
Toimistoissa ympäri maailmaa kytee hiljainen vallankumous – eikä se liity pingispöytiin tai hanakombuchaan. Kyse on “helposta web-datan poiminnasta”: siitä, että ihan kuka tahansa, ei pelkästään koodarit, voi napata hyödyllistä dataa netistä minuuteissa eikä päivissä. Jos olet joskus tuijottanut verkkosivua ja miettinyt, että “voisinko vain kerätä kaikki nimet, hinnat tai sähköpostit ja tiputtaa ne suoraan taulukkoon”, et todellakaan ole ainoa. Olen jutellut myyjien, markkinoijien ja operatiivisten tiimien kanssa, ja kaikilla on sama fiilis: “Miksi tämän pitää olla edelleen näin hankalaa?”
Totuus on, että tarve yksinkertaisille web-scraping-menetelmille kasvaa ihan räjähdysmäisesti. mukaan 65 % organisaatioista käyttää nyt generatiivista tekoälyä vähintään yhdessä liiketoimintatoiminnossa, ja web-datan poiminta nousee vauhdilla yhdeksi halutuimmista käyttötapauksista. Web scraping -markkinan arvioidaan yltävän , ja erityisesti ei-tekniset liiketoimintakäyttäjät puskevat kehitystä kohti työkaluja, joilla datan kerääminen on yhtä vaivatonta kuin kopioi–liitä. Mutta mitä “helppo web-datan poiminta” oikeasti tarkoittaa – ja miten saat siitä irti konkreettista hyötyä työnkulun yksinkertaistamiseen? Puretaan homma osiin.
Helppo web-datan poiminta ei-teknisille käyttäjille: nolla koodia, nolla päänvaivaa
Aloitetaan ihan perusteista: Mitä “helppo web-datan poiminta” on? Ytimeltään se tarkoittaa sitä, että sotkuinen ja jatkuvasti elävä web muutetaan siisteiksi, rakenteisiksi taulukoiksi – ilman ainuttakaan koodiriviä. Ei-teknisille liiketoimintakäyttäjille tämä on iso pelinmuutos. Ei enää IT:n perässä juoksemista, ei enää painimista Python-skriptien kanssa, eikä sitä, että homma kaatuu siihen, kun sivusto vaihtaa ulkoasua yhdessä yössä.
Miksi tämä on juuri nyt niin ajankohtaista? Web on dynaamisempi kuin koskaan. Sivustot käyttävät loputonta skrollausta, ponnahdusikkunoita ja monimutkaista JavaScriptiä, jotka rikkovat perinteiset scrapersit vähän väliä. Samaan aikaan liiketoimintatiimeihin kohdistuva paine tuottaa oivalluksia – nopeasti – on kovempi kuin ennen. 98 % organisaatioista sanoo julkisen web-datan olevan kriittistä tai erittäin tärkeää toiminnalleen, ja yli puolet hyödyntää sitä päivittäin.
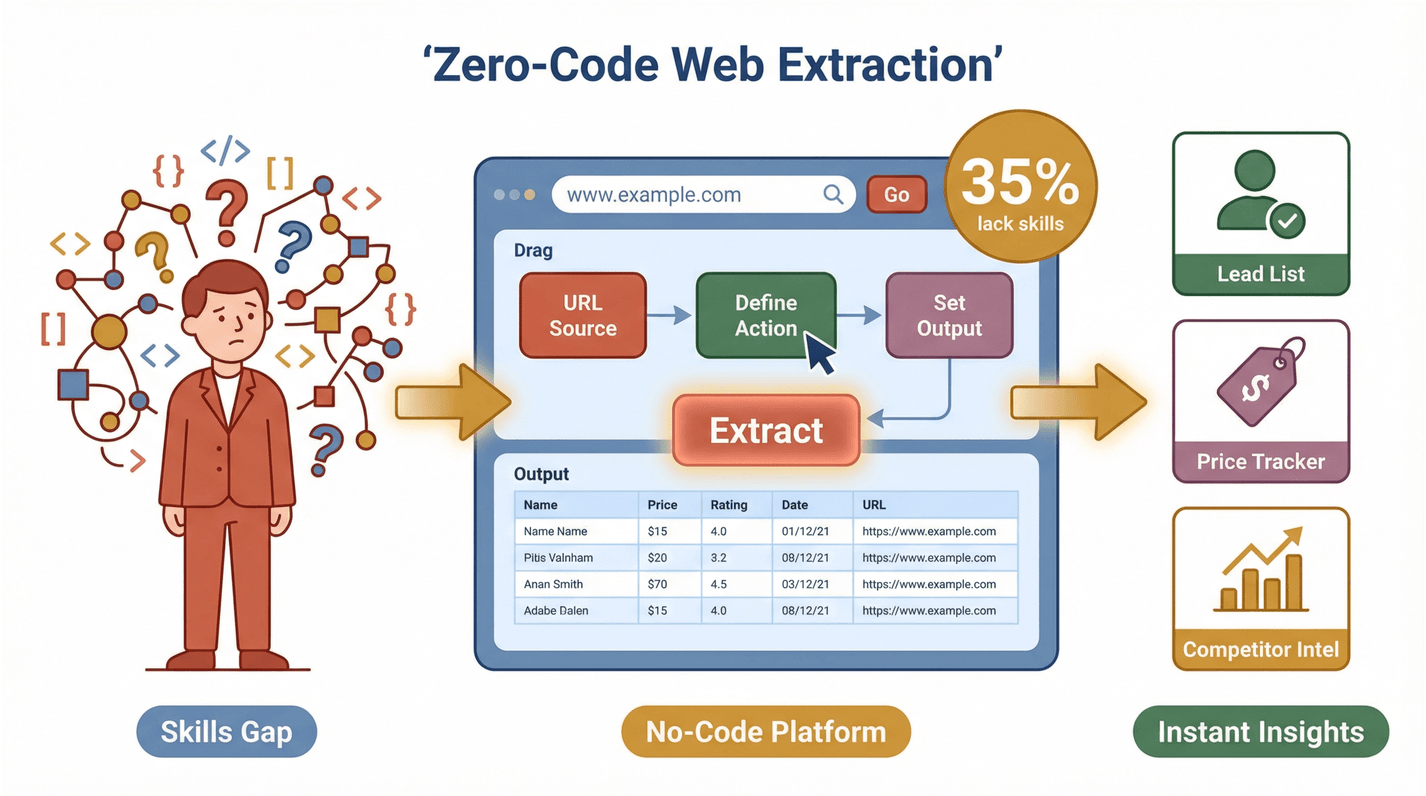
Mutta tässä on se koukku: suurin osa näistä tiimeistä ei ole teknisiä. Tuore kysely osoitti, että 35 % organisaatioista ei omaa oikeaa osaamista web-datan poimintaan, ja 33 %:lla ei ole oikeita työkaluja. Tämä avaa valtavan mahdollisuuden no-code-ratkaisuille. Kun kuka tahansa voi poimia ja hyödyntää web-dataa, tuottavuus nousee ihan uudelle tasolle – olitpa rakentamassa liidilistaa, seuraamassa kilpailijoita tai valvomassa hintoja.
No-code/low-code-liike: miksi sillä on väliä
No-code- ja low-code-työkalujen yleistyminen tarkoittaa käytännössä teknologian demokratisoitumista. Se ei ole vain Piilaakson muotisana, vaan ihan oikea muutos siinä, miten työtä tehdään. Web scraping -maailmassa tämä tarkoittaa:
- Ei koodausta: Dataa voi poimia kuka tahansa, ei vain kehittäjät.
- Nopeus: Tulokset minuuteissa, eivät päivissä.
- Joustavuus: Uusiin sivustoihin ja datatarpeisiin voi reagoida heti.
- Vähemmän virheitä: Automaatio vähentää kopioi–liitä-mokia.
Parasta on, ettei sinun tarvitse muuttua tekniikkavelhoksi päästäksesi mukaan.
Miksi perinteiset web scraping -työkalut turhauttavat
Ollaan rehellisiä: perinteiset web scraping -työkalut tuntuvat usein siltä, että ne on tehty kehittäjiltä kehittäjille – ei liiketoimintakäyttäjille. Olen nähnyt tämän käytännössä: tiimit innostuvat projektista, mutta törmäävät seinään, kun työkalu pyytää CSS-selektoreita, XPathia tai säännöllisiä lausekkeita. Sitten katse lasittuu ja alkaa “palataan ensi kvartaalissa” -viestit.
Tyypilliset kompastuskivet:
- Koodia vaaditaan: Monet vanhan koulukunnan työkalut edellyttävät skriptien kirjoittamista tai monimutkaisten mallien säätämistä.
- Hankala käyttöönotto: Jokainen kenttä pitää kartoittaa, kirjautumiset hoitaa ja proxyt virittää, ettei tule estoja.
- Hauraat säännöt: Sivuston layout muuttuu ja scraper hajoaa. Sitten debuggaat koodia sen sijaan, että tekisit varsinaista työtäsi.
- Ylläpitotaakka: Jokainen sivustopäivitys vie takaisin lähtöruutuun.
Ei ihme, että mukaan suurimmat tekniset haasteet web scrapingissa ovat IP-osoitteiden blokkaus/bannaus (56 %), dynaaminen sisältö (55 %) ja CAPTCHA:t (52 %). Jopa kokeneet tiimit saavat tehdä töitä pysyäkseen mukana.
Samaan aikaan liiketoimintakäyttäjät haluavat vain yksinkertaisen ja luotettavan tavan saada data taulukoihin tai CRM:ään. Tässä kohtaa helppo web-datan poiminta ja yksinkertaiset web-scraping-menetelmät astuvat kuvaan.
Miten Thunderbit tekee helposta web-datan poiminnasta mahdollista
Tässä kohtaa innostun – koska juuri tätä ongelmaa lähdimme ratkomaan . Missiomme on tehdä web scrapingista niin helppoa, että kuka tahansa onnistuu siinä, riippumatta teknisestä taustasta.
Thunderbit on , joka muuttaa web-datan poiminnan kahden klikkauksen jutuksi. Näin se toimii:
- Kerro mitä haluat: Kuvaile luonnollisella kielellä, mitä dataa tarvitset. Esimerkiksi: “Poimi tältä sivulta kaikki tuotenimet ja hinnat.”
- Klikkaa “AI Suggest Fields”: Thunderbitin tekoäly lukee sivun ja ehdottaa parhaat sarakkeet poimittavaksi – kuten “Nimi”, “Hinta”, “Sähköposti” tai “Kuva”.
- Klikkaa “Scrape”: Thunderbit hoitaa loput: sivutuksen, alasivut ja tarvittaessa myös kirjautumisen takana olevan sisällön.
Siinä se. Ei koodia, ei malleja, ei tuskaista käyttöönottoa. Käyttöliittymä on tehty liiketoimintakäyttäjille – myyntiin, markkinointiin, verkkokauppaan, kiinteistöihin – jotka haluavat tuloksia, eivät säätöä.
Thunderbitin tekoälypohjainen työnkulku: fiksumpaa, ei raskaampaa
Se varsinainen taika on tekoälyssä. Thunderbit ei vain arvaile, mitä haluat – se lukee sivun, ymmärtää kontekstin ja jäsentää datan automaattisesti. Jos haluat hienosäätää, voit lisätä kenttäkohtaisia ohjeita (kuten “luokittele tämä sarake” tai “käännä englanniksi”), mutta useimmat käyttäjät klikkaavat ja etenevät.
Tekoälypohjainen lähestymistapa tarkoittaa:
- Vähemmän virheitä: Tekoäly mukautuu eri layouteihin, joten tulokset pysyvät tasaisina, vaikka sivusto muuttuisi.
- Nopeampi aloitus: Ei tarvetta rakentaa malleja tai kirjoittaa skriptejä.
- Hyödynnettävä data: Thunderbit voi nimetä, luokitella ja jopa rikastaa dataa poiminnan aikana.
Syvempää perehdytystä varten katso tai . Lisää oppaita löydät myös , kuten ja .
Thunderbitin erottuvat ominaisuudet yksinkertaisiin web-scraping-menetelmiin
Thunderbitin etu ei ole vain tekoäly – vaan koko työnkulku, joka on rakennettu oikeita liiketoimintatarpeita varten. Tässä ominaisuuksia, joista käyttäjämme erityisesti tykkäävät:
- Automaattinen sivutus: Thunderbit hoitaa monisivuiset listat ja loputtoman skrollauksen ilman säätöä.
- Alasivujen poiminta: Tarvitsetko lisätietoja? Thunderbit voi avata jokaisen alasivun (kuten tuotesivut tai LinkedIn-profiilit) ja rikastaa datasetin automaattisesti.
- Vienti minne tahansa: Lähetä data suoraan Exceliin, Google Sheetsiin, Airtableen, Notioniin tai lataa CSV/JSON-muodossa. Ei enää kopioi–liitä-maratooneja.
- Toimii kirjautumisen takana: Poimi dataa sivustoilta, jotka vaativat kirjautumisen – Thunderbit toimii selaimessasi, joten se näkee saman kuin sinä.
- Tekoälypohjainen nimeäminen ja luokittelu: Lisää ohjeita datan luokitteluun, tagitukseen tai kääntämiseen poiminnan yhteydessä.
- Ajastettu scraping: Aseta toistuvat ajot, jotta data pysyy tuoreena – täydellinen hintaseurantaan tai liidien seurantaan.
Ja kyllä, kaikki tämä löytyy työkalusta, johon luottaa yli .
Automaattinen sivutus ja alasivujen poiminta
Yksi web scrapingin isoimmista päänsäryistä on sivutettujen listojen tai sisäkkäisten detaljisivujen käsittely. Thunderbitilla sinun ei tarvitse stressata siitä. Tekoäly tunnistaa sivutuksen (oli se “Next”-painike tai loputon skrollaus) ja seuraa alasivulinkkejä automaattisesti. Näin voit poimia satoja tai tuhansia rivejä kerralla – ilman manuaalista klikkailua.
Esimerkiksi jos poimit Amazonin tuotelistaa, Thunderbit voi kerätä tuotteet useilta sivuilta ja siirtyä sitten jokaiselle tuotesivulle hakemaan arvostelut, tähtiluokitukset tai myyjätiedot. Se on kuin väsymätön assistentti, joka ei kyllästy.
Vienti useissa muodoissa ja CRM-integraatiot
Data on hyödyllistä vasta, kun sitä voi oikeasti käyttää. Thunderbitilla viet tulokset siinä muodossa, mitä tiimisi tarvitsee – Excel, Google Sheets, Airtable, Notion tai CSV/JSON. Voit myös syöttää datan suoraan CRM:ään tai työnkulun työkaluihin, jotta myynti- ja operatiiviset tiimit pysyvät kartalla.
Suorat integraatiot säästävät valtavasti aikaa. Ei enää sotkuisten vientien siivoamista tai sarakkeiden uudelleenmuotoilua – Thunderbitin tekoäly hoitaa sen.
Käytännön esimerkkejä helposta web-datan poiminnasta
Missä helppo web-datan poiminta tuo suurimman hyödyn? Tässä muutamia tosielämän tilanteita, joita olen nähnyt Thunderbit-käyttäjiltä:
Liidien poiminta myyntiin
Myyntitiimit elävät ja kuolevat liidilistoillaan. Thunderbitilla voit poimia yhteystietoja LinkedInistä, Google Mapsista tai yrityshakemistoista minuuteissa. Avaa sivu, klikkaa “AI Suggest Fields” ja anna Thunderbitin kerätä nimet, sähköpostit, puhelinnumerot ja yritystiedot valmiiseen taulukkoon.
Eräs myyntipäällikkö kertoi, että aiemmin liidien kopiointi vei tunteja viikossa. Nyt Thunderbitilla he rakentavat kohdennettuja listoja murto-osassa ajasta – ja tiimi voi keskittyä kontaktointiin, ei datan syöttöön.
Verkkokauppa ja markkinaseuranta
Verkkokauppatiimit käyttävät Thunderbitia kilpailijoiden SKU:iden, hintojen ja arvostelujen seurantaan Amazonissa, Shopifyssa ja muilla alustoilla. Haluatko seurata hintamuutoksia tai uusia tuotelanseerauksia? Aseta ajastettu poiminta ja saat tuoreen datan Google Sheetiin joka aamu.
Thunderbitin alasivujen poiminta on erityisen hyödyllinen tässä: voit kerätä tuotedetaljit, kuvat ja jopa asiakasarvostelut ilman vaivaa.
Kiinteistödata analytiikkaan
Kiinteistöalan ammattilaiset hyödyntävät Thunderbitia kerätäkseen kohdelistauksia, hintoja ja välittäjätietoja sivustoilta kuten Zillow tai Realtor.com. Tekoäly hoitaa sivutuksen ja alasivut, joten saat kattavan ja ajantasaisen markkinanäkymän – analyysiin tai asiakasraportteihin.
Eräs analyytikko kertoi, että aiemmin koko iltapäivän vienyt työ hoituu nyt muutamalla klikkauksella. Siinä yksinkertaisten web-scraping-menetelmien voima.
Perinteisten ja yksinkertaisten web-scraping-menetelmien vertailu
Kootaan erot rinnakkain:
| Ominaisuus | Perinteiset scrapersit | Helppo web-datan poiminta (Thunderbit) |
|---|---|---|
| Koodausta vaaditaan | Kyllä (skriptit, selektorit) | Ei (tekoäly + luonnollinen kieli) |
| Käyttöönottoaika | Suuri (mallit, konfigurointi) | Pieni (2 klikkausta) |
| Ylläpito | Usein (hajoaa sivustomuutoksissa) | Vähäinen (tekoäly mukautuu) |
| Sivutuksen käsittely | Manuaalinen asetus | Automaattinen |
| Alasivujen poiminta | Monimutkainen logiikka | 1 klikkaus |
| Vientimuodot | Usein rajalliset | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Toimii kirjautumisen takana | Joskus (asetuksilla) | Kyllä (selainpohjainen) |
| Datan nimeäminen/luokittelu | Manuaalinen jälkikäsittely | Tekoälypohjainen, sisäänrakennettu |
| Ajastus/seuranta | Joskus (edistyneissä) | Kyllä (helppo asetus) |
Ero on kuin yö ja päivä. Thunderbitilla kuka tahansa voi poimia, järjestää ja hyödyntää web-dataa – ilman teknistä osaamista.
Tulevaisuuden trendit: helppo web-datan poiminta ja yksinkertaiset web-scraping-menetelmät
Tulevaisuus näyttää tosi hyvältä helpolle web-datan poiminnalle. Tekoäly kehittyy koko ajan, ja no-code-työkalujen kysyntä kasvaa vauhdilla. mukaan 78 % organisaatioista käyttää nyt tekoälyä vähintään yhdessä toiminnossa, ja agenttimaiset järjestelmät – tekoälytyökalut, jotka hoitavat monivaiheisia web-työnkulkuja – yleistyvät.
Mitä tämä tarkoittaa liiketoimintakäyttäjille? Enemmän tehoa, vähemmän säätöä. Tekoälyn parantuessa näemme:
- Entistä fiksumman kenttien tunnistuksen: Tekoäly ymmärtää monimutkaisempaa dataa ja suhteita.
- Paremmat integraatiot: Suorat yhteydet yhä useampiin liiketoimintatyökaluihin ja alustoihin.
- Luotettavuuden kasvun: Vähemmän rikkoutumista ja tasaisemmat tulokset myös dynaamisilla tai suojatuilla sivuilla.
- Laajemman saavutettavuuden: Web-datan poiminnasta tulee perustaito kaikille, ei vain “tekeville”.
Ja kyllä, Thunderbit on tämän kehityksen etulinjassa.
Yhteenveto ja tärkeimmät opit
Web on maailman suurin tietokanta – mutta vielä ihan hiljattain siihen pääsivät käsiksi lähinnä koodarit. Tämä muuttuu nopeasti. Helpon web-datan poiminnan ja yksinkertaisten web-scraping-menetelmien avulla kuka tahansa voi muuttaa verkkosivut käyttökelpoiseksi dataksi minuuteissa.
Tärkeimmät opit:
- Nollakoodinen web-datan poiminta on tullut jäädäkseen: Thunderbitin kaltaiset työkalut mahdollistavat web-datan keruun ja käytön ilman teknistä osaamista.
- Tekoäly on se ratkaiseva tekijä: Kun kenttien valinta, sivutus, alasivujen poiminta ja datan luokittelu automatisoidaan, aikaa säästyy ja virheet vähenevät.
- Liiketoimintahyödyt ovat konkreettisia: Myynti-, verkkokauppa- ja kiinteistötiimit saavat tuottavuusloikan, tuoreempaa dataa ja parempaa päätöksentekoa.
- Tulevaisuus on vieläkin parempi: Kun tekoäly ja no-code-työkalut kehittyvät, web-datan poiminnasta tulee yhtä arkipäiväistä kuin sähköpostin lähettämisestä.
Jos olet kyllästynyt manuaaliseen kopioi–liitä-työhön, turhautunut rikkoutuviin scrapersiin tai muuten vain utelias mahdollisuuksista, kokeile . Voit ja aloittaa datan poiminnan ilmaiseksi – ei asennussäätöä, ei koodia, ei vaivaa.
Ja jos haluat syventyä lisää, käy lukemassa oppaita, vinkkejä ja käytännön esimerkkejä.
UKK
1. Mitä “helppo web-datan poiminta” tarkoittaa ja kenelle se sopii?
Helppo web-datan poiminta tarkoittaa nollakoodisia, tekoälypohjaisia web scraping -menetelmiä, joilla kuka tahansa – erityisesti ei-tekniset liiketoimintakäyttäjät – voi poimia rakenteista dataa verkkosivuilta nopeasti ja vaivattomasti. Se sopii erinomaisesti myyntiin, markkinointiin, verkkokauppaan ja operatiivisiin tiimeihin, jotka tarvitsevat hyödynnettävää dataa ilman teknistä säätöä.
2. Miten Thunderbit eroaa perinteisistä web scraping -työkaluista?
Thunderbit hyödyntää tekoälyä kenttien valinnan, sivutuksen ja alasivujen poiminnan automatisointiin. Toisin kuin perinteiset scrapersit, jotka vaativat koodausta tai monimutkaisia malleja, Thunderbitissa voit kuvata tarpeesi selkokielellä ja poimia datan kahdella klikkauksella.
3. Pystyykö Thunderbit käsittelemään dynaamisia tai monisivuisia sivustoja?
Kyllä. Thunderbit tunnistaa ja hoitaa sivutuksen automaattisesti (myös loputtoman skrollauksen) ja voi seurata alasivulinkkejä syvempää datan poimintaa varten – minimaalisella käyttöönotolla.
4. Mitä vientivaihtoehtoja Thunderbit tukee?
Thunderbitilla voit viedä datan suoraan Exceliin, Google Sheetsiin, Airtableen, Notioniin, CSV- tai JSON-muodossa. Voit myös integroida CRM:iin ja muihin työnkulun työkaluihin sujuvia prosesseja varten.
5. Onko helppojen web-datan poimintatyökalujen, kuten Thunderbitin, käyttö turvallista ja eettistä?
Thunderbit kannustaa vastuulliseen ja eettiseen web scraping -käyttöön. Kunnioita aina sivustojen käyttöehtoja, vältä henkilötietojen poimintaa ilman suostumusta ja käytä nopeusrajoituksia palvelun häiriöiden välttämiseksi. Parhaista käytännöistä lisää: .
Haluatko hyödyntää web-datan voiman? Kokeile Thunderbitia jo tänään ja näe, miten helppo web-datan poiminta voi muuttaa työnkulkuasi.
Lue lisää