Redfin opdaterer , efter de er kommet ud. Den slags frisk data er guld værd for alle, der bygger en data pipeline til ejendomsmarkedet — og det er netop derfor, så mange scrapers går efter Redfin og bliver blokeret inden for få minutter.
Jeg har i årevis arbejdet med værktøjer til dataudtræk hos , og jeg kan sige det helt lige ud: kløften mellem at “scrape Redfin” og at “scrape Redfin uden at blive blokeret” er dér, hvor de fleste guides falder fra hinanden. De viser dig BeautifulSoup-koden, springer let hen over det punkt, hvor Cloudflare æder dine forespørgsler, og lader dig bare stirre på en 403-side og undre dig over, hvad der gik galt. Denne guide er anderledes. Jeg gennemgår tre reelle tilgange — HTML-parsing, Redfins skjulte API og en no-code-rute med Thunderbit — og bruger god tid på de anti-bot-beskyttelser, der faktisk betyder noget. Til sidst ved du præcis, hvilken metode der passer til dit niveau, din skala og din tolerance for vedligeholdelsesbesvær.
Hvad er Redfin, og hvorfor er dataene vigtige?
Redfin er en teknologidrevet ejendomsmægler med fastansatte mæglere, som henter boliger direkte fra MLS-feeds. Tjenesten dækker og har næsten 50 millioner månedlige besøgende. I modsætning til portaler, der kun samler data ind, er Redfins data verificeret af mæglere, og deres egen Redfin Estimate AVM dækker med en medianfejl på blot 1,96% for boliger, der er til salg.
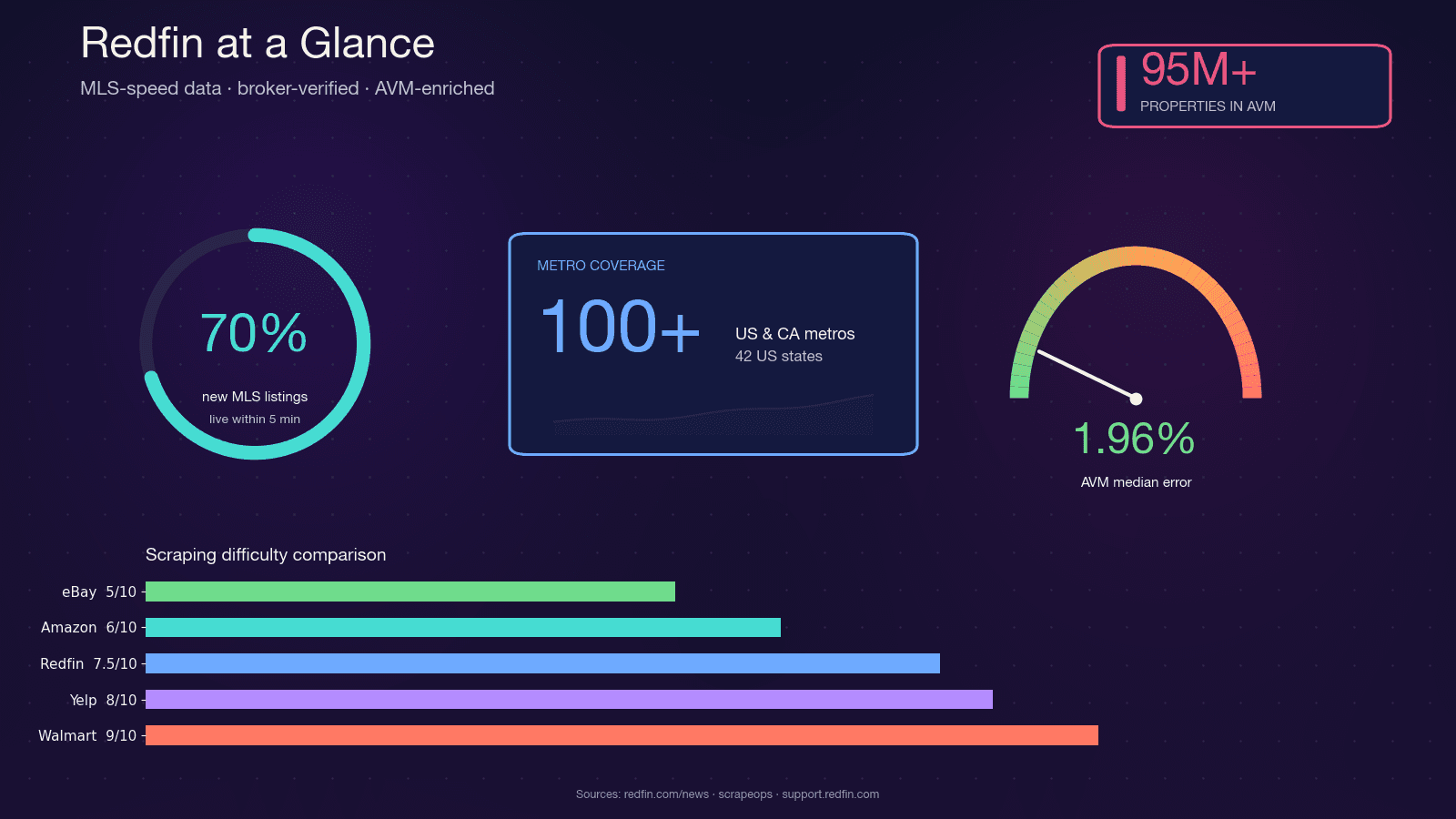
Kombinationen af MLS-hastighed, mæglerverificeret kvalitet og en stærk AVM er grunden til, at ejendomsinvestorer, mæglere, proptech-startups og dataanalytikere alle ønsker programmatisk adgang til Redfin-data. Python er det oplagte valg til opgaven: scraping-økosystemet (requests, BeautifulSoup, Selenium, Playwright) er modent, fællesskabet er enormt, og det spiller direkte sammen med pandas og Jupyter til analyse.
Hvorfor scrape Redfin med Python?
Brugsscenarierne er lige så forskellige som de mennesker, der har brug for dataene. Her er, hvordan forskellige målgrupper typisk bruger scraped Redfin-data:
| Målgruppe | Primært scraping-mål | Eksempel på brug |
|---|---|---|
| Ejendomsmæglere | Leadgenerering, markedsindsigt | Nye boliger og udløbne annoncer i serviceområdet; mægleroversigt til konkurrentanalyse |
| Ejendomsinvestorer | Deal flow, cap rate-analyse | Screening af lejeafkast, identificering af undervurderede boliger, daglige alarmer for nye boliger |
| Proptech-startups | Produktdata pipelines | AVM-træningsdata, markedsdashboards, iBuyer-opkøbsmotorer |
| Dataanalytikere | Markedsresearch, BI | Medianpris-trends på ZIP-kode-niveau, tidsserier for dage på markedet, forholdet mellem salgspris og udbudspris |
| Wholesalers / flippere | Overvågning af nødlidende boliger | Registrering af prisnedsættelser, tvangsauktioner, off-market comps |
Den bredere tendens bekræfter det: bruger nu predictive analytics til at finde muligheder og styre risiko. PropTech-markedet forventes at nå med en årlig vækst på 16,4%. Strukturerede ejendomsdata er ikke længere “nice to have” — de er et minimum.
Alle Redfin-datafelter, du kan scrape (komplet reference)
Før du skriver en eneste linje kode, skal du vide, hvad der faktisk er tilgængeligt. Jeg har gennemgået Redfins søgeresultatsider, detaljesider for boliger og mæglerprofiler — og sammenholdt det med open-source Stingray API wrappers som og . Det samlede antal lander på 117 forskellige felter på tværs af sidetyper.
Denne tabel er værd at bogmærke. At kende dataskemaet, før du koder, sparer timer med trial-and-error og jagt på selectors.
Felter på søgeresultatsiden
Det her er de lette felter, der ligger på listing-kortene — ofte kan de trækkes ud uden fuld JS-rendering:
| Felt | Datatype | Bemærkninger |
|---|---|---|
| Ejendoms-ID | Tal | Redfins interne int, udlæst fra /home/{id} i href |
| Udbudspris | Tal | |
| Fuld adresse | Tekst | |
| Soveværelser / Badeværelser / m² | Tal | Tre værdier i rækkefølge |
| Ejendomstype | Single Select | SFH, Condo, Townhouse, Multi |
| Status | Tekst | Active, Pending, Contingent |
| Dage på markedet | Tal | |
| Indikator for prisnedsættelse | Tal | Afvigelse fra oprindelig pris |
| Primært billede | Billed-URL | Ét billede pr. kort |
| Hot Home-badge | Boolean | |
| Dato/tid for åbent hus | Tekst | |
| Mæglerangivelse | Tekst |
Felter på detaljesiden for boligen
Detaljesiden er dér, hvor dybden for alvor er. Mange af disse felter kræver JavaScript-rendering eller Stingray API’et:
| Felt | Datatype | Bemærkninger |
|---|---|---|
| Redfin Estimate (på markedet) | Tal | Via /stingray/api/home/details/avm |
| Redfin Estimate (ikke på markedet) | Tal | Via /stingray/api/home/details/owner-estimate; medianfejl 7,52% |
| Byggeår / renoveret | Tal | |
| Grundstørrelse | Tal | |
| HOA-bidrag | Tal | Månedligt, hvis relevant |
| Ejendomsskat (årlig) | Tal | |
| Skattemæssig vurderet værdi | Tal | |
| Salgshistorik-tabel | Tabel | Pris, dato, hændelsestype |
| Beskrivelse af boligen | Tekst | Markedsføringsafsnit |
| Billed-URL’er (karusel) | Billed-URL’er | 20+ pr. bolig |
| Navn, telefon og e-mail på mægler | Tekst / Telefon / E-mail | Telefon er ofte skjult |
| Skolevurderinger (elementary/middle/high) | Tal | Plus distriktsnavn |
| Walk / Transit / Bike Score | Tal | |
| Klimarisikoscorer | Tal | Oversvømmelse, brand, varme, vind |
| Lignende aktive / solgte / nærliggende boliger | URL’er | Karuseldata |
| Parkering, garage, varme, køling | Tekst | Facilitet-grupper |
Felter på mæglerprofilen
| Felt | Datatype | Bemærkninger |
|---|---|---|
| Mæglernavn, billede, mæglerfirma, bio | Tekst / Billede | |
| Telefon, kontaktformular | Telefon / Tekst | Klik for at vise |
| Antal aktive boliger | Tal | |
| Salg de sidste 12 måneder / samlet volumen | Tal | |
| Gennemsnitligt forhold mellem listepris og salgspris | Tal | |
| Stjernebedømmelse / antal anmeldelser | Tal | |
| Erfaring i år / licensnr. | Tekst / Tal |
Når du bruger Thunderbits AI Suggest Fields-funktion på en Redfin-side, registrerer den automatisk de fleste af disse kolonner og tildeler de rigtige datatyper — uden at du manuelt skal mappe CSS selectors. Mere om det senere.
Redfins anti-bot-beskyttelse afkodet (ikke bare “brug en proxy”)
Her vil jeg gerne slå en pæl i jorden, for de fleste guides springer let hen over blokeringer og går direkte til “køb proxies hos vores sponsor”. Det hjælper ikke. Hvis du ikke forstår hvad Redfin gør for at opdage scrapers, bruger du bare proxy-kreditter uden at komme videre. , og — “mindre aggressiv end Zillow’s enterprise WAF, med fokus på custom rate limiting og JavaScript-challenges.”
Redfin kører et lagdelt setup: Cloudflare i kanten (JS-challenge, Turnstile, TLS/JA3-fingerprinting) plus en Redfin-specifik rate limiter i applikationslaget. Der er ingen Crawl-delay i deres robots.txt, fordi håndhævelsen sker på WAF-niveau.
Hvorfor simpel requests + BeautifulSoup fejler på Redfin
Hvis du sender en basal requests.get() til en Redfin-boligside med standard headers, sker der typisk dette:
- HTTP 403 — Cloudflares JS-challenge blev ikke løst, så du får challengen i stedet for boligdata.
- En interstitial challenge-side — HTML-body indeholder Cloudflares Turnstile-widget, ikke boliginformation.
- HTTP 200 med delvis HTML — Du får en skal med en stor indlejret JSON-blok under
root.__reactServerState.InitialContext, men ingen for-renderede listing-kort, ingen pris-historik og ingen skolevurderinger.
Redfin bruger sit eget (ikke Next.js), og hydration-nøglen er Redfin-specifik — root.__reactServerState.InitialContext med listing-data indlejret under ReactServerAgent.cache.dataCache. Det er ikke __NEXT_DATA__ eller window.__INITIAL_STATE__.
Den mest almindelige årsag til tavse 403’er? Manglende Sec-Fetch-* headers. Redfin/Cloudflare validerer eksplicit Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest og Sec-Fetch-User. Hvis de mangler, bliver du markeret med det samme.
Strategien til at komme igennem: forsinkelser, headers, proxies og sessions
Her er hele gennemgangen af forsvarslagene og de konkrete tiltag til hver enkelt:
| Redfins forsvar | Hvad det gør | Signal | Afværgestrategi |
|---|---|---|---|
| Cloudflare JS-challenge | Interstitial, der udsteder cf_clearance-cookie | 403 + Cloudflare HTML-body | curl_cffi med impersonate="chrome120"; varm session via forsiden; amerikansk residential proxy |
| Cloudflare Turnstile | Interaktiv CAPTCHA på højrisiko-sessions | 403 + Turnstile-widget | Headless browser med stealth + residential proxy |
| Cloudflare Error 1020 (ASN-ban) | Blokerer markerede IP’er/ASN’er i WAF | 403-body “Error 1020 Access Denied” | Skift til residential/mobile proxy; brug aldrig datacenter ASN’er |
| TLS/JA3-fingerprinting | Finder ikke-browser TLS-stakke | Tavs 403 selv med perfekte headers | curl_cffi impersonation eller rigtig browser |
| HTTP/2-fingerprinting | Tjekker HTTP/2 SETTINGS og HPACK-rækkefølge | Tavs blokering | curl_cffi taler HTTP/2 som Chrome |
| Headervalidering (UA, Sec-Fetch-*) | Browser-konsistent headersæt | 403 ved første request | Fuld Chrome-headerpakke inkl. Sec-Fetch-Site/Mode/Dest/User, realistisk Referer |
| Cookie-/sessionskontinuitet | Tracker cf_clearance, RF_BROWSER_ID | Challenges på kolde deep-link hits | Vedvarende session; varm først på forsiden |
| Rate limit i app-laget | Per-IP request-begrænsning | 429 | 2–5 sek. pause med jitter; eksponentiel backoff |
| Dårligt datacenter-IP-ry | Blokerer kendte DC ASN’er | Øjeblikkelig 1020/403 | Kun US residential- eller mobile proxies |
| Concurrency-detektion | Flere parallelle requests fra samme IP | Pludselig Turnstile-escalation | Højst 2 samtidige pr. IP |
Praktiske grænser fra community-tests:
- Sikker kadence: 1 request pr. 2–3 sekunder pr. IP
- Vedvarende >20–30 req/min fra én datacenter-IP udløser en challenge inden for få minutter
- Bløde rate limits forsvinder typisk efter 5–15 minutter, hvis trafikken stopper
- Ban mod datacenter-IP’er (AWS, GCP, Azure, OVH) kan vare fra timer til dage
Standard Python requests (urllib3 + OpenSSL) giver en — og bliver blokeret lydløst, selv med perfekte headers. Den almindelige brancheløsning er curl_cffi med impersonate="chrome120", som taler Chrome-korrekt TLS + HTTP/2.
Tre måder at scrape Redfin med Python på (og hvilken du bør vælge)
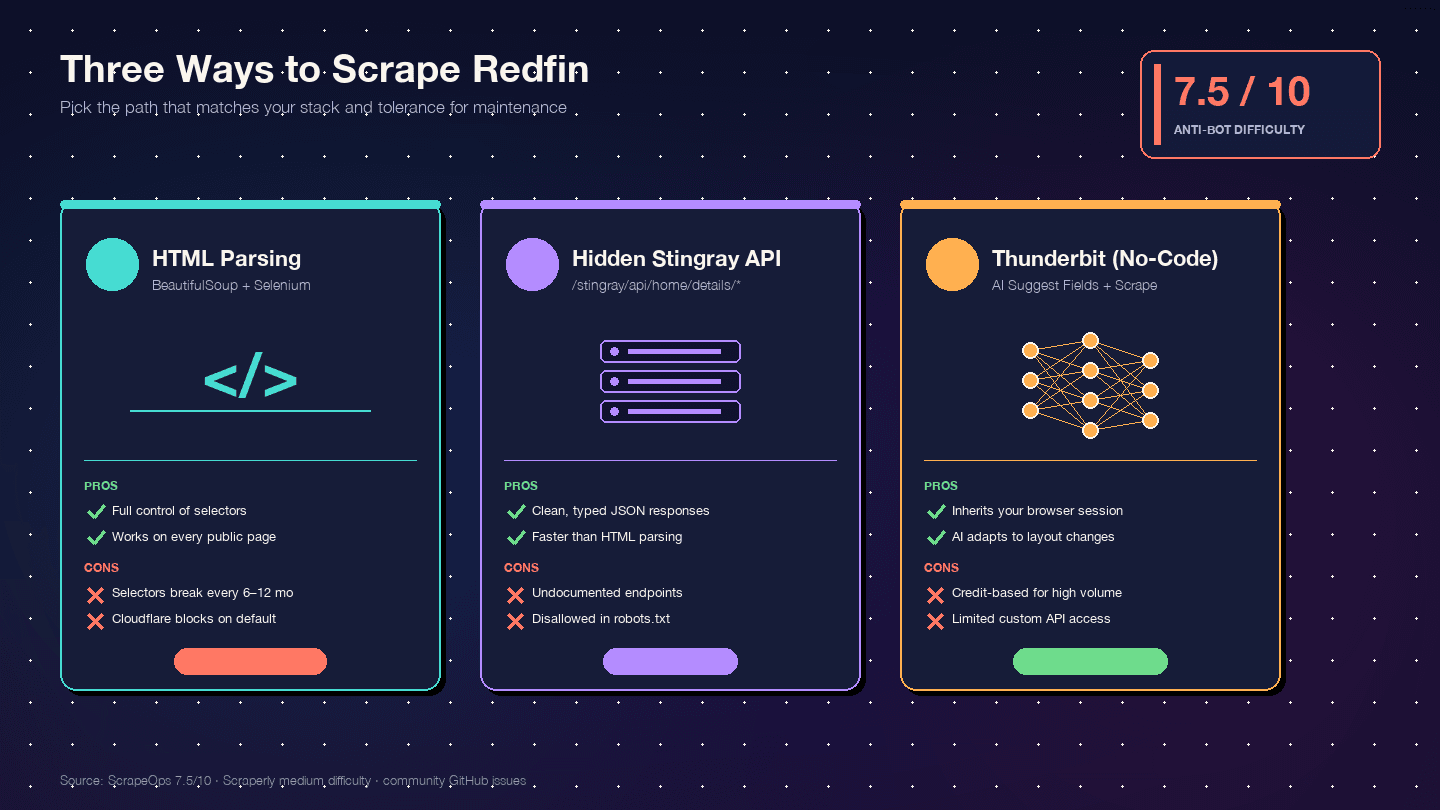
Jeg har ikke fundet en eneste konkurrerende guide, der sammenligner alle tre tilgange side om side. Her er beslutningsmatrixen:
| Kriterium | HTML-parsing (BS4 + Selenium) | Stingray skjult API | Thunderbit (No-code) |
|---|---|---|---|
| Sværhedsgrad ved opsætning | Mellem (Python-miljø + browserdriver) | Høj (reverse engineering af endpoints) | Lav (installer Chrome-udvidelse) |
| Risiko for blokering | Høj (DOM-requests er mest synlige) | Mellem (API-lignende requests ser renere ud) | Lavest (bruger din rigtige browsersession) |
| Kvalitet af datastruktur | Mellem (ustruktureret HTML → manuel parsing) | Fremragende (forstruktureret JSON) | Høj (AI registrerer felter + datatyper automatisk) |
| Vedligeholdelsesbyrde | Høj — én layoutændring kan ødelægge selectors | Mellem — endpoints kan ændre sig uden varsel | Lavest — AI tilpasser sig layoutændringer |
| Skala | Lav–mellem (hundreder med proxies) | Mellem–høj (tusinder, renere requests) | Mellem (50 sider/batch via cloud scraping) |
| Bedst til | Udviklere, der vil have fuld kontrol | Udviklere, der vil have ren JSON | Ikke-udviklere, hurtige projekter, løbende data uden udviklerressourcer |
Vedligeholdelse er værd at fremhæve. Redfin har sendt to generationer af card-DOM’er — den gamle (homecardV2Price) og den nuværende (span.bp-Homecard__Price--value). Historikken i GitHub issues viser, at CSS-selector-brud sker omtrent hver 6.–12. måned. Når det sker, går en BeautifulSoup-scraper i stykker natten over. En AI-baseret feltgenkender tilpasser sig.
Før du går i gang
- Sværhedsgrad: Mellem (tilgang 1 & 2), Begynder (tilgang 3)
- Tid: Ca. 30 minutter for tilgang 1 eller 2; ca. 5 minutter for tilgang 3
- Det skal du bruge:
- Python 3.8+ med pip (tilgang 1 & 2)
- Chrome-browser (alle tilgange)
- (tilgang 3)
- Amerikanske residential proxies til scraping i stor skala (tilgang 1 & 2)
Tilgang 1: Scrape Redfin med Python ved hjælp af HTML-parsing (BeautifulSoup + Selenium)
Det her er “fuld kontrol”-vejen. Du skriver selectors, du styrer browseren, og du håndterer fejlene.
Det er den mest lærerige tilgang. Den er også den mest skrøbelige.
Trin 1: Sæt dit Python-miljø op
Opret et virtuelt miljø og installer de nødvendige biblioteker:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # På Windows: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi er helt afgørende her — det er det, der lader dine HTTP-forespørgsler efterligne et rigtigt Chrome TLS-fingerprint i stedet for standardfingerprintet fra Python requests, som Cloudflare blokerer med det samme.
Trin 2: Konfigurer browser-headers og session
Det er her, de fleste begyndere fejler. Du skal bruge det fulde sæt Chrome-headers, inklusive de Sec-Fetch-* headers som Redfin/Cloudflare eksplicit validerer:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Varm sessionen op — indsamler cf_clearance- og RF_BROWSER_ID-cookies
17session.get("https://www.redfin.com/")At varme sessionen op er afgørende — hvis du rammer en dyb bolig-URL koldt (uden tidligere cookies og uden Referer), scorer Cloudflare dig lavere.
Start altid med forsiden.
Trin 3: Scrape Redfin-søgeresultater
Når sessionen er varm, kan du hente en byside og parse listing-kortene. Nuværende selectors (2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Sider 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Blokeret på side {page_num}: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Tilfældig pause mellem 2 og 5 sekunder
28 time.sleep(random.uniform(2, 5))
29print(f"Scraped {len(listings)} listings")Du bør se en voksende liste af dictionaries, hver med pris, adresse, sove-/badeværelser, m² og link til detaljesiden for en San Francisco-bolig. Hvis du får 0 kort, så tjek HTTP-statuskoden — en 403 betyder, at Cloudflare har fanget dig, og at du sandsynligvis har brug for residential proxies.
Trin 4: Scrape individuelle detaljesider for boliger
Søgeresultater giver det grundlæggende. Detaljesiderne giver Redfin Estimate, byggeår, HOA, salgshistorik, mæglerinfo og fotos. Disse sider kræver JavaScript-rendering, så skift til Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Berig de første 10
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Vent på JS-rendering
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Efter dette trin bør dine første 10 boliger være beriget med Redfin Estimate-værdier og data for byggeår. XPath-selectors er mere robuste end CSS til disse indlejrede amenity-felter, men de er stadig skrøbelige — enhver ændring i DOM’en kan ødelægge dem.
Trin 5: Håndter blokeringer og fejl
Implementér retry-logik med eksponentiel backoff:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Blokeret ({resp.status_code}). Prøver igen om {wait:.1f}s...")
10 time.sleep(wait)
11 else:
12 print(f"Uventet status: {resp.status_code}")
13 break
14 return NoneTegn på, at du er blevet blokeret: HTTP 403 med Cloudflare-HTML i body’en, HTTP 429 (eksplicit rate limit), tom response body eller “Error 1020 Access Denied” i sidens indhold. Hvis det sker konsekvent, er det tid til at tilføje residential proxies eller skifte til API-tilgangen.
Tilgang 2: Scrape Redfin med Python ved hjælp af det skjulte Stingray API
Det her er min favorit. Redfins frontend taler med et internt JSON API på /stingray/api/home/details/*, og svarene kommer tilbage som ren, typet JSON — ingen HTML-parsing nødvendig.
Sådan finder du Redfins skjulte API-endpoints
Åbn Chrome DevTools → Network-fanen → filtrér efter Fetch/XHR → gå til en Redfin-boligside. Du vil se requests til endpoints som:
api/home/details/initialInfo— omsætter URL → propertyId, listingIdapi/home/details/aboveTheFold— pris, soveværelser, badeværelser, m², billeder, status, mægler, MLS#api/home/details/belowTheFold— faciliteter, HOA, skatter, parkering, byggeår, grund, historikapi/home/details/avm— Redfin Estimate for boliger på markedetapi/home/details/owner-estimate— Redfin Estimate for boliger uden for markedetapi/home/details/descriptiveParagraph— markedsføringsbeskrivelse
For lejesider udtrækkes rentalId (en UUID på 36 tegn) fra URL’en i <meta property="og:image">-tagget.
Dataudtræk via Stingray API’et
Der er en vigtig detalje: Stingray JSON-svar er præfikset med den bogstavelige streng {}&& som anti-CSRF-mekanisme. Du skal fjerne den, før du parser:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Varm sessionen op
6session.get("https://www.redfin.com/")
7# Hent en boligside for at få cookies og property ID
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Ram nu Stingray API'et
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Fjern anti-CSRF-præfikset
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Udtræk strukturerede data
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))Svaret indeholder typede felter: pris som heltal, sove-/badeværelser som tal, billed-URL’er som arrays og mæglerinfo som indlejrede objekter. Ingen BeautifulSoup-parsing, ingen CSS selectors, ingen gæt.
Fordele og begrænsninger ved den skjulte API-tilgang
Fordele:
- Forstruktureret JSON — langt renere end HTML-parsing
- Hurtigere per request (mindre payload, ingen rendering)
- Lavere risiko for blokering (API-lignende requests med korrekte headers ser mere naturlige ud)
Begrænsninger:
- Endpoints kan ændre sig uden varsel — der er ingen officiel dokumentation
robots.txtforbyder eksplicit/stingray/for wildcard user-agent- Kræver reverse engineering for at opdage nye endpoints
- Kræver stadig opvarmning af session og korrekte headers for at undgå Cloudflare
No-code-alternativet: Scrape Redfin med Thunderbit
Hvis du har brug for Redfin-data og ikke ønsker at vedligeholde Python-scripts — eller du bare vil have resultater på fem minutter — så start her. Vi byggede til netop det: struktureret dataudtræk fra enhver hjemmeside, helt uden kode.
Trin 1: Installer Thunderbit og gå til Redfin
Installer fra Chrome Web Store. Åbn Redfin og gå til en søgeresultatside — for eksempel boliger til salg i San Francisco.
Trin 2: Klik på "AI Suggest Fields"
Klik på Thunderbit-ikonet i browserens værktøjslinje, og klik derefter på "AI Suggest Fields." AI’en læser Redfin-siden og foreslår automatisk kolonner som “Adresse,” “Pris,” “Soveværelser,” “Badeværelser,” “m²,” “Ejendomstype” og “Listing Photo” — med de rigtige datatyper allerede sat.
Du kan fjerne kolonner, du ikke har brug for, eller tilføje egne ved at klikke på "+ Add Column" og beskrive, hvad du vil have, i almindeligt sprog (fx “listing agent name” eller “days on market”).
Du bør nu se en tabelvisning med de valgte kolonner klar til at blive udfyldt.
Trin 3: Klik på "Scrape" og se dataene komme ind
Klik på "Scrape". Thunderbit behandler de synlige listings og udfylder din tabel. Ved paginerede resultater håndterer den pagination automatisk — ingen loop-logik nødvendig.
I min test blev en tabel med 50 rækker udfyldt på omkring 45 sekunder. Strukturerede data, klar til eksport.
Sådan håndterer Thunderbit Redfins anti-bot-beskyttelse
Fordi Thunderbit kører i din egen browser, arver den dine eksisterende Redfin-cookies, din session og dit browser-fingerprint. For Cloudflare ligner det en almindelig bruger, der browser Redfin — fordi det teknisk set er det. Ingen headless browser, ingen datacenter-IP, intet TLS-fingerprint der ikke matcher. For offentligt tilgængelige sider kan Thunderbits cloud scraping-mode behandle 50 sider ad gangen.
Det er en fundamentalt anderledes tilgang end at sende requests fra et Python-script på en server.
Din browsersession er allerede trusted.
Scrape Redfin-undersider med Thunderbit
Efter du har scraped søgeresultaterne, kan du klikke "Scrape Subpages" for at få AI’en til at besøge hver detalje-URL og berige din tabel med ekstra felter — Redfin Estimate, byggeår, HOA-bidrag, mæglerinfo, boligfotos og salgshistorik.
Det svarer til Selenium-loopet på 40 linjer fra tilgang 1 — bortset fra at det kræver ét klik og ingen vedligeholdelse.
Når Redfin ændrer sin DOM fra homecardV2Price til span.bp-Homecard__Price--value, tilpasser AI’en sig. Det gør dine Python-selectors ikke.
Mere end CSV: Eksportér Redfin-data til Google Sheets, Airtable og Notion
De fleste guides stopper ved df.to_csv(). Det er fint til en engangsanalyse. Men hvis du arbejder i et ejendomsteam, har du brug for kollaborative, levende data — ikke statiske filer, der bare samler støv på en desktop.
Eksport med Python (gspread + Airtable API)
Google Sheets via gspread:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Vis ejendomsbilleder inline via IMAGE()-formel
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Bemærk: Sheets har en hård grænse på 10 millioner celler pr. regneark, og API’et tillader . Brug ws.batch_update() i stedet for cell-for-cell loops, hvis du har mere end få dusin rækker.
Airtable via pyairtable:
Vigtig ændring i 2024: Airtable . Du skal nu bruge Personal Access Tokens (PATs) — enhver guide, der stadig viser api_key=..., er forældet.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable henter og hoster igen
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Airtables rate limit er , med 30 sekunders lockout ved overtrædelse. Attachment-feltet accepterer payloads som [{"url": ...}] — Airtables servere henter URL’en, hoster den igen på deres CDN og genererer thumbnails automatisk.
Eksport med Thunderbit (1 klik til Sheets, Airtable, Notion)
Thunderbit har indbygget 1-klik eksport til Google Sheets, Airtable og Notion — og her er den del, jeg faktisk er ret stolt af: boligfotos uploades og vises som inline-billeder i Notion og Airtable. Ingen =IMAGE()-tricks, ingen ødelagte CDN-links. Du klikker “Export to Airtable”, og dit team får en visuel ejendomsdatabase med thumbnails, de kan gennemse på telefonen.
For ejendomsteams, der arbejder visuelt med boligudvælgelse, er det forskellen mellem et brugbart værktøj og en bunke CSV-rækker.
Er det lovligt at scrape Redfin? Hvad ToS, robots.txt og retspraksis siger
Jeg er ikke advokat, og det her er ikke juridisk rådgivning. Men efter mange år i dataudtræksbranchen kan jeg sige: “er det lovligt?” er det spørgsmål, alle stiller, og som de fleste guides sniger sig udenom.
Redfins robots.txt
Redfins er detaljeret. De vigtigste punkter:
- Fuldt blokerede bots:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— Redfin nævner specifikt den populære LLM-æra scraping-tjeneste - Wildcard
User-agent: *Disallow highlights:/stingray/(hele det interne API-navnerum),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - Ingen
Crawl-delay:-direktiv for nogen user agent - 50+ sitemaps deklareret — sitemaps er den reneste og mindst WAF-tunge måde at enumerere URL’er på
Redfins brugsbetingelser
siger: "You may not automatedly crawl or query the Services for any purpose or by any means... unless you have received prior express written permission."
Det er en browsewrap-aftale — accept via fortsat brug, ikke via klik. Amerikanske domstole har historisk været skeptiske over for at håndhæve browsewrap over for brugere, som ikke havde faktisk kendskab til vilkårene (se Nguyen v. Barnes & Noble, 9th Cir. 2014).
Relevant retspraksis (kort)
- Van Buren v. United States (Højesteret, 2021): CFAA’s “exceeds authorized access”-regel bruger en “gates-up-or-down”-test. At bruge en åben dør til et uvelkomment formål er ikke føderal hacking.
- hiQ Labs v. LinkedIn (9th Cir., 2022): Scraping af offentligt tilgængelige data er ikke en CFAA-overtrædelse. Men hiQ betalte til sidst $500.000 i et forlig på kontraktbrud — fordi hiQ havde oprettet LinkedIn-konti og klikket “I agree.”
- Meta Platforms v. Bright Data (N.D. Cal., jan. 2024): Retten gav Bright Data medhold ved summary judgment — logget-ud scraping af offentlige data gjorde ikke Bright Data til en “user” bundet af Metas ToS.
- X Corp. v. Bright Data (N.D. Cal., maj 2024): Dommer Alsup afviste X’s krav og fastslog, at statslige krav, der forsøgte at kontrollere kopiering af offentligt indhold, blev fortrængt af Copyright Act.
Praktiske råd
- Scrape kun offentligt tilgængelige data — opret aldrig en konto og scrape bagefter (det skaber eksponering under klikbaserede kontraktvilkår)
- Respekter rate limits — aggressivt volumen kan understøtte krav om trespass-to-chattels
- Genudgiv ikke rå data eller fotos i stor skala — -sagen (anlagt i juli 2025, potentielle skader på over $1 mia.) er en påmindelse om, at billedophavsret er alvorligt
- Thunderbits browserbaserede tilgang — der kører i din egen autentificerede session — ligger tættere på “manuel browsing i maskinhastighed” end på en headless datacenter-bot, og det er den mest forsvarlige position, man kan have uden en licenseret API
Tips og almindelige faldgruber
Et par hårdt tjente erfaringer fra at bygge udtræksværktøjer og se tusindvis af brugere scrape ejendomssider:
- Varm altid din session op. Ram
redfin.com/før nogen deep URL. Kolde deep-link hits er den største trigger for Cloudflare-challenges. - Roter User-Agent strings realistisk. Brug ikke kun én — roter mellem 5–10 aktuelle Chrome/Firefox UAs. Men roter ikke for aggressivt (en ny UA for hver request ser mistænkeligt ud).
- Deduplicér efter ejendoms-ID. Redfins pagination overlapper nogle gange. Parse
/home/{id}fra hver listing-URL og dedupliker, før du beriger dataene. - Undgå helst at scrape i spidsbelastningstiden. Sen aften / tidlig morgen amerikansk tid giver efter min erfaring mindre WAF-kontrol.
- Hvis du får en 429, så skru ned med det samme og eksponentielt. Lad være med at prøve igen med det samme — det er sådan, du går fra en blød rate-limit til et hårdt IP-ban.
- Til store projekter (1.000+ sider), budgettér med residential proxies. Datacenter-IP’er (AWS, GCP, Azure, OVH) er sortlistet af Cloudflares ASN-ry-system. Du rammer næsten straks Error 1020.
Sådan vælger du den rigtige måde at scrape Redfin på
Så hvilken tilgang skal du vælge? Det afhænger af, hvem du er, og hvad du har brug for.
HTML-parsing (BeautifulSoup + Selenium): Bedst til udviklere, der vil have fuld kontrol, er komfortable med at vedligeholde CSS selectors og ikke har noget imod at bygge om, når Redfin ændrer DOM’en. Forvent at skulle vende tilbage til koden hver 6.–12. måned.
Skjult Stingray API: Bedst til udviklere, der har brug for ren, struktureret JSON og kan håndtere reverse engineering af udokumenterede endpoints. Mindre vedligehold end HTML-parsing, men endpoints kan ændre sig uden varsel. Husk, at /stingray/ er eksplicit forbudt i robots.txt.
Thunderbit (No-code): Bedst til ikke-udviklere, hurtige projekter og teams, der har brug for løbende Redfin-data uden udviklerressourcer. AI’en tilpasser sig layoutændringer, subpage-scraping beriger data med ét klik, og eksport til , Airtable eller Notion er indbygget. Hvis du er et ejendomsteam, der har brug for en levende ejendomsdatabase — ikke et engangs-CSV-dump — er det den letteste vej.
Uanset hvilken vej du vælger: forstå Redfins anti-bot-beskyttelse, før du går i gang, ved hvilke felter du har brug for, vælg et eksportformat der passer til teamets workflow, og hold dig på den rigtige side af .
Klar til at prøve no-code-ruten? lader dig eksperimentere med Redfin-scraping og se resultater på få minutter. Til Python-tilgangene er kodeeksemplerne ovenfor et fungerende udgangspunkt — du skal bare tilføje proxies og tålmodighed.
Ofte stillede spørgsmål
Har Redfin en offentlig API?
Nej. Redfin tilbyder ikke en officiel offentlig API. Det skjulte Stingray API (/stingray/api/home/details/*) returnerer struktureret JSON og bruges af Redfins egen frontend, men det er uofficielt, udokumenteret, kan ændre sig uden varsel og er eksplicit forbudt i Redfins robots.txt. Open-source wrappers som på PyPI giver Python-adgang, men brug dem med forståelse for risiciene.
Kan jeg scrape Redfin uden Python?
Ja. er en AI Chrome-udvidelse, som arver din browsersession for bedre modstandsdygtighed over for anti-bot-systemer — installer den, gå til Redfin, klik på "AI Suggest Fields" og eksportér til Excel, Google Sheets, Airtable eller Notion. Der findes også andre no-code scrapingværktøjer og færdige datasæt-leverandører på markedet, hvis du vil undersøge alternativer.
Hvor ofte ændrer Redfin layout på sit website?
Historikken i community GitHub issues viser, at CSS-selector-brud sker omtrent hver 6.–12. måned. Redfin har sendt to generationer af card-DOM’er — den gamle (homecardV2Price, homeAddressV2) og den nuværende (bp-Homecard__Price--value, bp-Homecard__Address). Modne scrapers prøver begge i rækkefølge.
AI-baserede værktøjer som Thunderbit , fordi de genkender felter ud fra indhold i stedet for CSS selectors.
Hvilken proxytype er bedst til at scrape Redfin?
US residential proxies til scraping i stor skala — community benchmarks placerer succesraten omkring 80%. Datacenter proxies rammer næsten med det samme Cloudflare Error 1020; AWS-, GCP-, Azure- og OVH-IP-områder er sortlistede. Mobile proxies har den højeste succesrate, men koster 5–10 gange mere.
Til mindre personlige projekter (<100 sider) kan korrekte headers + curl_cffi-impersonation + 2–5 sekunders forsinkelser måske fungere uden proxies.
Kan jeg scrape solgte eller off-market boligdata fra Redfin?
Ja. Data for solgte boliger og den off-market Redfin Estimate (medianfejl ) er tilgængelige på detaljesider ved hjælp af de samme scrapingmetoder. Felterne er dog anderledes end for aktive boliger: off-market-sider viser salgspris, salgsdato, ejendomshistorik og owner-estimate-endpointet, men mangler aktuel listepris, dage på markedet og info om åbent hus. Stingray API-endpointet for off-market estimates er api/home/details/owner-estimate i stedet for api/home/details/avm.
Læs mere