

Apollo-listakyselyiden optimointi ei ole vain tekninen harjoitus — se on selviytymistaaito kaikille, jotka ovat riippuvaisia reaaliaikaisesta uutisdatasta, automaattisesta uutisten poiminnasta tai nopearytmisistä myynnin ja operatiivisen työn prosesseista. Olen nähnyt omin silmin, kuinka hidas listakysely voi muuttaa sulavalta näyttävän hallintapaneelin pullonkaulaksi: myyntitiimit tuijottavat latausikoneita ja ops-porukka paikkaa ongelmia spreadsheetsissä. Maailmassa, jossa 60 % myyntiedustajien ajasta kuluu jo muihin kuin myyntitehtäviin, jokainen millisekunti merkitsee.
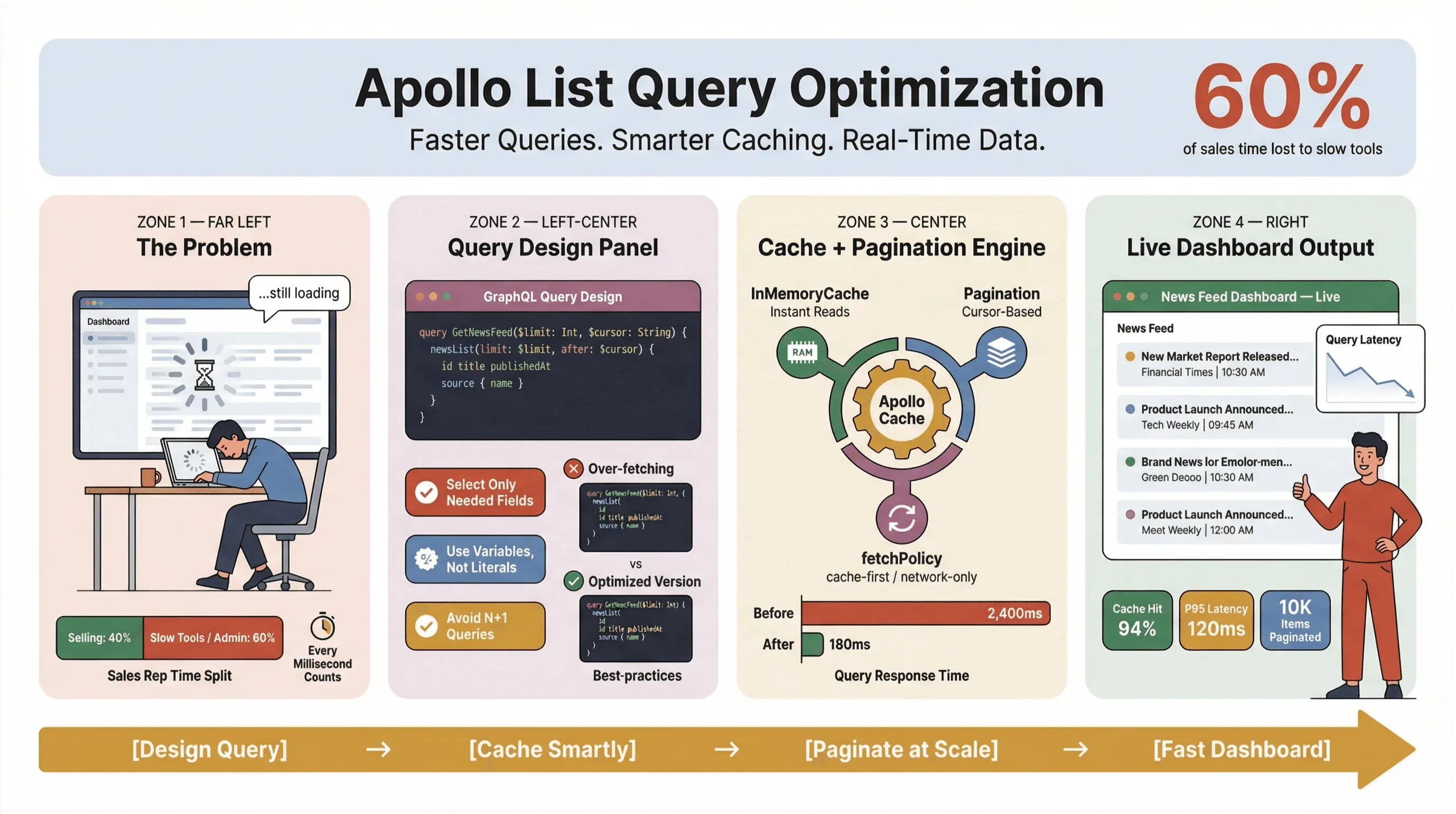
Miten siis pidät Apollo Clientin listakyselyt nopeina, luotettavina ja tasalaatuisina myös suuressa mittakaavassa — etenkin kun poimit uutisia, seuraat liidejä tai pyörität liiketoiminnan kannalta kriittisiä dashboardeja? Tässä oppaassa käyn läpi tuotannossa toimiviksi todetut käytännöt: kyselysuunnittelu, välimuisti, sivutus ja no-code-työkalujen, kuten Thunderbit, hyödyntäminen uutisten poiminnan rutiinitöiden automatisointiin.
--- Olitpa kehittäjä, tuotepäällikkö tai vain se henkilö, jota kaikki syyttävät, kun dashboard on hidas, tämä on Apollo GraphQL -listojen suorituskyvyn pelikirjasi.
Kokeile Thunderbitia automatisoituun uutisten poimintaan
Miksi Apollo-listakyselyt kannattaa optimoida? (apollo client list performance, optimize apollo list queries)
Puhutaan suoraan: kukaan ei halua odottaa uutisotsikoiden tai myyntiliidien latautumista. Liiketoimintaympäristöissä — erityisesti niissä, jotka tukeutuvat automatisoituun uutisten poimintaan tai reaaliaikaiseen dataan — hitaat Apollo-listakyselyt eivät vain ärsytä käyttäjiä; ne maksavat rahaa, viivästyttävät päätöksiä ja ajavat ihmiset takaisin manuaaliseen työhön. Toistuva Slack Workforce Labin tutkimus on johdonmukaisesti osoittanut, että toimistotyöntekijät käyttävät noin kolmanneksen — ja tuoreemmissa raporteissa jo lähemmäs 40 % — työpäivästään matalan arvon toistuviin tehtäviin, usein siksi, että työkalut pirstovat työn hitaiden käyttöliittymien yli.
Näin käy, kun listakyselyitä ei optimoida:
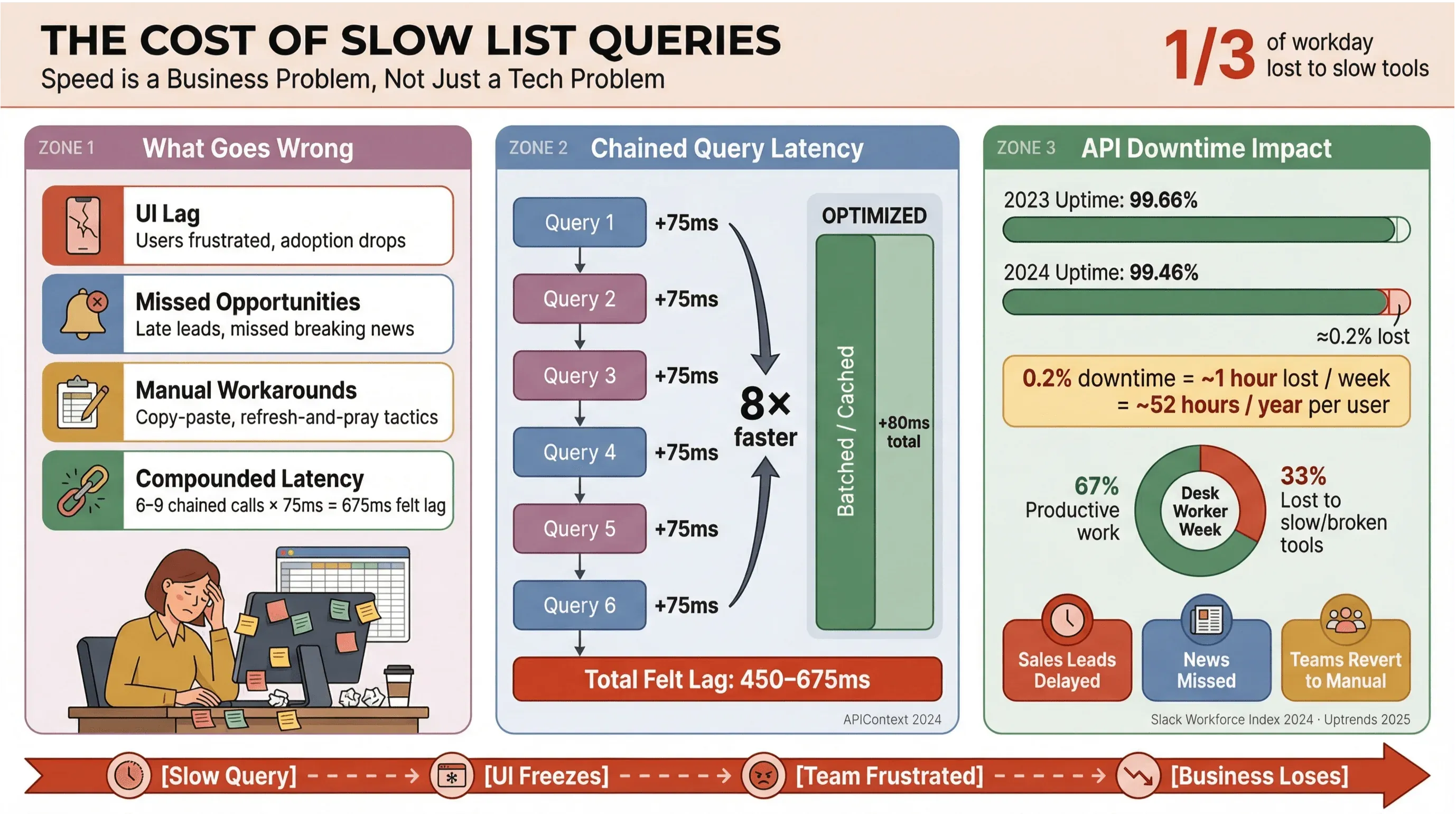
- Käyttöliittymä hidastelee: Käyttäjät kokevat viiveitä, mikä lisää turhautumista ja heikentää käyttöönottoa.
- Mahdollisuuksia menetetään: Myynnissä tai uutisseurannassa jo muutaman sekunnin viive voi tarkoittaa kuuman liidin tai breaking newsin menettämistä.
- Manuaaliset kiertotiet: Tiimit palaavat copy-pasteen, taulukoihin tai “päivitä ja rukoile” -taktiikkaan.
- Kertyvä viive: Jokainen hidas API-kutsu kasautuu — jos työnkulku käynnistää 6–9 riippuvaista kyselyä, maltillinen 75 ms viive per kutsu voi kasvaa jopa 450–675 ms:n “tuntuvaksi” viiveeksi (APIContext).
Ja kyse ei ole vain nopeudesta. API-käyttökatkot ovat yleistymässä, ja keskimääräinen käyttöaika on laskenut 99,66 prosentista 99,46 prosenttiin vain vuodessa — mikä tarkoittaa lähes tunnin menetettyä tuottavuutta viikossa listapainotteisissa sovelluksissa. Kun liiketoimintasi nojaa reaaliaikaiseen uutisdataan, se on riski, johon ei ole varaa.
Oikean datastruktuurin ja kenttien valinta (apollo graphql list best practices)
Yksi yleisimmistä virheistä, joita näen (ja kyllä, olen itsekin tehnyt sen), on käsitellä jokaista listakyselyä kuin se olisi yksityiskohtakysely. GraphQL:ssa voit hakea juuri sen, mitä tarvitset — käytä tätä hyödyksi. Ylipoiminta on suorituskyvyn vihollinen, erityisesti uutisten poimintatyökaluissa ja reaaliaikaisissa dashboardeissa.
Kenttien räätälöinti automatisoituun uutisten poimintaan
Otetaan esimerkiksi uutisvirta. Tarvitsetko todella listakyselyssä koko artikkelin tekstin, kaikki tagit, kommentit ja kirjoittajan esittelyn? Todennäköisesti et. Ero näyttää tältä:
Tehokas listakysely:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Tehoton listakysely (älä tee näin):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Ensimmäinen kysely on kevyt ja tehokas — täydellinen lajitteluun, suodatukseen ja rivien renderöintiin. Entä toinen? Se on naamioitu yksityiskohtakysely, joka hakee valtavia payloadeja ja hidastaa kaiken (GraphQL spec, Apollo best practices).
Vinkki: Käytä kaksitasoista mallia — hae listassa vain kevyet kentät ja lataa raskaat tiedot (kuten koko teksti tai NLP-rikastus) vasta, kun käyttäjä avaa kohteen tai vie hiiren sen päälle.
Apollo Clientin välimuistin hyödyntäminen nopeampiin kyselyihin (apollo client list performance)
Apollo Clientin välimuisti on tärkein yksittäinen vipu listakyselyiden suorituskyvyssä. Kun se on konfiguroitu hyvin, voit:
- Palvella toistuvat kyselyt välittömästi ilman verkkokierrosta
- Vähentää palvelimen kuormitusta ja API-kustannuksia
- Mahdollistaa sujuvan eteen/taakse-navigoinnin ja suodatinmuutokset
Mutta välimuisti ei ole taikaa — se vaatii hieman asetuksia ja kurinalaisuutta.
Tehokkaiden välimuistikäytäntöjen määrittäminen
Apollo tukee useita fetch policy -asetuksia:
| Politiikka | Mitä se tekee | Paras käyttötapa uutislistoille |
|---|---|---|
| cache-first | Lukee välimuistista, hakee verkosta jos data puuttuu | Listoihin palaaminen, suodattimien vaihto, eteen/taakse-navigointi |
| network-only | Hakee aina verkosta | Manuaalinen päivitys, “viimeisimmät otsikot” |
| cache-and-network | Palauttaa ensin välimuistin ja päivittää sitten verkosta | Nopea ensimmäinen renderöinti + taustapäivitys (erinomainen uutisvirroille) |
| no-cache | Hakee aina, ei koskaan tallenna välimuistiin | Kertaluonteiset herkät kyselyt (harvinainen listoissa) |
Reaaliaikaisessa uutisdatassa pidän cache-and-network-asetuksesta — käyttäjä saa välittömästi tulokset, ja data päivittyy taustalla. Ole kuitenkin tarkkana käyttöliittymän välkkymisen kanssa, jos data järjestyy uudelleen päivityksessä (GitHub issue).
Välimuistin konfigurointivinkit:
- Käytä vakaita ID-tunnisteita (
idtai_id) normalisointiin (Apollo cache docs). - Säädä välimuistin kokoa ja roskienkeruuta suuria listoita varten (memory management).
- Vältä valtavien, normalisoimattomien objektien tallentamista
ROOT_QUERY-solmun alle — se voi hidastaa sovellusta (community report).
Sivutuksen toteuttaminen ja item-määrän rajaaminen (apollo graphql list best practices)
Jos lataat kerralla satoja tai tuhansia uutisartikkeleita tai myyntiliidejä, kutsut ongelmia. Sivutus ei ole vain käyttöliittymäominaisuus — se on suorituskyvyn välttämättömyys.
Apollo tukee sekä offset-pohjaista että cursor-pohjaista sivutusta. Näin ne vertautuvat:
| Sivutustyyppi | Edut | Haitat | Paras käyttöön |
|---|---|---|---|
| Offset-pohjainen | Yksinkertainen, helppo toteuttaa | Voi ohittaa/tuplata rivejä, jos data muuttuu | Muuttumattomat tai pienet listat |
| Cursor-pohjainen | Vakaa, toimii hyvin datan muuttuessa | Hieman monimutkaisempi | Uutisvirrat, suuret listat |
Useimmissa reaaliaikaisissa uutis- tai liidilistoissa cursor-pohjainen sivutus on oikea valinta. Se pitää datan johdonmukaisena, vaikka uusia kohteita saapuu tai vanhoja poistuu (GraphQL Foundation).
Apollo-sivutusvinkit:
- Määritä
keyArgshallitsemaan sivutetun kentän cache-avaimia (docs). - Toteuta
merge-funktio, joka yhdistää sivut välimuistiin. - Käytä
fetchMore-metodia uusien sivujen lataamiseen ilman, että aiemmat tulokset ylikirjoittuvat.
Käytännölliset sivutusmallit uutisten poimintatyökaluille
Tyypillinen uutisten poiminnan käyttöliittymä:
- näyttää uusimmat 20–50 otsikkoa (vain kevyet kentät)
- lataa lisää scrollatessa tai “seuraava sivu” -klikkauksella
- hakee yksityiskohdat vasta tarvittaessa
Näin käyttöliittymä pysyy nopeana, API tyytyväisenä ja käyttäjät tehokkaina.
Thunderbitin integrointi automatisoituun uutisten poimintaan
Puhutaan nyt siitä, mistä kaikki tämä jäsennelty uutisdata oikeastaan tulee: tässä kohtaa Thunderbit astuu kuvaan.
Hanki Thunderbit Chrome -laajennus Get Started Free
Thunderbit on no-code AI web scraper -Chrome-laajennus, joka voi poimia uutisotsikot, URL-osoitteet, lähteet, kirjoittajat, julkaisupäivät, tiivistelmät ja kuvat käytännössä miltä tahansa sivustolta — ilman koodausta. Olen nähnyt tiimien käyttävän Thunderbitia koko uutisten poimintaprosessin automatisointiin, jolloin epäjäsennellyistä verkkosivuista syntyy siistiä, strukturoitua dataa, joka voidaan syöttää suoraan tietokantaan tai GraphQL APIin.
Thunderbitin ja Apollon yhdistäminen reaaliaikaiseen uutisdataan
Tässä on työnkulku, jota suosittelen myynnin ja ops-tiimien käyttöön, kun ajantasainen uutistieto on tärkeää:
- Poimintakerros: Käytä Thunderbitin News Scraper -templaattia noutamaan jäsenneltyä uutisdataa kohdesivustoilta ajastetusti.
- Tallennuskerros: Tallenna poimittu data tietokantaan, joka on optimoitu nopeaa hakua varten.
- GraphQL-kerros: Tarjoa API:n kautta
newsFeed-listakenttä janewsArticle(id)-yksityiskohtakenttä. - Asiakaskerros: Käytä Apollo Clientia listan hakemiseen (kevyet kentät, sivutettuna) ja hae yksityiskohdat vasta tarpeen mukaan.
Tämä “poimi → tallenna → kysy” -putki tarkoittaa, että Apollo-kyselysi toimivat aina tuoreen, jäsennellyn datan kanssa — ilman manuaalista copy-pastea tai hauraiden skriptien ylläpitoa.
Lisäbonus: Thunderbit voi rikastaa listojasi myös lisäkentillä (kuten sentimentti tai kategoria) AI-pohjaisilla kenttäehdotuksillaan, jolloin uutisvirtasi muuttuu entistä älykkäämmäksi.
Vaiheittainen opas: Apollo-listakyselyiden optimointi
Valmis viemään tämän käytäntöön? Tässä oma tarkistuslistani Apollo-listakyselyiden optimointiin:
-
Pienennä kyselyitäsi
- Pyydä vain kentät, joita tarvitaan listan renderöintiin (otsikko, URL, aikaleima jne.).
- Siirrä raskaat kentät (koko teksti, kuvat, rikastus) yksityiskohtakyselyihin.
-
Toteuta sivutus
- Käytä cursor-pohjaista sivutusta suurissa tai dynaamisissa listoissa.
- Määritä
keyArgs- jamerge-funktiot, jotta välimuisti pysyy oikein.
-
Hyödynnä Apollo-välimuistia
- Normalisoi entiteetit vakailla ID-tunnisteilla.
- Valitse oikea fetch policy (
cache-and-networksopii hyvin uutisiin). - Säädä välimuistin koko ja roskienkeruu datamäärääsi sopivaksi.
-
Integroi automaattinen poiminta
- Käytä Thunderbitia uutisten poiminnan automatisointiin ja datan ajantasaisena pitämiseen.
- Vie jäsennelty data suoraan tietokantaan tai taulukkoon.
-
Seuraa ja vianmääritä
- Käytä Apollo Client Devtoolsia kyselyiden, välimuistin ja suorituskyvyn tarkasteluun.
- Tarkkaile suuria välimuistikirjoituksia, liiallisia watched query -kyselyitä ja käyttöliittymän nykimistä.
- Seuraa p95/p99-latenssia ja virheprosentteja (New Relic, Uptrends).
Kyselysuorituskyvyn seuranta ja vianmääritys
Apollo Devtools on tässä kullanarvoinen. Niillä voit:
- tarkastella aktiivisia kyselyitä ja välimuistin tilaa
- havaita duplikaattikyselyt tai liian monet watcherit
- tunnistaa suuret välimuistiobjektit tai normalisointiongelmat
Jos huomaat käyttöliittymän hidastelua tai hitaita päivityksiä, tarkista:
- liian suuret listakyselyt (pienennä niitä)
- heikko välimuistin normalisointi (korjaa ID:t)
- sivutuksen merge-ongelmat (tarkista
keyArgsjamerge)
Äläkä unohda mitata tail latencya — ei vain keskiarvoja. Siellä todellinen käyttäjäkipu piilee.
Perinteisen ja AI-ohjatun uutisten poiminnan vertailu
Myönnetään suoraan: ennen uutisdatan poiminta tarkoitti omien skriptien kirjoittamista, headless-selainten säätämistä ja toivomista, ettei sivun rakenne muuttuisi yön aikana. Nyt AI-pohjaisilla työkaluilla, kuten Thunderbitilla, koko prosessi voidaan automatisoida — ei koodia, ei draamaa.
| Lähestymistapa | Vahvuudet | Rajoitukset liiketoimintakäyttäjille |
|---|---|---|
| Skriptipohjainen poiminta | Täysin räätälöitävissä, edullinen suuressa mittakaavassa | Vaatii paljon ylläpitoa, tarvitsee kehittäjäaikaa |
| Hallinnoidut poiminta-alustat | Nopeaa aloittaa, hoitaa bot-suojausten kiertämisen puolestasi | Vaatii silti konfigurointia, kustannukset kasvavat käytön mukana |
| AI-ohjattu poiminta (Thunderbit) | Selviää sotkuisista sivuasetteluista, ei koodausta | Tulokset vaativat laadunvarmistusta ja sovittamista omaan skeemaan |
| No-code-visuaaliset poimijat | Helppo käyttää ei-teknisille käyttäjille | Voi rikkoutua käyttöliittymämuutoksissa, rajallinen skaalautuvuus |
| Proxy-/unlocker-infra | Ohittaa estot, tukee suurta läpivirtausta | Poimintalogiikkaa tarvitaan silti, compliance-riskit |
Oikeudellinen huomio: Julkisen datan poiminta on yleensä laillista, mutta kunnioita aina käyttöehtoja ja rate limit -rajoja (Reuters).
Tärkeimmät opit Apollo GraphQL -listojen parhaista käytännöistä
Kootaan olennaiset asiat yhteen:
- Optimoi nopeuden ja selkeyden mukaan: Pienennä listakyselyitä, käytä sivutusta ja hyödynnä välimuistia aggressiivisesti.
- Rakenne ratkaisee: Hae vain tarvittava — siirrä raskaat kentät yksityiskohtakyselyihin.
- Välimuisti on ystäväsi: Käytä Apollon normalisointia ja fetch policy -asetuksia, jotta data saadaan esiin välittömästi.
- Automatisoi poiminta: Työkalut kuten Thunderbit tekevät uutisten poiminnasta ja listojen rikastamisesta kaikkien ulottuvilla.
- Seuraa ja kehitä: Käytä Devtoolsia ja observability-hallintapaneeleja pullonkaulojen tunnistamiseen ajoissa.
Myynnin, opsin ja uutistiimien näkökulmasta nämä käytännöt tarkoittavat vähemmän odottelua, enemmän tekemistä — ja paljon vähemmän “miksi tämä on niin hidasta?” -viestejä Slackissa.
Yhteenveto: seuraavat askeleet Apollo-listakyselyiden optimointiin
Jos ajat yhä raskaita, sivuttamattomia tai välimuistille hankalia listakyselyjä, nyt on aika auditoida ja päivittää. Aloita pienestä: karsi kenttiä, lisää sivutus ja säädä välimuisti kohdilleen. Sen jälkeen voit nostaa tasoa integroimalla automaattisia poimintatyökaluja, kuten Thunderbitin, jotta data pysyy tuoreena ja käyttökelpoisena.
Haluatko mennä syvemmälle? Tutustu Apollo-dokumentaatioon, Thunderbit-blogiin tai liity Apollo Communityyn käytännön vinkkejä ja vianmääritystä varten. Ja jos haluat automatisoida uutisten poiminnan, kokeile Thunderbitin News Scraper -templaattia — se on pelin muuttaja kaikille, jotka tarvitsevat reaaliaikaista dataa ilman päänvaivaa.
Käytä Thunderbitin News Scraper -templaattia
Jos et tämän lukemisen jälkeen tee mitään muuta: tiivistä listakyselyidesi kenttävalintoja, lisää cursor-pohjainen sivutus ja valitse järkevä fetch policy. Nämä kolme muutosta riittävät usein siirtämään listakyselyn "havaittavasta" viiveestä "huomaamattomaan" — ja vapauttavat sinut keskittymään dataan, eivät lataustilaan.
Usein kysytyt kysymykset
1. Miksi Apollo-listakyselyt hidastuvat reaaliaikaisissa uutis- tai myyntidashboardeissa?
Listakyselyt voivat hidastua, jos ne hakevat liikaa dataa, niissä ei ole sivutusta tai niitä ei ole välimuistittu oikein. Suuritahtisissa työnkuluissa, kuten uutisseurannassa, pienetkin viiveet kasautuvat ja aiheuttavat käyttöliittymän hidastelua sekä tuottavuuden laskua.
2. Mikä on paras tapa rakentaa Apollo-listakyselyt automatisoituun uutisten poimintaan?
Pyydä vain ne kentät, joita tarvitset listan näyttämiseen (esim. otsikko, URL, aikaleima). Siirrä raskaat kentät, kuten koko artikkelin teksti tai kuvat, yksityiskohtakyselyihin ja käytä sivutusta pitämään payloadit pieninä ja nopeina.
3. Miten Apollo Clientin välimuisti parantaa listojen suorituskykyä?
Apollo-välimuisti tallentaa aiemmin haetun datan, joten toistuvat kyselyt palautuvat välittömästi. Oikea normalisointi ja fetch policy -asetukset, kuten cache-and-network, voivat nopeuttaa listanäkymiä merkittävästi ja vähentää palvelinkuormaa.
4. Miten Thunderbit auttaa uutisten poiminnassa ja Apollo-integraatiossa?
Thunderbit on no-code AI web scraper, joka poimii jäsenneltyä uutisdataa miltä tahansa sivustolta. Voit käyttää sitä uutisten poiminnan automatisointiin ja syöttää datan sitten tietokantaan tai GraphQL APIin Apollo Clientin käyttöön.
5. Millä työkaluilla voin seurata ja vianmäärittää Apollo-listakyselyiden suorituskykyä?
Apollo Client Devtools auttaa tarkastelemaan kyselyitä, välimuistin tilaa ja suorituskykyä reaaliajassa. Yhdistä siihen observability-hallintapaneelit, kuten New Relic tai Uptrends, latenssin ja virheprosenttien seurantaan, ja kehitä kyselysuunnittelua tulosten optimoimiseksi.
Haluatko lisää vinkkejä web scrapingista, automaatiosta ja reaaliaikaisista dataworkfloista? Käy Thunderbit-blogissa syventymässä oppaisiin, tutoriaaleihin ja uusimpiin AI-pohjaisen tuottavuuden keinoihin.
Kokeile Thunderbit AI Web Scraperia Get Started Free
Lue lisää
- Kuinka optimoida Apollo-listat tehokkaaseen liidien hallintaan
- Apollo-tiedonrikastus: ominaisuudet, hyödyt ja AI-tehostus
- Kuinka hallita Apollo-prospektointia: vaiheittainen opas
- Kuinka käyttää web scraperin sivutusta tehokkaaseen poimintaan
- Kuinka käyttää web scraperin sivutusta tehokkaaseen poimintaan




