

At optimere Apollo-listeforespørgsler er ikke bare en teknisk øvelse — det er en overlevelseskompetence for alle, der er afhængige af realtidsnyheder, automatiseret nyhedsudtræk eller højhastigheds-workflows inden for salg og drift. Jeg har selv set, hvordan en langsom listeforespørgsel kan forvandle et elegant dashboard til en flaskehals, hvor salgsteams sidder og glor på en spinner, mens driftsfolk febrilsk finder nødløsninger i regneark. I en verden hvor 60% af sælgeres tid allerede går tabt til opgaver, der ikke skaber salg, tæller hvert millisekund.
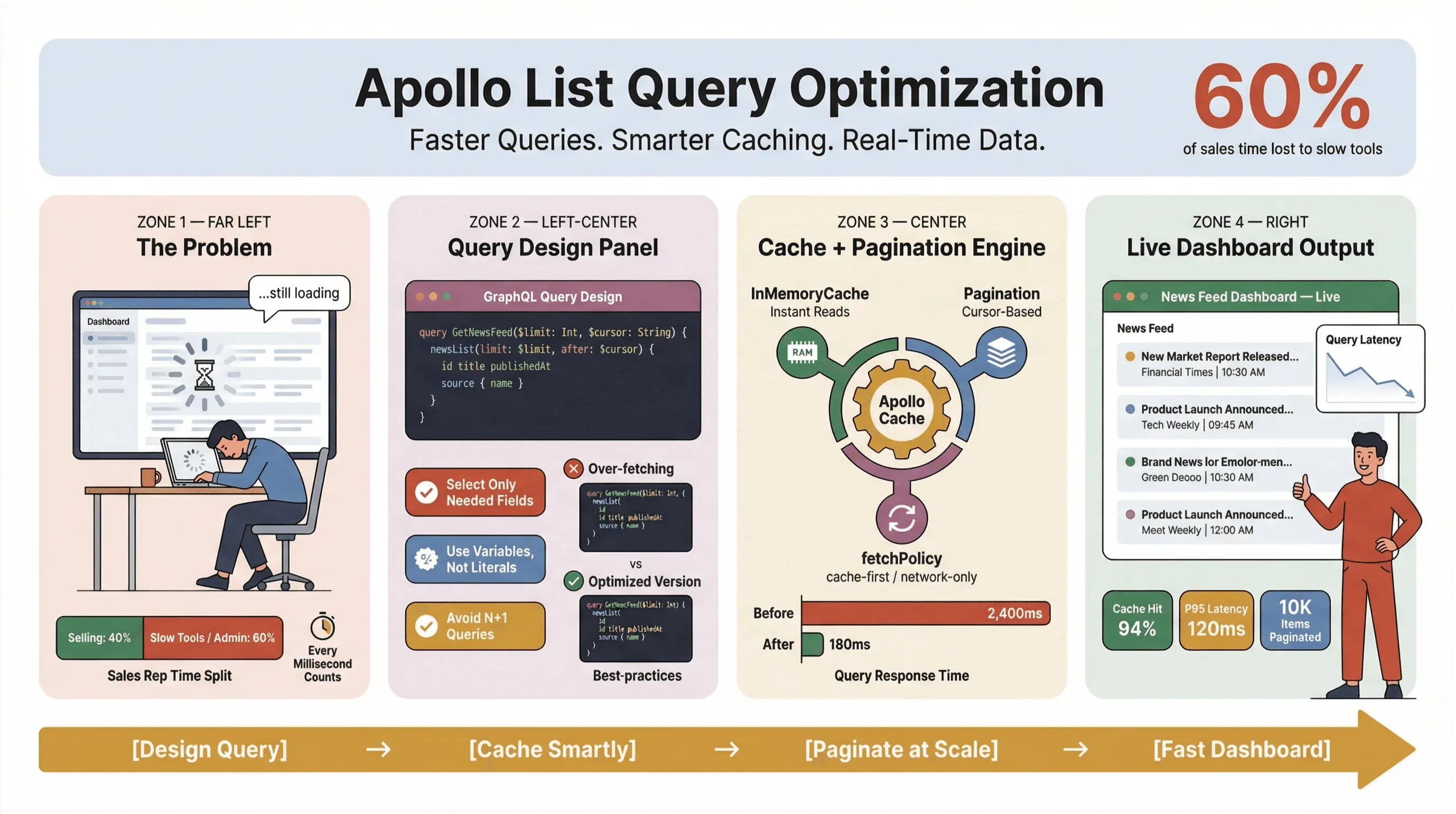
Så hvordan holder man Apollo Client-listeforespørgsler hurtige, stabile og konsistente i stor skala — især når man scraper nyheder, følger leads eller driver forretningskritiske dashboards? I denne guide gennemgår jeg de metoder, der holder i produktion: forespørgselsdesign, caching, paginering og integration af no-code-værktøjer som Thunderbit til at automatisere det tunge arbejde med nyhedsudtræk.
--- Uanset om du er udvikler, produktchef eller bare den person, alle giver skylden, når dashboardet er langsomt, er dette din playbook til Apollo GraphQL-listeperformance.
Prøv Thunderbit til automatiseret nyhedsudtræk
Hvorfor optimere Apollo-listeforespørgsler? (apollo client listeperformance, optimer apollo-listeforespørgsler)
Lad os være ærlige: ingen gider vente på nyhedsoverskrifter eller salgsleads. I forretningsmiljøer — især dem, der bygger på automatiseret nyhedsudtræk eller realtidsdata — er langsomme Apollo-listeforespørgsler ikke bare irriterende; de koster penge, forsinker beslutninger og sender folk tilbage til manuelt arbejde. Gentagne undersøgelser fra Slack Workforce Lab har konsekvent vist, at kontorarbejdere bruger omkring en tredjedel — og i nyere rapporter tættere på 40% — af deres arbejdsdag på lavværdige, gentagne opgaver, ofte fordi deres værktøjer splitter arbejdet op på langsomme flader.
Her er, hvad der sker, når listeforespørgsler ikke er optimerede:
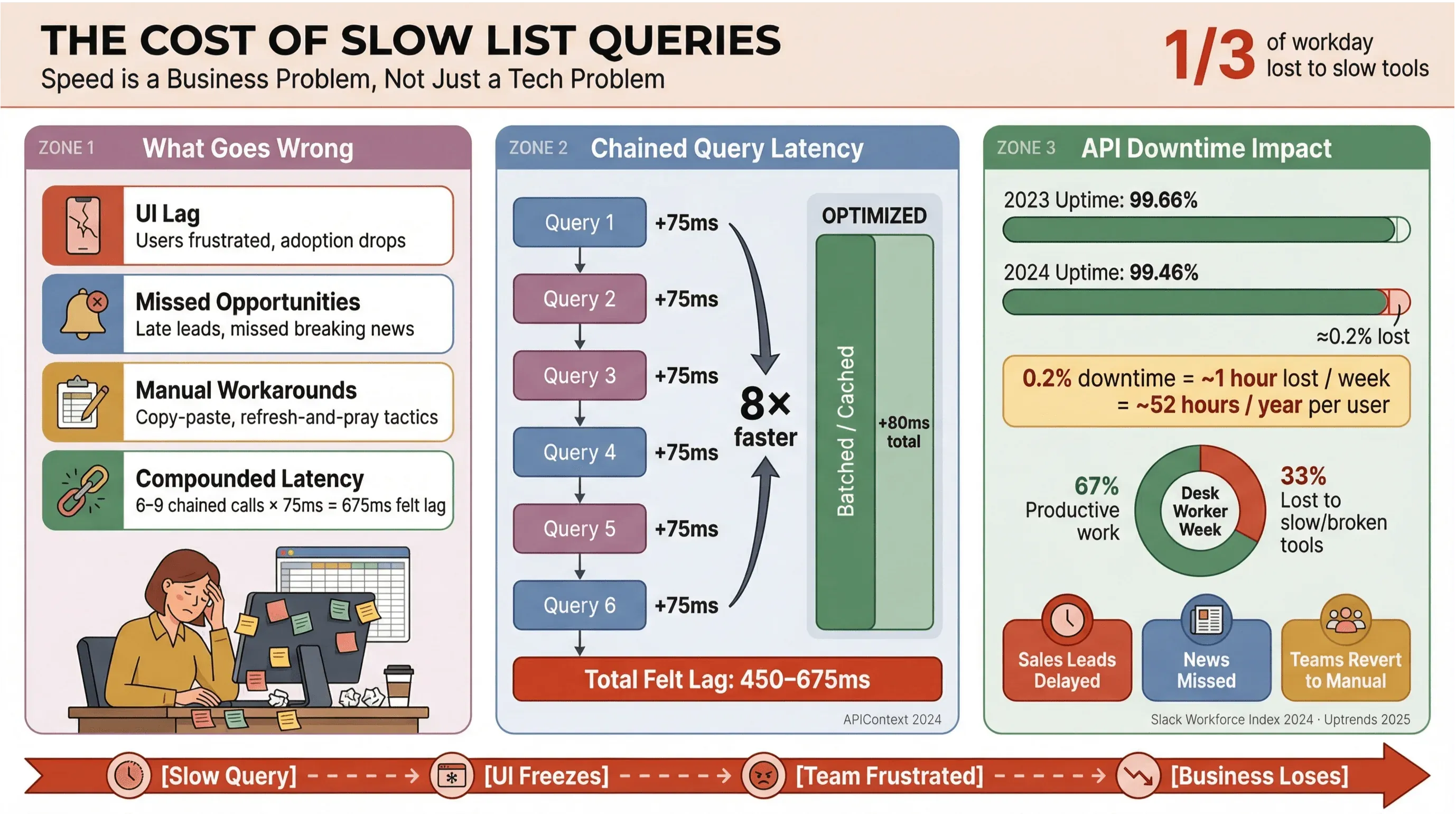
- UI-forsinkelse: Brugere oplever ventetid, hvilket skaber frustration og lavere adoption.
- Mistede muligheder: I salg eller nyhedsovervågning kan selv få sekunders forsinkelse betyde, at man går glip af et varmt lead eller en vigtig nyhed.
- Manuelle nødløsninger: Teams falder tilbage på copy-paste, regneark eller “opdatér og håb på det bedste”.
- Akkumuleret latenstid: Hvert langsomt API-kald lægger sig oven i det næste — hvis dit workflow udløser 6–9 afhængige forespørgsler, kan en beskeden 75 ms forsinkelse pr. kald vokse til en oplevet forsinkelse på 450–675 ms (APIContext).
Og det handler ikke kun om fart. API-nedetid er stigende, og gennemsnitlig oppetid er faldet fra 99,66% til 99,46% på bare ét år — hvilket svarer til næsten en times tabt produktivitet om ugen for apps med mange lister. Når din forretning er afhængig af realtidsnyheder, er det en risiko, du ikke kan ignorere.
Vælg den rigtige datastruktur og de rigtige felter (apollo graphql liste bedste praksis)
En af de mest almindelige fejl, jeg ser (og ja, jeg har selv lavet den), er at behandle alle listeforespørgsler som detaljeforespørgsler. I GraphQL kan du hente præcis det, du har brug for — så brug den mulighed. Overhentning er performance-fjenden, især i nyhedsscraping-værktøjer og realtid-dashboards.
Tilpas felterne til automatiseret nyhedsudtræk
Lad os sige, at du bygger et nyhedsfeed. Har du virkelig brug for hele artikelteksten, alle tags, kommentarer og forfatterbios i din listeforespørgsel? Sandsynligvis ikke. Her er forskellen:
Effektiv listeforespørgsel:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Ineffektiv listeforespørgsel (lad være med det her):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Den første forespørgsel er slank og effektiv — perfekt til rangering, filtrering og rendering af rækker. Den anden? Det er i virkeligheden en detaljeforespørgsel forklædt som liste, som trækker enorme datamængder ind og bremser alt ned (GraphQL-specifikation, Apollo best practices).
Pro tip: Brug en todelt model — hent kun lette felter i listen, og indlæs tunge detaljer (som fuld tekst eller NLP-berigelse) først når brugeren åbner et element eller holder musen over det.
Udnyt Apollo Client-cache til hurtigere forespørgsler (apollo client listeperformance)
Apollo Client-cachen er det stærkeste værktøj, du har til listeperformance. Når den er sat rigtigt op, kan den hjælpe dig med at:
- Svare på gentagne forespørgsler med det samme (uden netværkskald)
- Reducere serverbelastning og API-omkostninger
- Skabe gnidningsfri frem/tilbage-navigation og filterændringer
Men caching er ikke magi — det kræver lidt opsætning og disciplin.
Sæt effektive cache-politikker op
Apollo understøtter flere fetch policies:
| Politik | Hvad den gør | Bedste brugsscenarie til nyhedslister |
|---|---|---|
| cache-first | Læser fra cache og henter fra netværket, hvis noget mangler | Genbesøgte lister, filterskift, frem/tilbage-navigation |
| network-only | Henter altid fra netværket | Manuel opdatering, “seneste overskrifter” |
| cache-and-network | Returnerer cache først og opdaterer derefter med netværkssvar | Hurtig første rendering + baggrundsopdatering (god til nyhedsfeeds) |
| no-cache | Henter altid, gemmer aldrig i cache | Engangsforespørgsler med følsomme data (sjældent til lister) |
Til realtidsnyhedsdata kan jeg godt lide cache-and-network — det giver brugeren et øjeblikkeligt resultat og opdaterer derefter i baggrunden. Vær bare opmærksom på UI-flimmer, hvis data bliver omrokeret ved opdatering (GitHub issue).
Tips til cache-konfiguration:
- Brug stabile IDs (
ideller_id) til normalisering (Apollo cache docs). - Justér cachestørrelse og garbage collection til store lister (memory management).
- Undgå at gemme store, unormaliserede blobs under
ROOT_QUERY— det kan få appen til at hænge (community report).
Implementér paginering og begræns antal elementer (apollo graphql liste bedste praksis)
Hvis du indlæser hundredvis eller tusindvis af nyhedsartikler eller salgsleads på én gang, beder du om problemer. Paginering er ikke bare en UX-funktion — det er en performance-nødvendighed.
Apollo understøtter både offset-baseret og cursor-baseret paginering. Sådan ser de ud i forhold til hinanden:
| Pagineringstype | Fordele | Ulemper | Bedst til |
|---|---|---|---|
| Offset-baseret | Simpel, let at implementere | Kan springe over eller duplikere elementer, hvis data ændrer sig | Uforanderlige eller små lister |
| Cursor-baseret | Stabil, håndterer dataskift bedre | Lidt mere kompleks | Nyhedsfeeds, store lister |
For de fleste realtidsnyheder eller lead-lister er cursor-baseret paginering vejen frem. Den holder data konsistent, selv når nye elementer kommer til, eller gamle bliver slettet (GraphQL Foundation).
Apollo-tips til paginering:
- Konfigurer
keyArgsfor at styre cache-nøgler til paginerede felter (docs). - Implementér en
merge-funktion til at samle sider i cachen. - Brug
fetchMoretil at indlæse flere sider uden at overskrive tidligere resultater.
Praktiske pagineringsmønstre til nyhedsscraping-værktøjer
En typisk UI til nyhedsscraping vil:
- Vise de seneste 20–50 overskrifter (kun lette felter)
- Indlæse mere ved scroll eller klik på “næste side”
- Hente detaljer først, når de er nødvendige
Det holder din UI hurtig, din API glad og dine brugere produktive.
Integrér Thunderbit til automatiseret nyhedsudtræk
Lad os nu tale om elefanten i rummet: hvor kommer alle de strukturerede nyhedsdata egentlig fra? Det er her, Thunderbit kommer ind.
Få Thunderbit Chrome-udvidelsen Get Started Free
Thunderbit er en no-code AI web scraper Chrome-udvidelse, som kan udtrække nyhedsoverskrifter, URLs, kilder, forfattere, udgivelsesdatoer, resuméer og billeder fra stort set enhver hjemmeside — helt uden kodning. Jeg har set teams bruge Thunderbit til at automatisere hele nyhedsudtræksprocessen og omdanne ustrukturerede websider til rene, strukturerede data, der kan sendes direkte ind i en database eller GraphQL API.
Kombinér Thunderbit med Apollo til realtidsnyhedsdata
Her er et workflow, jeg godt kan lide til salgs- og drifts teams, der har brug for opdaterede nyheder:
- Udtrækslag: Brug Thunderbits News Scraper template til at hente strukturerede nyhedsdata fra udvalgte sites efter en fast tidsplan.
- Lagringslag: Gem de scrape-de data i en database, der er optimeret til hurtig genfindelse.
- GraphQL-lag: Eksponér et
newsFeed-listefelt og etnewsArticle(id)-detailfelt via din API. - Klientlag: Brug Apollo Client til at hente listen (lette felter, pagineret) og kun hente detaljer, når det er nødvendigt.
Denne “scrape → gem → forespørg”-pipeline betyder, at dine Apollo-forespørgsler altid arbejder med friske, strukturerede data — uden manuel copy-paste eller skrøbelige scripts.
Bonus: Thunderbit kan også berige dine lister med ekstra felter (som sentiment eller kategori) via AI-drevne feltforslag, så dit nyhedsfeed bliver endnu klogere.
Trin-for-trin-guide: Optimering af Apollo-listeforespørgsler
Klar til at omsætte det til praksis? Her er min faste tjekliste til optimering af Apollo-listeforespørgsler:
-
Skær dine forespørgsler ned
- Bed kun om de felter, der er nødvendige for at gengive listen (titel, URL, tidsstempel osv.).
- Flyt tunge felter (fuld tekst, billeder, berigelse) over i detailforespørgsler.
-
Implementér paginering
- Brug cursor-baseret paginering til store eller dynamiske lister.
- Konfigurer
keyArgsogmerge-funktioner for korrekt cacheadfærd.
-
Udnyt Apollo-cachen
- Normalisér entiteter med stabile IDs.
- Vælg den rigtige fetch policy (
cache-and-networker stærk til nyheder). - Justér cachestørrelse og garbage collection efter datamængden.
-
Integrér automatiseret udtræk
- Brug Thunderbit til at automatisere nyhedsscraping og holde data friske.
- Eksportér strukturerede data direkte til din database eller dit regneark.
-
Overvåg og fejlfind
- Brug Apollo Client Devtools til at inspicere forespørgsler, cache og performance.
- Hold øje med store cache-skrivninger, for mange overvågede forespørgsler og UI-ryk.
- Følg p95/p99-latenstid og fejlrater (New Relic, Uptrends).
Overvågning og fejlfinding af forespørgselsperformance
Apollo’s Devtools er en kæmpe hjælp her. Du kan:
- Inspicere aktive forespørgsler og cache-status
- Opdage dublerede forespørgsler eller for mange watchers
- Identificere store cache-blobs eller problemer med normalisering
Hvis du ser UI-forsinkelse eller langsomme opdateringer, så kig efter:
- For store listeforespørgsler (skær dem ned)
- Dårlig cache-normalisering (ret dine IDs)
- Problemer med paginerings-merge (gennemgå
keyArgsogmerge)
Og glem ikke at måle tail latency — ikke kun gennemsnit. Det er dér, de virkelige brugerproblemer gemmer sig.
Sammenligning af traditionelle og AI-drevne tilgange til nyhedsscraping
Lad os være ærlige: før i tiden betød scraping af nyhedsdata, at man skulle skrive egne scripts, håndtere headless-browsere og krydse fingre for, at sidens layout ikke ændrede sig natten over. I dag kan du med AI-drevne værktøjer som Thunderbit automatisere hele processen — uden kode og uden drama.
| Tilgang | Styrker | Begrænsninger for erhvervsbrugere |
|---|---|---|
| Scripted scraping | Fuld kontrol, billig i stor skala | Kræver vedligeholdelse og udviklingstid |
| Administrerede scrapingplatforme | Hurtig opstart, håndterer anti-bot | Kræver stadig opsætning, omkostninger vokser med brug |
| AI-drevet udtræk (Thunderbit) | Klarer uensartede layouts, kræver ingen kode | Output skal kvalitetssikres og tilpasses dit skema |
| Visuelle no-code scrapers | Tilgængeligt for ikke-udviklere | Kan bryde ved UI-ændringer, begrænset skala |
| Proxy-/unlocker-infrastruktur | Omgår blokeringer, understøtter høj throughput | Kræver stadig udtrækslogik, compliance-risici |
Juridisk note: Det er som udgangspunkt lovligt at scrape offentlige data, men respekter altid vilkår for brug og rate limits (Reuters).
Vigtige takeaways til Apollo GraphQL-liste best practices
Lad os samle de vigtigste pointer:
- Optimér for hastighed og klarhed: Skær listeforespørgsler ned, paginér og cache aggressivt.
- Struktur betyder noget: Hent kun det, du har brug for — flyt tunge felter til detailforespørgsler.
- Cachen er din ven: Brug Apollo-normalisering og fetch policies til at levere data med det samme.
- Automatisér udtræk: Værktøjer som Thunderbit gør nyhedsscraping og berigelse af lister tilgængeligt for alle.
- Overvåg og justér: Brug Devtools og observability-dashboards til at fange flaskehalse tidligt.
For salgs-, drifts- og nyhedsteams betyder disse best practices mindre ventetid, mere tid til handling — og langt færre “hvorfor er det her så langsomt?”-beskeder i Slack.
Konklusion: Næste skridt til at optimere dine Apollo-lister
Hvis du stadig kører tunge, ikke-paginerede eller cache-uhensigtsmæssige listeforespørgsler, er det nu, du skal gennemgå dem og opgradere. Start småt: trim dine felter, tilføj paginering og finjustér cachen. Tag derefter næste skridt ved at integrere automatiserede udtræksværktøjer som Thunderbit for at holde dine data friske og handlingsklare.
Vil du dykke dybere? Se Apollo docs, Thunderbit Blog eller bliv en del af Apollo Community for praktiske tips og fejlfinding. Og hvis du er klar til at automatisere dit nyhedsudtræk, så prøv Thunderbits News Scraper template — det er en gamechanger for alle, der har brug for realtidsdata uden besvær.
Brug Thunderbits News Scraper-skabelon
Hvis du ikke gør andet efter at have læst dette: skær ned på feltudvælgelsen i dine listeforespørgsler, tilføj cursor-baseret paginering, og vælg en fornuftig fetch policy. Bare de tre ændringer flytter som regel en listeforespørgsel fra “mærkbar” forsinkelse til “næsten usynlig” — og frigør dig til at fokusere på dataene, ikke indlæsningsindikatoren.
Ofte stillede spørgsmål
1. Hvorfor bliver Apollo-listeforespørgsler langsomme i realtidsnyheds- eller salgsdashboards?
Listeforespørgsler kan blive langsomme, hvis de henter for mange data, mangler paginering eller ikke er ordentligt cachet. I workflows med høj frekvens, som nyhedsovervågning, vokser selv små forsinkelser hurtigt og fører til UI-forsinkelse og tabt produktivitet.
2. Hvad er den bedste måde at strukturere Apollo-listeforespørgsler til automatiseret nyhedsudtræk?
Bed kun om de felter, du skal bruge for at vise listen (fx titel, URL, tidsstempel). Flyt tunge felter som fuld artikeltekst eller billeder over i detailforespørgsler, og paginér resultaterne, så payloads forbliver små og hurtige.
3. Hvordan forbedrer Apollo Clients cache listeperformance?
Apollo-cachen gemmer tidligere hentede data, så gentagne forespørgsler kan besvares med det samme. Korrekt cache-normalisering og fetch policies (som cache-and-network) kan gøre listevisninger markant hurtigere og reducere serverbelastningen.
4. Hvordan kan Thunderbit hjælpe med nyhedsscraping og Apollo-integration?
Thunderbit er en no-code AI web scraper, der udtrækker strukturerede nyhedsdata fra enhver hjemmeside. Du kan bruge den til at automatisere nyhedsudtræk og derefter sende dataene videre til din database eller GraphQL API til brug med Apollo Client.
5. Hvilke værktøjer kan jeg bruge til at overvåge og fejlfinde Apollo-listeforespørgselsperformance?
Apollo Client Devtools lader dig inspicere forespørgsler, cache-status og performance i realtid. Kombinér det med observability-dashboards som New Relic eller Uptrends for at følge latenstid og fejlrater og justér dit forespørgselsdesign for de bedste resultater.
Vil du have flere tips om webscraping, automatisering og realtidsdata-workflows? Tjek Thunderbit Blog for dybdegående guides, tutorials og det nyeste inden for AI-drevet produktivitet.
Prøv Thunderbit AI Web Scraper Get Started Free
Læs mere
- Sådan optimerer du Apollo-lister til effektiv leadhåndtering
- Apollo Data Enrichment: Funktioner, fordele og et AI-boost
- Sådan mestrer du Apollo-prospecting: En trin-for-trin-guide
- Sådan bruger du webscraper-paginering til effektiv udtrækning
- Sådan bruger du webscraper-paginering til effektiv udtrækning




