Substack scraper














Få adgang til Substack-data med Thunderbit
Send Substack-data direkte til dine apps
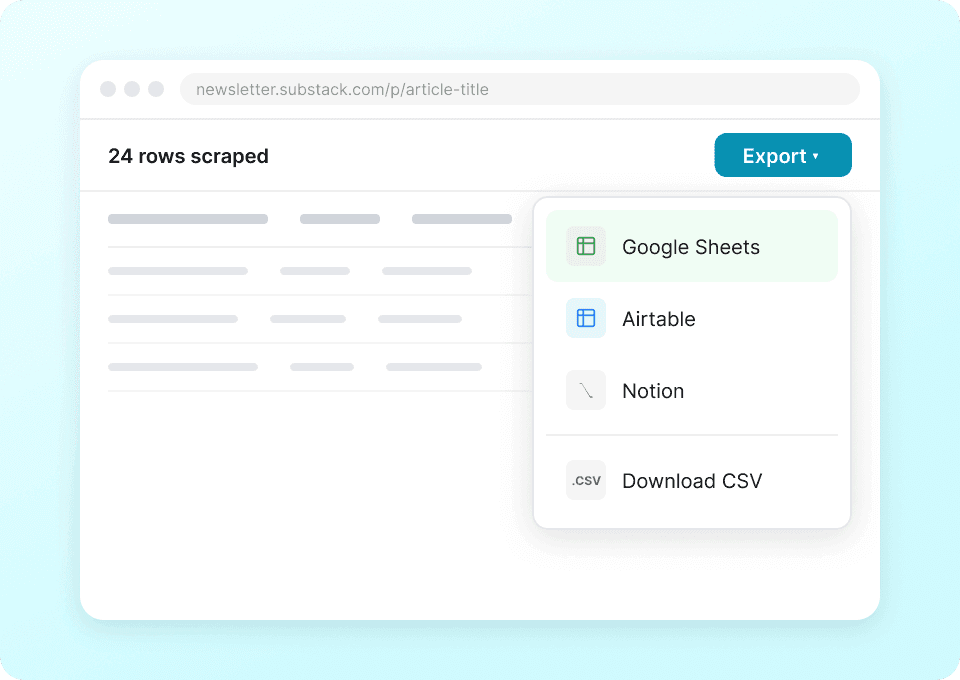
Slut med manuelt at kopiere og indsætte publikationsdetaljer fra Substack som forfatternavne, artikeltitler og antal abonnenter. Med Thunderbit sender du med ét klik dine udtrukne data direkte til Google Sheets, Notion eller Airtable — så du kan analysere publikationstrends og indholdsperformance uden det tidskrævende håndarbejde.
Én scraper til Substack og meget mere
Du behøver ikke jonglere med et nyt værktøj til hver eneste hjemmeside. Thunderbit virker direkte på Substack og indeholder mere end 50 færdige skabeloner til andre populære platforme. Udtræk publikationsbeskrivelser, artikelindhold og meget mere — og brug derefter det samme værktøj til at indsamle data hvor som helst på nettet.
Få hele Substack-historien
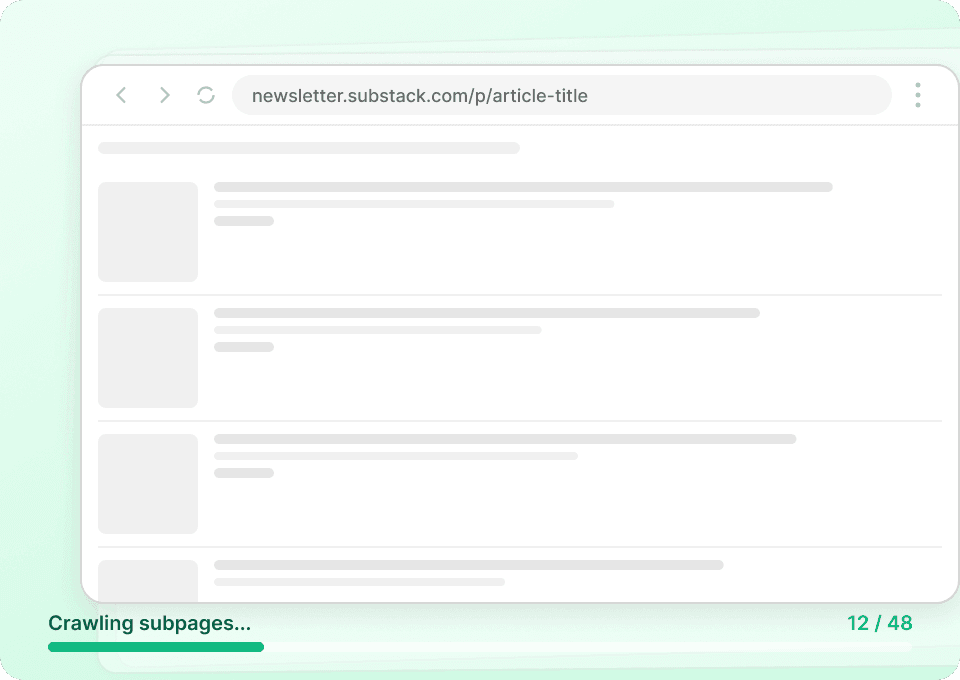
Substack-listsider viser kun resuméer. Thunderbit besøger automatisk hver artikels underside for at hente det fulde indhold, så du får et komplet datasæt i én omgang. Fang artikeltitler, forfatternavne, publikationsnavne og den fulde artikeltekst — helt uden at åbne en eneste side manuelt.
Har du svært ved at scrape Substack effektivt?
Se, hvorfor Thunderbit slår traditionelle scrapers til Substack-data.
Traditionelle scrapers
Den gammeldags måde at gøre tingene påThunderbit
Den smartere tilgangTag ikke bare vores ord for det
Se, hvad vores brugere siger om Thunderbit.






Ofte stillede spørgsmål
Relateret brugsscenarier
Udforsk flere brugsscenarier for Thunderbits web scraper.

HKTVmall Scraper
Udtræk produktnavne, priser, bedømmelser og meget mere fra HKTVmall-lister på 2 klik — helt uden kodning. Eksportér direkte til Excel, Google Sheets eller Notion, og omsæt HKTVmall-data til konkrete indsigter.
Læs mere ->PeopleWhiz-scraper
Thunderbit PeopleWhiz Scraper lader dig udtrække data fra PeopleWhiz-søgeresultater og profiler med AI-drevne felttilbud. Indsaml navne, kontaktoplysninger, lokationer og meget mere til research, marketing eller leadgenerering. Gør PeopleWhiz-data til strukturerede datasæt hurtigt og effektivt.
Læs mere ->Lowe's scraper
Udtræk produktnavne, priser, modelnumre og meget mere fra Lowe's på 2 klik — og eksporter derefter straks til Excel, Google Sheets eller Notion. Ingen kodning nødvendig.
Læs mere ->
Sports Direct Scraper
Udtræk produktnavne, priser og rabatprocenter fra Sports Direct på 2 klik med Thunderbits AI — og eksportér derefter dine data direkte til Excel, Google Sheets eller Notion med det samme. Ingen kodning eller opsætning er nødvendig.
Læs mere ->Macy's scraper
Udtræk Macy's produktnavne, priser og rabatprocenter med 2 klik — og eksporter det straks til Excel, Google Sheets eller Notion. Thunderbits AI klarer det tunge arbejde, så du kan fokusere på det, dataene fortæller.
Læs mere ->
MySpace Scraper
Udtræk brugernavne, bioer og placeringer fra Myspace-profiler med 2 klik — og eksporter straks rene, strukturerede data til Excel, Google Sheets eller Notion.
Læs mere ->Klar til at give dit dataudtræk et boost?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
Gratis prøveperiode giver ubegrænsede credits til 8 websider.



