisesti saatavilla olevassa datassa
Keskity dataan, jonka kuka tahansa voi nähdä kirjautumatta sisään — tuoteluettelot, yrityshakemistot, julkiset rekisterit, hinnoittelusivut. Heti kun siirryt kirjautumisen taakse, olet korkeammassa riskissä.
Älä kierrä teknisiä esteitä
Jos sivusto käyttää CAPTCHAa, IP-estoja, käyttörajoja tai maksumuureja, ne ovat merkkejä. Niiden kiertäminen voi laukaista DMCA-, CFAA- tai sopimusväitteitä. Jos data on tarpeeksi tärkeää, etsi mieluummin virallinen API tai datakumppanuus.
Tarkista käyttöehdot
Erityisesti, jos olet luonut tilin tai klikannut "Hyväksyn." Lue käyttöehdot scrapingin vastaisten lausekkeiden varalta. Jos ehdot kieltävät scrapingin ja olet hyväksynyt ne, mieti, onko data saatavilla muualta.
Minimoi henkilötietojen kerääminen
Jos keräät PII:tä (nimiä, sähköposteja, puhelinnumeroita), varmista, että käyttötarkoituksesi on sovellettavien osavaltioiden tietosuojalakien mukainen. Faktuaalisen yritysdatan — yritysten nimet, tuotteen hinnat, listauksen tiedot — scraping on huomattavasti vähemmän riskialtista kuin yksittäisten kuluttajaprofiilien scraping.
Kunnioita robots.txt:ää ja käyttörajoja
Robots.txt (RFC 9309) ei ole itsessään juridisesti sitova, mutta sen kunnioittaminen osoittaa vilpitöntä mieltä. Älä myöskään kuormita verkkosivun palvelimia liikaa — rajoita pyyntösi, käytä järkeviä aikavälejä äläkä aiheuta infrastruktuurivahinkoa.
Käytä dataa analyysiin, älä uudelleenjulkaisuun
Transformatiivinen käyttö — analyysi, kokoaminen, sisäinen tutkimus, kilpailija-analytiikka — on paljon turvallisempaa kuin jonkun toisen artikkelien, kuvien tai arvostelujen kopiointi ja uudelleenjulkaisu. Jos rakennat tiimillesi dashboardeja tai taulukoita, olet paremmassa asemassa kuin jos julkaiset scrapatun sisällön uudelleen omalla verkkosivullasi.
Valitse työkalut, jotka on suunniteltu lainmukaiseen scrapingiin
Tässä kohtaa mainitsen, mitä olemme rakentaneet Thunderbitissa. Meidän AI web scraper -Chrome-laajennuksemme on suunniteltu liiketoimintakäyttäjille, jotka haluavat poimia jäsenneltyä dataa julkisilta verkkosivuilta — tuoteluetteloista, yrityshakemistoista, kiinteistödatasta, liidetiedoista — ilman koodausta tai teknisten esteiden kiertämistä. AI lukee sivun, ehdottaa kenttiä ja antaa sinun viedä tiedon Exceliin, Google Sheetiin, Airtableen tai Notioniin. Se on rakennettu yllä olevan päätöspuun matalimman riskin haaralle: julkiset sivut, faktadata, ei kirjautumisen kiertämistä.
Siitä huolimatta mikään työkalu ei tee sinua immuuniksi oikeudellisille riskeille. Vastuu siitä, mitä scrapat ja miten käytät sitä, on aina sinulla.
Pidä lokit ja pysähdy cease-and-desist -ilmoitukseen
Dokumentoi scraping-toimintasi ja liiketoimintatarkoituksesi. Jos saat cease-and-desist -kirjeen, lopeta ja konsultoi lakimiestä. Scrapingin jatkaminen virallisen ilmoituksen jälkeen nostaa riskiprofiiliasi merkittävästi, erityisesti jos mukana on portin takaisia järjestelmiä.
Keskeiset johtopäätökset web scrapingin laillisuudesta Yhdysvalloissa
Lyhyt versio:
- Mikään Yhdysvaltain liittovaltion laki ei kiellä web scrapingia. Julkisesti saatavilla olevan faktadatan kerääminen on yleensä sallittua.
- Laillisuus riippuu siitä, mitä scrapaat, miten siihen pääset käsiksi ja mitä teet sillä. Julkiset sivut + faktadata + sisäinen analyysi = matalin riski.
- CFAA:n soveltamisala on kaventunut Van Burenin ja hiQ:n jälkeen, mutta tekijänoikeus-, sopimus-, yksityisyys- ja liikesalaisuusvaatimukset ovat itsenäisiä riskejä, jotka ovat yhä voimassa.
- Rikosoikeudellinen vastuu on harvinainen tyypillisessä yritysscrapingissa. Useimmat riskit ovat siviilioikeudellisia — oikeusjuttuja, eivät rautoja.
- hiQ v. LinkedIn ei ole yleinen vapautuskirja. Kyse oli alustavasta kieltomääräyksestä, joka myöhemmin sovittiin. Rohkaiseva, mutta ei takuu.
- Osavaltioiden tietosuojalaeilla on merkitystä, kun PII on mukana, mutta ei-PII-data (hinnat, listaukset, tekniset tiedot) sisältää pienimmän riskin.
- AI-koulutuksen käyttötapaukset ovat uusi ja vielä avoin oikeudellinen rajapinta. Liiketoiminnan omaa analyysiä varten tehty scraping on eri riskiprofiili kuin scraping kaupallisten AI-mallien rakentamiseen.
- Parhaiden käytäntöjen noudattaminen — julkinen data, käyttöehtojen kunnioittaminen, PII:n välttäminen, esteiden kiertämisen välttäminen ja datan vastuullinen käyttö — pitää tiimisi turva-alueella.
Tarvittava vastuuvapauslauseke: tämä artikkeli on informatiivinen, ei oikeudellista neuvontaa. Jos suunnittelet laajamittaista scraping-operaatiota tai käsittelet arkaluonteista dataa, konsultoi pätevää asianajajaa. Mutta sille myyntipäällikölle, joka haluaa vain poimia liidejä julkisesta hakemistosta, tai verkkokauppatiimille, joka seuraa kilpailijoiden hintoja? Laki on todennäköisesti enemmän sinun puolellasi kuin arvaat.
Jos haluat nähdä, miten Thunderbit tekee tällaisesta julkisen datan poiminnasta helppoa — ei koodia, ei kiertämistä, vain jäsenneltyä dataa työnkulkuusi — tutustu pikaoppaaseemme tai lataa Chrome-laajennus ja kokeile itse.
Usein kysytyt kysymykset
1. Onko web scraping laillista Yhdysvalloissa vuonna 2026?
Kyllä, web scraping on Yhdysvalloissa yleensä laillista, kun keräät julkisesti saatavilla olevaa dataa. Sitä ei kieltävää liittovaltion lakia ole. Mutta se, miten scrapaat, mitä dataa keräät ja miten käytät sitä, voi synnyttää oikeudellisia riskejä CFAA:n, tekijänoikeuslain, sopimusoikeuden tai osavaltioiden tietosuojasäännösten perusteella. Turvallisin lähestymistapa on pysyä julkisilla sivuilla, välttää teknisten esteiden kiertämistä, minimoida henkilötietojen kerääminen ja käyttää dataa analyysiin eikä suoraan uudelleenjulkaisuun.
2. Voinko joutua vankilaan web scrapingin takia?
Rikosoikeudellinen syyte web scrapingista on erittäin harvinainen ja vaatisi tyypillisesti pääsyä dataan autentikointisuojusten takana ilman lupaa (CFAA-rikkomus) tai petoksen tekemistä. Oikeusministeriön vuoden 2022 CFAA-syytepolitiikan mukaan tavalliset käyttöehtorikkomukset eivät riitä rikossyytteeseen. Useimmat web scraping -kiistat ovat siviilioikeudellisia — oikeusjuttuja, eivät rikosasioita.
3. Muuttuuko scraping laittomaksi, jos rikot verkkosivun käyttöehtoja?
Ei automaattisesti. Verkkosivun käyttöehtojen rikkominen on sopimusasia, ei rikos. Jos olet hyväksynyt clickwrap-ehdot, jotka kieltävät scrapingin, verkkosivu voi ajaa siviilioikeudellista sopimusrikkomusväitettä. Mutta browsewrap-ehdot (linkki alatunnisteessa) ovat paljon vaikeampia panna täytäntöön, erityisesti jos et ole koskaan kirjautunut sisään tai klikannut "Hyväksyn". Tuomioistuimet ovat suhtautuneet skeptisesti passiivisten browsewrap-ehtojen täytäntöönpanoon useissa scraping-tapauksissa.
4. Onko henkilötietojen (esim. sähköpostien, puhelinnumeroiden) kerääminen laillista Yhdysvalloissa?
Riippuu tilanteesta. Monet Yhdysvaltain osavaltioiden tietosuojalait — mukaan lukien CCPA, VCDPA, CPA ja muut — sisältävät poikkeuksia julkisesti saatavilla olevalle henkilötiedolle, mutta määritelmät ja jatkokäyttöön liittyvät velvoitteet vaihtelevat. Ei-henkilökohtaisen datan (tuotteiden hinnat, yrityslistaukset, julkiset rekisterit) scraping on paljon vähemmän riskialtista kuin yksittäisten kuluttajaprofiilien scraping. Jos keräät PII:tä laajassa mittakaavassa, tarkista sovellettavat osavaltion lait ja varmista, että sinulla on lainmukainen tarkoitus.
5. Tekikö hiQ v. LinkedIn kaikesta web scrapingista laillista?
Ei. hiQ-ratkaisu oli alustava kieltomääräys — väliaikainen määräys, joka perustui menestymisen todennäköisyyteen — ei lopullinen ratkaisu asiakysymyksestä. Ninth Circuit totesi, että julkisen datan käyttö todennäköisesti ei rikkonut CFAA:ta, mutta tapaus sovittiin vuonna 2022 ilman lopullista tuomioistuimen ratkaisua. Se ei anna yleistä lupaa scrapata mitä tahansa verkkosivua, eikä se käsittele tekijänoikeus-, sopimus-, yksityisyys- tai liikesalaisuusvaatimuksia. Se on rohkaiseva uutinen julkisen datan scrapeereille, mutta ei oikeudellinen takuu.
Lue lisää




