Wikipedia Search Result Scraper
Vil du hente data i bulk? Prøv Thunderbit gratis.








Collect Wikipedia Search Results Fast
How to Extract Wikipedia Results Using Thunderbit



Learn how to extract structured data from Wikipedia search results
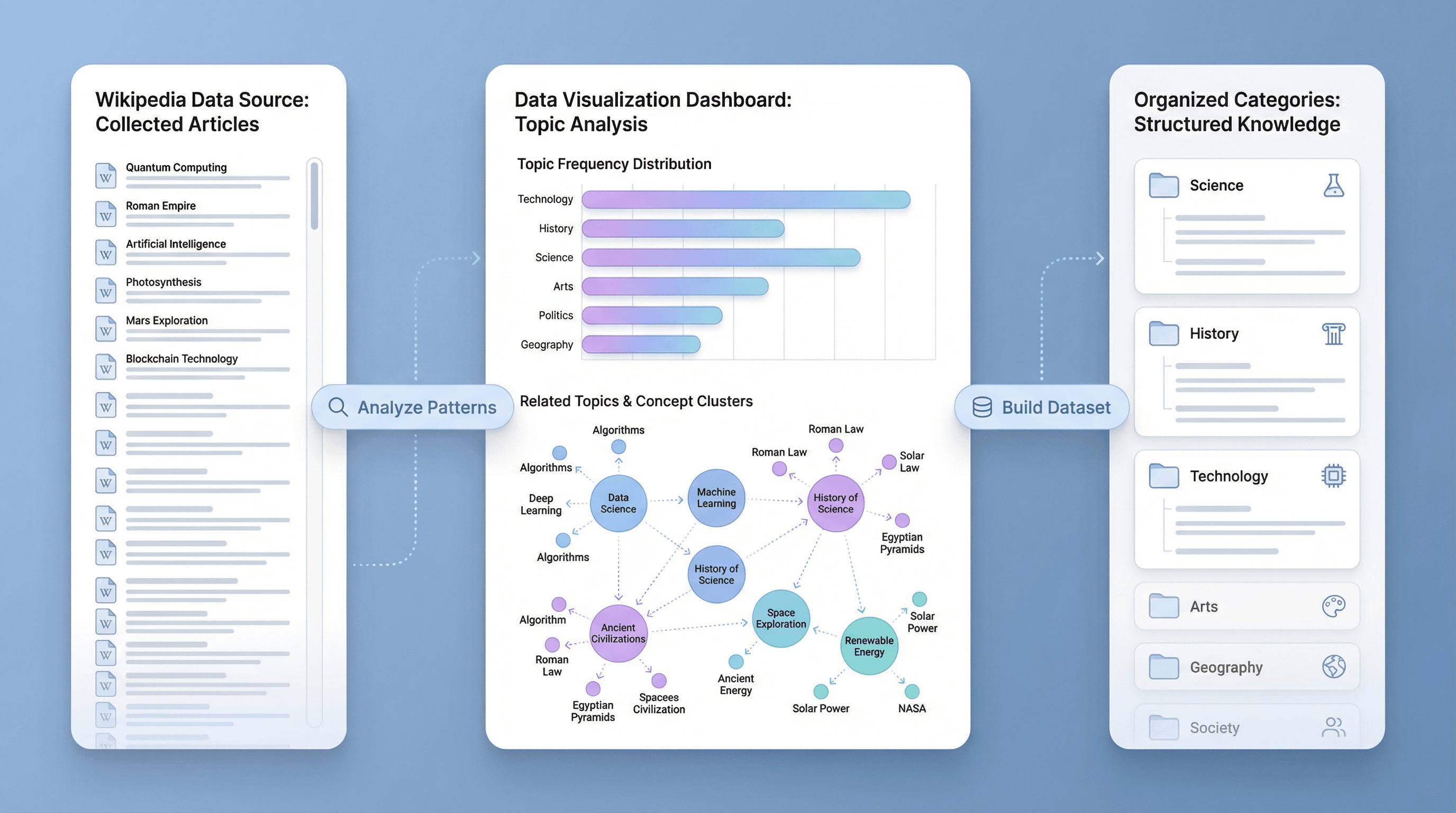
Collect Topic Data from Wikipedia Search Pages

Analyze and Organize Large Sets of Wikipedia Results
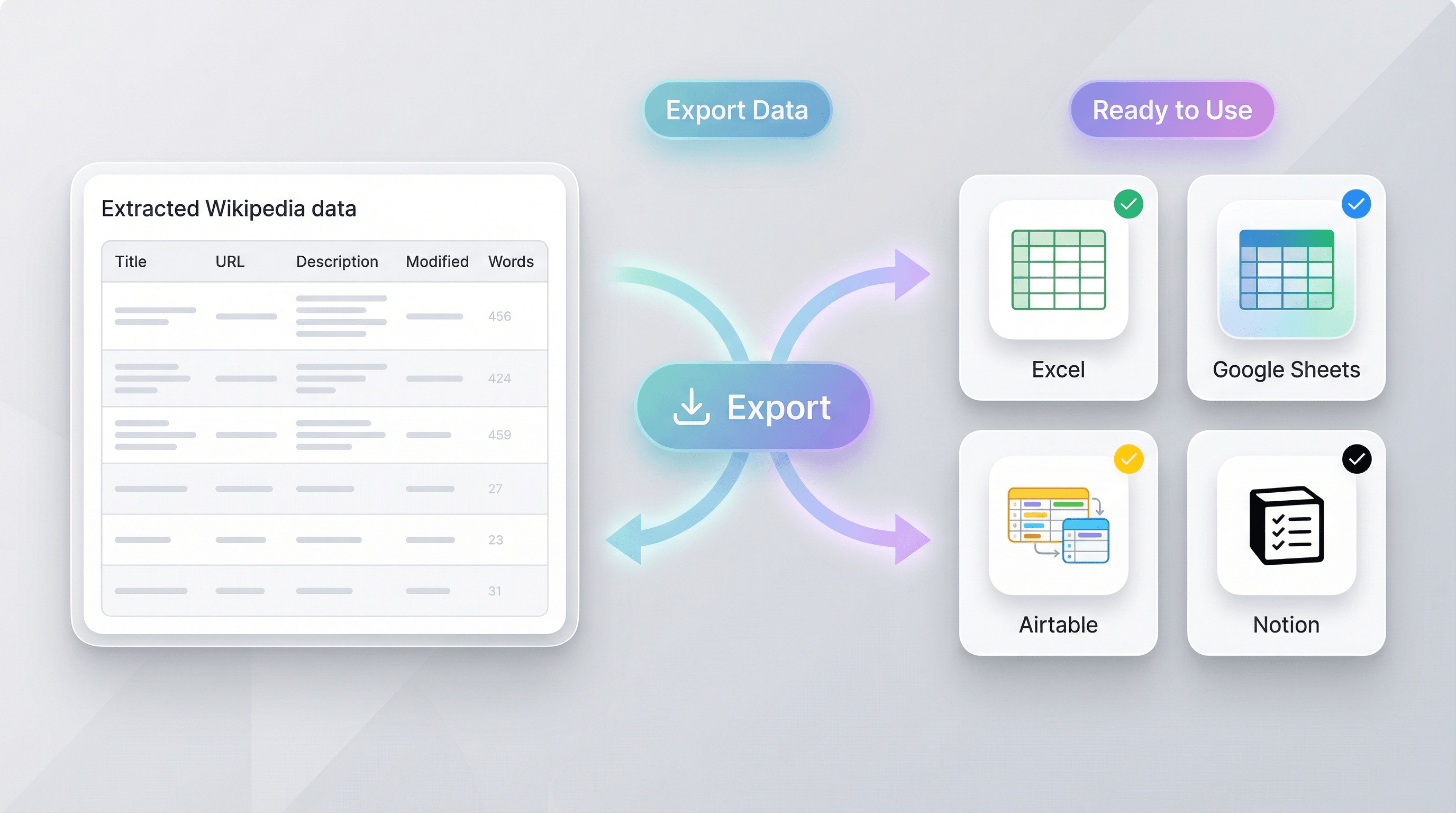
Export Wikipedia Data to Spreadsheets and Databases
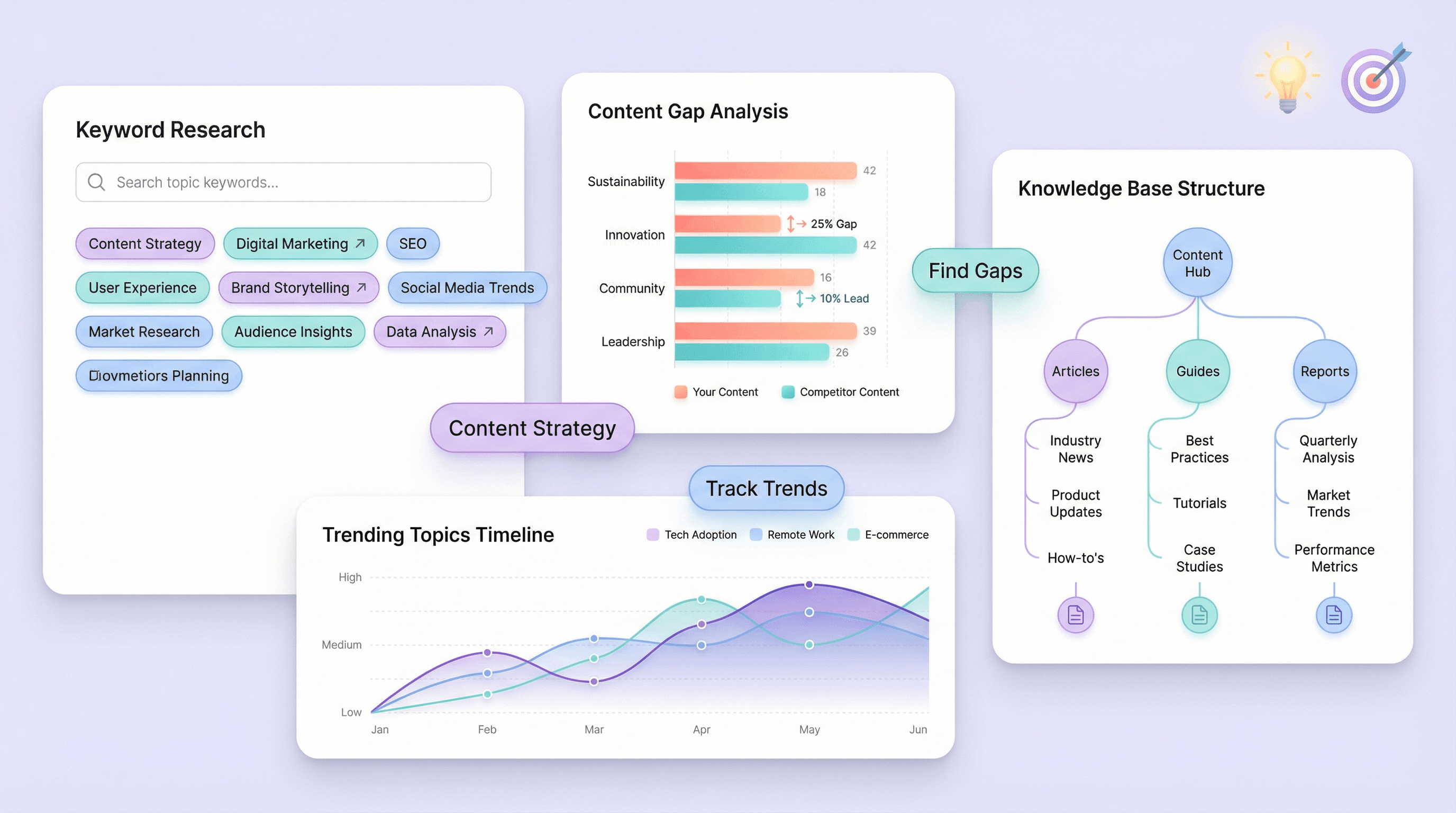
Support Content Strategy and SEO Research
Opdag flere gratis værktøjer
Sitemap-ekstraktor
Analyser en XML-sitemap-URL og list alle sidelinks i en overskuelig tabel. Gennemgå hurtigt sidens struktur og find manglende eller uventede URL’er til SEO og QA.
Billedudtrækker fra en hjemmeside
Udtræk straks alle billeder fra enhver webside og डाउनलोडér dem på ingen tid. Helt gratis, hurtigt og supernemt at eksportere.
Listecrawler
Udtræk ordnede og uordnede listeelementer fra enhver webside-URL. Gennemgå grupperede lister i ren tekst for hurtigt at fange de vigtigste pointer.
URL-udtrækker og batch-downloader
Udtræk alle website-links fra enhver side og download dem som CSV. Indsaml hurtigt URL'er til research, analyse eller dataindsamlingsopgaver.
Google Scholar-scraper
Udtræk akademiske resultater fra en Google Scholar-side og eksportér papirtitler, citationer, forfattere og publikationsoplysninger i CSV for hurtigere research.
G2 Software Product Scraper
Extract structured insights from any G2 software page, including ratings, reviews, and product details, to streamline competitor analysis and market research.
Text Extractor
Extracts text from images and lets you download the results. Quickly convert scanned documents or pictures into editable text for easy use.
AI-generator til e-mail-emnelinjer
Generér fængende emnelinjer til e-mails ud fra en kort beskrivelse. Øg åbningsraten med AI-drevne forslag. Hurtigt, enkelt og uden krav om tilmelding.
Amazon Produkt-scraper
Udtræk produktinformation fra Amazon ved at indsætte produkt-URL'er. Få titler, priser, vurderinger og meget mere i en struktureret tabel, som er klar til hurtig eksport og gennemgang.
AI Sales Email Generator
Create personalized sales emails in seconds with the free AI Sales Email Generator. Perfect for sales teams and entrepreneurs. Try it now and boost your outreach with Thunderbit’s suite of AI tools.
Telefonnummer-ekstraktor
Skan hurtigt websider, filer eller tekst for at finde telefonnumre. Få en ren, eksportklar liste på få sekunder — ideel til at opbygge kontaktlister eller যাচ verificere data.
E-mail-ekstraktor og verifikator
Find og udtræk e-mailadresser fra websider, PDF’er eller tekst med E-mail-Extractor. Hurtigt, præcist og klar til eksport når som helst.
Tester til emnelinjer i e-mails
Få en score på en emnelinje ud fra længde, klarhed, hast, personalisering og spamrisiko. Få konkrete tips til at forbedre åbningsraten.
Billed til Excel-konverter
Konverter billeder af tabeller, kvitteringer eller lister til strukturerede JSON-arrays, så de nemt kan eksporteres til Excel. Spar tid på manuel dataindtastning og sikre høj nøjagtighed.