
Internettet vokser i et tempo, der næsten er svært at fatte. Hver eneste dag bliver milliarder af nye sider, produkter, anmeldelser og datasæt publiceret — og de driver alt fra markedsanalyse til AI-træning og din næste Amazon-shoppingtur. Som en, der har brugt mange år i SaaS og automation, har jeg selv set, hvor meget de rigtige data kan afgøre en forretningsbeslutning. Men her er udfordringen: Det bliver sværere — ikke lettere — at indsamle, opdatere og få overblik over al denne webdata. Traditionelle webscrapere har svært ved at følge med, og virksomheder leder efter en smartere og hurtigere måde at omsætte internettet til brugbar indsigt på. Her kommer cloud crawleren ind i billedet — et værktøj, der stille og roligt er ved at ændre måden, organisationer finder og udnytter webdata i stor skala.
Så hvad er en cloud crawler egentlig? Hvordan adskiller den sig fra de webscrapere, du måske allerede kender? Og hvorfor satser teams fra salg til drift på netop denne teknologi for at holde sig foran i en datadrevet verden? Lad os gå i dybden, afmystificere buzzwords og se, hvordan cloud crawlers — især Thunderbits løsning — er ved at ændre spillereglerne for moderne virksomheder.
Hvad er en cloud crawler? Næste skridt i dataopdagelse
Lad os skære det ud i pap: En cloud crawler er ikke bare en webscraper, der ligger i skyen. Den minder mere om en motor til dataopdagelse — et smart, cloud-baseret system, der automatisk kan finde, udtrække og analysere enorme datasæt fra hele internettet. Hvor en traditionel webscraper typisk henter information fra et begrænset antal sider ad gangen, ofte én side ad gangen og som regel fra én enkelt enhed, arbejder en cloud crawler på et helt andet niveau. Den kører i kraftfulde cloud-datacentre, crawler tusindvis (eller endda millioner) af sider samtidigt og kan håndtere alt fra tekst til billeder og PDF-filer — uanset hvor komplekst eller omfattende det pågældende website er.
Tænk på det sådan her: Hvis en webscraper er som én bibliotekar, der kopierer passager fra en bog, så er en cloud crawler et team af supercomputere, der scanner alle bøger i biblioteket på én gang, mens de markerer, organiserer og analyserer indholdet undervejs. Resultatet? Virksomheder får rigere, friskere og mere handlingsrettede data — uden flaskehalse fra lokal hardware eller manuelt arbejde (, ).
Cloud crawler vs. traditionel webscraper: Hvad er den reelle forskel?
Hvis du nogensinde har brugt en webscraper, kender du grundprincipperne: Peg den mod en side, definer hvad du vil have, og lad den trække dataene ud. Men som internettet bliver større og mere komplekst, begynder den gamle tilgang at vise sine begrænsninger. Sådan står cloud crawlers og traditionelle webscrapere over for hinanden:
| Funktion/område | Traditionel webscraper | Cloud crawler |
|---|---|---|
| Drift | Kører på din lokale enhed eller server | Kører i skyen (eksterne datacentre) |
| Skala | Begrænset af computerens kapacitet | Massivt parallel — tusindvis af sider samtidig |
| Hastighed | Langsommere, især ved store opgaver | Højhastigheds batchbehandling |
| Vedligeholdelse | Kræver hyppige opdateringer og bryder ofte ved ændringer på sitet | Cloud-baseret, automatisk opdatering, mindre skrøbelig |
| Datatyper | Typisk tekst, nogle gange billeder | Tekst, billeder, PDF’er og komplekse layouts |
| Adgang | Bundet til din enhed og dit netværk | Tilgængelig overalt fra enhver enhed |
| Planlægning | Manuel eller grundlæggende automation | Avanceret planlægning, tilbagevendende jobs |
| Bedst til | Små projekter, simple websites | Store, hyppige eller komplekse databehov |
Cloud crawlers er bygget til det moderne web — hvor data er overalt, og hvor hastighed og skala ikke er til forhandling (, ).
Sådan gør cloud crawlers dataindsamling markant mere effektiv
Her bliver det virkelig interessant. Cloud crawlers bruger cloud computing til at behandle tusindvis af websider parallelt. Det betyder, at du kan scrape et helt ecommerce-katalog, overvåge konkurrenters priser på tværs af dusinvis af sites eller samle boligannoncer fra alle de store portaler — alt sammen på en brøkdel af den tid, en traditionel scraper ville bruge.
Hvorfor er det vigtigt? Fordi datafriskhed er afgørende i brancher som ecommerce, finans og ejendomme. Priser, lagerstatus og markedstendenser kan ændre sig fra minut til minut. At vente timer — eller dage — på, at en lokal scraper bliver færdig, er simpelthen ikke holdbart. Cloud crawlers er ikke begrænset af din laptops RAM eller kontorets Wi‑Fi — de skalerer op efter behov, så du kan håndtere store opgaver uden at svede over det (, ).
Brancher, der især drager fordel af denne effektivitet, inkluderer:
- Ecommerce: Prisovervågning, samling af produktkataloger, analyse af anmeldelser
- Ejendomme: Samling af boligannoncer, overvågning af markedstendenser, sammenligning af ejendomme
- Finans: Nyheder og sentimentanalyse, overvågning af aktier/krypto, regulatorisk tracking
- Salg & marketing: Leadgenerering, konkurrentanalyse, opsporing af trends
Og ærligt talt — det er kun toppen af isbjerget. Hvis du har brug for webdata i stor skala, er en cloud crawler din nye bedste ven.
Thunderbits cloud crawler-løsning: Hurtig, fleksibel og stærk
Lad mig lige tage Thunderbit-hatten på et øjeblik (okay, jeg tager den faktisk aldrig helt af). s cloud scraping-tilstand er vores svar på den moderne dataudfordring — en cloud crawler bygget til forretningsbrugere, der vil have resultater, ikke besvær.
Det er det, der gør Thunderbits cloud crawler særlig:
- Højhastigheds batch-scraping: Scrape op til 50 sider ad gangen med cloud-servere i USA, EU og Asien for global rækkevidde. Slut med at vente på, at din laptop kæmper sig gennem en lang liste.
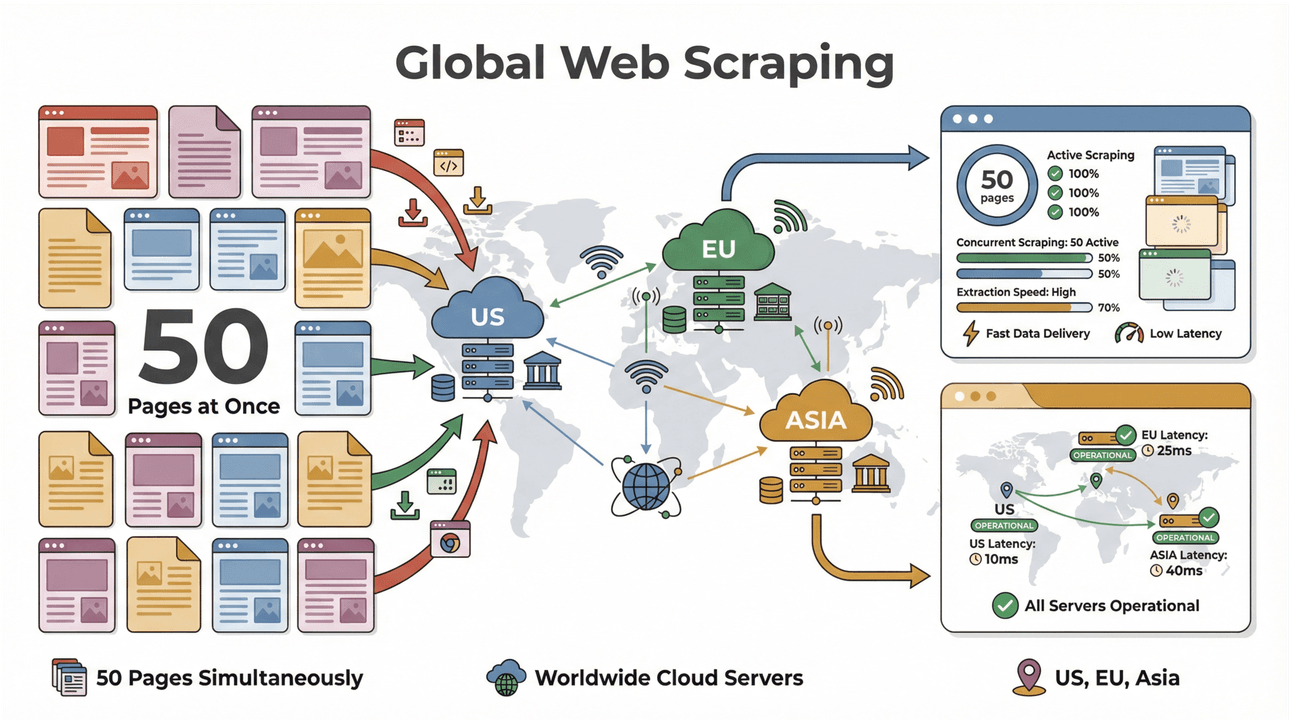
- Understøttelse af komplekse sider: Thunderbits AI kan håndtere alt fra dynamiske ecommerce-sites til vanskelige PDF’er og endda billedudtræk. Hvis det ligger på nettet, kan Thunderbit sandsynligvis scrape det ().
- Crawling af undersider: Har du brug for at berige dine data med detaljer fra undersider, som produkt-specifikationer eller forfatterbiografier? Thunderbits AI kan besøge hver underside og samle resultaterne i dit primære datasæt ().
- Smart datastrukturering: Brug “AI Suggest Fields” til at lade Thunderbit læse siden og foreslå de bedste kolonner — ingen kode eller skabelonarbejde kræves.
- Eksport overalt: Send dine data direkte til Excel, Google Sheets, Airtable eller Notion. Eller download som CSV/JSON — alt efter hvad der passer til din arbejdsgang ().
- Ingen vedligeholdelse nødvendig: Thunderbits AI tilpasser sig ændringer på websitet, så du ikke konstant skal reparere ødelagte scrapere ().
Og ja, du kan prøve det hele med en — så du behøver ikke tage mit ord for det.
Deployment af cloud crawler: Cloud vs. lokal — hvad passer bedst til dig?
En af de største fordele ved cloud crawlers er fleksibiliteten i driften. Med en traditionel crawler på din egen computer er du bundet til en bestemt enhed, et bestemt netværk og ofte en del opsætningsbesvær. Hvis computeren går i dvale, eller internettet ryger, stopper dit scrape. Skaleringen kræver mere hardware eller flere scripts.
Cloud crawlers vender op og ned på den model:
- Ingen specialhardware nødvendig: Alt det tunge arbejde foregår i skyen. Du kan starte store scraping-opgaver fra en Chromebook, en Mac eller endda din telefon.
- Adgang hvor som helst fra: Er du på farten eller arbejder du remote? Intet problem — din cloud crawler er altid tilgængelig.
- Nem skalering: Skal du scrape 10.000 sider i stedet for 100? Så øg bare jobstørrelsen — uden hjælp fra IT.
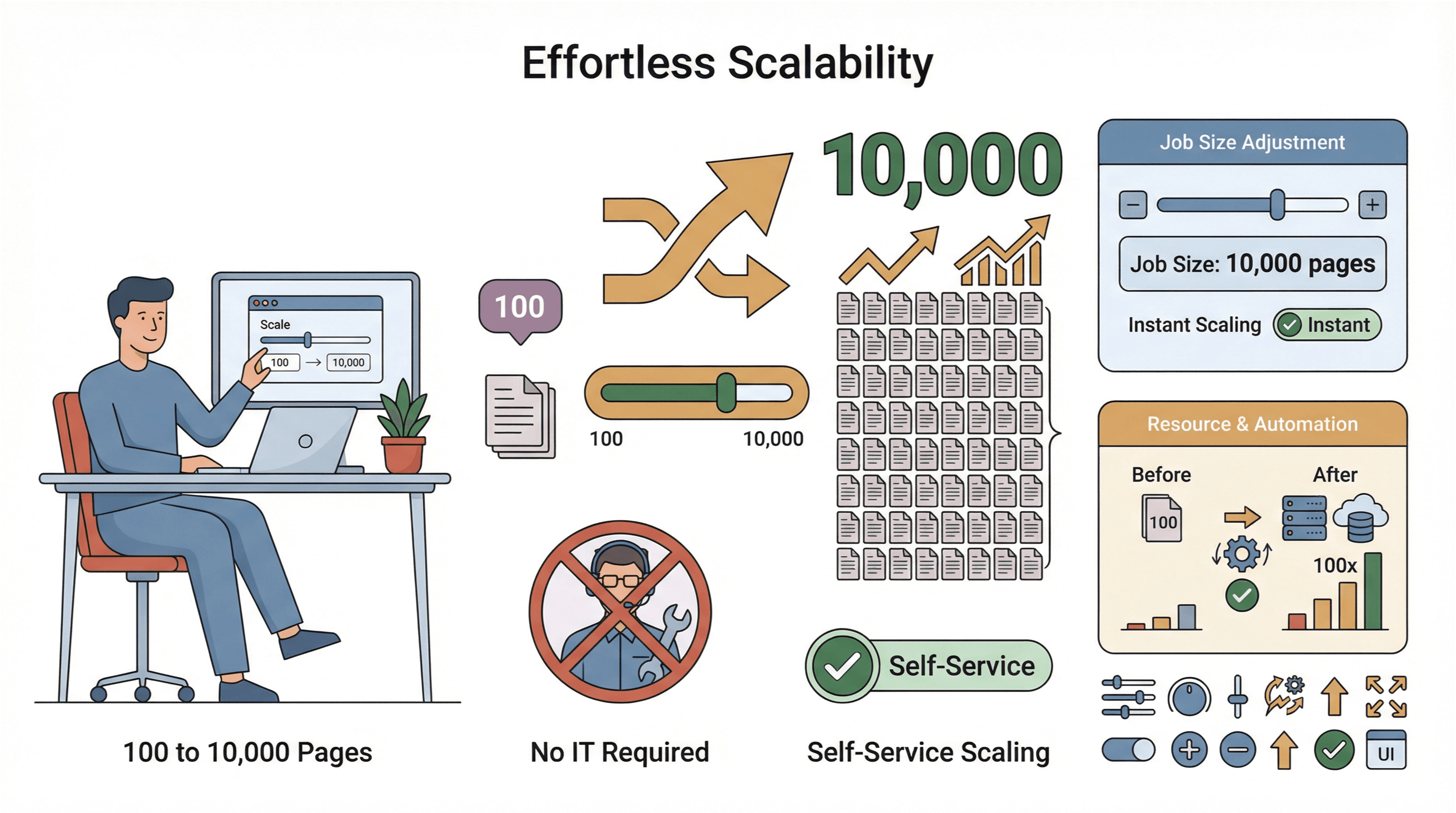
- Global dataindsamling: Med cloud-servere i flere regioner kan du få adgang til geo-begrænset indhold og håndtere compliance mere smidigt ().
Selvfølgelig er sikkerhed og compliance altid blandt de største bekymringer. De bedste cloud crawlers (inklusive Thunderbit) bruger krypterede forbindelser, respekterer websites’ vilkår og tilbyder funktioner, der hjælper dig med at håndtere følsomme data ansvarligt.
Virkningen i praksis: Sådan ændrer cloud crawlers datadrevne strategier
Lad os blive konkrete. Hvorfor skifter virksomheder til cloud crawlers? Fordi de ser reel og målbar effekt:
- Markedsanalyse i realtid: Detailhandlere bruger cloud crawlers til at følge konkurrenters priser og lagerstatus i realtid, så de kan lave dynamisk prissætning og reagere hurtigere på markedsændringer ().
- Forudsigelse af forbrugertendenser: Brands samler anmeldelser, opslag på sociale medier og forumdiskussioner for at spotte nye trends og justere kampagner løbende.
- Salg & leadgenerering: Salgsteams bygger opdaterede leadlister fra kataloger, event-sites og endda PDF’er — og fylder CRM’er med friske, kvalificerede kontakter ().
- Drift & compliance: Finansvirksomheder bruger cloud crawlers til at overvåge regulatoriske opdateringer, nyheder og indberetninger på tværs af flere jurisdiktioner — og dermed reducere risiko og holde sig foran ændringer.
Det gennemgående mønster? Cloud crawlers hjælper teams med at bevæge sig hurtigere, træffe klogere beslutninger og overhale konkurrenter, der stadig sidder fast i langsomsporet.
De vigtigste funktioner at kigge efter i en cloud crawler
Ikke alle cloud crawlers er skabt lige. Hvis du vurderer muligheder, er her de funktioner, der betyder mest — og hvor Thunderbit virkelig skiller sig ud:
- Skalerbarhed: Kan den håndtere tusindvis af sider på én gang? Bliver den langsommere, når jobbet vokser?
- Brugervenlighed: Er grænsefladen intuitiv for ikke-tekniske brugere? Kan du sætte et scrape op med få klik?
- Understøttelse af flere datatyper: Tekst, billeder, PDF’er, undersider — kan den håndtere det hele?
- Integration: Eksporterer den til dine foretrukne værktøjer (Excel, Sheets, Notion, Airtable)?
- Planlægning: Kan du opsætte tilbagevendende jobs, så dataene altid er friske?
- AI-hjælp: Tilbyder den smarte feltforslag, dataforbedring og automatisk tilpasning til ændringer på sitet?
- Sikkerhed & compliance: Er dine data og dine credentials beskyttet? Hjælper den dig med at overholde privatlivsregler?
Thunderbit krydser alle disse felter af, hvilket gør værktøjet til et oplagt valg for teams, der vil have kraft uden bøvl.
Kom i gang: Sådan bruger du en cloud crawler i din virksomhed
Klar til at gå i gang? Sådan kan en typisk bruger komme i gang med en cloud crawler som Thunderbit:
- Installer : Hurtig opsætning, ingen IT nødvendig.
- Vælg din kilde: Åbn websitet, listen eller dokumentet, du vil scrape.
- Klik på “AI Suggest Fields”: Lad Thunderbits AI scanne siden og foreslå de bedste kolonner at udtrække.
- Tilpas efter behov: Tilføj, fjern eller omdøb felter, så de passer til dit behov.
- Vælg cloud scraping-tilstand: Ved store opgaver eller komplekse sites skal du skifte til cloud-tilstand for maksimal hastighed.
- Start scrape-jobbet: Thunderbit behandler op til 50 sider ad gangen i skyen.
- Gennemgå og eksportér: Forhåndsvis resultaterne, og eksportér derefter til Excel, Google Sheets, Notion eller Airtable.
- Planlæg gentagne jobs: Ved løbende behov kan du opsætte planlagte scraping-opgaver — så opdateres data automatisk ().
Pro-tip: Start med et lille job for at lære flowet, og skru derefter op, når du føler dig tryg. Og vær ikke bange for at bruge Thunderbits support eller dokumentation — de er der for at hjælpe.
Fremtiden for dataindsamling: Hvad bliver det næste for cloud crawlers?
Cloud crawler-revolutionen er kun lige begyndt. Her er det, jeg holder øje med i de kommende år:
- Klogere AI-udtræk: Cloud crawlers bliver bedre til at forstå kontekst, relationer og endda sentiment — hvilket gør de indsamlede data mere værdifulde ().
- Understøttelse af nye datatyper: Forvent bedre håndtering af video, lyd og interaktivt indhold — ikke kun statisk tekst og billeder.
- Dybere automation: Fra automatisk planlægning til realtidsalarmer bliver cloud crawlers endnu mere hands-off for forretningsbrugere.
- Stærkere compliance: Efterhånden som privatlivslovgivningen udvikler sig, vil cloud crawlers få flere værktøjer til at hjælpe teams med at holde sig på den rigtige side af reglerne.
- Integration med BI- og AI-værktøjer: Direkte datapipelines fra cloud crawlers til analyseplatforme, dashboards og machine learning-platforme.
Kort sagt er cloud crawlers godt på vej til at blive rygraden i digital forretningsstrategi — og drive alt fra produktlanceringer til AI-drevet forecasting ().
Konklusion: Hvorfor cloud crawlers er uundværlige for moderne virksomheder
Kort sagt: Internettet eksploderer i data, og de gamle metoder til indsamling kan simpelthen ikke følge med. Cloud crawlers er næste udviklingstrin — med hastighed, skala og intelligens, som traditionelle scrapere ikke kan matche. Værktøjer som gør det muligt for ethvert team, teknisk eller ej, at udnytte hele potentialet i webdata — og skabe bedre beslutninger, hurtigere reaktioner og en reel konkurrencefordel.
Hvis du er klar til at lægge manuel scraping og langsomme datastrømme bag dig, er det nu, du skal udforske, hvad en cloud crawler kan gøre for din virksomhed. Prøv Thunderbits cloud scraping-tilstand, og se, hvor let — og kraftfuld — moderne dataopdagelse kan være. Og hvis du vil dykke dybere, så tjek for flere guides, tips og konkrete eksempler.
Ofte stillede spørgsmål
1. Hvad er en cloud crawler i simple termer?
En cloud crawler er et cloud-baseret værktøj, der automatisk finder, udtrækker og analyserer store mængder data fra nettet. I modsætning til traditionelle scrapere, der kører på din lokale enhed, arbejder cloud crawlers i kraftfulde datacentre, hvilket giver massiv skala og hastighed.
2. Hvordan er en cloud crawler anderledes end en almindelig webscraper?
Cloud crawlers kører i skyen, kan håndtere tusindvis af sider på én gang, understøtter komplekse datatyper som billeder og PDF’er og kræver hverken vedligeholdelse eller lokal hardware. Traditionelle scrapere er begrænset af din enheds kapacitet og egner sig bedst til mindre, enklere opgaver.
3. Hvad er de største fordele ved at bruge en cloud crawler?
Cloud crawlers giver højhastighedsdataindsamling i stor skala, understøttelse af komplekse websites, nem adgang fra hvor som helst og avancerede funktioner som planlægning og AI-drevet udtræk. De er ideelle for virksomheder, der har brug for friske og handlingsrettede data hurtigt.
4. Hvordan fungerer Thunderbits cloud crawler for forretningsbrugere?
Thunderbits cloud crawler lader dig sætte et scrape op med få klik — helt uden kodning. Du kan udtrække data fra websites, PDF’er og billeder, berige dem med AI og eksportere direkte til Excel, Google Sheets, Notion eller Airtable. Den er designet til ikke-tekniske brugere, der vil have resultater frem for kompleksitet.
5. Er cloud crawling sikkert og i overensstemmelse med regler om databeskyttelse?
Ja, førende cloud crawlers som Thunderbit bruger krypterede forbindelser og best practices for datasikkerhed. Sørg altid for kun at scrape offentligt tilgængelige data og respektere website-vilkår samt privatlivsregler.
Klar til at se, hvad en cloud crawler kan gøre? og begynd at udforske verdenen af datainindsamling i stor skala, drevet af skyen, allerede i dag.
Læs mere