

Mit OpenRouter-dashboard viste $47 brugt før frokost på en tirsdag. Jeg havde måske kørt et dusin kodningsopgaver — ikke noget voldsomt, bare lidt refaktorering og et par bugfixes. Det var dér, det gik op for mig, at OpenClaws standardindstillinger stille og roligt sendte hver eneste interaktion, inklusive baggrunds-heartbeat-pings, gennem Claude Opus til $15+ pr. million tokens.
Hvis du har oplevet noget lignende — og ud fra foraene er der mange, der har (“Jeg bruger allerede 40 dollars og det bliver ikke engang brugt ret meget,” skrev en bruger) — så gennemgår denne guide hele den audit- og optimeringsproces, jeg brugte til at skære mit månedlige forbrug ned med cirka 90 %. Ikke bare “skift til en billigere model”, men en systematisk gennemgang af, hvor tokens faktisk ryger hen, hvordan du overvåger dem, hvilke budgetmodeller der faktisk holder til reelt agentarbejde, og tre copy-paste-konfigurationer, du kan bruge i dag. Hele processen tog en eftermiddag.
Hvad er OpenClaw tokenforbrug (og hvorfor er det så højt som standard)?
Tokens er den enhed, der faktureres for hver AI-interaktion i OpenClaw. Tænk på dem som små tekstbidder — omtrent 4 engelske tegn per token. Hver besked du sender, hvert svar du får, hver baggrundsproces der kører: alt faktureres i tokens.
Problemet er, at OpenClaws standardopsætning er skruet til maksimal kapacitet, ikke minimal pris. Out of the box er primærmodellen sat til anthropic/claude-opus-4-5 — den dyreste mulighed, der findes. Heartbeat-pings? De kører også på Opus. Sub-agenter, der startes til sideopgaver? Også Opus. At bruge Opus til et heartbeat-ping er lidt som at hyre en neurokirurg til at sætte et plaster på. Teknisk set kompetent, men helt absurd dyrt.
De fleste brugere opdager ikke, at de betaler premiumpriser for trivielle baggrundsopgaver. Standardkonfigurationen antager i praksis, at du vil have den bedste model til alting hele tiden — og den fakturerer derefter.
Hvorfor det at reducere OpenClaw tokenforbrug sparer mere end bare penge
Den åbenlyse gevinst er lavere omkostninger. Men der er også sekundære fordele, som hober sig op over tid.
Billigere modeller er ofte hurtigere. Gemini 2.5 Flash-Lite kører omkring 214 tokens i sekundet mod Opus på omkring 51 — altså en 4x hastighedsforbedring i hver interaktion. GPT-OSS-120B på Cerebras rammer 1,917 tokens i sekundet, hvilket er cirka 35x hurtigere end Opus. I et agent-loop med 50+ tool-calling-runder betyder den forskel, at du bliver færdig på få minutter i stedet for at vente på Opus’ smertefulde 13,6 sekunder til første token i hver rundtur.
Du får også mere luft, før du rammer rate limits, færre throttled sessions og plads til at skalere brugen uden at skalere din angst over regningen.
Forventede besparelser på tværs af forskellige brugsmønstre:
| Brugerprofil | Estimeret månedligt forbrug (standard) | Efter fuld optimering | Månedlig besparelse |
|---|---|---|---|
| Let (~10 forespørgsler/dag) | ~$100 | ~$12 | ~88% |
| Moderat (~50 forespørgsler/dag) | ~$500 | ~$90 | ~82% |
| Tunge brugere (~200+ forespørgsler/dag) | ~$1,750 | ~$220 | ~87% |
Det her er ikke hypotetisk. En udvikler dokumenterede, at han gik fra $600–750/måned ned til $3–4/dag — en reel reduktion på 90 % — ved at kombinere modelrouting med de skjulte læk, der gennemgås senere i denne guide.
Anatomien bag OpenClaw tokenforbrug: Hvor alle tokens faktisk går hen
Det her er den del, de fleste optimeringsguides springer over, og det er den vigtigste del. Du kan ikke fikse det, du ikke kan se.
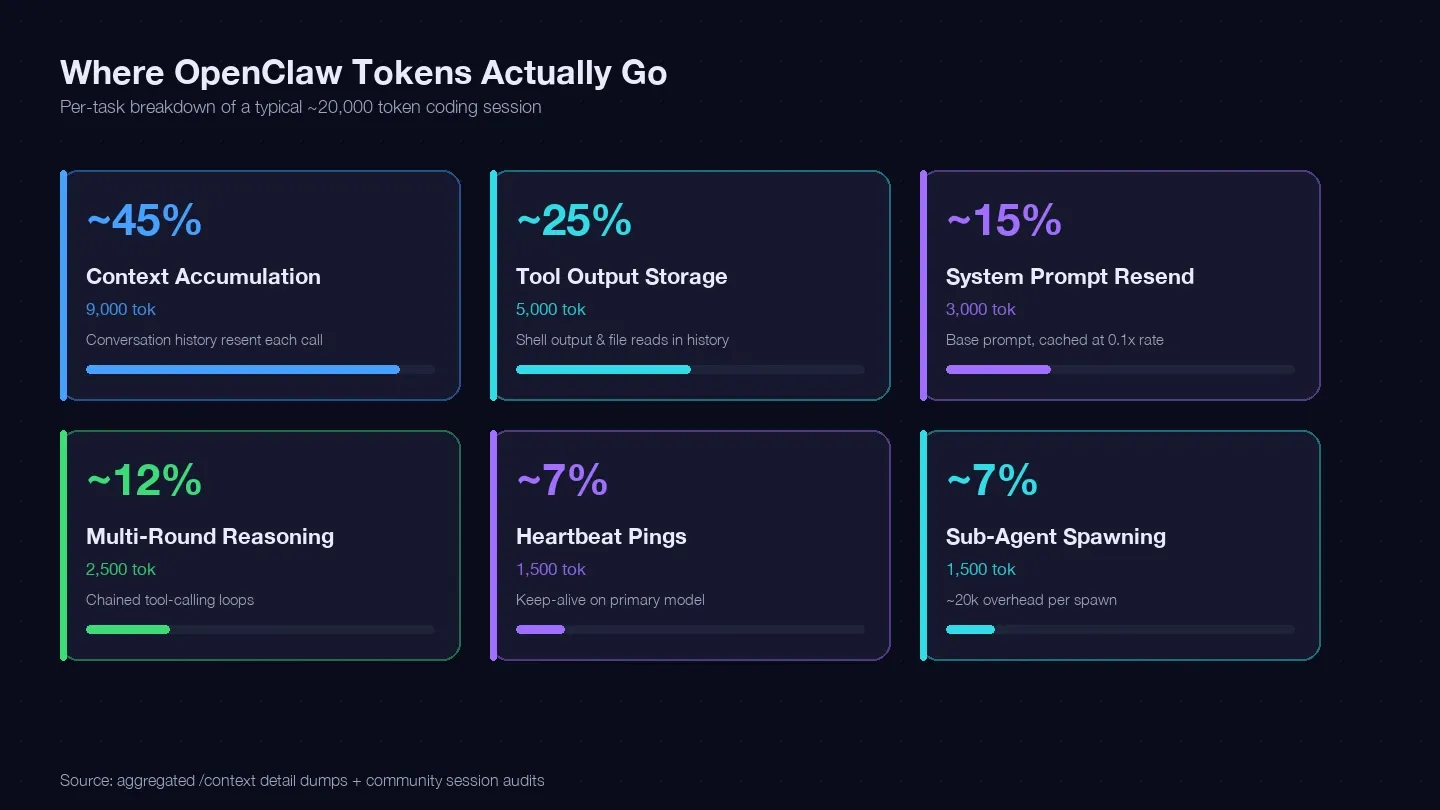
Jeg auditerede flere sessioner og krydstjekkede med LaoZhangs guide til omkostningsoptimering og community-/context-dumps for at bygge et tokenregnskab for en typisk enkelt kodningsopgave. Her er, hvor cirka 20.000 tokens faktisk endte:
| Tokentype | Typisk % af totalen | Eksempel (1 kodningsopgave) | Kan du styre det? |
|---|---|---|---|
| Akkumulering af kontekst (chat-historik sendes igen ved hver kald) | ~40–50% | ~9,000 tokens | Ja — /clear, /compact, kortere sessioner |
| Lagring af tool output (shell-output, filaflæsninger gemt i historik) | ~20–30% | ~5,000 tokens | Ja — mindre aflæsninger, snævrere tool-scope |
| Genafsendelse af system prompt (~15K base) | ~10–15% | ~3,000 tokens | Delvist — cache reads til 0.1x rate |
| Flertrinsræsonnement (kædede tool-calling loops) | ~10–15% | ~2,500 tokens | Modelvalg + bedre prompts |
| Heartbeat / keep-alive pings | ~5–10% | ~1,500 tokens | Ja — konfigurationsændring |
| Sub-agent kald | ~5–10% | ~1,500 tokens | Ja — modelrouting |
Den største enkeltpost — akkumulering af kontekst — er, at din samtalehistorik sendes igen ved hvert API-kald. Et rigtigt session-dump viste 185.400 tokens bare i Messages-bucketen, og modellen havde endnu ikke svaret. System prompten og tools lagde yderligere ~35.800 tokens i fast overhead oveni.
Pointen er: hvis du ikke rydder sessioner mellem urelaterede opgaver, betaler du for at genudsende hele din samtalehistorik ved hver eneste tur.
Sådan overvåger du OpenClaw tokenforbrug (du kan ikke skære det ned, hvis du ikke kan se det)
Før du ændrer noget som helst, skal du have indsigt i, hvor dine tokens forsvinder hen. At hoppe direkte til “brug en billigere model” uden overvågning er som at prøve at tabe sig uden nogensinde at stille sig på en vægt.
Tjek dit OpenRouter-dashboard
Hvis du router gennem OpenRouter, er Activity-siden det letteste dashboard uden opsætning. Du kan filtrere efter model, provider, API-nøgle og tidsperiode. Usage Accounting-visningen fordeler prompt, completion, reasoning og cached tokens på hver forespørgsel. Der er en Export-knap (CSV eller PDF) til længerevarende analyse.
Hvad du skal kigge efter: hvilken model der brugte flest tokens, og om heartbeat- eller sub-agent-forespørgsler dukker op som overraskende store poster.
Gennemgå dine lokale API-logs
OpenClaw gemmer sessionsdata i ~/.openclaw/agents.main/sessions/sessions.json, som indeholder totalTokens pr. session. Du kan også køre openclaw logs --follow --json for realtidslogning per request.
En vigtig detalje: sessions.json totalTokens opdateres ikke efter compaction, så dashboardet kan vise forældede værdier før compaction. Stol mere på /status og /context detail end på de gemte totaler.
Brug tredjepartssporing (til moderate til tunge brugere)
LiteLLM proxy giver dig et OpenAI-kompatibelt endpoint foran 100+ providers og logger automatisk forbrug pr. virtuel nøgle, model, bruger og team. Den stærkeste funktion: hårde budgetter pr. nøgle, som overlever /clear — en løbsk sub-agent kan ikke sprænge en grænse, du har sat.
Helicone er endnu enklere — et base-URL-skift på én linje, som giver dig en Sessions-visning, der grupperer relaterede requests. En enkelt “ret den her bug”-prompt, der spreder sig til 8+ sub-agent kald, vises som én sessionrække med den reelle totalpris. Gratis niveau: 10.000 requests/måned.
Hurtige tjek direkte i OpenClaw
Til daglig overvågning klarer fire in-session kommandoer jobbet:
/status— viser kontekstforbrug, sidste input/output-tokens, estimeret pris/usage full— usage-footer pr. svar/context detail— tokenfordeling pr. fil, pr. skill, pr. tool/compact [guidance]— tvinger compaction med valgfri fokus-tekst
Kør /context detail før og efter, du ændrer konfigurationen. Så kan du måle, om optimeringerne faktisk virkede.
OpenClaw billigste model-showdown: Hvilke budget-LLM’er klarer faktisk agentarbejde?
De fleste guides fejler her. De viser dig en pristabel, peger på den billigste række og kalder det en dag. Benchmarks forudsiger ikke den virkelige agent-ydelse — det har communityet sagt højt og tydeligt igen og igen. Som en bruger formulerede det: “benchmarks fortæller ikke ret meget om, hvilken der fungerer bedst til agentic AI.”
Den vigtige indsigt er: den billigste model er ikke altid det billigste resultat. En model, der fejler og prøver igen fire gange, koster mere end en mellemklassemodel, der lykkes i første forsøg. I produktionssystemer bør du regne med en 5–10 % retry-rate — og hvis fem LLM-kald er kædet sammen, og trin fire fejler, betyder en naiv retry, at alle fem trin køres igen.
Her er min kapabilitetsmatrix med en “Real Agentic Score” baseret på faktiske brugerrapporter i stedet for syntetiske benchmarks:
| Model | Input $/1M | Output $/1M | Pålidelighed ved tool-calling | Flertrinsræsonnement | Real Agentic Score (1–5) | Bedst til |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Blandt — lejlighedsvise loops | Grundlæggende | ⭐2.5 | Heartbeats, simple opslag |
| GPT-OSS-120B | $0.04 | $0.19 | Acceptabel | Acceptabel | ⭐3.0 | Budgeteksperimenter, hastighedskritisk |
| DeepSeek V3.2 | $0.26 | $0.38 | Ustabil (6 åbne issues) | God | ⭐3.0 | Ræsonnementstungt, minimalt tool-calling |
| Kimi K2.5 | $0.38 | $1.72 | God (via :exacto) | Acceptabel | ⭐3.5 | Enkelt til mellemkomplekst kodearbejde |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | God | God | ⭐4.0 | Generel kodning til hverdagsbrug |
| Claude Haiku 4.5 | $1.00 | $5.00 | Fremragende | God | ⭐4.5 | Pålidelig mellemklasse-backup |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Fremragende | Fremragende | ⭐5.0 | Komplekse flertrinsopgaver |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Fremragende | Fremragende | ⭐5.0 | Kun til de sværeste problemer |
En advarsel om DeepSeek og Gemini Flash til tool-calling
DeepSeek V3.2 ser fantastisk ud på papiret — 72–74 % på SWE-Bench, 11–36x billigere end Sonnet. I praksis dokumenterer seks separate GitHub-issues på tværs af Cline, Roo Code, Continue og NVIDIA NIM ødelagt tool-calling-adfærd. Composios head-to-head-dom: “DeepSeek V3.2 byggede dele af appen, men snublede over eksekvering, hastighed og pålidelighed.” Zvi Mowshowitz’ one-liner: “okay and cheap, but”.
Gemini 2.5 Flash har et lignende hul. En tråd i Google AI Developers Forum med titlen “Very frustrating experience with Gemini 2.5 function calling performance” åbner med: “adfærden i funktion-kald hos Gemini-modeller er blevet fuldstændig upålidelig og uforudsigelig.”
OpenRouter pegede på en vigtig nuance: “modellers tilbøjelighed til at kalde tools og nøjagtigheden af de kald kan variere markant på tværs af hosts med samme weights.” Hvis du router billige modeller gennem OpenRouter, så kig efter :exacto-tagget — et stille provider-skift kan forvandle en pålidelig billig model til en dyr retry-loop fra den ene dag til den anden.
Hvornår du skal bruge hvilken model
- Gemini Flash-Lite: Heartbeats, keep-alive pings, simple Q&A. Aldrig til flertrins tool-calling.
- MiniMax M2.5/M2.7: Din daglige model til generelle kodningsopgaver. SWE-Pro 56.22, Terminal-Bench 2 57.0% til en brøkdel af Sonnet-prisen.
- Claude Haiku 4.5: Den pålidelige backup, når billige modeller snubler over tool-calls. Fremragende tool-calling-pålidelighed til ca. 3x lavere pris end Sonnet.
- Claude Sonnet 4.6: Komplekse flertrins agentopgaver. Her får du mest værdi for pengene.
- Claude Opus: Gem den til de allersværeste problemer. Lad den ikke være standard til noget som helst.
(Modelpriser ændrer sig ofte — tjek aktuelle priser på OpenRouter eller direkte hos udbyderen, før du låser en konfiguration fast.)
De skjulte tokenlæk, de fleste guides springer over
Brugere på fora rapporterer, at det at slå bestemte funktioner fra kan reducere omkostningerne drastisk, men ingen guide, jeg har fundet, giver en samlet tjekliste over alle skjulte læk og deres reelle tokenpåvirkning. Her er hele gennemgangen:
| Skjult læk | Tokencost pr. forekomst | Sådan løser du det | Konfigurationsnøgle |
|---|---|---|---|
| Standard-heartbeat på Opus | ~100,000 tokens/kørsel uden isolation | Haiku-override + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Opstart af sub-agenter | ~20,000 tokens pr. spawn før noget arbejde | Rout sub-agents til Haiku | subagents.model |
| Indlæsning af fuld kodebase-kontekst | ~3,000–15,000 tokens pr. auto-explore | .clawignore for node_modules, dist, lockfiles | .clawrules + .clawignore |
| Memory auto-summarize | ~500–2,000 tokens/session | Slå fra eller reducer frekvensen | memory: false eller memory.max_context_tokens |
| Akkumulering af samtalehistorik | ~500+ tokens/turn (kumulativt) | Start nye sessioner mellem urelaterede opgaver | /clear-disciplin |
| MCP-server tool overhead | ~7,000 tokens for 4 servere; 50,000+ for 5+ | Hold MCP minimalt | Fjern ubrugte MCP’er |
| Initialisering af skills/plugins | 200–1,000 tokens pr. indlæst skill | Slå ubrugte skills fra | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7x standard sessionsomkostning | Brug kun til reelt parallelt arbejde | Foretræk sekventielt |
Heartbeat-lækket fortjener sin egen bemærkning. Som standard kører heartbeats på primærmodellen (Opus) hvert 30. minut. Sætter du isolatedSession: true, falder det fra ~100.000 tokens pr. kørsel ned til 2.000–5.000 tokens — en reduktion på 95–98 % på netop den post.
Tre hurtige gevinster, der sparer flest tokens på under to minutter
Alle tre er risikofrie og tager under to minutter:
-
/clearmellem urelaterede opgaver (5 sekunder). Det er den største enkeltstående besparelse. Forum-konsensus vurderer det til 50–70 % reduktion bare ved at rydde sessionhistorik, før du starter nyt arbejde. Husk de 185k tokens i Messages-bucketen fra /context-dumpet?/clearsletter dem. -
/model haiku-4.5til rutinearbejde (10 sekunder). Strategisk modelskift giver 60–80 % lavere omkostninger på rutineopgaver. Haiku klarer de fleste enkle kodeopgaver, filopslag og commit-beskeder uden problemer. -
Skær
.clawrulesned til <200 linjer + tilføj.clawignore(90 sekunder). Din rules-fil indlæses ved hver eneste besked. Ved 200 linjer er det ~1.500–2.000 tokens pr. tur; ved 1.000 linjer er det 8.000–10.000 tokens, som permanent belaster hver request. Kombineret med en.clawignore, der udelukkernode_modules/,dist/, lockfiles og genereret kode, påstår én udvikler at have opnået en 92 % reduktion i tokenforbrug alene gennem denne disciplin.
Trin for trin: Tre færdigkopierbare configs, der skærer OpenClaw tokenforbrug ned

Tre komplette, kommenterede openclaw.json-konfigurationer følger — fra “kom bare i gang” til “fuld optimeringspakke.” Hver inkluderer inline-kommentarer og estimerede månedlige omkostninger.
Før du starter:
- Sværhedsgrad: Begynder (Config A) → Mellem (Config B) → Avanceret (Config C)
- Tidsforbrug: ~5 minutter for Config A, ~15 minutter for Config C
- Det skal du bruge: OpenClaw installeret, en teksteditor, adgang til
~/.openclaw/openclaw.json
Config A: Begynder — bare spar penge
Fem linjer. Nul kompleksitet. Skifter standardmodellen fra Opus til Sonnet, slår memory-overhead fra og isolerer heartbeats til Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // var Opus — øjeblikkelig 3-5x besparelse
"heartbeat": {
"every": "55m", // matcher 1 time cache-TTL for maksimal cache-hit
"model": "anthropic/claude-haiku-4-5", // Haiku til pings, ikke Opus
"isolatedSession": true // ~100k → 2-5k tokens pr. kørsel
}
}
},
"memory": { "enabled": false } // sparer ~500-2k tokens/session
}
Det bør du se efter at have anvendt dette: Kør /status før og efter. Din pris pr. request bør falde tydeligt, og heartbeat-poster i OpenRouter Activity-siden bør vise Haiku i stedet for Opus.
| Forbrugsniveau | Standard (Opus) | Config A (Sonnet + Haiku-heartbeats) | Besparelse |
|---|---|---|---|
| Let (~10 q/dag) | ~$100 | ~$35 | 65% |
| Moderat (~50 q/dag) | ~$500 | ~$250 | 50% |
| Tung (~200 q/dag) | ~$1,750 | ~$900 | 49% |
Config B: Mellem — smart trelags-routing
Primær Sonnet til reelt arbejde. Haiku til sub-agenter og compaction. Gemini Flash-Lite som budget-fallback, når Claude er throttled. Fallback-kæder håndterer automatisk provider-afbrydelser.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // hvis Sonnet er throttled
"google/gemini-2.5-flash-lite" // ultra-billig sidste udvej
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 min < 1h cache-TTL = cache-hits
"model": "google/gemini-2.5-flash-lite", // øre pr. ping
"isolatedSession": true,
"lightContext": true // minimal kontekst i heartbeat-kald
},
"subagents": {
"maxConcurrent": 4, // ned fra standard 8
"model": "anthropic/claude-haiku-4-5" // sub-agenter behøver ikke Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // compaction-sammenfatninger via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Forventet resultat: Sub-agent-poster i dine logs bør nu vise Haiku-priser. Heartbeats bør koste næsten ingenting. Din fallback-kæde betyder, at et Claude-udfald ikke stopper din session — den nedgraderer elegant til Gemini.
| Forbrugsniveau | Standard | Config B | Besparelse |
|---|---|---|---|
| Let | ~$100 | ~$20 | 80% |
| Moderat | ~$500 | ~$150 | 70% |
| Tung | ~$1,750 | ~$500 | 71% |
Config C: Power user — fuld optimeringspakke
Per-sub-agent modeltildeling, kontekst-compaction låst til Haiku, vision-routing til Gemini Flash, stramme .clawrules + .clawignore, og ubrugte skills slået fra. Det er denne config, der får dig ned i 85–90 % besparelsesområdet.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // anden provider som backup
"minimax/minimax-m2-7", // billig daglig fallback
"anthropic/claude-haiku-4-5" // sidste udvej
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // ingen heartbeats om natten
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // ned fra standard 20000
"imageModel": "google/gemini-3-flash" // vision-opgaver via billig model
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // minimal memory
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Eksempel på override pr. sub-agent — indsæt i ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Kører lint/format-tjek og laver trivielle rettelser
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
Minimums- .clawignore — den her alene skærer typiske bootstraps fra 150k tegn ned mod 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Forbrugsniveau | Standard | Config C | Besparelse |
|---|---|---|---|
| Let | ~$100 | ~$12 | 88% |
| Moderat | ~$500 | ~$90 | 82% |
| Tung | ~$1,750 | ~$220 | 87% |
Disse tal matcher to uafhængige rapporter fra rigtige brugere: Praney Behl dokumenterede $600–750/md → $3–4/dag (90 % reduktion), og LaoZhang-case studies viste $943 → $347 (63 %), $1,750 → $1,000 (64 %), $200 → $70 (65 %) med delvis optimering.
Brug /model-kommandoen til at styre OpenClaw tokenforbrug i farten
/model-kommandoen skifter den aktive model til næste tur, mens den bevarer din samtalekontekst — ingen reset, ingen tabt historik. Det er den daglige vane, der over tid giver større og større besparelser.
Praktisk workflow:
- Arbejder du på en rodet refaktorering med mange filer? Bliv på Sonnet.
- Hurtigt spørgsmål som “hvad gør den her regex?”?
/model haiku, spørg, og skift derefter tilbage med/model sonnet. - Commit-besked eller sproglig finpudsning af dokumentation?
/model flash-lite, færdig.
Du kan oprette aliases i openclaw.json under commands.aliases og mappe korte navne (haiku, sonnet, opus, flash) til de fulde provider-strenge. Det sparer et par tastetryk ved hvert skift.
Regnestykket: 50 forespørgsler/dag på Sonnet er cirka $3/dag. De samme 50 forespørgsler fordelt 70/20/10 på Haiku/Sonnet/Opus er omkring $1.10/dag. Over en måned er det $90 → $33 — 63 % billigere uden at ændre værktøjer, kun vaner.
Bonus: Spor OpenClaw modelpriser på tværs af providers med Thunderbit
Spor modelpriser på tværs af providers med AI Get Started Free
Med så mange modeller og providers — OpenRouter, direkte Anthropic API, Google AI Studio, DeepSeek, MiniMax — ændrer priserne sig ofte. Anthropic skar Opus output-prisen ned med ~67 % fra den ene dag til den anden. Google trimmede Gemini free-tier-grænserne 50–80 % i december 2025. At holde et statisk prisark opdateret manuelt er en tabt kamp.
Thunderbit løser det uden noget scraping-kode. Det er en AI web scraper Chrome-udvidelse, der er bygget præcis til den slags struktureret dataudtræk.
Det workflow, jeg bruger:
- Åbn OpenRouter-modelsiden i Chrome og klik på Thunderbits “AI Suggest Fields”. Den læser siden og foreslår kolonner — modelnavn, inputpris, outputpris, kontekstvindue, provider.
- Tryk Scrape, og eksporter direkte til Google Sheets.
- Opsæt et planlagt scrape i almindeligt sprog — “hver mandag kl. 9, gen-scrape OpenRouter-modellisten” — og så kører det automatisk i skyen.
Derefter opdaterer din personlige pristracker sig selv. Enhver model, der pludselig bliver 30 % billigere — eller enhver provider, der får et Exacto-tag — dukker op i dit Monday-morgen-regneark uden, at du løfter en finger. Vi har skrevet mere om AI data extraction til business-use cases på vores blog.
Sammenligner du priser på tværs af direkte provider-sider (Anthropic, Google, DeepSeek)? Thunderbits subpage scraping følger hvert model-link ind på detaljesiden og trækker priser pr. provider ud — nyttigt, når du vil vide, om det er billigere at route Kimi K2.5 gennem OpenRouter end at gå direkte via NVIDIA Build. Tjek Thunderbit-priser for gratis niveau og plan-detaljer.
Vigtigste pointer til at skære OpenClaw tokenforbrug ned
Rammen er: Forstå → Overvåg → Ruter → Optimer.
De vigtigste handlinger, rangeret:
- Brug ikke Opus som standard. Skift primærmodel til Sonnet eller MiniMax M2.7. Det alene giver en 3–5x reduktion i omkostninger.
- Isolér heartbeats. Sæt
isolatedSession: trueog route heartbeats til Gemini Flash-Lite. Det forvandler en ~100k token-læk til ~2–5k. - Route sub-agenter til Haiku. Hver spawn indlæser ~20k tokens i kontekst, før der udføres noget arbejde. Lad ikke det ske på Opus.
- Brug
/clearkonsekvent. Gratis, tager 5 sekunder, og communityet er enige om, at det sparer mere end nogen anden enkelt handling. - Tilføj
.clawignore. Ved at udeladenode_modules, lockfiles og build-artifacts skærer du bootstrapping-kontekst markant ned. - Overvåg med
/context detailfør og efter ændringer. Hvis du ikke kan måle det, kan du ikke forbedre det.
Den billigste model afhænger af opgaven. Gemini Flash-Lite til heartbeats. MiniMax M2.7 til daglig kodning. Haiku til pålidelig tool-calling. Sonnet til komplekse flertrinsopgaver. Opus til de reelt svære problemer — og intet andet.
De fleste læsere kan nå 50–70 % besparelse på en enkelt eftermiddag med Config A eller B. De fulde 85–90 % kræver, at du lægger det hele ovenpå hinanden — modelrouting, fixes af skjulte læk, .clawignore, disciplin med sessioner — men det kan lade sig gøre, og det holder.
FAQ
1. Hvad koster OpenClaw pr. måned?
Det afhænger helt af din konfiguration, dit forbrug og dine modelvalg. Lettere brugere (~10 forespørgsler/dag) bruger typisk $5–30/md med optimering, eller $100+ med standardindstillinger. Moderate brugere (~50 forespørgsler/dag) ligger på $90–400/md. Tunge brugere kan ramme $600–2,000+/md med standardopsætningen — et dokumenteret ekstremt eksempel var $5,623 på én måned. Anthropics egne interne data peger på et medianforbrug på $13/udvikler/aktiv-dag.
2. Hvad er den billigste OpenClaw-model, der stadig fungerer godt til kodning?
MiniMax M2.5/M2.7 er den bedste generelle hverdagsmodel — god tool-calling-pålidelighed, SWE-Pro 56.22, til cirka $0.28/$1.10 pr. million tokens. Til heartbeats og simple opslag er Gemini 2.5 Flash-Lite til $0.10/$0.40 svær at slå. Claude Haiku 4.5 til $1/$5 er den pålidelige mellemklasse-backup, når du har brug for fremragende tool-calling uden at betale Sonnet-priser.
3. Kan jeg bruge modeller på gratis niveau med OpenClaw?
Teknisk set ja. GPT-OSS-120B er gratis via OpenRouters :free-tag og NVIDIA Build. Gemini Flash-Lite har en gratis tier (15 RPM, 1.000 requests/dag). DeepSeek giver 5M gratis tokens ved tilmelding. Men gratis tiers har aggressive rate limits, lavere hastighed og ustabil tilgængelighed. Billige betalte modeller — øre pr. million tokens — er langt mere driftssikre til almindelig brug.
4. Mister jeg min kontekst, hvis jeg skifter model midt i en samtale med /model?
Nej. /model bevarer hele din sessionkontekst — næste tur routes til den nye model med hele historikken intakt. Det er bekræftet i OpenClaws concepts-dokumentation og fungerer på samme måde i Claude Code. Du kan frit hoppe mellem Haiku til hurtige spørgsmål og Sonnet til komplekst arbejde uden at miste noget.
5. Hvad er den hurtigste måde at sænke min OpenClaw-regning på i dag?
Skriv /clear mellem urelaterede opgaver. Det er gratis, tager fem sekunder og sletter den samtalehistorik, der bliver gen-send på hvert API-kald. En rigtig session viste 185.000 tokens i akkumuleret beskedhistorik — alt sammen blev sendt og faktureret igen ved hver eneste tur. At rydde det, før du starter nyt arbejde, er den vane med højest afkast, du kan bygge.
Prøv Thunderbit til AI web scraping Get Started Free




