
Hvilket programmeringssprog bør du bruge til web scraping? Det kommer helt an på dit projekt — og jeg har seriøst set udviklere kaste håndklædet i ringen af ren frustration, fordi de valgte forkert fra start.
Markedet for web scraping-software ramte . Vælger du rigtigt, får du hurtigere resultater og mindre vedligehold. Vælger du forkert, ender du med scrapers der knækker, og weekender der bare… forsvinder.
Jeg har bygget automatiseringsværktøjer i årevis. Her får du syv sprog, jeg selv har brugt til scraping — med kodeeksempler, ærlige trade-offs og et kig på, hvornår du helt bør droppe at kode og i stedet bruge .
Sådan valgte vi det bedste sprog til web scraping
Når vi snakker web scraping, er alle sprog altså ikke skabt lige. Jeg har set projekter tage fart (og crashe hårdt) afhængigt af nogle få afgørende ting:
- Brugervenlighed: Hvor hurtigt kan du komme i gang? Er syntaksen til at arbejde med, eller føles det som om du skal have en PhD bare for at printe “Hello, World”?
- Biblioteker og værktøjer: Findes der solide biblioteker til HTTP-requests, HTML-parsing og håndtering af dynamisk indhold? Eller skal du bygge det hele selv fra bunden?
- Ydeevne: Kan det klare scraping af millioner af sider, eller går det i stå efter et par hundrede?
- Håndtering af dynamisk indhold: Moderne websites elsker JavaScript. Kan dit sprog følge med, eller bliver du hægtet af?
- Community og support: Når du rammer en mur (og det gør du), er der så et community, der kan hjælpe dig videre?
Ud fra de kriterier — og en del sene aftener med tests — er her de syv sprog, jeg gennemgår:
- Python: Standardvalget for både begyndere og garvede.
- JavaScript & Node.js: Konge til dynamisk indhold.
- Ruby: Pæn syntaks, hurtige scripts.
- PHP: Ligetil server-side tilgang.
- C++: Når du har brug for rå power.
- Java: Enterprise-klar og skalerbar.
- Go (Golang): Hurtig og stærk til concurrency.
Og hvis du tænker: “Shuai, jeg gider slet ikke kode,” så bliv hængende — Thunderbit kommer til sidst.
Python web scraping: Den begyndervenlige kraftpakke
Vi starter med publikumsfavoritten: Python. Hvis du spørger et rum fuld af datafolk: “Hvad er det bedste programmeringssprog til web scraping?” — så svarer de “Python” i kor, som var det en Taylor Swift-koncert.
Hvorfor Python?
- Begyndervenlig syntaks: Du kan nærmest læse Python-kode højt, og det lyder som almindeligt sprog.
- Uovertruffen bibliotekssupport: Fra til HTML-parsing, til til crawling i stor skala, til til HTTP, og til browser-automatisering — Python har hele pakken.
- Kæmpe community: Over om web scraping alene.
Eksempel i Python: Scrape en sidetitel
1import requests
2from bs4 import BeautifulSoup
3response = requests.get("<https://example.com>")
4soup = BeautifulSoup(response.text, 'html.parser')
5title = soup.title.string
6print(f"Page title: {title}")Styrker:
- Hurtig udvikling og prototyper.
- Masser af guides, tutorials og Q&A.
- Perfekt til dataarbejde — scrape med Python, analysér med pandas, visualisér med matplotlib.
Begrænsninger:
- Langsommere end kompilerede sprog ved meget store jobs.
- Meget dynamiske sites kan blive lidt bøvlede (selvom Selenium og Playwright hjælper).
- Ikke ideelt, hvis du skal scrape millioner af sider i lynfart.
Konklusion:
Hvis du er ny i scraping, eller bare vil have ting gjort hurtigt, er Python det bedste sprog til web scraping — punktum. .
JavaScript & Node.js: Scraping af dynamiske websites uden besvær
Hvis Python er en schweizerkniv, så er JavaScript (og Node.js) mere som en boremaskine — især når du skal scrape moderne websites, der er tunge på JavaScript.
Hvorfor JavaScript/Node.js?
- Naturligt valg til dynamisk indhold: Det kører i browseren og kan derfor “se” det samme som brugeren — også når siden er bygget med React, Angular eller Vue.
- Async som standard: Node.js kan håndtere hundredvis af requests parallelt.
- Velkendt for webudviklere: Har du bygget websites, kan du allerede en masse JavaScript.
Vigtige biblioteker:
- : Automatisering af headless Chrome.
- : Automatisering på tværs af flere browsere.
- : jQuery-lignende HTML-parsing til Node.
Eksempel i Node.js: Scrape en sidetitel med Puppeteer
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
6 const title = await page.title();
7 console.log(`Page title: ${title}`);
8 await browser.close();
9})();Styrker:
- Håndterer JavaScript-renderet indhold direkte.
- God til infinite scroll, pop-ups og interaktive sites.
- Effektiv til scraping i stor skala med høj grad af samtidighed.
Begrænsninger:
- Async-programmering kan være lidt af en mundfuld i starten.
- Headless browsere æder RAM, hvis du kører for mange på én gang.
- Færre værktøjer til dataanalyse end Python.
Hvornår er JavaScript/Node.js det bedste sprog til web scraping?
Når dit målsite er dynamisk, eller du vil automatisere browserhandlinger. .
Ruby: Ren syntaks til hurtige web scraping-scripts
Ruby er ikke kun Rails og kodepoesi. Det er også et fint valg til web scraping — især hvis du elsker, at koden læser som en lille haiku.
Hvorfor Ruby?
- Læsbar og udtryksfuld syntaks: Du kan skrive en scraper i Ruby, der næsten er lige så let at læse som din indkøbsliste.
- God til prototyper: Hurtig at skrive og nem at justere.
- Vigtige biblioteker: til parsing, til automatiseret navigation.
Eksempel i Ruby: Scrape en sidetitel
1require 'open-uri'
2require 'nokogiri'
3html = URI.open("<https://example.com>")
4doc = Nokogiri::HTML(html)
5title = doc.at('title').text
6puts "Page title: #{title}"Styrker:
- Meget læsbart og kortfattet.
- Godt til små projekter, engangsscripts eller hvis du allerede bruger Ruby.
Begrænsninger:
- Langsommere end Python eller Node.js ved større jobs.
- Færre scraping-biblioteker og mindre scraping-fokuseret community.
- Ikke ideelt til JavaScript-tunge sites (selvom du kan bruge Watir eller Selenium).
Bedst til:
Hvis du er Rubyist eller vil lave et hurtigt script, er Ruby en fornøjelse. Til massiv, dynamisk scraping bør du kigge andre steder.
PHP: Enkel server-side dataudtrækning
PHP kan føles som et levn fra internettets barndom, men det lever i bedste velgående — især hvis du vil scrape data direkte på din server.
Hvorfor PHP?
- Kører næsten overalt: De fleste webservere har allerede PHP.
- Nem integration i webapps: Scrape og vis data på dit site i samme flow.
- Vigtige biblioteker: til HTTP, til requests, til headless browser-automatisering.
Eksempel i PHP: Scrape en sidetitel
1<?php
2$ch = curl_init("<https://example.com>");
3curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
4$html = curl_exec($ch);
5curl_close($ch);
6$dom = new DOMDocument();
7@$dom->loadHTML($html);
8$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
9echo "Page title: $title\n";
10?>Styrker:
- Let at deploye på webservere.
- Godt, når scraping er en del af et webflow.
- Hurtigt til simple server-side scraping-opgaver.
Begrænsninger:
- Begrænset bibliotekssupport til avanceret scraping.
- Ikke bygget til høj concurrency eller scraping i stor skala.
- JavaScript-tunge sites er svære (selvom Panther kan hjælpe).
Bedst til:
Hvis din stack allerede er PHP, eller du vil scrape og vise data på dit site, er PHP et praktisk valg. .
C++: Højtydende web scraping til store projekter
C++ er muskelbilen blandt programmeringssprog. Hvis du har brug for maksimal hastighed og fuld kontrol — og ikke er bange for at få lidt olie på fingrene — kan C++ være vejen frem.
Hvorfor C++?
- Ekstremt hurtigt: Slår de fleste sprog i CPU-tunge opgaver.
- Detaljeret kontrol: Styr hukommelse, tråde og performance-tuning.
- Vigtige biblioteker: til HTTP, til parsing.
Eksempel i C++: Scrape en sidetitel
1#include <curl/curl.h>
2#include <iostream>
3#include <string>
4size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
5 std::string* html = static_cast<std::string*>(userp);
6 size_t totalSize = size * nmemb;
7 html->append(static_cast<char*>(contents), totalSize);
8 return totalSize;
9}
10int main() {
11 CURL* curl = curl_easy_init();
12 std::string html;
13 if(curl) {
14 curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
15 curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
16 curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
17 CURLcode res = curl_easy_perform(curl);
18 curl_easy_cleanup(curl);
19 }
20 std::size_t startPos = html.find("<title>");
21 std::size_t endPos = html.find("</title>");
22 if(startPos != std::string::npos && endPos != std::string::npos) {
23 startPos += 7;
24 std::string title = html.substr(startPos, endPos - startPos);
25 std::cout << "Page title: " << title << std::endl;
26 } else {
27 std::cout << "Title tag not found" << std::endl;
28 }
29 return 0;
30}Styrker:
- Uovertruffen hastighed til enorme scraping-jobs.
- Godt til at bygge scraping ind i højtydende systemer.
Begrænsninger:
- Stejl læringskurve (sæt kaffen over).
- Manuel hukommelsesstyring.
- Få high-level biblioteker; ikke ideelt til dynamisk indhold.
Bedst til:
Når du skal scrape millioner af sider, eller performance er helt afgørende. Ellers risikerer du at bruge mere tid på debugging end på scraping.
Java: Enterprise-klar web scraping
Java er arbejdshesten i enterprise-verdenen. Hvis du bygger noget, der skal køre længe, håndtere store datamængder og overleve lidt af hvert, er Java et stærkt bud.
Hvorfor Java?
- Robust og skalerbart: Perfekt til store, langvarige scraping-projekter.
- Stærk typing og fejlhåndtering: Færre ubehagelige overraskelser i produktion.
- Vigtige biblioteker: til parsing, til browser-automatisering, til HTTP.
Eksempel i Java: Scrape en sidetitel
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3public class ScrapeTitle {
4 public static void main(String[] args) throws Exception {
5 Document doc = Jsoup.connect("<https://example.com>").get();
6 String title = doc.title();
7 System.out.println("Page title: " + title);
8 }
9}Styrker:
- Høj ydeevne og god concurrency.
- Fremragende til store, vedligeholdelige kodebaser.
- God støtte til dynamisk indhold (via Selenium eller HtmlUnit).
Begrænsninger:
- Verbos syntaks; mere opsætning end scripting-sprog.
- Overkill til små engangsopgaver.
Bedst til:
Scraping i enterprise-skala, eller når du har brug for høj driftssikkerhed og skalerbarhed.
Go (Golang): Hurtig og parallel web scraping
Go er relativt nyt, men har allerede fået seriøst momentum — især til højhastigheds-scraping med concurrency.
Hvorfor Go?
- Kompileret hastighed: Næsten på niveau med C++.
- Indbygget concurrency: Goroutines gør parallel scraping overraskende ligetil.
- Vigtige biblioteker: til scraping, til parsing.
Eksempel i Go: Scrape en sidetitel
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly"
5)
6func main() {
7 c := colly.NewCollector()
8 c.OnHTML("title", func(e *colly.HTMLElement) {
9 fmt.Println("Page title:", e.Text)
10 })
11 err := c.Visit("<https://example.com>")
12 if err != nil {
13 fmt.Println("Error:", err)
14 }
15}Styrker:
- Meget hurtigt og ressourceeffektivt til scraping i stor skala.
- Nem deployment (én binær fil).
- Stærkt til concurrent crawling.
Begrænsninger:
- Mindre community end Python eller Node.js.
- Færre high-level scraping-biblioteker.
- JavaScript-tunge sites kræver ekstra opsætning (Chromedp eller Selenium).
Bedst til:
Når du skal scrape i stor skala, eller Python ikke er hurtigt nok. .
Sammenligning af de bedste programmeringssprog til web scraping
Lad os samle trådene. Her er en side-om-side sammenligning, så du kan vælge det bedste sprog til web scraping i 2026:
| Sprog/Værktøj | Brugervenlighed | Ydeevne | Bibliotekssupport | Håndtering af dynamisk indhold | Bedste use case |
|---|---|---|---|---|---|
| Python | Meget høj | Moderat | Fremragende | God (Selenium/Playwright) | Allround, begyndere, dataanalyse |
| JavaScript/Node.js | Mellem | Høj | Stærk | Fremragende (native) | Dynamiske sites, async scraping, webudviklere |
| Ruby | Høj | Moderat | Ok | Begrænset (Watir) | Hurtige scripts, prototyper |
| PHP | Mellem | Moderat | Rimelig | Begrænset (Panther) | Server-side, integration i webapps |
| C++ | Lav | Meget høj | Begrænset | Meget begrænset | Performance-kritisk, ekstrem skala |
| Java | Mellem | Høj | God | God (Selenium/HtmlUnit) | Enterprise, langkørende services |
| Go (Golang) | Mellem | Meget høj | Voksende | Moderat (Chromedp) | Høj hastighed, concurrent scraping |
Hvornår du bør droppe kodning: Thunderbit som no-code løsning til web scraping
Lad os være helt ærlige: Nogle gange vil du bare have data — uden kodning, debugging og “hvorfor virker den selector ikke”-hovedpine. Det er præcis her kommer ind i billedet.
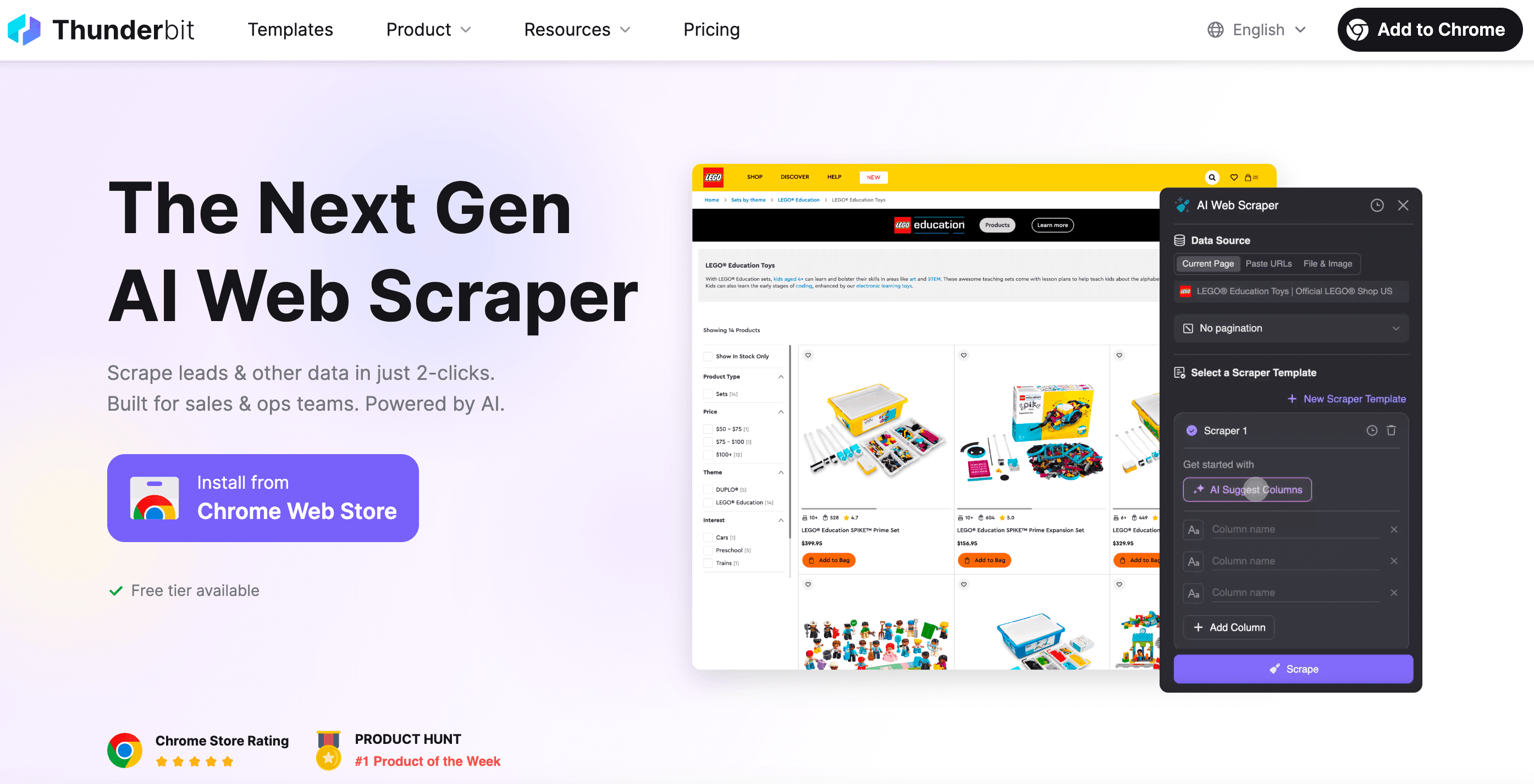
Som medstifter af Thunderbit ville jeg bygge et værktøj, der gør web scraping lige så nemt som at bestille takeaway. Her er det, der gør Thunderbit anderledes:
- Opsætning i 2 klik: Klik på “AI Suggest Fields” og derefter “Scrape”. Ingen bøvl med HTTP-requests, proxies eller anti-bot tricks.
- Smarte skabeloner: Én scraper template kan tilpasse sig flere sidelayouts. Du behøver ikke omskrive din scraper, hver gang et site ændrer sig.
- Browser- og cloud-scraping: Vælg mellem scraping i din browser (perfekt til sites med login) eller i skyen (super hurtigt til offentlige data).
- Håndterer dynamisk indhold: Thunderbits AI styrer en rigtig browser — så den kan klare infinite scroll, pop-ups, logins og meget mere.
- Eksportér hvor du vil: Download til Excel, Google Sheets, Airtable, Notion — eller kopier direkte til udklipsholderen.
- Ingen vedligehold: Hvis et site ændrer sig, kører du bare AI-forslaget igen. Slut med sene debugging-nætter.
- Planlægning og automatisering: Sæt scrapers til at køre efter en tidsplan — ingen cron jobs og ingen serveropsætning.
- Specialiserede extractors: Skal du bruge emails, telefonnumre eller billeder? Thunderbit har one-click extractors til det også.
Og det bedste? Du behøver ikke kunne én eneste linje kode. Thunderbit er lavet til business-brugere, marketing, salg, ejendomsmæglere — alle der har brug for data hurtigt.
Vil du se Thunderbit i praksis? eller kig forbi vores for demoer.
Konklusion: Sådan vælger du det bedste sprog til web scraping i 2026
Web scraping i 2026 er mere tilgængeligt — og mere kraftfuldt — end nogensinde før. Her er mine vigtigste takeaways efter år i automatiserings-skyttegravene:
- Python er stadig det bedste sprog til web scraping, hvis du vil i gang hurtigt og have masser af ressourcer lige ved hånden.
- JavaScript/Node.js er suverænt til dynamiske, JavaScript-tunge sites.
- Ruby og PHP er stærke til hurtige scripts og web-integration, især hvis du allerede bruger dem.
- C++ og Go er oplagte, når du har brug for fart og skala.
- Java er et sikkert valg til enterprise og langsigtede projekter.
- Og hvis du vil springe kodning helt over? er dit hemmelige våben.
Inden du går i gang, så spørg dig selv:
- Hvor stort er mit projekt?
- Skal jeg håndtere dynamisk indhold?
- Hvor tryg er jeg teknisk?
- Vil jeg bygge noget — eller bare have data?
Prøv et af kodeeksemplerne ovenfor, eller giv Thunderbit et skud til dit næste projekt. Og hvis du vil nørde videre, så kig forbi for flere guides, tips og historier fra virkeligheden.
God scraping — og må dine data altid være rene, strukturerede og kun et klik væk.
P.S. Hvis du nogensinde ender i et web scraping-kaninhul kl. 02 om natten, så husk: Der er altid Thunderbit. Eller kaffe. Eller begge dele.
FAQs
1. Hvad er det bedste programmeringssprog til web scraping i 2026?
Python er fortsat førstevalget takket være den læsbare syntaks, stærke biblioteker (som BeautifulSoup, Scrapy og Selenium) og et stort community. Det passer både til begyndere og erfarne — især hvis du kombinerer scraping med dataanalyse.
2. Hvilket sprog er bedst til at scrape JavaScript-tunge websites?
JavaScript (Node.js) er det bedste valg til dynamiske sites. Værktøjer som Puppeteer og Playwright giver fuld browserkontrol, så du kan interagere med indhold, der indlæses via React, Vue eller Angular.
3. Findes der en no-code mulighed til web scraping?
Ja — er en no-code AI Web Scraper, der klarer alt fra dynamisk indhold til planlægning. Klik blot på “AI Suggest Fields” og begynd at scrape. Perfekt til salg, marketing eller driftsteams, der hurtigt skal bruge strukturerede data.
Læs mere: