

Ollaan rehellisiä: Amazon on käytännössä koko internetin ostoskeskus, supermarketti ja elektroniikkaliike yhdessä paketissa. Jos työskentelet myynnin, verkkokaupan tai operaatioiden parissa, tiedät jo, että se, mitä Amazonissa tapahtuu, ei jää vain Amazonin sisälle — se vaikuttaa hinnoitteluusi, varastoihisi ja jopa seuraavan ison tuotelanseerauksesi suunnitelmiin. Mutta tässä on koukku: kaikki nuo herkulliset tuotetiedot, hinnat, arviot ja arvostelut ovat piilossa selainkäyttöliittymän takana, joka on tehty ostajille, ei dataa janoaville tiimeille. Miten siis saat tiedot haltuusi ilman että käytät viikonloppuasi kopioimiseen ja liittämiseen niin kuin olisi vuosi 1999?
Siksi web scraping tulee kuvaan. Tässä oppaassa näytän kaksi tapaa poimia Amazonin tuotetietoja: perinteisen “kääri hihat ja koodaa se Pythonilla” -tavan sekä modernin “anna AI:n hoitaa raskas työ” -tavan käyttämällä no code -web scraperia, kuten Thunderbitiä. Käyn läpi oikeaa Python-koodia kaikkine sudenkuoppeineen ja kiertotapoineen, ja sitten näytän, miten Thunderbit saa samat tiedot vain parilla klikkauksella — ilman koodausta. Olitpa kehittäjä, liiketoiminta-analyytikko tai vain joku, joka on kyllästynyt manuaaliseen tiedonsyöttöön, tästä löytyy sinulle ratkaisu.
Miksi Amazonin tuotetietoja kannattaa poimia? (amazon scraper python, web scraping with python)
Amazon ei ole vain maailman suurin verkkokauppias — se on myös maailman suurin avoin paikka kilpailutiedon keräämiseen. Kun siellä on yli 600 miljoonaa listattua tuotetta ja lähes 2 miljoonaa aktiivista myyjää, Amazon on aarreaitta kaikille, jotka haluavat:

- Seurata hintoja (ja säätää omia hintoja reaaliajassa)
- Analysoida kilpailijoita (seurata uusia julkaisuja, arvioita ja arvosteluja)
- Generoida liidejä (löytää myyjiä, toimittajia tai jopa mahdollisia kumppaneita)
- Ennustaa kysyntää (seuraamalla varastotasoja ja myyntisijoituksia)
- Tunnistaa markkinatrendejä (kaivamalla arvosteluja ja hakutuloksia)
Eikä kyse ole vain teoriasta — oikeat yritykset näkevät oikeaa ROI:ta. Esimerkiksi eräs elektroniikkakauppias käytti Amazonin hinnoitteludataa nostaakseen katteitaan 15 %, kun taas toinen brändi näki 4 %:n myynnin kasvun ja 30 % vähemmän analyytikon työaikaa automatisoituaan kilpailijoiden hintaseurannan.
Tässä on nopea taulukko käyttötapauksista ja siitä, millaista ROI:ta voit odottaa:
| Käyttötapaus | Kuka käyttää | Tyypillinen ROI / hyöty |
|---|---|---|
| Hintaseuranta | Verkkokauppa, operaatio | 15 %+ parannus katteessa, 4 % myynnin kasvu, 30 % vähemmän analyytikon aikaa |
| Kilpailija-analyysi | Myynti, tuote, operaatio | Nopeammat hinnansäädöt, parempi kilpailukyky |
| Markkinatutkimus (arvostelut) | Tuote, markkinointi | Nopeampi tuotekehitys, parempi mainosteksti, SEO-näkemyksiä |
| Liidien generointi | Myynti | 3 000+ liidiä/kk, 8+ tuntia säästettyä aikaa myyjää kohden viikossa |
| Varasto- ja kysyntäennuste | Operaatio, toimitusketju | 20 % vähemmän ylivarastoa, vähemmän loppuneita tuotteita |
| Trendien tunnistaminen | Markkinointi, johto | Kuumien tuotteiden ja kategorioiden varhainen havaitseminen |
Ja tässä varsinainen pointti: yli 90 % organisaatioista raportoi nyt mitattavaa arvoa data-analytiikasta. Jos et poimi dataa Amazonista, jätät oivalluksia — ja rahaa — pöydälle.
Yhteenveto: Amazon Scraper Python vs. no code -web scraper -työkalut
Amazon-datan saa ulos selaimesta ja taulukoihin tai dashboardeihin kahdella pääkeinolla:
-
Amazon Scraper Python (web scraping with python):
Kirjoitat oman skriptin Python-kirjastoilla, kuten Requests ja BeautifulSoup. Tämä antaa sinulle täyden kontrollin, mutta sinun täytyy osata koodata, käsitellä bottisuojauksia ja ylläpitää skriptiäsi Amazonin muuttaessa sivustoaan.
-
No code -web scraper -työkalut (kuten Thunderbit):
Käytät työkalua, jossa osoitat, klikkaat ja poimit datan — ilman ohjelmointia. Nykyaikaiset työkalut, kuten Thunderbit, käyttävät jopa AI:ta päättämään, mitä dataa poimia, käsittelevät alasivut ja sivutuksen sekä vievät tiedot suoraan Exceliin tai Google Sheetiin.
Näin ne vertautuvat:
| Kriteeri | Python-scraper | No code (Thunderbit) |
|---|---|---|
| Käyttöönottoaika | Korkea (asennus, koodi, debuggaus) | Matala (asennus, laajennus) |
| Tarvittava osaaminen | Koodaustaito vaaditaan | Ei tarvita (osoita ja klikkaa) |
| Joustavuus | Rajaton | Korkea yleisissä käyttötapauksissa |
| Ylläpito | Korjaat koodin itse | Työkalu päivittyy itse |
| Bottisuojauksen käsittely | Hoidat proxyt ja otsakkeet itse | Sisäänrakennettu, hoidettu puolestasi |
| Skaalautuvuus | Manuaalinen (säikeet, proxyt) | Pilviscraping, rinnakkaistettu |
| Datan vienti | Räätälöity (CSV, Excel, tietokanta) | Yhdellä klikkauksella Exceliin, Sheetiin |
| Kustannus | Ilmainen (aikasi + proxyt) | Freemium, maksu skaalasta |
Seuraavissa osioissa käyn läpi molemmat lähestymistavat — ensin miten rakennat Amazon-scraperin Pythonilla (oikealla koodilla), sitten miten teet saman Thunderbitin AI web scraperilla.
Aloittaminen Amazon Scraper Pythonilla: vaatimukset ja käyttöönotto
Ennen kuin sukellamme koodiin, laitetaan ympäristö kuntoon.
Tarvitset:
- Python 3.x (lataa python.org-sivustolta)
- Koodieditorin (pidän VS Codesta, mutta mikä tahansa käy)
- Seuraavat kirjastot:
requests(HTTP-pyyntöihin)beautifulsoup4(HTML:n jäsentämiseen)lxml(nopea HTML-jäsentäjä)pandas(datariveihin ja vientiin)re(säännöllisiin lausekkeisiin, sisäänrakennettu)
Asenna kirjastot:
pip install requests beautifulsoup4 lxml pandas
Projektin käyttöönotto:
- Luo uusi kansio projektille.
- Avaa editori, luo uusi Python-tiedosto (esim.
amazon_scraper.py). - Olet valmis aloittamaan!
Vaihe vaiheelta: web scraping Pythonilla Amazonin tuotetiedoille
Käydään läpi yhden Amazonin tuotesivun scrappaaminen. (Älä huoli, pääsemme pian myös useiden tuotteiden ja sivujen scrappaamiseen.)
1. Pyyntöjen lähettäminen ja HTML:n hakeminen
Ensimmäiseksi haetaan tuotesivun HTML. (Korvaa URL millä tahansa Amazonin tuotteella.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Huom: Tämä peruspyyntö todennäköisesti estetään Amazonin toimesta. Saatat nähdä 503-virheen tai CAPTCHA:n tuotesivun sijaan. Miksi? Koska Amazon tietää, ettet ole oikea selain.
Amazonin bottisuojausten käsittely
Amazon ei pidä boteista. Välttääksesi eston, sinun täytyy:
- Asettaa User-Agent-otsake (esiinny Chromena tai Firefoxina)
- Vaihdella User-Agent-arvoja (älä käytä aina samaa)
- Hidastaa pyyntöjäsi (lisää satunnaisia viiveitä)
- Käyttää proxyja (laajamittaiseen scrappaukseen)
Näin asetat otsakkeet:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
Haluatko tehdä tästä hieman kehittyneemmän? Käytä User-Agent-listaa ja vaihtele sitä jokaisessa pyynnössä. Suurempiin urakoihin kannattaa käyttää proxy-palvelua (niitä on paljon), mutta pienemmässä mittakaavassa otsakkeet ja viiveet riittävät yleensä hyvin.
Keskeisten tuotetietojen poimiminen
Kun HTML on käsissäsi, on aika jäsentää se BeautifulSoupilla.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Poimitaan nyt tärkeimmät tiedot:
Tuotteen nimi
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Hinta
Amazonin hinta voi sijaita useassa paikassa. Kokeile näitä:
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Arvosana ja arvostelujen määrä
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # esim. "1,554 ratings"
Pääkuvan URL
Amazon piilottaa joskus korkearesoluutioiset kuvat HTML:n sisällä olevaan JSONiin. Tässä nopea regex-lähestymistapa:
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
Tai poimi pääkuva-tagista:
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Tuotetiedot
Tekniset tiedot, kuten merkki, paino ja mitat, löytyvät yleensä taulukosta:
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
Tai jos Amazon käyttää “detailBullets”-muotoa:
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Tulosta tulokset:
print("Otsikko:", product_title)
print("Hinta:", price)
print("Arvosana:", rating, "perustuen", reviews_count, "arvosteluun")
print("Pääkuvan URL:", main_image_url)
print("Tiedot:", details)
Useiden tuotteiden scrappaaminen ja sivutuksen käsittely
Yksi tuote on kiva, mutta todennäköisesti haluat koko listan. Näin scrappaat hakutuloksia ja useita sivuja.
Poimi tuotelinkit hakusivulta
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Käsittele sivutus
Amazonin hakutulosten URL-osoitteissa käytetään &page=2, &page=3 jne.
for page in range(1, 6): # scrape first 5 pages
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... poimi tuotelinkit kuten yllä ...
Käy tuotesivut läpi ja vie tiedot CSV:ksi
Kerää tuotetiedot sanakirjalistaan ja käytä sitten pandasia:
import pandas as pd
df = pd.DataFrame(product_data_list) # list of dicts
df.to_csv("amazon_products.csv", index=False)
Tai Exceliin:
df.to_excel("amazon_products.xlsx", index=False)
Parhaat käytännöt Amazon Scraper Python -projekteihin
Totuus on, että Amazon muuttaa sivustoaan jatkuvasti ja taistelee scrappereita vastaan. Näin pidät projektin toiminnassa:
- Vaihtele otsakkeita ja User-Agent-arvoja (käytä kirjastoa, kuten
fake-useragent) - Käytä proxyja laajamittaiseen scrappaukseen
- Hidasta pyyntöjä (satunnainen
time.sleep()pyyntöjen välissä) - Käsittele virheet siististi (yritä uudelleen 503-virheen jälkeen, hidasta tahtia jos saat eston)
- Kirjoita joustava jäsentelylogiikka (etsi useita valitsimia per kenttä)
- Seuraa HTML-muutoksia (jos skripti palauttaa yhtäkkiä kaikkeen
None, tarkista sivu) - Noudata robots.txt:tä (Amazon kieltää scrappauksen monista osioista — toimi vastuullisesti)
- Puhdista data lennossa (poista valuuttasymbolit, pilkut ja välilyönnit)
- Pysy yhteydessä yhteisöön (foorumit, Stack Overflow, Redditin r/webscraping)
Tarkistuslista scrapperisi ylläpitoon:
- Vaihda User-Agent-arvoja ja otsakkeita
- Käytä proxyja, jos scrappaat isossa mittakaavassa
- Lisää satunnaisia viiveitä
- Jaa koodi moduuleihin, jotta sitä on helppo päivittää
- Seuraa estoja ja CAPTCHA:ja
- Vie data säännöllisesti
- Dokumentoi valitsimet ja logiikka
Syvempää perehdytystä varten katso oppaani web scrapingista Pythonilla.
No code -vaihtoehto: Amazonin scrappaus Thunderbit AI Web Scraperilla
Scrapaa Amazonin tuotetiedot AI:n avulla Get Started Free
Okei, nyt olet nähnyt Python-tavan. Mutta entä jos et halua koodata — tai haluat vain saada datan kahdella klikkauksella ja jatkaa elämääsi? Silloin Thunderbit astuu kuvaan.
Thunderbit on AI web scraper -Chrome-laajennus, jolla voit poimia Amazonin tuotetietoja (ja käytännössä miltä tahansa sivustolta) ilman koodausta. Tässä syyt, miksi pidän siitä:
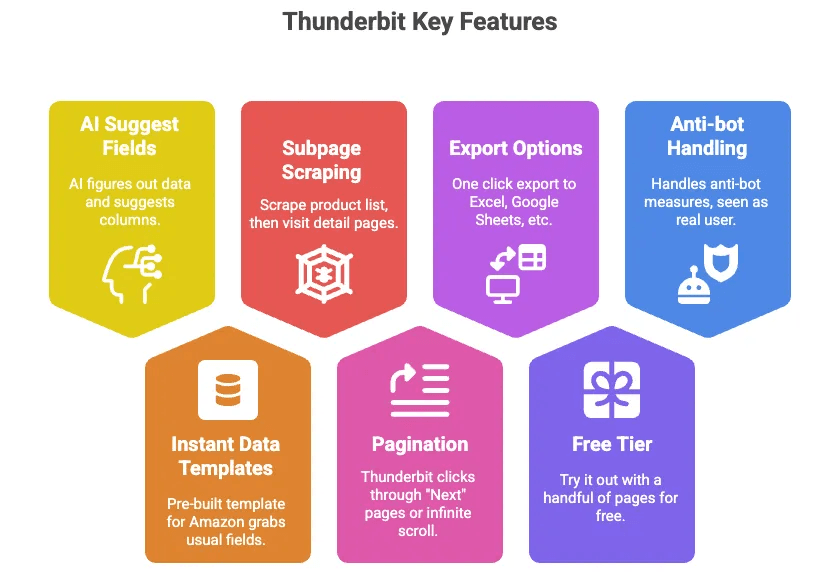
- AI ehdottaa kentät: Paina vain nappia, ja Thunderbitin AI päättelee, mitä dataa sivulla on, ja ehdottaa sarakkeita (kuten nimi, hinta, arvosana jne.).
- Välittömät datamallit: Amazonille on valmiiksi rakennettu malli, joka hakee kaikki tavalliset kentät — ei käyttöönottoa.
- Alasivujen scrappaus: Scrappaa tuoteluettelo ja anna Thunderbitin vierailla jokaisen tuotteen sivulla ja poimia lisätiedot automaattisesti.
- Sivutus: Thunderbit voi klikata puolestasi “Seuraava”-sivuja tai loputonta vieritystä.
- Vienti Exceliin, Google Sheetiin, Airtableen, Notioniin: Yhdellä klikkauksella data on käyttövalmista.
- Ilmainen taso: Kokeile useita sivuja ilmaiseksi.
- Hoitaa bottisuojauksen puolestasi: Koska se toimii selaimessasi (tai pilvessä), Amazon näkee sen oikeana käyttäjänä.
Vaihe vaiheelta: Thunderbitin käyttö Amazonin tuotetietojen scrappaamiseen
Näin helppoa se on:
-
Asenna Thunderbit:
Lataa Thunderbit Chrome -laajennus ja kirjaudu sisään.
-
Avaa Amazon:
Siirry Amazon-sivulle, jonka haluat scrapeata (hakutulokset, tuotesivu, mitä ikinä).
-
Klikkaa “AI Suggest Fields” tai käytä mallia:
Thunderbit ehdottaa poimittavia sarakkeita (tai voit valita Amazon Product -mallin).
-
Tarkista sarakkeet:
Säädä sarakkeita haluamallasi tavalla (lisää/poista kenttiä, nimeä uudelleen jne.).
-
Klikkaa “Scrape”:
Thunderbit hakee sivun datan ja näyttää sen taulukossa.
-
Käsittele alasivut ja sivutus:
Jos scrappasit listan, klikkaa “Scrape Subpages” vieraillaksesi jokaisen tuotteen sivulla ja poimiaksesi lisää tietoa. Thunderbit voi myös klikata puolestasi “Next”-sivuja automaattisesti.
-
Vie data:
Klikkaa “Export to Excel” tai “Export to Google Sheets.” Valmista.
-
(Valinnainen) Ajoita scrappaus:
Tarvitsetko tämän datan joka päivä? Käytä Thunderbitin ajastinta automatisointiin.
Siinä kaikki. Ei koodia, ei debuggausta, ei proxyja, ei päänsärkyä. Visuaalista läpikäyntiä varten katso Thunderbitin YouTube-kanava tai Amazon Product Scraper -mallisivu.
Kokeile Amazon Product Scraper -mallia
Amazon Scraper Python vs. no code -web scraper: vertailu rinnakkain
Kootaan kaikki yhteen:
| Kriteeri | Python-scraper | Thunderbit (No Code) |
|---|---|---|
| Käyttöönottoaika | Korkea (asennus, koodi, debuggaus) | Matala (asennus, laajennus) |
| Tarvittava osaaminen | Koodaustaito vaaditaan | Ei tarvita (osoita ja klikkaa) |
| Joustavuus | Rajaton | Korkea yleisissä käyttötapauksissa |
| Ylläpito | Korjaat koodin itse | Työkalu päivittyy itse |
| Bottisuojauksen käsittely | Hoidat proxyt ja otsakkeet itse | Sisäänrakennettu, hoidettu puolestasi |
| Skaalautuvuus | Manuaalinen (säikeet, proxyt) | Pilviscraping, rinnakkaistettu |
| Datan vienti | Räätälöity (CSV, Excel, tietokanta) | Yhdellä klikkauksella Exceliin, Sheetiin |
| Kustannus | Ilmainen (aikasi + proxyt) | Freemium, maksu skaalasta |
| Paras kenelle | Kehittäjät, räätälöidyt tarpeet | Liiketoiminnan käyttäjät, nopeat tulokset |
Jos olet kehittäjä, joka rakastaa säätämistä ja tarvitsee jotain todella räätälöityä, Python on sinun kaverisi. Jos haluat nopeutta, yksinkertaisuutta ja nolla koodausta, Thunderbit on oikea valinta.
Milloin valita Python, no code tai AI web scraper Amazon-datalle
Valitse Python, jos:
- Tarvitset räätälöityä logiikkaa tai haluat integroida scrappauksen backend-järjestelmiisi
- Scrappaat todella suuressa mittakaavassa (kymmeniä tuhansia tuotteita)
- Haluat oppia, miten scraping toimii konepellin alla
Valitse Thunderbit (no code, AI web scraper), jos:
- Haluat dataa nopeasti ilman koodausta
- Olet liiketoimintakäyttäjä, analyytikko tai markkinoija
- Haluat, että tiimisi voi hankkia dataa itse
- Haluat välttää proxien, bottisuojauksen ja ylläpidon vaivan
Käytä molempia, jos:
- Haluat prototypoida nopeasti Thunderbitillä ja rakentaa sitten räätälöidyn Python-ratkaisun tuotantoon
- Haluat käyttää Thunderbitiä datan keräämiseen ja Pythonia datan puhdistamiseen/analysointiin
Useimmille liiketoimintakäyttäjille Thunderbit kattaa 90 % Amazon-scrappaustarpeista murto-osassa ajasta. Jäljelle jäävään 10 %:iin — superräätälöityyn, laajamittaiseen tai syvälle integroitavaan tekemiseen — Python on yhä kuningas.
Yhteenveto ja tärkeimmät opit
Näin scrappaat Amazonin tuotteet ja arvostelut AI:lla vuonna 2025 Get Started Free
Amazonin tuotetietojen scrappaus on supervoima jokaiselle myynti-, verkkokauppa- tai operaatiotiimille. Seuraatpa hintoja, analysoit kilpailijoita tai vain yrität säästää tiimisi loputtomalta kopioi-liitä-rumbalta, sinulle löytyy ratkaisu.
- Python-scraping antaa täyden kontrollin, mutta sisältää oppimiskäyrän ja jatkuvaa ylläpitoa.
- No code -web scraperit, kuten Thunderbit, tekevät Amazon-datan poimimisesta kaikkien ulottuvilla olevaa — ei koodausta, ei päänsärkyä, vain tuloksia.
- Paras lähestymistapa? Käytä työkalua, joka sopii taitoihisi, aikatauluusi ja liiketoimintatavoitteisiisi.
Jos olet utelias, kokeile Thunderbitiä — alkuun pääsee ilmaiseksi, ja tulet hämmästymään siitä, kuinka nopeasti saat tarvitsemasi datan. Ja jos olet kehittäjä, älä pelkää yhdistellä työkaluja: joskus nopein tapa rakentaa on antaa AI:n hoitaa tylsät osat puolestasi.
Hanki Thunderbit Chrome -laajennus
Usein kysytyt kysymykset
1. Miksi yrityksen kannattaisi scrappata Amazonin tuotetietoja?
Amazonin scrappaus antaa yrityksille mahdollisuuden seurata hintoja, analysoida kilpailijoita, kerätä arvosteluja tuotekehitystä varten, ennustaa kysyntää ja generoida myyntiliidejä. Kun Amazonissa on yli 600 miljoonaa tuotetta ja lähes 2 miljoonaa myyjää, se on rikas lähde kilpailutiedolle.
2. Mitkä ovat tärkeimmät erot Pythonin ja no code -työkalujen, kuten Thunderbitin, välillä Amazonin scrappauksessa?
Python-scraperit tarjoavat maksimaalisen joustavuuden, mutta vaativat koodaustaitoja, käyttöönottoaikaa ja jatkuvaa ylläpitoa. Thunderbit, no code -AI web scraper, antaa käyttäjille mahdollisuuden poimia Amazon-dataa välittömästi Chrome-laajennuksen kautta — ilman koodausta, sisäänrakennetulla bottisuojausten käsittelyllä ja vientiominaisuuksilla Exceliin tai Sheetiin.
3. Onko Amazonin datan scrappaaminen laillista?
Amazonin käyttöehdot yleensä kieltävät scrappauksen, ja he käyttävät aktiivisesti bottisuojauksia. Monet yritykset kuitenkin scrappaavat edelleen julkisesti saatavilla olevaa dataa vastuullisesti, esimerkiksi kunnioittamalla pyyntörajoja ja välttämällä liiallisia pyyntöjä.
4. Millaisia tietoja voin poimia Amazonista web scraping -työkaluilla?
Yleisiä kenttiä ovat tuotteen nimi, hinta, arvosanat, arvostelujen määrä, kuvat, tuotetiedot, saatavuus ja jopa myyjätiedot. Thunderbit tukee myös alasivujen scrappausta ja sivutusta, jotta data saadaan talteen useilta listoilta ja sivuilta.
5. Milloin minun kannattaa valita Python-scraping Thunderbitin kaltaisen työkalun sijaan — tai päinvastoin?
Valitse Python, jos tarvitset täyden kontrollin, räätälöityä logiikkaa tai aiot integroida scrappauksen backend-järjestelmiin. Valitse Thunderbit, jos haluat nopeita tuloksia ilman koodausta, tarvitset helppoa skaalautuvuutta tai olet liiketoimintakäyttäjä ja etsit vähän ylläpitoa vaativaa ratkaisua.
Haluatko mennä syvemmälle? Katso nämä resurssit:
- Thunderbit Blogi
- Mitä on datan scrappaus ja miten se tehdään vuonna 2025
- Näin scrappaat Amazonin tuotteet ja arvostelut AI:lla vuonna 2025
- Opas web scrapingiin Pythonilla
Hyviä scrappauksia — ja olkoot taulukkosi aina ajan tasalla.
Kokeile Thunderbit AI Web Scraperia Amazonille Get Started Free




