
Rikkinäiset linkit. Orvot sivut. Se yksi vuoden 2019 “testisivu”, jonka Google on jostain syystä päättänyt indeksoida. Jos ylläpidät verkkosivustoa, tiedät kyllä tämän tuskan.
Hyvä verkkosivuston crawler nappaa nämä kaikki kiinni — ja piirtää koko sivustosi kartalle, jotta voit oikeasti korjata ongelmat etkä vain arvailla. Silti moni sotkee “web crawlerin” ja “web scraperin”. Ne eivät ole sama asia.
Testasin 10 ilmaista crawleria oikeilla sivustoilla. Osa on timanttisia SEO-auditointeihin. Toiset taas loistavat datan poiminnassa. Tässä mikä toimi — ja mikä ei.
Mikä on verkkosivuston crawler? Perusasiat selkeästi
Tehdään tämä heti selväksi: verkkosivuston crawler ei ole sama kuin web scraper. Tiedän, termejä viljellään ristiin rastiin, mutta kyse on eri työkaluista. Ajattele crawleria sivustosi kartoitusinsinöörinä: se koluaa jokaisen nurkan, seuraa linkit ja rakentaa kokonaiskuvan kaikista sivuista. Sen tehtävä on löytää: kerätä URL-osoitteet, hahmottaa sivustorakenne ja tunnistaa sisältö. Näin toimivat myös hakukoneiden botit, ja samalla tavalla SEO-työkalut tarkistavat sivustosi kunnon ().
Web scraper taas on datan kaivaja. Sitä ei kiinnosta koko kartta — se etsii “kultaa”: tuotehintoja, yritysnimiä, arvosteluja, sähköposteja ja mitä ikinä tarvitset. Scraper poimii tietyt kentät niiltä sivuilta, jotka crawler on löytänyt ().
Pieni vertaus:
- Crawler: henkilö, joka kävelee ruokakaupan jokaisen käytävän läpi ja tekee listan kaikista tuotteista.
- Scraper: henkilö, joka menee suoraan kahvihyllylle ja kirjaa ylös jokaisen luomusekoituksen hinnan.
Miksi tällä on väliä? Koska jos haluat vain löytää kaikki sivustosi sivut (esimerkiksi SEO-auditointia varten), tarvitset crawlerin. Jos taas haluat kerätä kilpailijan sivustolta kaikki tuotehinnat, tarvitset scraperin — tai mieluiten työkalun, joka hoitaa molemmat.
Miksi käyttää online-web crawleria? Keskeiset hyödyt liiketoiminnalle
Miksi crawleriin kannattaa ylipäätään panostaa? Koska web ei ole menossa pienemmäksi. Itse asiassa yli sivustojensa optimointiin, ja osa SEO-työkaluista crawlaa jopa .
Mitä hyötyä crawlerista on käytännössä?
- SEO-auditoinnit: löydä rikkinäiset linkit, puuttuvat otsikot, duplikaatit, orvot sivut ja paljon muuta ().
- Linkkien tarkistus & QA: bongaa 404:t ja uudelleenohjausloopit ennen kuin käyttäjät ehtivät niihin ().
- Sivukarttojen luonti: generoi XML-sitemapit automaattisesti hakukoneita ja suunnittelua varten ().
- Sisältöinventaario: listaa kaikki sivut, niiden hierarkia ja metatiedot.
- Vaatimustenmukaisuus & saavutettavuus: tarkista jokainen sivu WCAG-, SEO- ja lakivaatimusten näkökulmasta ().
- Suorituskyky & tietoturva: liputa hitaat sivut, liian suuret kuvat tai tietoturvaongelmat ().
- Dataa AI:lle ja analytiikalle: syötä crawlatut tiedot analytiikka- tai AI-työkaluihin ().
Tässä nopea taulukko, joka yhdistää käyttötapaukset rooleihin:
| Käyttötapaus | Kenelle sopii | Hyöty / lopputulos |
|---|---|---|
| SEO & sivuston auditointi | Markkinointi, SEO, pienyrittäjät | Löydä tekniset ongelmat, optimoi rakenne, paranna sijoituksia |
| Sisältöinventaario & QA | Sisältövastaavat, webmasterit | Auditoi tai migroi sisältöä, löydä rikkinäiset linkit/kuvat |
| Liidien generointi (scraping) | Myynti, business development | Automatisoi prospektointi, täytä CRM tuoreilla liideillä |
| Kilpailijaseuranta | Verkkokauppa, tuotepäälliköt | Seuraa kilpailijan hintoja, uusia tuotteita, varastotilannetta |
| Sitemap & rakenteen kloonaus | Kehittäjät, DevOps, konsultit | Kloonaa rakenne uudistuksia tai varmuuskopioita varten |
| Sisällön aggregointi | Tutkijat, media, analyytikot | Kerää dataa useilta sivustoilta analyysiin tai trendiseurantaan |
| Markkinatutkimus | Analyytikot, AI-koulutustiimit | Kerää laajoja aineistoja analyysiin tai mallien koulutukseen |
()
Miten valitsimme parhaat ilmaiset verkkosivuston crawler-työkalut
Olen viettänyt lukemattomia iltoja (ja juonut enemmän kahvia kuin kehtaan myöntää) crawler-työkalujen parissa: dokumentaatiota, testiajoja ja vertailuja. Näihin kiinnitin huomiota:
- Tekninen suorituskyky: selviääkö se moderneista sivustoista (JavaScript, kirjautumiset, dynaaminen sisältö)?
- Helppokäyttöisyys: sopiiko myös ei-teknisille käyttäjille vai vaatiiko komentorivitaikuutta?
- Ilmaisen version rajat: onko se oikeasti ilmainen vai pelkkä maistiainen?
- Saatavuus: pilvipalvelu, työpöytäsovellus vai koodikirjasto?
- Erikoisominaisuudet: tarjoaako jotain uniikkia — kuten AI-poimintaa, visuaalisia sivukarttoja tai tapahtumapohjaista crawlingia?
Testasin jokaisen työkalun, luin käyttäjäpalautetta ja vertasin ominaisuuksia rinnakkain. Jos työkalu sai minut harkitsemaan läppärin heittämistä ikkunasta, se ei päässyt listalle.
Pikavertailu: 10 parasta ilmaista verkkosivuston crawleria
| Työkalu & tyyppi | Keskeiset ominaisuudet | Paras käyttötapaus | Tekniset vaatimukset | Ilmaisen version tiedot |
|---|---|---|---|---|
| BrightData (Pilvi/API) | Enterprise-crawling, proxyt, JS-renderöinti, CAPTCHA-ratkaisu | Suurimittainen datankeruu | Teknisestä osaamisesta hyötyä | Ilmainen kokeilu: 3 scrapers, 100 riviä/kpl (noin 300 riviä yhteensä) |
| Crawlbase (Pilvi/API) | API-crawling, anti-bot, proxyt, JS-renderöinti | Kehittäjille taustajärjestelmän crawling-infra | API-integraatio | Ilmainen: ~5 000 API-kutsua 7 päivää, sitten 1 000/kk |
| ScraperAPI (Pilvi/API) | Proxy-kierto, JS-renderöinti, asynkroninen crawl, valmiit endpointit | Kehittäjät, hintaseuranta, SEO-data | Kevyt käyttöönotto | Ilmainen: 5 000 API-kutsua 7 päivää, sitten 1 000/kk |
| Diffbot Crawlbot (Pilvi) | AI-crawl + poiminta, knowledge graph, JS-renderöinti | Rakenteinen data skaalassa, AI/ML | API-integraatio | Ilmainen: 10 000 krediittiä/kk (noin 10k sivua) |
| Screaming Frog (Työpöytä) | SEO-auditointi, linkki/meta-analyysi, sitemap, custom extraction | SEO-auditoinnit, sivuston ylläpito | Työpöytäsovellus, GUI | Ilmainen: 500 URL per crawl, vain perusominaisuudet |
| SiteOne Crawler (Työpöytä) | SEO, suorituskyky, saavutettavuus, tietoturva, offline-export, Markdown | Kehittäjät, QA, migraatiot, dokumentointi | Työpöytä/CLI, GUI | Ilmainen & open-source, 1 000 URL GUI-raportissa (muokattavissa) |
| Crawljax (Java, OpenSrc) | Tapahtumapohjainen crawl JS-sivustoille, staattinen export | Kehittäjät, QA dynaamisille web-sovelluksille | Java, CLI/asetukset | Ilmainen & open-source, ei rajoja |
| Apache Nutch (Java, OpenSrc) | Hajautettu, plugin-pohjainen, Hadoop-integraatio, oma haku | Omat hakukoneet, massiivinen crawl | Java, komentorivi | Ilmainen & open-source, vain infrakustannukset |
| YaCy (Java, OpenSrc) | P2P-crawl & haku, yksityisyys, web/intranet-indeksointi | Yksityinen haku, hajautus | Java, selainkäyttöliittymä | Ilmainen & open-source, ei rajoja |
| PowerMapper (Työpöytä/SaaS) | Visuaaliset sitemapit, saavutettavuus, QA, selainyhteensopivuus | Toimistot, QA, visuaalinen kartoitus | GUI, helppo | Ilmainen kokeilu: 30 päivää, 100 sivua (työpöytä) tai 10 sivua (online) per skannaus |
BrightData: enterprise-tason pilvipohjainen verkkosivuston crawler

BrightData on web crawlingin “raskas sarja”. Se on pilvialusta, jossa on valtava proxy-verkko, JavaScript-renderöinti, CAPTCHA-ratkaisu ja IDE räätälöityihin crawl-ajohin. Jos teet laajamittaista datankeruuta — esimerkiksi seuraat satojen verkkokauppojen hintoja — BrightDatan infra on vaikea päihittää ().
Vahvuudet:
- Selviää tiukoista anti-bot-suojauksista
- Skaalautuu enterprise-tarpeisiin
- Valmiita pohjia yleisille sivustoille
Rajoitukset:
- Ei pysyvää ilmaistasoa (vain kokeilu: 3 scrapers, 100 riviä/kpl)
- Ylilyönti yksinkertaisiin auditointeihin
- Oppimiskynnys ei-teknisille käyttäjille
Jos sinun pitää crawlaa webiä isossa mittakaavassa, BrightData on kuin Formula 1 -auto vuokralle. Älä vain odota, että se pysyy ilmaisena koeajon jälkeen ().
Crawlbase: API-vetoinen ilmainen web crawler kehittäjille

Crawlbase (entinen ProxyCrawl) keskittyy ohjelmalliseen crawlingiin. Kutsut heidän API:a URL:lla, ja saat HTML:n takaisin — proxyt, geokohdistus ja CAPTCHAt hoituvat taustalla ().
Vahvuudet:
- Korkea onnistumisprosentti (99 % +)
- Toimii JavaScript-painotteisilla sivuilla
- Helppo upottaa omiin sovelluksiin ja työnkulkuihin
Rajoitukset:
- Vaatii API- tai SDK-integraatiota
- Ilmainen: ~5 000 API-kutsua 7 päivää, sitten 1 000/kk
Jos olet kehittäjä ja haluat skaalata crawlingia (ja mahdollisesti scrapingia) ilman proxyjen ylläpitoa, Crawlbase on varma valinta ().
ScraperAPI: dynaamisen web crawlingin helpottaja

ScraperAPI on “hae tämä puolestani” -API. Syötät URL:n, ja se hoitaa proxyt, headless-selaimet ja anti-bot-suojaukset, ja palauttaa HTML:n (tai joillekin sivustoille rakenteista dataa). Se on erityisen hyvä dynaamisille sivuille ja tarjoaa varsin reilun ilmaistason ().
Vahvuudet:
- Kehittäjälle todella helppo (yksi API-kutsu)
- Hoitaa CAPTCHAt, IP-estot ja JavaScriptin
- Ilmainen: 5 000 API-kutsua 7 päivää, sitten 1 000/kk
Rajoitukset:
- Ei visuaalisia crawl-raportteja
- Linkkien seuraaminen vaatii oman crawl-logiikan skriptaamista
Jos haluat liittää web crawlingin koodipohjaasi minuuteissa, ScraperAPI on helppo valinta.
Diffbot Crawlbot: automaattinen sivustorakenteen tunnistus

Diffbot Crawlbot menee “älykkääksi”. Se ei vain crawlaa — se käyttää AI:ta sivujen luokitteluun ja rakenteisen datan poimintaan (artikkelit, tuotteet, tapahtumat jne.) JSON-muotoon. Kuin robotti-harjoittelija, joka oikeasti ymmärtää lukemaansa ().
Vahvuudet:
- AI-pohjainen poiminta, ei pelkkä crawling
- Toimii JavaScriptin ja dynaamisen sisällön kanssa
- Ilmainen: 10 000 krediittiä/kk (noin 10k sivua)
Rajoitukset:
- Kehittäjäpainotteinen (API-integraatio)
- Ei visuaalinen SEO-työkalu — enemmän dataprojekteihin
Jos tarvitset rakenteista dataa skaalassa, erityisesti AI:ta tai analytiikkaa varten, Diffbot on tehokas.
Screaming Frog: ilmainen työpöytä-SEO crawler

Screaming Frog on SEO-auditointien klassikko työpöydällä. Ilmaisversio crawlaa jopa 500 URL:ia per skannaus ja näyttää kaiken oleellisen: rikkinäiset linkit, metat, duplikaatit, sitemapit ja paljon muuta ().
Vahvuudet:
- Nopea, perusteellinen ja SEO-piireissä luotettu
- Ei koodausta — syötä URL ja käynnistä
- Ilmainen 500 URL:iin per crawl
Rajoitukset:
- Vain työpöydällä (ei pilviversiota)
- Edistyneet ominaisuudet (JS-renderöinti, ajastus) vaativat maksullisen lisenssin
Jos SEO on sinulle tärkeää, Screaming Frog kuuluu työkalupakkiin — mutta 10 000 sivun sivustoa se ei crawlaa ilmaiseksi.
SiteOne Crawler: staattinen export ja dokumentointi

SiteOne Crawler on teknisten auditointien linkkuveitsi. Se on open-source, toimii useilla alustoilla ja pystyy crawlaamaan, auditoimaan ja jopa viemään sivuston Markdowniksi dokumentointia tai offline-käyttöä varten ().
Vahvuudet:
- Kattaa SEO:n, suorituskyvyn, saavutettavuuden ja tietoturvan
- Vie sivuston arkistointia tai migraatiota varten
- Ilmainen & open-source, ei käyttörajoja
Rajoitukset:
- Teknisempi kuin osa GUI-työkaluista
- GUI-raportti rajattu oletuksena 1 000 URL:iin (muokattavissa)
Jos olet kehittäjä, QA tai konsultti ja haluat syvää näkyvyyttä (ja pidät open sourcesta), SiteOne on todellinen löytö.
Crawljax: open source Java -crawler dynaamisille sivuille
Crawljax on erikoistyökalu: se on tehty moderneille, JavaScript-raskaille web-sovelluksille simuloimalla käyttäjän toimintoja (klikkaukset, lomakkeiden täytöt jne.). Se on tapahtumapohjainen ja voi jopa tuottaa dynaamisesta sivustosta staattisen version ().
Vahvuudet:
- Erinomainen SPA- ja AJAX-sivustojen crawlingiin
- Open-source ja laajennettavissa
- Ei käyttörajoja
Rajoitukset:
- Vaatii Javaa sekä ohjelmointia/asetusten säätöä
- Ei sovi ei-teknisille käyttäjille
Jos sinun pitää crawlaa React- tai Angular-sovellus “oikean käyttäjän” tavoin, Crawljax on hyvä kumppani.
Apache Nutch: skaalautuva hajautettu verkkosivuston crawler

Apache Nutch on open source -crawlerien “klassikko”. Se on suunniteltu valtaviin, hajautettuihin crawl-ajohin — esimerkiksi oman hakukoneen rakentamiseen tai miljoonien sivujen indeksointiin ().
Vahvuudet:
- Skaalautuu miljardeihin sivuihin Hadoopin avulla
- Erittäin muokattava ja laajennettava
- Ilmainen & open-source
Rajoitukset:
- Jyrkkä oppimiskäyrä (Java, komentorivi, konfiguraatiot)
- Ei pienille sivustoille tai satunnaiseen käyttöön
Jos haluat crawlaa webiä isossa mittakaavassa etkä säikähdä komentoriviä, Nutch on siihen tehty.
YaCy: vertaisverkkoon perustuva web crawler ja hakukone
YaCy on omalaatuinen, hajautettu crawler ja hakukone. Jokainen instanssi crawlaa ja indeksoi sivustoja, ja voit liittyä P2P-verkkoon jakamaan indeksejä muiden kanssa ().
Vahvuudet:
- Yksityisyys edellä, ei keskitettyä palvelinta
- Sopii yksityisen tai intranet-haun rakentamiseen
- Ilmainen & open-source
Rajoitukset:
- Tulokset riippuvat verkon kattavuudesta
- Vaatii hieman käyttöönottoa (Java, selainkäyttöliittymä)
Jos hajautus kiinnostaa tai haluat oman hakukoneen, YaCy on todella mielenkiintoinen vaihtoehto.
PowerMapper: visuaalinen sitemap-generaattori UX:ään ja QA:han

PowerMapper keskittyy sivustorakenteen visualisointiin. Se crawlaa sivuston ja luo interaktiivisia sivukarttoja, ja lisäksi se tarkistaa saavutettavuuden, selainyhteensopivuuden ja SEO-perusasiat ().
Vahvuudet:
- Visuaaliset sitemapit ovat loistavia toimistoille ja suunnittelijoille
- Tarkistaa saavutettavuuden ja vaatimustenmukaisuuden
- Helppo GUI, ei teknistä osaamista
Rajoitukset:
- Vain kokeilu (30 päivää, 100 sivua työpöydällä / 10 sivua verkossa per skannaus)
- Täysversio on maksullinen
Jos sinun pitää esitellä sivukartta asiakkaalle tai tarkistaa compliance, PowerMapper on kätevä.
Näin valitset oikean ilmaisen web crawlerin
Kun vaihtoehtoja on paljon, miten valita? Tässä nopea ohje:
- SEO-auditointeihin: Screaming Frog (pienet sivustot), PowerMapper (visuaalinen), SiteOne (syvä auditointi)
- Dynaamisiin web-sovelluksiin: Crawljax
- Suurimittaiseen crawlingiin tai omaan hakuun: Apache Nutch, YaCy
- Kehittäjille, jotka tarvitsevat API:n: Crawlbase, ScraperAPI, Diffbot
- Dokumentointiin tai arkistointiin: SiteOne Crawler
- Enterprise-mittakaavaan kokeilulla: BrightData, Diffbot
Tärkeimmät valintakriteerit:
- Skaalautuvuus: kuinka suuri sivusto tai crawl-työ on?
- Helppous: haluatko koodata vai klikata?
- Vienti: tarvitsetko CSV/JSON-muotoa tai integraatioita?
- Tuki: löytyykö yhteisöä tai ohjeita, jos jumitut?
Kun web crawling kohtaa web scrapingin: miksi Thunderbit on fiksumpi valinta
Rehellisesti: harva tekee web crawlingia vain saadakseen “kivan kartan”. Useimmiten tavoite on saada rakenteista dataa — tuotelistoja, yhteystietoja tai sisältöinventaarioita. Tässä kohtaa astuu kuvaan.
Thunderbit ei ole pelkkä crawler tai scraper — se on AI-pohjainen Chrome-laajennus, joka yhdistää molemmat. Näin se toimii:
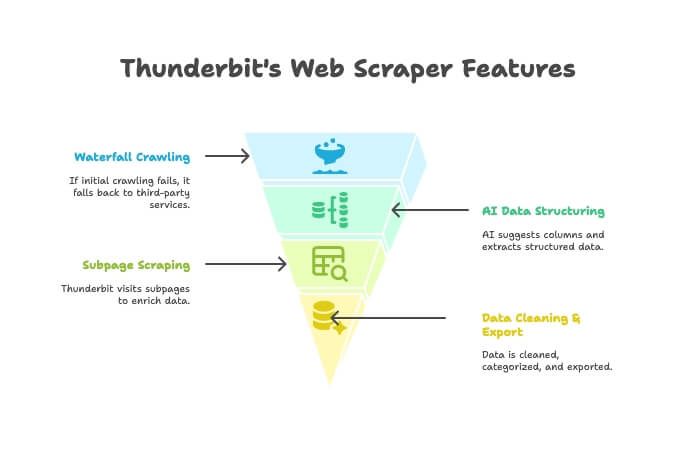
- AI Crawler: Thunderbit tutkii sivustoa crawlerin tavoin.
- Waterfall Crawling: jos Thunderbitin oma moottori ei saa sivua auki (esim. tiukka anti-bot), se vaihtaa automaattisesti kolmannen osapuolen crawling-palveluihin — ilman käsisäätöä.
- AI-datan jäsentäminen: kun HTML on saatu, Thunderbitin AI ehdottaa oikeat sarakkeet ja poimii rakenteisen datan (nimet, hinnat, sähköpostit jne.) ilman, että kirjoitat yhtään selektoria.
- Alasivujen scraping: tarvitsetko tiedot jokaiselta tuotesivulta? Thunderbit voi käydä automaattisesti jokaisella alasivulla ja rikastaa taulukkoa.
- Datan siivous & vienti: voit tiivistää, luokitella, kääntää ja viedä datan Exceliin, Google Sheetsiin, Airtableen tai Notioniin yhdellä klikkauksella.
- No-code-helppous: jos osaat käyttää selainta, osaat käyttää Thunderbitia. Ei koodausta, ei proxyja, ei päänsärkyä.
Milloin Thunderbit kannattaa valita perinteisen crawlerin sijaan?
- Kun lopputavoite on siisti, käyttökelpoinen taulukko — ei pelkkä URL-lista.
- Kun haluat automatisoida koko ketjun (crawl, poimi, siivoa, vie) yhdessä paikassa.
- Kun arvostat aikaa ja hermoja.
Voit ja nähdä itse, miksi niin moni yrityskäyttäjä vaihtaa siihen.
Yhteenveto: miten saat eniten irti ilmaisista verkkosivuston crawlereista
Verkkosivuston crawlerit ovat kehittyneet valtavasti. Olitpa markkinoija, kehittäjä tai vain henkilö, joka haluaa pitää sivuston kunnossa, sinulle löytyy ilmainen (tai ainakin ilmaiseksi kokeiltava) työkalu. Enterprise-tason alustoista kuten BrightData ja Diffbot, open source -helmistä kuten SiteOne ja Crawljax, aina visuaalisiin kartoittajiin kuten PowerMapper — vaihtoehtoja on enemmän kuin koskaan.
Mutta jos etsit fiksumpaa ja integroidumpaa tapaa päästä “tarvitsen tämän datan” -tilasta “tässä on taulukko” -tilaan, kokeile Thunderbitia. Se on tehty yrityskäyttäjille, jotka haluavat tuloksia — eivät pelkkiä raportteja.
Valmiina aloittamaan? Lataa työkalu, aja skannaus ja katso, mitä olet missannut. Ja jos haluat muuttaa crawlingin toiminnalliseksi dataksi kahdella klikkauksella, .
Lisää käytännön oppaita ja syväluotauksia löydät .
UKK
Mikä ero on verkkosivuston crawlerilla ja web scraperilla?
Crawler löytää ja kartoittaa sivuston kaikki sivut (kuin sisällysluettelo). Scraper poimii tietyt tietokentät (kuten hinnat, sähköpostit tai arvostelut) näiltä sivuilta. Crawler löytää, scraper kaivaa ().
Mikä ilmainen web crawler sopii parhaiten ei-teknisille käyttäjille?
Pienille sivustoille ja SEO-auditointeihin Screaming Frog on helppo. Visuaaliseen kartoitukseen PowerMapper toimii hyvin kokeilun aikana. Thunderbit on helpoin, jos tavoitteena on rakenteinen data ja haluat no-code-kokemuksen suoraan selaimessa.
Estävätkö jotkin sivustot web crawlerit?
Kyllä — osa sivustoista käyttää robots.txt-tiedostoja tai anti-bot-suojauksia (kuten CAPTCHAt tai IP-estot) estääkseen crawlingin. Työkalut kuten ScraperAPI, Crawlbase ja Thunderbit (waterfall crawling) pystyvät usein kiertämään näitä, mutta crawlaa aina vastuullisesti ja kunnioita sivuston sääntöjä ().
Onko ilmaisissa verkkosivuston crawlereissa sivu- tai ominaisuusrajoja?
Useimmissa on. Esimerkiksi Screaming Frogin ilmaisversio on rajattu 500 URL:iin per crawl; PowerMapperin kokeilu 100 sivuun. API-työkaluissa on usein kuukausittaiset krediittirajat. Open source -työkaluissa kuten SiteOne tai Crawljax ei yleensä ole kovia rajoja, mutta laitteistosi asettaa käytännön rajat.
Onko web crawlerin käyttö laillista ja tietosuojan mukaista?
Yleisesti ottaen julkisten verkkosivujen crawling on laillista, mutta tarkista aina sivuston käyttöehdot ja robots.txt. Älä koskaan crawlaa yksityistä tai salasanasuojattua dataa ilman lupaa, ja huomioi tietosuojalainsäädäntö, jos poimit henkilötietoja ().