
Sidste uge skrev en af vores brugere til os: "Jeg skal bruge priser, beskrivelser og variantdata fra 14 konkurrenters Shopify-butikker — inden fredag." Det er omkring 4.000 produktsider. Copy-paste? Det kommer ikke til at ske.
Hvis du nogensinde har prøvet at trække produktdata ud af en Shopify-butik — priser, billeder, beskrivelser, varianter, anmeldelser — så kender du smerten. Der findes over i 2026, og ingen af dem har en "eksportér til udefrakommende"-knap. Samtidig siger , at de aktivt holder øje med konkurrenters priser, og ecommerce-udbydere fortæller, at det manuelt kan tage bare at uploade ét produkt med varianter og billeder. Gang det med et par hundrede produkter, og så er din uge væk.
Derfor er Shopify scraper Chrome-udvidelser blevet en fast del af ecommerce-værktøjskassen — til konkurrentanalyse, dropshipping-research, katalogmigration og meget mere. Men de fleste "bedste scraper"-artikler oplister bare funktioner uden at vise, hvad der faktisk sker, når du bruger dem på rigtige Shopify-butikker. Den her artikel er anderledes. Jeg testede otte udvidelser på faktiske storefronts, ramte virkelige anti-bot-vægge og fandt ud af, hvilke værktøjer der leverer de dybe produktdata, du har brug for — og hvilke der kun skraber overfladen.
Hvorfor ecommerce-teams har brug for en Shopify scraper Chrome-udvidelse
Shopify-butikker er skatkamre af kommercielt brugbare produktdata. Men som outsider får du ikke en CSV-download. Du får et storefront. For at gøre det til brugbar indsigt har du brug for en scraper — og brugsscenarierne rækker langt ud over "jeg vil bare have en liste over produktnavne."
Det egentlige spørgsmål er: hvilke data har du faktisk brug for, og til hvilken arbejdsproces? Sådan passer de mest almindelige ecommerce-scenarier sammen med konkrete datafelter:
Konkurrentprisanalyse
Du skal bruge: produkttitler, priser, sammenligningspriser og prisniveauet pr. variant. Det er kernen i en dynamisk prisstrategi — ikke bare at vide, hvad en konkurrent tager, men også hvordan de rabatterer, pakker og prissætter på tværs af størrelser eller farver.
Produktsøgning til dropshipping
Du skal bruge: titler, alle billeder (ikke kun thumbnails), fulde beskrivelser og udgivelsesdatoer. Ved at sortere efter nyeste udgivelsesdato kan du spotte trends eller helt nye produkter, før markedet bliver mættet.
Katalogimport til din egen butik
Du skal bruge: titler, body HTML, alle billeder, varianter, SKU'er og priser — helst i en . Det er ikke alle værktøjer, der leverer det pænt.
Estimering af salgstempo
Du skal bruge: produkttitler og lagerantal, målt over tid. Ved at tage snapshots af lagerbeholdningen efter en fast plan kan du estimere, hvor hurtigt en konkurrent sælger ud — et groft, men nyttigt pejlemærke, når direkte salgsdata ikke er tilgængelige.
Leadgenerering (find butiksejere)
Du skal bruge: butiksnavn, kontaktmail, telefonnummer og nogle gange de apps eller den tech stack, en butik bruger. Salgsteams bruger det til at bygge outreach-lister opdelt efter niche eller teknologi.
Her er et hurtigt overblik:
| Brugsscenarie | Nødvendige nøglefelter | Anbefalet arbejdsproces |
|---|---|---|
| Konkurrentprisanalyse | Titel, pris, sammenligningspris, variantpriser | Skrab listeside + berig undersider for varianter |
| Produktsøgning til dropshipping | Titel, pris, billeder (alle), beskrivelse, udgivelsesdato | Skrab undersider + sorter efter nyeste udgivelsesdato |
| Katalogimport til din butik | Titel, body HTML, billeder, varianter, SKU, pris | Fuld skrabning af undersider → eksportér som Shopify-import-CSV |
| Salgsestimering | Titel, lagerantal (over tid) | Planlagt scraping → tracking i Google Sheets |
| Leadgenerering (butiksejere) | Butiksnavn, mail, telefon, brugte apps | Skrab butikkens kontaktsider + mail-/telefonudtrækkere |
Sådan evaluerede jeg disse 8 Shopify scraper Chrome-udvidelser
Jeg installerede alle otte udvidelser og kørte dem mod det samme sæt rigtige Shopify-butikker — inklusive offentlige butikker, butikker beskyttet af Cloudflare og butikker med products.json deaktiveret. Jeg kiggede ikke bare på funktionslister. Jeg ville se, hvad der faktisk sker, når du trykker "scrape" på en live Shopify-kollektionsside.
Her er de otte kriterier, jeg brugte, og hvorfor de er særligt vigtige for Shopify:
| Kriterium | Hvorfor det er vigtigt for Shopify scraping |
|---|---|
| Nem opsætning | Kan en ikke-teknisk dropshipper komme i gang på under 5 minutter? |
| Udtrukne datafelter | Får den titel, pris, billeder, beskrivelser, varianter OG anmeldelser — eller kun overfladedata? |
| Berigelse af undersider | Kan den skrabe en listeside og derefter automatisk besøge hver produktside for fulde detaljer? |
| Håndtering af pagination | Kan den skrabe videre end første produktside (klik-pagination eller endless scroll)? |
| Robusthed mod anti-bot | Håndterer den Cloudflare Turnstiles eller Shopify-beskyttelse uden at gå i stykker? |
| Eksportformater | CSV, Excel, Google Sheets, Airtable, Notion, Shopify-importklar CSV? |
| Planlagt/gentagen scraping | Kan den overvåge priser eller lagerændringer automatisk over tid? |
| Prisgennemsigtighed | Begrænsninger i gratisniveau, kreditsystem, fast pris — og hvad du faktisk får |
Med den ramme på plads er her, hvordan hvert værktøj klarede sig.
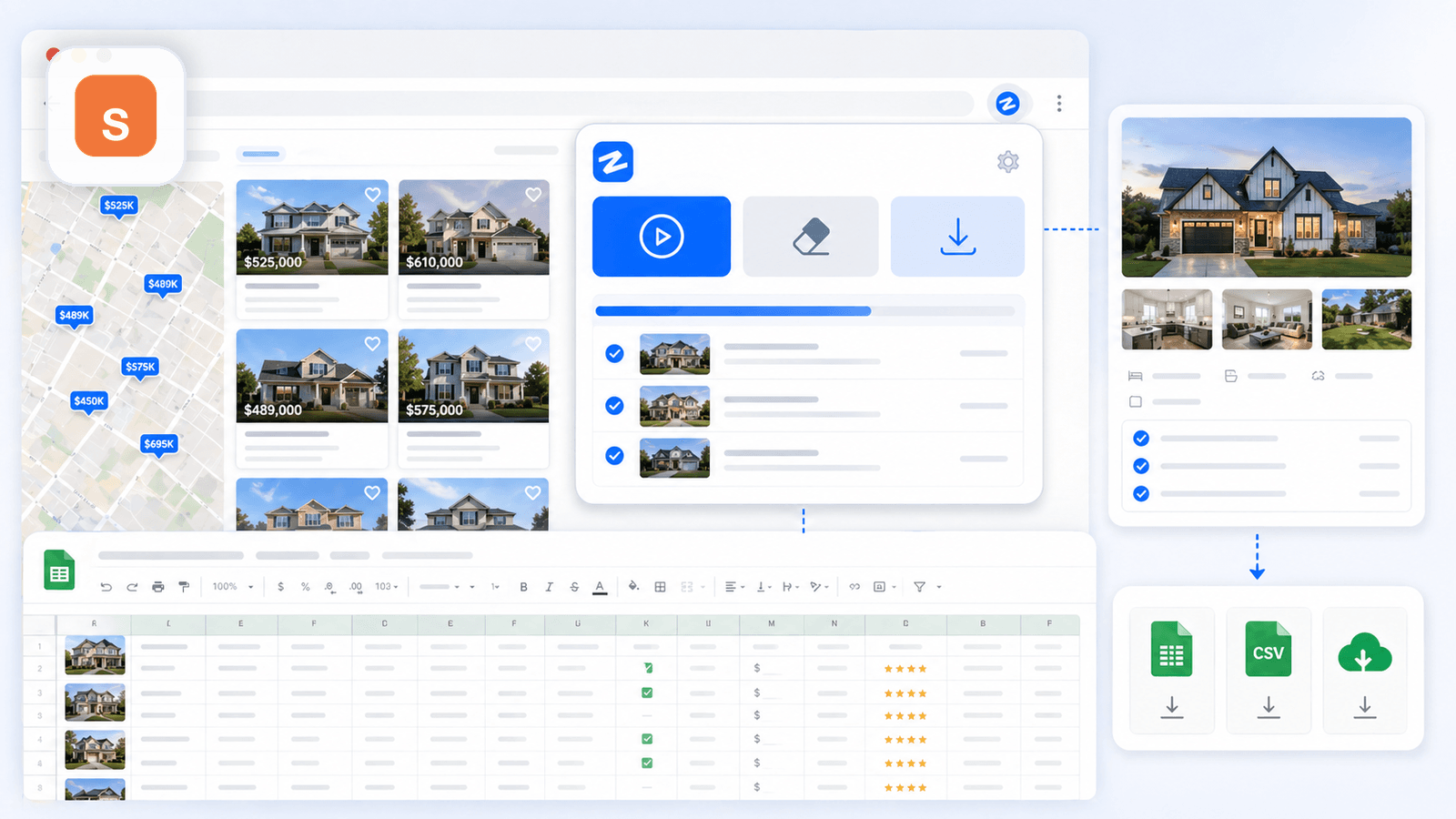
1. Thunderbit — den AI-drevne Shopify scraper bygget til ikke-kodere
er det værktøj, vi har bygget hos Thunderbit specifikt til forretningsbrugere, der vil have dybe produktdata uden at skrive kode, konfigurere CSS-selektorer eller bruge 20 minutter på opsætning. Arbejdsgangen på en Shopify-butik er ægte to klik: åbn en kollektionsside, klik "AI-forslå felter", og AI'en læser siden og foreslår kolonner (titel, pris, billede osv.). Klik "Scrape", og så er du færdig med listesiden.
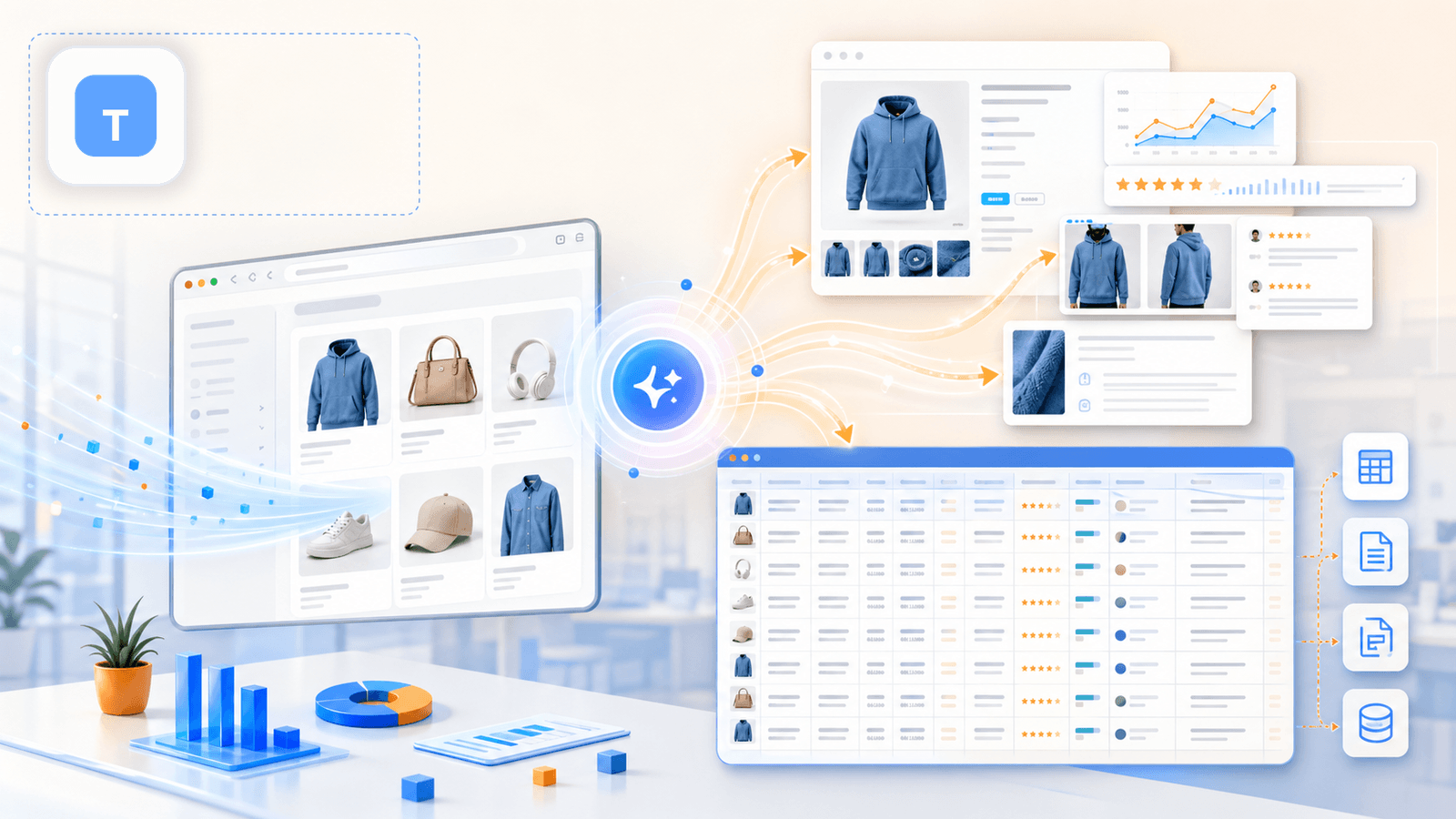
Men den virkelige forskel — og det, de fleste sammenlignende artikler overser — er, hvad der sker bagefter.
Berigelse af undersider: funktionen, der ændrer alt
Når du har skrabet listesiden, klikker du "Scrape undersider". Thunderbits AI besøger hver enkelt produkt-URL og tilføjer data fra detaljesiden til din oprindelige tabel: fulde beskrivelser, alle galleri-billeder, variantmuligheder, SKU'er, antal anmeldelser og meget mere. Det er det trin, der forvandler et overfladisk regneark til et brugbart datasæt til konkurrentanalyse.
Jeg dykker længere ned i, hvorfor det her er vigtigt (og viser en før/efter-sammenligning) i et dedikeret afsnit nedenfor.
Styrker ved Shopify scraping
- AI-forslå felter læser Shopify-siden og genererer automatisk den rigtige kolonnestruktur — ingen CSS-selektorer, ingen manuel opsætning
- Skrabning af undersider udfylder de datamangler, listesider overser (fulde beskrivelser, variantmuligheder, billedgallerier, anmeldelser)
- Cloud scraping-tilstand til hurtig masseudtrækning på offentlige butikker; browser scraping-tilstand til butikker beskyttet af Cloudflare eller login
- Håndtering af pagination (klikbaseret og endless scroll)
- Planlagt scraping til løbende overvågning af priser/lager — beskriv planen i almindeligt sprog (f.eks. "hver mandag kl. 9")
- Gratis mail- og telefonudtrækkere til leadgenerering
- Eksport til Excel, Google Sheets, Airtable, Notion, CSV, JSON — inklusive Shopify-importvenlige formater
- Field AI Prompt lader dig tilføje egne instruktioner pr. kolonne (f.eks. "kategorisér i 3 produkttyper" eller "oversæt beskrivelsen til engelsk")
Hvor den kommer til kort
- Kreditsbaseret pris betyder, at meget stor skala scraping (ti-tusindvis af produkter) kræver et betalt abonnement
- AI-behandlingen tilføjer et par sekunder pr. række sammenlignet med skabelonbaserede scrapers på helt enkle sider
Pris
- Gratis niveau: 6 sider (eller op til 10 med gratis prøve), alle eksporter gratis
- Starter: , 500 credits/måned
- Professional-niveauer: fra $38/måned (3.000 credits) op til $249/måned (20.000 credits)
- Credit-regler: 1 outputrække = 1 credit for web scraping; 1 outputrække = 2 credits for skrabning af undersider; eksport er altid gratis
Bedst til: Ikke-tekniske ecommerce-teams, der har brug for de dybeste Shopify-produktdata med minimal opsætning — og som vil overvåge konkurrenter over tid.
2. Instant Data Scraper — den konfigurationsfri auto-detekt-løsning
Instant Data Scraper er en gratis Chrome-udvidelse, der bruger heuristiske algoritmer til automatisk at genkende tabeldata på websider. Der er slet ingen konfiguration — åbn en Shopify-kollektionsside, klik på udvidelsesikonet, og så forsøger den at finde og vise produktdata i en tabel.
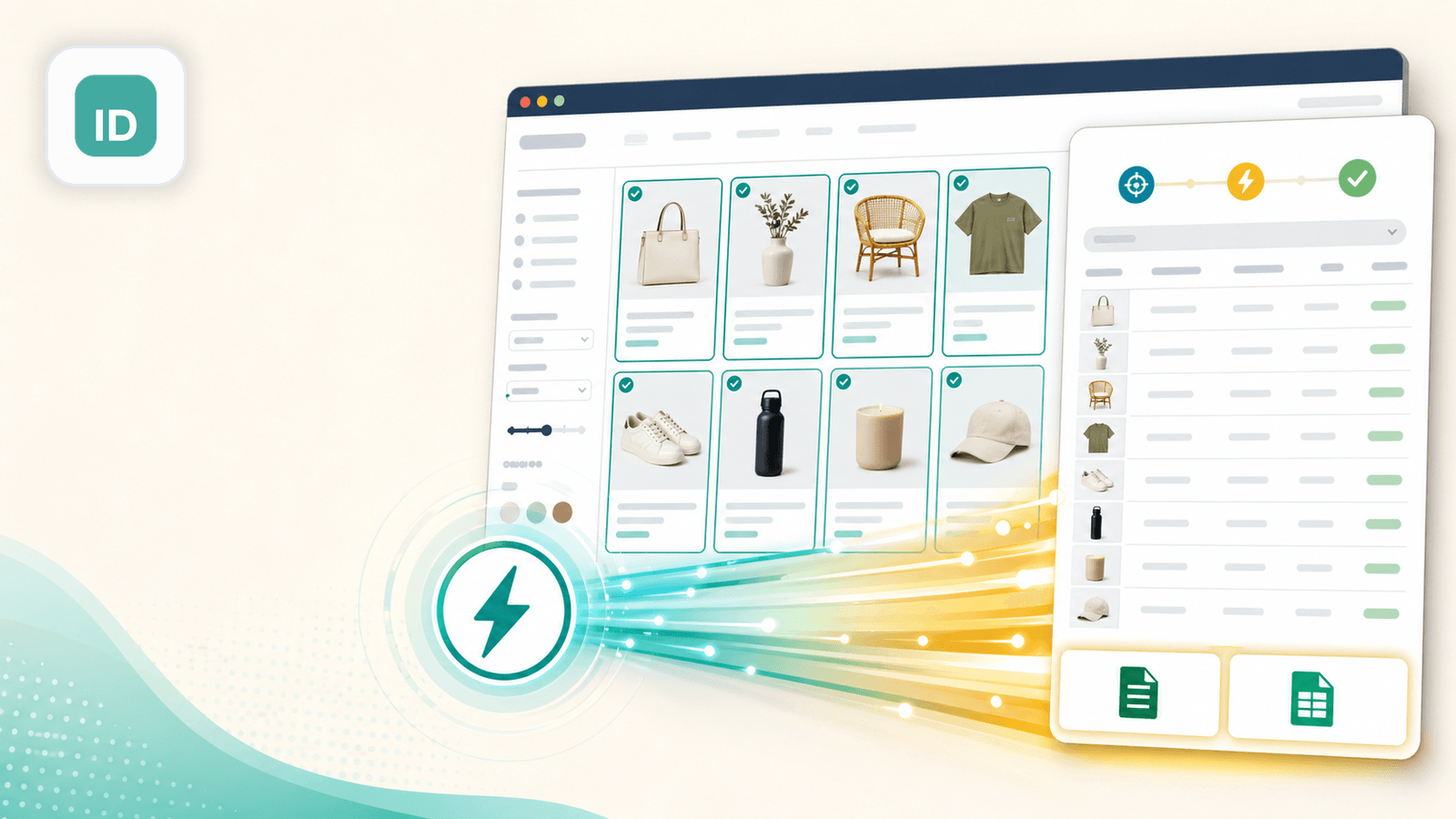
I min test fungerede den godt på standard Shopify Dawn-theme-kollektionssider og fangede titler, priser og thumbnail-URL'er på få sekunder. På butikker med ikke-standard layouts trak den af og til navigationslinks eller footer-indhold ind i stedet for produkter — man skal lige tjekke outputtet med øjet.
Styrker ved Shopify scraping
- Helt gratis uden brugsbegrænsninger
- Auto-detektion betyder nul opsætningstid — godt til hurtige engangseksporter
- Understøtter pagination (kan automatisk klikke "næste side")
- Eksport til CSV og XLSX
Hvor den kommer til kort
- Auto-detektion rammer eller misser på Shopify-butikker med ikke-standard layouts
- Ingen berigelse af undersider: du får det, der ligger på listesiden (titel, pris, thumbnail), men ikke fulde beskrivelser, varianter eller anmeldelser
- Ingen AI til at rense, mærke eller transformere data
- Ingen planlægning, ingen cloud scraping
- Ingen direkte eksport til Google Sheets, Airtable eller Notion
Pris
- Helt gratis
Bedst til: Alle, der har brug for en hurtig, gratis og opsætningsfri eksport af synlige listesidedata fra en standard Shopify-butik.
3. Web Scraper — den visuelle sitemap-bygger
Web Scraper (webscraper.io) er den klassiske klik-og-vælg Chrome-udvidelse til at bygge "sitemaps" — scraping-opskrifter, hvor du vælger elementer på siden og definerer et scraping-forløb. På Shopify ville du oprette et sitemap ved at klikke på produkttitler, priser, billeder og definere regler for pagination og link-following.
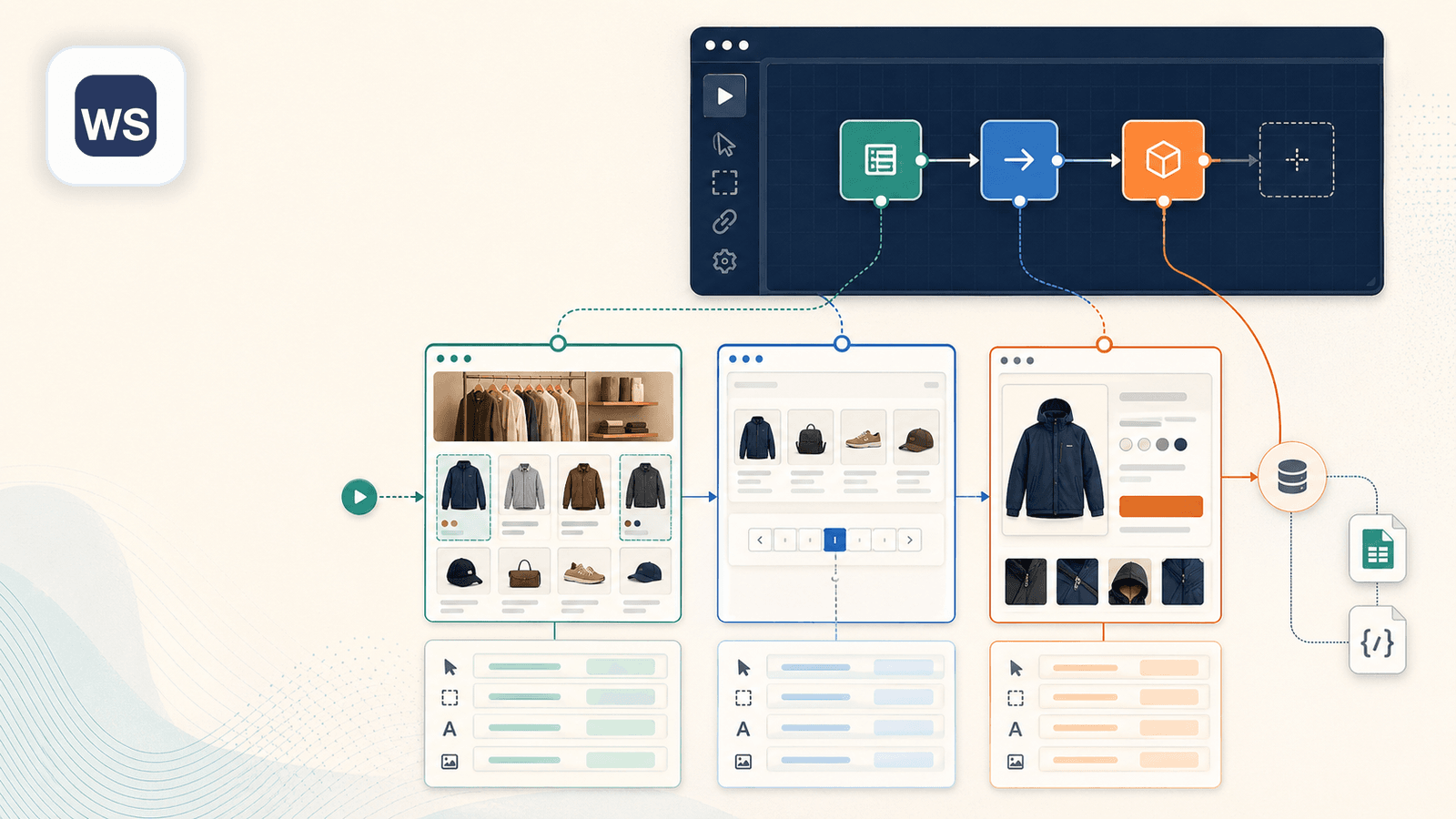
Styrker ved Shopify scraping
- Visuel selector-bygger giver mere kontrol end auto-detekt-værktøjer
- Kan følge links til undersider (produktsider) — men kræver, at du manuelt konfigurerer parent-child-selektorer i sitemappet
- Håndterer pagination med korrekt opsætning
- Gratis browserbaseret scraping; betalte cloud-scraping-planer tilgængelige (fra $50/måned)
- Eksport til CSV; cloud-planer understøtter Google Sheets og andre formater
Hvor den kommer til kort
- Opsætningen er mere tidskrævende: at lave et sitemap med parent-child-selektorer tog mig omkring 15 minutter for en ny Shopify-butik
- Skrabning af undersider kræver — ikke en one-click-berigelse
- Sitemaps går i stykker, når Shopify-butikker ændrer layout eller CSS-klasser
- Læringskurven er stejlere end for AI-drevne alternativer
Pris
- Browser-udvidelse: Gratis
- Cloud-planer: Project $50/måned, Professional $100/måned, Scale fra $200/måned
Bedst til: Tekniske brugere, der vil have detaljeret kontrol over deres scraping-flow og ikke har noget imod selv at bygge opskriften.
4. Data Miner — den opskriftsbaserede scraper
Data Miner (dataminer.io) er bygget op omkring "recipes" — færdige eller brugerdefinerede scraping-skabeloner, du anvender på en side. Der er et offentligt recipe-bibliotek, så du kan måske finde en Shopify-skabelon delt af en anden bruger, eller du kan bygge din egen ved at vælge elementer på siden.
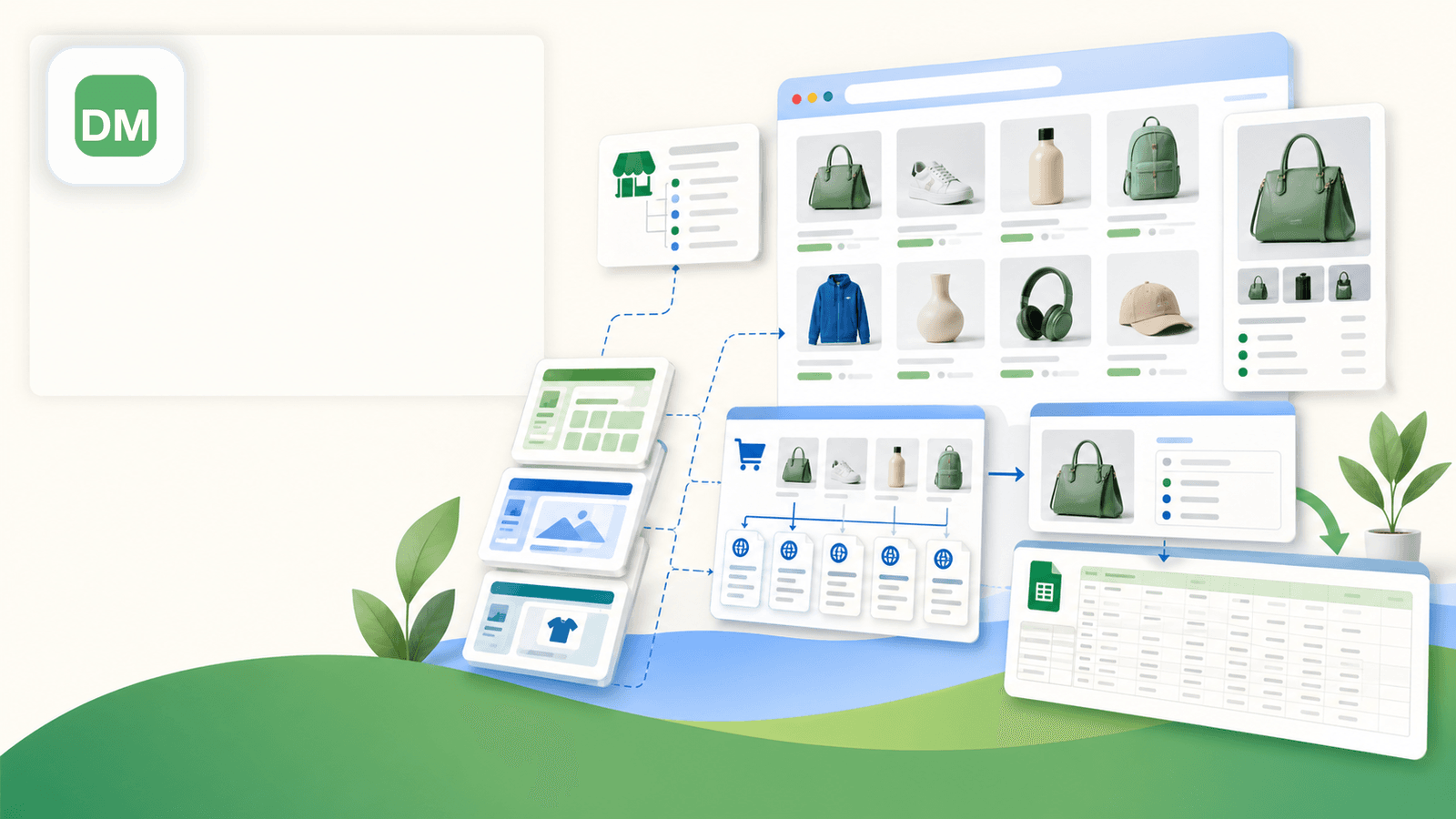
Styrker ved Shopify scraping
- Recipe-biblioteket kan have færdige Shopify-skabeloner delt af andre brugere
- Visuel recipe-bygger til brugerdefinerede scraping-konfigurationer
- Håndterer pagination via recipe-konfiguration
- Eksport til CSV, Excel, Google Sheets og TSV
- Crawl-workflows til at besøge detaljesider efter listesider
Hvor den kommer til kort
- Gratis niveau er begrænset til 500 sider/måned
- Recipes er baseret på CSS-selektorer, så de går i stykker, når butikkens layout ændrer sig
- Ingen AI-drevet feltsuggestion eller datatransformation
- Ingen indbygget one-click-workflow til berigelse af undersider — kræver en separat crawl-recipe til detaljesider
- Planlagte crawls findes, men er ikke den mest elegante planlægningsløsning
Pris
- Gratis: 500 sider/måned
- Solo: $19,99/måned
- Small Business: $49/måned
- Business: $99/måned
- Business Plus: $200/måned
Bedst til: Brugere, der godt kan lide at arbejde med skabeloner og vil have et recipe-bibliotek til at gøre opsætningen hurtigere på almindelige sites.
5. Simplescraper — den lette extractor
Simplescraper (simplescraper.io) er en minimalistisk Chrome-udvidelse og cloud-baseret scraper, der lægger vægt på enkelhed. Du klikker på dataelementer på en Shopify-side, Simplescraper genererer CSS-selektorer og udtrækker de matchende data.
Styrker ved Shopify scraping
- Rent, minimalistisk interface — hurtigt at lære
- Cloud scraping tilgængelig til planlagte og større jobs
- API-adgang til udviklere, der vil integrere scraped data i workflows
- Eksport til CSV, JSON, Google Sheets, Airtable og via webhooks
- Deep scraping-koncept til at følge links til detaljesider
- Login-kompatible workflows til session-følsomme butikker
Hvor den kommer til kort
- Manuelt selector-baseret tilgang — ingen AI til automatisk at finde felter
- Skrabning af undersider kræver ekstra konfiguration
- Mindre community og færre færdige skabeloner end Web Scraper eller Data Miner
- Gratis niveau: 100 credits (1 JS-renderet side = 2 credits)
- Pris på betalte niveauer er mindre gennemsigtig på den officielle side end hos de fleste konkurrenter
Pris
- Gratis: 100 credits
- Betalte planer: Tredjepartskilder angiver Plus til ca. $39/måned, Pro til ca. $70/måned, Premium til ca. $150/måned (ifølge G2-prisdata)
Bedst til: Brugere, der vil have en let og moderne cloud scraper med gode integrationer og ikke har brug for AI-drevet feltgenkendelse.
6. Octoparse — Chrome-udvidelsen med desktop-motor
Octoparse (octoparse.com) er primært en desktop-applikation med en tilhørende Chrome-udvidelse. Den tilbyder både en visuel workflow-bygger og færdige skabeloner til populære sites, inklusive en Shopify-specifik scraping-vejledning.

Styrker ved Shopify scraping
- Færdige Shopify-skabeloner til almindelige scraping-opgaver
- Kraftig desktop-app med avancerede funktioner: IP-rotation, planlagt scraping, cloud-ekstraktion
- Håndterer pagination, endless scroll og AJAX-indlæst indhold godt
- Den stærkeste dokumenterede anti-bot-håndtering på denne liste, inklusive automatisk CAPTCHA-håndtering
- Eksport til CSV, Excel, JSON, HTML, XML, databaser og Google Sheets
Hvor den kommer til kort
- Selve Chrome-udvidelsen er begrænset — de fleste kraftfunktioner kræver desktop-appen
- Desktop-appen har en stejlere læringskurve med sin visuelle workflow-bygger
- Gratis niveau er begrænset; reel brug kræver et betalt abonnement
- Tungere opsætning end rene Chrome-udvidelser — ikke ideelt til en hurtig 5-minutters scrape
- Desktop-appen findes kun til Windows/Mac (ikke ren browser-baseret)
Pris
- Gratis plan tilgængelig
- Basic: $39/måned
- Standard: ca. $83/måned (månedligt), ca. $75/måned (årligt)
- Professional: ca. $299/måned (månedligt), ca. $208/måned (årligt)
- Enterprise: skræddersyet
Bedst til: Teams, der har brug for scraping i enterprise-skala med IP-rotation, anti-bot-håndtering og tilbagevendende cloud-jobs — og som ikke har noget imod en desktop-app.
7. Bardeen — scraperen med automation først
Bardeen (bardeen.ai) er en browser-automatiseringsplatform, der kombinerer web scraping med workflow-automation. Brugere bygger "playbooks", som kan skrabe data og derefter sende dem videre til andre apps — tænk på det som "hvis jeg skraber det her, så push det til mit CRM."

Styrker ved Shopify scraping
- Workflow-automation ud over scraping: skrab Shopify-data → berig → push til CRM eller regneark i ét playbook
- Integrationer med 100+ apps (Google Sheets, Airtable, Notion, HubSpot, Slack osv.)
- AI-drevne funktioner til dataudtræk og klassificering
- Kører i browseren — ingen desktop-app nødvendig
- Tids-/datobaserede automations til planlægning
Hvor den kommer til kort
- Primært et automation-værktøj, ikke en dedikeret scraper — scraping-funktionerne er mindre dybe end specialiserede værktøjer
- Oprettelse af playbooks kan være forvirrende for brugere, der bare vil udtrække en produktliste
- Gratis niveau er begrænset til 100 credits
- Berigelse af undersider og håndtering af pagination er mindre intuitivt end i dedikerede scraping-værktøjer
- Overkill, hvis du kun skal skrabe data uden efterfølgende automation
Pris
- Gratis: 100 credits
- Basic: $10/måned, 100 credits/måned
- Premium: $50/måned, 1.000 credits/måned (~$40/måned årligt)
- Enterprise: skræddersyet
- Credit-model: 1 credit pr. scraper-række, 3 credits pr. berigelsesrække
Bedst til: Teams, der vil skrabe Shopify-data og straks sende dem videre til efterfølgende apps (CRM'er, regneark, Slack) i én automatiseret arbejdsgang.
8. Listly — konverteren fra liste til regneark
Listly (listly.io) er designet specifikt til at omdanne lister og tabeller på websider til data, der er klar til regneark. Klik på udvidelsen på en Shopify-kollektionsside, og Listly forsøger at genkende produktlisten og eksportere den som et regneark.

Styrker ved Shopify scraping
- Ekstremt enkelt interface — bygget til one-click listeudtræk
- God til at genkende gentagne listesstrukturer (som produktgrid)
- Eksporterer direkte til Excel og Google Sheets
- Group scraping-funktion til at behandle flere URL'er på én gang
- Planlægning tilgængelig på Business-planer
Hvor den kommer til kort
- Begrænset til det, den automatisk genkender på siden — ingen brugerdefineret feltkonfiguration
- Ingen berigelse af undersider — eksporterer kun data på listesideniveau
- Kæmper med ikke-standard Shopify-themes eller butikker med tung JavaScript-rendering
- Gratis niveau er meget begrænset (10 URL'er/måned)
- Færre eksportmuligheder end konkurrenterne (primært Excel og Sheets)
Pris
- Gratis: 10 URL'er/måned, grundlæggende 1-sides udtræk, Excel-download, Google Sheet-eksport
- Light: $30/måned ($187,20/år ved årlig betaling)
- Business: $90/måned ($993,60/år ved årlig betaling) — tilføjer avanceret udtræk, gruppeudtræk, planlægning, auto-scroll/klik, API-beta
Bedst til: Brugere, der vil have den simpleste vej fra en Shopify-kollektionsside til et regneark — og ikke har brug for dybe produktdata.
Alle 8 Shopify scraper Chrome-udvidelser sammenlignet
Her er den fulde sammenligning side om side. Jeg har forsøgt at være specifik i hver celle i stedet for bare at sætte flueben — fordi "understøtter pagination" betyder meget forskellige ting afhængigt af værktøjet.
| Værktøj | Nem opsætning | Datafelter | Berigelse af undersider | Pagination | Anti-bot-håndtering | Eksportformater | Planlægning | Gratis niveau / pris |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Meget nemt (AI-ledet, 2 klik) | Stærkest for ikke-tekniske brugere (AI foreslår alle relevante felter) | Ja — berigelse med ét klik | Ja (klik + endless scroll) | Cloud til offentlige, browser til beskyttede | Sheets, Airtable, Notion, CSV, JSON, Excel | Ja (planlægning i almindeligt sprog) | Gratis 6 sider; betalt fra $15/md. |
| Instant Data Scraper | Ekstremt nemt (ingen konfiguration) | Godt kun til listesidedata | Nej | Ja (auto-genkender næste side) | Kun browser, ingen anti-bot-historik | CSV, XLSX | Nej | Gratis |
| Web Scraper | Mellem-svært (manuelt sitemap) | Fleksibel hvis sitemap er godt bygget | Ja, men manuelt via link-selektorer | Ja (med sitemap-konfiguration) | Browser lokalt; proxy-rotation på cloud-planer | CSV lokalt; bredere i cloud | Ja på cloud-planer | Gratis udvidelse; cloud fra $50/md. |
| Data Miner | Mellem (recipe-baseret) | Godt hvis en recipe findes eller bygges | Ja, men opsætning i flere trin | Ja (recipe-konfiguration) | Mest browser-side | CSV, Excel, Sheets, TSV | Automatiserede crawls findes | Gratis 500 sider/md.; betalt fra $19,99/md. |
| Simplescraper | Let-mellem (selector-baseret) | Solid til let ekstraktion | Deep scraping findes, men ikke med ét klik | Ja (endless scroll understøttes) | Proxy-rotation og login-venlig | CSV, JSON, Sheets, Airtable, webhooks | Ja | Gratis 100 credits; betalte niveauer findes |
| Octoparse | Sværere (desktop-app) | Meget stærk, når den er sat op | Ja, via workflows eller skabeloner | Ja (AJAX, endless scroll) | Stærkest anti-bot (IP-rotation, CAPTCHA) | CSV, Excel, JSON, HTML, XML, DB'er, Sheets | Ja på Standard+ | Gratis; Basic $39/md.; cloud fra ca. $83/md. |
| Bardeen | Mellem (playbook-bygger) | God når den kobles til automation | Muligt i workflow-logik, ikke Shopify-first | Muligt | Kører i browser, anti-bot er ikke kerne | CSV, Sheets, Airtable, Notion | Ja via automations | Gratis 100 credits; Basic $10/md.; Premium $50/md. |
| Listly | Meget nemt (one-click listegenkendelse) | Bedst til synlige rækkedata i lister | Nej | Begrænset til den genkendte listesstruktur | Minimal | Excel, Sheets, CSV/JSON API på Business | Ja på Business | Gratis 10 URL'er/md.; Light $30/md.; Business $90/md. |
Hurtig konklusion efter prioritet
Hvis du har brug for de dybeste Shopify-produktdata med minimal opsætning, er Thunderbits AI + berigelse af undersider den stærkeste kombination. Hvis du vil have en helt gratis, hurtig og simpel eksport, virker Instant Data Scraper til enkle sider. Hvis du vil have fuld kontrol og ikke har noget imod at bygge opskrifter, giver Web Scraper eller Octoparse dig den mulighed. Og hvis dit egentlige mål er scrape → automatisér → push til CRM, så er Bardeen workflow-platformen værd at kigge på.
At skrabe listesiden er kun halvdelen af arbejdet: arbejdsgangen med berigelse af undersider
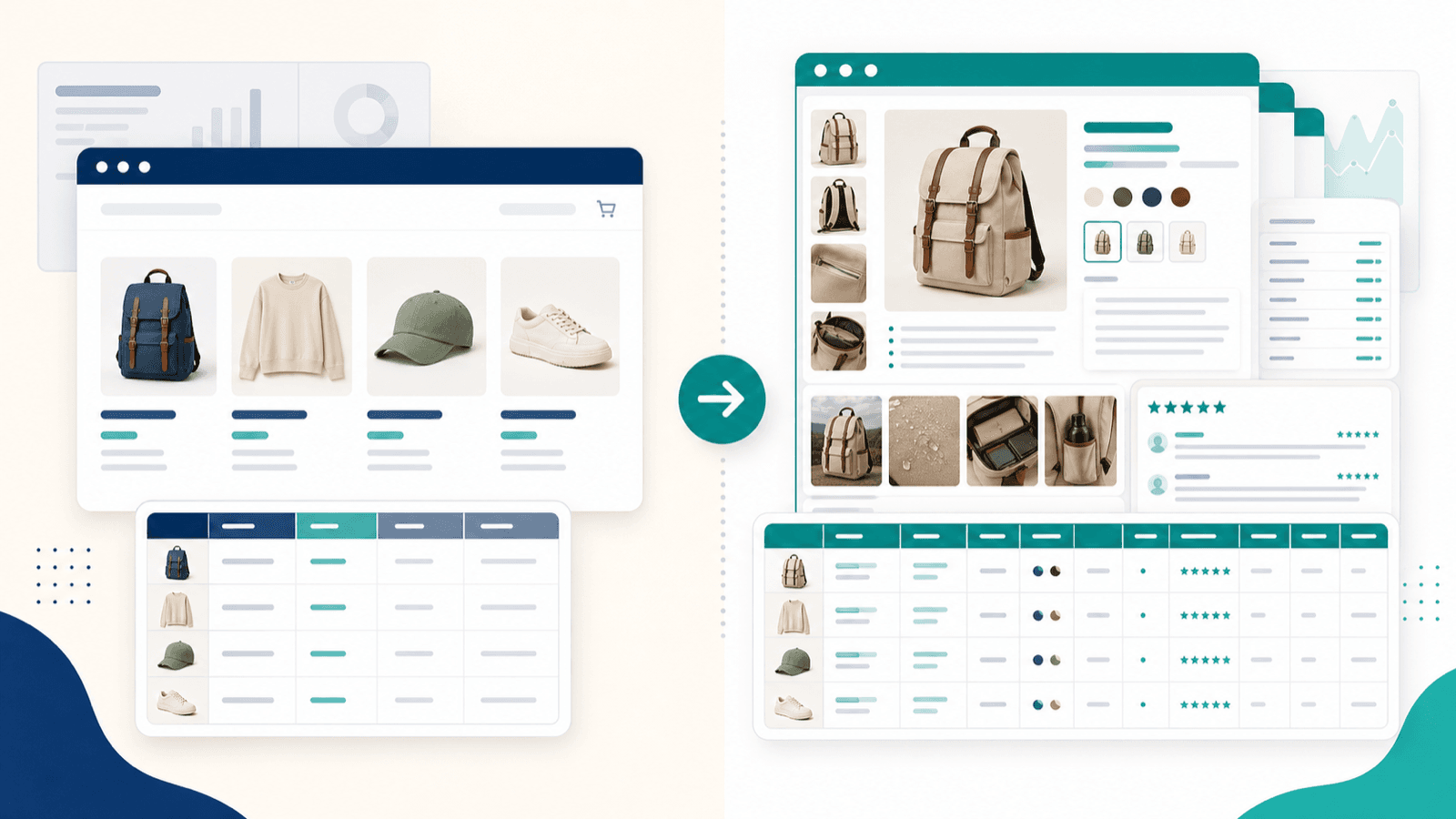
Det her er den sektion, jeg ville ønske, at alle andre Shopify scraper-artikler inkluderede — for det er det største hul i konkurrenternes indhold, og den største frustration, jeg hører fra ecommerce-brugere.
Når du skraber en Shopify-kollektionsside (altså listesiden), får du overfladedata: titler, priser, thumbnails, måske en afkortet beskrivelse. Men de felter, du faktisk har brug for til konkurrentanalyse, katalogimport eller dropshipping-research, ligger på de individuelle produktsider.
Hvad du får fra listesiden vs. efter berigelse af undersider
| Datafelt | Kun fra listesiden | Efter berigelse af undersider |
|---|---|---|
| Produkttitel | ✅ | ✅ |
| Pris | ✅ | ✅ |
| Thumbnail-billede | ✅ | ✅ + alle galleri-billeder |
| Kort beskrivelse | ⚠️ Afkortet | ✅ Fuld HTML-beskrivelse |
| Varianter (størrelse, farve) | ❌ | ✅ |
| SKU / lager | ❌ | ✅ |
| Anmeldelser / ratings | ❌ | ✅ |
Det er en kæmpe forskel.
En eksport kun fra listesiden giver dig et overfladisk regneark. En eksport beriget med undersider giver dig et brugbart datasæt til konkurrentanalyse.
Sådan fungerer skrabning af undersider i Thunderbit (trin for trin)
- Gå til Shopify-buttikens kollektions-/listeside
- Klik "AI-forslå felter" — Thunderbit læser siden og foreslår kolonner (titel, pris, billede, link osv.)
- Klik "Scrape" for at udtrække data fra listesiden
- Klik "Scrape undersider" — AI besøger hver produkt-URL og tilføjer data fra detaljesiden (fuld beskrivelse, alle billeder, varianter, anmeldelser) til den oprindelige tabel
- Eksportér den berigede tabel til Excel, Google Sheets, Airtable, Notion eller CSV
Hele processen tager et par minutter for en typisk kollektion, og du ender med et datasæt, som ellers ville have taget timer at samle manuelt.
Hvilke andre værktøjer understøtter berigelse af undersider?
- Web Scraper: Ja, men kræver manuel sitemap-konfiguration med link-selektorer og child sitemaps — regn med 15-20 minutters opsætning pr. butik
- Octoparse: Ja, via workflow-bygger eller skabeloner — kraftfuldt, men tungere opsætning
- Data Miner: Ja, via flertrins crawl-workflows — ikke en one-click-løsning
- Simplescraper: Deep scraping-konceptet findes, men er mindre plug-and-play
- Instant Data Scraper, Listly, Bardeen: Ingen dokumenteret one-click berigelse af undersider til Shopify
Forskellen mellem "kan teknisk følge links med 20 minutters manuel opsætning" og "berigelse med ét klik" er forskellen på et værktøj til scraper-ingeniører og et værktøj til ecommerce-operatører.
Når Shopify's products.json fejler — og hvorfor Chrome-udvidelser er din backup-plan
Hvis du har læst andre guides til Shopify scraping, har du sikkert set /products.json-tricket: tilføj bare /products.json til en Shopify-URL, og du får strukturerede produktdata i JSON-format. Det er et reelt endpoint, og når det virker, er det praktisk.
Sådan fungerer products.json
Shopify-butikker eksponerer et på /products.json, som returnerer strukturerede produktdata. Du kan paginere med ?page=2&limit=250 (maks. 250 produkter pr. side).
Felter, der typisk returneres, inkluderer: title, body_html, vendor, product_type, tags, published_at, variants (med price, compare_at_price, sku, available) og images.
Hvad products.json mangler
- Ingen anmeldelsesdata eller rating-tal
- Begrænset formatering af beskrivelser sammenlignet med renderede sider
- Egne metafields er ofte ikke med
- Variantbilleder kan være inkonsistente
- Intet renderet merchandising-indhold, badges eller social proof
Når products.json går i stykker
Jeg kørte direkte HTTP-tjek mod otte rigtige Shopify-storefronts den 27. april 2026. Resultatet var tydeligt:
| Butik | Resultat |
|---|---|
| kith.com | ✅ Fungerede — ren JSON |
| colourpop.com | ✅ Fungerede |
| allbirds.com | ✅ Fungerede |
| brooklinen.com | ✅ Fungerede |
| negativeunderwear.com | ✅ Fungerede |
| gymshark.com | ❌ Blokeret — 403 HTML i stedet for JSON |
| mvmt.com | ⚠️ Delvist deaktiveret — 200 HTML-side, ikke JSON |
| fashionnova.com | ❌ Deaktiveret — 404 |
Fem ud af otte returnerede ren JSON. Tre gjorde ikke.
Brugere på fora rapporterer det samme: "Af en eller anden grund vælger nogle Shopify-butikker ikke at eksponere products.json." Password-beskyttede butikker, butikker med egne API-opsætninger og domæner beskyttet af Cloudflare kan alle bryde mønstret.
Fallback med Chrome-udvidelse
Når products.json ikke er tilgængelig, udtrækker en Chrome-udvidelses-scraper data direkte fra den renderede side (DOM'en). Det er kernen i browserbaserede scrapers: de ser og udtrækker det, du ser i din browser, uanset om API'et er tilgængeligt eller ej. Det gør Chrome-udvidelser til den pålidelige Plan B — og ofte Plan A, når du har brug for renderede sidedata som anmeldelser, merchandising-indhold eller fulde billedgallerier.
Anti-bot-beskyttelse: hvad der faktisk sker, når du scraper Shopify-butikker
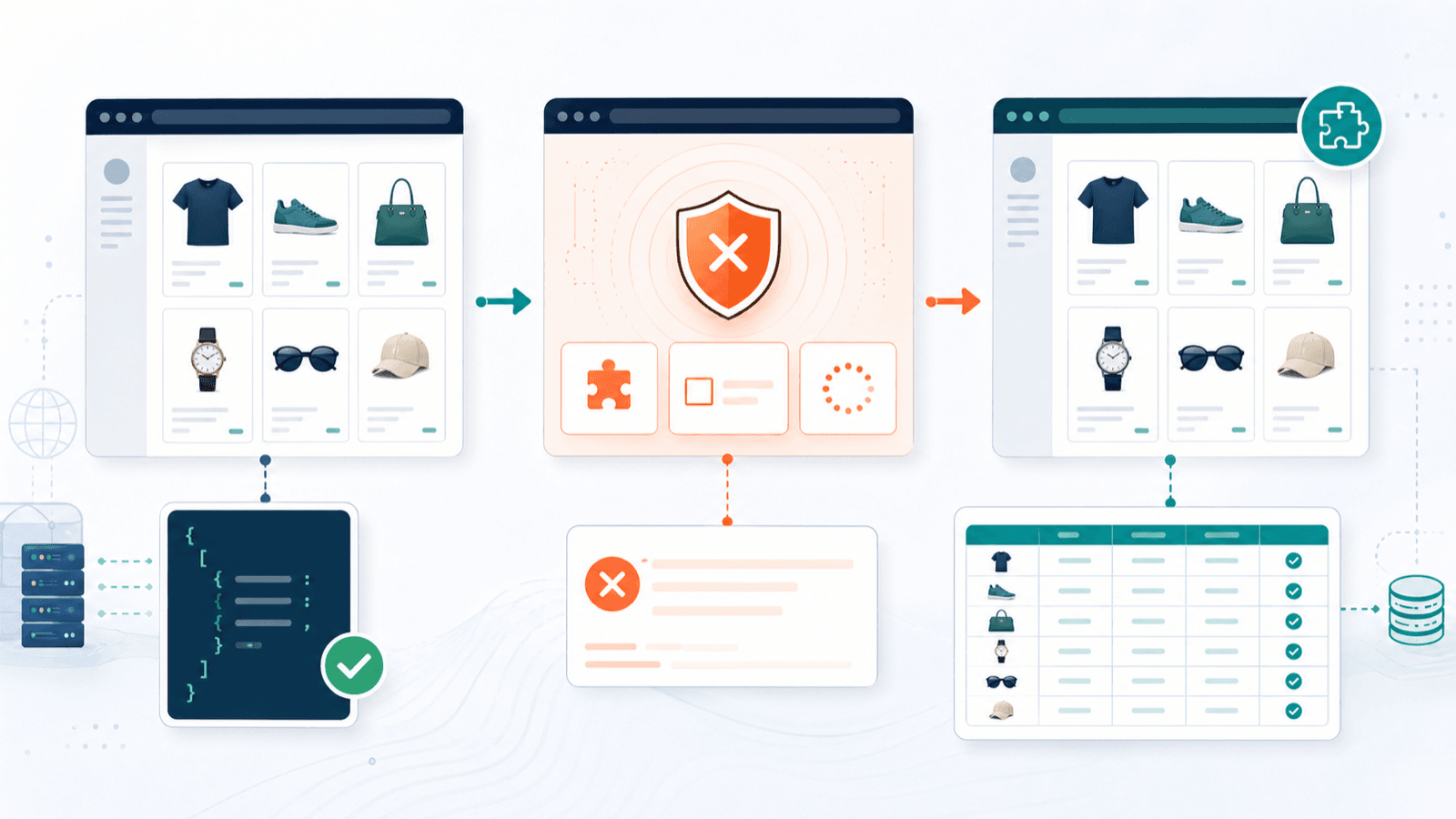
De fleste Shopify scraper-artikler opfører sig, som om alle butikker står åbne på vid gab. Det gør de ikke. , at 99,2 % af Shopify-butikker bruger Cloudflare-infrastruktur. Det betyder ikke, at alle butikker aggressivt blokerer scrapers, men det betyder, at infrastrukturen til at blokere dem findes overalt.
I praksis ser spektret sådan ud:
Nemt at scrape
- Offentlige butikker uden aggressiv Cloudflare-beskyttelse
- Butikker med products.json aktiveret
- Butikker med standard Shopify-themes (konsekvent DOM-struktur)
Sværere at scrape
- Cloudflare-beskyttede butikker (CAPTCHA-udfordringer, Turnstiles)
- Butikker med login-krav eller adgang via password
- Shopify Plus-butikker med egne sikkerhedslag
- Butikker med aggressiv rate limiting
Sådan håndterer hvert værktøj anti-bot-scenarier
| Scenarie | Bedste tilgang | Værktøjer, der håndterer det |
|---|---|---|
| Offentlig butik, ingen anti-bot | Cloud scraping (hurtigt) | Thunderbit (cloud-tilstand), Instant Data Scraper, de fleste andre |
| Cloudflare-beskyttet butik | Browserbaseret scraping (bruger din session) | Thunderbit (browser-tilstand), Web Scraper, Octoparse |
| Login-krævet / privat butik | Browser scraping med din indloggede session | Thunderbit (browser-tilstand), Web Scraper, Simplescraper |
| products.json deaktiveret | DOM-baseret udtræk fra renderet side | Alle Chrome-udvidelser (det er deres styrke) |
Thunderbits dobbelte cloud/browser scraping-tilstande er virkelig relevante her. Cloud-tilstand er hurtig til masseudtræk på offentlige butikker. Browser-tilstand bruger din rigtige Chrome-session, når anti-bot-beskyttelse kræver det. Den fleksibilitet reddede mig på gymshark.com, hvor cloud-forespørgsler blev blokeret, men browser-tilstand virkede fint.
Planlagt Shopify scraping: overvåg priser og lager over tid
Engangsscraping er nyttigt. Men ecommerce-teams har typisk brug for løbende konkurrentindsigt — ikke bare et enkelt øjebliksbillede. Prisændringer, lagerudsving, nye produktlanceringer: det sker hele tiden. En bruger i et forum sagde det meget præcist: "Det er mere nyttigt at se deres aktuelle lagerniveau og snapshots af, hvordan niveauet falder."
Alligevel nævner næsten ingen konkurrerende artikel planlagt eller tilbagevendende scraping. Det er et tydeligt blindt punkt.
Sådan fungerer planlagt Shopify-overvågning
- Sæt en tilbagevendende scraping op af en konkurrents kollektions- eller produktsider
- Data eksporteres til Google Sheets (eller Airtable) ved hver kørsel, så du får en tidsserie med pris- og lagerdata
- Brug dataene til at følge: prisfald/-stigninger, udsolgte varer, nye produkter og sæsonmønstre
Sådan sætter du planlagt scraping op med Thunderbit
Thunderbit gør det absurd nemt.
Du beskriver planen i almindeligt sprog (f.eks. "hver mandag kl. 9"), indtaster Shopify-butikens URL'er og klikker "Planlæg". Thunderbit kører scraping automatisk og eksporterer til det valgte mål. Ingen cron-jobs, ingen kode, ingen tredjeparts-scheduler.
Planlægningssupport på tværs af alle 8 værktøjer
| Værktøj | Planlægning? |
|---|---|
| Thunderbit | Ja — planlægning i almindeligt sprog |
| Instant Data Scraper | Nej |
| Web Scraper | Ja — på cloud-planer |
| Data Miner | Automatiserede crawls findes, men ikke den enkleste planlægningsløsning |
| Simplescraper | Ja |
| Octoparse | Ja — på Standard og op |
| Bardeen | Ja — via tids-/datobaserede automations |
| Listly | Ja — på Business-planen |
Hvis løbende konkurrentovervågning er en del af dit workflow, er det en vigtig forskel. De fleste gratis Chrome-udvidelser tilbyder det slet ikke.
Hvilken Shopify scraper Chrome-udvidelse passer til dit behov?

I stedet for en generisk "vælg den, du bedst kan lide"-afslutning får du her en beslutningsmatrix mappet til konkrete brugsscenarier:
| Brugsscenarie | Bedste anbefaling | Hvorfor |
|---|---|---|
| Konkurrentprisanalyse | Thunderbit | Liste + berigelse af undersider + planlægning = komplet prisworkflow |
| Hurtig engangseksport | Instant Data Scraper | Hurtigste gratis vej, når du kun skal bruge synlige listesidedata |
| Katalogimport til din Shopify-butik | Thunderbit | Fuld data fra undersider + Shopify-importvenlig CSV/Excel-eksport |
| Løbende overvågning af pris/lager | Thunderbit eller Octoparse | Nemmest no-code planlægning vs. stærkest enterprise-lignende planlægning |
| Leadgenerering (kontakt til butiksejere) | Thunderbit | Indbyggede mail-/telefonudtrækkere + struktureret eksport |
| Komplekse flertrins-automations | Bardeen | Skrab, berig og send videre til downstream-apps i ét workflow |
| Tekniske brugere, der vil have fuld kontrol | Web Scraper eller Octoparse | Bedst manuel kontrol over selektorer, flow og udtrækslogik |
Afslutning
Shopify scraping i 2026 handler ikke om, hvorvidt du kan få produktdata ud — det handler om, hvor dybt, hvor hurtigt og hvor gentageligt dit workflow er. De fleste artikler i den her niche stopper ved listesiden. Den reelle værdi ligger i berigelse af undersider, planlagt overvågning og håndtering af de anti-bot-udfordringer, som virkelige Shopify-butikker kaster efter dig.
Hvis du vil se, hvordan det ser ud i praksis — fra kollektionsside til fuldt beriget datasæt på få klik — så prøv . Og hvis Thunderbit ikke er det perfekte match, er Instant Data Scraper et solidt gratis udgangspunkt til simple opgaver, mens Web Scraper og Octoparse er stærke valg for tekniske brugere, der vil have mere kontrol.
God scraping — og må dine produktdata altid være komplette, strukturerede og rige på varianter.
FAQ
1. Er det lovligt at scrape data fra Shopify-butikker?
Offentligt tilgængelige produktdata i Shopify-butikker er generelt tilgængelige for alle, der besøger sitet. Når det er sagt, afhænger lovligheden af din jurisdiktion, butikkens vilkår og hvad du gør med dataene. At scrape offentlige priser til konkurrentanalyse er almindelig praksis; at kopiere indhold i fuld skala og genudgive det indebærer større risiko. Det her er ikke juridisk rådgivning — tal med en fagperson om din konkrete situation.
2. Kan jeg scrape Shopify-butikker, der kræver login eller password?
Ja, men du skal bruge en browserbaseret scraper, der arbejder med din indloggede Chrome-session. Cloud scrapers kan som regel ikke tilgå sider bag login. Thunderbits browser-tilstand, Web Scraper (lokalt) og Simplescrapers login-workflows understøtter alle dette scenarie.
3. Hvor mange produkter kan jeg scrape fra en Shopify-butik på én gang?
Det afhænger af værktøjet og planen. Shopify's products.json-endpoint paginerer med . Thunderbits cloud-tilstand behandler op til 50 sider ad gangen. Gratis niveauer på tværs af de fleste værktøjer sætter loft over sider, rækker eller credits — så tjek dine planbegrænsninger, før du starter et stort job.
4. Hvad er forskellen på cloud scraping og browser scraping for Shopify?
Cloud scraping kører på eksterne servere — det er hurtigere og bedre til offentlige butikker uden anti-bot-beskyttelse. Browser scraping bruger din lokale Chrome-session, hvilket betyder, at den kan håndtere Cloudflare-beskyttede butikker, login-krævede butikker eller butikker med regionsfølsomt indhold. Thunderbit tilbyder begge tilstande, og valget afhænger typisk af, om butikken blokerer eksterne forespørgsler.
5. Kan jeg eksportere scraped Shopify-data direkte til Google Sheets eller Airtable?
Ja, men ikke alle værktøjer understøtter det. Thunderbit eksporterer til Google Sheets, Airtable, Notion, Excel, CSV og JSON — alt sammen gratis. Data Miner og Listly understøtter Google Sheets. Simplescraper understøtter Sheets og Airtable. Octoparse understøtter Google Sheets på premium-niveauer. Bardeen integrerer med Sheets, Airtable og Notion. Instant Data Scraper eksporterer kun til CSV og XLSX uden direkte Sheets-integration.
Læs mere