I 2015 betød scraping tit, at du måtte nærmest trygle en udvikler om et Python-script eller ofre en hel weekend på at lære XPath. I 2026 skriver du bare “hent alle produktnavne og priser”, og så fikser en AI resten.
Den udvikling er gået vildt hurtigt. Over er i dag afhængige af web scraping. Markedet rundede og forventes at fordoble sig frem mod 2030.
Den største motor bag det hele? AI-webcrawlere. De kan tilpasse sig, når et site ændrer layout. De forstår, hvad der faktisk står på siden – ikke kun HTML-tags. Og de virker også for folk, der aldrig har skrevet en linje kode.
Jeg har brugt måneder på at teste 15 af dem. Her er mine konklusioner – inklusive hvorfor Thunderbit (ja, virksomheden jeg var med til at stifte) endte øverst.
Hvorfor AI ændrer web scraping: Den nye æra for Web Scraper-værktøjer
Lad os lige sige det, som det er: klassisk web scraping var aldrig bygget til den gennemsnitlige forretningsbruger. Det var selectors, kode og krydsede fingre for, at scriptet ikke brækkede sammen, næste gang et website fik nyt layout. Men AI og LLM’er har vendt spillet på hovedet.
Det sker især på de her måder:
- Instruktioner i naturligt sprog: I stedet for at nørkle med kode fortæller du bare AI’en, hvad du vil have. Værktøjer som forstår almindelige instruktioner og sætter udtrækket op for dig ().
- Adaptiv læring: AI-scrapere kan på websites, så du slipper for en masse vedligehold.
- Håndtering af dynamisk indhold: Moderne sites elsker JavaScript og uendelig scroll. AI-drevne værktøjer kan interagere med den slags elementer og fange data, som gamle scrapere ofte misser.
- Struktureret output med AI-parsing: LLM-baserede scrapere og leverer pæne, strukturerede datasæt.
- Automatisk omgåelse af anti-bot: AI-scrapere kan og bruge proxies/headless browsers for at undgå IP-blokering.
- Integrerede dataflows: De bedste værktøjer nøjes ikke med at hente data – de afleverer dem dér, hvor du faktisk arbejder, fx med eksport med ét klik til Google Sheets, Airtable, Notion m.m. ().
Resultatet? Web scraping er blevet en klik-oplevelse (eller nærmest en chat), så salg, marketing og drift – ikke kun udviklere – kan arbejde direkte med webdata.
15 AI-webcrawlere, der er værd at kende i 2026
Lad os tage de 15 bedste AI-webcrawlere – med Thunderbit først. Jeg giver dig et klart overblik over kernefunktioner, målgruppe, pris og hvad der gør hver løsning speciel. Og ja: jeg er ærlig om, hvor de er stærke (og hvor de ikke er).
1. Thunderbit: AI Web Scraper til alle
Jeg er selvfølgelig lidt biased, men Thunderbit er den AI Web Scraper, jeg selv ville have ønsket fandtes for år tilbage. Derfor ligger den #1 her:
- Udtræk via naturligt sprog: Du “chatter” med Thunderbit. Beskriv bare, hvad du vil have – “scrape alle produktnavne og priser fra denne side” – og AI’en klarer resten (). Ingen kode, ingen selectors, ingen bøvl.
- Undersider & crawling i flere niveauer: Thunderbit kan . Fx: hent en produktliste og klik derefter ind på hvert produkt for detaljer – i samme kørsel.
- Struktureret output med det samme: AI’en , foreslår relevante felter, normaliserer formater og kan endda opsummere eller kategorisere tekst.
- Bred understøttelse af kilder: Thunderbit er ikke kun til HTML – den kan også udtrække fra PDF’er og billeder via indbygget OCR og vision AI ().
- Integrationer til forretningen: Eksport med ét klik til Google Sheets, Airtable, Notion eller Excel (). Planlæg scraping og send data direkte ind i teamets workflow.
- Færdige templates: Til sites som Amazon, LinkedIn, Zillow m.fl. tilbyder Thunderbit til udtræk med ét klik.
- Brugervenlig og tilgængelig: Interfacet er klik-baseret med en intuitiv assistent. Mange er i gang på få minutter.

Thunderbit bruges af , bl.a. teams hos Accenture, Grammarly og Puma. Salgsteams bruger den til at , ejendomsmæglere samler boligannoncer, og marketing holder øje med konkurrenter – uden at skrive en eneste linje kode.
Pris: Der findes et (op til 100 steps/måned), og betalte planer starter ved $14,99/måned. Selv Pro-planerne er realistiske for enkeltpersoner og små teams.
Thunderbit er det tætteste, jeg har set på at “gøre nettet til en database” – og den er lavet til alle, ikke kun ingeniører.
2. Crawl4AI
Hvem er den til: Udviklere og tekniske teams, der bygger egne pipelines.
Crawl4AI er et open-source framework i Python, optimeret til fart og web crawling i stor skala – med . Det er ekstremt hurtigt, understøtter headless browsers til dynamisk indhold og kan strukturere data, så det er nemt at bruge i AI-workflows.
- Bedst til: Udviklere, der vil have en stærk og tilpasningsbar crawling-motor.
- Pris: Gratis (MIT-licens). Du skal selv hoste og køre det.
3. ScrapeGraphAI
Hvem er den til: Udviklere og analytikere, der bygger AI-agenter eller komplekse datapipelines.
ScrapeGraphAI er et prompt-styret open-source Python-bibliotek, der omdanner websites til strukturerede data-“grafer” ved hjælp af LLM’er. Du kan skrive prompts som “Udtræk alle produktnavne, priser og ratings fra de første 5 sider”, og så bygger den et scraping-flow for dig ().
- Bedst til: Tekniske brugere, der vil have fleksibel, prompt-baseret scraping.
- Pris: Gratis som open-source; cloud API starter ved $20/måned.
4. Firecrawl
Hvem er den til: Udviklere, der bygger AI-agenter eller datapipelines i stor skala.
Firecrawl er en AI-fokuseret crawling-platform og API, der gør hele websites til “LLM-klar” data (). Den leverer output i Markdown eller JSON, håndterer dynamisk indhold og integrerer med frameworks som LangChain og LlamaIndex.
- Bedst til: Udviklere, der vil fodre AI-modeller med live webdata.
- Pris: Open-source core er gratis; cloud-planer starter ved $19/måned.
5. Browse AI
Hvem er den til: Forretningsbrugere, growth hackers og analytikere.
Browse AI er en no-code platform med et . Du “træner” en robot ved at klikke på de data, du vil have, og AI’en generaliserer mønsteret til fremtidige scraping-kørsler. Den håndterer logins, uendelig scroll og kan overvåge sites for ændringer.
- Bedst til: Ikke-tekniske brugere, der vil automatisere dataindsamling og overvågning.
- Pris: Gratis plan (50 credits/måned); betalte planer starter ved $19/måned.
6. LLM Scraper
Hvem er den til: Udviklere, der vil lade AI’en stå for parsing.
LLM Scraper er et open-source bibliotek i JavaScript/TypeScript, hvor du kan , og så udtrækker en LLM data fra enhver webside. Det bygger på Playwright, understøtter flere LLM-udbydere og kan endda generere genbrugelig kode.
- Bedst til: Udviklere, der vil gøre enhver webside til strukturerede data med LLM’er.
- Pris: Gratis (MIT-licens).
7. Reader (Jina Reader)
Hvem er den til: Udviklere, der bygger LLM-apps, chatbots eller opsummeringsværktøjer.
Jina Reader er et API, der udtrækker og returnerer LLM-klar Markdown eller JSON. Den er drevet af en specialmodel og kan også lave billedtekster.
- Bedst til: At hente læsbart indhold til LLM’er eller Q&A-systemer.
- Pris: Gratis API (ingen nøgle nødvendig til basal brug).
8. Bright Data
Hvem er den til: Enterprise og professionelle brugere, der har brug for skala, compliance og stabil drift.
Bright Data er en tung spiller i webdata, med et stort proxy-netværk og . De tilbyder færdige scrapere, en generel Web Scraper API og “LLM-ready” data feeds.
- Bedst til: Organisationer, der skal bruge pålidelige webdata i stor skala.
- Pris: Forbrugsbaseret og premium. Gratis prøveperioder findes.
9. Octoparse
Hvem er den til: Ikke-tekniske til semi-tekniske brugere.
Octoparse er et etableret no-code værktøj med en og AI-baseret auto-detect. Den håndterer logins, uendelig scroll og kan eksportere i flere formater.
- Bedst til: Analytikere, små virksomheder eller research.
- Pris: Gratis niveau; betalte planer starter ved $119/måned.
10. Apify
Hvem er den til: Udviklere og tech-teams, der har brug for skræddersyet scraping/automation.
Apify er en cloud-platform til at køre scraping-scripts (“actors”) og har en . Den skalerer godt, integrerer med AI og understøtter proxy management.
- Bedst til: Udviklere, der vil køre egne scripts i skyen.
- Pris: Gratis niveau; forbrugsbaserede planer starter ved $49/måned.
11. Zyte (Scrapy Cloud)
Hvem er den til: Udviklere og virksomheder, der vil have enterprise-grade scraping.
Zyte står bag Scrapy og tilbyder en cloud-platform med . Den håndterer planlægning, proxies og projekter i stor skala.
- Bedst til: Dev-teams med langsigtede scraping-projekter.
- Pris: Gratis trials til skræddersyede enterprise-planer.
12. Webscraper.io
Hvem er den til: Begyndere, journalister og forskere.
er en til klik-baseret dataudtræk. Den er enkel, gratis lokalt og tilbyder cloud-service til større jobs.
- Bedst til: Hurtige, enkeltstående scraping-opgaver.
- Pris: Gratis udvidelse; cloud-planer starter ved ca. $50/måned.
13. ParseHub
Hvem er den til: Ikke-tekniske brugere, der har brug for mere kraft end de helt basale værktøjer.
ParseHub er en desktop-app med et visuelt workflow til at scrape dynamisk indhold, inkl. kort og formularer. Den kan køre projekter i skyen og tilbyder et API.
- Bedst til: Digitale marketingfolk, analytikere og journalister.
- Pris: Gratis niveau (200 sider/kørsel); betalte planer starter ved $189/måned.
14. Diffbot
Hvem er den til: Enterprise og AI-virksomheder, der har brug for strukturerede webdata i stor skala.
Diffbot bruger computer vision og NLP til fra enhver webside og tilbyder API’er til artikler, produkter samt en stor knowledge graph.
- Bedst til: Market intelligence, finans og træningsdata til AI.
- Pris: Premium, fra ca. $299/måned.
15. DataMiner
Hvem er den til: Ikke-tekniske brugere – især i salg, marketing og journalistik.
DataMiner er en til hurtig, klik-baseret dataudtræk. Den har et bibliotek af færdige “recipes” og kan eksportere direkte til Google Sheets.
- Bedst til: Hurtige opgaver som at eksportere tabeller eller lister til regneark.
- Pris: Gratis niveau (500 sider/dag); Pro starter ved ca. $19/måned.
Sammenligning af de bedste AI Web Scraper-værktøjer: Hvad passer til dine behov?
Her er en hurtig sammenligning, så du kan finde det rigtige match:
| Tool | AI/LLM Usage | Ease of Use | Output/Integration | Ideal For | Pricing |
|---|---|---|---|---|---|
| Thunderbit | Naturligt sprog-UI; AI foreslår felter | Nemmest (no-code chat) | Sheets, Airtable, Notion-eksport | Ikke-tekniske teams | Gratis niveau; Pro ~$30/md |
| Crawl4AI | AI-klar crawling; integrér LLMs | Svær (kode i Python) | Library/CLI; integrér via kode | Devs der skal bruge hurtige AI-datapipelines | Gratis |
| ScrapeGraphAI | LLM prompt-pipelines til scraping | Medium (lidt kode eller API) | API/SDK; JSON-output | Devs/analytikere der bygger AI-agenter | Gratis OSS; API $20+/md |
| Firecrawl | Crawls til LLM-klar Markdown/JSON | Medium (API/SDK) | SDKs (Py, Node, osv.); LangChain-integration | Devs der kobler live webdata til AI | Gratis + betalt cloud |
| Browse AI | AI-assisteret point & click | Nem (no-code) | 7000+ app-integrationer (Zapier) | Ikke-tekniske brugere der automatiserer web-overvågning | Gratis 50 runs; Betalt $19+/md |
| LLM Scraper | Bruger LLMs til at parse side til schema | Svær (kode TS/JS) | Kodebibliotek; JSON-output | Devs der vil have AI til parsing | Gratis (brug egen LLM API) |
| Reader (Jina) | AI-model udtrækker tekst/JSON | Nem (simpelt API-kald) | REST API returnerer Markdown/JSON | Devs der tilføjer web search/indhold til LLMs | Gratis API |
| Bright Data | AI-forbedrede scraping-API’er; stort proxy-netværk | Svær (API, teknisk) | API’er/SDKs; datastreams eller datasæt | Enterprise-skala | Forbrugsbaseret |
| Octoparse | AI auto-detect af lister | Moderat (no-code app) | CSV/Excel, API til resultater | Semi-tekniske brugere | Gratis begrænset; $59–$166/md |
| Apify | Nogle AI-features (Actors, AI-tutorials) | Svær (kode scripts) | Omfattende API; integrerer med LangChain | Devs der skal bruge custom scraping i cloud | Gratis niveau; pay-as-you-go |
| Zyte (Scrapy) | ML-baseret auto extraction; Scrapy framework | Svær (kode Python) | API, Scrapy Cloud UI; JSON/CSV | Dev teams, langsigtede projekter | Custom pricing |
| Webscraper.io | Ingen AI (manuelle templates) | Nem (browser extension) | CSV-download, Cloud API | Begyndere, hurtige one-off scrapes | Gratis udvidelse; Cloud ~$50/md |
| ParseHub | Ingen eksplicit LLM; visuel builder | Moderat (no-code app) | JSON/CSV; API til cloud runs | Ikke-devs der scraper komplekse sites | Gratis 200 sider; Betalt $189+/md |
| Diffbot | AI vision/NLP til enhver side; knowledge graph | Nem (bare API-kald) | API’er (Article/Prod/...) + Knowledge Graph query | Enterprise, strukturerede webdata | Starter ~$299/md |
| DataMiner | Ingen LLM; community recipes | Nemmest (browser UI) | Excel/CSV-eksport; Google Sheets | Ikke-tekniske brugere der scraper til regneark | Gratis begrænset; Pro ~$19/md |
Værktøjstyper: Fra udvikler-favoritter til forretningsvenlige Web Scrapers
For at gøre listen mere spiselig kan vi dele værktøjerne op i nogle tydelige kategorier:
1. Udvikler- og open-source-kraftværker
- Eksempler: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Styrker: Høj fleksibilitet, skalerbarhed og mulighed for at skræddersy. Perfekt til egne pipelines eller integration med AI-modeller.
- Ulemper: Kræver kode og mere opsætning.
- Use cases: Bygge en custom datapipeline, scrape komplekse sites eller integrere med interne systemer.
2. AI-integrerede scraping-agenter
- Eksempler: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Styrker: Forkorter vejen fra “hent data” til “forstå data”. Naturligt sprog gør dem langt mere tilgængelige.
- Ulemper: Nogle er stadig i udvikling og giver ikke altid helt finmasket kontrol.
- Use cases: Hurtige svar/datasæt, autonome agenter eller live data til LLM’er.
3. No-code/low-code, forretningsvenlige scrapere
- Eksempler: Thunderbit, Browse AI, Octoparse, ParseHub, , DataMiner
- Styrker: Brugervenlige, kræver minimal eller ingen kode, og passer godt til løbende forretningsopgaver.
- Ulemper: Kan få det svært på meget komplekse sites eller ved ekstrem skala.
- Use cases: Leadgenerering, konkurrentovervågning, research og enkeltstående dataudtræk.
4. Enterprise dataplatforme og services
- Eksempler: Bright Data, Diffbot, Zyte
- Styrker: End-to-end løsninger, managed services, compliance og driftssikkerhed i stor skala.
- Ulemper: Dyrere og kræver ofte mere onboarding.
- Use cases: Store, altid-kørende datapipelines, market intelligence og AI-træningsdata.
Sådan vælger du den rigtige AI-webcrawler til dine web scraping-behov
Det kan hurtigt føles som en jungle at vælge, så her er min trin-for-trin guide:
- Afklar mål og datakrav: Hvilke sites og hvilke data? Hvor ofte? Hvor meget? Og hvad skal data bruges til?
- Vurder dit tekniske niveau: Ingen kode? Prøv Thunderbit, Browse AI eller Octoparse. Lidt scripting? LLM Scraper eller DataMiner. Stærke dev-skills? Crawl4AI, Apify eller Zyte.
- Tænk i frekvens og skala: Engangsopgave? Brug gratis værktøjer. Gentagende? Kig efter planlægning. Stor skala? Enterprise eller open-source i stor skala.
- Budget og prismodel: Gratis planer er perfekte til at teste. Abonnement vs. forbrug afhænger af dit behov.
- Test og proof of concept: Prøv et par værktøjer på dine egne data. De fleste har gratis niveauer.
- Vedligeholdelse og support: Hvem fikser det, når sitet ændrer sig? No-code med AI kan ofte rette små ændringer automatisk; open-source afhænger af dig eller community.
- Match værktøj til scenarie: Salgsteam der scraper leads? Thunderbit eller Browse AI. Researcher der samler tweets? DataMiner eller . AI-model der skal bruge nyhedsartikler? Jina Reader eller Zyte. Bygge en sammenligningsside? Apify eller Zyte.
- Planlæg en backup: Nogle gange virker ét værktøj bare ikke på et bestemt site. Hav en fallback.
Det “rigtige” værktøj er det, der giver dig de data, du skal bruge, med mindst mulig friktion – og inden for budget. Ofte er det en kombination.
Thunderbit vs. klassiske Web Scraper-værktøjer: Hvad gør den anderledes?
Lad os være helt konkrete om, hvorfor Thunderbit skiller sig ud:
- Interface i naturligt sprog: Ingen kode og ingen klik-gymnastik. Beskriv bare, hvad du vil have ().
- Nul konfiguration & forslag til templates: Thunderbit finder automatisk pagination, undersider og foreslår templates til populære sites ().
- AI-drevet datarensning og berigelse: Opsummér, kategorisér, oversæt og berig data, mens du scraper ().
- Mindre vedligeholdelsesbøvl: Thunderbits AI er robust over for mindre ændringer på sites, så ting går sjældnere i stykker.
- Integration til business-værktøjer: Direkte eksport til Google Sheets, Airtable, Notion – ingen CSV-manøvrer ().
- Hurtigere værdi: Fra idé til data på minutter – ikke dage.
- Lav læringskurve: Kan du browse nettet og forklare, hvad du vil have, kan du bruge Thunderbit.
- Fleksibilitet: Scrape websites, PDF’er, billeder m.m. – med samme værktøj.
Thunderbit er ikke bare en scraper – det er en dataassistent, der passer ind i dit workflow, uanset om du arbejder med salg, marketing, ecommerce eller ejendom.
Best practices for web scraping med AI Web Scraper-værktøjer
For at få mest muligt ud af AI Web Scrapers får du her mine bedste råd:
- Definér dine databehov tydeligt: Kend felter, antal sider og ønsket format.
- Brug AI-forslag aktivt: Udnyt felt-detektion og AI-forslag, så du ikke overser vigtige data ().
- Start småt og valider: Test på et lille udsnit, tjek output og justér.
- Håndtér dynamisk indhold: Sørg for at værktøjet understøtter interaktioner (pagination, uendelig scroll osv.).
- Respektér website-politikker: Tjek robots.txt, undgå følsomme data og respekter rate limits.
- Integrér for automatisering: Brug eksport og webhooks til at sende data direkte ind i workflowet.
- Hold datakvaliteten høj: Lav sanity checks, brug efterbehandling og overvåg fejl.
- Skriv korte, præcise prompts: Klare instruktioner giver bedre resultater.
- Lær af community: Fora og communities er guld værd til tips og fejlfinding.
- Hold dig opdateret: AI-værktøjer udvikler sig hurtigt – følg med i nye features.
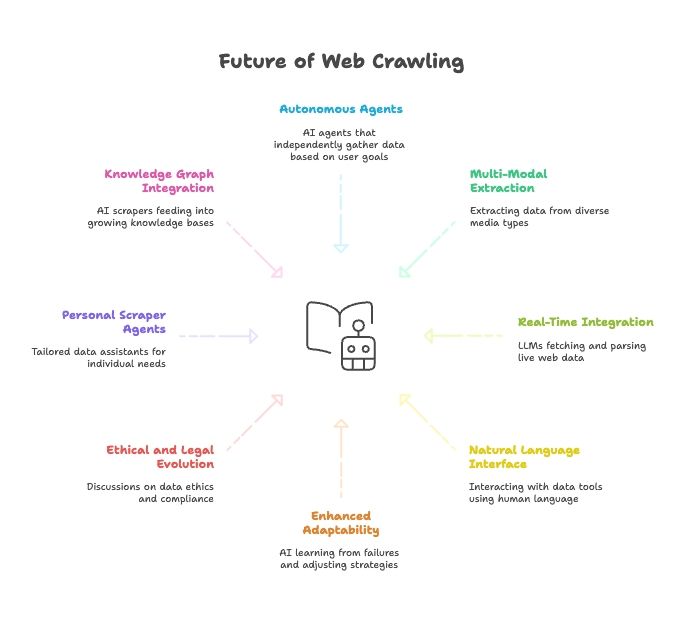
Fremtiden for web scraping: AI, LLM’er og naturligt sprog som standard
Fremadrettet går sammensmeltningen af AI og web scraping kun hurtigere:
- Fuldt autonome scraping-agenter: Snart fortæller du bare en agent dit mål, og den finder selv ud af at hente data.
- Multimodal dataudtræk: Scrapere vil hente data fra tekst, billeder, PDF’er – og endda video.
- Realtidsintegration med AI-modeller: LLM’er får indbyggede moduler til at hente og parse live webdata.
- Naturligt sprog til alt: Vi taler med dataværktøjer, som vi taler med mennesker – så alle kan indsamle og transformere data.
- Bedre tilpasningsevne: AI-scrapere lærer af fejl og justerer strategi automatisk.
- Etik og jura i udvikling: Forvent mere fokus på dataetik, compliance og fair use.
- Personlige scraping-agenter: Forestil dig en personlig dataassistent, der samler nyheder, jobopslag m.m. efter dine behov.
- Integration med knowledge graphs: AI-scrapere vil løbende fodre voksende vidensbaser og gøre AI smartere.
Konklusionen? Fremtiden for web scraping hænger tæt sammen med AI’s udvikling. Værktøjerne bliver klogere, mere autonome og mere tilgængelige dag for dag.
Konklusion: Skab forretningsværdi med den rigtige AI-webcrawler
Web scraping er gået fra nichekompetence til en central forretningskapabilitet – takket være AI. De 15 værktøjer her viser, hvad der er muligt i 2026, fra udvikler-tunge løsninger til forretningsvenlige assistenter.
Hemmeligheden er enkel: Det rigtige værktøj kan mangedoble værdien af dine webdata. For ikke-tekniske teams er Thunderbit den nemmeste måde at gøre nettet til en struktureret database, klar til analyse – uden kode, uden besvær, bare resultater.
Uanset om du samler leads, overvåger konkurrenter eller fodrer din næste AI-model, så brug tid på at afklare behov, teste et par værktøjer og vælge det, der passer. Og hvis du vil opleve fremtidens web scraping allerede i dag, så . De indsigter, du mangler, er kun en prompt væk.
Nysgerrig på mere? Se for guides, tutorials og det nyeste inden for AI-drevet dataudtræk.
Videre læsning:
FAQs
1. Hvad er en AI-webcrawler, og hvordan adskiller den sig fra traditionelle web scrapere?
En AI-webcrawler bruger NLP og machine learning til at forstå, udtrække og strukturere webdata. I modsætning til traditionelle scrapere, der kræver manuel kodning og XPath-selectors, kan AI-værktøjer håndtere dynamisk indhold, tilpasse sig layoutændringer og forstå instruktioner i almindeligt sprog.
2. Hvem bør bruge AI web scraping-værktøjer som Thunderbit?
Thunderbit er lavet til både ikke-tekniske og tekniske brugere. Den er ideel til salg, marketing, drift, research og ecommerce, der vil udtrække strukturerede data fra websites, PDF’er eller billeder – uden at skrive kode.
3. Hvilke funktioner gør Thunderbit særligt i forhold til andre AI-webcrawlere?
Thunderbit tilbyder interface i naturligt sprog, crawling i flere niveauer, automatisk strukturering af data, OCR-understøttelse og nem eksport til fx Google Sheets og Airtable. Derudover får du AI-forslag til felter og færdige templates til populære sites.
4. Findes der gratis muligheder for AI web scraping i 2026?
Ja. Flere værktøjer som Thunderbit, Browse AI og DataMiner har gratis planer med begrænset brug. For udviklere findes open-source muligheder som Crawl4AI og ScrapeGraphAI, der giver fuld funktionalitet uden licensomkostninger – men kræver teknisk opsætning.
5. Hvordan vælger jeg den rigtige AI-webcrawler til mine behov?
Start med at afklare dine datamål, dit tekniske niveau, budget og krav til skala. Hvis du vil have en no-code løsning, der er nem at bruge, er Thunderbit eller Browse AI gode valg. Til stor skala eller skræddersyede behov passer Apify eller Bright Data bedre.