Tempoet i digitale nyheder i dag er mildest talt svimlende. Hvert minut bliver tusindvis af overskrifter publiceret, opdateret eller diskret redigeret—på tværs af store medier, nicheblogs og sociale feeds. For at sætte det i perspektiv indlæser over 4 millioner nyhedsartikler hver eneste dag, mens følger nyheder på 100+ sprog og opdaterer sit globale feed hvert 15. minut. For alle i medier, forskning eller business intelligence føles det at forsøge at følge med manuelt som at øse en synkende båd med et kaffekrus.
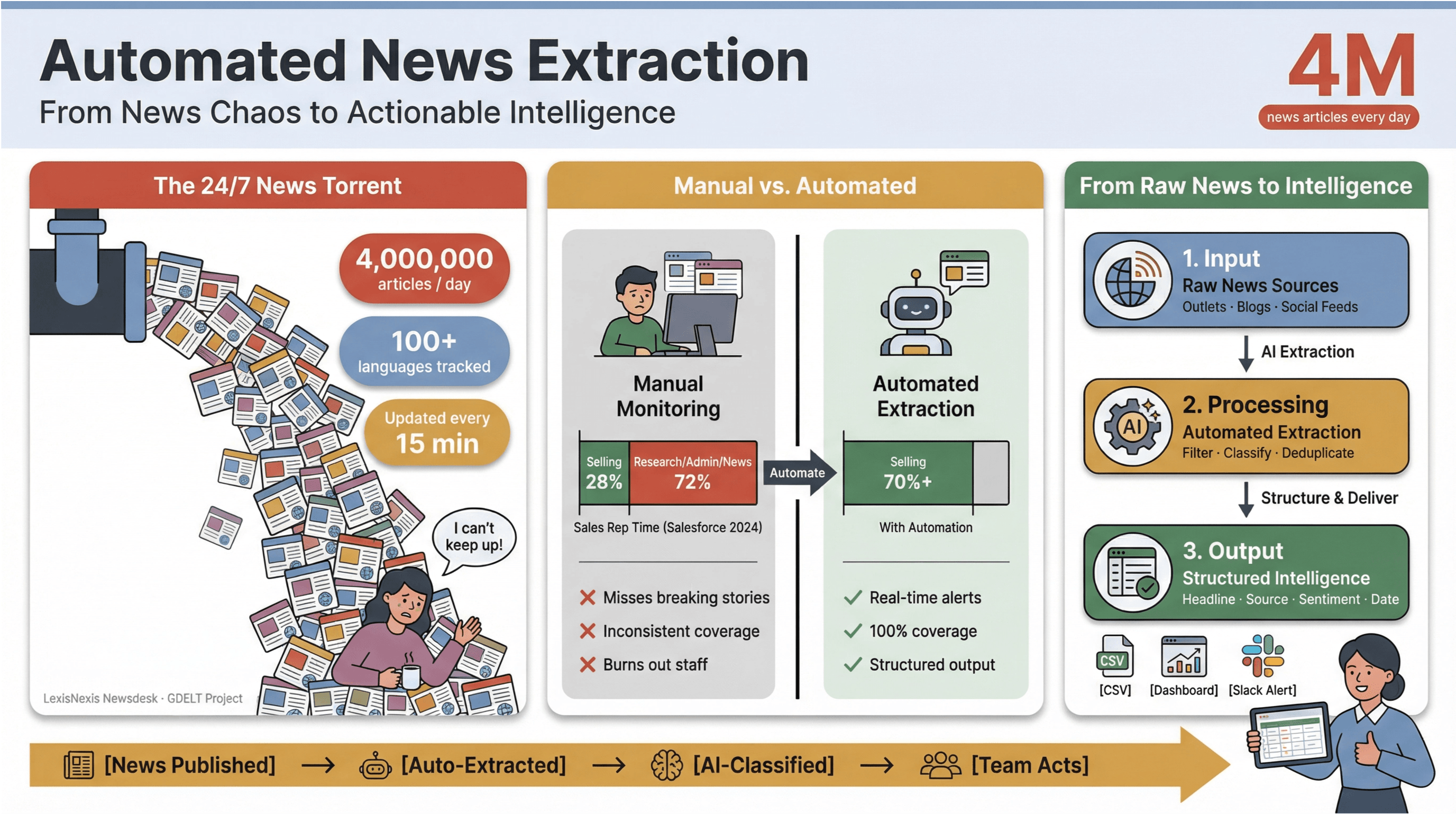
Jeg har selv set, hvordan manuel nyhedsovervågning sluger tid og dræner ressourcer. Salgsteams bruger under en tredjedel af ugen på faktisk at sælge——mens resten forsvinder i research, administration og ja, endeløs jonglering med nyhedsfaner. Derfor er automatiseret nyhedsudtræk blevet et hemmeligt våben for moderne teams: det er den eneste måde at gøre 24/7-nyhedscyklens kaos til struktureret, handlingsorienteret indsigt—uden at brænde medarbejderne af eller misse de historier, der betyder mest.
Lad os dykke ned i, hvad automatiseret nyhedsudtræk egentlig dækker over, hvorfor det er afgørende for alle, der arbejder med nyhedsdata i realtid, og hvordan du bygger et robust workflow, der også spiller efter reglerne—med de bedste værktøjer (inklusive hvordan gør processen overraskende enkel—selv for ikke-tekniske brugere som min mor).
Automatiseret nyhedsudtræk: Hvorfor det er uundværligt for moderne redaktioner
Automatiseret nyhedsudtræk er præcis, hvad det lyder som: software, der indsamler nyhedsindhold automatisk og omdanner det til strukturerede, søgbare data—tænk rækker og kolonner i stedet for rodede websider eller PDF’er. I praksis betyder det, at du kan overvåge hundredvis (eller tusindvis) af kilder, udtrække nøglefelter som overskrift, tidsstempel, forfatter og brødtekst og sende data videre til dashboards, alarmer eller analyser—uden nogensinde at røre Ctrl+C/Ctrl+V.
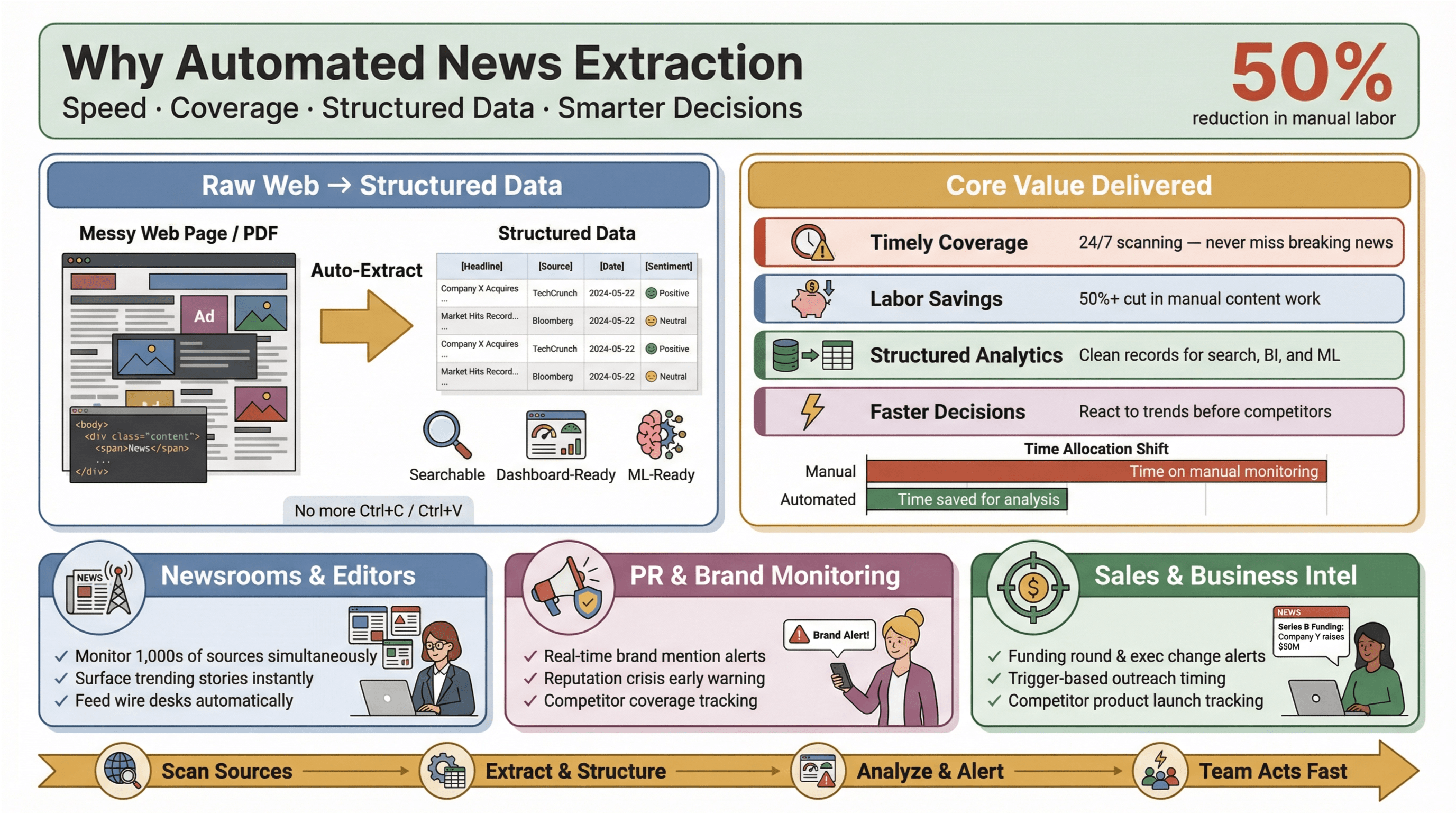 Hvorfor er det vigtigt? Fordi hastighed er alt i nutidens nyhedsbillede. Uanset om du er redaktør, PR-ansvarlig der holder øje med omtale, eller analytiker der følger konkurrenters træk, kan det at være først med viden være forskellen på at gribe en mulighed og at komme haltende bagefter. Automatiserede udtræksværktøjer gør, at selv små teams kan levere på et niveau, der normalt kræver langt større ressourcer—ved at hente nyhedsdata i realtid fra hele nettet, reducere manuelt arbejde og fremhæve de historier, der betyder mest.
Hvorfor er det vigtigt? Fordi hastighed er alt i nutidens nyhedsbillede. Uanset om du er redaktør, PR-ansvarlig der holder øje med omtale, eller analytiker der følger konkurrenters træk, kan det at være først med viden være forskellen på at gribe en mulighed og at komme haltende bagefter. Automatiserede udtræksværktøjer gør, at selv små teams kan levere på et niveau, der normalt kræver langt større ressourcer—ved at hente nyhedsdata i realtid fra hele nettet, reducere manuelt arbejde og fremhæve de historier, der betyder mest.
Og effekten er til at tage og føle på: undersøgelser viser, at automatisering kan reducere manuelt arbejde med indholdsopdateringer med mindst 50%, så der frigøres tid til reel analyse og beslutningstagning.
Kerneværdien af automatiseret nyhedsudtræk i nyhedsbranchen
Lad os blive helt konkrete. Hvad giver automatiseret nyhedsudtræk faktisk redaktioner og forretningsteams?
- Rettidig og dækkende overvågning: Du misser ikke længere breaking news, fordi nogen glemte at tjekke et feed. Automatiserede værktøjer scanner kilder døgnet rundt.
- Besparelser på tid og omkostninger: Små og mellemstore teams kan følge lige så mange kilder som de store—uden at ansætte en hær af praktikanter.
- Strukturerede data til analyse: I stedet for at rode i ustrukturerede artikler får du rene poster, klar til søgning, dashboards og machine learning.
- Hurtigere og bedre beslutninger: Nyhedsdata i realtid gør det muligt at reagere på markedsændringer, PR-kriser eller nye trends før konkurrenterne.
I PR og kommunikation fremhæver platforme som og overvågning i realtid som afgørende for at beskytte omdømme og handle hurtigt på skadelig omtale. I salg bliver nyhedsalarmer i realtid til “kontekstkort” i prospektering—fx finansieringsrunder, ledelsesændringer eller produktlanceringer, der udløser outreach på det helt rigtige tidspunkt.
Sådan vælger du de rigtige nyhedsscraping-værktøjer til forskellige scenarier
Ikke alle værktøjer til nyhedsscraping er lige skarpe. Det rigtige valg afhænger af dine mål, din tekniske komfort og hvilke typer nyheder, du arbejder med. Her er en enkel ramme til at finde det bedste match:
Vurdering af brugervenlighed og tilgængelighed
For de fleste forretningsbrugere og journalister er brugervenlighed ikke til forhandling. Du vil have et værktøj, der virker med det samme—uden kode og uden besværlig opsætning. No-code og low-code platforme som , og lader dig bygge scrapers visuelt—peg, klik og udtræk.
Thunderbit skiller sig især ud med sin to-trins proces: beskriv, hvad du vil have, lad AI foreslå felter, og tryk “Scrape”. Selv ikke-tekniske brugere kan sætte en nyhedsdatapipeline op på minutter i stedet for timer.
Sikkerhed og hensyn til databeskyttelse
Med store datamængder følger stort ansvar. Værktøjer til nyhedsscraping kan få adgang til følsomt indhold, så sikkerhed og compliance bør være i fokus. Kig efter:
- Kryptering af data (under overførsel og i hvile)
- Tydelige privatlivspolitikker (Thunderbit oplyser fx, at de ikke sælger brugerdata og kun tilgår indhold, du selv vælger at scrape)
- Detaljerede tilladelser (især for browser-udvidelser—tjek altid, hvilke data værktøjet kan tilgå)
- Overholdelse af lokale regler (GDPR, CCPA og for EU-brugere )
For ekstra ro i maven: vælg velrenommerede leverandører, gennemgå udvidelsestilladelser, og begræns adgang til det nødvendige.
Match værktøjer til nyhedstyper og branchebehov
Nogle værktøjer er særligt stærke inden for bestemte nyhedsområder:
- Finans: API’er som og tilbyder clustering, sentiment og event-detektion til finansnyheder.
- Tech & startups: Skræddersyet scraping med Thunderbit eller Octoparse gør det muligt at ramme nicheblogs, pressemeddelelser eller eventlister.
- Politik & regulering: Licenserede databaser som og giver adgang til premiumkilder og arkiver.
Hvis du skal overvåge en blanding af mainstream, niche og internationale kilder—inklusive dem uden API’er—er fleksible, AI-drevne scrapers som Thunderbit ofte det bedste valg.
Thunderbits unikke fordele til udtræk af nyhedsdata i real tid
Lad os kigge på, hvad der gør til et stærkt valg til automatiseret nyhedsudtræk—særligt hvis du vil have nyhedsdata i realtid uden tekniske hovedpiner.
Thunderbit er en AI-drevet web scraper Chrome Extension målrettet forretningsbrugere, journalister og analytikere, der har brug for opdateret, struktureret nyhedsindhold fra enhver hjemmeside. Her er grunden til, at det er blevet mit foretrukne værktøj:
- AI Suggest Fields: Thunderbit læser nyhedssiden og foreslår automatisk de bedste kolonner at udtrække—overskrift, tidsstempel, forfatter, resumé m.m. Ingen bøvl med selectors eller skabeloner.
- Subpage Scraping: Har du brug for hele artiklen og ikke kun overskriften? Thunderbit kan besøge hvert nyhedslink, udtrække brødtekst, entiteter og tags og samle det hele i én struktureret tabel.
- Masseeksport & øjeblikkelige opdateringer: Eksportér direkte til Excel, Google Sheets, Airtable eller Notion med ét klik. Slut med copy-paste-maraton og CSV-rod.
- Scheduled Scraper: Opsæt tilbagevendende jobs (hver time, dagligt eller med egne intervaller) for at holde din nyhedspipeline frisk—perfekt til breaking news, markedsmonitorering eller løbende research.
- Tilpasningsevne: Thunderbits AI tilpasser sig layoutændringer og long-tail nyhedssites, så du bruger mindre tid på at reparere scrapers og mere tid på at analysere data.
Med over og en rating på 4,8 stjerner er det et værktøj, teams verden over bruger til alt fra PR-overvågning til konkurrentanalyse.
AI-drevet feltdetektion og Subpage Scraping
En af Thunderbits stærkeste funktioner er AI-drevet feltdetektion. Klik på “AI Suggest Fields”, og værktøjet scanner nyhedssiden og identificerer centrale felter som titel, dato, forfatter og resumé. Du kan justere eller tilføje egne felter (fx “tag denne artikel som ‘regnskab’, hvis den nævner kvartalsresultater”), og Thunderbits AI klarer resten.
Subpage Scraping er en gamechanger for nyheder: Du scraper en forside eller sektionsliste for overskrifter og lader derefter Thunderbit besøge hver artikel-URL for at hente hele historien, entiteter og endda billeder. Resultatet er komplette, berigede nyhedsposter—klar til søgning, dashboards eller videre AI-analyse.
Masseeksport og øjeblikkelige opdateringer
Thunderbit gør eksport af nyhedsdata nemt. Med ét klik kan du sende dit strukturerede nyhedsfeed til Google Sheets, Airtable, Notion eller downloade som CSV/Excel. For teams, der lever i regneark eller BI-værktøjer, er det en stor tidsbesparelse.
Og fordi Thunderbit understøtter Scheduled Scraper, kan du få det til at køre hver time, hver dag eller efter din egen plan—så dine nyhedsdata altid er opdaterede. Du slipper for at vente på, at Google Alerts indekserer historier flere dage for sent.
Sådan håndterer du driftsudfordringer i løsninger med nyhedsdata i realtid
Selv med de bedste værktøjer følger der udfordringer med nyhedsudtræk i realtid. Her er, hvordan du tackler de mest almindelige:
Håndtering af latenstid og datafriskhed
- Planlæg scraping efter nyhedstempo: Ved breaking news kan scrapers køre hvert 15.–30. minut (i tråd med ). For langsommere områder kan dagligt eller hver time være nok.
- Overvåg forskellen mellem publicering og hentning: Mål tiden fra en artikel udgives, til dit system henter den. Hvis forsinkelsen vokser, kan det skyldes blokeringer eller performance.
- Scrape igen for “stille redigeringer”: Nyhedsartikler opdateres ofte efter publicering. Planlæg et ekstra scrape 24 timer senere for at fange rettelser eller diskrete ændringer ().
Håndtering af API-begrænsninger og variation mellem kilder
- Respektér API-kvoter: Hvis du bruger nyheds-API’er, så hold øje med rate limits—fordel kald over tid og cache resultater, når det er muligt ().
- Fjern dubletter og brug canonical: Nyhedshistorier kan ligge på flere URL’er eller blive opdateret. Gem canonical-URL’er og brug hashes (fx titel + dato) for at undgå dubletter ().
- Håndtér dynamisk indhold: For sites med infinite scroll eller lazy loading skal du bruge værktøjer, der kan rendere dynamisk indhold, og holde øje med layoutændringer ().
Smart analyse af nyhedsdata: AI og machine learning i praksis
At udtrække nyheder er kun første skridt. Den reelle værdi kommer af at analysere og handle på data—og her er AI og machine learning stærke.
- Entitetsudtræk: Brug NLP til at identificere personer, organisationer og steder i hver artikel ().
- Emneklassifikation: Tag artikler automatisk efter emne, sentiment eller hast—så dashboards og alarmer bliver smartere ().
- Event clustering: Saml dubletter og relaterede historier på tværs af medier, så du ser helheden (ikke bare en strøm af næsten identiske overskrifter).
- Personalisering og målretning: Brug nyhedsdata i realtid til at segmentere målgrupper, forbedre annonce-targeting eller anbefale indhold—og løfte engagement og ROI.
Fx bruger PR-teams nyhedsanalyse i realtid til at opdage spirende kriser, før de går viralt, mens salgsteams beriger prospektlister med “trigger events” som finansieringsrunder eller nye ledelsesansættelser.
Tjekliste: Bedste praksis for automatiseret nyhedsudtræk
Her er en hurtig tjekliste, der hjælper dig med at holde din nyhedsudtrækspipeline stabil:
| Bedste praksis | Hvorfor det er vigtigt | Sådan gør du |
|---|---|---|
| Planlæg hyppige scrapes | Minimer forsinkelse, fang breaking news | Tilpas frekvens til nyhedstempo (fx hver 15. min ved hurtige områder) |
| Brug AI-drevet udtræk | Tilpasning til layoutændringer, hurtigere opsætning | Værktøjer som Thunderbit, Diffbot, Zyte API |
| Fjern dubletter og brug canonical | Undgå dobbelte alarmer, hold data rene | Gem canonical-URL’er, brug hashes til deduplikering |
| Overvåg udtrækskvalitet | Fang manglende felter, drift eller fejl | Mål % komplette poster, latenstid og fejlrater |
| Respektér jura/compliance | Reducér juridisk risiko, bevar tillid | Brug officielle API’er/feeds, gennemgå vilkår, minimer persondata |
| Eksportér til strukturerede formater | Muliggør videre analyse | CSV, Excel, Sheets, Notion, Airtable |
| Planlæg re-scrapes for redigeringer | Fang ændringer efter publicering | Besøg artikler igen efter 24t/1u (GDELT-model) |
| Sikr din pipeline | Beskyt følsomme data | Kryptering, adgangskontrol, velrenommerede værktøjer |
Sådan bygger du et robust workflow til automatiseret nyhedsudtræk
Klar til at bygge din egen “black box” til nyhedsdata? Her er et trin-for-trin workflow:
- Identificér dine kilder: Lav en liste over nyhedssites, blogs eller API’er, du vil overvåge.
- Sæt udtræk op: Brug Thunderbit eller et andet værktøj til at definere felter (AI Suggest Fields gør det nemt).
- Planlæg scrapes: Vælg frekvens efter nyhedstempo—hver time ved breaking news, dagligt ved langsommere områder.
- Berig med subpages: For hver overskrift: scrape hele artiklen for brødtekst, entiteter og tags.
- Fjern dubletter og normalisér: Gem canonical-URL’er, hash poster og standardisér felter.
- Eksportér og integrér: Send strukturerede data til Excel, Google Sheets, Airtable eller Notion til analyse.
- Overvåg og tilpas: Følg kvaliteten, hold øje med layoutændringer, og justér efter behov.
- Overhold reglerne: Gennemgå vilkår, respekter robots.txt, og minimer persondata.
Som en visuel model:
Kilder → Udtræk (AI-felter) → Subpage-berigelse → Deduplikering → Eksport → Analyse/alarmer → Overvågning
Konklusion og vigtigste pointer
Automatiseret nyhedsudtræk er ikke længere bare “nice-to-have”—det er nødvendigt for alle, der vil være på forkant i en verden, hvor nyheder bryder (og ændrer sig) fra minut til minut. Med bedste praksis og de rigtige værktøjer kan du forvandle den digitale nyhedsstrøm til en stabil kilde af struktureret, handlingsklar indsigt.
Vigtigste takeaways:
- Skalaen og hastigheden i online nyheder kræver automatisering—manuel overvågning kan ikke følge med.
- Værktøjer til automatiseret nyhedsudtræk sparer tid, sænker omkostninger og gør små teams i stand til at matche langt større organisationers dækning.
- Det rigtige værktøj handler om balance mellem brugervenlighed, sikkerhed og tilpasningsevne—Thunderbit skiller sig ud med AI-drevet enkelhed og eksport i realtid.
- Byg workflowet omkring friskhed, deduplikering, compliance og kvalitetsmonitorering for at sikre pålidelige, anvendelige nyhedsdata.
- AI og machine learning skaber endnu mere værdi—med smartere målretning, personalisering og beslutningsstøtte.
Hvis du stadig copy-paster overskrifter eller venter på, at Google Alerts indhenter virkeligheden, er det tid til at opgradere. og oplev, hvor nemt automatiseret nyhedsudtræk kan være. For flere tips, workflows og dybdegående guides, se .
FAQs
1. Hvad er automatiseret nyhedsudtræk, og hvordan fungerer det?
Automatiseret nyhedsudtræk er processen, hvor software indsamler nyhedsartikler og omdanner dem til strukturerede data (fx tabeller eller JSON) til analyse, søgning eller alarmer. Værktøjer som Thunderbit bruger AI til at identificere nøglefelter (overskrift, tidsstempel, forfatter, brødtekst) og udtrække dem automatisk fra websider eller API’er.
2. Hvorfor er nyhedsdata i realtid så vigtigt for virksomheder?
Nyhedsdata i realtid gør det muligt for virksomheder at reagere hurtigt på markedsbegivenheder, PR-kriser eller konkurrenters træk. Uanset om du arbejder med salg, PR eller research, giver opdaterede nyheder bedre og hurtigere beslutninger—og et forspring.
3. Hvordan gør Thunderbit nyhedsscraping lettere for ikke-tekniske brugere?
Thunderbit har en enkel to-trins proces: beskriv, hvilke data du vil have, og lad AI foreslå felter. Med funktioner som Subpage Scraping og øjeblikkelig eksport til Excel eller Google Sheets kan selv ikke-tekniske brugere bygge solide nyhedsdatapipelines på få minutter.
4. Hvilke juridiske og compliance-mæssige hensyn gælder ved nyhedsscraping?
Gennemgå altid vilkår for de sites, du scraper, brug helst officielle API’er eller feeds, når de findes, og respekter robots.txt. Undgå at scrape indhold bag login eller paywall uden tilladelse, og minimer indsamling af persondata for at overholde privatlivslovgivning.
5. Hvordan sikrer jeg, at mit workflow til nyhedsudtræk forbliver stabilt over tid?
Planlæg regelmæssige scrapes, overvåg udtrækskvalitet, og brug værktøjer, der kan tilpasse sig layoutændringer (som Thunderbits AI-drevne udtræk). Fjern dubletter, mål forsinkelsen mellem publicering og udtræk, og opsæt alarmer ved fejl eller manglende felter, så din pipeline forbliver sund og opdateret.
Læs mere