

Webdata er standardinput til salg, marketing og drift. Hvis du stadig sidder og kopierer og indsætter manuelt, er du allerede bagud.
Men her er problemet med “gratis” scrapingværktøjer: de fleste er slet ikke rigtig gratis. Enten er det prøveperioder med stramme begrænsninger, eller også er de funktioner, du faktisk har brug for, gemt bag en betalingsmur.
Jeg testede 12 værktøjer for at finde ud af, hvilke der faktisk lader dig lave reelt arbejde på gratisniveauet. Jeg scrape’ede Google Maps-lister, dynamiske sider bag login og PDF-filer. Nogle leverede varen. Andre spildte bare min eftermiddag.
Her får du den ærlige gennemgang — og jeg starter med dem, jeg faktisk vil anbefale.
Hvorfor gratis scrapers er vigtigere end nogensinde
Lad os være ærlige: I 2026 er web scraping ikke længere kun for hackere eller data scientists. Det er blevet et fast værktøj i moderne virksomheder, og tallene bakker det op. Markedet for web scraping software nåede 1,01 mia. dollars i 2024, og det forventes at mere end fordobles frem mod 2032. Hvorfor? Fordi alle fra salgsteams til ejendomsmæglere bruger webdata til at komme foran.
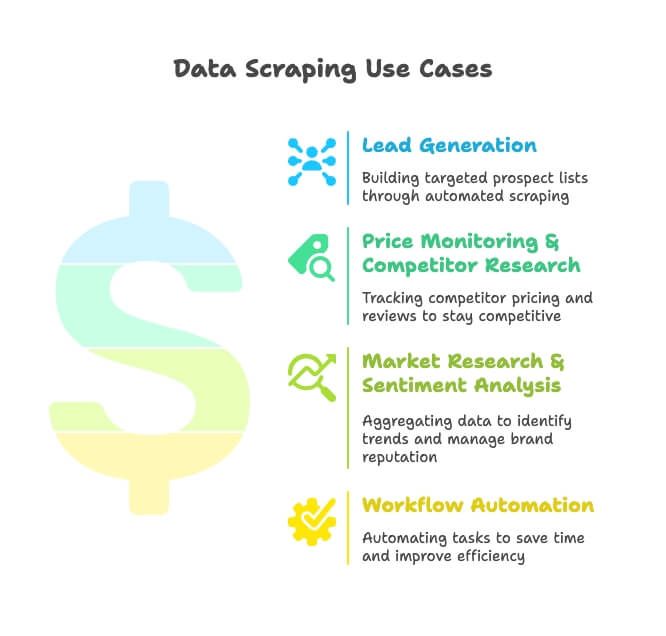
- Leadgenerering: Salgsteams scraper kataloger, Google Maps og sociale medier for at bygge målrettede prospektlister — farvel til manuelt benarbejde.
- Prisovervågning og konkurrentanalyse: E-commerce- og retailteams følger konkurrenternes produkter, priser og anmeldelser for at holde sig skarpe (og ja, 82 % af e-handelsvirksomheder scraper netop af den grund).
- Markedsresearch og sentimentanalyse: Marketingfolk samler anmeldelser, nyheder og sociale signaler for at spotte trends og styre brandets omdømme.
- Workflow-automatisering: Driftsteams automatiserer alt fra lagerkontrol til planlagte rapporter og sparer timer hver uge.
Og her er en sjov statistik: Virksomheder, der bruger AI-drevne web scrapers, sparer 30–40 % af deres tid sammenlignet med manuelle metoder. Det er ikke bare lidt tid — det er forskellen på at gå hjem kl. 18 eller kl. 21.
Sådan udvalgte vi de bedste gratis data scraper-værktøjer
Jeg har set mange “bedste web scraper”-lister, der bare genbruger marketingtekst. Ikke her. Til denne liste kiggede jeg på:
- Reel brugbarhed på gratisplanen: Kan gratisniveauet bruges til rigtigt arbejde, eller er det bare en lokkefælde?
- Brugervenlighed: Kan en uden kode få resultater på få minutter, eller kræver det en ph.d. i Regex?
- Understøttede websidetyper: Statiske sider, dynamiske sider, sider med pagination, login-beskyttede sider, PDF’er, sociale medier — kan værktøjet håndtere virkelige scenarier?
- Eksportmuligheder: Kan du få data ind i Excel, Google Sheets, Notion eller Airtable uden bøvl?
- Ekstra funktioner: AI-drevet udtræk, planlægning, skabeloner, efterbehandling, integrationer.
- Målgruppe: Er værktøjet til forretningsbrugere, analytikere eller udviklere?
Jeg gennemgik også dokumentationen for hvert værktøj, testede onboarding og sammenlignede begrænsningerne på gratisplanerne — fordi “gratis” ikke altid er så gratis, som det lyder.
Overblik: 12 gratis data scrapers sammenlignet
Her er et hurtigt side om side-overblik, så du nemt kan finde det rette værktøj til dit behov.
| Værktøj | Platform | Begrænsninger på gratisplan | Bedst til | Eksportformater | Unikke funktioner |
|---|---|---|---|---|---|
| Thunderbit | Chrome-udvidelse | 6 sider/måned | Ikke-kodere, virksomheder | Excel, CSV | AI-prompter, PDF-/billedscraping, subpage crawl |
| Browse AI | Cloud | 50 credits/måned | No-code-brugere | CSV, Sheets | Point-and-click-robotter, planlægning |
| Octoparse | Desktop | 10 opgaver, 50k rækker/måned | No-code, semi-tekniske brugere | CSV, Excel, JSON | Visuelt workflow, understøttelse af dynamiske sider |
| ParseHub | Desktop | 5 projekter, 200 sider/kørsel | No-code, semi-tekniske brugere | CSV, Excel, JSON | Visuelt, understøttelse af dynamiske sider |
| Webscraper.io | Chrome-udvidelse | Ubegrænset lokal brug | No-code, simple opgaver | CSV, XLSX | Sitemap-baseret, community-skabeloner |
| Apify | Cloud | 5 dollars i credits/måned | Teams, semi-tekniske brugere, udviklere | CSV, JSON, Sheets | Actor-markedsplads, planlægning, API |
| Scrapy | Python-bibliotek | Ubegrænset (open source) | Udviklere | CSV, JSON, DB | Fuld kodekontrol, skalerbar |
| Puppeteer | Node.js-bibliotek | Ubegrænset (open source) | Udviklere | Brugerdefineret (kode) | Headless browser, understøttelse af dynamisk JavaScript |
| Selenium | Flere sprog | Ubegrænset (open source) | Udviklere | Brugerdefineret (kode) | Browserautomatisering, understøttelse af flere browsere |
| Zyte | Cloud | 1 spider, 1 time/job, 7 dages opbevaring | Udviklere, driftsteams | CSV, JSON | Hosted Scrapy, proxyhåndtering |
| SerpAPI | API | 100 søgninger/måned | Udviklere, analytikere | JSON | Søgemaskine-API’er, anti-blocking |
| Diffbot | API | 10.000 credits/måned | Udviklere, AI-projekter | JSON | AI-udtræk, knowledge graph |
Thunderbit: Det bedste valg til AI-drevet og brugervenlig data scraping
Scrape data fra enhver hjemmeside med AI Get Started Free
Lad os tale om, hvorfor Thunderbit ligger øverst på min liste. Jeg siger ikke bare det her, fordi jeg er en del af teamet — jeg mener oprigtigt, at Thunderbit er det tætteste, man kommer på en AI-praktikant, der faktisk lytter (og ikke beder om kaffepauser).
Thunderbit er ikke den klassiske “lær værktøjet først, og scrape bagefter”-oplevelse. Det føles mere som at give instruktioner til en smart assistent: Du beskriver, hvad du vil have (“Hent alle produktnavne, priser og links fra siden”), og Thunderbits AI finder resten ud af det. Ingen XPath, ingen CSS-selectors, ingen Regex-hovedpine. Og hvis du vil scrape undersider som produktsider eller virksomheds kontaktlinks, kan Thunderbit automatisk klikke sig videre og berige din tabel — igen bare ved at trykke på en knap.
Men det, der virkelig skiller Thunderbit ud, er det, der sker efter selve scrapen. Har du brug for at opsummere, oversætte, kategorisere eller rydde op i dataene? Thunderbits indbyggede AI-efterbehandling klarer det. Du får ikke bare rå data — du får strukturerede, brugbare oplysninger, der er klar til CRM, regneark eller dit næste store projekt.
Gratisplan: Thunderbits gratis prøveperiode giver dig mulighed for at scrape op til 6 sider (eller 10 med prøveboost), inklusive PDF’er, billeder og endda skabeloner til sociale medier. Du kan eksportere til Excel eller CSV gratis og prøve funktioner som udtræk af e-mail, telefon og billeder. Til større opgaver låser betalte planer op for flere sider, direkte eksport til Google Sheets/Notion/Airtable, planlagt scraping og instant templates til populære sider som Amazon, Google Maps og Instagram.
Hvis du vil se Thunderbit i aktion, så tjek Thunderbit Chrome-udvidelsen eller besøg vores YouTube-kanal for hurtige introduktionsvideoer.
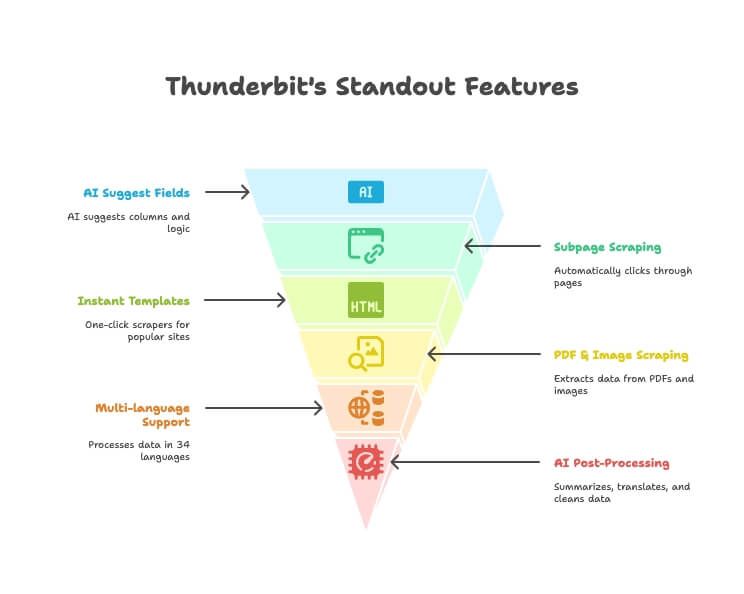
Thunderbits stærkeste funktioner
- AI-forslag til felter: Beskriv bare de data, du vil have, så foreslår Thunderbits AI de rigtige kolonner og udtrækslogik.
- Scraping af undersider: Klik automatisk ind på detaljesider eller links og berig din hovedtabel — ingen manuel opsætning.
- Instant templates: Scrapers med ét klik til Amazon, Google Maps, Instagram og meget mere.
- PDF- og billedscraping: Udtræk tabeller og data fra PDF’er og billeder ved hjælp af AI — uden ekstra værktøjer.
- Understøttelse af flere sprog: Scrape og behandl data på 34 sprog.
- Direkte eksport: Send dine data direkte til Excel, Google Sheets, Notion eller Airtable (betalte planer).
- AI-efterbehandling: Opsummer, oversæt, kategorisér og rens data, mens du scraper.
- Gratis udtræk af e-mail/telefon/billeder: Hent kontaktoplysninger eller billeder fra enhver side med ét klik.
Thunderbit bygger bro mellem “bare at scrape data” og “at få data, du faktisk kan bruge”. Det er det tætteste, jeg har set på en ægte AI-dataassistent til forretningsbrugere.
Resten af top 12: Gennemgang af gratis data scraper-værktøjer
Lad os gennemgå resten af feltet, opdelt efter hvem de passer bedst til.
Til no-code- og forretningsbrugere
Thunderbit
Allerede gennemgået ovenfor. Den nemmeste vej ind for ikke-kodere, med AI-funktioner og instant templates.
Webscraper.io
- Platform: Chrome-udvidelse
- Bedst til: Enkle, statiske sider; ikke-kodere, der ikke har noget imod lidt trial and error.
- Nøglefunktioner: Sitemap-baseret scraping, understøtter pagination, eksport til CSV/XLSX.
- Gratisplan: Ubegrænset lokal brug, men ingen cloud-kørsler eller planlægning. Kun manuel brug.
- Begrænsninger: Ingen indbygget håndtering af login, PDF’er eller komplekst dynamisk indhold. Kun community-support.
ParseHub
- Platform: Desktop-app (Windows, Mac, Linux)
- Bedst til: Ikke-kodere og semi-tekniske brugere, der vil investere tid i at lære det.
- Nøglefunktioner: Visuel workflow-bygger, understøtter dynamiske sider, AJAX, logins og pagination.
- Gratisplan: 5 offentlige projekter, 200 sider pr. kørsel, kun manuelle kørsler.
- Begrænsninger: Projekter er offentlige på gratisplanen (vær forsigtig med følsomme data), ingen planlægning, langsommere udtræk.
Octoparse
- Platform: Desktop-app (Windows/Mac), Cloud (betalt)
- Bedst til: Ikke-kodere og analytikere, der vil have kraft og fleksibilitet.
- Nøglefunktioner: Visuel point-and-click, understøttelse af dynamisk indhold, skabeloner til populære sider.
- Gratisplan: 10 opgaver, op til 50.000 rækker/måned, kun desktop (ingen cloud/planlægning).
- Begrænsninger: Ingen API, IP-rotation eller planlægning på gratisniveau. Læringskurven kan være stejl for komplekse sider.
Browse AI
- Platform: Cloud
- Bedst til: No-code-brugere, der vil automatisere enkel scraping og overvågning.
- Nøglefunktioner: Point-and-click robotoptager, planlægning, integrationer (Sheets, Zapier).
- Gratisplan: 50 credits/måned, 1 website, op til 5 robotter.
- Begrænsninger: Begrænset volumen, en vis indledende læringskurve ved komplekse sider.
Til udviklere og tekniske brugere
Scrapy
- Platform: Python-bibliotek (open source)
- Bedst til: Udviklere, der vil have fuld kontrol og skalerbarhed.
- Nøglefunktioner: Meget fleksibelt, understøtter store crawls, middleware og pipelines.
- Gratisplan: Ubegrænset (open source).
- Begrænsninger: Ingen GUI, kræver Python-kode. Ikke til ikke-kodere.
Puppeteer
- Platform: Node.js-bibliotek (open source)
- Bedst til: Udviklere, der scraper dynamiske sider med meget JavaScript.
- Nøglefunktioner: Headless browser-automatisering, fuld kontrol over navigation og udtræk.
- Gratisplan: Ubegrænset (open source).
- Begrænsninger: Kræver JavaScript-kodning, ingen GUI.
Selenium
- Platform: Flere sprog (Python, Java osv.), open source
- Bedst til: Udviklere, der automatiserer browsere til scraping eller test.
- Nøglefunktioner: Understøtter flere browsere, automatiserer klik, scroll og login.
- Gratisplan: Ubegrænset (open source).
- Begrænsninger: Langsommere end headless-biblioteker, kræver scripting.
Zyte (Scrapy Cloud)
- Platform: Cloud
- Bedst til: Udviklere og driftsteams, der vil køre Scrapy-spiders i stor skala.
- Nøglefunktioner: Hosted Scrapy, proxyhåndtering, jobplanlægning.
- Gratisplan: 1 samtidige spider, 1 time/job, 7 dages dataopbevaring.
- Begrænsninger: Ingen avanceret planlægning på gratisplanen, kræver kendskab til Scrapy.
Til teams og enterprise-brug
Apify
- Platform: Cloud
- Bedst til: Teams, semi-tekniske brugere og udviklere, der vil bruge færdige eller brugerdefinerede scrapers.
- Nøglefunktioner: Actor-markedsplads (færdige bots), planlægning, API, integrationer.
- Gratisplan: 5 dollars i credits/måned (nok til små opgaver), 7 dages dataopbevaring.
- Begrænsninger: Visse læringskurver, brug er begrænset af credits.
SerpAPI
- Platform: API
- Bedst til: Udviklere og analytikere, der har brug for data fra søgemaskiner (Google, Bing, YouTube).
- Nøglefunktioner: Søge-API’er, anti-blocking, struktureret JSON-output.
- Gratisplan: 100 søgninger/måned.
- Begrænsninger: Ikke til vilkårlige websites, kun API-brug.
Diffbot
- Platform: API
- Bedst til: Udviklere, AI/ML-teams og virksomheder, der har brug for strukturerede webdata i stor skala.
- Nøglefunktioner: AI-drevet udtræk, knowledge graph, artikel- og produkt-API’er.
- Gratisplan: 10.000 credits/måned.
- Begrænsninger: Kun API, kræver tekniske færdigheder, throughput er rate-limited.
Begrænsninger på gratisplanen: Hvad “gratis” egentlig betyder for hver data scraper
Lad os være ærlige — “gratis” kan betyde alt fra “ubegrænset for hobbybrugere” til “lige nok til at få dig hooked.” Her er, hvad du faktisk får:
| Værktøj | Sider/rækker pr. måned | Eksportformater | Planlægning | API-adgang | Vigtige begrænsninger på gratisplanen |
|---|---|---|---|---|---|
| Thunderbit | 6 sider | Excel, CSV | Nej | Nej | AI-forslag til felter er begrænset, ingen direkte eksport til Sheets/Notion på gratis |
| Browse AI | 50 credits | CSV, Sheets | Ja | Ja | 1 website, 5 robotter, 15 dages opbevaring |
| Octoparse | 50.000 rækker | CSV, Excel, JSON | Nej | Nej | Kun desktop, ingen cloud/planlægning |
| ParseHub | 200 sider/kørsel | CSV, Excel, JSON | Nej | Nej | 5 offentlige projekter, lav hastighed |
| Webscraper.io | Ubegrænset lokalt | CSV, XLSX | Nej | Nej | Manuelle kørsler, ingen cloud |
| Apify | 5 dollars i credits (~lille brug) | CSV, JSON, Sheets | Ja | Ja | 7 dages opbevaring, credit-loft |
| Scrapy | Ubegrænset | CSV, JSON, DB | Nej | N/A | Kræver kodning |
| Puppeteer | Ubegrænset | Brugerdefineret (kode) | Nej | N/A | Kræver kodning |
| Selenium | Ubegrænset | Brugerdefineret (kode) | Nej | N/A | Kræver kodning |
| Zyte | 1 spider, 1 time/job | CSV, JSON | Begrænset | Ja | 7 dages opbevaring, 1 samtidig jobkørsel |
| SerpAPI | 100 søgninger | JSON | Nej | Ja | Kun søge-API’er |
| Diffbot | 10.000 credits | JSON | Nej | Ja | Kun API, rate-limited |
Kort sagt: Til rigtige projekter tilbyder Thunderbit, Browse AI og Apify de mest brugbare gratis prøveperioder for forretningsbrugere. Til løbende eller større scraping rammer du hurtigt loftet og må opgradere eller skifte til open source-/kodebaserede løsninger.
Hvilket data scraper-værktøj passer bedst til dig? (Guide efter bruger-type)
Her er et hurtigt cheat sheet, der hjælper dig med at vælge ud fra rolle og teknisk niveau:
| Brugertype | Bedste værktøjer (gratis) | Hvorfor |
|---|---|---|
| Ikke-koder (salg/marketing) | Thunderbit, Browse AI, Webscraper.io | Hurtigst at lære, point-and-click, AI-hjælp |
| Semi-teknisk (drift/analytiker) | Octoparse, ParseHub, Apify, Zyte | Mere kraft, kan håndtere komplekse sider, noget scripting muligt |
| Udvikler/ingeniør | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | Fuld kontrol, ubegrænset, API-first |
| Team/enterprise | Apify, Zyte | Samarbejde, planlægning, integrationer |
Scenarier fra den virkelige verden: Sammenligning af værktøjernes fleksibilitet
Lad os se, hvordan værktøjerne klarer sig i fem almindelige scraping-scenarier:
| Scenarie | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lister med pagination | Let | Let | Mellem | Mellem | Mellem | Let | Let | Let | Let | Let | N/A | Mellem |
| Google Maps-lister | Let* | Svært | Mellem | Mellem | Svært | Let | Svært | Svært | Svært | Svært | Let | N/A |
| Login-beskyttede sider | Let | Mellem | Mellem | Mellem | Manuel | Mellem | Let | Let | Let | Let | N/A | N/A |
| PDF-dataudtræk | Let | Nej | Nej | Nej | Nej | Mellem | Svært | Svært | Svært | Svært | Nej | Begrænset |
| Indhold fra sociale medier | Let* | Delvist | Svært | Svært | Svært | Let | Svært | Svært | Svært | Svært | YouTube | Begrænset |
- Thunderbit og Apify tilbyder færdige skabeloner/actors til Google Maps og scraping af sociale medier, hvilket gør disse scenarier langt nemmere for ikke-tekniske brugere.
Plugin vs. desktop vs. cloud: Hvilken oplevelse er bedst med et web scraper-værktøj?
- Chrome-udvidelser (Thunderbit, Webscraper.io):
- Fordele: Hurtig opstart, kører i browseren, minimal opsætning.
- Ulemper: Manuel brug, kan påvirkes af ændringer på siden, begrænset automatisering.
- Thunderbits fordel: AI håndterer ændringer i struktur, navigation til undersider og endda PDF-/billedscraping — hvilket gør det langt mere robust end traditionelle udvidelser.
- Desktop-apps (Octoparse, ParseHub):
- Fordele: Kraftfulde, visuelle workflows, håndterer dynamiske sider og logins.
- Ulemper: Stejlere læringskurve, ingen cloud-automatisering på gratisplaner, afhængige af operativsystem.
- Cloud-platforme (Browse AI, Apify, Zyte):
- Fordele: Planlægning, teamsamarbejde, skalerbarhed, integrationer.
- Ulemper: Gratisplaner er ofte begrænset af credits, kræver noget opsætning og muligvis API-viden.
- Open source-biblioteker (Scrapy, Puppeteer, Selenium):
- Fordele: Ubegrænsede, fleksible, ideelle til udviklere.
- Ulemper: Kræver kodning, ikke til forretningsbrugere.
Web scraping-trends i 2026: Det, der adskiller moderne værktøjer
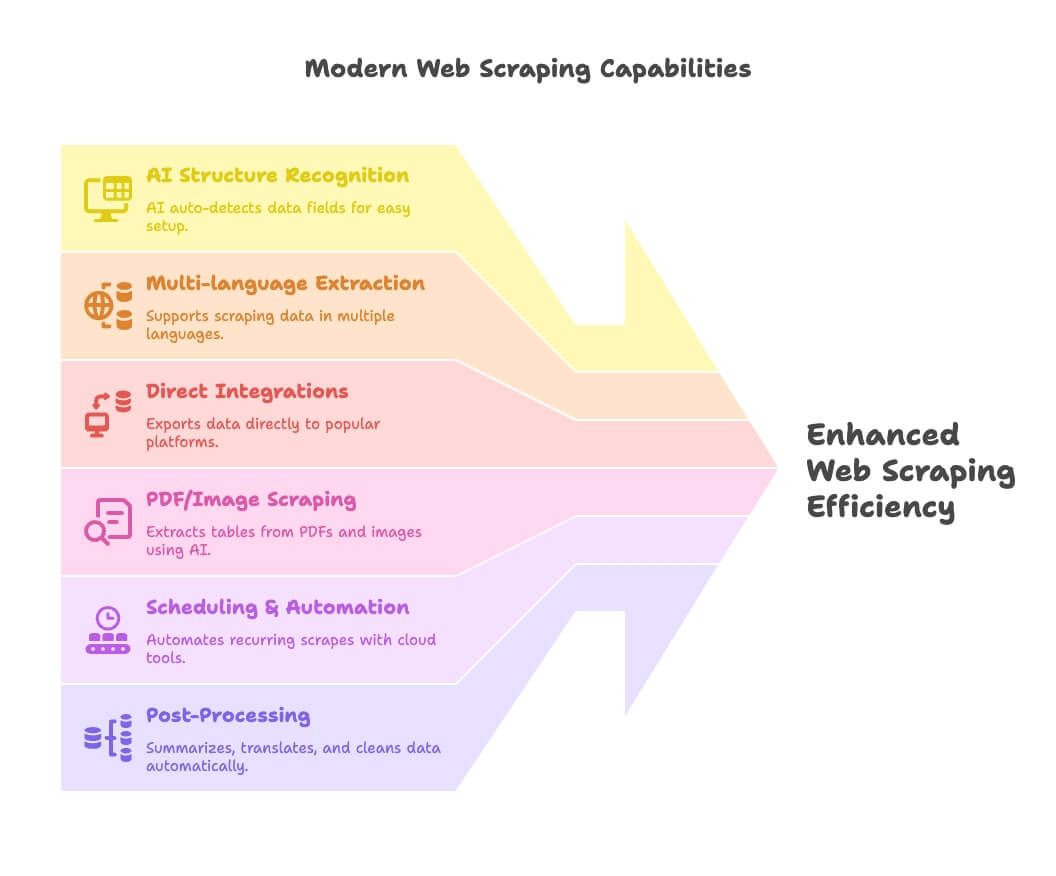
Web scraping i 2026 handler om AI, automatisering og integration. Her er det nye:
- AI-baseret strukturgenkendelse: Værktøjer som Thunderbit bruger AI til automatisk at finde datafelter, så opsætningen bliver legende let for ikke-kodere.
- Udtræk på flere sprog: Thunderbit og andre understøtter scraping og behandling af data på dusinvis af sprog.
- Direkte integrationer: Eksporter scraped data direkte til Google Sheets, Notion eller Airtable — slut med CSV-bøvl.
- PDF-/billedscraping: Thunderbit fører an her og gør det muligt at udtrække tabeller fra PDF’er og billeder med AI.
- Planlægning og automatisering: Cloud-værktøjer som Apify og Browse AI lader dig sætte det op én gang og lade det køre igen og igen.
- Efterbehandling: Opsummer, oversæt, kategorisér og rens data, mens du scraper — slut med rodede regneark.
Thunderbit, Apify og SerpAPI ligger i front på disse trends, men Thunderbit skiller sig ud ved at gøre AI-drevet scraping tilgængelig for alle, ikke kun udviklere.
Mere end scraping: Datahåndtering og værdiskabende funktioner
Det handler ikke kun om at hente data — det handler om at gøre den anvendelig. Her er, hvordan de bedste værktøjer klarer sig på efterbehandling:
| Værktøj | Rensning | Oversættelse | Kategorisering | Opsummering | Noter |
|---|---|---|---|---|---|
| Thunderbit | Ja | Ja | Ja | Ja | Indbygget AI-efterbehandling |
| Apify | Delvist | Delvist | Delvist | Delvist | Afhænger af den actor, du bruger |
| Browse AI | Nej | Nej | Nej | Nej | Kun rå data |
| Octoparse | Delvist | Nej | Delvist | Nej | Noget feltbehandling |
| ParseHub | Delvist | Nej | Delvist | Nej | Noget feltbehandling |
| Webscraper.io | Nej | Nej | Nej | Nej | Kun rå data |
| Scrapy | Ja* | Ja* | Ja* | Ja* | Hvis det er kodet af en udvikler |
| Puppeteer | Ja* | Ja* | Ja* | Ja* | Hvis det er kodet af en udvikler |
| Selenium | Ja* | Ja* | Ja* | Ja* | Hvis det er kodet af en udvikler |
| Zyte | Delvist | Nej | Delvist | Nej | Nogle automatiske udtræksfunktioner |
| SerpAPI | Nej | Nej | Nej | Nej | Kun strukturerede søgedata |
| Diffbot | Ja | Ja | Ja | Ja | AI-drevet, men kun via API |
- Udvikleren skal selv implementere behandlingslogikken.
Thunderbit er det eneste værktøj, der lader ikke-tekniske brugere gå fra rå webdata til brugbare, strukturerede indsigter — alt i én arbejdsgang.
Community, support og læringsressourcer: Sådan kommer du hurtigt i gang
Dokumentation og onboarding betyder meget — virkelig meget. Sådan klarer værktøjerne sig:
| Værktøj | Dokumentation og tutorials | Community | Skabeloner | Læringskurve |
|---|---|---|---|---|
| Thunderbit | Fremragende | Voksende | Ja | Meget lav |
| Browse AI | God | God | Ja | Lav |
| Octoparse | Fremragende | Stor | Ja | Mellem |
| ParseHub | Fremragende | Stor | Ja | Mellem |
| Webscraper.io | God | Forum | Ja | Mellem |
| Apify | Fremragende | Stor | Ja | Mellem-høj |
| Scrapy | Fremragende | Kæmpe | N/A | Høj |
| Puppeteer | God | Stor | N/A | Høj |
| Selenium | God | Kæmpe | N/A | Høj |
| Zyte | God | Stor | Ja | Mellem-høj |
| SerpAPI | God | Mellem | N/A | Høj |
| Diffbot | God | Mellem | N/A | Høj |
Thunderbit og Browse AI er lettest for begyndere. Octoparse og ParseHub har gode ressourcer, men kræver mere tålmodighed. Apify og udviklerværktøjer har stejle læringskurver, men er veldokumenterede.
Konklusion: Vælg den rigtige gratis data scraper i 2026
Se de bedste web scraping-værktøjer i 2026 Get Started Free
Kort fortalt: Ikke alle “gratis” data scraper-værktøjer er lige brugbare, og dit valg bør afhænge af din rolle, dit tekniske niveau og dine faktiske scraping-behov.
- Hvis du er forretningsbruger eller ikke-koder og vil have data hurtigt — især fra vanskelige sider, PDF’er eller billeder — er Thunderbit det bedste sted at starte. Den AI-drevne tilgang, prompts i naturligt sprog og efterbehandlingsfunktioner gør det til det tætteste, man kommer på en rigtig AI-dataassistent. Prøv Thunderbit Chrome-udvidelsen gratis og se, hvor hurtigt du kan gå fra “jeg har brug for de her data” til “her er mit regneark”.
- Hvis du er udvikler eller har brug for ubegrænset, tilpasselig scraping, er open source-værktøjer som Scrapy, Puppeteer og Selenium dit bedste valg.
- Til teams og semi-tekniske brugere tilbyder Apify og Zyte skalerbare, samarbejdsvenlige løsninger med generøse gratisniveauer til små opgaver.
Uanset din arbejdsgang bør du starte med det værktøj, der matcher dine færdigheder og behov. Og husk: I 2026 behøver du ikke være udvikler for at udnytte webdata — du skal bare have den rigtige assistent (og måske en smule humor, når robotterne løber fra dig).
Vil du dykke dybere ned? Se flere guides og sammenligninger på Thunderbit Blog, herunder:
- Hvad er data scraping, og hvordan gør man det i 2026
- Sådan scraper du webstedsdata til Excel med AI
- De bedste web scraping-værktøjer og software i 2026
Prøv AI Web Scraper Get Started Free




