
Er web scraping ulovligt? Det er det million-dollar-spørgsmål, jeg hører fra founders, marketingfolk og data-nørder hver eneste uge.
Med — første gang automatiseret trafik har overhalet menneskelig aktivitet — og en stor del af det brugt til web scraping til business intelligence, salg og AI-træning, er det ikke mærkeligt, at alle prøver at finde ud af, hvor de juridiske grænser egentlig går.
Den ene dag ser du en overskrift om en dom, der siger, at scraping af offentlige data er helt lovligt. Den næste advarer myndighederne om “ulovlig” indsamling af data fra sociale medier. Det er forvirrende, også for folk som mig, der bruger dagene på at bygge AI-værktøjer til web scraping hos .
Så, er web scraping ulovligt? Svaret er ikke et enkelt ja eller nej. Det afhænger af, hvad du scraper, hvor du scraper fra, hvordan du bruger dataene, og hvad lovgivningen siger i dit land.
I denne dybdegående gennemgang gennemgår jeg det juridiske landskab, afliver nogle udbredte myter og deler praktiske tips (plus et par erfaringer fra virkeligheden) til, hvordan du holder dig på den sikre side — uanset om du er solo-founder eller del af et Fortune 500-data-team.
Web Scraping og loven: Findes der en klar grænse?
Hvis du håbede på et svar i én sætning, så sparer jeg dig tiden: loven har ikke trukket en skarp og tydelig grænse for web scraping.
I stedet er det et kludetæppe af overlappende regler — dataejerskab, privatliv, immaterielle rettigheder, anti-hacking-lovgivning og de berygtede Terms of Service (ToS). Alle kan komme i spil, og svaret afhænger ofte af din konkrete situation ().
Lad os dele det op i de tre store juridiske kategorier:
- Dataejerskab: Generelt kan fakta og offentlige oplysninger (som priser eller telefonnumre) ikke ophavsretsbeskyttes. Men kreativt indhold (artikler, billeder) og proprietære databaser kan være beskyttet — især i EU, hvor der findes særlige “database rights” ().
- Privatliv: Moderne privatlivslovgivning (tænk GDPR i Europa og PIPL i Kina) behandler persondata som en reguleret ressource — også selvom de er offentligt tilgængelige. At scrape navne, e-mails eller sociale profiler uden et lovligt grundlag kan få dig i problemer ().
- Kontrakter (Terms of Service): Mange websites forbyder direkte scraping i deres ToS. Selvom ToS ikke er lov, kan domstole behandle dem som bindende kontrakter. Overtrædelse kan føre til sager, og i nogle tilfælde kan det også udløse anti-hacking-lovgivning, hvis du omgår tekniske blokeringer ().
Så, er web scraping ulovligt? Nogle gange ja, nogle gange nej — og ofte “det kommer an på det.” Djævlen ligger i detaljerne.
Sammenligning af juridiske perspektiver: USA, EU, UK og Kina
Her er en hurtig tabel, der viser, hvordan større regioner ser på web scraping:
| Region | Scraping af offentlige data | Scraping af personlige/private data | Håndhævelse & vigtige pointer |
|---|---|---|---|
| USA | Generelt tilladt for offentlige data (se hiQ v. LinkedIn). Overtrædelse af ToS kan føre til civile søgsmål. | Begrænset/ulovligt, hvis du bryder logins eller misbruger persondata. Delstatslove (som CCPA) kan gælde. | Påbud, IP-blokering, retssager. CFAA kan bruges, hvis du omgår tekniske barrierer. |
| EU | Betinget tilladt for offentlige, ikke-personlige data. Database-rettigheder kan gælde. EU AI Act (2026) indfører krav om gennemsigtighed for AI-træningsdata. | Hårdt reguleret under GDPR — også offentlige persondata kræver et lovligt grundlag. | Databeskyttelsesmyndigheder kan udstede bøder ved privatlivsbrud. Ophavsret/database-rettigheder håndhæves også. EU AI Act forbyder scraping af ansigtsbilleder til AI. |
| UK | Ligner EU. Offentlige, ikke-personlige data kan scraped, men datarettigheder og kontrakter skal respekteres. | Strengt på persondata — UK GDPR gælder. Computer Misuse Act kriminaliserer uautoriseret adgang. | ICO kan sanktionere overtrædelser af databeskyttelsen. Domstole kan håndhæve ToS. |
| Kina | Stramt kontrolleret. Offentlige, ikke-personlige data kan scraped til intern brug, men miljøet er forsigtigt. | Meget begrænset — PIPL kræver samtykke til persondata. Love om unfair competition gælder. | Straffesager ved storskalascraping. Domstole bruger unfair competition-lovgivning til at stoppe uautoriseret scraping. |
(, )
Er web scraping ulovligt? De vigtigste juridiske faktorer
Hvad er det så, der afgør, om dit scraping-projekt er lovligt eller risikabelt? Her er de store faktorer:
- Offentlige vs. private data: At scrape data, som alle kan se på det åbne web, er generelt sikrere. Men scraping bag login, betalingsmur eller tekniske barrierer? Det er sandsynligvis ulovligt ().
- Datatypen: Persondata (navne, e-mails, profiler) udløser privatlivslovgivning. Ophavsretligt beskyttet indhold (artikler, billeder) må ikke kopieres i sin helhed. Rene fakta (priser, vejr) er som regel fair game ().
- Formålet: Intern analyse eller research bliver typisk set mere lempeligt på end viderublicering eller salg af scraped data. Bruger du dataene til direkte konkurrence med kilden? Så er en retssag lige om hjørnet ().
- Overholdelse af website-regler: Tjek altid robots.txt og ToS. Robots.txt er ikke juridisk bindende, men det er god praksis at respektere det. ToS-overtrædelser kan føre til civile sager eller værre ().
- Tekniske foranstaltninger: Det er vigtigt at scrape i menneskelignende tempo og ikke omgå sikkerhedsforanstaltninger. Hvis du hamrer en server eller går uden om CAPTCHAs, kan du bevæge dig ind i hacking-territorium ().
Hvad ændrede sig i 2024–2026: vigtige domme og reguleringer
Landskabet for web scraping har ændret sig markant siden 2023. Her er de udviklinger, som alle scrapers bør kende:
Store domme
-
Meta v. Bright Data (2024): En føderal amerikansk domstol . Dommeren slog fast, at “en besøgende ikke betragtes som en ‘user’, medmindre vedkommende har en konto.” Meta trak de resterende krav tilbage kort efter. Det er en vigtig sejr for scraping af offentlige data.
-
X Corp v. Bright Data (2024): Twitter (nu X) tabte en lignende sag, hvilket understreger det samme princip: scraping af offentligt tilgængelige data uden login er ikke en ToS-overtrædelse, fordi scraperen aldrig har accepteret vilkårene.
-
Reddit v. Perplexity AI (oktober 2025): Reddit , med henvisning til DMCA og påstand om omgåelse af anti-bot-systemer. Det peger på en ny juridisk strategi: platforme vender sig mod ophavsret og anti-omgåelseskrav i stedet for CFAA.
-
NYT v. OpenAI (marts 2025): En føderal dommer og afviste OpenAIs anmodning om at få sagen afvist. Det kan blive en vigtig præcedens for, om scraping af indhold til træning af AI-modeller kan kaldes “fair use”.
-
Anthropic-forlig (september 2025): Anthropic indgik et forlig på 1,5 mia. dollar i et amerikansk class action-søgsmål om brug af ophavsretligt beskyttede tekster til træning af sin AI-model — et tydeligt signal om, at omkostningerne ved scraping til AI er meget reelle.
Den store trend: fra CFAA til kontrakt- og ophavsret
Mønstret er tydeligt: CFAA (Computer Fraud and Abuse Act) mister styrke som våben mod scrapers af offentlige data. Virksomheder, der forsøgte at bruge CFAA mod scraping af offentlige data — Meta, X, LinkedIn — har i vid udstrækning tabt. I stedet flytter det juridiske slagfelt til:
- Kontraktsret (ToS-overtrædelser — men domstolene siger, at ikke-brugere ikke er bundet af ToS)
- Ophavsretlige krav (især ved AI-træningsdata)
- Anti-omgåelsesregler (DMCA Section 1201)
For scrapers betyder det, at den juridiske risiko ikke er forsvundet — den har bare flyttet sig.
Regulatoriske ændringer
- CCPA-opdateringer i 2026: Californiens reviderede CCPA-regler og tilføjede nye regler for automatiseret beslutningstagning (ADMT), risikovurderinger og krav til data brokers.
- Nye amerikanske delstatslove om privatliv: Indiana, Kentucky og Rhode Island vedtog omfattende privatlivslove, der gælder fra 2026.
- EU AI Act: Fuld håndhævelse begynder — med krav om, at AI-udviklere oplyser kilder til træningsdata, respekterer opt-outs for ophavsret og forbyder scraping af ansigtsbilleder til AI-systemer.
- AI Accountability for Publishers Act (februar 2026): Et foreslået amerikansk lovforslag, som vil kræve, at AI-virksomheder får tilladelse og betaler udgivere, før de scraper deres indhold.
Scraping-politikker hos store platforme: Det skal du vide
Ikke alle websites behandler scraping ens. Her er et overblik platform for platform over, hvad de største sider tillader, hvad de blokerer, og hvad domstolene har sagt:
| Platform | ToS om scraping | Tekniske forsvar | Juridisk håndhævelse | Hvad der i praksis er sikkert |
|---|---|---|---|---|
| Google (Search & Maps) | Forbyder automatiseret adgang i ToS. Maps Platform har en tydelig “No Scraping”-klausul. | SearchGuard JS-udfordringer, CAPTCHAs, rate limiting. Opdaterede robots.txt i 2025 for at blokere AI-crawlere. | Sagsøgte scrapers i december 2025 med DMCA. Blokerer aktivt AI-crawlere (Anthropic, Meta, OpenAI). | Scraping af offentlige Google Maps-forretningsdata er juridisk forsvarligt (hiQ-præcedens), men forvent tekniske blokeringer. Brug officielle APIs, hvor det er muligt. |
| Amazon | Forbyder eksplicit al scraping i Conditions of Use (“no robot, spider, scraper, or other automated means”). | Aggressiv bot-detektion, CAPTCHA, IP-blokering. robots.txt blokerer alle bots undtagen Googlebot/Bingbot. Blokerer eksplicit AI-crawlere siden 2025. | Sagsøgte Perplexity AI i november 2025. Sender regelmæssigt cease-and-desist-breve. Opdaterede BSA i marts 2026 med regler for AI-agenter. | Offentlige produktdata (priser, produkter) er faktuelle og kan scraped efter amerikansk ret, men Amazon bekæmper det hårdt. Begræns requests og undgå persondata. |
| Forbyder scraping i ToS; kræver brugeraccept for at få adgang til tjenester. | Login-mure for det meste profilindhold, anti-bot-detektion, rate limiting. | hiQ-sagen bekræftede, at scraping af offentlige profiler ikke er en CFAA-overtrædelse, men LinkedIn vandt på kontrakt/uretmæssig konkurrence, da falske konti blev brugt. | Offentlige profiler (synlige uden login) er juridisk forsvarlige at scrape. Opret aldrig falske konti, og scrape aldrig data bag login. | |
| Meta (Facebook & Instagram) | ToS forbyder scraping; særregler for data bag login vs. data uden login. | Login-mure for det meste indhold, avanceret bot-detektion. | Tabte til Bright Data i 2024 — retten slog fast, at ToS ikke gælder for scrapers, der ikke er logget ind. Trak de resterende krav tilbage. | Offentlige data (virksomhedssider, offentlige opslag) uden login står juridisk stærkere. Scrape aldrig private profiler eller data bag login. |
| X (Twitter) | Opdaterede ToS i 2023 for at forbyde al scraping og crawling uden skriftligt samtykke. Fjernede undtagelsen for robots.txt. | robots.txt blokerer alle crawlers (Disallow: /). Cloudflare Turnstile-udfordringer. Stramme rate limits (300 req/time). IP-reputationsscoring. | Tabte til Bright Data om offentlige data, men begrænser teknisk adgang aggressivt. | Offentlige tweets og profiler er juridisk forsvarlige, men X’s tekniske barrierer er blandt de hårdeste i 2026. Forvent blokeringer uden premium proxy-infrastruktur. |
Kort sagt: Domstole har konsekvent slået fast, at scraping af offentligt synlige data uden login ikke overtræder CFAA. Men platforme kan stadig gå efter dig med kontraktret, ophavsret eller anti-omgåelsesregler — og de vil gøre livet svært med tekniske barrierer. Scrape altid ansvarligt.
AI-træningsdata og web scraping: Den nye juridiske frontlinje
Hvis du følger med i nyhederne i 2026, ved du, at scraping af data til træning af AI-modeller er blevet den heftigste juridiske slagmark. Her er, hvad der sker:
- Ophavsretssagerne hober sig op. New York Times, forfattere og udgivere har sagsøgt OpenAI, Anthropic og andre og hævder, at massiv scraping af ophavsretligt beskyttet indhold til træning af LLM’er ikke er “fair use”. Anthropic indgik et stort forlig i et class action-søgsmål for 1,5 mia. dollar i 2025 — et klart tegn på, at omkostningerne ved scraping til AI er meget reelle.
- Forsvaret “fair use” er usikkert. Amerikanske domstole har endnu ikke afgjort definitivt, om træning af AI på scraped data er fair use. Tidlige afgørelser tyder på, at det i høj grad afhænger af hvordan dataene blev indsamlet, og hvad der sker med AI’ens output.
- Ny lovgivning er på vej. (fremsat i februar 2026) vil kræve, at AI-virksomheder får tilladelse og betaler udgivere, før de scraper deres indhold.
- EU AI Act (fuld håndhævelse ) kræver, at AI-udviklere oplyser kilder til træningsdata, respekterer maskinlæsbare copyright-opt-outs (under Copyright Directive’s TDM-undtagelse) og mærker AI-genereret indhold. Den forbyder også AI-systemer, der scraper ansigtsbilleder fra internettet.
- AI/LLM-crawlere eksploderer. AI-crawlere firedoblede deres andel af webtrafikken fra 2,6% til 10,1% på bare otte måneder. OpenAIs GPTBot voksede alene med 305%. Som svar opdaterer store sites (Amazon, Reddit, NYT) robots.txt for eksplicit at blokere AI-crawlere.
Hvad det betyder for dig: Hvis du scraper data til klassiske forretningsformål (leadgen, prisovervågning, markedsresearch), gælder disse AI-specifikke regler måske ikke direkte. Men hvis du bruger scraped data til at træne AI-modeller, så vær ekstremt forsigtig — og få juridisk rådgivning.
Web scraping-lovgivning rundt om i verden: En hurtig sammenligning
Lad os zoome ud og se, hvordan reglerne ser ud globalt:
- USA: Intet generelt forbud. Scraping af offentligt tilgængelige sider er som udgangspunkt lovligt (), og dommene i Meta- og X Corp-sagerne i 2024 har yderligere styrket sagen for scraping af offentlige data. Men scraping bag login eller tekniske blokeringer kan stadig udløse CFAA. Tendensen går nu i retning af, at virksomheder bruger kontraktsret og ophavsretlige krav i stedet. Privatlivslovgivningen udvides hurtigt: CCPA fik store opdateringer med virkning fra 1. januar 2026, inklusive nye regler om automatiseret beslutningstagning og krav til data brokers. Indiana, Kentucky og Rhode Island vedtog også omfattende privatlivslove i 2026.
- Den Europæiske Union: Strenge privatlivsregler. GDPR gælder også for offentlige persondata. Database-rettigheder kan blokere storskala scraping af strukturerede data (). NYT: træder i fuld kraft den 2. august 2026, og kræver at AI-udviklere oplyser kilder til træningsdata og respekterer copyright-opt-outs. Loven forbyder scraping af ansigtsbilleder fra internettet til AI-systemer.
- Storbritannien: Minder om EU-reglerne efter Brexit. Offentlige data kan scraped, men scraping af personoplysninger er stramt reguleret. Computer Misuse Act kan kriminalisere uautoriseret adgang.
- Kina: Meget restriktivt. PIPL og Data Security Law kræver samtykke til persondata. Domstole bruger unfair competition-lovgivning til at blokere scraping, der skader virksomheder ().
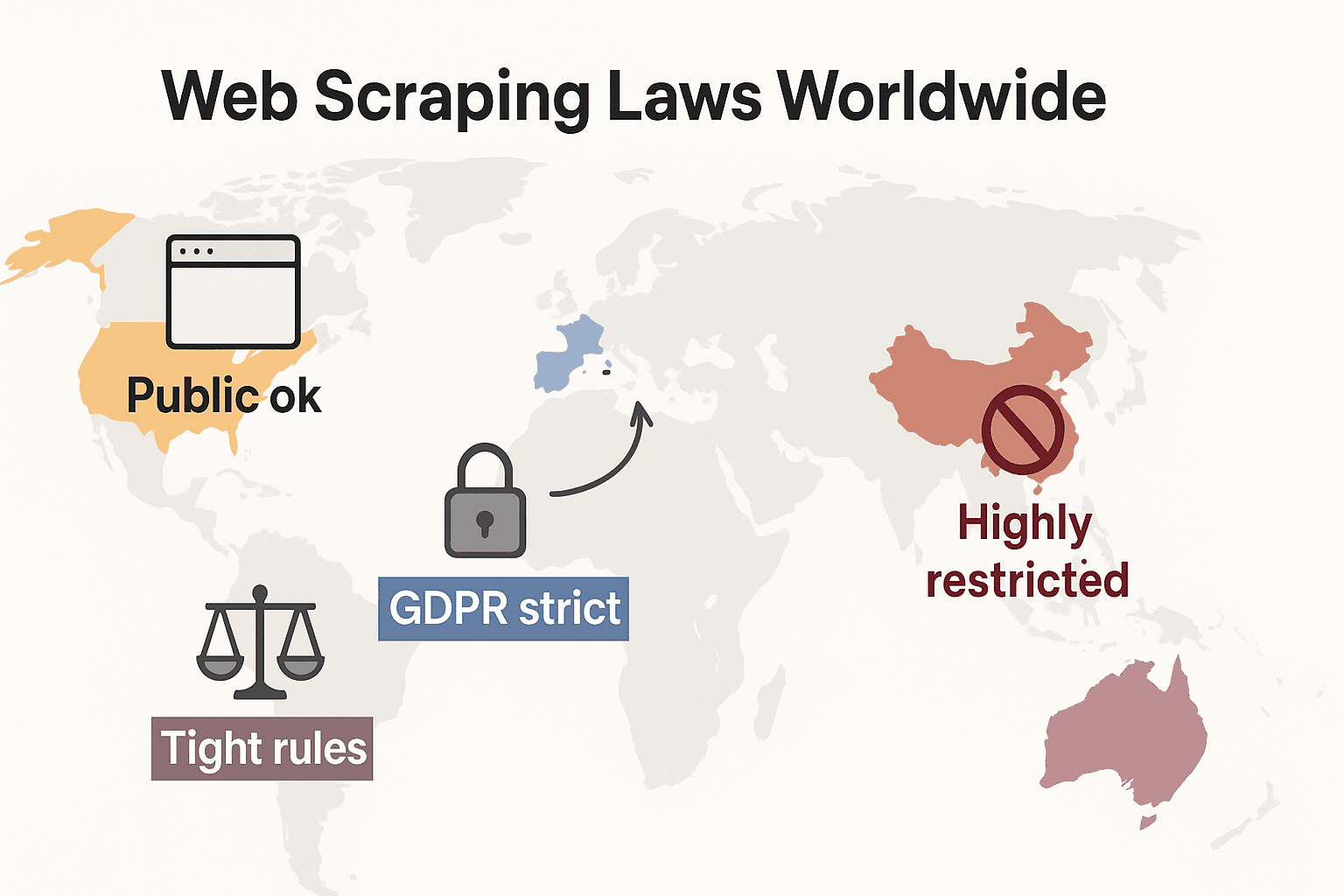
Konklusionen er klar: scraping af offentlige, ikke-personlige data til intern brug er som regel det sikreste. Alt andet? Tjek lokal lovgivning og gå varsomt frem.
Udbredte myter om web scrapings lovlighed
Lad os aflive nogle myter, jeg hører hele tiden:
- Myte 1: “Web scraping er ulovligt, punktum.”
Forkert. Der findes ingen lov, der forbyder al web scraping. Det er måden og indholdet, der afgør sagen (). - Myte 2: “Hvis data er offentlige, kan jeg gøre, hvad jeg vil med dem.”
Ikke helt. Offentlige data kan stadig være beskyttet af privatlivs- eller ophavsretslovgivning, og ToS kan begrænse bestemte anvendelser (). - Myte 3: “Web scraping er det samme som hacking.”
Nej. At scrape offentlige websider er ikke hacking. At omgå login eller tekniske barrierer er en helt anden sag (). - Myte 4: “Hvis jeg ikke bliver taget, er det fint.”
Risikabel tankegang. Mange sites bruger anti-bot-teknologi og opdager dig. Tavshed er ikke samtykke. - Myte 5: “Hvis jeg giver kredit eller bruger data internt, er det okay.”
Kildeangivelse ophæver ikke ophavsret eller privatlivsregler. Intern brug er sikrere, men ikke et frit pas. - Myte 6: “Alt web scraping krænker privatlivets fred.”
Ikke alt scraping involverer persondata. Men scraping af store mængder personlige oplysninger uden sikkerhedsforanstaltninger er næsten altid ulovligt (). - Myte 7: “Hvis en websites ToS forbyder scraping, er det altid ulovligt at scrape.”
Ikke nødvendigvis. I 2024 slog domstolene i Meta v. Bright Data og X Corp v. Bright Data fast, at ToS ikke kan binde brugere, som aldrig har accepteret dem — altså hvis du scraper uden at logge ind eller oprette en konto, gælder sidens ToS muligvis ikke for dig. Det er stadig et område i udvikling, men det er en markant ændring.
Sådan scraper du data lovligt: bedste praksis for compliance
Her er min faste tjekliste til lovlig og etisk web scraping:
- Læs og respekter sidens Terms of Service. Hvis der står “no scraping”, så overvej at stoppe eller bede om tilladelse ().
- Hold dig til offentlige data. Hvis du har brug for et password, er det begrænset — lad være med at scrape det ().
- Tjek robots.txt og crawl høfligt. Det er ikke juridisk bindende, men god etikette. Belas ikke servere — spred dine requests ud ().
- Undgå persondata, medmindre du har et lovligt grundlag. Hvis du skal indsamle det, så overhold GDPR/CCPA og minimér mængden.
- Videreskriv ikke scraped indhold i sin helhed. Tilføj værdi eller analyse, eller få tilladelse ().
- Lad være med at fodre scraped indhold ind i AI-modeller uden at tjekke ophavsret. Landskabet ændrer sig hurtigt — få rådgivning, hvis det er dit use case.
- Brug officielle APIs eller dataeksporter, når de findes. De er bygget til formålet og er normalt sikrere ().
- Vær gennemsigtig og ansvarlig. Hvis du indsamler persondata, så informér folk og før log over dine aktiviteter.
- Minimér og beskyt dine data. Indsaml kun det, du har brug for, hold det korrekt, og opbevar det sikkert.
- Hold dig opdateret og søg juridisk rådgivning ved gråzoner. Lovgivning og domme ændrer sig hurtigt — især EU AI Act og amerikanske delstatslove om privatliv. Når du er i tvivl, så spørg en ekspert.
Brug af web scraping-værktøjer lovligt: det virksomheder skal vide
Web scraping-værktøjer som gør dataindsamling tilgængelig for folk uden kodeerfaring, men du skal stadig bruge dem ansvarligt:
- Vælg værktøjer med compliance i fokus. Thunderbit scraper for eksempel kun det, du kan se i din browser — ingen skjulte API-hacks eller uautoriseret adgang ().
- Hold dig til legitime use cases. Intern analyse, markedsresearch og overvågning af konkurrenters priser er generelt sikkert. Videresalg eller offentliggørelse af scraped data? Meget mere risikabelt.
- Konfigurer værktøjerne til compliance. Sæt crawl-forsinkelser, respekter robots.txt, og brug templates, der kun indsamler det, du har brug for.
- Behold data internt. Brug af scraped data internt er sikrere end at videresende eller genpublicere dem.
- Uddan dit team. Sørg for, at alle forstår reglerne og best practice.
- Brug indbyggede compliance-funktioner. Thunderbit advarer brugere om risikable sites, scraper i menneskelignende tempo og gemmer ikke dine data på deres servere.
- Tving det ikke igennem. Hvis et værktøj ikke kan scrape et site, så lad være med at forsøge at hacke udenom. Ikke alle data kan hentes uden risiko.
Thunderbits tilgang: AI web scraping med compliance i centrum
Hos har vi brugt meget tid på at tænke over compliance. Sådan hjælper vores AI Web Scraper brugerne med at holde sig på den rigtige side af loven:
- Scraper kun det, du kan se. Thunderbit fungerer i din browser-session, så den kan ikke tilgå data, du ikke selv kunne kopiere manuelt.
- Vejleder med advarsler. Hvis du forsøger at scrape et site med strenge anti-scraping-regler, advarer Thunderbit dig.
- Menneskelige scrape-hastigheder. Uanset om du scraper lokalt eller i skyen, undgår Thunderbit at belaste servere unødigt.
- Tilpasset dataval. Vores AI foreslår relevante kolonner, så du kun indsamler det, du har brug for.
- Understøttelse af undersider og pagination. Thunderbit navigerer på sites som en rigtig bruger og respekterer deres struktur.
- Privatliv og sikkerhed. Dine data bliver hos dig — Thunderbit gemmer eller genbruger dem ikke.
- Compliance-venlige eksportmuligheder. Eksportér direkte til Google Sheets, Airtable, Notion eller CSV til sikker intern brug.
- Planlægning og automatisering. Opsæt gentagne scrapes med ansvarlige intervaller.
- Flersproget support. Thunderbits brugerflade understøtter 34 sprog, så compliance er tilgængelig globalt.
- Løbende opdatering af templates. Vores instant templates til populære sites holdes opdateret i takt med juridiske og tekniske ændringer.
Ved at bygge compliance ind i produktet hjælper Thunderbit teams med at indsamle de data, de har brug for — uden juridisk hovedpine.
Vær på forkant: Tilpas dig juridiske og tekniske ændringer i web scraping
Web scraping er ikke noget, man bare sætter op og glemmer. Lovgivning og websites ændrer sig hele tiden. Sådan holder du dig foran:
- Følg de juridiske udviklinger. Tempoet accelererede i 2024–2026 — følg tech-law-nyheder, regulatoropdateringer og brancheblogs (som ). Hold øje med håndhævelsen af EU AI Act (august 2026), nye amerikanske delstatslove om privatliv og de igangværende AI-ophavsretssager.
- Tilpas dig tekniske ændringer. Sites opdaterer hele tiden deres layout og anti-bot-forsvar. Store platforme (Amazon, X, Google) strammede markant op i 2025–2026. Thunderbits AI og templates er designet til at tilpasse sig automatisk.
- Brug officielle APIs, når de findes. Hvis et site skifter til en betalt API-model, kan det være værd at skifte for bedre stabilitet og compliance.
- Auditer din scraping løbende. Dokumentér dine kilder, tjek ændringer i ToS eller politikker, og justér din strategi efter behov.
- Brug Thunderbits template-opdateringer. Vores team holder skabelonerne aktuelle, så du slipper for at bekymre dig om breaking changes eller nye compliance-krav.
- Vær fleksibel. Hvis en datakilde bliver for risikabel, så skift til en anden eller undersøg et partnerskab.
Med de rigtige værktøjer og den rigtige tilgang kan du holde din data-pipeline kørende — uden at træde på juridiske landminer.
Konklusion: Navigér i det juridiske landskab for web scraping
Web scraping er ikke i sig selv ulovligt — det er et stærkt værktøj til forretning, research og innovation. Men som alle værktøjer kommer det med regler. Nøglen er at forstå, hvad du scraper, hvordan du scraper det, og hvad du vil gøre med dataene. Respekter lokal lovgivning, følg websites’ politikker, og brug compliance-fokuserede værktøjer som for at holde din drift på den rigtige side af loven.
Domafgørelserne fra 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) har styrket sagen for scraping af offentlige data, men nye risici vokser frem omkring AI-træningsdata, ophavsretskrav og EU AI Act. Platformsspecifikke regler varierer meget — Google, Amazon, LinkedIn, Meta og X håndhæver hver deres politikker forskelligt — så kend landskabet, før du scraper.
Hvis du er i tvivl, så søg juridisk rådgivning — især ved store eller følsomme projekter. Og husk: det juridiske landskab ændrer sig hele tiden, så vær opdateret og fleksibel.
Vil du lære mere om web scraping, compliance og automatisering? Tjek for flere guides, eller prøv selv.
Ofte stillede spørgsmål
1. Er web scraping ulovligt overalt?
Nej. Web scraping er ikke i sig selv ulovligt, men lovligheden afhænger af, hvad du scraper, hvordan du gør det, og hvor du befinder dig. Scraping af offentlige, ikke-personlige data til intern brug er generelt tilladt i de fleste regioner, men scraping af persondata eller ophavsretligt beskyttet indhold — eller overtrædelse af sidens vilkår — kan være ulovligt ().
2. Gør robots.txt scraping ulovligt, hvis jeg ignorerer det?
Robots.txt er ikke juridisk bindende, men det er best practice at respektere det. At ignorere robots.txt gør ikke i sig selv, at du bliver sagsøgt, men det kan få dig til at fremstå som en “bad actor”, hvis der opstår en tvist ().
3. Kan jeg scrape Google, Amazon eller LinkedIn?
Det er kompliceret. Alle tre forbyder scraping i deres ToS, men domstole har slået fast, at ToS måske ikke binder brugere, der ikke er logget ind (se Meta v. Bright Data og X Corp v. Bright Data, begge fra 2024). Scraping af offentligt synlige data (produktpriser, virksomhedsopslag, offentlige profiler) er generelt juridisk forsvarligt i USA. Hver platform håndhæver dog sine regler forskelligt: Amazon er mest aggressiv med juridiske tiltag (de sagsøgte Perplexity AI i november 2025); LinkedIn bruger primært tekniske barrierer og kontraktkrav; Google bruger i stigende grad DMCA-baseret håndhævelse. Scrape altid ansvarligt, og forvent tekniske modforanstaltninger.
4. Kan jeg scrape Facebook eller Instagram?
Efter Meta v. Bright Data (2024) står scraping af offentlige data fra Facebook og Instagram uden login juridisk stærkere. Retten slog fast, at Metas ToS ikke gælder for ikke-brugere. Men opret aldrig falske konti, og scrape aldrig data bag login-mure — det er at gå over grænsen.
5. Kan jeg scrape X (Twitter)?
X opdaterede sine ToS i 2023 for at forbyde al scraping uden skriftligt samtykke og har indført aggressive tekniske forsvar (Cloudflare Turnstile, rate limits på 300 requests/time, IP-reputationsscoring). Bright Data vandt dog en tilsvarende sag, hvor offentlige data scraped uden konto ikke er bundet af X’s ToS. Teknisk set er X en af de sværeste platforme at scrape i 2026.
6. Er det lovligt at scrape data til træning af AI-modeller?
Det er det største åbne spørgsmål i 2026. Store sager (NYT v. OpenAI, Anthropics forlig på 1,5 mia. dollar) peger på betydelig juridisk risiko. EU AI Act kræver oplysning om kilder til træningsdata og respekt for copyright-opt-outs. Det foreslåede AI Accountability for Publishers Act vil kræve tilladelse og betaling. Hvis du scraper til AI-træning, så få juridisk rådgivning, før du går videre.
7. Hvad er den sikreste måde at bruge web scraping-værktøjer som Thunderbit på?
Hold dig til at scrape offentlige data, respekter sidernes vilkår, undgå personoplysninger, medmindre du har et lovligt grundlag, og brug dataene internt. Thunderbit er designet til at hjælpe dig med at overholde reglerne ved kun at scrape det, der er synligt i din browser, og ved at advare dig om risikable sites ().
8. Kan jeg scrape data til kommerciel brug?
Det kommer an på. Brug af scraped data til intern analyse eller research er generelt sikrere. Videresalg eller offentliggørelse af scraped data, især hvis de er ophavsretligt beskyttede eller personlige, er langt mere risikabelt og kan kræve tilladelse eller licens.
9. Hvordan følger jeg med i juridiske og tekniske ændringer i web scraping?
Følg tech-law-nyheder, hold øje med ændringer i ToS og politikker på dine målsites, og brug værktøjer som Thunderbit, der løbende opdaterer templates og compliance-funktioner. Vigtige ting at holde øje med i 2026: håndhævelse af EU AI Act (august), igangværende AI-ophavsretssager og nye amerikanske delstatslove om privatliv. Når du er i tvivl, så kontakt en juridisk ekspert.