
Vuonna 2015 tiedon kaapiminen tarkoitti sitä, että piti pyytää kehittäjää kirjoittamaan Python-skripti tai käyttää viikonloppu XPathin opetteluun. Vuonna 2026 kirjoitat vain: “nouda kaikki tuotteen nimet ja hinnat”, ja AI hoitaa loput.
Tuo muutos tapahtui nopeasti. Yli nojaa nyt web-kaappaukseen. Markkina ylitti ja on matkalla kaksinkertaistumaan vuoteen 2030 mennessä.
Suurin ajuri? AI-web-crawlerit. Ne mukautuvat sivuasettelun muutoksiin. Ne ymmärtävät sivun sisällön, eivät vain HTML-tageja. Ja ne toimivat ihmisille, jotka eivät ole koskaan kirjoittaneet riviäkään koodia.
Olen käyttänyt kuukausia testaten 15:ta niistä. Tässä on, mitä löysin — mukaan lukien miksi Thunderbit (kyllä, yritys jonka perustin yhdessä) vei ykkössijan.
Miksi AI mullistaa verkkosivujen kaappaamisen: web-kaavintatyökalujen uusi aikakausi
Ollaan rehellisiä: perinteinen web-kaappaus ei koskaan ollut tavallisen liiketoiminnan käyttäjän työkalu. Kaikki pyöri koodin, valitsijoiden ja toiveiden varassa — ja siinä toivottiin, ettei skripti hajoaisi seuraavan sivustopäivityksen jälkeen. Mutta AI ja LLM:t ovat kääntäneet asetelman täysin päälaelleen.
Näin:
- Luonnollisen kielen ohjeet: Koodin kanssa säätämisen sijaan kerrot vain AI:lle, mitä haluat. Työkalut kuten ymmärtävät selkeät ohjeesi ja hoitavat kaappauksen puolestasi ().
- Mukautuva oppiminen: AI-kaapimet voivat , mikä vähentää ylläpitotarvetta.
- Dynaamisen sisällön käsittely: Nykysivustot rakastavat JavaScriptiä ja loputonta vieritystä. AI-pohjaiset työkalut osaavat käsitellä nämä elementit ja poimia dataa, jonka vanhan koulukunnan kaapimet jättäisivät huomaamatta.
- Rakenteinen tuloste AI-jäsennyksellä: LLM-pohjaiset kaapimet oikeasti ja tuottavat siistiä, rakenteista dataa.
- Automaattinen bot-suojauksen kierto: AI-kaapimet voivat ja käyttää prokseja/headless-selaimia IP-estojen välttämiseksi.
- Integroidut datatyönkulut: Parhaat työkalut eivät vain hae dataa — ne toimittavat sen sinne, missä sitä tarvitset, yhdellä klikkauksella Google Sheetsiin, Airtableen, Notioniin ja muualle ().
Mitä tästä seuraa? Web-kaappaus on nyt piste ja klikkaus -kokemus — tai jopa chat-tyylinen — ja se tuo verkkodatan suoraan myynnin, markkinoinnin ja operatiivisten tiimien käyttöön, ei vain kehittäjille.
15 AI-web-crawleria, joihin kannattaa kiinnittää huomiota vuonna 2026
Käydään läpi 15 parasta AI-web-crawleria Thunderbitistä alkaen. Kerron kunkin työkalun keskeiset ominaisuudet, kohdekäyttäjät, hinnoittelun ja sen, mikä tekee siitä erottuvan. Ja kyllä, olen rehellinen siitä, missä kukin loistaa — ja missä se ehkä ei loista.
1. Thunderbit: AI-web-kaavin kaikille
Olen tässä luonnollisesti hieman puolueellinen, mutta Thunderbit on AI-web-kaavin, jonka olisin toivonut olleen käytössä jo vuosia sitten. Tässä syyt, miksi se on tämän listan ykkönen:
- Luonnollisen kielen poiminta: “Keskustelet” Thunderbitin kanssa. Kuvaile vain haluamasi data — esimerkiksi “kaavi tältä sivulta kaikki tuotteiden nimet ja hinnat” — ja AI hoitaa loput (). Ei koodia, ei valitsijoita, ei päänsärkyä.
- Alasivujen ja monitasoinen kaappaus: Thunderbit voi . Esimerkiksi voit kaapia tuoteluettelon ja avata sitten jokaisen tuotteen tiedot — kaikki yhdellä kertaa.
- Välitön rakenteinen tuloste: AI , ehdottaa olennaisia kenttiä, yhtenäistää formaatteja ja jopa tiivistää tai luokittelee tekstiä.
- Laaja lähdetuki: Thunderbit ei rajoitu HTML:ään — se voi poimia tietoa PDF:istä ja kuvista sisäänrakennetun OCR:n ja vision AI:n avulla ().
- Liiketoiminta-integraatiot: Yhden klikkauksen vienti Google Sheetsiin, Airtableen, Notioniin tai Exceliin (). Ajasta kaappaukset ja ohjaa data suoraan tiimisi työnkulkuun.
- Valmiit mallipohjat: Sivustoille kuten Amazon, LinkedIn, Zillow jne. Thunderbit tarjoaa yhden klikkauksen tiedonpoimintaa varten.
- Helppokäyttöinen ja saavutettava: Käyttöliittymä on piste- ja klikkauspohjainen, ja avustaja on intuitiivinen. Käyttäjät pääsevät vauhtiin minuuteissa.

Thunderbitiin luottaa yli , mukaan lukien tiimit Accenturella, Grammarlylla ja Pumalla. Myyntitiimit käyttävät sitä , kiinteistönvälittäjät kokoavat kohdelistoja ja markkinoijat seuraavat kilpailijoita — kaikki ilman, että tarvitsisi kirjoittaa riviäkään koodia.
Hinnoittelu: Saatavilla on (jopa 100 vaihetta kuukaudessa), ja maksulliset paketit alkavat 14,99 dollarista kuukaudessa. Jopa pro-paketit ovat edullisia yksittäisille käyttäjille ja pienille tiimeille.
Thunderbit on lähimpänä sitä, mitä olen nähnyt “webin muuttamisessa tietokannaksi” — ja se on rakennettu kaikille, ei vain insinööreille.
2. Crawl4AI
Kenelle se sopii: Kehittäjille ja teknisille tiimeille, jotka rakentavat omia putkia.
Crawl4AI on avoimen lähdekoodin, Python-pohjainen kehys, joka on optimoitu nopeuteen ja laajamittaiseen kaappaukseen, ja se on rakennettu . Se on erittäin nopea, tukee headless-selaimia dynaamista sisältöä varten ja pystyy jäsentämään kaapatun datan helposti AI-työnkulkuihin syötettäväksi.
- Paras kohde: Kehittäjille, jotka tarvitsevat tehokkaan ja muokattavan kaappausmoottorin.
- Hinnoittelu: Ilmainen (MIT-lisenssi). Sinun täytyy itse hostata ja ajaa se.
3. ScrapeGraphAI
Kenelle se sopii: Kehittäjille ja analyytikoille, jotka rakentavat AI-agentteja tai monimutkaisia dataputkia.
ScrapeGraphAI on prompt-ohjattu, avoimen lähdekoodin Python-kirjasto, joka muuntaa verkkosivustot rakenteisiksi data-“graafeiksi” LLM:ien avulla. Voit kirjoittaa promptin kuten “poimi kaikkien ensimmäisten 5 sivun tuotteen nimet, hinnat ja arvostelut”, ja se rakentaa sinulle kaappaustyönkulun ().
- Paras kohde: Teknisille käyttäjille, jotka haluavat joustavaa, prompt-pohjaista kaappausta.
- Hinnoittelu: Avoimen lähdekoodin kirjasto on ilmainen; pilvi-API alkaa 20 dollarista kuukaudessa.
4. Firecrawl
Kenelle se sopii: Kehittäjille, jotka rakentavat AI-agentteja tai laajamittaisia dataputkia.
Firecrawl on AI-keskeinen kaappausalusta ja API, joka muuntaa kokonaiset verkkosivustot “LLM-valmiiksi” dataksi (). Se tuottaa Markdownia tai JSONia, käsittelee dynaamista sisältöä ja integroituu frameworkeihin kuten LangChain ja LlamaIndex.
- Paras kohde: Kehittäjille, joiden täytyy syöttää reaaliaikaista verkkodataa AI-malleihin.
- Hinnoittelu: Avoimen lähdekoodin ydin on ilmainen; pilvipaketit alkavat 19 dollarista kuukaudessa.
5. Browse AI
Kenelle se sopii: Liiketoiminnan käyttäjille, growth-hackereille ja analyytikoille.
Browse AI on no-code-alusta, jossa on . “Koulutat” robotin klikkaamalla haluamaasi dataa, ja AI yleistää mallin tulevia kaappauksia varten. Se käsittelee kirjautumiset, loputtoman vierityksen ja voi seurata sivustojen muutoksia.
- Paras kohde: Ei-teknisille käyttäjille, jotka haluavat automatisoida datankeruun ja seurannan.
- Hinnoittelu: Ilmainen suunnitelma (50 krediittiä/kk); maksulliset paketit alkavat 19 dollarista kuukaudessa.
6. LLM Scraper
Kenelle se sopii: Kehittäjille, jotka haluavat AI:n hoitavan jäsentämisen.
LLM Scraper on avoimen lähdekoodin JavaScript/TypeScript-kirjasto, jonka avulla voit ja antaa LLM:n poimia kyseisen datan miltä tahansa verkkosivulta. Se perustuu Playwrightiin, tukee useita LLM-toimittajia ja voi jopa generoida uudelleenkäytettävää koodia.
- Paras kohde: Kehittäjille, jotka haluavat muuntaa minkä tahansa verkkosivun rakenteiseksi dataksi LLM:ien avulla.
- Hinnoittelu: Ilmainen (MIT-lisenssi).
7. Reader (Jina Reader)
Kenelle se sopii: Kehittäjille, jotka rakentavat LLM-sovelluksia, chatbotteja tai tiivistäjiä.
Jina Reader on API, joka poimii , ja palauttaa LLM-valmista Markdownia tai JSONia. Se toimii räätälöidyn AI-mallin pohjalta ja voi jopa lisätä kuvatekstit.
- Paras kohde: Siistin, luettavan sisällön hakemiseen LLM:ille tai Q&A-järjestelmille.
- Hinnoittelu: Ilmainen API (peruskäyttöön ei tarvita avainta).
8. Bright Data
Kenelle se sopii: Yrityksille ja ammattikäyttäjille, jotka tarvitsevat skaalautuvuutta, vaatimustenmukaisuutta ja luotettavuutta.
Bright Data on web-datateollisuuden raskassarjalainen, jolla on massiivinen proxy-verkosto ja . Se tarjoaa valmiita kaapimia, yleisen Web Scraper API:n ja “LLM-valmiita” datasyötteitä.
- Paras kohde: Organisaatioille, jotka tarvitsevat luotettavaa web-dataa suuressa mittakaavassa.
- Hinnoittelu: Käyttöpohjainen, premium-tasoinen. Ilmaisia kokeiluja saatavilla.
9. Octoparse
Kenelle se sopii: Ei-teknisille ja puoliteknisille käyttäjille.
Octoparse on vakiintunut no-code-työkalu, jossa on ja AI-pohjainen automaattinen tunnistus. Se käsittelee kirjautumiset, loputtoman vierityksen ja voi viedä dataa eri muodoissa.
- Paras kohde: Analyytikoille, pienyrittäjille tai tutkijoille.
- Hinnoittelu: Ilmainen taso saatavilla; maksulliset paketit alkavat 119 dollarista kuukaudessa.
10. Apify
Kenelle se sopii: Kehittäjille ja teknisille tiimeille, jotka tarvitsevat räätälöityä kaappausta/automaatioita.
Apify on pilvialusta kaappausskriptien (“actors”) ajamiseen, ja se tarjoaa . Se on skaalautuva, integroituu AI:hin ja tukee proxy-hallintaa.
- Paras kohde: Kehittäjille, jotka haluavat ajaa omia skriptejään pilvessä.
- Hinnoittelu: Ilmainen taso; käyttöön perustuvat maksulliset paketit alkavat 49 dollarista kuukaudessa.
11. Zyte (Scrapy Cloud)
Kenelle se sopii: Kehittäjille ja yrityksille, jotka tarvitsevat enterprise-tason kaappausta.
Zyte on Scrapyn takana oleva yritys, joka tarjoaa pilvialustan ja . Se hoitaa ajastuksen, proxyt ja laajamittaiset projektit.
- Paras kohde: Dev-tiimeille, jotka pyörittävät pitkäkestoisia kaappausprojekteja.
- Hinnoittelu: Ilmaisista kokeiluista räätälöityihin enterprise-paketteihin.
12. Webscraper.io
Kenelle se sopii: Aloittelijoille, journalisteille ja tutkijoille.
on piste- ja klikkauspohjaiseen datanpoimintaan. Se on yksinkertainen, ilmainen paikalliseen käyttöön ja tarjoaa pilvipalvelun suurempiin töihin.
- Paras kohde: Nopeisiin, kertaluonteisiin kaappaustehtäviin.
- Hinnoittelu: Ilmainen laajennus; pilvipaketit alkavat noin 50 dollarista kuukaudessa.
13. ParseHub
Kenelle se sopii: Ei-teknisille käyttäjille, jotka tarvitsevat enemmän tehoa kuin perusvälineet tarjoavat.
ParseHub on työpöytäsovellus, jossa on visuaalinen työnkulku dynaamisen sisällön kaappaamiseen, mukaan lukien kartat ja lomakkeet. Se voi ajaa projekteja pilvessä ja tarjoaa API:n.
- Paras kohde: Digimarkkinoijille, analyytikoille ja journalisteille.
- Hinnoittelu: Ilmainen taso (200 sivua/ajo); maksulliset paketit alkavat 189 dollarista kuukaudessa.
14. Diffbot
Kenelle se sopii: Yrityksille ja AI-yhtiöille, jotka tarvitsevat laajamittaista rakenteista verkkodataa.
Diffbot käyttää tietokonenäköä ja NLP:tä miltä tahansa verkkosivulta. Se tarjoaa API:t artikkeleille, tuotteille ja massiiviselle tietograafille.
- Paras kohde: Markkinatiedon, rahoituksen ja AI-koulutusdatan tarpeisiin.
- Hinnoittelu: Premium, alkaen noin 299 dollarista kuukaudessa.
15. DataMiner
Kenelle se sopii: Ei-teknisille käyttäjille, erityisesti myynnissä, markkinoinnissa ja journalismissa.
DataMiner on nopeaan, piste- ja klikkauspohjaiseen web-datan poimintaan. Siinä on kirjasto valmiita “reseptejä”, ja se voi viedä tiedot suoraan Google Sheetsiin.
- Paras kohde: Nopeisiin tehtäviin, kuten taulukoiden tai listojen viemiseen taulukoihin.
- Hinnoittelu: Ilmainen taso (500 sivua/päivä); Pro alkaa noin 19 dollarista kuukaudessa.
Parhaiden AI-web-kaavintyökalujen vertailu: mikä sopii sinulle?
Tässä korkean tason vertailu, joka auttaa löytämään sopivan vaihtoehdon:
| Työkalu | AI/LLM:n käyttö | Käytön helppous | Tuloste/integraatio | Paras kohde | Hinnoittelu |
|---|---|---|---|---|---|
| Thunderbit | Luonnollisen kielen käyttöliittymä; AI ehdottaa kentät | Helpoin (no-code-chat) | Sheets-, Airtable- ja Notion-viennit | Ei-tekniset tiimit | Ilmainen taso; Pro noin 30 $/kk |
| Crawl4AI | AI-valmis kaappaus; LLM-integraatiot | Vaikea (Python-koodi) | Kirjasto/CLI; integrointi koodilla | Kehittäjät, jotka tarvitsevat nopeita AI-dataputkia | Ilmainen |
| ScrapeGraphAI | LLM-prompt-putket kaapaukseen | Keskitaso (jonkin verran koodausta tai API) | API/SDK; JSON-tuloste | Kehittäjät/analyytikot, jotka rakentavat AI-agentteja | Ilmainen OSS; API 20 $+/kk |
| Firecrawl | Kaappaa LLM-valmiiksi Markdowniksi/JSONiksi | Keskitaso (API/SDK-käyttö) | SDK:t (Py, Node jne.); LangChain-integraatio | Kehittäjät, jotka syöttävät live-verkkodataa AI:lle | Ilmainen + maksullinen pilvi |
| Browse AI | AI-avusteinen piste ja klikkaus | Helppo (no-code) | Yli 7000 sovellusintegraatiota (Zapier) | Ei-tekniset käyttäjät, jotka automatisoivat sivustojen seurantaa | Ilmainen 50 ajoa; maksullinen 19 $+/kk |
| LLM Scraper | Käyttää LLM:iä sivun jäsentämiseen skeemaksi | Vaikea (TS/JS-koodi) | Koodikirjasto; JSON-tuloste | Kehittäjät, jotka haluavat AI:n hoitavan jäsentämisen | Ilmainen (käytä omaa LLM-API:a) |
| Reader (Jina) | AI-malli poimii tekstiä/JSONia | Helppo (yksinkertainen API-kutsu) | REST API palauttaa Markdownin/JSONin | Kehittäjät, jotka lisäävät web-haun/sisällön LLM:iin | Ilmainen API |
| Bright Data | AI:lla tehostetut kaappausta API:t; laaja proxy-verkko | Vaikea (API, tekninen) | API:t/SDK:t; datasyötteet tai aineistot | Yritystason käyttö | Käyttöpohjainen |
| Octoparse | AI tunnistaa listat automaattisesti | Kohtalainen (no-code-sovellus) | CSV/Excel, API tuloksille | Puolitekniset käyttäjät | Ilmainen rajoitetusti; 59–166 $/kk |
| Apify | Joitakin AI-ominaisuuksia (Actors, AI-oppaat) | Vaikea (koodiscriptit) | Kattava API; integraatiot LangChainin kanssa | Kehittäjät, jotka tarvitsevat räätälöityä kaappausta pilvessä | Ilmainen taso; pay-as-you-go |
| Zyte (Scrapy) | ML-pohjainen automaattipoiminta; Scrapy-kehys | Vaikea (Python-koodi) | API, Scrapy Cloud UI; JSON/CSV | Dev-tiimit, pitkäkestoiset projektit | Räätälöity hinnoittelu |
| Webscraper.io | Ei AI:ta (manuaaliset mallipohjat) | Helppo (selaimen laajennus) | CSV-lataus, Cloud API | Aloittelijat, nopeat kertakaappaukset | Ilmainen laajennus; pilvi noin 50 $/kk |
| ParseHub | Ei eksplisiittistä LLM:ää; visuaalinen rakentaja | Kohtalainen (no-code-sovellus) | JSON/CSV; API pilviajoille | Ei-kehittäjät, jotka kaapivat monimutkaisia sivustoja | Ilmainen 200 sivua; maksullinen 189 $+/kk |
| Diffbot | AI-näkö/NLP mille tahansa sivulle; tietograafi | Helppo (pelkät API-kutsut) | API:t (Article/Prod/...) + Knowledge Graph -kyselyt | Yritykset, rakenteinen web-data | Alkaa noin 299 $/kk |
| DataMiner | Ei LLM:ää; yhteisön reseptit | Helpoin (selaimen UI) | Excel/CSV-vienti; Google Sheets | Ei-tekniset käyttäjät, jotka kaappaavat dataa taulukkoihin | Ilmainen rajoitetusti; Pro noin 19 $/kk |
Työkalukategoriat: kehittäjien tehovälineistä liiketoimintaystävällisiin kaapimiin
Jotta tämä lista olisi helpompi hahmottaa, jaetaan työkalut muutamaan kategoriaan:
1. Kehittäjien ja avoimen lähdekoodin tehotyökalut
- Esimerkkejä: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Vahvuudet: Korkea joustavuus, skaala ja muokattavuus. Erinomainen omien putkien rakentamiseen tai AI-mallien integrointiin.
- Kompromissit: Vaativat koodaustaitoja ja enemmän konfigurointia.
- Käyttötapaukset: Oman dataputken rakentaminen, monimutkaisten sivustojen kaappaus tai integraatio sisäisiin järjestelmiin.
2. AI-integroidut kaappausagentit
- Esimerkkejä: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Vahvuudet: Kaventavat kuilua kaappauksen ja datan ymmärtämisen välillä. Luonnollisen kielen käyttöliittymät tekevät niistä helposti lähestyttäviä.
- Kompromissit: Osa on vielä kehittymässä; ne eivät välttämättä tarjoa täysin tarkkaa kontrollia.
- Käyttötapaukset: Nopeat vastaukset tai aineistot, autonomisten agenttien rakentaminen tai live-datan syöttäminen LLM:ille.
3. No-code/low-code-liiketoimintaystävälliset kaapimet
- Esimerkkejä: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Vahvuudet: Käyttäjäystävällisiä, vähän tai ei lainkaan koodausta, hyviä säännöllisiin liiketoimintatehtäviin.
- Kompromissit: Saattaa olla vaikeuksia erittäin monimutkaisten sivustojen tai massiivisen skaalan kanssa.
- Käyttötapaukset: Liidien generointi, kilpailijoiden seuranta, tutkimusprojektit ja kertaluonteiset datanpoiminnat.
4. Yritysdatan alustat ja palvelut
- Esimerkkejä: Bright Data, Diffbot, Zyte
- Vahvuudet: Täyden pinon ratkaisut, hallinnoidut palvelut, vaatimustenmukaisuus ja skaalautuva luotettavuus.
- Kompromissit: Korkeampi hinta, enemmän käyttöönottoa.
- Käyttötapaukset: Suurivolyymiset, jatkuvasti käynnissä olevat dataputket, markkinatieto ja AI-koulutusdata.
Kuinka valitset oikean AI-web-crawlerin verkkosivujen kaappaustarpeisiin
Oikean työkalun valitseminen voi tuntua ylivoimaiselta, joten tässä vaiheittainen opas:
- Määritä tavoitteesi ja datatarpeesi: Mitä sivustoja ja dataa tarvitset? Kuinka usein? Kuinka paljon? Mitä aiot tehdä sillä?
- Arvioi tekninen osaamisesi: Ei koodausta? Kokeile Thunderbitiä, Browse AI:ta tai Octoparsea. Pientä skriptausta? LLM Scraper tai DataMiner. Vahvat dev-taidot? Crawl4AI, Apify tai Zyte.
- Harkitse toistuvuutta ja skaalaa: Kertaluonteinen? Käytä ilmaisia työkaluja. Toistuva? Etsi ajastusominaisuuksia. Suuri skaala? Yritystyökalut tai avoimen lähdekoodin ratkaisut skaalassa.
- Budjetti ja hinnoittelumalli: Ilmaiset suunnitelmat ovat hyviä testaamiseen. Tilaus vs. käyttöperusteinen riippuu tarpeistasi.
- Kokeilu ja proof of concept: Testaa muutamaa työkalua omalla datallasi. Useimmilla on ilmainen taso.
- Ylläpito ja tuki: Kuka korjaa asiat, jos sivusto muuttuu? AI:lla varustetut no-code-työkalut voivat korjata pienet muutokset automaattisesti; avoin lähdekoodi nojaa sinuun tai yhteisöön.
- Kohdista työkalut käyttötapauksiin: Myyntitiimi kaivaa liidejä? Thunderbit tai Browse AI. Tutkija kerää twiittejä? DataMiner tai . AI-malli tarvitsee uutisartikkeleita? Jina Reader tai Zyte. Rakennat vertailusivustoa? Apify tai Zyte.
- Suunnittele vararatkaisu: Joskus yksi työkalu ei toimi jollakin tietyllä sivustolla. Pidä varavaihtoehto.
“Oikea” työkalu on se, joka tuottaa tarvitsemasi datan mahdollisimman vähällä kitkalla ja budjettisi puitteissa. Joskus se on useamman työkalun yhdistelmä.
Thunderbit vs. perinteiset web-kaavintatyökalut: mikä tekee siitä erottuvan?
Katsotaan tarkemmin, miksi Thunderbit on erilainen:
- Luonnollisen kielen käyttöliittymä: Ei koodia, ei piste- ja klikkausakrobatiaa. Kuvaile vain, mitä haluat ().
- Nolla-asennusta ja mallipohjaehdotuksia: Thunderbit tunnistaa automaattisesti sivutuksen, alasivut ja jopa ehdottaa mallipohjia yleisille sivustoille ().
- AI-pohjainen datan siivous ja rikastus: Tiivistä, luokittele, käännä ja rikasta dataa samalla kun kaivat sitä ().
- Vähemmän ylläpitohuolia: Thunderbitin AI kestää pieniä sivustomuutoksia paremmin, joten rikkoutumisia tulee harvemmin.
- Liiketoimintatyökalujen integraatio: Suora vienti Google Sheetsiin, Airtableen ja Notioniin — ei enää CSV-säätöä ().
- Nopeus arvoksi: Vie ideasta dataan minuuteissa, ei päivissä.
- Oppimiskynnys: Jos osaat selata verkkoa ja kuvailla, mitä tarvitset, osaat käyttää Thunderbitiä.
- Mukautuvuus: Kaavi verkkosivustoja, PDF:iä, kuvia ja paljon muuta — samalla työkalulla.
Thunderbit ei ole vain kaavin — se on data-avustaja, joka istuu työkulkuusi, olitpa sitten myynnissä, markkinoinnissa, verkkokaupassa tai kiinteistöalalla.
Verkkosivujen kaappauksen parhaat käytännöt AI-web-kaapimilla
Jotta saat AI-web-kaapimista kaiken irti, tässä parhaat vinkkini:
- Määrittele datatarpeesi selkeästi: Tiedä, mitä kenttiä haluat, kuinka monta sivua ja missä muodossa tarvitset datan.
- Hyödynnä AI-ehdotuksia: Käytä työkalujen kenttätunnistusta ja AI-ehdotuksia tärkeän datan löytämiseen, jonka muuten saattaisit ohittaa ().
- Aloita pienestä ja validoi: Testaa pienellä otoksella, tarkista tuloste ja säädä tarvittaessa.
- Käsittele dynaaminen sisältö: Varmista, että työkalusi tukee dynaamista sisältöä ja vuorovaikutuksia (sivutus, loputon vieritys jne.).
- Kunnioita sivuston sääntöjä: Tarkista robots.txt, vältä arkaluonteisen datan kaappaamista ja noudata käyttörajoja.
- Integroi automaatioon: Käytä vientiominaisuuksia ja webhooksia liittääksesi kaapatun datan suoraan työnkulkuusi.
- Pidä datan laatu kunnossa: Tee datalle järkevyystarkistuksia, käytä jälkikäsittelyä ja seuraa virheitä.
- Ole napakka prompteissa: Kun käytät AI-ohjattuja työkaluja, selkeät ja täsmälliset ohjeet tuottavat parempia tuloksia.
- Opi yhteisöltä: Liity foorumeille ja yhteisöihin saadaksesi vinkkejä ja vianmääritysapua.
- Pysy ajan tasalla: AI-työkalut kehittyvät nopeasti — seuraa uusia ominaisuuksia ja parannuksia.
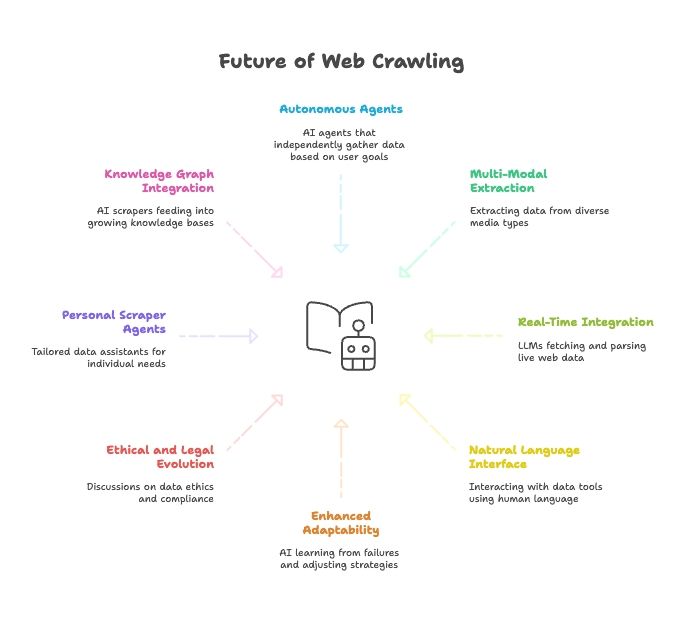
Web-kaappauksen tulevaisuus: AI, LLM:t ja luonnollisen kielen web-kaappausagenttien nousu
Tulevaisuutta kohti mentäessä AI:n ja web-kaappauksen yhdistyminen vain kiihtyy:
- Täysin autonomiset kaappausagentit: Pian kerrot vain AI-agentille lopullisen tavoitteesi, ja se selvittää, miten data hankitaan.
- Monimodaalinen tiedonpoiminta: Kaapimet hakevat dataa tekstistä, kuvista, PDF:istä ja jopa videoista.
- Reaaliaikainen integraatio AI-malleihin: LLM:iin tulee sisäänrakennettuja moduuleja live-verkkodatan hakemiseen ja jäsentämiseen.
- Luonnollinen kieli kaikkialla: Keskustelemme datatyökalujemme kanssa kuten ihmisten kanssa, mikä tekee tiedon keruusta ja muuntamisesta kaikkien saavutettavissa olevaa.
- Parantunut mukautuvuus: AI-kaapimet oppivat epäonnistumisista ja mukauttavat strategioitaan automaattisesti.
- Eettinen ja juridinen kehitys: Odotettavissa on enemmän keskustelua datan etiikasta, vaatimustenmukaisuudesta ja reilusta käytöstä.
- Henkilökohtaiset kaappausagentit: Kuvittele henkilökohtainen data-avustaja, joka kerää uutisia, työpaikkailmoituksia ja muuta juuri sinun tarpeisiisi räätälöitynä.
- Integraatio tietograafeihin: AI-kaapimet syöttävät jatkuvasti dataa yhä kasvaviin tietopohjiin ja tehostavat älykkäämpää AI:ta.
Yhteenveto? Web-kaappauksen tulevaisuus on sidoksissa AI:n tulevaisuuteen. Työkalut muuttuvat älykkäämmiksi, autonomisemmiksi ja helpommin lähestyttäviksi joka päivä.
Yhteenveto: liiketoiminta-arvon vapauttaminen oikealla AI-web-crawlerilla
Web-kaappaus on AI:n ansiosta siirtynyt kapeasta teknisestä taidosta keskeiseksi liiketoimintakyvykkyydeksi. Nämä 15 työkalua edustavat sitä, mikä on mahdollista vuonna 2026 — kehittäjien tehomonsterista liiketoimintaystävällisiin avustajiin.
Todellinen salaisuus? Oikean työkalun valinta voi kasvattaa merkittävästi web-datasta saatavaa arvoa. Ei-teknisille tiimeille Thunderbit on helpoin tapa muuttaa verkko rakenteiseksi, analyysivalmiiksi tietokannaksi — ei koodia, ei säätöä, vain tuloksia.
Joten keräätpä liidejä, seuraat kilpailijoita tai syötät dataa seuraavan sukupolven AI-malliin, käytä aikaa tarpeidesi arviointiin, testaa muutamaa työkalua ja katso, mikä toimii sinulle. Ja jos haluat kokea web-kaappauksen tulevaisuuden jo tänään, . Tarvitsemasi oivallukset ovat vain promptin päässä.
Kiinnostuitko lisää? Tutustu syväluotauksia, ohjeita ja uusinta AI-pohjaista tiedonpoimintaa varten.
Lisälukemista:
Usein kysytyt kysymykset
1. Mikä on AI-web-crawler ja miten se eroaa perinteisistä web-kaapimista?
AI-web-crawler käyttää luonnollisen kielen käsittelyä ja koneoppimista ymmärtääkseen, poimiakseen ja rakentaakseen web-dataa. Toisin kuin perinteiset kaapimet, jotka vaativat manuaalista koodausta ja XPath-valitsimia, AI-työkalut voivat käsitellä dynaamista sisältöä, mukautua sivuasettelun muutoksiin ja tulkita käyttäjän ohjeita selkeällä kielellä.
2. Kenen pitäisi käyttää AI-web-kaappaustyökaluja kuten Thunderbit?
Thunderbit on rakennettu sekä ei-teknisille että teknisille käyttäjille. Se sopii erinomaisesti myynnin, markkinoinnin, operaatioiden, tutkimuksen ja verkkokaupan ammattilaisille, jotka haluavat poimia rakenteista dataa verkkosivuilta, PDF:istä tai kuvista — ilman koodin kirjoittamista.
3. Mitkä ominaisuudet tekevät Thunderbitistä erottuvan muihin AI-web-crawlereihin verrattuna?
Thunderbit tarjoaa luonnollisen kielen käyttöliittymän, monitasoisen kaappauksen, automaattisen datan rakenteistamisen, OCR-tuen ja saumattomat viennit alustoille kuten Google Sheets ja Airtable. Siihen sisältyy myös AI-pohjaisia kenttäehdotuksia ja valmiita mallipohjia suosittuja sivustoja varten.
4. Onko vuonna 2026 saatavilla ilmaisia AI-web-kaappausvaihtoehtoja?
Kyllä. Monet työkalut, kuten Thunderbit, Browse AI ja DataMiner, tarjoavat ilmaisia suunnitelmia rajoitetulla käytöllä. Kehittäjille avoimen lähdekoodin vaihtoehdot kuten Crawl4AI ja ScrapeGraphAI tarjoavat täyden toiminnallisuuden ilman kustannuksia, vaikka ne vaativat teknistä käyttöönottoa.
5. Miten valitsen tarpeisiini sopivan AI-web-crawlerin?
Aloita määrittelemällä datatavoitteesi, tekninen osaamisesi, budjettisi ja skaalaustarpeesi. Jos haluat no-code- ja helppokäyttöisen ratkaisun, Thunderbit tai Browse AI ovat erinomaisia valintoja. Suurimittaiseen tai räätälöityyn käyttöön sopivat paremmin työkalut kuten Apify tai Bright Data.