
Amazon har og i sit katalog. Hvis du nogensinde har prøvet manuelt at kopiere produkttitler, priser, vurderinger og ASIN'er over i et regneark, kender du smerten — og den vokser hurtigt i takt med mængden.
Jeg arbejder hos , hvor vi bygger en AI-webscraper, så jeg bruger meget tid på at tænke over, hvordan folk udtrækker data fra websites. Men til denne artikel ville jeg gøre noget, som ingen anden oversigt synes at gøre: sætte syv faktiske Chrome-udvidelser op, som du kan installere og køre på Amazon, teste dem på de samme sider og give dig et ærligt svar på, hvad der virker, hvad der ikke gør, og hvor hvert værktøj passer ind. Jeg vurderede hver udvidelse ud fra otte kriterier, som direkte afspejler de frustrationer, jeg ser i fora og hos vores egne brugere — ting som AI-baseret feltgenkendelse, scraping af undersider, ban-risiko, gratisniveauer og eksportmuligheder. Uanset om du er Amazon-sælger, marketingfolk eller bare træt af copy-paste, er denne guide til dig.
Hvorfor overhovedet scrape Amazon-produktdata?
Så hvem scraper egentlig Amazon, og hvorfor?
Det korte svar er næsten alle, der sælger, markedsfører eller researcher produkter online. Amazon siger, at i butikken kommer fra uafhængige sælgere, og de sælgere holder konstant øje med hinanden. Her er de mest almindelige use cases, jeg ser:
| Use case | Hvem gør det | Hvad de får |
|---|---|---|
| Overvågning af konkurrentpriser | Sælgere, pristeams, bureauer | Pris- og tilgængelighedsdata i realtid for rivalprodukter |
| Produktresearch og trendovervågning | Amazon-sælgere, markedsanalytikere | Se nye kategorier, nye aktører og ændringer i efterspørgslen |
| Analyse af anmeldelsestemaer | Private label-sælgere, brandteams | Gentagne klager, mangler ved funktioner og muligheder |
| Leadgenerering (sælgerkontakter) | Engrostteams, bureauer | Sælgernavne, storefronts og kontaktoplysninger |
| Overvågning af katalog og lager | E-handel, brandbeskyttelse | Spor lagerniveauer, ændringer i listings og uautoriserede sælgere |
| Nøgleords- og listingoptimering | Brand owners, markedspladsoperatører | Søgetermdata, listing-tekst og konkurrentnøgleord |
ROI'en er håndgribelig. Amazons egne case studies viser, at efter optimering til de bedste søgetermer ved hjælp af strukturerede data. Og en viste, at medarbejdere bruger mere end 9 timer om ugen på gentagen dataindtastning. Hvis du kan automatisere bare en del af det, frigør du seriøs tid til egentlig beslutningstagning.
Hvad gør en god Amazon Scraper Chrome-udvidelse? (Mine testkriterier)
Ikke alle Chrome-udvidelser er skabt lige — og de fleste sammenligningsartikler blander API'er, desktop-apps og browserudvidelser sammen, som om de var udskiftelige. Det er de ikke. Her er den ramme, jeg brugte, og hvorfor hvert kriterium betyder noget:
- Opsætningsvenlighed - Kan en ikke-teknisk bruger få resultater på under 5 minutter? (Fora bekræfter, at dette er en topbekymring.)
- AI-drevet feltgenkendelse - Genkender værktøjet automatisk produktfelter, eller skal du konfigurere selectors manuelt? (Ingen konkurrerende artikel omtaler dette som en kategori.)
- Scraping af undersider / detaljesider - Kan du berige listing-data med oplysninger fra produktsiden i én arbejdsgang?
- Anti-bot / ban-risiko-håndtering - Hvordan håndterer det Amazons aggressive bot-detektion? (Den i brugerfora.)
- Understøttelse af paginering - Kan det automatisk scrape flere resultatsider?
- Gratis niveau / pris - Hvad får du reelt uden at betale? (Brugere spørger eksplicit efter gratis muligheder, og ingen konkurrent giver et praktisk svar.)
- Eksportmuligheder - CSV, Excel, Google Sheets, Airtable, Notion?
- Planlægning og automatisering - Kan du få det til at køre løbende?
Jeg testede hver udvidelse på Amazon US-søgeresultater og produktsider, med de samme søgninger og de samme betingelser.

AI-drevet vs. selector-baseret scraping: Hvorfor det betyder noget på Amazon
Der er en forskel, som ingen anden Amazon scraper-oversigt nævner — og det er den enkelt største faktor for, hvor meget vedligeholdelse din scraper vil kræve.
De fleste Chrome-udvidelser til scraping arbejder ved at mappe CSS selectors til datafelter. Du (eller værktøjets skabelon) peger på HTML-elementet for "pris" eller "titel", og scrapers trækker det, der ligger der. Problemet? Amazon ændrer deres underliggende HTML og CSS for at ødelægge scrapers. Brugerforum beskriver hashede eller skiftende klassenavne som en .
Her er en sammenligning af de tre hovedtilgange:
| Tilgang | Sådan virker det | Når Amazon ændrer layout |
|---|---|---|
| Selector-baseret (traditionel) | Brugeren mapper manuelt CSS selectors til felter | Bryder sammen - brugeren må konfigurere igen |
| Skabelonbaseret | Færdiglavede opskrifter til Amazon-sider | Bryder sammen, indtil udvikleren opdaterer skabelonen |
| AI-drevet (fx Thunderbit) | AI læser sideindholdet og genkender felter automatisk | Tilpasser sig automatisk - ingen vedligeholdelse |
Kun én af de syv udvidelser, jeg testede — Thunderbit — bruger AI-feltgenkendelse som standardopsætning. Resten er afhængige af selectors eller skabeloner, hvilket betyder mere vedligeholdelse, når Amazon uundgåeligt ændrer deres sider. Hvis du forstår den forskel, sparer du dig selv for meget frustration senere.
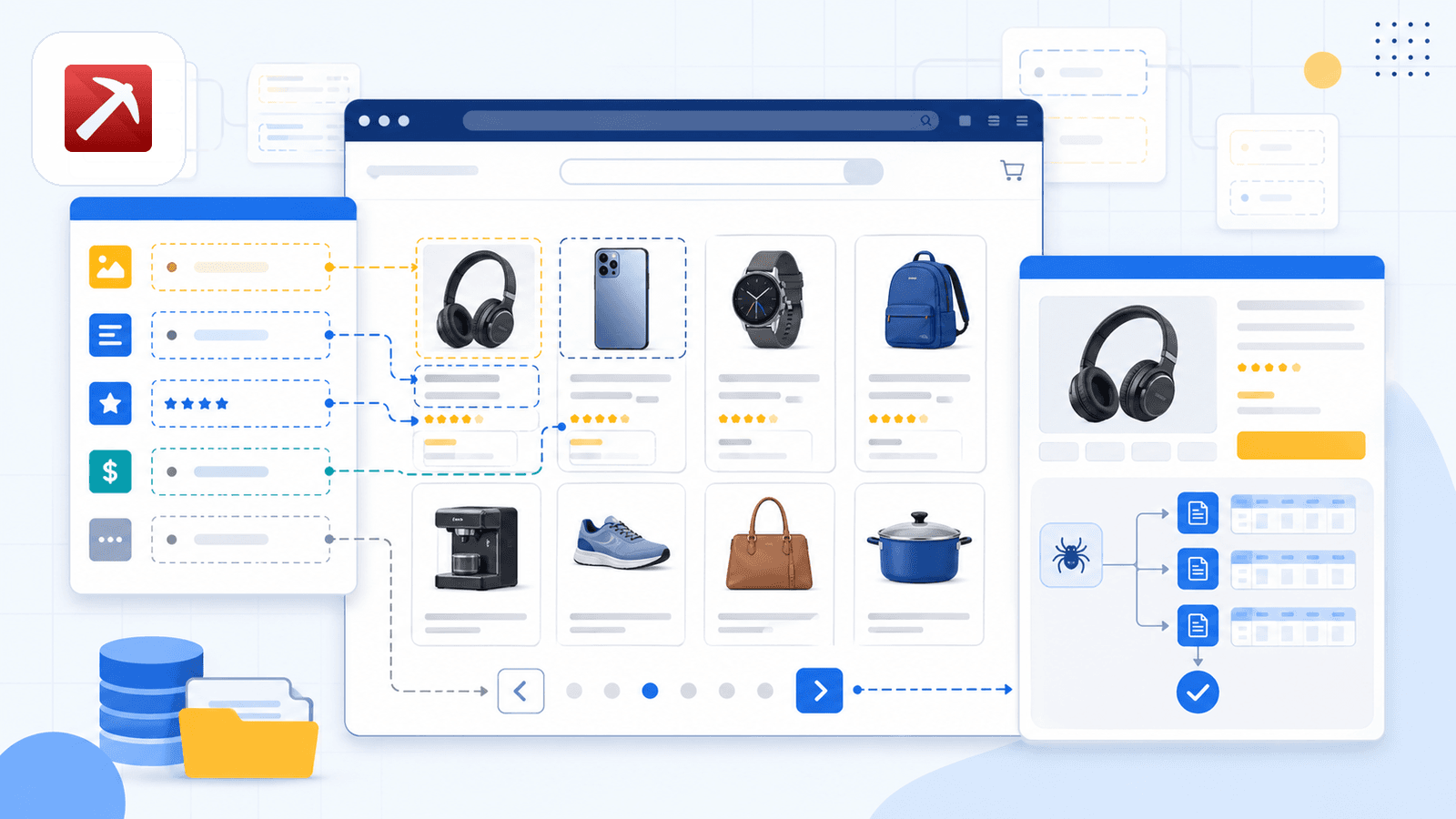
1. Thunderbit - Den AI-drevne Amazon Scraper Chrome-udvidelse
er værktøjet, vi selv har bygget, så jeg er helt åben om det. Men jeg mener også oprigtigt, at det er det bedste valg for ikke-tekniske brugere, der vil have hurtige og præcise Amazon-data uden at kæmpe med selectors eller kode.
Den vigtigste forskel er AI Suggest Fields. Når du åbner en Amazon-søgeresultatside og klikker på knappen, læser Thunderbits AI siden og foreslår kolonnenavne — titel, pris, vurdering, ASIN, antal anmeldelser, produkt-URL og meget mere. Du skal ikke konfigurere noget. AI'en finder ud af, hvad der er på siden, og foreslår de rigtige felter og datatyper.
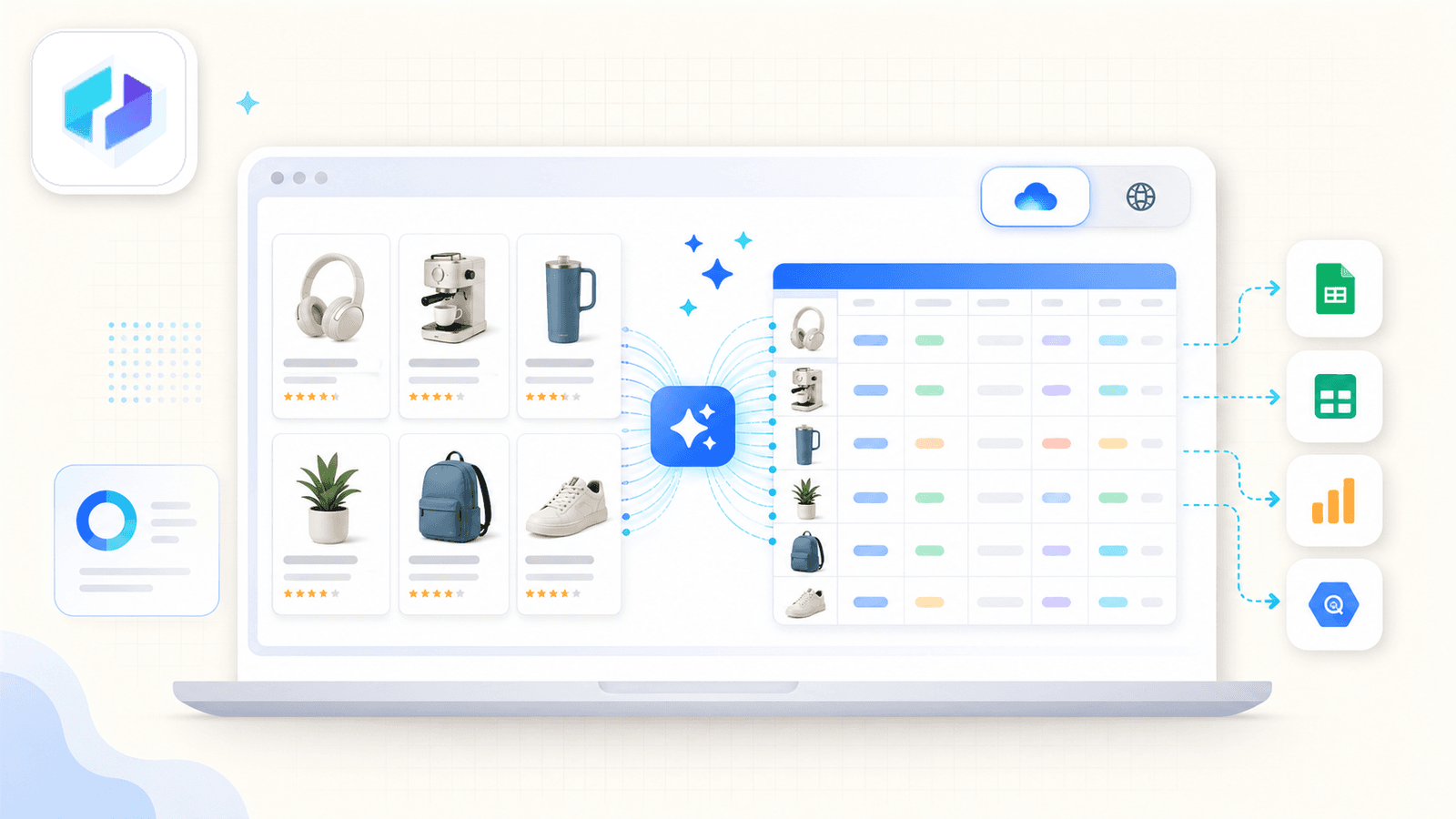
Sådan ser en typisk Amazon-scraping-session ud:
- Installer , og åbn en Amazon-søgeresultatside.
- Klik på AI Suggest Fields - AI'en opdager og foreslår kolonner.
- Klik på Scrape - data udfyldes med det samme.
- På populære Amazon-sider kan du også bruge den færdigbyggede for en ægte 1-klik-oplevelse.
Det, der virkelig skiller Thunderbit ud, er scraping af undersider. Efter du har scraped listingsiden, klik på Scrape Subpages - Thunderbit besøger hver produkt-URL og tilføjer detaljefelter (fulde beskrivelser, punktlister, sælgeroplysninger, billed-URL'er) til den samme tabel. De fleste konkurrerende udvidelser tilbyder simpelthen ikke det.
Der er også en cloud vs. browser-toggle. Cloud-tilstand scraper op til 50 sider samtidig for offentlige listings. Browser-tilstand bruger din egen Chrome-session - ideel når du er logget ind i Seller Central eller skal holde lav profil.
Planlægning er beskrevet i helt almindeligt sprog: Beskriv tidsintervallet, og AI'en omsætter det til en plan.
Eksportmulighederne dækker Excel, Google Sheets, Airtable, Notion, CSV og JSON - alt sammen inkluderet i gratisniveauet.
Fordele og ulemper ved Thunderbit
Fordele:
- AI registrerer felter automatisk - ingen selector-opsætning, ingen vedligeholdelse når Amazon ændrer layout
- Berigelse af undersider med ét klik
- Cloud/browser-toggle for fleksibilitet og lavere ban-risiko
- Bredeste eksportmuligheder (Sheets, Airtable, Notion, Excel, CSV, JSON)
- Planlægning med naturligt sprog
- Færdig Amazon-skabelon til øjeblikkelige resultater
Ulemper:
- Kreditbaseret system betyder, at storforbrugere skal have en betalt plan
- AI-feltgenkendelse tilføjer et kort behandlingsled (et par sekunder)
- Et nyere værktøj, så der er mindre community-dokumentation end for ældre løsninger
Priser for Thunderbit
- Gratis niveau: 6 sider (10 med trial boost), inkluderer AI-funktioner og alle eksportformater
- Betalte planer: Starter ved ca. $9/måned (årligt) for 500 credits; 1 credit = 1 output-række
- Se for de seneste detaljer
2. Instant Data Scraper - Den gratis, no-frills løsning
Instant Data Scraper er en Chrome-udvidelse, der automatisk genkender tabeldata på websider ved hjælp af heuristiske algoritmer. Den har eksisteret i årevis og er stadig en af de mest downloadede gratis scrapers i Chrome Web Store.
På Amazon aktiverer du udvidelsen på en søgeresultatside, og den forsøger automatisk at finde datatabellen. Nogle gange skal du klikke på "try another table", hvis den første genkendelse rammer forkert. Til simple, enkeltstående scraping-opgaver fungerer den rimeligt godt.
Der er dog en vigtig nuance for 2026: den officielle landingsside siger nu, at Instant Data Scraper ikke længere ejes, udvikles eller understøttes af Web Robots. Det betyder ingen opdateringer, ingen fejlrettelser og ingen nye funktioner. I en rapporterede en , at den håndterede oversigtssider, men gik i stå, når der skulle klikkes ned til detaljeniveau.
Fordele og ulemper ved Instant Data Scraper
Fordele:
- 100% gratis, ingen konto nødvendig
- Let og hurtig til simple tabeller
- Understøtter grundlæggende paginering (klik på "Næste")
Ulemper:
- Ingen AI-feltgenkendelse (bygger på mønstergenkendelse, som kan fejlfortolke Amazons komplekse layout)
- Ingen scraping af undersider
- Kun CSV/Excel-eksport
- Ingen planlægning, ingen cloud-mulighed
- Ikke længere vedligeholdt - bryder sammen, når Amazon ændrer layout, og ingen retter det
3. Web Scraper - Den erfarne udvidelse til manuel opsætning
Web Scraper er en af de mest etablerede Chrome-udvidelser til scraping, bygget op omkring en visuel sitemap-bygger. Du åbner DevTools, opretter et "sitemap" ved at pege og klikke for at definere selectors, konfigurerer paginering og kan følge links til produktsider.
Web Scraper tilbyder også en Amazon Products Listings Scraper-skabelon i sit marketplace, som håndterer navigation, paginering og udtræk fra produktsider. Deres trin-for-trin-guide gennemgår en opsætning i 8 trin - installér, generér selectors, konfigurer paginering, følg produktlinks, kør lokalt eller i cloud.
Cloud-versionen tilføjer planlægning, API-adgang, proxy-rotation, CAPTCHA-bypass og Google Sheets-integration.

Fordele og ulemper ved Web Scraper
Fordele:
- Modent, veldokumenteret og understøttet af et community
- Gratis browserudvidelse (ubegrænset lokal brug)
- Marketplace-skabeloner til Amazon
- Cloud-mulighed til skalering (planlægning, IP-rotation, integrationer)
- Understøtter at følge links til produktsider (delvis berigelse af undersider)
Ulemper:
- Kræver manuel opsætning af selectors - stejlere læringskurve for ikke-tekniske brugere
- Ingen AI-baseret auto-genkendelse af felter
- Skabeloner kan bryde sammen, når Amazon opdaterer layoutet
- Avancerede funktioner er låst bag betalte cloud-planer
Priser for Web Scraper
- Gratis: Chrome-udvidelse, ubegrænset lokal scraping
- Cloud-planer: Starter ved $50/måned (Project), $100/måned (Professional), fra $200/måned (Scale)
4. Octoparse - Platformen med mange funktioner (men med et Chrome-udvidelses-forbehold)
Octoparse er en stærk no-code scrapingplatform med færdigbyggede Amazon-skabeloner til produktdetaljer, søgning på nøgleord og anmeldelser. Den understøtter cloud-scraping, planlægning og arbejdsgange i flere trin.
Der er dog en vigtig nuance: Octoparse's Chrome Web Store-udvidelse er i øjeblikket opført som Octoparse AI Web Automation, og den siger eksplicit, at den kun virker sammen med Octoparse AI Bot på Windows. Så den reelle scraping-oplevelse er platform-først, ikke udvidelses-først. Hvis du leder efter en ren "installér og scrape i Chrome"-arbejdsgang, er Octoparse mere en desktop-app med en browserassistent.
Når det er sagt, er skabelonerne fremragende. Du indtaster en søge-URL, Octoparse udtrækker produktdata automatisk, og du kan bygge tilpassede arbejdsgange med point-and-click selectors, paginering og link-følgning til detaljesider.
Fordele og ulemper ved Octoparse
Fordele:
- Robust funktionssæt med Amazon-skabeloner
- Cloud-noder til hastighed, planlægning og udtræk fra undersider via workflows
- Håndterer paginering godt
- God til komplekse, flertrins scraping-pipelines
Ulemper:
- Fuld styrke kræver desktop-appen - ikke en ren Chrome-udvidelsesoplevelse
- Ingen AI-autoforeslåede felter (der findes et separat Chat4Data-produkt, men det er en anden udvidelse)
- Gratisplanen er begrænset til ca. 50K dataeksport/måned, 10.000 rækker pr. eksport
- Interfacet kan føles komplekst for begyndere
Priser for Octoparse
- Gratis: Begrænset (lokal udtrækning, 50K eksportloft)
- Standard: ca. $75-$83/måned
- Professional: ca. $208-$249/måned
- Tilføjelser: IP-rotation til $3/GB, CAPTCHA-løsning til $2-$2.50 pr. 1.000
5. Axiom.ai - Den no-code botbygger
Axiom.ai er en Chrome-udvidelse til at bygge browser-automatiseringsbots med en visuel no-code-bygger. Det er mere et generelt automatiseringsværktøj end en dedikeret scraper, men det har Amazon-scraping-skabeloner og guides til ASIN-udtræk.
Du opretter en bot (eller bruger en skabelon), som løber gennem produkt-URL'er i et Google Sheet, besøger hver side, udtrækker data via point-and-click selectors og skriver resultaterne tilbage til arket. Planlægning er tilgængelig på betalte planer, og cloud-kørsler tilbydes nu fra 1 bot i cloud på Starter og Pro op til 20 samtidige cloud-bots på Ultimate.
Fordele og ulemper ved Axiom.ai
Fordele:
- Alsidig no-code-automatisering (ikke kun scraping)
- Naturlig integration med Google Sheets
- Planlægning og cloud-kørsler på betalte planer
- Skabeloner til Amazon
- God til flertrins-arbejdsgange ud over dataudtræk
Ulemper:
- Tungere opsætning til et simpelt scrape (kræver bot-design, Google Sheet-konfiguration, loop-test)
- Ingen AI-feltgenkendelse
- Ingen berigelse af undersider med ét klik (skal bygges som et separat bot-trin)
- Eksport begrænset til Google Sheets eller CSV
Priser for Axiom.ai
- Gratis: 2 timers runtime
- Starter: $15/måned
- Pro: $50/måned
- Pro Max: $150/måned
- Ultimate: $250/måned
6. Data Miner - Udvidelsen drevet af recipes
Data Miner er en Chrome-udvidelse, der fokuserer på at udtrække data ved hjælp af "recipes" - foruddefinerede eller brugerdefinerede scraping-skabeloner. Du søger efter en eksisterende Amazon-recipe i det offentlige bibliotek eller opretter din egen ved at vælge sideelementer.
Data Miner understøtter paginering via sin Next Page Automation-funktion, og den tilbyder også en Crawl Scrape-arbejdsgang til at besøge detaljer-URL'er og anvende en anden recipe. Så det er ikke "ingen scraping af undersider" - men det er en manuel proces i flere trin snarere end berigelse med ét klik.
Den store begrænsning er gratisniveauet: 500 sider/måned, og nogle domæner er begrænset på gratisplanen. Recipes er sitespecifikke, og Data Miners egen dokumentation advarer om, at hvis siden ændrer sig, og reference-HTML-koden ændrer sig, vil recipe'en ikke virke.
Fordele og ulemper ved Data Miner
Fordele:
- Let at køre en eksisterende recipe
- Community-bibliotek med recipes
- Understøtter paginering og crawling af detaljesider (manuel opsætning)
- Enkelt interface
Ulemper:
- Gratisniveauet er begrænset til 500 sider/måned
- Ingen AI-feltgenkendelse
- Recipes bryder sammen, når Amazon ændrer layout
- Ingen cloud-scraping, ingen planlægning i offentlige docs
- Eksport: CSV, Excel, clipboard; Google Sheets på betalte planer
Priser for Data Miner
- Gratis: 500 sider/måned
- Betalt: $19.99, $49, $99, $200/måned med stigende grænser og funktioner
7. Helium 10 - Amazon-sælgernes intelligenssuite
Helium 10 er et omfattende værktøjssæt til Amazon-sælgere, ikke en generel webscraper. Dets Chrome-udvidelse (Xray) lægger data direkte oven på Amazon-søgeresultater — og viser estimeret salg, omsætning, vurderingstendenser, BSR og meget mere. Det er designet til Amazon-sælgere, der laver produktresearch, ikke til at udtrække rå sidedata.
Helium 10 har også en gratis plan i 2026, men adgang til Chrome-udvidelsen er begrænset på gratisniveauet. Udvidelsen kan eksportere resultater i CSV eller Excel og understøtter clipboard-workflows.
Fordele og ulemper ved Helium 10
Fordele:
- Dybe Amazon-specifikke indsigter (salgsestimater, nøgleordsdata, BSR-trends)
- Stoler på af professionelle sælgere
- Cloud-baserede data og planlægning til tracking af nøgleord/rank
- Gratisplan tilgængelig (begrænset)
Ulemper:
- Ikke en generel scraper - kan ikke udtrække brugerdefinerede felter fra vilkårlige sider
- Dyrt sammenlignet med scraping-fokuserede værktøjer
- Begrænsede eksportformater (CSV, Excel)
- Ingen AI-feltgenkendelse, ingen berigelse af undersider i scraping-forstand
Priser for Helium 10
- Gratis: Begrænset adgang, inklusive Chrome-udvidelse
- Starter: $49/måned
- Platinum: $229/måned
- Diamond: $359/måned
Amazon Scraper Chrome-udvidelser sammenlignet: Den fulde side om side
Her er den ærlige sammenligningstabel. Jeg har rettet nogle antagelser fra tidligere udkast efter praktisk test og verifikation i 2026:
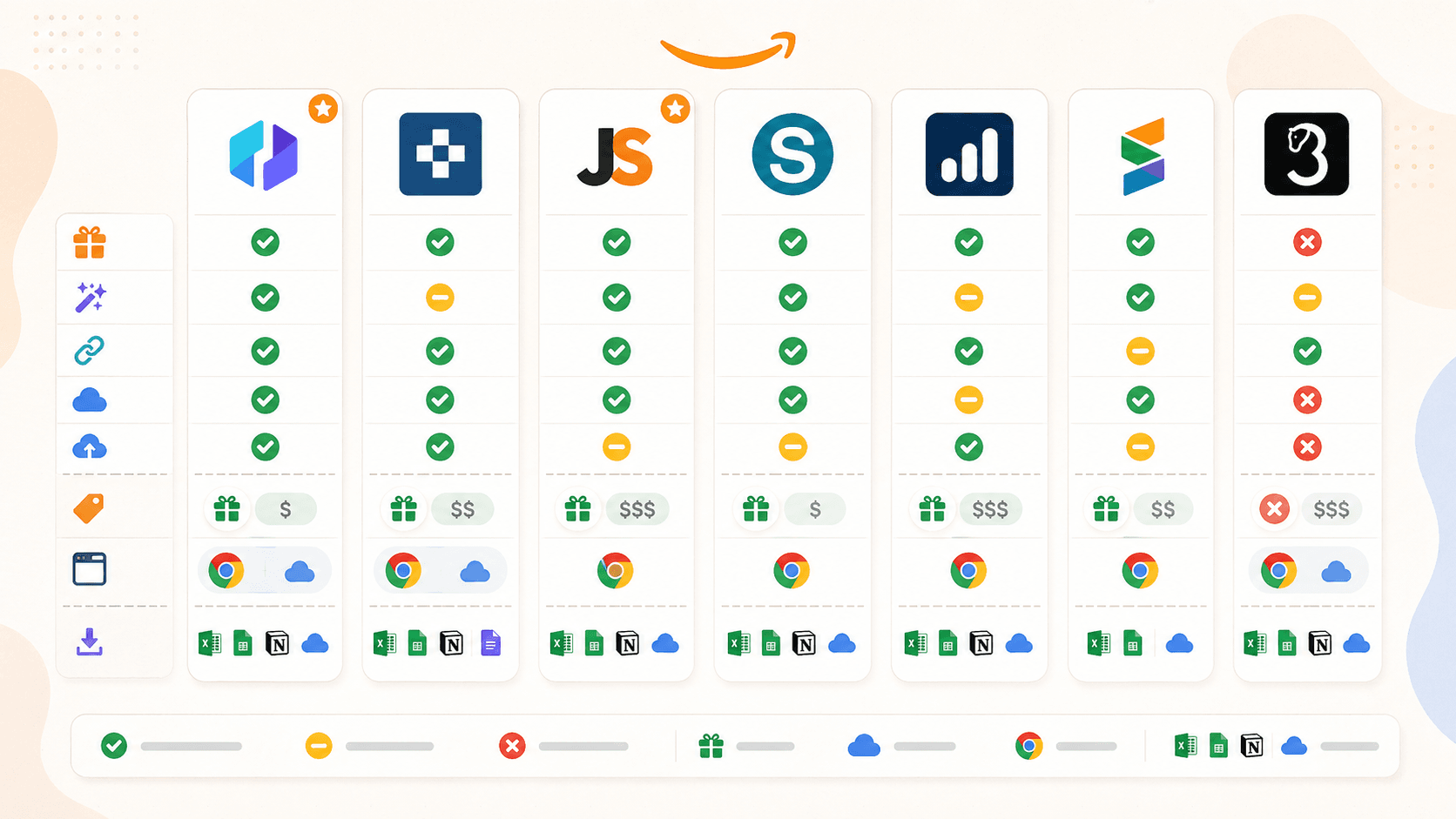
| Funktion | Thunderbit | Instant Data Scraper | Web Scraper | Octoparse | Axiom.ai | Data Miner | Helium 10 |
|---|---|---|---|---|---|---|---|
| Primær kategori | AI scraper-udvidelse | Gratis heuristisk scraper | Selector-/skabelon-scraper | No-code scrapingplatform | Browser-automatiserings-bygger | Recipe-baseret scraper-udvidelse | Overlejring til sælgerresearch |
| AI-autoforeslåede felter | Ja | Nej | Nej | Nej (separat Chat4Data) | Nej | Nej | Nej |
| Berigelse af undersider | Ja (1 klik) | Nej | Ja (manuel sitemap) | Ja (workflow) | Ja (manuel bot-trin) | Ja (manuel crawl) | N/A |
| Cloud-scraping | Ja | Nej | Ja (betalt) | Ja (betalt) | Ja (betalt) | Nej | Cloud-baseret analyse |
| Planlægning | Ja | Nej | Ja (betalt) | Ja (betalt) | Ja (betalt) | Nej | Ja (tracking af nøgleord/rank) |
| Gratis niveau | Ja (6-10 sider) | Ja (helt gratis) | Ja (kun browser) | Ja (begrænset) | Ja (2 t runtime) | Ja (500 sider/md.) | Ja (begrænset) |
| Færdig Amazon-skabelon | Ja | Nej | Ja | Ja | Ja (guides) | Recipe-bibliotek | N/A |
| Eksport til Sheets/Airtable/Notion | Ja (alt) | Kun CSV/Excel | CSV, Excel, JSON; Sheets via cloud | CSV, Excel, JSON, mere | Google Sheets, CSV | CSV, Excel; Sheets på betalt | CSV, Excel |
Et par ting springer i øjnene. Thunderbit er den eneste udvidelse med AI-feltgenkendelse og de bredeste eksportmuligheder på gratisniveauet. Instant Data Scraper er den enkleste gratis løsning, men den vedligeholdes ikke længere. Web Scraper og Octoparse er stærke for brugere, der er villige til at investere tid i opsætning, men ingen af dem er en ren "installér og kør"-oplevelse i Chrome. Axiom.ai er bedst til flertrins-automatisering ud over scraping. Data Miner er let at bruge til eksisterende recipes, men gratisniveauet er stramt. Helium 10 er et værktøj til sælgerintelligens, ikke en generel scraper.
Cloud vs. browser-scraping på Amazon: Det du skal vide om ban-risiko
Det her er elefanten i rummet. Amazon opdager og blokerer aktivt automatiseret scraping. Brugere på Reddit rapporterer , og Amazons egne siger eksplicit, at licensen ikke omfatter "any use of data mining, robots, or similar data gathering and extraction tools."
Så hvad er den praktiske forskel på browser- og cloud-scraping?
- Browser-scraping kører i din egen Chrome-session — rigtige cookies, logget ind-tilstand, naturlig browsing-adfærd. Det ser mere menneskeligt ud ved lav volumen, men binder din browser.
- Cloud-scraping bruger eksterne servere for hastighed (Thunderbit håndterer 50 sider ad gangen i cloud-tilstand), men kræver hastighedsbegrænsning og proxy-rotation for at undgå detektion.
Her er en beslutningsmatrix, jeg bruger:
| Scenarie | Anbefalet tilstand | Hvorfor |
|---|---|---|
| Scraping af 20 produktsider til research | Browser | Lav volumen, naturlig adfærd |
| Overvågning af 500 konkurrent-SKU'er ugentligt | Cloud | Hastighed er vigtig, offentlige data |
| Scraping mens du er logget ind i Seller Central | Browser | Kræver din login-session |
| Engangs masseeksport af en kategori | Cloud | Parallel scraping for hastighed |
Blandt de syv udvidelser er cloud-scraping tilgængelig i Thunderbit, Web Scraper (betalt), Octoparse (betalt), Axiom.ai (betalt) og Helium 10 (til deres analyse). Instant Data Scraper og Data Miner er kun til browser.
Praktiske tips til at reducere ban-risiko: Hold forespørgselsintervaller rimelige, undgå scraping i myldretiden, og roter user agents, hvis dit værktøj understøtter det. Og lov dig selv aldrig "nul risiko" — håndter den bare bedst muligt.
Fra listingside til produktside: Sådan virker scraping af undersider på Amazon
Denne arbejdsgang er undervurderet — og ingen konkurrerende artikel demonstrerer den fra ende til anden.
Når du scraper en Amazon-søgeresultatside, får du opsummerede data: produkttitler, priser, vurderinger, ASIN'er og produkt-URL'er. Men ofte har du også brug for data fra produktsiden — fulde beskrivelser, punktlister, billed-URL'er, sælgeroplysninger, opdeling af anmeldelser. Det er her, scraping af undersider kommer ind i billedet.
Med Thunderbit er arbejdsgangen:
- Scrape Amazon-søgeresultatsiden -> få en tabel med produkter (titel, pris, vurdering, ASIN, produkt-URL).
- Klik på "Scrape Subpages" -> Thunderbit besøger hver produkt-URL og tilføjer detaljefelter (beskrivelse, antal anmeldelser, sælgernavn, billed-URL'er osv.) til den samme tabel.
- Eksportér den berigede tabel til Google Sheets, Airtable, Notion eller Excel.
AI'en genkender strukturen på undersiden og beriger tabellen automatisk — ingen manuel opsætning. Efter min erfaring sparer det mindst en time pr. batch sammenlignet med at åbne hver produktside og kopiere felter manuelt.
Andre værktøjer kan også gøre det, men med mere arbejde:
- Web Scraper: Du konfigurerer et sitemap til at følge produktlinks og definerer selectors for hvert detaljefelt. Det virker, men det er en manuel proces i flere trin.
- Octoparse: Du bygger en workflow med link-følgende trin. Kraftfuldt, men ikke med ét klik.
- Axiom.ai: Du designer en bot-loop, der besøger hver URL og udtrækker data. Fleksibelt, men kræver bot-bygningsfærdigheder.
- Data Miner: Du bruger Crawl Scrape-funktionen til at besøge gemte URL'er og anvende en anden recipe. Manuel og afhængig af recipe.
- Instant Data Scraper og Helium 10: Ingen arbejdsgang til berigelse af undersider.
Hvis du ofte har brug for både listing-niveau og detaljeniveau-data fra Amazon, bør værktøjet, du vælger, gøre denne arbejdsgang let — ikke bare mulig.
Den ærlige gennemgang af gratisniveauet: Hvad får du egentlig uden at betale?
Brugerfora spørger om det her mere end noget andet, og ingen konkurrerende artikel svarer gennemsigtigt på det.
| Udvidelse | Gratis niveau | Hvad du får gratis | Hvornår du skal opgradere |
|---|---|---|---|
| Thunderbit | Ja (6 sider, 10 med trial) | AI-forslag til felter, alle eksportformater (Excel, Sheets, Airtable, Notion), email-/telefonudtræk | Brug for flere sider eller planlagt scraping |
| Instant Data Scraper | Ja (helt gratis) | Grundlæggende tabelgenkendelse, CSV/Excel-eksport | N/A (intet betalt niveau, men heller ingen opdateringer) |
| Web Scraper | Ja (kun browser) | Browser-scraping, CSV-eksport | Cloud-scraping, planlægning, integrationer |
| Octoparse | Ja (begrænset) | Ca. 50K eksport/måned, lokal udtrækning | Flere poster, cloud-noder |
| Axiom.ai | Ja (2 timers runtime) | Grundlæggende automatiseringer, Google Sheets | Flere køringer, planlægning, cloud |
| Data Miner | Ja (500 sider/md.) | Recipes, CSV/Excel, Next Page Automation | Flere sider, Sheets, crawl-funktioner |
| Helium 10 | Ja (begrænset) | Begrænset adgang til Chrome-udvidelsen | Fuld Xray, nøgleordsværktøjer, planlægning |
Det vigtigste at forstå: Thunderbits gratisniveau inkluderer AI-funktioner og alle eksportformater — de fleste konkurrenter låser avanceret eksport eller AI bag betalte planer. Instant Data Scraper er helt gratis, men mangler AI, undersider og planlægning (og vedligeholdes ikke længere). Helium 10 har godt nok en gratisplan, men adgang til udvidelsen er begrænset, og det er ikke en generel scraper.
Min anbefaling efter scenarie:
- "Jeg vil bare teste vandene" -> Instant Data Scraper (helt gratis) eller Thunderbits gratisniveau
- "Jeg har brug for regelmæssig, pålidelig scraping" -> Thunderbit eller Web Scrapers betalte planer
- "Amazon-sælger, der har brug for markedsindsigt" -> Helium 10
Hvilken Amazon Scraper Chrome-udvidelse skal du vælge?
Efter at have testet alle syv, er min ærlige vurdering:
- Bedst til ikke-tekniske brugere, der vil have hurtige resultater med AI: Thunderbit. AI genkender felter automatisk, berigelse af undersider med ét klik, de bredeste eksportmuligheder, cloud/browser-toggle. Hvis du vil gå fra Amazon-side til regneark på under to minutter, er det her valget.
- Bedste helt gratis løsning til hurtige, enkeltstående scraping-opgaver: Instant Data Scraper. Ingen omkostninger, ingen konto, men begrænsede funktioner og ikke længere vedligeholdt.
- Bedst til brugere, der er komfortable med manuel opsætning: Web Scraper. Fleksibel sitemap-bygger, god cloud-mulighed, veldokumenteret.
- Bedst til komplekse scraping-pipelines i flere trin: Octoparse (desktop + udvidelse) eller Axiom.ai (browserbots). Begge er stærke, men ingen af dem er en ren "installér og kør"-Chrome-udvidelse.
- Bedst til simpel extraction baseret på recipes: Data Miner. Let at bruge eksisterende recipes, men begrænset gratisniveau og ingen AI.
- Bedst til Amazon-sælgerintelligens (ikke generel scraping): Helium 10. Bygget til formålet, dybe proprietære data, men dyrt og ikke en generel scraper.
Hvis du vil se, hvordan AI-drevet Amazon-scraping faktisk ser ud, så . Jeg tror, du vil blive overrasket over, hvor meget du kan nå på bare få klik. Og hvis Thunderbit ikke er det perfekte match, så prøv et par af de andre på listen — der har aldrig været et bedre tidspunkt at stoppe med at kopiere og indsætte og begynde at scrape smartere.
For flere tips til Amazon-scraping kan du se vores guides om , og . Du kan også se tutorials på .
FAQs
1. Er det lovligt at scrape Amazon-produktdata?
Scraping af offentligt synlige data er som udgangspunkt tilladt, men Amazons forbyder eksplicit data mining og automatiseret udtræk uden skriftligt samtykke. Denne artikel er ikke juridisk rådgivning — gennemgå altid Amazons vilkår, før du scraper i stor skala.
2. Kan Amazon opdage og blokere Chrome-udvidelser til scraping?
Ja. Amazon har anti-bot-systemer, der kan udløse CAPTCHA'er, drosle forespørgsler ned eller blokere IP'er. Brug af rimelige forespørgselsrater, browserbaseret scraping til små opgaver og cloud-scraping med hastighedsbegrænsning til større opgaver kan reducere risikoen. Se afsnittet om cloud vs. browser ovenfor for en praktisk beslutningsmatrix.
3. Hvilke data kan du scrape fra Amazon med en Chrome-udvidelse?
Almindelige felter inkluderer produkttitler, priser, vurderinger, antal anmeldelser, ASIN'er, sælgernavne, beskrivelser, billed-URL'er, tilgængelighed og leveringsinfo. AI-drevne værktøjer som Thunderbit kan automatisk genkende og foreslå disse felter uden manuel opsætning.
4. Skal jeg kunne kode for at bruge en Amazon scraper Chrome-udvidelse?
Nej — alle syv værktøjer, vi testede, er designet til ikke-tekniske brugere. Nogle kræver mere opsætning (Web Scraper, Octoparse, Axiom.ai), mens andre næsten er uden konfiguration (Thunderbit, Instant Data Scraper). Afvejningen er som regel fleksibilitet vs. brugervenlighed.
5. Hvilken Amazon scraper Chrome-udvidelse har det bedste gratisniveau?
Thunderbits gratisniveau inkluderer AI-feltgenkendelse og alle eksportformater (Sheets, Airtable, Notion, Excel, CSV, JSON), som de fleste konkurrenter låser bag betalte planer. Instant Data Scraper er helt gratis, men mangler AI, undersider og planlægning. Data Miner giver 500 gratis sider/måned. Helium 10's gratisplan er begrænset og fokuseret på sælgerresearch, ikke generel scraping.
Lær mere