
Lad mig sige det sådan: Hvis jeg fik en dollar hver gang nogen sendte mig en PDF fyldt med “vigtige data” og forventede, at jeg på magisk vis gjorde den om til et regneark, så havde jeg sandsynligvis råd til en livstidsforsyning af kaffe (og måske et par ekstra Chrome-udvidelser). PDF-filer er overalt — salgskontrakter, produktkataloger, forskningsartikler, fakturaer, du nævner det. Men når det faktisk handler om at bruge dataene i de filer? Ja, så begynder det sjove (læs: hovedpinen).
Jeg har været helt nede i maskinrummet — kopieret, indsat, omformateret og nogle gange bare givet op, når formateringen gik helt i stykker, eller billeder og links forsvandt ud i den blå luft. Men her er de gode nyheder: verdenen af PDF-scraping har ændret sig markant, især med fremkomsten af AI-drevne værktøjer. Hvis du er træt af at bruge timer på at taste tal ind igen eller miste forstanden over ødelagte tabeller, er du det rigtige sted. Lad os dykke ned i PDF-scraping, hvorfor det betyder noget, og hvordan værktøjer som Thunderbit gør det (endelig) smertefrit.
Hvad er PDF-scraping? Forstå det grundlæggende i udtræk af PDF-data
Lad os starte enkelt: PDF-scraping er bare en smart måde at sige “at hente strukturerede data ud af PDF-filer — automatisk.” En PDF scraper er et værktøj (software, udvidelse eller service), der trækker de ting ud, du faktisk har brug for — tekst, tabeller, billeder, links, du nævner det — og lægger det over i et format, du reelt kan bruge, som Excel, Google Sheets eller en database.
Men der er et aber dabei: PDF-filer er ikke som websider eller Excel-filer. De er mere som digitale udskrifter, designet til at se ens ud overalt, ikke til nemt at blive pillet fra hinanden af en computer. Nogle PDF’er har markerbar tekst, andre er bare scannede billeder (som kræver OCR — optisk tegngenkendelse), og formateringen kan være helt ude i skoven. Så at scrape en PDF handler ikke bare om at kopiere tekst — det handler om at afkode et puslespil af layout, skrifttyper og nogle gange endda skjulte metadata.
Hvad kan du udtrække fra en PDF?
- Almindelig tekst (afsnit, overskrifter osv.)
- Tabeller (tænk: regnskaber, produktspecifikationer, spørgeskemadata)
- Billeder og grafik (diagrammer, logoer, scannede signaturer)
- Hyperlinks og referencer (indlejrede URL’er, citater)
- Formulardata (felter fra udfyldelige formularer)
- Metadata (forfatter, titel, oprettelsesdato, tags)
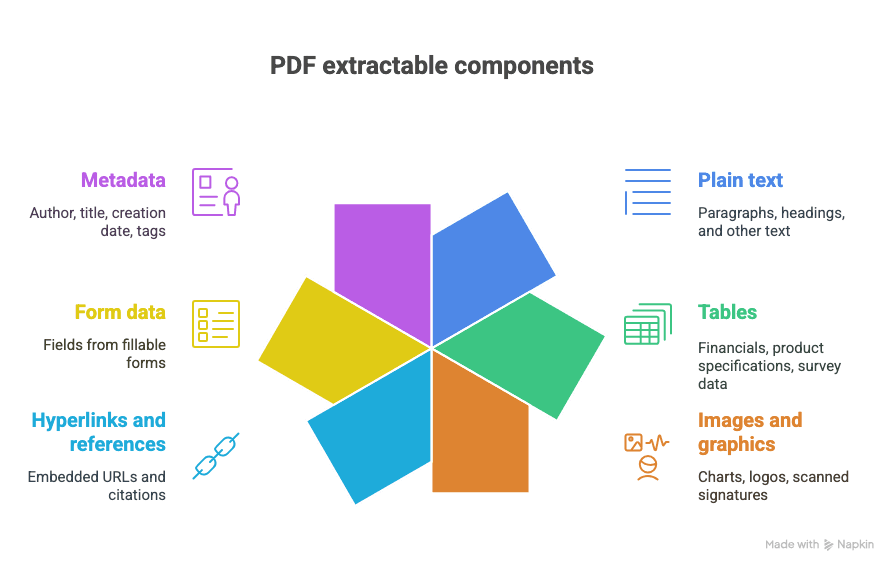
Og ja, nogle gange er det hele blandet sammen i ét herligt, kaotisk dokument.
Hvorfor PDF-scraping er vigtigt: praktiske brugsscenarier og forretningsfordele
Så hvorfor overhovedet scrape PDF’er? Fordi alle bruger dem, og dataene i dem er ofte kritiske for forretningen. Det er her, PDF-scraping virkelig skinner:
| Brugsscenarie | Manuelt arbejde | Med PDF Scraper | Tids- og fejlbesparelse |
|---|---|---|---|
| Udtræk af salgsemner | Timer med at kopiere kontakter fra tilbud eller event-PDF’er, risiko for at misse leads | Trækker straks alle leads ind i et regneark | 80–90 % hurtigere, færre fejl |
| Produktdata til e-handel | Dage med at indtaste produktspecifikationer fra leverandør-PDF’er, formateringsmareridt | Masseudtræk til CSV eller Sheets | 95 %+ tidsbesparelse, ensartede data |
| Analyse af forskningsdata | Uger med at afskrive tabeller fra akademiske artikler, høj risiko for slåfejl | Udtrækker tabeller, referencer og endda scannet tekst | 80 % tidsbesparelse, højere nøjagtighed |
Lad os sætte tal på:
- 2,5 billioner PDF’er bliver oprettet hvert år.
- 90 % af organisationer bruger PDF som primært format til informationsdeling.
- Manuel digital administration (som indtastning af PDF-data) sluger 40 % af arbejdstiden.
- Automatiserede værktøjer kan reducere fejlprocenter fra 5–10 % ned til 1 %.
Hvis du arbejder med salg, e-handel eller forskning, er automatisering af udtræk af PDF-data ikke bare en rar bonus — det er en konkurrencefordel.
Traditionelle metoder til PDF-scraping: udfordringer og begrænsninger
Lad os være ærlige: de gamle måder at få data ud af PDF’er på er… ikke gode. Her er, hvad de fleste af os har prøvet (og hvorfor det er så frustrerende):

1. Manuel kopier-og-indsæt
- Smertepunkter: Formateringen bliver ødelagt, tabeller ender i kaos, billeder og links forsvinder, og du står tilbage med migræne.
- Arbejdsomkostning: Høj. Hvis du har 5.000 PDF’er, og det tager 1 minut pr. fil, er det 80+ timer af dit liv, du aldrig får igen.
- Fejlrate: 5–10 %. Tastefejl, oversprungne rækker, utilsigtede sletninger — været der, gjort det.
2. Konverter til Word/Excel og ryd derefter op
- Smertepunkter: Virker nogle gange til simple dokumenter, men komplekse layouts eller tabeller bliver rodet sammen. Du skal stadig rydde op bagefter.
- Billeder/links: Forsvinder som regel i oversættelsen.
- Målrettet udtræk: Glem det — du får hele dokumentet, ikke kun det, du har brug for.
3. Brugerdefinerede scripts (Python osv.)
- Smertepunkter: Du skal være programmør (eller have én på hurtigkald). Hvert nyt PDF-format betyder, at scriptet skal justeres. Scannede PDF’er? Held og lykke.
- Vedligeholdelse: Høj. Hver gang en leverandør ændrer deres fakturaskabelon, går dit script i stykker.
- Skalerbarhed: Ikke for sarte sjæle (eller ikke-tekniske brugere).
4. Online-konvertere
- Smertepunkter: Nemme til engangsopgaver, men du skal uploade følsomme dokumenter til en tredjepartsserver (hej, compliance-problemer). Begrænset kontrol over, hvad der bliver udtrukket.
- Formatering: Svingende. Du risikerer at bruge mere tid på oprydning, end du sparer.
Kort sagt: Traditionelle metoder er langsomme, fejlbehæftede og kan ikke skaleres. Derfor vælger så mange teams bare at “leve med det” — men til en høj pris i produktivitet.
Moderne løsninger til PDF-scraping: fra kode til no-code-værktøjer
Heldigvis er vi ikke længere fastlåst i de mørke tider. Landskabet har eksploderet med smartere, hurtigere og mere brugervenlige muligheder for PDF-scraping.
1. Kodningsbiblioteker (for udviklere)
- Eksempler: PyPDF2, PDFMiner, Tabula-py.
- Styrker: Superfleksible, kan automatiseres til store batcher, gratis (open source).
- Svagheder: Høj opsætningstid, kræver programmeringsevner, skrøbelige (går i stykker ved nye formater), begrænset OCR-/billedunderstøttelse.
2. Online PDF-konvertere
- Eksempler: Smallpdf, PDF2Go, Zamzar.
- Styrker: Ingen opsætning, nemt for ikke-tekniske brugere, hurtigt til små opgaver.
- Svagheder: Begrænset tilpasning, bekymringer om privatliv, formateringsfejl, begrænsninger på filstørrelse/sider.
3. AI-drevne PDF-scrapere
- Eksempler: Thunderbit, Nanonets, Docparser.
- Styrker: Ingen kodning nødvendig, håndterer tekst/tabeller/billeder/links, AI foreslår, hvad der skal udtrækkes, understøtter batchjobs, integrerer med Sheets/Notion/Airtable.
- Svagheder: Nogle har kredit-/sidegrænser, kræver måske internetforbindelse, og der kan være en indlæringskurve ved komplekse dokumenter.
Sammenligning af PDF-scrapingværktøjer: hvilken tilgang passer til dine behov?
| Værktøj/metode | Opsætning | Bedst til | Udtrækker | Kan tilpasses? | Pris |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Mellem (UI/kode) | Tabeller i PDF’er | Tabeller | Delvist | Gratis |
| PDFMiner | Kræver kodning | Teksttunge PDF’er | Tekst | Ja (kode) | Gratis |
| PyPDF2 | Kræver kodning | Enkel tekst/metadata | Tekst, metadata | Ja (kode) | Gratis |
| Smallpdf/online konv. | Ingen (webbaseret) | Hurtige konverteringer | Hele dokumentet (Word/Excel) | Nej | Freemium |
| Thunderbit | 2-kliks installation | Forretningsbrugere, teams | Tekst, tabeller, billeder, links | Ja (AI-prompts) | Freemium ($16,5/md. for Pro) |
Mød Thunderbit: AI PDF Scraper Chrome-udvidelsen
Sådan scraper du data fra PDF med AI Get Started Free
Lad os nu tale om det værktøj, der har gjort mit liv — og mange forretningsbrugeres liv — så meget lettere: Thunderbit.
Hvad gør Thunderbit anderledes?
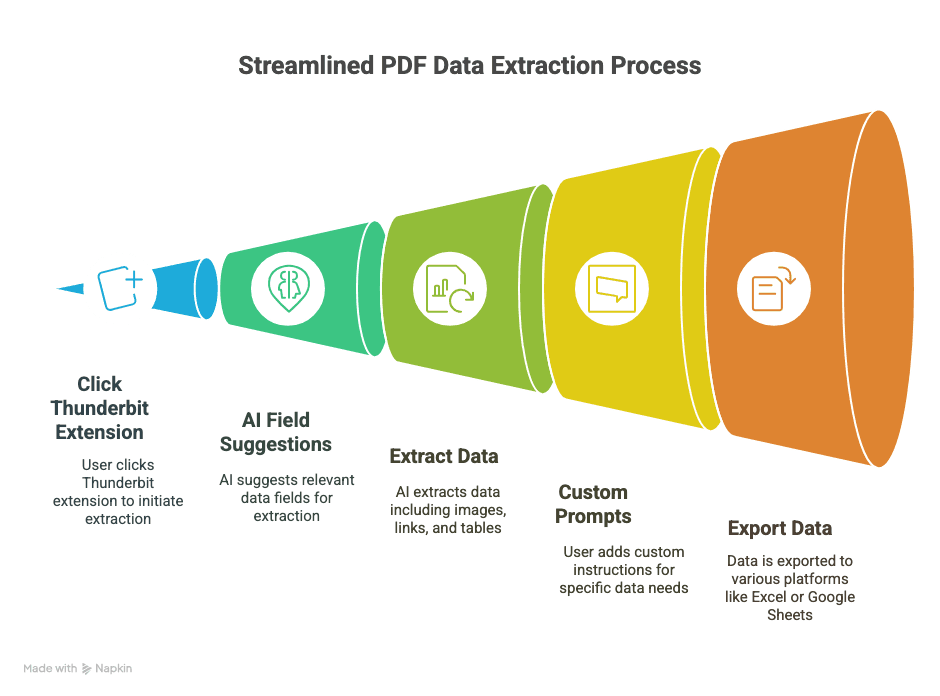
- 2-kliks udtræk: Åbn en PDF i Chrome, klik på Thunderbit-udvidelsen, og lad AI klare resten.
- AI-drevne feltsuggestioner: Thunderbits “AI Suggest Fields” læser din PDF og foreslår de kolonner, du sandsynligvis har brug for (som “Navn”, “E-mail”, “Pris” osv.).
- Håndterer billeder, links og tabeller: Ikke kun almindelig tekst — Thunderbit kan trække billeder, hyperlinks ud og endda køre OCR på scannede dokumenter.
- Brugerdefinerede prompts: Har du kun brug for telefonnumre eller produktspecifikationer? Tilføj en brugerdefineret instruktion, så fokuserer Thunderbit kun på det.
- Eksporter overalt: Send dine data direkte til Excel, Google Sheets, Airtable eller Notion. Slut med CSV-krumspring.
- Batch- og underpagescraping: Har du en liste med PDF’er eller links? Thunderbit kan behandle dem alle på én gang.
- Pålidelighed i virksomhedsklasse: Designet til nøjagtighed, privatliv og rigtige arbejdsgange.
Kort sagt er det som at have en digital praktikant, der faktisk elsker at lave dataindtastning (og aldrig bliver træt).
Sådan scraper du data fra en PDF med Thunderbit: trin-for-trin-guide
Download Thunderbit Chrome-udvidelsen Get Started Free
Klar til at se, hvor nemt det kan være? Sådan bruger jeg Thunderbit til at gøre PDF’er til strukturerede data, der kan bruges:
1. Installer Thunderbit
- Hent Thunderbit Chrome-udvidelsen.
- Opret en konto (Google-konto eller e-mail — det tager få sekunder).
2. Åbn din PDF i Chrome
- Åbn enten en PDF fra et weblink, eller træk en lokal PDF ind i en Chrome-fane.
3. Start Thunderbit på PDF’en
- Klik på Thunderbit-ikonet i browserens værktøjslinje.
- Vælg “AI Web Scraper” — Thunderbit registrerer PDF’en og gør klar til at arbejde.
4. Lad AI foreslå felter
- Klik på “AI Suggest Columns”.
- Thunderbits AI scanner PDF’en og anbefaler kolonner (som “Dato”, “Beløb”, “Kontaktnavn” osv.).
- Se de udtrukne data i en tabel direkte i udvidelsen.
5. Tilpas om nødvendigt
- Omdøb kolonner, slet ekstra felter, eller tilføj dine egne (fx “Garantiperiode” eller “Produkt-URL”).
- Ved vanskelige data kan du markere tekst i PDF’en for at træne AI’en i, hvad du vil have.
6. Vælg eksportformat
- Vælg mellem CSV, Google Sheets, Airtable eller Notion.
- Giv Thunderbit adgang til at oprette forbindelse (engangsopsætning).
7. Scrape og eksportér
- Tryk på “Scrape” eller “Export”.
- Thunderbit behandler PDF’en og sender dataene derhen, hvor du vil have dem — som regel på få sekunder.
Prøv Thunderbit PDF Scraper nu
Det var det. Ingen kodning, ingen kopier-og-indsæt, intet drama.
Tips til præcis udtrækning af PDF-data med Thunderbit
- Gennemgå AI-forslåede felter: AI’en er klog, men et hurtigt kig sikrer, at du får præcis det, du har brug for.
- Håndter komplekse tabeller: Ved tabeller over flere sider eller mærkeligt formaterede tabeller kan du bruge forhåndsvisningen til at spotte problemer og justere kolonner efter behov.
- Udtræk billeder/links: Sørg for at inkludere disse felter, hvis din PDF har dem — Thunderbit kan også hente dem.
- Scannede PDF’er: Thunderbits indbyggede OCR er solid, men jo renere scanningen er, desto bedre bliver resultatet.
- Brugerdefinerede prompts: Vil du kun have e-mails eller telefonnumre? Tilføj en prompt som “Udtræk alle e-mailadresser”, så fokuserer Thunderbit på dem.
Avanceret PDF-scraping: udtræk af billeder, links og brugerdefinerede data
Thunderbit handler ikke kun om almindelig tekst. Sådan får du endnu mere ud af dine PDF’er:
- Billeder: Udtræk logoer, diagrammer eller andre indlejrede grafikker. Thunderbit kan endda OCR-læse tekst inde i billeder.
- Hyperlinks: Træk alle URL’er eller referencer ud — perfekt til forskningsartikler eller CV’er.
- Brugerdefinerede datatyper: Brug AI-prompts til kun at udtrække det, du har brug for (fx “Find alle produkt-SKU’er og deres priser”).
- Resuméer og kategorisering: Tilføj en kolonne og bed Thunderbit om at opsummere et afsnit eller kategorisere data i realtid.
Parsning af data fra PDF til specifikke forretningsbehov
- Salg: Udtræk kun kontaktoplysninger fra en batch af tilbud.
- E-handel: Hent produktspecifikationer, priser og billeder fra leverandørkataloger.
- Forskning: Træk tabeller, referencer og generér endda resuméer fra akademiske artikler.
Og når du først har dataene, kan du strukturere dem til nem analyse i Excel, Google Sheets eller Notion — Thunderbit klarer det tunge arbejde, og du får bare lov at bruge resultaterne.
Eksport og brug af dine PDF-data: fra udtræk til handling
At få dataene ud er kun begyndelsen. Sådan får du dem til at arbejde for dig:
- Eksportmuligheder: CSV, Excel, Google Sheets, Airtable, Notion — vælg din favorit.
- Formateringstips: Brug Thunderbits kolonnetypeindstillinger (tal, dato, tekst) for rene data, der er klar til analyse.
- Workflow-integration: Forbind de eksporterede data til CRM-systemer, lagerstyring eller analysetavler.
- Samarbejde: Del Google Sheets eller Airtable-baser med dit team — alle arbejder ud fra de samme opdaterede data.
Det bedste? Slut med at e-maile regneark frem og tilbage eller spekulere på, om du har overset en række.
Almindelige faldgruber ved PDF-scraping og hvordan du undgår dem
Selv med de bedste værktøjer kan der opstå nogle snubletråde. Her er, hvad jeg har lært — nogle gange på den hårde måde:
- OCR-fejl: Slørede scans eller mærkelige skrifttyper kan snyde selv den bedste OCR. Brug så rene PDF’er som muligt, og dobbelttjek kritiske felter.
- Komplekse layouts: Tabeller med flere kolonner eller indlejrede tabeller kan have brug for lidt manuel vejledning — brug Thunderbits manuelle markering eller prompts.
- Datatyper: Tal med kommaer eller datoer i usædvanlige formater? Sæt kolonnens datatype før eksport, eller ryd op i Excel/Sheets.
- Filstørrelse-/sidegrænser: Kæmpe PDF’er? Del dem op i mindre bidder, eller brug Thunderbits cloud-tilstand til batchjobs.
- AI-“hallucination”: Sjældent, men AI kan nogle gange gætte et kolonnenavn eller udfylde manglende data. Tjek altid outputtet, især når det gælder vigtige tal.
- Manuel gennemgang: Ved data, der er forretningskritiske, så lav en hurtig validering — automatiske værktøjer er nøjagtige, men et menneskeligt blik skader aldrig.
Og hvis du rammer en mur, er Thunderbits support og community klar til at hjælpe.
Konklusion og vigtigste pointer: få PDF-scraping til at arbejde for din virksomhed
Lad os runde af. At scrape data fra PDF’er var engang et mareridt — langsomt, fejlbehæftet og bare kedeligt. Men med moderne værktøjer som Thunderbit er det nu hurtigt, præcist og (vovet sagt) næsten behageligt.
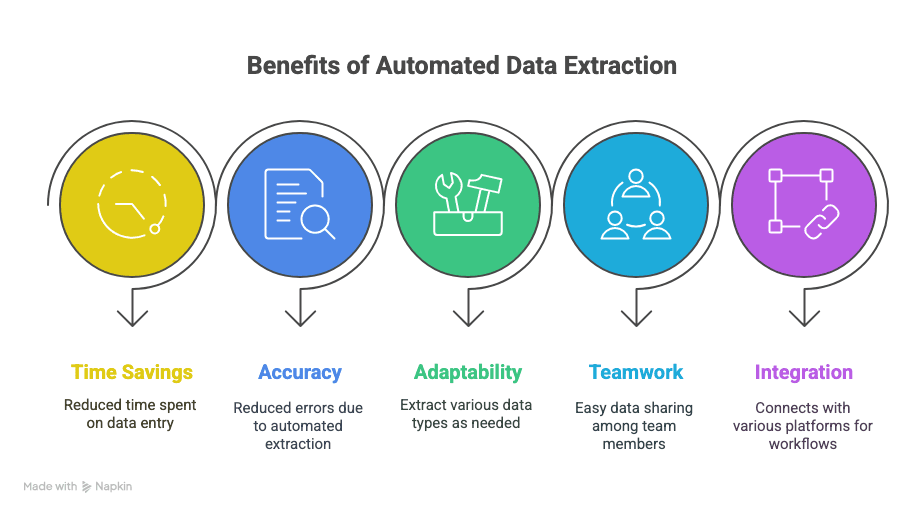
Det her får du:
- Tid tilbage: Timer — eller endda uger — sparet på manuel dataindtastning.
- Færre fejl: Automatisk udtræk betyder færre tastefejl og færre oversprungne rækker.
- Fleksibilitet: Udtræk præcis det, du har brug for — tekst, tabeller, billeder, links, du nævner det.
- Samarbejde: Del data øjeblikkeligt med dit team, uanset hvor de befinder sig.
- Klogere arbejdsgange: Integrer med Sheets, Notion, Airtable og meget mere.
Klar til at prøve det? Download Thunderbit Chrome-udvidelsen, kør den på din næste PDF, og se, hvor meget lettere livet kan blive. Dit fremtidige jeg (og din karpaltunnel) vil takke dig.
For flere tips og guides, tjek Thunderbit Blog eller dyk dybere ned i Sådan scraper du data fra PDF med AI.
Lad os forvandle de der PDF-hovedpiner til produktivitetsgevinster — ét klik ad gangen.
Shuai Guan, medstifter og CEO, Thunderbit
Prøv Thunderbit AI PDF Scraper Get Started Free




