
Internettet flyder med værdifulde data — uanset om du arbejder med salg, ecommerce eller markedsresearch, er web scraping et hemmeligt våben til leadgenerering, prisovervågning og konkurrenceanalyse. Men der er et problem: jo flere virksomheder der bruger scraping, desto hårdere slår websites igen. Faktisk bruger over , og er blevet standard. Hvis du nogensinde har set dit Python-script køre problemfrit i 20 minutter — og pludselig ramme en mur af 403-fejl — så kender du frustrationen.
Jeg har brugt mange år inden for SaaS og automation, og jeg har selv set, hvordan scraping-projekter på et øjeblik kan gå fra “wow, det her er nemt” til “hvorfor bliver jeg blokeret overalt?”. Så lad os være konkrete: jeg viser dig, hvordan du laver web scraping i Python uden at blive blokeret, deler de bedste teknikker og kodeeksempler og viser, hvornår det er tid til at overveje AI-drevne alternativer som . Uanset om du er Python-pro eller bare lige har skrabet dig gennem det (ja, ordspillet var tilsigtet), går du herfra med et værktøjssæt til pålidelig dataudtræk uden blokeringer.
Hvad betyder web scraping uden at blive blokeret i Python?
Grundlæggende betyder web scraping uden at blive blokeret at udtrække data fra websites på en måde, der ikke udløser deres anti-bot-forsvar. I Python-verdenen handler det om mere end bare at skrive et requests.get()-loop — det handler om at falde naturligt ind, efterligne rigtige brugere og være et skridt foran detektionssystemerne.
Hvorfor Python? — takket være den enkle syntaks, det enorme økosystem (tænk: requests, BeautifulSoup, Scrapy, Selenium) og fleksibiliteten til alt fra hurtige scripts til distribuerede crawlere. Men popularitet har en pris: mange anti-bot-systemer er i dag finjusteret til at genkende scraping-mønstre fra Python.
Hvis du vil scrape stabilt, skal du altså længere end det basale. Det betyder, at du skal forstå, hvordan sites opdager bots — og hvordan du kan overliste dem uden at krydse etiske eller juridiske grænser.
Hvorfor det er vigtigt at undgå blokeringer i Python-webscraping-projekter
At blive blokeret er ikke bare en teknisk irritation — det kan vælte hele forretningsprocesser. Lad os bryde det ned:
| Brugsscenarie | Konsekvens ved blokering |
|---|---|
| Leadgenerering | Ufuldstændige eller forældede prospect-lister, tabt salg |
| Prisovervågning | Missede konkurrenters prisændringer, dårlige prisbeslutninger |
| Indholdsaggregation | Huller i nyheder, anmeldelser eller researchdata |
| Markedsindsigt | Blinde vinkler i konkurrent- eller brancheovervågning |
| Ejendomsannoncer | Unøjagtige eller forældede ejendomsdata, tabte muligheder |
Når en scraper bliver blokeret, mangler du ikke bare data — du spilder også ressourcer, risikerer compliance-problemer og kan ende med at træffe dårlige forretningsbeslutninger på baggrund af ufuldstændige oplysninger. I en verden hvor , er pålidelighed alt.
Sådan opdager og blokerer websites Python-webscrapere
Websites er blevet virkelig dygtige til at spotte bots. Her er de mest almindelige anti-scraping-forsvar, du vil støde på (, ):
- IP-adresse sortlistning: For mange forespørgsler fra den samme IP? Blokeret.
- Tjek af User-Agent og headers: Forespørgsler uden eller med generiske headers (som Pythons standard
python-requests/2.25.1) skiller sig ud. - Rate limiting: For mange forespørgsler på kort tid udløser throttling eller blokering.
- CAPTCHAs: “Bevis, at du er et menneske”-opgaver, som bots ikke kan løse (i hvert fald ikke nemt).
- Adfærdsanalyse: Sites holder øje med robotagtige mønstre — som at klikke på den samme knap med præcis samme interval.
- Honeypots: Skjulte links eller felter, som kun bots interagerer med.
- Browser fingerprinting: Indsamling af detaljer om din browser og enhed for at opdage automatiseringsværktøjer.
- Cookie- og sessionssporing: Bots, der ikke håndterer cookies eller sessioner korrekt, bliver markeret.
Tænk på det som lufthavnssikkerhed: hvis du ser ud, opfører dig og bevæger dig som alle andre, glider du lige igennem. Møder du op i trenchcoat og solbriller, så forvent ekstra spørgsmål.
Vigtige Python-teknikker til web scraping uden at blive blokeret
Lad os komme til det gode: hvordan du faktisk undgår blokeringer, når du scraper med Python. Her er de vigtigste strategier, enhver scraper bør kende:

Skiftende proxies og IP-adresser
Hvorfor det er vigtigt: Hvis alle dine forespørgsler kommer fra den samme IP, er du et oplagt mål for IP-blokering. Skiftende proxies fordeler forespørgslerne på mange IP-adresser, så det bliver langt sværere at blokere dig.
Sådan gør du i Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...flere proxies
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # behandl responsenDu kan bruge betalte proxy-tjenester (som residential eller skiftende proxies) for mere stabilitet ().
Sæt User-Agent og brugerdefinerede headers
Hvorfor det er vigtigt: Pythons standard-headers skriger “bot”. Efterlign rigtige browsere ved at sætte user-agent og andre headers.
Kodeeksempel:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Skift user-agents for ekstra camouflage ().
Tilfældiggør timing og mønstre i forespørgsler
Hvorfor det er vigtigt: Bots er hurtige og forudsigelige; mennesker er langsomme og tilfældige. Tilføj pauser og bland din navigation.
Python-tip:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Vent 2–7 sekunderDu kan også tilfældiggøre klikstier og scrollmønstre, hvis du bruger Selenium.
Håndter cookies og sessioner
Hvorfor det er vigtigt: Mange sites kræver cookies eller sessionstokens for at give adgang til indhold. Bots, der ignorerer dette, bliver blokeret.
Sådan gør du i Python:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session håndterer cookies automatiskVed mere komplekse flows kan du bruge Selenium til at fange og genbruge cookies.
Efterlign menneskelig adfærd med headless browsere
Hvorfor det er vigtigt: Nogle sites bruger JavaScript, musebevægelser eller scrolling som signaler på, at der er en rigtig bruger. Headless browsere som Selenium eller Playwright kan efterligne de handlinger.
Eksempel med Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Det hjælper dig med at omgå adfærdsanalyse og dynamisk indhold ().
Avancerede strategier: Sådan omgår du CAPTCHAs og honeypots i Python
CAPTCHAs er designet til at stoppe bots i deres spor. Selvom nogle Python-biblioteker kan løse enkle CAPTCHAs, bruger de fleste seriøse scrapere tredjepartstjenester (som 2Captcha eller Anti-Captcha) til at løse dem mod betaling ().
Eksempel på integration:
1# Pseudokode til brug af 2Captcha API
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Vent på løsning, og send derefter med din forespørgselHoneypots er skjulte felter eller links, som kun bots interagerer med. Undgå at klikke på eller sende noget, der ikke er synligt i en rigtig browser ().
Sådan designer du robuste request-headers med Python-biblioteker
Ud over user-agent kan du rotere og tilfældiggøre andre headers (som Referer, Accept, Origin osv.) for at falde endnu mere ind.
Med Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # Flere headers
7 }
8 }Med Selenium: Brug browserprofiler eller extensions til at sætte headers, eller injicér dem via JavaScript.
Hold din header-liste opdateret — kopier rigtige browser-forespørgsler via browserens DevTools for inspiration.
Når traditionel Python-scraping ikke slår til: Fremvæksten af anti-bot-teknologi
Sandheden er, at jo mere scraping vokser, desto bedre bliver anti-bot-teknologien også. . AI-drevet detektion, dynamiske grænser for forespørgsler og browser fingerprinting gør det sværere end nogensinde selv for avancerede Python-scripts at forblive usete ().
Nogle gange rammer du en mur, uanset hvor snedig din kode er. Det er dér, du bør overveje en anden tilgang.
Thunderbit: Et AI Web Scraper-alternativ til Python-scraping
Når Python når sin grænse, træder til som en no-code, AI-drevet web scraper, bygget til forretningsbrugere — ikke kun udviklere. I stedet for at kæmpe med proxies, headers og CAPTCHAs læser Thunderbits AI-agent websitet, foreslår de bedste felter at udtrække og håndterer alt fra navigation på undersider til eksport af data.
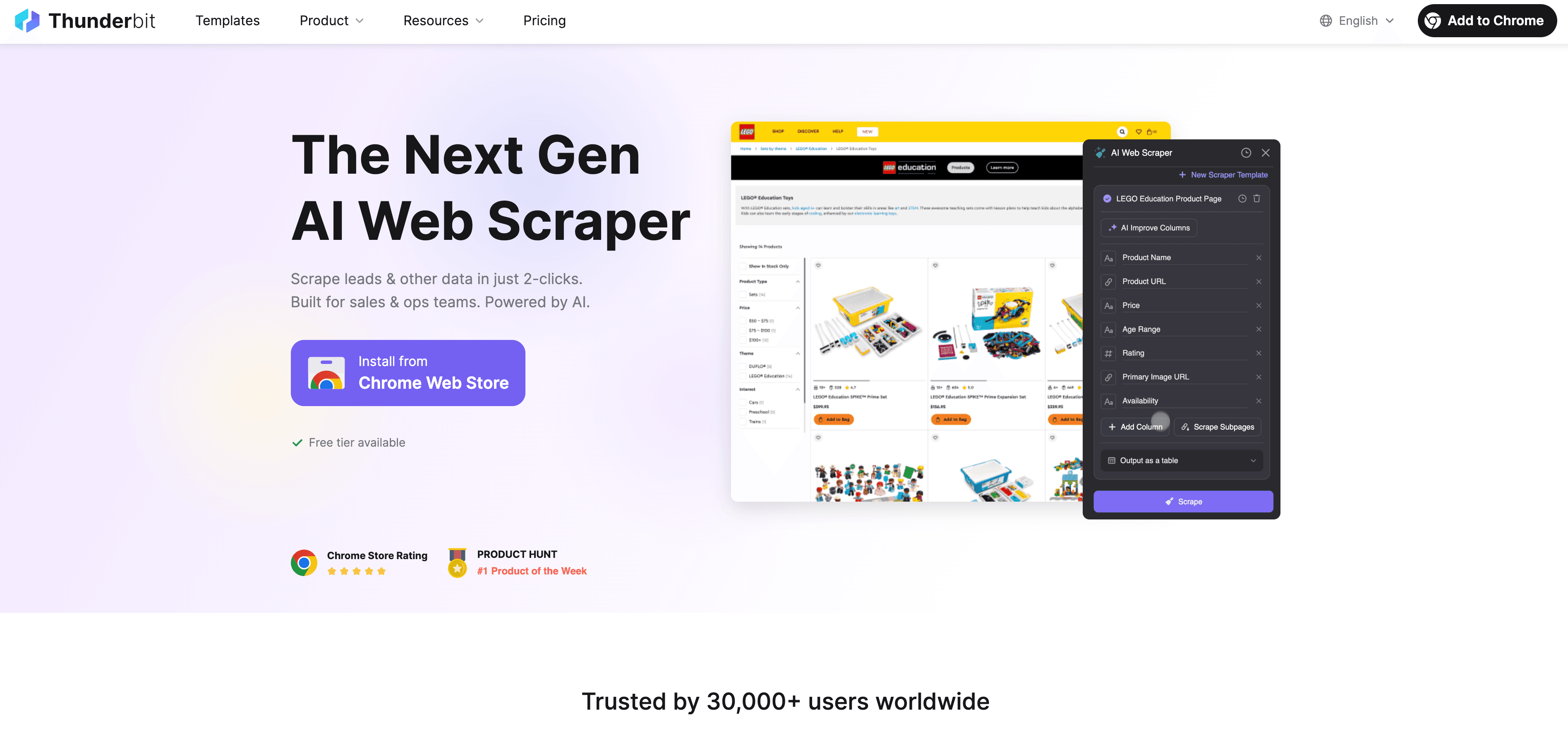
Hvad gør Thunderbit anderledes?
- AI-forslag til felter: Klik på “AI Suggest Fields”, og Thunderbit scanner siden, anbefaler kolonner og genererer endda udtræksinstruktioner.
- Scraping af undersider: Thunderbit kan besøge hver underside (som produktdetaljer eller LinkedIn-profiler) og automatisk berige din tabel.
- Cloud- eller browser-scraping: Vælg den hurtigste løsning — cloud til offentlige sites, browser til sider beskyttet af login.
- Planlagt scraping: Sæt det op én gang og lad det køre — Thunderbit kan scrape efter tidsplan, så dine data altid er friske.
- Øjeblikkelige skabeloner: Til populære sites (Amazon, Zillow, Shopify osv.) tilbyder Thunderbit 1-klik-skabeloner — ingen opsætning nødvendig.
- Gratis dataeksport: Eksportér til Excel, Google Sheets, Airtable eller Notion — uden ekstra gebyrer.
Thunderbit har tillid fra over , og du behøver ikke skrive en eneste linje kode.
Sådan hjælper Thunderbit brugere med at undgå blokeringer og automatisere dataudtræk
Thunderbits AI efterligner ikke bare menneskelig adfærd — den tilpasser sig hvert site i realtid og reducerer risikoen for at blive blokeret. Sådan fungerer det:
- AI tilpasser sig layoutændringer: Slut med ødelagte scripts, når et site ændrer design.
- Håndtering af undersider og paginering: Thunderbit følger automatisk links og sider med pagination, præcis som en rigtig bruger.
- Cloud-scraping i stor skala: Scrape op til 50 sider ad gangen, lynhurtigt.
- Ingen kodning, ingen vedligeholdelse: Brug tiden på analyse i stedet for fejlfinding.
For en mere grundig gennemgang kan du læse .
Sammenligning: Python-scraping vs. Thunderbit — hvad skal du vælge?
Lad os sætte dem op side om side:
| Funktion | Python-scraping | Thunderbit |
|---|---|---|
| Opsætningstid | Mellem til høj (scripts, proxies osv.) | Lav (2 klik, AI klarer resten) |
| Tekniske færdigheder | Kræver kodning | Ingen kodning nødvendig |
| Pålidelighed | Varierer (let at knække) | Høj (AI tilpasser sig ændringer) |
| Risiko for blokering | Mellem til høj | Lav (AI efterligner brugere og tilpasser sig) |
| Skalerbarhed | Kræver specialkode/cloud-opsætning | Indbygget cloud-/batch-scraping |
| Vedligeholdelse | Hyppig (siteændringer, blokeringer) | Minimal (AI justerer automatisk) |
| Eksportmuligheder | Manuel (CSV, database) | Direkte til Sheets, Notion, Airtable, CSV |
| Pris | Gratis (men tidskrævende) | Gratis plan, betalte abonnementer til større behov |
Hvornår du skal bruge Python:
- Du har brug for fuld kontrol, speciallogik eller integration med andre Python-workflows.
- Du scraper sites med minimale anti-bot-forsvar.
Hvornår du skal bruge Thunderbit:
- Du vil have fart, stabilitet og nul opsætning.
- Du scraper komplekse eller ofte skiftende sites.
- Du vil slippe for proxies, CAPTCHAs og kode.
Trin-for-trin-guide: Sådan sætter du web scraping op uden at blive blokeret i Python
Lad os gennemgå et praktisk eksempel: scraping af produktdata fra et eksempel-site, mens vi anvender best practices for at undgå blokering.
1. Installer de nødvendige biblioteker
1pip install requests beautifulsoup4 fake-useragent2. Forbered dit script
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Erstat med dine URLs
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Udtræk data her
16 print(soup.title.text)
17 else:
18 print(f"Blokeret eller fejl på {url}: {response.status_code}")
19 time.sleep(random.uniform(2, 6)) # Tilfældig pause3. Tilføj proxy-rotation (valgfrit)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Flere proxies
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...resten af koden4. Håndter cookies og sessioner
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...resten af koden5. Tips til fejlfinding
- Hvis du ser mange 403/429-fejl, så sænk tempoet på dine forespørgsler eller prøv nye proxies.
- Hvis du rammer CAPTCHAs, kan du overveje Selenium eller en CAPTCHA-løsningstjeneste.
- Tjek altid sitets
robots.txtog vilkår for brug.
Konklusion og vigtigste pointer
Web scraping i Python er stærkt — men risikoen for at blive blokeret er konstant, efterhånden som anti-bot-teknologien udvikler sig. Den bedste måde at undgå blokeringer på? Kombinér tekniske best practices (skiftende proxies, smarte headers, tilfældige pauser, session-håndtering og headless browsere) med respekt for sidernes regler og etik.
Men nogle gange er selv de bedste Python-tricks ikke nok. Det er her, AI-drevne værktøjer som skinner — de giver en no-code, blokresistent og forretningsvenlig måde at udtrække de data, du har brug for, hurtigt.
Vil du se, hvor nemt scraping kan være? og prøv det selv — eller besøg vores for flere scraping-tips og tutorials.
Ofte stillede spørgsmål
1. Hvorfor blokerer websites Python-webscrapere?
Websites blokerer scrapere for at beskytte deres data, forhindre overbelastning af servere og stoppe automatiserede bots i at misbruge deres tjenester. Python-scripts er nemme at spotte, hvis de bruger standard-headers, ikke håndterer cookies eller sender for mange forespørgsler for hurtigt.
2. Hvad er de mest effektive måder at undgå at blive blokeret, når man scraper med Python?
Brug skiftende proxies, sæt realistiske user-agent-strings og headers, tilfældiggør tidspunktet for forespørgsler, håndter cookies/sessioner og efterlign menneskelig adfærd med værktøjer som Selenium eller Playwright.
3. Hvordan hjælper Thunderbit med at undgå blokeringer sammenlignet med Python-scripts?
Thunderbit bruger AI til at tilpasse sig sidernes layout, efterligne menneskelig browsing og håndtere undersider og pagination automatisk. Det reducerer risikoen for blokeringer ved at falde naturligt ind og justere sin tilgang i realtid — uden kode eller proxies.
4. Hvornår skal jeg bruge Python-scraping kontra et AI-værktøj som Thunderbit?
Brug Python, når du har brug for speciallogik, integration med anden Python-kode eller scraper enkle sites. Brug Thunderbit til hurtig, pålidelig og skalerbar scraping — især når sites er komplekse, ofte ændrer sig eller blokerer scripts aggressivt.
5. Er web scraping lovligt?
Web scraping er lovligt for offentligt tilgængelige data, men du skal respektere hvert sites vilkår for brug, privatlivspolitik og relevante love. Scrape aldrig følsomme eller private data, og brug altid scraping etisk og ansvarligt.
Klar til at scrape smartere i stedet for hårdere? Prøv Thunderbit, og lad blokeringerne blive bag dig.
Læs mere:
- Google News-scraping med Python: En trin-for-trin-guide
- Byg et værktøj til prisovervågning af Best Buy med Python
- 14 måder at lave web scraping uden at blive blokeret
- 10 bedste tips til, hvordan du undgår at blive blokeret ved web scraping