
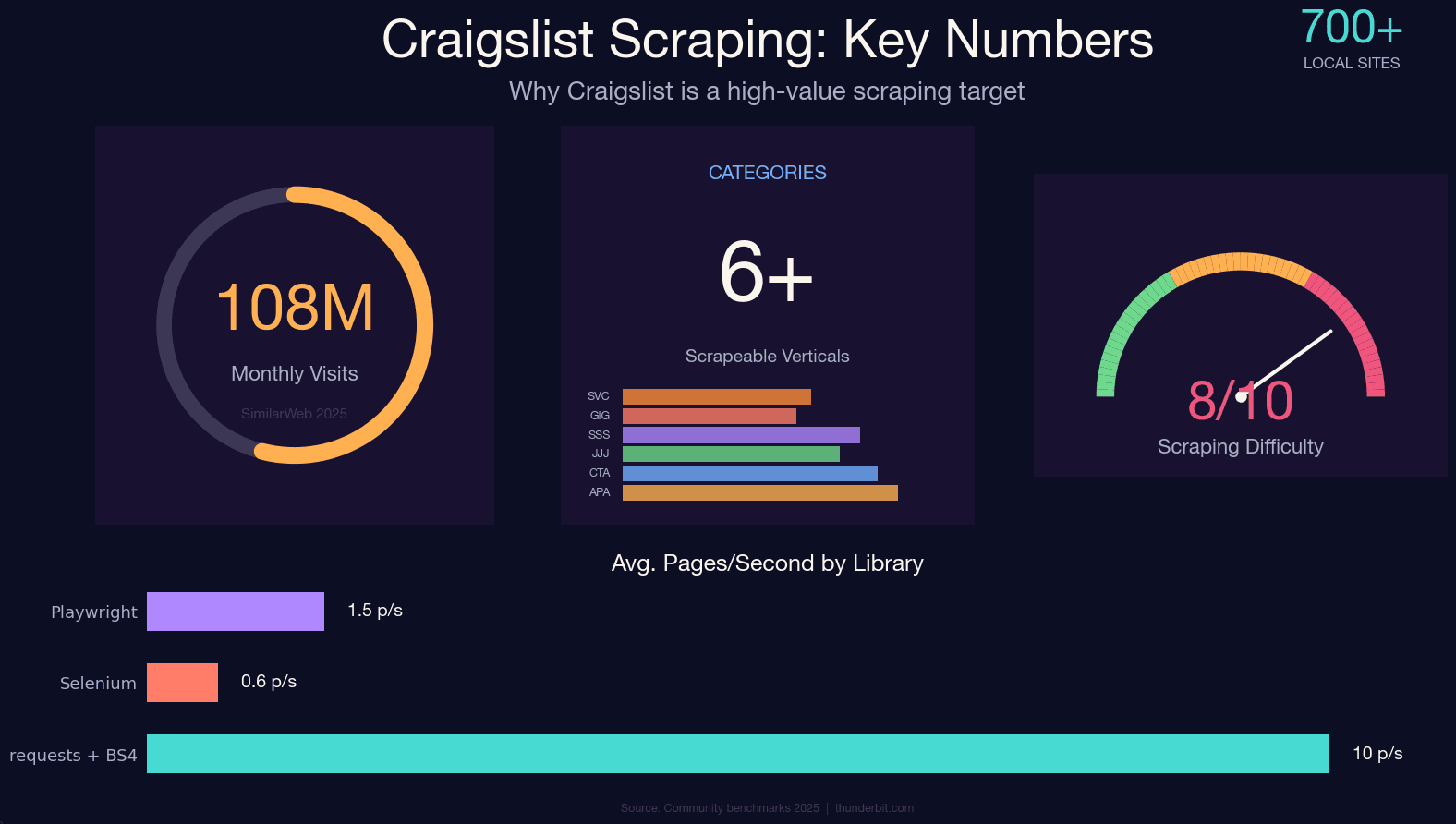
Craigslist trækker stadig omkring på tværs af cirka 700 lokale sites — og der findes stadig ingen offentlig API. Hvis du vil have strukturerede data fra boligannoncer, brugte biler, jobopslag eller gigs, er scrape craigslist med python i praksis din eneste mulighed.
Craigslist' eget anti-bot-system er dog benhårdt. Det bruger ikke Cloudflare eller DataDome — det kører på deres egen nginx-baserede rate limiter, som er blevet finpudset i over et årti. Rammer du forkert, får du en ren 403, før du har nået din anden kop kaffe. Jeg har brugt meget tid på at teste forskellige tilgange mod Craigslist' forsvar, og denne guide er resultatet: en opdateret Python-tutorial til 2025, der virker på tværs af kategorier og dækker JSON-LD-ekstraktionsmetoden (den klart største forbedring i forhold til forældede guides), ærlige anti-ban-strategier, det juridiske landskab og et no-code alternativ til alle, der bare vil have dataene uden at skrive én eneste linje kode.
Hvad betyder det at scrape Craigslist med Python?
Web scraping af Craigslist betyder, at du bruger Python-scripts til programmatisk at besøge Craigslist-sider, udtrække de strukturerede data, du har brug for — titler, priser, beskrivelser, billeder, lokationer, opslagstidspunkter — og gemme dem i et regneark, en database eller en JSON-fil.
Python er det oplagte valg her på grund af dets stærke økosystem af biblioteker. Med requests, BeautifulSoup, lxml og curl_cffi kan du bygge en fungerende Craigslist scraper på under 100 linjer. Fællesskabet er enormt, så når Craigslist ændrer noget (hvilket de gør), har nogen allerede fundet løsningen.
Det vigtigste at vide er dette: Craigslist tilbyder . Den eneste officielle programmatiske grænseflade er Bulk Posting Interface (BAPI), som kun kan skrive — den lader godkendte betalende annoncører indsende opslag, men ikke hente dem. Ethvert "Craigslist API"-produkt, du ser på tredjepartsplatforme, er en uofficiel scraper, ikke et sanktioneret endpoint. Hvis du vil have data i større mængder, scraper du.
Hvorfor scrape Craigslist? Reelle use cases
Craigslist er ikke bare et sted, hvor man finder en brugt sofa. Det er et kæmpe, løbende opdateret datasæt på tværs af mange vertikaler. Her er, hvem der faktisk får værdi ud af at scrape det:
| Use Case | Hvem får værdi | Hvad du udtrækker |
|---|---|---|
| Overvågning af bolig- og lejepriser | Ejendomsmæglere, lejere, PropTech-virksomheder | Pris, kvm, soveværelser, kvarter, bredde/længde |
| Analyse af markedet for brugte biler | Bilforhandlere, forbrugerapps, forskere | Pris, mærke, model, årgang, kilometertal, stand |
| Analyse af jobmarkedet | Recruitere, arbejdsmarkedsøkonomer, workforce-analytikere | Titel, løn, ansættelsestype, dato for opslag |
| Lead-generering | Salgsteams, servicevirksomheder | Kontaktinfo, firmanavne, serviceområde |
| Konkurrencedygtig prisovervågning | Lokale serviceudbydere, ecommerce-teams | Servicepriser, beskrivelser, dækningsområder |
Det mest citerede akademiske eksempel er — omkring 500.000 amerikanske brugtbilannoncer med 26 variabler, som har dannet grundlag for adskillige artikler, herunder et ResearchGate-studie fra 2024 om dynamikken på det amerikanske marked for brugte biler. Hedgefonde har købt aggregerede Craigslist-lejedata til forskning i lejeudvikling. Og salgsteams scraper jævnligt service- og gigs-kategorier for at finde leads.
Regnestykket er simpelt: 8 timers manuel copy-paste versus omkring 10 minutter med en velbygget scraper.
Scrape Craigslist med Python: alle kategorier, ikke kun biler
Næsten alle Craigslist-guides, jeg har fundet, dækker kun biler til salg — hvilket svarer til at skrive en Google-tutorial, der kun handler om billedsøgning. Craigslist har masser af kategorier, og URL-strukturen er forskellig for hver af dem.
Strukturen er altid: https://{city}.craigslist.org/search/{category_slug}
Skift byens subdomæne og sluggen, så scraper du en helt anden vertikal. Her er en reference-tabel over de mest populære kategorier (verificeret april 2025):
| Kategori | URL-slug | Typiske felter at udtrække |
|---|---|---|
| Lejligheder / bolig | /search/apa | Pris, kvm, soveværelser, lokation, husdyrspolitik |
| Biler & lastbiler | /search/cta | Pris, mærke, model, årgang, kilometertal |
| Jobs | /search/jjj | Titel, virksomhed, løn, ansættelsestype |
| Services | /search/bbb | Titel, beskrivelse, telefonnummer, område |
| Gigs | /search/ggg | Titel, kompensation, dato, kategori |
| Til salg (generelt) | /search/sss | Titel, pris, stand, lokation |
Du kan også kombinere query-parametre til filtrering:
| Parameter | Formål | Eksempel |
|---|---|---|
query | Søgeord i fuld tekst | ?query=studio |
min_price / max_price | Prisinterval | &min_price=1500&max_price=3000 |
hasPic | Kun opslag med billeder | &hasPic=1 |
postedToday | Seneste 24 timer | &postedToday=1 |
sort | Sortering | &sort=priceasc |
s | Paginerings-offset (120 pr. side) | ?s=120 |
Så en URL som https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 giver dig lejligheder i New York mellem 1.500 og 3.000 dollars med billeder. Hver Python-scraper i denne guide virker på tværs af alle disse kategorier — du skal bare skifte sluggen.
Craigslist HTML-selectors i 2025: gamle vs. nye (og JSON-genvejen)
Den hyppigste årsag til, at Craigslist scrapers går i stykker, er ændringer i HTML-strukturen. Hvis du følger en tutorial fra 2022, der siger, at du skal ramme .result-row eller .result-info, så er din scraper allerede død.
Craigslist omskrev markupen til søgeresultater i 2023–2024. De gamle class-navne ligger stadig inde i nye wrappers, men hvis du targeter dem øverst i DOM-træet, får du en tom liste. Her er, hvad der ændrede sig:
| Element | Gammel selector (før 2024) | Nuværende selector (2025) |
|---|---|---|
| Listing-container | .result-info | .cl-search-result |
| Titel-link | .result-title | .posting-title a |
| Pris | .result-price | .priceinfo |
| Metadata (område) | .result-hood | .meta |
Men her er den egentlige indsigt — og det, der adskiller en 2025-opdateret scraper fra alt andet: du behøver slet ikke at parse HTML for søgeresultater.
Craigslist indlejrer nu hver synlig annonce i et <script id="ld_searchpage_results">-tag som struktureret JSON-LD-data. Et enkelt requests.get()-kald returnerer hele schema.org ItemList med alle annoncer på siden — titel, pris, valuta, lokation, billed-URL og link til detaljesiden. Ingen JavaScript-rendering er nødvendig. Ingen skrøbelige CSS-selectors.
JSON-LD-tilgangen er hurtigere, mere stabil og langt mindre tilbøjelig til at gå i stykker, når Craigslist ændrer i UI’et. Det er den metode, alle aktivt vedligeholdte GitHub-repos bruger, og det er den metode, vi bruger i tutorialen nedenfor.
En vigtig undtagelse: JSON-LD-blokken er — lejligheder (apa), til salg (sss), biler (cta), bolig (hhh). Den mangler ofte eller er begrænset for jobs (jjj), gigs (ggg), community (ccc) og services (bbb), fordi de annoncer ikke har schema.org/Offer-priser. For de kategorier skal du falde tilbage til HTML-vejen med .cl-search-result.
Vælg dit Python-stack: Requests + BS4 vs. Selenium vs. Playwright
Det her er spørgsmålet, der dukker op i hvert eneste scraping-forum: “Hvilket bibliotek skal jeg bruge?” For Craigslist er svaret mere entydigt end for de fleste andre sites.
| Faktor | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Hastighed | 5–15 sider/sek. (netværksbegrænset) | 0,3–1 sider/sek. | 0,5–2 sider/sek. |
| JS-renderet indhold | Nej | Ja | Ja |
| Hukommelse | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| Opsætningskompleksitet | Lav | Mellem | Mellem |
| Anti-bot-robusthed | Lav (kræver headers/proxies) | Mellem (rigtig browser) | Mellem-høj |
| Bedste Craigslist-use case | Søgeresultater (JSON-LD) | Detaljesider med dynamisk indhold | Storskalascraping med async |
| Læringskurve | Begyndervenlig | Moderat | Moderat |
Craigslist-sider er server-renderede. JSON-LD-blokken ligger i den første HTML. Der er ingen JavaScript-challenge på læseflows. Hver aktivt vedligeholdt bruger requests + BeautifulSoup eller Scrapy. Ingen bruger Selenium eller Playwright. Det er ikke en tilfældighed — et browser-automatiseringsframework tilføjer hundredvis af MB hukommelse, en 10–100x hastighedsstraff og et mere tydeligt fingerprint uden nogen gevinst.
Min anbefaling:
- requests + BS4: Start her. Det passer perfekt til JSON-LD-ekstraktionsmetoden og dækker 95% af behovene for Craigslist scraping.
- Selenium: Kun hvis du skal interagere med dynamisk indhold på specifikke detaljesider (sjældent på Craigslist).
- Playwright: Hvis du skalerer til tusindvis af sider med async concurrency — men helt ærligt er det Craigslist’ rate limiter, ikke bibliotekets throughput, der bliver flaskehalsen.
Vi har gennemgået sammenligningen mellem og en oversigt over de i separate indlæg, hvis du vil have den fulde gennemgang.
No-code alternativet: Scrape Craigslist uden at skrive Python
Et hurtigt sidespring, før vi går til koden — denne del er til alle, der ikke er udviklere. Ejendomsmæglere, salgsteams, operations managers — hvis du bare vil have dataene og ikke gider skrive Python, findes der en hurtigere vej.
er en AI web scraper, der fungerer som en Chrome-udvidelse. Den kan scrape Craigslist på cirka 2 klik, uden kode. Sådan fungerer det:
- Gå til en hvilken som helst Craigslist-resultatside (lejligheder, biler, jobs — enhver kategori).
- Klik på "AI Suggest Fields" i Thunderbit-sidepanelet. AI’en læser siden og finder automatisk kolonner som titel, pris, lokation og link.
- Klik på "Scrape" — dataene bliver udtrukket på få sekunder.
- Brug Subpage Scraping til at besøge hver annonces detaljeside og berige dataene med fulde beskrivelser, telefonnumre, billeder og attributter.
- Eksportér direkte til Google Sheets, Excel, Airtable eller Notion — helt gratis.
Til tilbagevendende behov — fx daglig overvågning af boligpriser eller ugentlige snapshots af jobopslag — kan Thunderbits Scheduled Scraper køre automatisk ud fra en plan, du beskriver i almindeligt sprog. Ingen cron jobs, ingen serveropsætning.
Thunderbit håndterer også anti-bot-mekanismer via sin Cloud Scraping-tilstand, så du slipper for at rotere proxies eller bygge headers selv. Hvis du vil prøve det, så hent og se selv.
Hvis du vil have fuld kontrol og tilpasning, så læs videre til Python-trin-for-trin-guiden.
Trin for trin: Sådan scraper du Craigslist med Python (fuld guide)
- Sværhedsgrad: Mellem
- Tidsforbrug: ~30 minutter (opsætning + første scrape)
- Det skal du bruge: Python 3.8+, Chrome-browser (til at inspicere sider), en terminal
Trin 1: Sæt dit Python-miljø op
Installer de nødvendige biblioteker:
1pip install requests beautifulsoup4 lxmllxml er valgfrit, men gør BeautifulSoup-parsing mærkbart hurtigere. Hvis du senere støder på TLS-fingerprinting-problemer (mere om det i anti-ban-afsnittet), kan du også installere curl_cffi:
1pip install curl_cffiDine imports:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomDu har nu et rent Python-miljø med alle afhængigheder installeret.
Trin 2: Byg Craigslist-URL’en til enhver kategori
Konstruér mål-URL’en dynamisk ved hjælp af by + kategori-slug + eventuelle filtre:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Eksempel: lejligheder i New York, $1500-$3000, med billeder
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Skift "apa" ud med "cta" (biler), "jjj" (jobs), "bbb" (services) eller en hvilken som helst slug fra kategoritabellen ovenfor. Skift "newyork" ud med "sfbay", "chicago", "losangeles" osv.
Trin 3: Hent siden og udtræk indlejret JSON
Send en GET-request med de rigtige headers, og parse derefter JSON-LD-blokken:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Hvis tag er None, er JSON-LD-blokken ikke til stede for den kategori — så skal du falde tilbage til HTML-parsing (se selector-tabellen ovenfor). For lejligheder, biler og til-salg-kategorier er JSON-LD-blokken normalt til stede.
Trin 4: Parse annoncedata til strukturerede records
Iterér gennem JSON-elementerne og udtræk de felter, du skal bruge:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Fandt {len(listings)} annoncer")Du bør se noget i stil med “Fandt 120 annoncer” (Craigslist viser 120 resultater pr. side). Nogle annoncer kan have None som pris, hvis afsenderen ikke har angivet en — håndter det pænt i din videre logik.
Trin 5: Scrape detaljesider for rigere data
Søgeresultater giver kun et sammendrag. For fulde beskrivelser, attributter (soveværelser, kvm, husdyrpolitik), GPS-koordinater og billeder skal du besøge hver annonces detalje-URL.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # kritisk: anti-ban jittertime.sleep(random.uniform(3, 6)) er ikke valgfrit. Spring du det over, rammer du en 403 inden for få dusin requests. Detaljesider er server-renderede med stabile selectors (#titletextonly, #postingbody, #map), som ikke har ændret sig siden omkring 2017 — noget af det få ved Craigslist, der faktisk er stabilt.
Trin 6: Håndter paginering for at scrape alle resultater
Craigslist bruger offset-parameteren ?s=120 til paginering. Hver side viser 120 resultater, og maks-offset er typisk 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))Prøv ikke at scrape tusindvis af sider i hurtig rækkefølge. Craigslist’ rate limiter er pr. IP, og bæredygtig throughput på en enkelt IP topper omkring 0,3–0,5 requests/sek., uanset hvilket bibliotek du bruger. Den grænse er sat af Craigslist, ikke af Python.
Trin 7: Eksportér dine Craigslist-data til CSV, JSON eller Google Sheets
Gem dine resultater:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Hvis du hellere vil springe eksportkoden helt over, tilbyder Thunderbit gratis eksport direkte til Google Sheets, Excel, Airtable eller Notion fra browseren. Men i Python-pipelines er CSV og JSON standardoutput. Du kan også sende dataene direkte videre til pandas til analyse eller til en database med sqlite3.
Sådan undgår du at blive bannet, når du scraper Craigslist med Python
De fleste tutorials glider let hen over den her del. Craigslist’ anti-bot-system er specialbygget, ikke hyldevare, og det har nogle ret specifikke særheder.

Brug realistiske request-headers
Craigslist validerer både rækkefølge og fuldstændighed af headers. En request uden Sec-Fetch-Dest eller med en forældet User-Agent bliver markeret, før den overhovedet rammer indholdet. Det fulde Chrome 120+-header-sæt (vist i trin 3 ovenfor) er minimum. Rotér User-Agent pr. session blandt 5–10 nyere Chrome/Firefox desktop-strenge — men skift den ikke midt i en session, for så ser det unaturligt ud.
Manglende Sec-Fetch-*-headers er den klart mest almindelige årsag til, at førstegangs-scrapers bliver blokeret med det samme.
Tilføj tilfældige pauser mellem requests
Fælles erfaring fra (ScrapingBee, Scraperly, Oxylabs, Multilogin) peger på tilfældigt 2–5 sekunder mellem hentning af søgeresultatsider og 3–6 sekunder mellem detaljesider. Konstante intervaller ligner bot-adfærd. Brug time.sleep(random.uniform(2, 5)) — aldrig time.sleep(2).
Rotér proxies (hvis du scraper i stor skala)
Craigslist blokerer ofte hele AWS-, GCP- og Azure-IP-ranges på forhånd. Datacenter-proxies er derfor ofte døde ved første request. Hvis du skal over et par hundrede sider, har du brug for residential rotating proxies, roteret for hver 20–30 requests. Mobile proxies har den laveste risiko for detektion, men koster $8–30/GB.
| Proxytype | Detektionsrisiko på Craigslist | Pris (2025) |
|---|---|---|
| Datacenter | Meget høj — blokeres ofte ved første request | $0,50–2/GB |
| Residential rotating | Lav — anbefalet | $5–15/GB |
| Mobile | Lavest | $8–30/GB |
Thunderbits Cloud Scraping-tilstand håndterer proxy-rotation automatisk, hvis du helst vil slippe for at administrere det selv.
Håndtér CAPTCHA’er roligt
CAPTCHA’er på Craigslist er sjældne i læseflows — de dukker mest op i posting- og reply-flows. Hvis en dukker op: hold pause i mindst 60 sekunder, skift IP, ryd cookies og sæt tempoet ned. Vedvarende CAPTCHA’er betyder, at din cadence er for aggressiv, ikke at det er en gåde, du skal brute-force med en solver.
Respektér rate limits og implementér backoff
Craigslist returnerer 403 (ikke 429), når du rammer deres rate limit. En 403 betyder, at den aktuelle IP er kommet på en deny list — prøv ikke blindt igen. Skift IP, skift UA, og vent.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1,5, 3, 6, 12, 24 sek.
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Et ekstra tip: community-rapporter peger konsekvent på kl. 2–6 om natten lokal tid i målbyn som det sikreste scraping-vindue, med ca. 30–40 % lavere blokrate end i dagtimerne.
TLS-fingerprinting — den skjulte fælde
Craigslist’ bot-lag inspicerer TLS ClientHello. Python-biblioteket requests (bygget på OpenSSL) har et JA3-fingerprint, der ikke matcher nogen rigtig browser. En perfekt User-Agent-header kombineret med et ikke-browser-TLS-fingerprint er en tydelig mismatch. Løsningen er med impersonate="chrome124", som emulerer Chromes TLS-handshake:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Hvis du får uforklarlige 403’er med rene residential IP’er og korrekte headers, er TLS-fingerprinting næsten helt sikkert årsagen.
Craigslist robots.txt, Terms of Service og etisk scraping
De fleste guides springer helt over denne del eller gemmer en enkelt linje i FAQ’en. I betragtning af, at Craigslist har vundet en mod en scraper (RadPad, 2017), fortjener det mere end en fodnote.
Hvad siger Craigslist’ robots.txt egentlig?
er overraskende kort. Den har én enkelt User-agent: *-blok med kun syv forbudte paths:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafAlle syv er interaktive eller muterende endpoints: reply, flag, suggest, email-a-friend. Annonsesider (/search/..., individuelle post-URL’er) er ikke forbudt. Der er ingen Crawl-delay-direktiv, selvom Craigslist håndhæver et via IP-blokering alligevel.
By-subdomæner udgiver også sitemaps — fx https://newyork.craigslist.org/sitemap/index.xml — som er den officielt opdagelige vej til annoncer.
Juridiske præcedenser: de sager, der betyder noget
Craigslist v. 3Taps (2013, afgjort 2015): 3Taps scraper Craigslist-annoncer og solgte dem videre. Da Craigslist sendte et cease-and-desist og blokerede deres IP’er, omdirigerede 3Taps trafikken med roterende proxies. Retten fastslog, at omgåelse af IP-blokeringer efter udtrykkelig tilbagekaldelse udgjorde "without authorization" under CFAA. 3Taps .
Meta v. Bright Data (2024): En nyere afgørelse slog fast, at Metas TOS ikke kan forbyde scraping af offentligt tilgængelige data, når man er logget ud. Retten vurderede, at en logget-ud scraper var “i samme situation som en besøgende”. Det er den vigtigste afgørelse for scrapers i 2024–2025 — hvis du aldrig opretter en Craigslist-konto, aldrig logger ind og kun tilgår offentligt synlige sider, er det ikke sikkert, at TOS kan håndhæves mod dig som kontrakt.
Det praktiske takeaway: CFAA-risikoen er markant reduceret efter Van Buren (2021) og hiQ v. LinkedIn (2022) for offentligt tilgængelige sider. Men erstatningskrav efter statslovgivning (trespass-to-chattels, misappropriation) er stadig reelle — det var dem, der førte både til 3Taps-forliget og RadPad-dommen på 60,5 mio. dollars.
Dette er information, ikke juridisk rådgivning. Hvis du scraper Craigslist kommercielt, så tal med en advokat.
Praktisk tjekliste for etisk scraping
- ✅ Overhold alle
Disallowi robots.txt — især de syv action-endpoints - ✅ Hold dig klart under 1.000 sider pr. 24 timer pr. IP (Craigslist’ TOS fastsætter over denne grænse som et forud fastsat erstatningsbeløb)
- ✅ Vær logget ud — opret aldrig en Craigslist-konto til scraping
- ✅ Omgå aldrig IP-blokeringer med proxies efter en udtrykkelig blokering (det var det, der væltede 3Taps)
- ✅ Tilføj pauser mellem requests — mindst 2–5 sekunder
- ✅ Scrape ikke personlige kontaktoplysninger til spam
- ✅ Distribuér ikke rå Craigslist-data eller præsenter dem som din egen platform
- ✅ Brug dataene til legitim forskning, analyse eller privat brug
- ✅ Foretræk offentliggjorte sitemaps frem for brute-force crawling, hvor det er muligt
- ✅ Fjern PII (emails, telefonnumre) ved indlæsning, hvis du gemmer data
Vi har skrevet en mere dybdegående guide om , hvis du vil have hele billedet.
Python vs. no-code: Hvilken tilgang passer til dig?
| Faktor | Python (requests + BS4) | Thunderbit (No-Code) |
|---|---|---|
| Opsætningstid | 30–60 min. (installér, skriv kode) | 2 minutter (installér Chrome-udvidelse) |
| Tekniske færdigheder | Mellem Python | Ingen |
| Tilpasning | Fuld kontrol over logik, felter og flow | AI finder felter automatisk; brugeren kan justere |
| Skala | Ubegrænset (med proxies, scheduling) | Scheduled Scraper til tilbagevendende opgaver |
| Anti-ban-håndtering | Manuel (headers, pauser, proxies, TLS) | Indbygget (Cloud Scraping) |
| Eksportmuligheder | CSV, JSON (du koder det selv) | Google Sheets, Excel, Airtable, Notion — gratis |
| Bedst til | Udviklere, data scientists, brugerdefinerede pipelines | Salgsteams, ejendomsmæglere, operations managers |
Brug Python, hvis du har brug for fuld tilpasning, planlægger at integrere dataene i en større pipeline eller vil forstå præcis, hvad der sker under motorhjelmen. Brug , hvis du vil have resultater hurtigt uden at skrive eller vedligeholde kode. Begge dele er valide. Det handler om dit use case, og om du helst vil bruge tiden i en terminal eller i en browser.
Afslutning
Craigslist er en rig, løbende opdateret datakilde på tværs af bolig, biler, jobs, services, gigs og meget mere — og uden en offentlig API er scraping den eneste måde at få strukturerede data i skala. Den metode, der faktisk virker i 2025, er at udtrække den indlejrede JSON-LD fra søgeresultaterne (ikke skrøbelige CSS-selectors), bruge requests + BeautifulSoup (ikke Selenium), tilføje realistiske headers med Sec-Fetch-*-felter, tilfældiggøre pauser og bruge residential proxies, hvis du går ud over et par hundrede sider.
JSON-LD-metoden er den største forbedring i forhold til forældede guides. Den er hurtigere, mere robust over for layoutændringer og kræver ingen JavaScript-rendering. Kombinér den med anti-ban-strategierne ovenfor, så undgår du de 403’er, der typisk fælder de fleste scrapers.
Hvis du hellere vil springe koden helt over, kan scrape enhver Craigslist-kategori med få klik og eksportere direkte til dit foretrukne regneark eller din database. Hvis du vil dykke dybere, dækker vores guides om og fundamentet mere detaljeret.
Ofte stillede spørgsmål
Er det lovligt at scrape Craigslist?
Craigslist’ Terms of Use forbyder automatiseret scraping og indeholder en liquidated-damages-klausul ($0,25 pr. side over 1.000/dag). Men nyere retsafgørelser — især Meta v. Bright Data (2024) og hiQ v. LinkedIn (2022) — har indsnævret CFAA-ansvaret for scraping af offentligt tilgængelige data, når man er logget ud. Erstatningskrav efter statslovgivning (trespass-to-chattels) er stadig en risiko, især ved kommerciel videredistribution. Respektér robots.txt, vær logget ud, tilføj pauser og videregiv ikke rå data. Dette er generel information, ikke juridisk rådgivning.
Har Craigslist en offentlig API?
Nej. Craigslist tilbyder kun en skrive-only Bulk Posting Interface (BAPI) til godkendte betalende annoncører. Der er ingen offentlig læse-API, intet developer portal og intet rate-limited lag til dataudtræk. Ethvert "Craigslist API"-produkt, du ser på tredjepartsplatforme, er en uofficiel scraper.
Hvorfor går min Craigslist scraper hele tiden i stykker?
Næsten altid på grund af ændringer i HTML-strukturen. Craigslist omskrev markupen til søgeresultater i 2023–2024, og guides, der bruger gamle selectors som .result-row eller .result-info, virker ikke længere. Skift til den indlejrede JSON-LD-metode (ved at parse script#ld_searchpage_results) for en langt mere robust løsning. Tjek også, at dine headers indeholder Sec-Fetch-*-felter — mangler de, bliver du blokeret med det samme.
Kan jeg scrape Craigslist uden Python?
Ja. Thunderbits AI web scraper Chrome-udvidelse virker på enhver Craigslist-side — lejligheder, biler, jobs, services. Klik på "AI Suggest Fields" for automatisk at finde kolonner, klik på "Scrape" for at udtrække dataene, og eksportér gratis til Google Sheets, Excel, Airtable eller Notion. Ingen kodning, ingen opsætning, ingen proxy-håndtering.
Hvor ofte kan jeg scrape Craigslist uden at blive bannet?
Med en enkelt residential IP ligger bæredygtig throughput på cirka 0,3–0,5 requests i sekundet med tilfældige 2–5 sekunders pauser mellem sider. Hold dig under 1.000 sider pr. 24 timer pr. IP for at undgå både bans og grænsen for liquidated damages i Craigslist’ TOS. Scraping i lavtrafik-timer (kl. 2–6 om natten lokal tid i målbyn) reducerer blokraten med omkring 30–40 %. Ved større volumener bør du rotere residential proxies hver 20–30 requests.
Læs mere