
Der er noget helt tidløst over at åbne en terminal, taste én enkelt kommando og se rå webdata vælte ind—lidt som at åbne døren til The Matrix. For udviklere og tekniske power users er den rene tryllestav: et beskedent kommandolinjeværktøj, der stille og roligt kører på milliarder af enheder—fra cloud-servere til dit smarte køleskab. Og selv i 2026, hvor der findes masser af blankpolerede no-code- og AI-scrapingværktøjer, er web scraping med curl stadig et oplagt valg, hvis du vil have fart, kontrol og mulighed for at script’e.
 Jeg har brugt år på at bygge automatiseringsværktøjer og hjælpe teams med at få styr på webdata, og jeg rækker stadig ud efter cURL, når jeg skal hente en side, fejlsøge et API eller hurtigt skitsere et scraping-flow. I den her guide får du en curl web scraping tutorial, der både tager dig gennem basics og de mere pro tricks—med konkrete kommandoeksempler, praktiske tips og et ærligt blik på, hvor cURL er stærk (og hvor den rammer en mur). Og hvis du er mere forretningsbruger og helst vil slippe for kommandolinjen, viser jeg også, hvordan , vores AI-drevne web scraper, kan tage dig fra “jeg skal bruge de her data” til “her er mit regneark” på to klik—helt uden kode.
Jeg har brugt år på at bygge automatiseringsværktøjer og hjælpe teams med at få styr på webdata, og jeg rækker stadig ud efter cURL, når jeg skal hente en side, fejlsøge et API eller hurtigt skitsere et scraping-flow. I den her guide får du en curl web scraping tutorial, der både tager dig gennem basics og de mere pro tricks—med konkrete kommandoeksempler, praktiske tips og et ærligt blik på, hvor cURL er stærk (og hvor den rammer en mur). Og hvis du er mere forretningsbruger og helst vil slippe for kommandolinjen, viser jeg også, hvordan , vores AI-drevne web scraper, kan tage dig fra “jeg skal bruge de her data” til “her er mit regneark” på to klik—helt uden kode.
Lad os dykke ned i, hvorfor cURL stadig er relevant til web scraping i 2025, hvordan du bruger det effektivt, og hvornår det giver mening at vælge noget endnu mere kraftfuldt.
Hvad er cURL? Fundamentet for web-scraping-with-curl
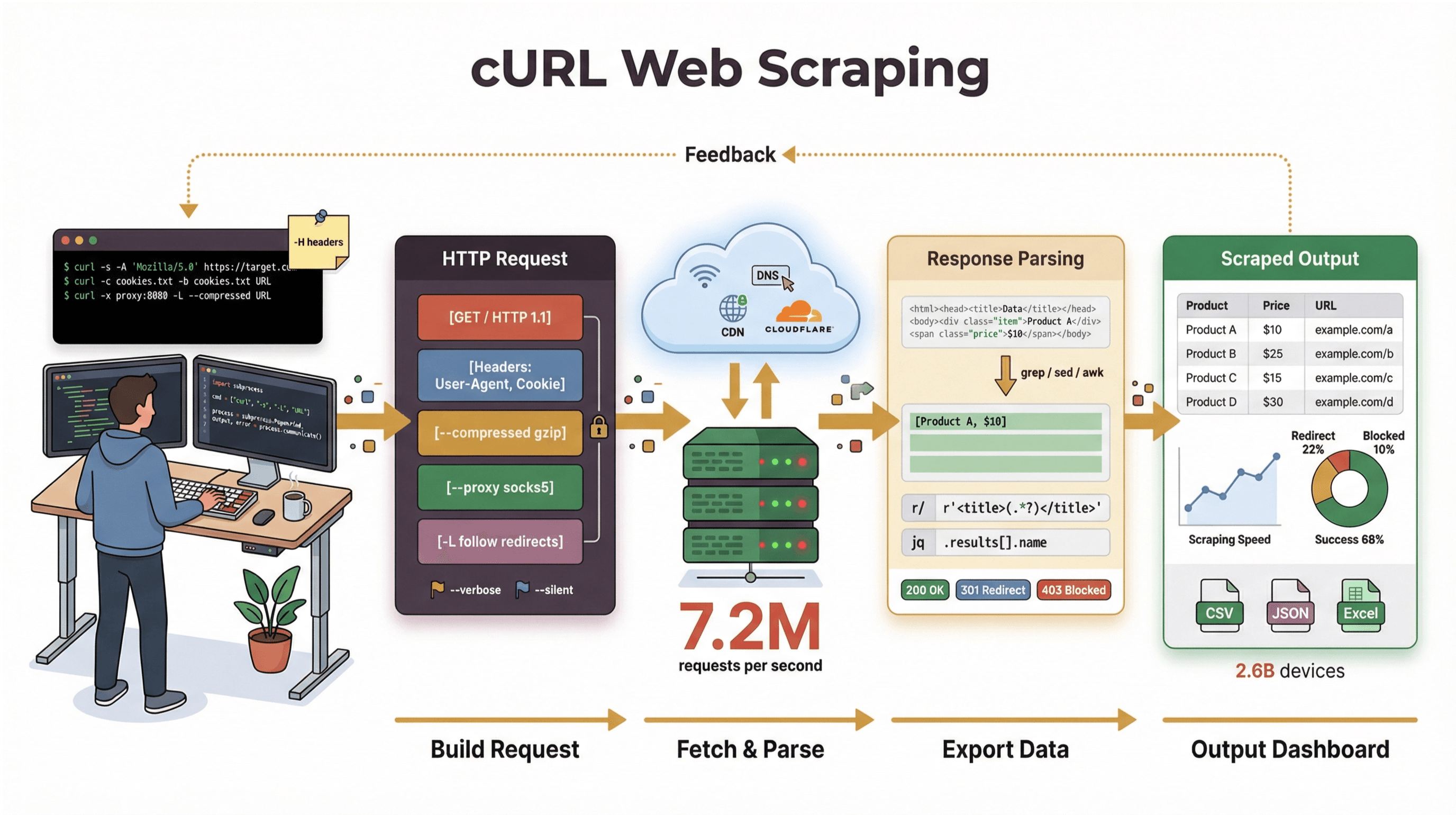
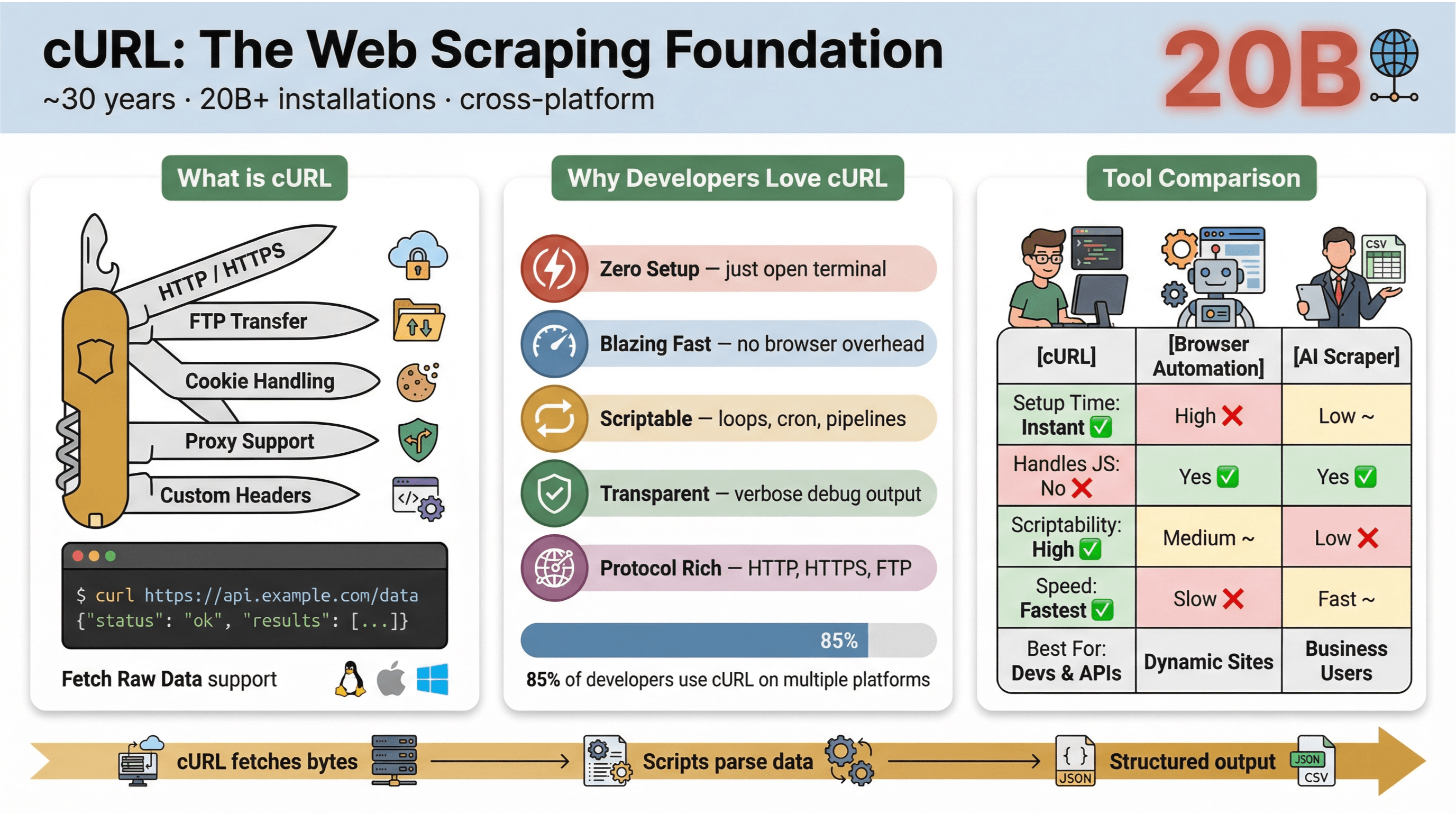
Helt nede på jorden er et kommandolinjeværktøj og et bibliotek til at flytte data via URL’er. Det har eksisteret i næsten 30 år (ja, seriøst), og det er overalt—indbygget i operativsystemer, brugt i scripts og i det stille ansvarlig for dataoverførsler i mere end . Hvis du nogensinde har kørt en hurtig kommando for at hente en webside, teste et API eller downloade en fil, har du med stor sandsynlighed brugt cURL.
 Her er grunden til, at cURL er så populært til web scraping:
Her er grunden til, at cURL er så populært til web scraping:
- Letvægts og på tværs af platforme: Kører på Linux, macOS, Windows og endda indlejrede enheder.
- Protokolunderstøttelse: Håndterer HTTP, HTTPS, FTP og meget mere.
- Kan script’es: Perfekt til automatisering, cron jobs og “glue code”.
- Ingen brugerinteraktion nødvendig: Designet til ikke-interaktiv brug—ideelt til batch-jobs og pipelines.
Men lad os være helt skarpe: cURL’s kerneopgave er at hente rå data—HTML, JSON, billeder, you name it. Det parser, renderer eller strukturerer ikke data for dig. Tænk på cURL som “første kilometer” i web scraping: det skaffer bytes’ene, men du skal bruge andre værktøjer (fx Python-scripts, grep/sed/awk eller en AI Web Scraper) for at omdanne det til struktureret information.
Vil du se de officielle docs, så kig på .
Hvorfor bruge cURL til web scraping? (curl web scraping tutorial)
Hvorfor vender udviklere og tekniske brugere igen og igen tilbage til cURL til web scraping, selv med alle de nye værktøjer? Her er det, der gør cURL særligt:
- Minimal opsætning: Ingen installationer, ingen afhængigheder—åbn terminalen og kom i gang.
- Hastighed: Hent data med det samme uden at vente på, at en browser loader.
- Scriptbarhed: Loop nemt over URL’er, automatisér requests og kæd kommandoer sammen.
- Protokoller og features: Håndtér cookies, proxies, redirects, custom headers og meget mere.
- Gennemsigtighed: Se præcis, hvad der sker, med verbose/debug-output.
I svarede over 85% af deltagerne, at de bruger cURL-kommandolinjeværktøjet, og næsten alle bruger det på flere platforme. Det er stadig den klassiske schweizerkniv til HTTP-requests, hurtige dataudtræk og fejlfinding.
Her er en hurtig sammenligning af cURL med andre scrapingmetoder:
| Funktion | cURL | Browser-automatisering (fx Selenium) | AI Web Scraper (fx Thunderbit) |
|---|---|---|---|
| Opsætningstid | Med det samme | Høj | Lav |
| Scriptbarhed | Høj | Mellem | Lav (ingen kode nødvendig) |
| Håndterer JavaScript | Nej | Ja | Ja (Thunderbit: via browser) |
| Cookie/session-support | Manuelt | Automatisk | Automatisk |
| Datastrukturering | Manuelt (parse senere) | Manuelt (parse senere) | AI-/skabelonbaseret |
| Bedst til | Devs, hurtige udtræk | Komplekse, dynamiske sites | Forretningsbrugere, struktureret eksport |
Kort sagt: cURL er suverænt til hurtige, scriptbare datahentninger—særligt for statiske sider, API’er eller simple automatiseringer. Men så snart du skal parse kompleks HTML, håndtere JavaScript eller eksportere strukturerede data, får du brug for noget mere specialiseret.
Kom i gang: Grundlæggende cURL web scraping-kommandoer
Lad os gøre det hands-on. Her er, trin for trin, hvordan du bruger cURL til basale web scraping-opgaver.
Hent rå HTML med cURL
Den mest simple case: hent HTML’en fra en webside.
1curl https://books.toscrape.com/Kommandoen henter forsiden fra , et offentligt demo-site til web scraping. Du ser rå HTML i terminalen—kig efter tags som <title> eller tekststumper som “In stock.”
Gem output i en fil
Vil du gemme HTML’en til senere parsing? Brug -o:
1curl -o page.html https://books.toscrape.com/Nu har du en page.html-fil med hele HTML-indholdet. Perfekt til videre analyse eller parsing med andre værktøjer.
Send POST-requests med cURL
Skal du indsende en formular eller tale med et API? Brug -d til POST. Her er et eksempel med , som er lavet til HTTP-test:
1curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"Du får et JSON-svar, der “ekkoer” de data, du sendte—super til test og prototyper.
Se headers og fejlsøg
Nogle gange vil du se response headers eller debugge requesten:
-
Kun headers (HEAD-request):
1curl -I https://books.toscrape.com/ -
Headers sammen med body:
1curl -i https://httpbin.org/get -
Verbose/debug-output:
1curl -v https://books.toscrape.com/
De her flags gør det meget nemmere at forstå, hvad der sker “under motorhjelmen”—helt centralt ved fejlfinding.
Her er en hurtig oversigt over kommandoerne:
| Opgave | Kommandoeksempel | Noter |
|---|---|---|
| Hent HTML | curl URL | Skriver HTML til terminalen |
| Gem i fil | curl -o file.html URL | Gemmer output i en fil |
| Se headers | curl -I URL eller curl -i URL | -I kun HEAD, -i inkluderer headers med body |
| POST formular-data | curl -d "a=1&b=2" URL | Sender form-encoded data |
| Debug request/response | curl -v URL | Viser detaljeret request/response-info |
Flere eksempler finder du i .
Næste niveau: Avanceret web scraping med cURL (web-scraping-with-curl)
Når du har styr på det grundlæggende, har cURL en hel værktøjskasse af avancerede muligheder til mere krævende scraping.
Håndtering af cookies og sessioner
Mange sites kræver cookies for at holde login-sessioner eller spore brugere. Med cURL kan du gemme og genbruge cookies på tværs af requests:
1# Gem cookies efter login
2curl -c cookies.txt https://example.com/login
3# Brug cookies i efterfølgende requests
4curl -b cookies.txt https://example.com/accountDet gør det muligt at efterligne en browsersession og tilgå sider bag login (så længe der ikke er en JavaScript-udfordring).
Spoof User-Agent og brug custom headers
Nogle websites serverer forskelligt indhold afhængigt af User-Agent eller headers. Som standard identificerer cURL sig som “curl/VERSION”, hvilket kan udløse blokeringer eller alternativt indhold. For at ligne en browser:
1curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/Du kan også sætte egne headers, fx sprogpræferencer:
1curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/Det hjælper dig med at få det samme indhold, som en rigtig browser ser.
Brug proxies til web scraping
Skal du sende dine requests via en proxy (geo-test eller for at undgå IP-bans)? Brug -x:
1curl -x http://proxy.example.org:4321 https://remote.example.org/Sørg for at bruge proxies ansvarligt og i overensstemmelse med sitets vilkår.
Automatisér scraping af flere sider
Vil du scrape flere sider—fx paginerede produktlister? Brug et simpelt shell-loop:
1for p in $(seq 2 5); do
2 curl -s -o "books-page-${p}.html" \
3 "https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
4 sleep 1
5doneDet henter side 2 til 5 i Books to Scrape-kataloget og gemmer hver side i sin egen fil. (Side 1 er forsiden.)
Begrænsninger ved web-scraping-with-curl: Det skal du vide
Selvom jeg er stor fan af cURL, er det ikke en mirakelløsning. Her er, hvor det typisk kommer til kort:
- Ingen JavaScript-eksekvering: cURL kan ikke håndtere sider, der kræver JavaScript for at rendere indhold eller løse anti-bot-udfordringer ().
- Parsing er manuelt: Du får rå HTML eller JSON, men du skal selv parse—ofte med ekstra scripts eller værktøjer.
- Begrænset session-håndtering: Komplekse logins, tokens eller flertrinsformularer bliver hurtigt rodet.
- Ingen indbygget datastrukturering: cURL omdanner ikke websider til rækker, tabeller eller regneark.
- Let at fange af anti-bot: Mange sites bruger avanceret bot-beskyttelse (JavaScript, fingerprinting, CAPTCHAs), som cURL ikke kan omgå ().
Her er en hurtig sammenligning:
| Begrænsning | Kun cURL | Moderne scrapingværktøjer (fx Thunderbit) |
|---|---|---|
| JavaScript-understøttelse | Nej | Ja |
| Datastrukturering | Manuelt | Automatisk (AI/skabelon) |
| Session-håndtering | Manuelt | Automatisk |
| Omgåelse af anti-bot | Begrænset | Avanceret (browser-baseret/AI) |
| Brugervenlighed | Teknisk | Ikke-teknisk |
Til statiske sider og API’er er cURL genialt. Til alt, der er dynamisk eller beskyttet, bør du op i værktøjskæden.
Thunderbit vs. cURL: Den bedste tilgang for ikke-tekniske brugere
Lad os snakke om , vores AI-drevne web scraper Chrome Extension. Hvis du arbejder med salg, marketing eller drift og bare vil have data fra et website ind i Excel, Google Sheets eller Notion—uden at røre kommandolinjen—så er Thunderbit bygget til dig.
Sådan står Thunderbit i forhold til cURL:
| Funktion | cURL | Thunderbit |
|---|---|---|
| Brugerflade | Kommandolinje | Peg-og-klik (Chrome Extension) |
| AI-feltforslag | Nej | Ja (AI læser siden og foreslår kolonner) |
| Pagination/undersider | Manuelt scripting | Automatisk (AI opdager og scraper) |
| Dataeksport | Manuelt (parse + gem) | Direkte til Excel, Google Sheets, Notion, Airtable |
| JavaScript/beskyttede sider | Nej | Ja (browser-baseret scraping) |
| No-code | Nej (kræver scripting) | Ja (alle kan bruge det) |
| Gratis niveau | Altid gratis | Gratis op til 6 sider (10 med trial-boost) |
Med Thunderbit åbner du bare udvidelsen, klikker “AI Suggest Fields”, og lader AI’en regne ud, hvilke data der skal udtrækkes. Du kan scrape tabeller, lister, produktdetaljer og endda besøge undersider automatisk. Derefter eksporterer du direkte til dine foretrukne business-værktøjer—ingen parsing, intet bøvl.
Thunderbit bruges af over og er især populært hos teams inden for salg, ecommerce og ejendom, der har brug for strukturerede data hurtigt.
Vil du prøve? .
Kombinér cURL og Thunderbit: Fleksible scrapingstrategier
Hvis du er teknisk bruger, behøver du ikke vælge kun ét værktøj. Faktisk kører mange teams cURL og Thunderbit side om side for maksimal fleksibilitet:
- Prototyp med cURL: Brug cURL til hurtigt at teste endpoints, inspicere headers og forstå, hvordan et site svarer.
- Skalér med Thunderbit: Når du har brug for strukturerede data, scraping af mange sider eller et workflow, der kan gentages, så skift til Thunderbit for peg-og-klik-udtræk og direkte eksport.
Et eksempel-workflow til markedsresearch:
- Brug cURL til at hente et par sider og inspicere HTML-strukturen.
- Find de felter, du vil have (fx produktnavne, priser, anmeldelser).
- Åbn Thunderbit, klik “AI Suggest Fields”, og lad AI’en sætte scraperen op.
- Scrape alle sider (inkl. undersider eller paginerede lister) og eksportér til Google Sheets.
- Analysér, del og handl på data—uden manuel parsing.
Hurtig beslutningstabel:
| Scenarie | Brug cURL | Brug Thunderbit | Brug begge |
|---|---|---|---|
| Hurtigt API- eller statisk side-fetch | ✅ | ||
| Strukturerede data i et regneark | ✅ | ||
| Fejlsøgning af headers/cookies | ✅ | ||
| Scraping af dynamiske/JS-tunge sider | ✅ | ||
| Gentageligt no-code-workflow | ✅ | ||
| Prototyping og derefter skalering | ✅ | ✅ | Hybrid workflow |
Typiske udfordringer og faldgruber ved web scraping med cURL
Før du går all-in med cURL, er her de udfordringer, du typisk støder på i praksis:
- Anti-bot-systemer: Mange sites bruger avanceret beskyttelse (JavaScript challenges, CAPTCHAs, fingerprinting), som cURL ikke kan omgå ().
- Datakvalitet: HTML ændrer sig, felter mangler, eller layouts er inkonsistente—det kan knække dine scripts.
- Vedligeholdelsesbyrde: Hver gang et site ændrer sig, skal du opdatere din parsinglogik.
- Jura og compliance: Tjek altid vilkår, robots.txt og relevant lovgivning, før du scraper. At data er offentlige betyder ikke automatisk, at de frit kan bruges (, ).
- Skaleringsgrænser: cURL er stærkt til små opgaver, men ved stor skala skal du selv håndtere proxies, rate limits og fejlhåndtering.
Tips til fejlsøgning og compliance:
- Start altid med sites, hvor du har tilladelse, eller demo-sites (som ).
- Respektér rate limits—undgå at “hamre” endpoints.
- Undgå at scrape persondata, medmindre du har et lovligt grundlag.
- Rammer du JavaScript- eller CAPTCHA-vægge, så overvej et browser-baseret værktøj som Thunderbit.
Trin-for-trin-opsummering: Sådan scraper du websites med cURL
Her er din hurtige tjekliste til web-scraping-with-curl:
- Find dine mål-URL’er: Start med en statisk side eller et API-endpoint.
- Hent siden:
curl URL - Gem output i en fil:
curl -o file.html URL - Se headers/debug:
curl -I URL,curl -v URL - Send POST-data:
curl -d "a=1&b=2" URL - Håndtér cookies/sessioner:
curl -c cookies.txt ...,curl -b cookies.txt ... - Sæt custom headers/User-Agent:
curl -A "..." -H "..." URL - Følg redirects:
curl -L URL - Brug proxies (hvis nødvendigt):
curl -x proxy:port URL - Automatisér scraping af flere sider: Brug shell-loops eller scripts.
- Parse og strukturér data: Brug ekstra værktøjer/scripts efter behov.
- Skift til Thunderbit for struktureret no-code scraping eller dynamiske sider.
Konklusion og vigtigste pointer: Vælg det rigtige web scraping-værktøj
Web-scraping-with-curl er stadig en stærk kompetence for tekniske brugere i 2026—særligt til hurtige dataudtræk, prototyper og automatisering. cURL’s hastighed, scriptbarhed og udbredelse gør det til en fast del af enhver udviklers værktøjskasse. Men i takt med at nettet bliver mere dynamisk og bedre beskyttet, og at forretningsbrugere forventer strukturerede data uden kode, flytter værktøjer som grænserne for, hvad der er muligt.
Vigtigste pointer:
- Brug cURL til statiske sider, API’er og hurtig prototyping—særligt når du vil have fuld kontrol.
- Skift til Thunderbit (eller lignende AI Web Scraper-værktøjer), når du har brug for strukturerede data, skal håndtere dynamiske/JavaScript-tunge sider, eller vil have et no-code workflow, der passer til forretningen.
- Kombinér begge for maksimal fleksibilitet: prototyp med cURL, skalér og strukturér med Thunderbit.
- Scrape altid ansvarligt—respektér vilkår, rate limits og juridiske rammer.
Vil du se, hvor nemt web scraping kan være? og oplev AI-drevet dataudtræk selv. Og hvis du vil dykke dybere, så kig forbi for flere guides, tips og brancheindsigter. Du vil måske også kunne lide:
God scraping—og må dine data altid være rene, strukturerede og kun en kommando (eller et klik) væk.
FAQs
1. Kan cURL håndtere websider, der renderes med JavaScript?
Nej, cURL kan ikke køre JavaScript. Det henter rå HTML, som serveren leverer. Hvis en side kræver JavaScript for at rendere indhold eller løse anti-bot-udfordringer, kan cURL ikke få adgang til dataene. I de tilfælde bør du bruge browser-baserede værktøjer som .
2. Hvordan gemmer jeg cURL-output direkte i en fil?
Brug -o: curl -o filename.html URL. Så skrives response body til en fil i stedet for at blive vist i terminalen.
3. Hvad er forskellen på cURL og Thunderbit til web scraping?
cURL er et kommandolinjeværktøj til at hente rå webdata—ideelt til tekniske brugere og automatisering. Thunderbit er en AI-drevet Chrome Extension til forretningsbrugere, der vil udtrække strukturerede data fra ethvert website, håndtere dynamiske sider og eksportere direkte til fx Excel eller Google Sheets—uden kode.
4. Er det lovligt at scrape websites med cURL?
At scrape offentlige data er generelt lovligt i USA efter nyere domme, men du bør altid tjekke sitets vilkår, robots.txt og relevant lovgivning. Undgå at scrape persondata eller beskyttede data uden tilladelse, og respekter rate limits og etiske retningslinjer (, ).
5. Hvornår bør jeg skifte fra cURL til et mere avanceret værktøj som Thunderbit?
Hvis du skal scrape dynamiske/JavaScript-tunge sider, vil have strukturerede data i et regneark, eller foretrækker et no-code workflow, er Thunderbit et bedre valg. Brug cURL til hurtige, tekniske opgaver; brug Thunderbit til forretningsvenlig, gentagelig dataudtræk.
For flere tips og guides om web scraping, besøg eller se vores .