

Mitä ohjelmointikieltä web-scrapingiin kannattaa käyttää? Se riippuu projektistasi — ja olen nähnyt kehittäjien lyövän hanskat tiskiin valittuaan väärän vaihtoehdon.
Web-scraping-ohjelmistojen markkina nousi $1,01 miljardiin vuonna 2024, ja sen odotetaan yli kaksinkertaistuvan vuoteen 2032 mennessä. Oikea kieli voi tarkoittaa nopeampia tuloksia ja vähemmän ylläpitoa. Väärä taas tarkoittaa rikkinäisiä scrapeja ja hukattuja viikonloppuja.
Olen rakentanut automaatiotyökaluja vuosia. Tässä on seitsemän kieltä, joita olen käyttänyt scrapingiin — mukana koodiesimerkkejä, rehellisiä kompromisseja ja katsaus siihen, milloin koodaus kannattaa jättää väliin ja käyttää sen sijaan Thunderbitia.
Miten valitsimme parhaan kielen web-scrapingiin
Web-scrapingissa kaikki ohjelmointikielet eivät ole samanarvoisia. Olen nähnyt projektien sekä lentävän että kaatuvan muutaman keskeisen tekijän perusteella:
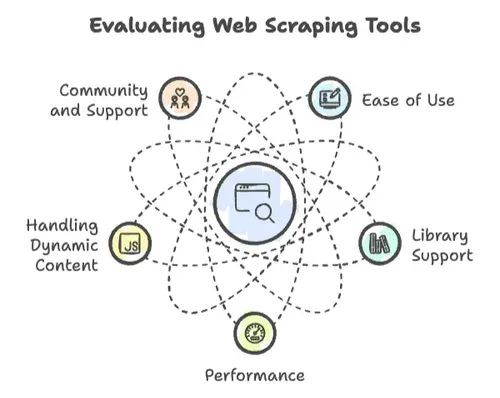
- Helppokäyttöisyys: Kuinka nopeasti pääset alkuun? Onko syntaksi selkeä, vai tarvitsetko tietojenkäsittelytieteen tohtorin tutkinon, jotta saat edes tulostettua “Hello, World”?
- Kirjastotuki: Löytyykö kunnollisia kirjastoja HTTP-pyyntöihin, HTML:n parsintaan ja dynaamisen sisällön käsittelyyn? Vai keksitkö pyörän uudelleen?
- Suorituskyky: Pystyykö se käsittelemään miljoonien sivujen scrapausta, vai hyytyykö se jo muutaman sadan jälkeen?
- Dynaamisen sisällön käsittely: Nykysivustot rakastavat JavaScriptiä. Pysyykö kielesi mukana?
- Yhteisö ja tuki: Kun törmäät seinään — ja niin käy — löytyykö apua yhteisöltä?
Näiden kriteerien ja monien myöhäisillan testien perusteella tässä ovat seitsemän kieltä, joihin pureudun:
- Python: Ensisijainen valinta aloittelijoille ja ammattilaisille.
- JavaScript & Node.js: Dynaamisen sisällön kuningas.
- Ruby: Siisti syntaksi, nopeat skriptit.
- PHP: Palvelinpuolen helppous.
- C++: Kun tarvitset raakaa nopeutta.
- Java: Yritysvalmis ja skaalautuva.
- Go (Golang): Nopea ja rinnakkainen.
Ja jos ajattelet: “Shuai, en halua koodata ollenkaan”, pysy mukana loppuun asti — siellä esittelen Thunderbitin.
Python web-scrapingiin: aloittelijaystävällinen tehopakkaus
Aloitetaan yleisön suosikista: Pythonista. Jos kysyt täynnä data-ammattilaisia olevalta huoneelta: “Mikä on paras ohjelmointikieli web-scrapingiin?” — saat Pythonin kaikumaan takaisin kuin Taylor Swift -konsertin lauluhuudon.
Miksi Python?
- Aloittelijaystävällinen syntaksi: Python-koodia voi lukea ääneen, ja se kuulostaa melkein englannilta.
- Verraton kirjastotuki: HTML:n parsintaan BeautifulSoup, laajamittaiseen crawlingiin Scrapy, HTTP-pyyntöihin Requests ja selainautomaation Selenium — Pythonista löytyy kaikki.
- Vahva yhteisö: Pelkästään web-scrapingista yli 33 000 Stack Overflow -kysymystä.
Esimerkkikoodi Pythonilla: sivun otsikon scraping
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Sivun otsikko: {title}")
Vahvuudet:
- Nopea kehitys ja prototypointi.
- Paljon opasvideoita ja Q&A-sisältöä.
- Erinomainen data-analyysiin — scrapea Pythonilla, analysoi pandasilla, visualisoi matplotlibilla.
- Kirjastot kehittyvät jatkuvasti: Scrapyn 2.14-versio (tammikuu 2026) toi natiivin
async/await-tuen koko frameworkiin, joten async ei ole enää vain Selenium/Playwright-juttu.
Rajoitukset:
- Hitaampi kuin käännetyt kielet massiivisissa töissä.
- Erittäin dynaamisten sivustojen käsittely voi olla kömpelöä (vaikka Selenium ja Playwright auttavat).
- Ei ihanteellinen miljoonien sivujen scrapaamiseen salamannopeasti.
Yhteenveto:
Jos olet uusi scrapingissa tai haluat vain saada asiat nopeasti tehtyä, Python on web-scrapingiin paras kieli — piste. Lisää siitä, miksi Python dominoi web-scrapingia.
JavaScript & Node.js: dynaamisten sivustojen scraping vaivattomasti
Jos Python on sveitsiläinen linkkuveitsi, JavaScript (ja Node.js) on porakone — etenkin modernien, JavaScript-painotteisten sivustojen scrapingiin.
Miksi JavaScript/Node.js?
- Natiivisti dynaamiselle sisällölle: Se toimii selaimessa, joten se näkee saman kuin käyttäjäkin — vaikka sivu olisi rakennettu Reactilla, Angularilla tai Vuella.
- Async oletuksena: Node.js pystyy käsittelemään satoja pyyntöjä yhtä aikaa.
- Tutun oloinen web-kehittäjille: Jos olet rakentanut verkkosivun, osaat jo jonkin verran JavaScriptiä.
Keskeiset kirjastot:
- Playwright: Moniselaintuki (Chromium, Firefox, WebKit), automaattinen odotus ja context-kohtaiset proxyt. Jos aloitat uuden Node-scraperin vuonna 2026, tämä on oletusvalinta.
- Puppeteer: Headless Chrome Chrome DevTools Protocolin kautta. Edelleen varma valinta Chrome-rajattuihin töihin ja kevyempään riippuvuuskokonaisuuteen.
- Cheerio: jQuery-tyylinen HTML-parsinta Nodeen silloin, kun et tarvitse oikeaa selainta.
Esimerkkikoodi Node.js:llä: sivun otsikon scraping Puppeteerilla
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Sivun otsikko: ${title}`);
await browser.close();
})();
Vahvuudet:
- Käsittelee JavaScriptillä renderöityä sisältöä natiivisti.
- Erinomainen loputtoman scrollauksen, ponnahdusikkunoiden ja interaktiivisten sivustojen scrapingiin.
- Tehokas laajamittaiseen, rinnakkaiseen scrapaamiseen.
Rajoitukset:
- Async-ohjelmointi voi olla aloittelijalle hankalaa.
- Headless-selaimet kuluttavat paljon muistia, jos niitä pyörittää liian monta kerralla.
- Data-analyysityökaluja on vähemmän kuin Pythonissa.
Milloin JavaScript/Node.js on paras ohjelmointikieli web-scrapingiin?
Kun kohdesivusto on dynaaminen tai haluat automatisoida selaintoimintoja. Lisää Node.js:stä dynaamisen sisällön scrapingissa.
Ruby: siisti syntaksi nopeisiin web-scraping-skripteihin
Ruby ei ole vain Rails-sovelluksia ja eleganttia koodirunoutta varten. Se on varteenotettava valinta web-scrapingiin — etenkin jos pidät koodista, joka lukee kuin haiku.
Miksi Ruby?
- Luettava ja ilmeikäs syntaksi: Rubyllä kirjoitettu scraper voi olla melkein yhtä helppo lukea kuin ostoslista.
- Hyvä prototypointiin: Nopea kirjoittaa, helppo säätää.
- Keskeiset kirjastot: Nokogiri parsintaan, Mechanize navigoinnin automatisointiin.
Esimerkkikoodi Rubyllä: sivun otsikon scraping
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Sivun otsikko: #{title}"
Vahvuudet:
- Erittäin luettava ja tiivis.
- Erinomainen pieniin projekteihin, kertaluonteisiin skripteihin tai silloin, kun käytät jo Rubyä.
Rajoitukset:
- Hitaampi kuin Python tai Node.js isoissa töissä.
- Vähemmän scraping-kirjastoja ja pienempi yhteisötuki scrapingiin.
- Ei ihanteellinen JavaScript-painotteisten sivustojen scrapingiin (vaikka Watir tai Selenium auttavat).
Paras käyttökohde:
Jos olet Ruby-tekijä tai haluat vääntää nopeasti skriptin, Ruby on ilo. Massiiviseen ja dynaamiseen scrapingiin kannattaa katsoa muualle.
PHP: palvelinpuolen yksinkertaisuutta web-datan poimintaan
PHP voi tuntua varhaisen webin jäänteeltä, mutta se on edelleen täysin käyttökelpoinen — etenkin jos haluat scrapata dataa suoraan palvelimellasi.
Miksi PHP?
- Toimii lähes kaikkialla: Useimmilla web-palvelimilla PHP on jo valmiina.
- Helppo integroida web-sovelluksiin: Scrape ja näytä data sivustollasi yhdellä kertaa.
- Keskeiset kirjastot: cURL HTTP:lle, Guzzle pyyntöihin, Symfony Panther headless-selaimen automaatioon.
Esimerkkikoodi PHP:llä: sivun otsikon scraping
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Sivun otsikko: $title\n";
?>
Vahvuudet:
- Helppo ottaa käyttöön web-palvelimilla.
- Sopii hyvin scrapingiin osana web-työnkulkua.
- Nopea yksinkertaisissa, palvelinpuolen scraping-tehtävissä.
Rajoitukset:
- Rajallinen kirjastotuki edistyneelle scrapingille.
- Ei rakennettu korkeaan rinnakkaisuuteen tai laajamittaiseen scrapaamiseen.
- JavaScript-painotteisten sivustojen käsittely on hankalaa (vaikka Panther auttaa).
Paras käyttökohde:
Jos nykyinen teknologiapinossi on jo PHP:tä tai haluat scrapata ja näyttää dataa sivustollasi, PHP on käytännöllinen valinta. Lisää PHP:stä vs. Pythonista scrapingissa.
C++: suorituskykyistä web-scrapingia suuriin projekteihin
C++ on ohjelmointikielten muscle car. Jos tarvitset raakaa nopeutta ja hallintaa etkä säikähdä hieman käsityötä, C++ voi viedä sinut pitkälle.
Miksi C++?
- Huippunopea: Päihittää useimmat kielet CPU-sidonnaisissa tehtävissä.
- Tarkka kontrolli: Hallitse muistia, säikeitä ja suorituskyvyn säätöjä.
- Keskeiset kirjastot: libcurl HTTP:lle, htmlcxx parsintaan.
Esimerkkikoodi C++:lla: sivun otsikon scraping
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Sivun otsikko: " << title << std::endl;
} else {
std::cout << "Title-tagia ei löytynyt" << std::endl;
}
return 0;
}
Vahvuudet:
- Verraton nopeus massiivisissa scraping-töissä.
- Erinomainen scrapingin integrointiin korkean suorituskyvyn järjestelmiin.
Rajoitukset:
- Jyrkkä oppimiskäyrä (varaa kahvia).
- Manuaalinen muistinhallinta.
- Rajallisesti korkean tason kirjastoja; ei ihanteellinen dynaamiselle sisällölle.
Paras käyttökohde:
Kun sinun täytyy scrapata miljoonia sivuja tai suorituskyky on ehdottoman kriittinen. Muuten saatat käyttää enemmän aikaa debuggaukseen kuin scrapaukseen.
Java: yritysvalmiita web-scraping-ratkaisuja
Java on yritysmaailman työjuhta. Jos rakennat jotain, jonka täytyy pyöriä ikuisesti, käsitellä valtavia tietomääriä ja selvitä zombiapokalypsista, Java on ystäväsi.
Miksi Java?
- Vankka ja skaalautuva: Erinomainen isoihin, pitkään eläviin scraping-projekteihin.
- Vahva tyypitys ja virheenkäsittely: Vähemmän yllätyksiä tuotannossa.
- Keskeiset kirjastot: Jsoup parsintaan, Selenium WebDriver selainautomaatioon, Apache HttpClient HTTP:lle.
Esimerkkikoodi Javalla: sivun otsikon scraping
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Sivun otsikko: " + title);
}
}
Vahvuudet:
- Korkea suorituskyky ja rinnakkaisuus.
- Erinomainen suuriin, ylläpidettäviin koodikantoihin.
- Hyvä tuki dynaamiselle sisällölle (Seleniumin tai HtmlUnitin kautta).
Rajoitukset:
- Runsassanaisempi syntaksi; enemmän alustusta kuin skriptikielissä.
- Ylilyönti pieniin, kertaluonteisiin skripteihin.
Paras käyttökohde:
Yritystason scraping tai tilanteet, joissa tarvitset äärimmäisen luotettavuutta ja skaalautuvuutta.
Go (Golang): nopeaa ja rinnakkaista web-scrapingia
Go on uusi tulokas, mutta se on jo tehnyt vaikutuksen — etenkin nopeatempoisessa, rinnakkaisessa scrapingissa.
Miksi Go?
- Käännetty nopeus: Lähes yhtä nopea kuin C++.
- Sisäänrakennettu rinnakkaisuus: Goroutinejen ansiosta rinnakkainen scraping on helppoa.
- Keskeiset kirjastot: Colly scrapingiin, Goquery parsintaan.
Esimerkkikoodi Golla: sivun otsikon scraping
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Sivun otsikko:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Virhe:", err)
}
}
Vahvuudet:
- Salamannopea ja tehokas laajamittaiseen scrapingiin.
- Helppo ottaa käyttöön (yksi binääri).
- Erinomainen rinnakkaiseen crawlingiin.
Rajoitukset:
- Pienempi yhteisö kuin Pythonilla tai Node.js:llä.
- Vähemmän korkean tason scraping-kirjastoja.
- JavaScript-painotteisten sivustojen käsittely vaatii lisäasetuksia (Chromedp tai Selenium).
Paras käyttökohde:
Kun sinun täytyy scrapata skaalassa tai Python ei yksinkertaisesti ole tarpeeksi nopea. Go vs. Python scrapingissa: suorituskykyvertailu.
Parhaiden ohjelmointikielten vertailu web-scrapingiin
Kootaan kaikki yhteen. Tässä rinnakkainen vertailu, joka auttaa valitsemaan parhaan kielen web-scrapingiin vuonna 2026:
| Kieli/työkalu | Helppokäyttöisyys | Suorituskyky | Kirjastotuki | Dynaamisen sisällön käsittely | Paras käyttötapaus |
|---|---|---|---|---|---|
| Python | Erittäin korkea | Kohtalainen | Erinomainen | Hyvä (Selenium/Playwright) | Yleispuolinen, aloittelijat, data-analyysi |
| JavaScript/Node.js | Keskitaso | Korkea | Vahva | Erinomainen (natiivisti) | Dynaamiset sivustot, async-scraping, web-kehittäjät |
| Ruby | Korkea | Kohtalainen | Kohtuullinen | Rajallinen (Watir) | Nopeat skriptit, prototypointi |
| PHP | Keskitaso | Kohtalainen | Melko hyvä | Rajallinen (Panther) | Palvelinpuoli, web-sovellusintegraatio |
| C++ | Matala | Erittäin korkea | Rajallinen | Hyvin rajallinen | Suorituskykykriittinen, valtava mittakaava |
| Java | Keskitaso | Korkea | Hyvä | Hyvä (Selenium/HtmlUnit) | Yrityskäyttö, pitkään ajettavat palvelut |
| Go (Golang) | Keskitaso | Erittäin korkea | Kasvava | Kohtalainen (Chromedp) | Suurinopeuksinen, rinnakkainen scraping |
Milloin koodaus kannattaa ohittaa: Thunderbit no-code web-scraping-ratkaisuna
Kokeile Thunderbit AI Web Scraperia No-code, tekoälypohjaista web-scrapingia liiketoiminnan käyttäjille, markkinoijille ja myyntitiimeille. Get Started Free
Okei, ollaan rehellisiä: joskus haluat vain datan — ilman koodausta, debuggailua tai sitä tuskaa, kun mietit miksi tämä valitsin ei toimi. Siinä Thunderbit astuu kuvaan.
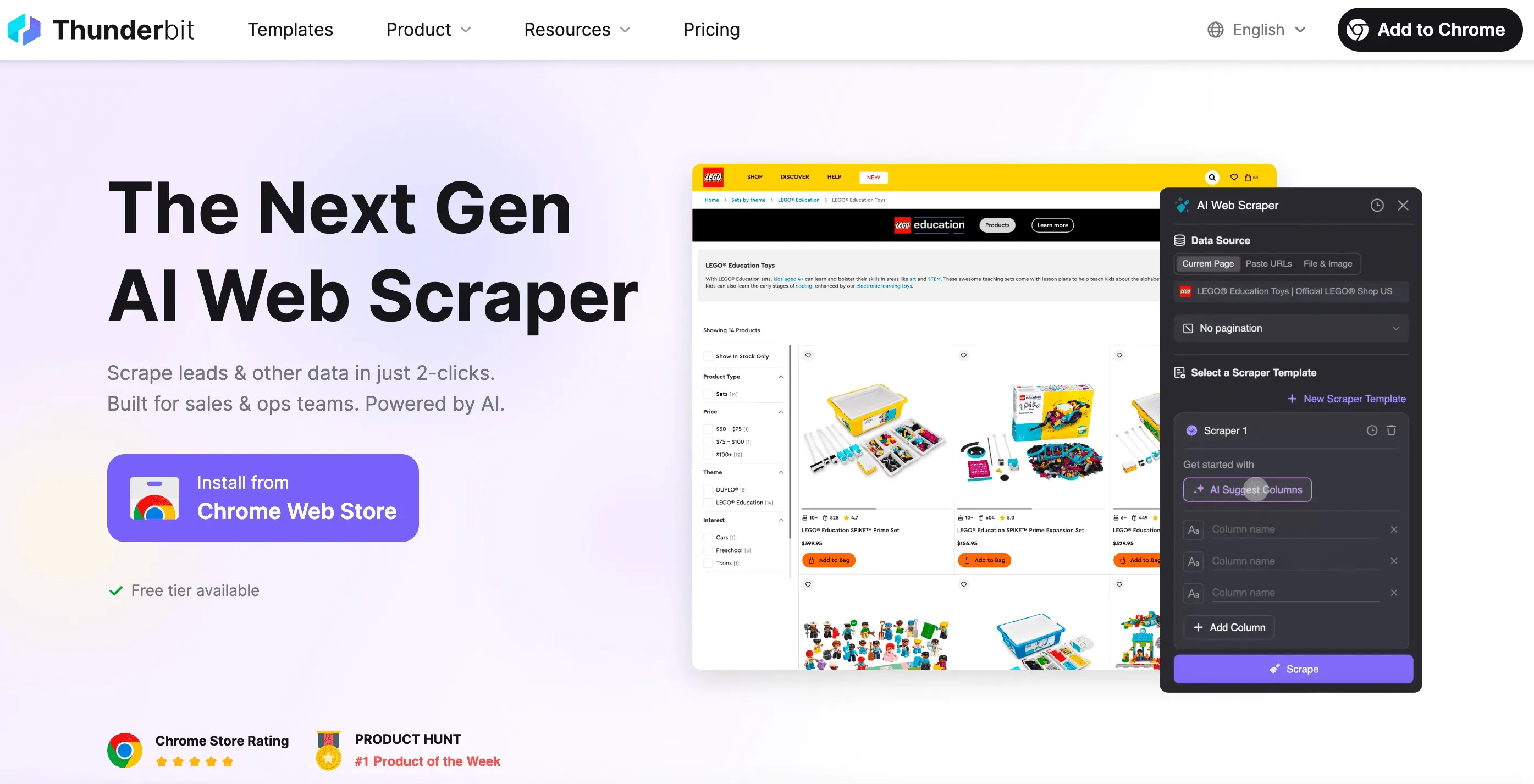
Thunderbitin perustajana halusin rakentaa työkalun, joka tekee web-scrapingista yhtä helppoa kuin ruoan tilaamisesta. Tässä on se, mikä erottaa Thunderbitin muista:
- 2 klikin käyttöönotto: Klikkaa vain “AI Suggest Fields” ja “Scrape”. Ei tarvetta säätää HTTP-pyyntöjen, proxien tai antibotin kikkailun kanssa.
- Älykkäät templatet: Yksi scraper-templaatti voi mukautua useisiin sivuasetteluihin. Scraperia ei tarvitse kirjoittaa uusiksi aina, kun sivusto muuttuu.
- Selain- ja pilviscraping: Valitse joko selaimessa tehtävä scraping (erinomainen kirjautuneille sivuille) tai pilvessä tehtävä scraping (supernopea julkiselle datalle).
- Käsittelee dynaamisen sisällön: Thunderbitin tekoäly ohjaa oikeaa selainta — joten se pystyy käsittelemään loputonta scrollausta, ponnahdusikkunoita, kirjautumisia ja paljon muuta.
- Vie minne haluat: Lataa Exceliin, Google Sheetsiin, Airtableen, Notioniin tai kopioi suoraan leikepöydälle.
- Ei ylläpitoa: Jos sivusto muuttuu, aja vain tekoälyehdotus uudelleen. Ei enää myöhäisillan debuggaussessioita.
- Ajoitus ja automaatio: Aseta scrapersi ajastetusti ajettaviksi — ei cron-töitä, ei palvelinasetuksia.
- Erikoistuneet poimijat: Tarvitsetko sähköposteja, puhelinnumeroita tai kuvia? Thunderbitissä on myös yhden klikin poimijat näihin.
Ja paras osa? Sinun ei tarvitse osata yhtään koodiriviä. Thunderbit on rakennettu liiketoiminnan käyttäjille, markkinoijille, myyntitiimeille, kiinteistöalan ammattilaisille — kenelle tahansa, joka tarvitsee dataa nopeasti.
Haluatko nähdä Thunderbitin käytännössä? Lataa Chrome-laajennus tai katso YouTube-kanavamme demovideoita varten.
Kokeile Thunderbit AI Web Scraperia ilmaiseksi
Yhteenveto: parhaan kielen valinta web-scrapingiin vuonna 2026
Mitä data scraping on ja miten sitä tehdään Get Started Free
Web-scraping vuonna 2026 on helpommin lähestyttävää — ja tehokkaampaa — kuin koskaan. Tässä on se, mitä olen oppinut vuosien automaatiotyöstä:
- Python on yhä paras kieli web-scrapingiin, jos haluat aloittaa nopeasti ja sinulla on paljon materiaalia käden ulottuvilla.
- JavaScript/Node.js on lyömätön dynaamisten, JavaScript-painotteisten sivustojen scrapingissa.
- Ruby ja PHP sopivat erinomaisesti nopeisiin skripteihin ja web-integraatioon, etenkin jos käytät niitä jo valmiiksi.
- C++ ja Go ovat ystäviäsi, kun tarvitset nopeutta ja mittakaavaa.
- Java on ensisijainen valinta yritystason, pitkäkestoisiin projekteihin.
- Entä jos haluat ohittaa koodauksen kokonaan? Thunderbit on salainen aseesi.
Ennen kuin syöksyt mukaan, kysy itseltäsi:
- Kuinka suuri projektini on?
- Tarvitsenko dynaamisen sisällön käsittelyä?
- Mikä on oma tekninen mukavuustasoni?
- Haluanko rakentaa vai vain saada datan?
Kokeile yhtä yllä olevista koodiesimerkeistä tai testaa Thunderbitia seuraavassa projektissasi. Ja jos haluat mennä syvemmälle, kurkkaa Thunderbit Blogiin lisää oppaita, vinkkejä ja oikeita scraping-tarinoita varten.
Hyviä scrapeja — ja toivottavasti datasi on aina puhdasta, jäsenneltyä ja vain klikkauksen päässä.
P.S. Jos joskus löydät itsesi jumissa web-scrapingin kaninkolossa kello 2 yöllä, muista: Thunderbit on aina olemassa. Tai kahvi. Tai molemmat.
Kokeile Thunderbit AI Web Scraperia nyt Get Started Free
UKK
1. Mikä on paras ohjelmointikieli web-scrapingiin vuonna 2026?
Python on edelleen ykkösvalinta luettavan syntaksinsa, tehokkaiden kirjastojensa (kuten BeautifulSoup, Scrapy ja Selenium) ja suuren yhteisönsä ansiosta. Se sopii erinomaisesti sekä aloittelijoille että ammattilaisille, erityisesti kun scrapingia yhdistetään data-analyysiin.
2. Mikä kieli on paras JavaScript-painotteisten sivustojen scrapingiin?
JavaScript (Node.js) on paras valinta dynaamisille sivustoille. Työkalut kuten Puppeteer ja Playwright antavat täyden hallinnan selaimeen, jolloin voit toimia Reactilla, Vuellä tai Angularilla ladatun sisällön kanssa.
3. Onko web-scrapingiin olemassa no-code-vaihtoehtoa?
Kyllä — Thunderbit on no-code AI web scraper, joka hoitaa kaiken dynaamisesta sisällöstä ajoitukseen. Klikkaa vain “AI Suggest Fields” ja aloita scrapaus. Se on täydellinen myynti-, markkinointi- tai operointitiimeille, jotka tarvitsevat jäsenneltyä dataa nopeasti.
4. Tarvitseeko minun silti valita kieli, jos AI-koodausagentti voi kirjoittaa scraperin puolestani?
Reilu kysymys vuonna 2026. Työkalut kuten Claude Code, Cursor ja OpenAI Codex generoivat mielellään Scrapy-hämähäkin, Playwright-skriptin tai Go + Colly -crawlerin yhden kappaleen promptista — joten kitka kysymyksessä “minkä kielen opin ensin” on aidosti pienempi kuin kaksi vuotta sitten. Mutta agentti tuottaa silti koodia jollakin kielellä, ja sinä (tai se, joka perii projektin) päädyt lukemaan, debuggamaan ja julkaisemaan sen. Siksi valinta on edelleen tärkeä; se vaikuttaa vain enemmän ylläpitoon kuin ensimmäisiin 30 riviin. Jos et halua koskea koodiin lainkaan, siihen Thunderbit sopii — se ohittaa kielikysymyksen kokonaan.
Lisää luettavaa:




