Der foregår en stille revolution på kontorer overalt – og den handler hverken om bordtennis eller kombucha på fad. Den handler om fremkomsten af “nem webudtræk”: at alle, ikke kun udviklere, kan hente brugbare data fra nettet på minutter i stedet for dage. Hvis du nogensinde har siddet og kigget på en hjemmeside og tænkt, at du bare ville nappe alle navnene, priserne eller e-mails og smide dem direkte i et regneark, så er du langt fra alene. Jeg har talt med sælgere, marketingfolk og driftsteams, der siger det samme: “Hvorfor er det stadig så bøvlet?”
Sandheden er, at behovet for enkle metoder til web scraping eksploderer. Ifølge bruger 65% af organisationer nu generativ AI i mindst én forretningsfunktion, og udtræk af webdata er lynhurtigt ved at blive en af de mest efterspurgte use cases. Markedet for web scraping forventes at ramme , og forretningsbrugere – især dem uden teknisk baggrund – skubber for alvor på efter værktøjer, der gør dataudtræk lige så nemt som copy-paste. Men hvad betyder “nem webudtræk” egentlig, og hvordan kan du bruge det til at gøre din arbejdsgang mere smooth? Lad os tage den fra toppen.
Nem webudtræk for ikke-tekniske brugere: Nul kode, nul hovedpine
Lad os starte helt basic: Hvad er “nem webudtræk”? Kort sagt handler det om at forvandle rodet, konstant skiftende webindhold til rene, strukturerede tabeller – uden at skrive en eneste linje kode. For ikke-tekniske forretningsbrugere er det en kæmpe gamechanger. Ingen flere “kan IT lige…?”-forespørgsler, ingen kamp med Python-scripts, og ingen opgivelse, når en hjemmeside ændrer layout fra den ene dag til den anden.
Hvorfor er det så vigtigt lige nu? Fordi nettet er mere dynamisk end nogensinde. Hjemmesider kører med uendelig scroll, pop-ups og tung JavaScript, som får klassiske scrapers til at knække igen og igen. Samtidig er presset på forretningsteams for at levere indsigter – hurtigt – større end nogensinde. I siger 98% af organisationer, at offentlige webdata er afgørende eller meget vigtige for deres drift, og over halvdelen bruger dem dagligt.
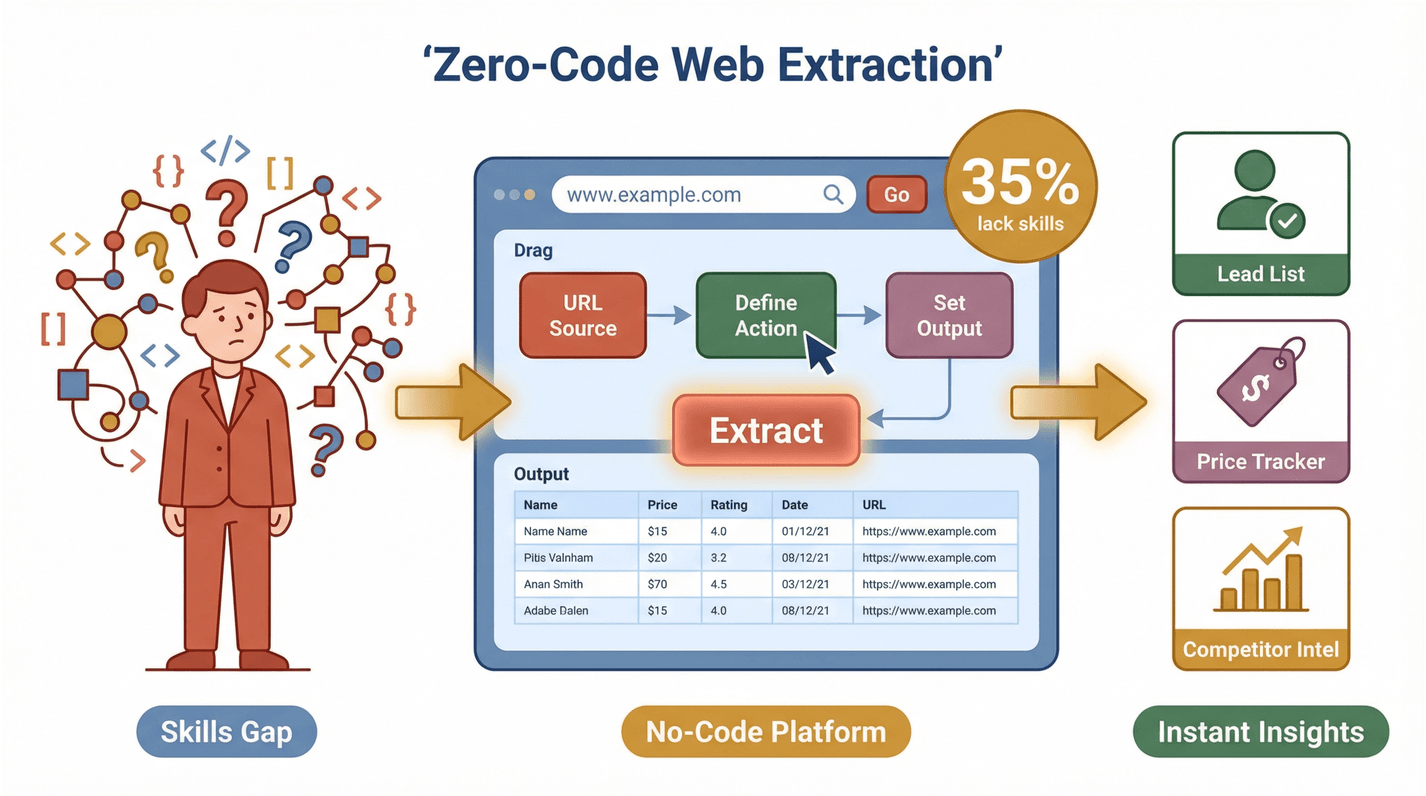
Men her er pointen: de fleste af de her teams er ikke tekniske. En nyere undersøgelse viste, at 35% af organisationer mangler de rette kompetencer til webdataudtræk, og 33% mangler de rette værktøjer. Det er en kæmpe åbning for no-code-løsninger. Når alle kan udtrække og bruge webdata, åbner det for et helt nyt produktivitetsgear – uanset om du bygger en leadliste, holder øje med konkurrenter eller overvåger priser.
No-code/low-code-bølgen: Hvorfor det betyder noget
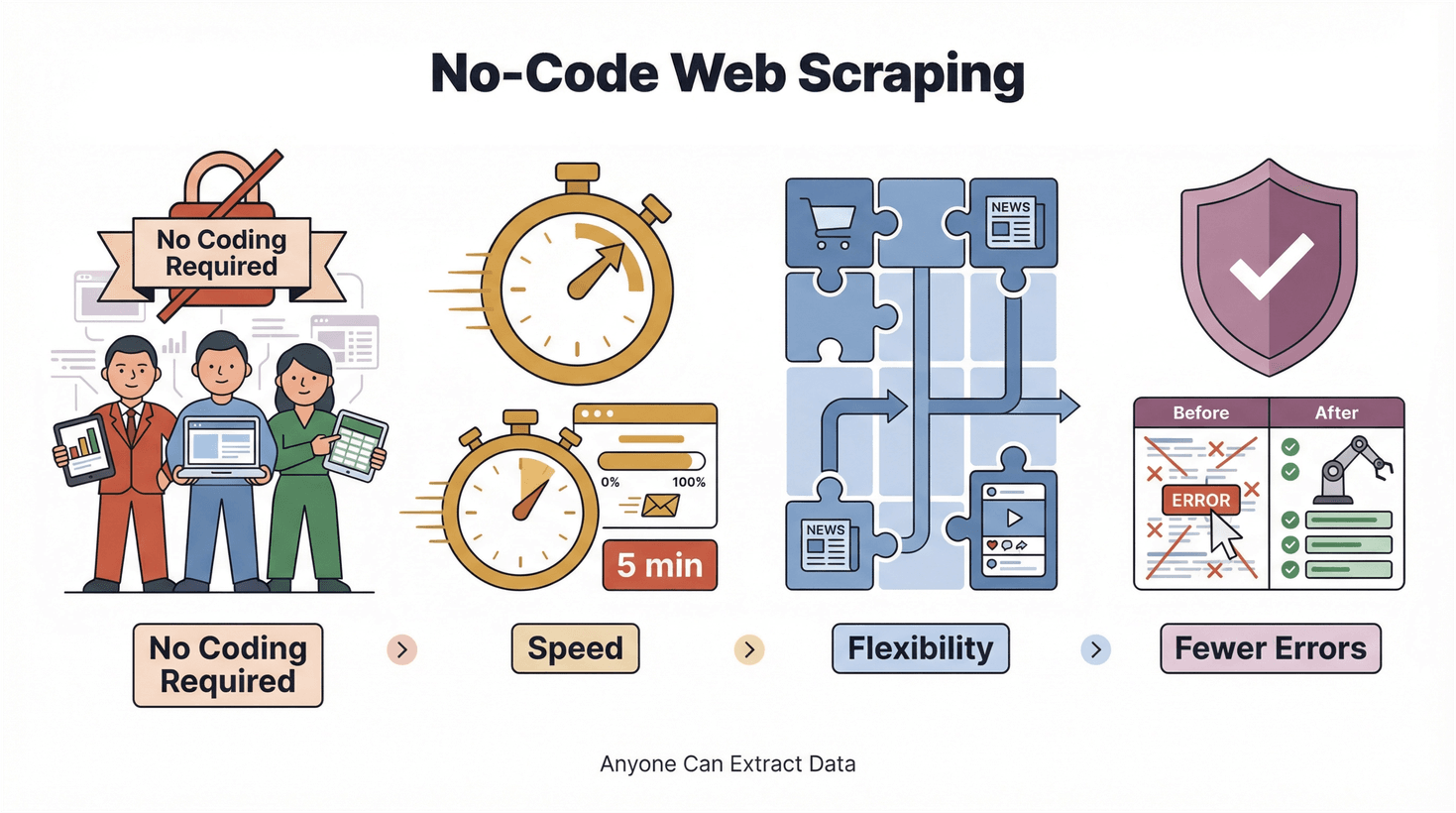
Fremgangen for no-code og low-code handler om at gøre teknologi tilgængelig for flere. Det er ikke bare et buzzword; det er et reelt skifte i, hvordan arbejde bliver udført. I web scraping-verdenen betyder det:
- Ingen kodning nødvendig: Alle kan udtrække data – ikke kun ingeniører.
- Hurtighed: Få resultater på minutter, ikke dage.
- Fleksibilitet: Tilpas dig nye sites og databehov med det samme.
- Færre fejl: Automatisering reducerer copy-paste-fejl.
Og det bedste? Du behøver ikke være en teknisk troldmand for at være med.
Hvorfor traditionelle web scraping-værktøjer er så frustrerende
Lad os være ærlige: traditionelle web scraping-værktøjer føles ofte som om, de er bygget af – og til – udviklere, ikke forretningsbrugere. Jeg har set det på tæt hold: teams bliver hypede på et nyt projekt, men rammer en mur, når værktøjet beder om CSS-selectors, XPath eller regulære udtryk. Så kommer de tomme blikke og “måske næste kvartal”-mails.
Her er, hvad der typisk går galt:
- Kodning kræves: Mange ældre værktøjer forventer scripts eller komplekse skabeloner.
- Besværlig opsætning: Du skal mappe hvert felt, håndtere login-flows og sætte proxies op for ikke at blive blokeret.
- Skrøbelig logik: Hjemmesider ændrer layout, og pludselig virker din scraper ikke. Nu fejlsøger du kode i stedet for at passe dit arbejde.
- Tung vedligeholdelse: Hver gang et site opdaterer, starter du forfra.
Det er ikke så mærkeligt, at de største tekniske udfordringer ifølge er blokering/banning af IP’er (56%), dynamisk indhold (55%) og CAPTCHA’er (52%). Selv stærke teams kan have svært ved at følge med.
Imens vil forretningsbrugere bare have en enkel og stabil måde at få data ind i regneark eller CRM. Det er her, nem webudtræk og enkle metoder til web scraping kommer ind i billedet.
Sådan gør Thunderbit nem webudtræk muligt
Her bliver det interessant – for det er præcis det problem, vi satte os for at løse hos . Vores mission er at gøre web scraping så enkelt, at alle kan være med, uanset teknisk niveau.
Thunderbit er en , der gør webudtræk til en proces med to klik. Sådan fungerer det:
- Beskriv, hvad du vil have: Brug almindeligt sprog til at fortælle Thunderbit, hvilke data du har brug for. Fx: “Udtræk alle produktnavne og priser fra denne side.”
- Klik på “AI Suggest Fields”: Thunderbits AI læser siden og foreslår de bedste kolonner at udtrække – som “Navn”, “Pris”, “E-mail” eller “Billede”.
- Klik på “Scrape”: Thunderbit klarer resten, inkl. paginering, undersider og endda indhold bag login, hvis det er nødvendigt.
Det er faktisk det hele. Ingen kode, ingen skabeloner, ingen opsætningsbøvl. Interfacet er lavet til forretningsbrugere – salg, marketing, ecommerce, ejendom – der bare vil have output, der virker.
Thunderbits AI-drevne workflow: Smartere, ikke hårdere
Den virkelige magi ligger i AI’en. Thunderbit gætter ikke bare – den læser siden, forstår konteksten og strukturerer data automatisk. Hvis du vil være ekstra specifik, kan du tilføje egne instruktioner pr. felt (fx “kategorisér denne kolonne” eller “oversæt til engelsk”), men de fleste klikker bare og kører.
Den AI-drevne tilgang betyder:
- Færre fejl: AI’en tilpasser sig forskellige layouts, så du får stabile resultater, selv når sites ændrer sig.
- Hurtigere opsætning: Ingen skabelonbygning og ingen scripts.
- Data, der kan bruges med det samme: Thunderbit kan navngive, kategorisere og endda berige data under udtrækket.
Vil du nørde mere, så se eller vores . Du kan også finde flere guides på , fx og .
Thunderbits unikke funktioner til enkle metoder til web scraping
Det, der adskiller Thunderbit, er ikke kun AI’en – det er hele workflowet, designet til reelle forretningsbehov. Her er nogle af de funktioner, brugerne er vilde med:
- Automatisk paginering: Thunderbit håndterer flersidede sites og uendelig scroll uden opsætning.
- Udtræk fra undersider: Har du brug for flere detaljer? Thunderbit kan besøge hver underside (fx produktdetaljer eller LinkedIn-profiler) og berige datasættet automatisk.
- Eksport hvor du vil: Send data direkte til Excel, Google Sheets, Airtable, Notion eller download som CSV/JSON. Slut med copy-paste-maraton.
- Virker på sider bag login: Udtræk data fra sites, der kræver login – Thunderbit kører i din browser og ser det samme som dig.
- AI-baseret labeling og kategorisering: Tilføj instruktioner til at klassificere, tagge eller oversætte data under udtrækket.
- Scheduled Scraper: Opsæt tilbagevendende jobs, så dine data altid er opdaterede – perfekt til prisovervågning eller lead tracking.
Og ja, alt det her findes i ét værktøj, som over allerede stoler på.
Automatisk paginering og udtræk fra undersider
En af de største hovedpiner ved web scraping er at håndtere paginerede lister eller indlejrede detaljesider. Med Thunderbit behøver du ikke bekymre dig. AI’en spotter paginering (uanset om det er en “Næste”-knap eller uendelig scroll) og følger links til undersider automatisk. Det betyder, at du kan udtrække hundredvis eller tusindvis af poster i ét hug – uden manuel klikning.
Hvis du fx scraper en produktliste på Amazon, kan Thunderbit hente alle produkter på tværs af flere sider og derefter gå ind på hver produktside for at hente anmeldelser, ratings eller sælgerinfo. Det er som at have en utrættelig assistent, der aldrig løber tør for energi.
Eksport i flere formater og CRM-integration
Data er kun noget værd, hvis du kan bruge dem. Thunderbit lader dig eksportere i det format, dit team har brug for – Excel, Google Sheets, Airtable, Notion eller CSV/JSON. Du kan endda sende data direkte ind i dit CRM eller workflow-værktøjer, så salg og drift altid har de nyeste oplysninger.
Den direkte integration sparer masser af tid. Ingen oprydning i rodede exports eller omformatering af kolonner – Thunderbits AI tager sig af det.
Praktiske use cases for nem webudtræk
Hvor gør nem webudtræk den største forskel? Her er nogle scenarier, jeg har set hos Thunderbit-brugere:
Lead-udtræk til salg
Salgsteams lever og dør på deres leadlister. Med Thunderbit kan du udtrække kontaktinfo fra LinkedIn, Google Maps eller virksomhedsregistre på få minutter. Åbn siden, klik “AI Suggest Fields”, og lad Thunderbit hente navne, e-mails, telefonnumre og virksomhedsdetaljer til et regneark, der er klar til brug.
En salgschef fortalte mig, at de før brugte timer hver uge på at copy-paste leads. Nu bygger de målrettede lister på en brøkdel af tiden – og teamet kan fokusere på outreach i stedet for dataindtastning.
Ecommerce og markedsmonitorering
Ecommerce-teams bruger Thunderbit til at følge konkurrenters SKU’er, priser og anmeldelser på tværs af Amazon, Shopify og andre platforme. Skal du overvåge prisændringer eller nye produktlanceringer? Opsæt et planlagt udtræk og få friske data leveret til dit Google Sheet hver morgen.
Thunderbits udtræk fra undersider er især nyttigt her – du kan hente produktdetaljer, billeder og endda kundeanmeldelser uden at løfte en finger.
Indsamling af ejendomsdata
Ejendomsprofessionelle bruger Thunderbit til at samle boligannoncer, priser og mæglerinfo fra sites som Zillow eller Realtor.com. AI’en håndterer paginering og undersider, så du får et komplet og opdateret markedsbillede – perfekt til analyse eller kunderapporter.
En ejendomsanalytiker delte, at noget, der før tog en hel eftermiddag, nu klares med få klik. Det er styrken ved enkle metoder til web scraping.
Sammenligning af traditionelle og enkle metoder til web scraping
Lad os samle det hele i en side-by-side sammenligning:
| Funktion | Traditionelle scrapers | Nem webudtræk (Thunderbit) |
|---|---|---|
| Kodning kræves | Ja (scripts, selectors) | Nej (AI + naturligt sprog) |
| Opsætningstid | Høj (skabeloner, konfiguration) | Lav (2 klik) |
| Vedligeholdelse | Hyppig (går i stykker ved site-ændringer) | Minimal (AI tilpasser sig) |
| Håndterer paginering | Manuel opsætning | Automatisk |
| Udtræk fra undersider | Kompliceret logik | 1 klik |
| Eksportformater | Ofte begrænset | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Virker på sider bag login | Nogle gange (med konfiguration) | Ja (browser-baseret) |
| Labeling/kategorisering af data | Manuel efterbehandling | AI-baseret, indbygget |
| Planlægning/monitorering | Nogle gange (avanceret) | Ja (nem opsætning) |
Forskellen er til at tage og føle på. Med Thunderbit kan alle udtrække, organisere og bruge webdata – uden tekniske forudsætninger.
Fremtidige trends i nem webudtræk og enkle metoder til web scraping
Fremtiden ser virkelig lovende ud for nem webudtræk. AI bliver kun skarpere, og efterspørgslen efter no-code-værktøjer vokser hurtigt. Ifølge bruger 78% af organisationer nu AI i mindst én funktion, og agentiske systemer – AI-værktøjer, der kan håndtere web-workflows i flere trin – er på vej frem.
Hvad betyder det for forretningsbrugere? Mere power, mindre bøvl. Når AI fortsætter med at udvikle sig, vil vi se:
- Endnu smartere feltgenkendelse: AI vil forstå mere komplekse data og sammenhænge.
- Bedre integration: Direkte forbindelser til flere forretningsværktøjer og platforme.
- Højere stabilitet: Færre brud og mere ensartede resultater – også på dynamiske eller beskyttede sites.
- Større tilgængelighed: Webudtræk bliver en standardkompetence for alle, ikke kun “tech-folk”.
Og ja, Thunderbit ligger helt forrest i den udvikling.
Konklusion og vigtigste pointer
Webben er verdens største database – men indtil for nylig var det primært udviklere, der kunne udnytte den. Det ændrer sig hurtigt. Med nem webudtræk og enkle metoder til web scraping kan alle omdanne hjemmesider til data, der kan handles på, på få minutter.
Her er det vigtigste, jeg har lært (og som jeg håber, du tager med):
- No-code webudtræk er kommet for at blive: Værktøjer som Thunderbit gør det muligt for alle at indsamle og bruge webdata – uden tekniske kompetencer.
- AI er den afgørende ingrediens: Når feltvalg, paginering, udtræk fra undersider og labeling automatiseres, sparer AI-scrapers tid og reducerer fejl.
- Forretningseffekten er reel: Salg, ecommerce og ejendom oplever allerede højere produktivitet, friskere data og bedre beslutninger.
- Fremtiden er endnu bedre: Når AI og no-code-værktøjer udvikler sig, bliver webdataudtræk lige så almindeligt som at sende en e-mail.
Hvis du er træt af manuel copy-paste, frustreret over scrapers der går i stykker, eller bare nysgerrig på mulighederne, så prøv . Du kan og begynde at udtrække data gratis – ingen opsætning, ingen kode, intet bøvl.
Og hvis du vil dykke dybere, så kig forbi for flere guides, tips og eksempler fra virkeligheden.
Ofte stillede spørgsmål (FAQ)
1. Hvad er “nem webudtræk”, og hvem er det til?
Nem webudtræk dækker over no-code, AI-drevne metoder til web scraping, der gør det muligt for alle – især ikke-tekniske forretningsbrugere – hurtigt og nemt at udtrække strukturerede data fra websites. Det er ideelt til salg, marketing, ecommerce og driftsteams, der har brug for data, de kan handle på, uden teknisk besvær.
2. Hvordan adskiller Thunderbit sig fra traditionelle web scraping-værktøjer?
Thunderbit bruger AI til at automatisere feltvalg, paginering og udtræk fra undersider. I modsætning til traditionelle scrapers, der kræver kodning eller komplekse skabeloner, kan du i Thunderbit beskrive dit behov i almindeligt sprog og udtrække data med kun to klik.
3. Kan Thunderbit håndtere dynamiske eller flersidede websites?
Ja. Thunderbit registrerer og håndterer automatisk paginering (inkl. uendelig scroll) og kan følge links til undersider for dybere dataudtræk – med minimal opsætning.
4. Hvilke eksportmuligheder understøtter Thunderbit?
Thunderbit lader dig eksportere data direkte til Excel, Google Sheets, Airtable, Notion, CSV eller JSON. Du kan også integrere med CRM’er og andre workflow-værktøjer for smidige forretningsprocesser.
5. Er det sikkert og etisk at bruge værktøjer til nem webudtræk som Thunderbit?
Thunderbit opfordrer til ansvarlig og etisk web scraping. Respektér altid hjemmesiders vilkår, undgå at scrape persondata uden samtykke, og brug rate limiting for at undgå at forstyrre tjenester. Se mere om best practices i .
Klar til at udnytte webdata? Prøv Thunderbit i dag og oplev, hvordan nem webudtræk kan forvandle din arbejdsgang.
Læs mere