

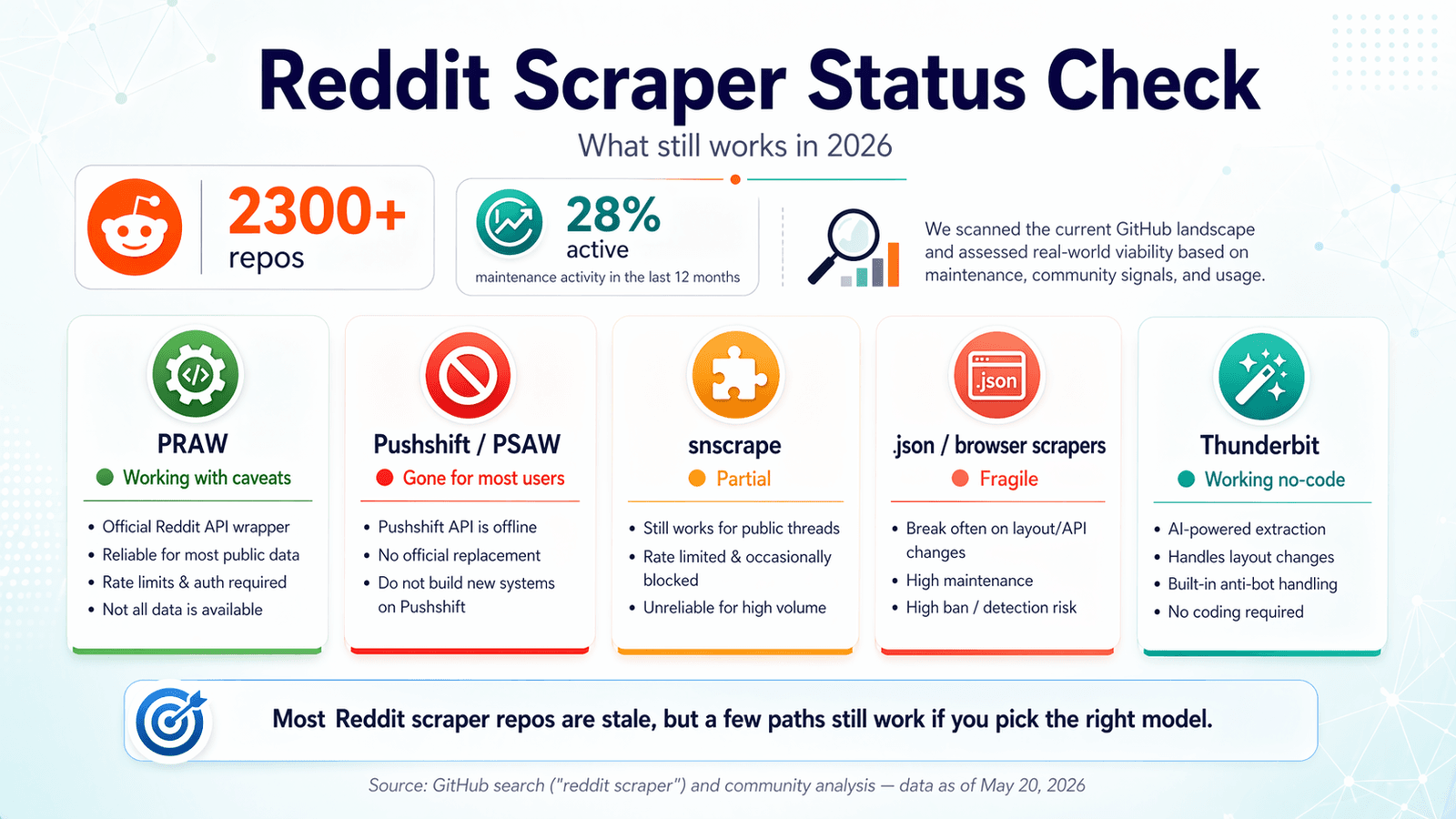
GitHub viser lige nu mere end 2.300 Reddit-scraper-repos. Det lyder som et tag-selv-bord. Men der er en hage: kun omkring 28 % viser nogen form for vedligeholdelsesaktivitet de seneste tolv måneder. Jeg har brugt de sidste par uger på at gennemgå disse repos, teste endpoints, læse issue-køer og krydstjekke Reddit’s egne politikopdateringer. Målet var at spare dig for at klone et repo, kæmpe med OAuth og opdage ved midnat, at det hele stille og roligt brød sammen i 2024. Reddit scraper GitHub-landskabet i 2026 er en kirkegård af gode intentioner blandet med en håndfuld reelt brugbare værktøjer. Denne guide dækker, hvad der stadig virker, hvad der gik i stykker, hvornår du bør droppe kode helt, og hvordan du holder dig på den rigtige side af Reddit’s stadig skrappere håndhævelse. Hvis du leder efter en genvej, er Thunderbit den no-code-løsning, vi byggede til netop den slags problem — men jeg er også ærlig omkring, hvor kodebaserede løsninger stadig giver bedst mening.
Hvad er et Reddit Scraper GitHub-repo (og hvorfor er så mange ødelagte)
Et "reddit scraper github"-repo er typisk et open source Python-projekt (eller nogle gange JavaScript), der automatiserer hentning af opslag, kommentarer, brugerdata eller medier fra Reddit. De falder generelt i fire lejre:
- API-wrappere (som PRAW): bruger Reddit’s officielle API, kræver OAuth og følger Reddit’s regler.
- Pushshift/PSAW-baserede værktøjer: blev brugt til at få adgang til Pushshift’s enorme Reddit-arkiv for historiske data.
- Scrapere til offentlige
.json-endpoints: tilføjer.jsontil Reddit-URL’er eller rammer offentligt tilgængelige endpoints uden autentificering. - Browserbaserede scrapere: bruger Playwright, Selenium eller browser-udvidelser til at indlæse Reddit-sider og trække det renderede indhold ud.
Hvorfor brød så mange sammen? Tre grunde.
- Reddit’s API-prisændring i midten af 2023. De gratis API-grænser faldt til 100 forespørgsler i minuttet med OAuth og kun 10 uden. Højere kommercielt forbrug koster nu $0,24 pr. 1.000 API-kald. Mange repos blev bygget til en verden, hvor API-adgang i praksis var ubegrænset — og den verden er væk.
- Pushshift’s offentlige adgang blev fjernet. Pushshift var rygraden i historisk Reddit-forskning. Da Reddit begrænsede adgangen, mistede en stor del af de "historiske scraper"-repos deres primære datakilde. Nogle README-filer får stadig disse værktøjer til at se levende ud, men afhængigheden underneden er væk for almindelige brugere.
- Reddit strammede både politik og håndhævelse. Robots.txt-opdateringen i 2024, Public Content Policy i 2025 og Responsible Builder Policy fra marts 2026 signalerer alle, at Reddit ikke længere behandler massiv scraping som uskyldig baggrundsstøj. De har endda indgivet klager mod Anthropic og SerpApi over uautoriseret dataadgang.
Kort sagt: Søg på "reddit scraper github", og du får hundredvis af resultater. Datoerne for sidste commit og antallet af åbne issues fortæller en helt anden historie.
Reddit Scraper GitHub-statuschecket i 2026: Hvad virker stadig
De fleste konkurrerende artikler blev skrevet i 2023 eller 2024 og er aldrig blevet opdateret. Forumbrugere bliver ved med at støde ind i fejl i repos, der virkede for et år siden — en brugers bøn, "Keep running into Reddit API limitation error :\ Any ideas how I can get past this?" er i bund og grund 2026-oplevelsen med Reddit-scraping i en nøddeskal.
Jeg lavede et friskhedstjek, verificeret pr. april 2026. Her er, hvad jeg fandt.
PRAW: Den officielle Python-wrapper
Status: ✅ Virker stadig, med forbehold.
PRAW (Python Reddit API Wrapper) er stadig det mest pålidelige open source-fundament til Reddit-scraping. Det vedligeholdes aktivt — 4.099 stjerner, sidste push 20. april 2026, kun 6 åbne issues, og PyPI angiver praw 7.8.1 (udgivet oktober 2024).
Styrker: Officiel, veldokumenteret, abstraherer det meste af Reddit’s API-kompleksitet.
Begrænsninger i 2026:
- Strammere OAuth-krav. Du skal have en registreret Reddit-app med en godkendt beskrivelse af anvendelsen.
- Lavere rate limits siden 2024 (100 forespørgsler/min med OAuth, 10 uden).
- Den hårde grænse på omkring 1.000 opslag pr. listing består. Fællesskabstråde på r/redditdev og Stack Overflow bekræfter: der er ingen måde at hente mere end 1.000 opslag pr. listing-endpoint.
PRAW er det sikreste valg, hvis du kan leve inden for API’ens rammer.
Det er bare ikke længere en fri massescraper.
Hvis du vil have en praktisk gennemgang af den officielle API-vej, passer denne tutorial godt til dette afsnit:
Pushshift / PSAW: Arkivet, der gik mørkt
Status: ❌ Offentlig adgang er væk.
PSAW var den foretrukne Python-wrapper til Pushshift, som tidligere var den letteste vej til historiske Reddit-data. I 2026 er repoet arkiveret, README’en siger bogstaveligt talt "THIS REPOSITORY IS STALE," og nyere åbne issues inkluderer perler som "Pushshift.io UNABLE to connect" og "The code not working. Possibly due to pushshift api."
Akademisk adgang kan stadig findes gennem bestemte kanaler, men for alle, der søger "reddit scraper github" i dag, er Pushshift/PSAW ikke en brugbar løsning. Hvis du har brug for dybe historiske Reddit-data, skal du undersøge godkendt akademisk dataadgang eller licenserede veje.
snscrape (Reddit-modul): Delvist og upålideligt
Status: ⚠️ Delvist — periodiske nedbrud, stort set ikke vedligeholdt.
snscrape har 5.337 stjerner, men sidste push var 15. november 2023. README’en siger stadig, at Reddit-scraping understøttes "via Pushshift." Åbne Reddit-relaterede issues inkluderer "Error reddit scraping" og "Reddit scraper returns no submissions before 2022-11-03," uden nogen nyere meningsfuld reparationsaktivitet.
Det kan fungere til små, engangshentninger i nogle miljøer, men det er ikke pålideligt til produktion eller tilbagevendende scraping. Betragt det som legacy.
Playwright og .json-endpoint scrapere: Workarounden, der virker (nogle gange)
Status: ✅ Virker, men er skrøbelig.
Idéen er enkel: brug en headless browser (Playwright, Puppeteer) til at indlæse Reddit-sider og scrape det renderede indhold, eller tilføj .json til Reddit-URL’er for at få strukturerede data uden den officielle API.
Styrker: Ingen API-nøgle nødvendig, kan omgå 1k-opslagsgrænsen, adgang til renderet indhold.
Svagheder: Bryder, når Reddit ændrer sit frontend-layout eller sin JSON-struktur, kan udløse anti-bot-foranstaltninger og kræver mere teknisk opsætning. I min egen test denne måned gav direkte forespørgsler til offentlige Reddit .json-endpoints 403-svar. Det betyder ikke, at alle miljøer bliver blokeret, men det betyder, at .json-genvejen ikke længere er noget, du bør gå ud fra bare "virker af sig selv."
Repos som yars er forfriskende ærlige omkring det: README’en advarer brugere om at "Use with rotating proxies, or Reddit might gift you with an IP ban." Det er dybest set fortællingen fra april 2026 i én sætning.
Hvis du evaluerer browser-automation-workarounden, er denne Playwright-tutorial et stærkt supplement til afsnittet nedenfor:
Thunderbit: AI-drevet browserscraping (ingen kode, ingen API-nøgle)
Status: ✅ Virker — tilpasser sig automatisk til sideændringer.
Thunderbit har en fundamentalt anderledes tilgang. Det er en Chrome-udvidelse, som bruger AI til at læse Reddit-sider, foreslå datafelter (opslagstitel, forfatter, upvotes, tidsstempel, URL osv.) og udtrække strukturerede data med to klik. Ingen OAuth-opsætning, ingen API-nøgler, intet Python-miljø, ingen afhængighedshåndtering. AI’en læser siden på ny hver gang, så når Reddit ændrer layout, tilpasser Thunderbit sig automatisk i stedet for at gå i stykker uden varsel.
Gratis eksport til CSV, Google Sheets, Airtable eller Notion. Håndterer paginering og scraping af undersider (f.eks. scraping af en subreddit-liste og derefter besøg af hvert opslag for at hente kommentarer). For dem, der vil have Reddit-data uden at vedligeholde et GitHub-repo, er dette den mindste modstands vej.
(Full disclosure: Vi byggede Thunderbit, så jeg er ikke helt neutral — men jeg er tydelig omkring, hvor kodebaserede løsninger stadig giver mere mening senere i artiklen.)
Sammenlignende statusoversigtstabel
| Værktøj / kategori | Virker stadig (april 2026)? | Kræver API-nøgle? | Bemærkninger |
|---|---|---|---|
| PRAW | ✅ Ja, med forbehold | Ja (OAuth) | Mest vedligeholdte open source-fundament. Begrænset af rate limits og 1k-opslagsgrænse. |
| Pushshift / PSAW | ❌ Nej (for de fleste brugere) | N/A | Offentlig adgang er væk. Repo arkiveret. |
| snscrape (Reddit-modul) | ⚠️ Delvist / upålideligt | Nej | Dokumenterer stadig Reddit "via Pushshift." Vedligeholdelsen gik i stå i 2023. |
| .json / offentlige endpoint-scrapere | ⚠️ Delvist | Nej | Kan virke, men direkte forespørgsler bliver i stigende grad blokeret. Afhænger af proxies. |
| Playwright / browser-scrapere | ✅ Ja, men skrøbeligt | Normalt nej | Mest brugbare DIY-løsning uden API. Sideændringer og anti-bot-tjek betyder stadig noget. |
| Thunderbit | ✅ Ja | Nej | AI/browser-workflow. Ingen OAuth, ingen selektorer. Bedst til ikke-udviklere. |
Rate limits, 1k-opslagsgrænsen og hvad der faktisk hjælper
Det her er det største smertepunkt for alle, der bruger et reddit scraper github-projekt. Forumtråde er fulde af frustration: "tired of runs dying halfway through because of rate limits," "Why am I only getting around 1,000 items?" De to centrale begrænsninger er Reddit’s API-rate limits (forespørgsler pr. minut) og grænsen på omkring 1.000 opslag pr. listing (API’en returnerer kun de seneste omkring 1.000 opslag pr. listing-endpoint).
Bedste praksis til håndtering af rate limits
Reddit’s nuværende offentlige baseline: 100 forespørgsler i minuttet med OAuth, 10 uden. Sådan håndterer du det i praksis:
- Eksponentiel backoff. Hvis du får et rate-limit-svar, så vent og prøv igen med en længere forsinkelse hver gang (1s, 2s, 4s, 8s…). Lad være med bare at hamre endpointet.
- Læs
X-Ratelimit-Remaining-headers. Reddit’s API-svar inkluderer headers, der fortæller, hvor mange forespørgsler du har tilbage, og hvornår vinduet nulstilles. Styr tempoet efter disse værdier, ikke efter gæt. - Roterende user-agents. Nogle repos foreslår dette for at undgå detektion. Det kan hjælpe, men brug det etisk — brug det ikke til at omgå ban, du selv har fortjent.
- Log alt. Tilføj logging for API-svar, rate-limit-headers og fejl. Når din scraper dør kl. 2 om natten, er logs din bedste ven.
Sådan bryder du 1.000-opslagsloftet
Den mest troværdige workaround til API’ens grænse på omkring 1.000 elementer i en listing er opdeling i tidsvinduer:
- Forespørg en tidsblok ved hjælp af
before- ogafter-timestamp-parametre. - Flyt vinduet fremad (eller bagud).
- Gentag.
- Deduplicér på post-ID.
Det er ikke elegant, men det er mere ærligt end at lade som om, at én request-loop kan hente vilkårlig historik fra et listing-endpoint. Til virkelig historiske data har du brug for godkendt akademisk adgang eller en licenseret vej — Pushshift er ikke længere standardsvaret.
Browserbaseret scraping (Playwright eller Thunderbit) omgår denne grænse helt, fordi det scraper det, der er renderet på siden, ikke det, API’en returnerer. Thunderbit’s pagineringsfunktion lader dig klikke dig gennem sider og indsamle data på så mange sider, du har brug for.
Deduplicering og fejlgendannelse
De fleste reddit scraper github-repos håndterer ikke deduplisering eller fejlgendannelse som standard. Brugere klager eksplicit over, at "none had deduping, rate limit avoidance after errors, checking if files are already downloaded." Her er, hvad du bør gøre:
- Deduplicering: Hash hvert posts ID (eller ID + indhold). Gem allerede sete hashes i en simpel SQLite-database eller endda en flad fil. Før indsættelse skal du tjekke, om hashen allerede findes. Det er især vigtigt, når du opdeler tidsvinduer eller genkører mislykkede jobs.
- Fejlgendannelse: Gem fremskridt i en checkpoint-fil efter hvert N. record. Hvis kørslen fejler, genstart fra det sidste checkpoint i stedet for fra nul. Det gør et 3-timers job, der dør i time 2, til en 1-times genoptagelse.
Hvordan forskellige tilgange håndterer disse begrænsninger

| Tilgang | Håndtering af rate limits | >1k opslag? | Auto-dedup? | Fejlgendannelse? |
|---|---|---|---|---|
| PRAW (rå) | Manuel (sleep/retry) | ❌ (API-grænse) | ❌ | ❌ |
| PRAW + opdeling i tidsvinduer | Manuel | ✅ (workaround) | ❌ | ❌ (medmindre du tilføjer det) |
| Playwright .json-scraping | N/A (ingen API) | ✅ | ❌ | ❌ |
| Thunderbit (browser-scraping) | Indbygget (AI-tempo) | ✅ (paginering) | N/A (visuel gennemgang) | Indbygget |
Når et Reddit Scraper GitHub-repo ikke er svaret: No-code-vejen
De fleste reddit scraper github-artikler antager, at man kan Python. Men mange af dem, der søger efter Reddit-scrapingløsninger, er marketingfolk, sælgere, forskere eller indie-founders, som ikke skriver Python til daglig. For dem giver et GitHub-repo skjulte omkostninger:
- Opsætning af OAuth-legitimationsoplysninger og en Reddit developer-app
- Håndtering af Python virtual environments og konfliktende afhængigheder
- Fejlfinding af kryptiske fejlmeddelelser, når PRAW’s internals ændrer sig
- Håndtering af tilbagekaldelse af API-nøgler, hvis Reddit beslutter, at din use case ikke er godkendt
- Vedligeholdelse af scriptet hver gang Reddit ændrer noget
Det her er ikke hypotetisk. bulk-downloader-for-reddit har 2.563 stjerner og 107 åbne issues. Nyere rapporter inkluderer "Struggling to install," "PRAW module error," og "Exception not allowing to even authenticate."
Brug et GitHub-repo hvis...
- Du har brug for specialbygget scrapinglogik (f.eks. specifik traversal af comment trees eller integration med en skræddersyet NLP-pipeline).
- Du vil integrere det i en eksisterende Python-datapipeline.
- Du har brug for at scrape i meget stor skala med specialiseret lagring (database, data warehouse).
- Du er tryg ved at vedligeholde kode og håndtere breaking changes.
Brug et no-code-værktøj hvis...
- Du har brug for Reddit-data hurtigt — inden for minutter, ikke timers opsætning.
- Du ikke vil administrere API-nøgler, OAuth-apps eller Python-miljøer.
- Du vil eksportere direkte til regneark, Notion eller Airtable til øjeblikkelig brug.
- Du vil have værktøjet til automatisk at tilpasse sig, når Reddit’s layout ændrer sig.
Thunderbit passer lige ned i no-code-sporet. Brugere kan scrape Reddit-opslag, kommentarer og brugerdata med AI-forslåede felter på 2 klik, eksportere gratis til CSV/Google Sheets/Airtable/Notion og håndtere paginering uden at skrive kode. Browserbaseret scraping betyder ingen OAuth-opsætning og ingen registrering af API-nøgler.
Hurtig gennemgang: Scraping af Reddit med Thunderbit (trin for trin)
- Installer Thunderbit Chrome-udvidelsen.
- Gå til den Reddit-side, du vil scrape (subreddit, søgeresultater, brugerprofil).
- Klik på "AI Suggest Fields." Thunderbit læser siden og foreslår kolonner — opslagstitel, forfatter, upvotes, tidsstempel, URL osv.
- Juster felterne, hvis det er nødvendigt, og klik derefter på "Scrape."
- Gennemgå datatabellen. Klik eventuelt på "Scrape Subpages" for at besøge hvert opslag og hente kommentarer eller ekstra detaljer.
- Eksportér til din foretrukne destination: Google Sheets, Excel, Airtable, Notion, CSV eller JSON.
To minutter. Nul linjer kode. Hvis du vil se det i praksis, så tjek Thunderbit YouTube-kanalen.
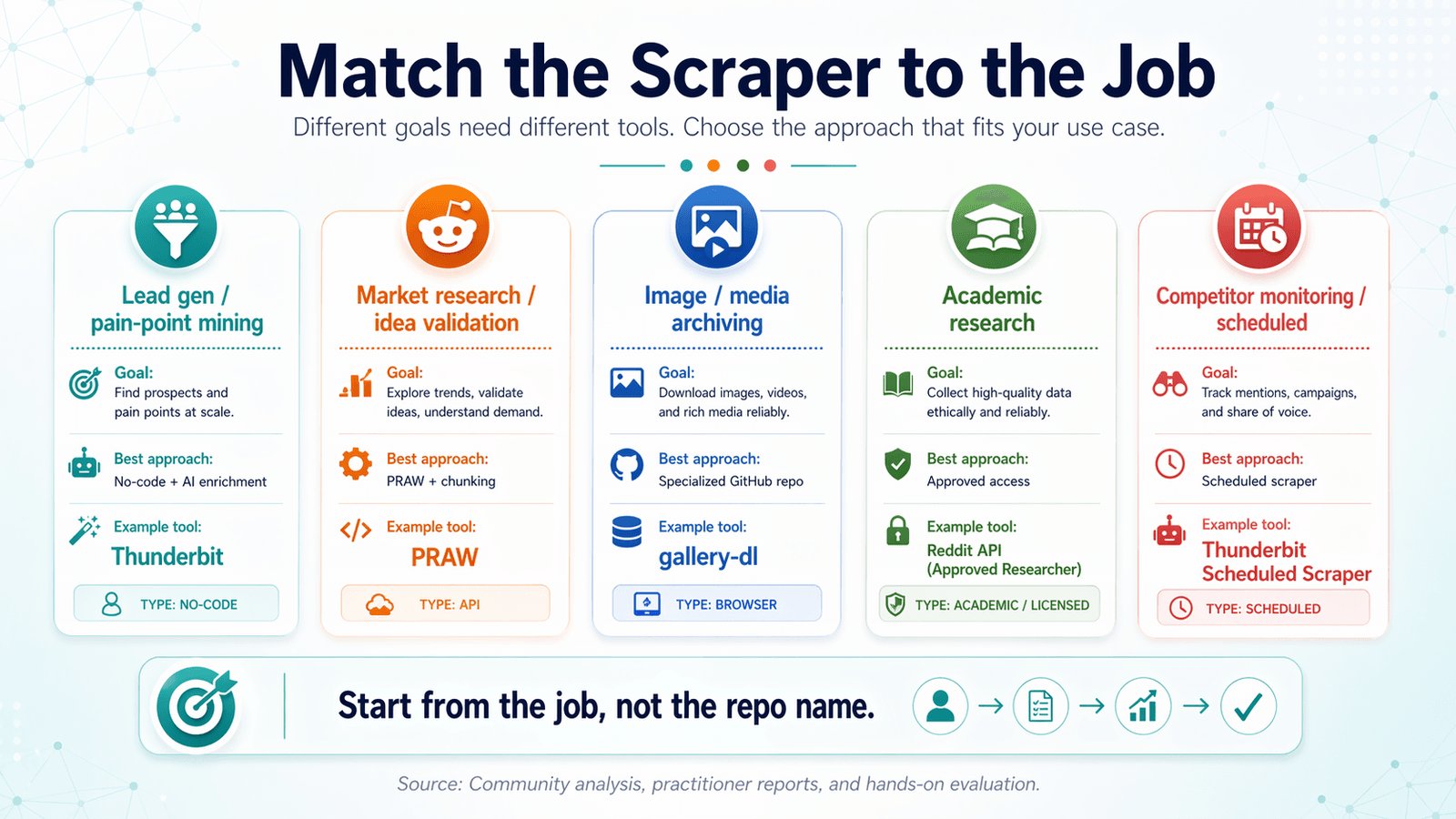
Match Reddit-scraperen med opgaven: En beslutningsmatrix for brugsscenarier
De fleste reddit scraper github-artikler organiserer efter værktøj. Det er bagvendt.
Start med dit mål, og arbejd dig baglæns til det rigtige værktøj.
Leadgenerering og identifikation af smertepunkter
Hvad du har brug for: Opslag + kommentarer med keyword-filtrering, AI-tagging/labeling, eksport til CRM-klare formater.
Bedste tilgang: No-code scraper med AI-anrikning.
Anbefalet værktøj: Thunderbit (AI-labeling + eksport til Google Sheets/Airtable til CRM-import).
Eksempel-workflow: Scrape en subreddit for opslag, der nævner et bestemt smertepunkt. Brug Thunderbit’s Field AI Prompt til at kategorisere sentiment eller tagge emner. Eksportér til dit salgsteams Airtable eller Google Sheet.
Markedsundersøgelse og idévalidering
Hvad du har brug for: Mange opslagstitler + scores, trenddata på subreddit-niveau.
Bedste tilgang: PRAW med tidsvindue-opdeling for volumen, eller Thunderbit til hurtige hentninger.
Eksempel: Scraping af r/SaaS eller r/startups for trending emner og upvote-mønstre over de seneste 90 dage.
Arkivering af billeder og medier
Hvad du har brug for: Media-URL’er, deduplicering, planlagte kørsler.
Bedste tilgang: Specialiseret GitHub-repo (f.eks. bulk-downloader-for-reddit) + cron-job.
Bemærk: Dedup betyder meget her — det er normalt, at det samme billede postes på tværs af subreddits.
Akademisk forskning og historiske data
Hvad du har brug for: Historiske data, komplette comment trees, store datasæt.
Bedste tilgang: Godkendt akademisk adgang eller en licenseret dataadgang. Pushshift er ikke længere standardsvaret.
Realitetstjek: Dette er den sværeste use case i 2026 på grund af Pushshift-begrænsninger og Reddit’s strammere datapolitikker.
Overvågning af konkurrenter og planlagt scraping
Hvad du har brug for: Gentagne scraping-kørsler med faste intervaller, ændringsdetektion.
Bedste tilgang: Thunderbit’s Scheduled Scraper (beskriv tidsintervallet i almindeligt engelsk, indsæt URL’er, klik Schedule) eller cron + script for kodebrugere.
Beslutningsmatrix for brugsscenarier
| Brugsscenarie | Hvad du har brug for | Bedste tilgang | Eksempelværktøj |
|---|---|---|---|
| Leadgen / smertepunktsanalyse | Opslag + kommentarer, keyword-filtrering, AI-tagging | No-code scraper + AI-anrikning | Thunderbit |
| Markedsundersøgelse / idévalidering | Mange opslagstitler + scores, data på subreddit-niveau | PRAW + tidsvindue-opdeling eller Thunderbit | PRAW eller Thunderbit |
| Arkivering af billeder/medier | Media-URL’er, dedup, planlagte kørsler | Specialiseret GitHub-repo + cron | bulk-downloader-for-reddit |
| Akademisk forskning | Historiske data, komplette comment trees | Godkendt akademisk adgang eller Playwright | Pushshift akademisk API (hvis tilgængelig) |
| Konkurrentovervågning / planlagt | Gentagne scraping-kørsler, ændringsdetektion | Scheduled scraper | Thunderbit Scheduled Scraper eller cron + script |
Sådan vurderer du ethvert Reddit Scraper GitHub-repo, før du går i gang
Før du kloner et repo og begynder at fejlsøge, så kør dette 5-minutters sundhedstjek. Det sparer dig for timer.
Repo-sundhedstjek på 5 minutter
- Dato for sidste commit. Hvis det er mere end 6 måneder siden, så gå forsigtigt frem. Reddit’s API ændrer sig ofte.
- Forholdet mellem åbne og lukkede issues. Mange ubesvarede issues er et rødt flag. Tjek om nyere issues nævner auth-fejl, 403’er eller Pushshift-nedbrud.
- LICENSE-fil. Tjek, om der findes en. Ingen licens = juridisk uklarhed (mere om det nedenfor).
- Afhængigheder. Er de nødvendige biblioteker opdaterede? Bruger det forældede pakker? En
requirements.txtfuld af fastlåste 2022-versioner er et advarselstegn. - README-kvalitet. Forklarer den opsætningen tydeligt? Er der brugseksempler? Dårlig dokumentation = mere fejlsøgning for dig.
- Stjerner vs. forks vs. nyere aktivitet. Mange stjerner men lav nyere aktivitet kan betyde, at projektet var populært, men nu er opgivet. Sammenlign stjerner med
pushed_at-datoen.
Et hurtigt eksempel: PSAW har 364 stjerner — ser troværdigt ud ved første blik. Men repoet er arkiveret, og README’en siger "THIS REPOSITORY IS STALE."
Stjerner alene fortæller ikke hele historien.
Tips til at få mest muligt ud af dit Reddit Scraper GitHub-setup
Hvis du alligevel vælger kodevejen, er her, hvordan du sparer dig selv for hovedpine.
Brug altid et virtuelt miljø
Et virtuelt miljø holder din scrapers afhængigheder isolerede, så de ikke konflikter med andre Python-projekter. Én kommando: python -m venv venv, og aktivér det derefter, før du installerer noget. Det er basal hygiejne, men jeg har set nok GitHub-issues med titlen "module not found" til at vide, at det er værd at gentage.
Opbevar legitimationsoplysninger sikkert
Hardcod aldrig dit Reddit API client ID eller secret i scriptet. Brug miljøvariabler eller en .env-fil, og tilføj .env til din .gitignore. Hvis du ved en fejl skubber credentials til GitHub, så roter dem med det samme — bots scanner efter eksponerede API-nøgler.
Log alt
Tilføj logging for API-svar, rate-limit-headers og fejl. Når noget går i stykker, er logs forskellen mellem "jeg ved præcis, hvad der skete" og "jeg aner ikke, hvorfor det stoppede."
Planlæg og automatisér gennemtænkt
Hvis du kører tilbagevendende scraping, så brug cron (Linux/Mac) eller Task Scheduler (Windows) — men overvåg fejl. Et cron-job, der stille fejler i to uger, er værre end ingen automatisering overhovedet.
Alternativt: Thunderbit’s Scheduled Scraper lader dig beskrive intervallet i almindeligt engelsk, uden at du skal bruge cron-syntaks.
Juridiske og etiske bedste praksisser for Reddit-scraping
Det her er ikke bare en standard ansvarsfraskrivelse. Reddit har håndhævet sine vilkår aggressivt siden API-ændringerne i 2023, og scraping af persondata medfører reel juridisk risiko.
Her er det, der faktisk betyder noget.
Reddit’s vilkår for brug: Hvad de faktisk siger
Reddit’s User Agreement (revideret frem til 31. marts 2026) forbyder eksplicit at tilgå, søge i eller indsamle data fra tjenesterne ved automatiserede midler, medmindre det er tilladt i vilkårene eller gennem en separat aftale. Data API Terms og Developer Terms tilføjer flere detaljer: Reddit kan overvåge og auditere udvikleres brug, ændre eller afbryde adgang og permanent blokere adgang ved overdreven eller misbrugende brug. Kommerciel brug kræver generelt eksplicit godkendelse.
March 2026’s Responsible Builder Policy går endnu længere: godkendelse kræves, før Reddit-data tilgås via API’en, ikke-godkendt kommercialisering samt AI/data-mining-brug er forbudt, og håndhævelse kan omfatte tilbagekaldelse af tokens, suspension af apps eller konti og suspension af tilknyttede bots eller domæner.
Overholdelse af robots.txt
Reddit’s nuværende robots.txt er usædvanligt restriktiv:
User-agent: *
Disallow: /
Det er et generelt forbud for alle automatiserede user agents. Den henviser også til Public Content Policy. Det er langt stærkere end de tilladende robots.txt-mønstre, som nogle udviklere stadig antager ud fra ældre webscraping-normer.
Bedste praksis: tjek altid robots.txt før scraping, også selvom dit værktøj ikke håndhæver det automatisk.
Persondata og privatliv (GDPR/CCPA)
Hvis du scraper brugernavne, opslagshistorik eller andre personhenførbare oplysninger, kan GDPR (EU) og CCPA (Californien) være relevante. Bedste praksis: anonymisér eller aggreger persondata, før du gemmer dem. Byg ikke profiler af individuelle brugere uden et lovligt grundlag.
Licensering af GitHub-repos: Tjek før du bygger
Mange reddit scraper github-repos bruger MIT- eller Apache-licenser (lempelige), men nogle har slet ingen LICENSE-fil — hvilket juridisk betyder "alle rettigheder forbeholdes." Før du forgrener, ændrer eller bygger videre på et repo, skal du altid tjekke LICENSE-filen. Ingen licens = juridisk uklarhed, uanset hvor mange stjerner det har.
Håndhævelse er reel i 2025–2026
Reddit’s håndhævelseshistorie stoppede ikke i 2023. Reddit indgav i 2025 en klage mod Anthropic med påstand om uautoriseret scraping/anvendelse af Reddit-indhold og gik også efter Reddit v. SerpApi i slutningen af 2025. Det er tegn på, at Reddit er villig til at gå juridisk til værks — ikke kun teknisk blokere.
Vælg den rigtige Reddit Scraper GitHub-tilgang i 2026
Reddit scraper GitHub-landskabet har ændret sig dramatisk siden 2023. De fleste repos er forældede. Rate limits og 1k-opslagsgrænsen er reelle begrænsninger. Pushshift er væk for almindelige brugere. Og Reddit’s politiklag er mere eksplicit og håndhæves hårdere end nogensinde.
Den korte version:
- PRAW er stadig det mest pålidelige open source-fundament, hvis du kan acceptere Reddit’s API-begrænsninger og vil bygge speciallogik.
- Pushshift/PSAW er ikke længere standardsvaret.
- snscrape’s Reddit-modul er legacy og upålideligt.
- .json- og offentlige endpoint-scrapere er skrøbelige og bliver ofte blokeret i 2026.
- Browserbaserede værktøjer — hvad enten det er Playwright-repos eller no-code-løsninger som Thunderbit — er den mest praktiske vej for mange brugere, især ikke-udviklere.
Start med din use case, ikke med værktøjet. Kør 5-minutters repo-sundhedstjekket, før du binder dig til et GitHub-projekt.
Og hvis du hellere vil springe opsætningen over og begynde at scrape Reddit på få minutter, så prøv Thunderbit.
Prøv Thunderbit til Reddit-scraping Get Started Free
Ofte stillede spørgsmål
Hvad er de bedste open source Reddit-scrapere på GitHub i 2026?
PRAW er stadig den mest pålidelige API-wrapper med aktiv vedligeholdelse og god dokumentation. URS er et troværdigt vedligeholdt CLI-værktøj bygget på PRAW. Playwright-baserede scrapere virker til scraping uden API, og snscrape’s Reddit-modul er delvist funktionelt, men stort set ikke vedligeholdt. Tjek altid datoen for sidste commit og åbne issues, før du bruger et repo — de fleste af de 2.300+ Reddit scraper-repos på GitHub er forældede.
Er det lovligt at scrape Reddit?
Scraping af offentligt tilgængelige data befinder sig i en juridisk gråzone, men Reddit’s egne vilkår er restriktive. User Agreement, Data API Terms, Public Content Policy, Responsible Builder Policy og robots.txt taler alle imod uautoriseret masse-scraping. Kommerciel videredistribution af scraped data kan kræve Reddit’s udtrykkelige tilladelse. Hvis du scraper persondata, kan GDPR og CCPA også være relevante.
Hvordan kommer jeg forbi Reddit’s API-rate limits?
Brug eksponentiel backoff, overvåg X-Ratelimit-Remaining-headers, og overvej opdeling i tidsvinduer for at arbejde inden for grænserne. Browserbaseret scraping (Playwright eller Thunderbit) omgår API-rate limits, fordi det scraper renderede sider, men det kommer med sine egne hensyn (sideindlæsningshastighed, anti-bot-foranstaltninger). Der findes ingen magisk metode til helt at fjerne rate limits — de håndhæves på serversiden.
Kan jeg scrape Reddit uden en API-nøgle?
Ja. Playwright-baserede scrapere og .json-URL-tricket kræver ikke API-nøgler. Thunderbit kræver heller ingen API-nøgle, da det scraper via browseren. Kompromiserne: .json-endpoints bliver i stigende grad blokeret (og returnerer 403 i mange miljøer pr. april 2026), og browserbaseret scraping er langsommere og mere ressourcekrævende end API-kald.
Hvad skete der med Pushshift til Reddit-scraping?
Pushshift’s offentlige API-adgang blev fjernet efter Reddit’s ændringer i datalicenseringen, der begyndte i 2023. PSAW-wrapperen er arkiveret og forældet. Begrænset akademisk adgang kan findes via specifikke godkendte kanaler, men for de fleste brugere, der søger "reddit scraper github" i dag, er Pushshift ikke længere en brugbar løsning. Hvis du har brug for dybe historiske Reddit-data, så undersøg Reddit’s godkendte akademiske eller licenserede datapathes.
Læs mere




