Lad mig fortælle dig en hemmelighed: Jeg troede engang, at web scraping kun var for hackere i hættetrøjer eller data scientists med flere skærme, end de egentlig havde brug for. Men i dag er det at udtrække data fra en hjemmeside lige så normalt i erhvervslivet som at hente morgenkaffen — bortset fra, heldigvis, at du hverken behøver kunne Python eller drikke tre espressoer før frokost. Med fremkomsten af AI-webscraper-værktøjer kan selv folk, der tror, at “HTML” er en ny sandwich hos Subway, hente strukturerede data fra det vilde web.
Hvis du nogensinde har siddet og kopieret og indsat rækker af produktinfo, leads eller prislister i et regneark, er du langt fra alene. Næsten bruger nu web scraping til markedsindsigt og overvågning af konkurrenter. Og med markedet for web scraping-software på vej mod er det tydeligt: dataudtræk fra web er ikke længere kun for tech-eliten. Så uanset om du arbejder med salg, marketing eller bare vil slippe for manuel indtastning, er denne guide til dig. Jeg gennemgår det grundlæggende, sammenligner traditionelle og AI-drevne metoder og viser dig, hvordan du kommer i gang — helt uden hættetrøje.
Grundlæggende om Web Scraper: Hvad betyder det at scrape data fra en hjemmeside?
Lad os starte enkelt. En web scraper er bare et værktøj (eller et script eller en Chrome-udvidelse), der automatisk indsamler data fra hjemmesider. Tænk på det som en lynhurtig praktikant, der aldrig brokker sig over gentagne opgaver. I stedet for at du kopierer og indsætter information række for række, klarer en web scraper det hele på få sekunder — og den beder endda ikke om kaffepause.
Der er to hovedtyper af data, du vil støde på:
- Strukturerede data: Det er de pæne, regnearksklare data — tænk tabeller med produktnavne, priser eller e-mails. De er organiserede, mærkede og nemme at analysere.
- Ustrukturerede data: Det er det vilde vesten — blogindlæg, anmeldelser, billeder eller andet, der ikke passer pænt ind i rækker og kolonner. De fleste web scraping-projekter har til formål at omdanne ustrukturerede data til strukturerede data, så de faktisk kan bruges.
Hvis du nogensinde har kopieret en tabel fra en hjemmeside ind i Excel, tillykke — så har du lavet manuel web scraping. Forestil dig nu at gøre det for 10.000 sider. (Det skal du ikke. Det er netop det, web scrapers er til.)
Hvorfor scrape data fra hjemmesider? De vigtigste fordele for virksomheder
Så hvorfor overhovedet bruge tid på at scrape data? Det korte svar er: virksomheder lever af data, og nettet er verdens største database. Uanset om du arbejder med salg, marketing, ecommerce eller ejendom, kan dataudtræk fra web give dig et markant forspring.
Her er nogle af de mest almindelige forretningscases:
| Brugsscenarie | Beskrivelse | Eksempel på ROI/fordel |
|---|---|---|
| Leadgenerering | Indsamling af kontaktoplysninger, e-mails eller virksomhedslister fra kataloger eller sociale sider | Salgsteams sparer timer og finder flere kvalificerede leads |
| Prisovervågning | Sporing af konkurrentpriser, lagerstatus eller kampagner i realtid | Detailhandlere justerer priser dynamisk og øger salget med 4 % |
| Markedsanalyse | Samling af anmeldelser, nyheder eller sociale signaler for at spotte trends | Marketingfolk målretter kampagner efter aktuelle forbrugerindsigter |
| Konkurrentanalyse | Overvågning af rivalers produktkataloger, lanceringer eller indhold | Virksomheder reagerer hurtigere på markedsændringer |
| Ejendomsindsigt | Scraping af boligannoncer, priser og tilgængelighed | Mæglere og investorer opdager muligheder før markedet |
Faktisk bruger i Storbritannien og Europa dynamiske prisstrategier drevet af konkurrenters pris-scraping. Og virksomheder som John Lewis og ASOS har set målbare salgsstigninger ved at bruge webdata til klogere beslutninger.
Traditionelle Web Scraper-værktøjer: Hvordan fungerer de?
Lad os spole tilbage til den “klassiske” måde at scrape data på — før AI begyndte at flexe musklerne. Traditionelle web scrapers er typisk scripts (ofte skrevet i Python) eller browserudvidelser, der følger et sæt regler for at hente de data, du vil have.
Sådan ser processen typisk ud:
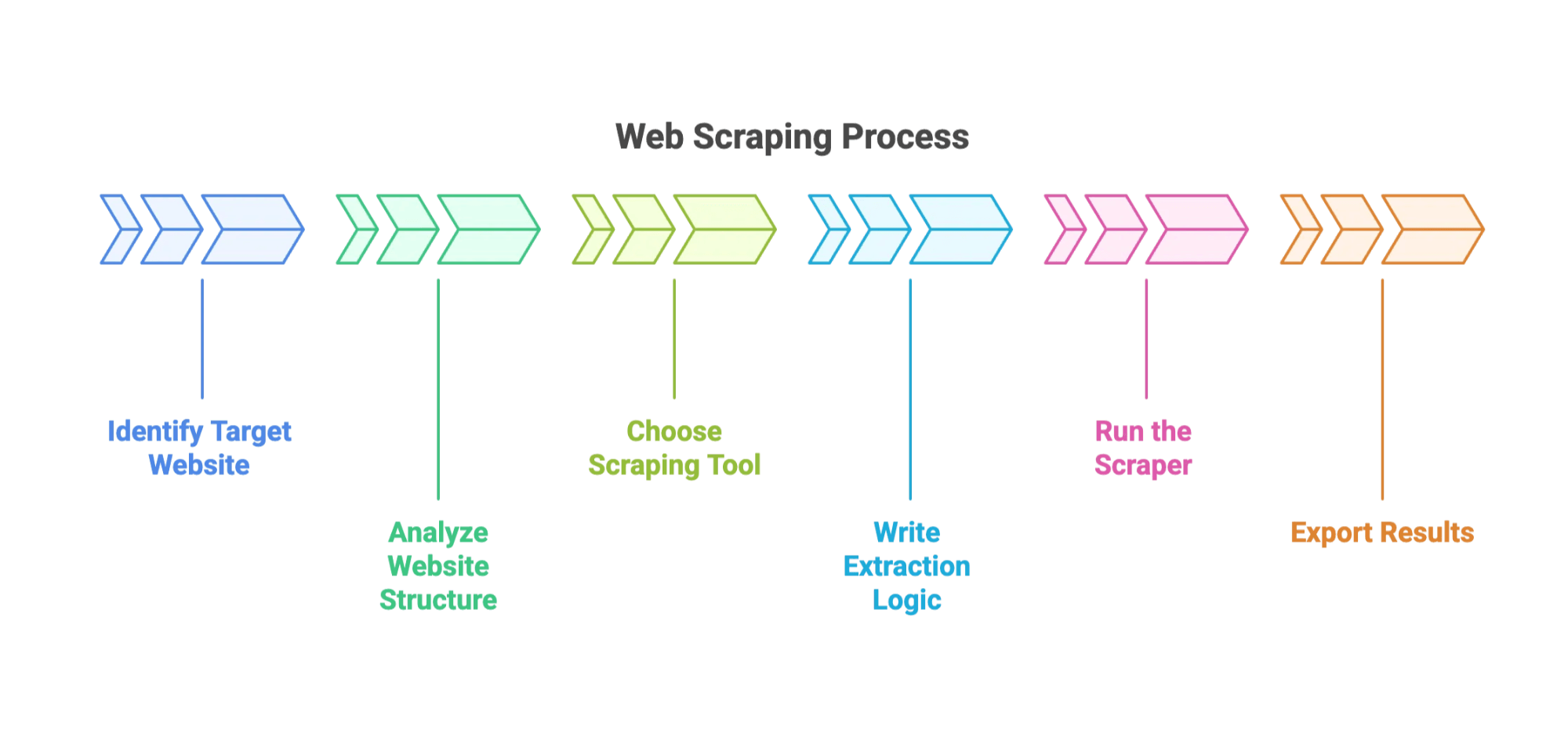
- Identificér din mål-hjemmeside og de ønskede datafelter.
- Analysér hjemmesidens struktur. (Det betyder at rode rundt i HTML’en med browserens Developer Tools. Det er lidt som digital arkæologi.)
- Vælg dit værktøj: Populære muligheder er , eller browser-plugins.
- Skriv udtrækslogikken: Fortæl værktøjet, hvordan det skal finde dataene — typisk ved hjælp af CSS-selectors eller XPath.
- Kør scraperen: Se den indsamle data på tværs af sider.
- Eksportér resultaterne: Typisk som CSV, JSON eller direkte til Excel.
Trin for trin: Udtræk data med en traditionel web scraper
Lad os sige, at du vil scrape produktlister fra en e-handelsportal. Her er en begynder-venlig gennemgang:
- Trin 1: Installer Python og BeautifulSoup-biblioteket.
- Trin 2: Brug browseren til at inspicere produktsiden. Find de HTML-tags, der indeholder produktnavn og pris.
- Trin 3: Skriv et kort script, der henter siden, parser HTML’en og udtrækker de relevante felter.
- Trin 4: Gennemløb flere sider (håndtering af paginering).
- Trin 5: Eksportér dataene til en CSV-fil.
Det lyder ligetil, men tro mig — dit første script går sandsynligvis i stykker mindst én gang. (Mit første forsøg scrape’ede 500 rækker med “None”, fordi jeg stavede et class-navn forkert. Ups.)
Almindelige udfordringer med traditionelle Web Scraper-løsninger
Her bliver tingene lidt mere drilske:
- Ændringer på hjemmesiden: Selv en lille justering i sidens layout kan ødelægge din scraper. går i stykker hver uge på grund af ændringer.
- Anti-bot-foranstaltninger: CAPTCHAs, IP-blokeringer og rate limits kan stoppe dig fuldstændigt. Du skal håndtere proxies, forsinkelser og nogle gange endda løse CAPTCHAs.
- Tekniske færdigheder kræves: Du skal kunne lidt kodning og HTML/CSS.
- Vedligeholdelse: Scrapers kræver konstant opsyn og opdateringer.
- Rodede data: Du kommer til at bruge tid på at rydde op i inkonsistente formater, manglende værdier eller mærkelig kodning.
For en nybegynder kan det føles som at bage en kage, mens opskriften hele tiden ændrer sig, og ovnen indimellem låser dig ude.
Her kommer AI Web Scraper: Gør dataudtræk tilgængeligt for alle
Nu til det sjove. AI-webscrapere er ved at ændre spillet (ups, næsten brugte jeg den forbudte formulering). I stedet for at skrive kode eller rode med selectors kan du bare fortælle værktøjet, hvad du vil have, i helt almindeligt dansk. AI’en klarer resten.
Thunderbit (det er os!) er et godt eksempel på den nye generation. Med kan du udtrække strukturerede data fra enhver hjemmeside ved hjælp af naturligt sprog — helt uden kodning. Uanset om du arbejder med salg, marketing eller ecommerce, kan du indsamle de data, du har brug for, på minutter i stedet for dage.
Thunderbit AI Web Scraper: Sådan gør den dataudtræk enklere
Lad mig vise dig, hvordan Thunderbit gør livet lettere:
- AI Suggest Fields: Klik bare på “AI Suggest Fields”, så læser Thunderbit hjemmesiden, foreslår kolonnenavne og endda, hvordan hvert felt skal udtrækkes.
- Subpage Scraping: Har du brug for flere detaljer? Thunderbit kan besøge hver underside (som individuelle produktsider) og berige din datatabel automatisk.
- Instant Templates: Til populære sider som Amazon eller Zillow kan du bruge færdiglavede skabeloner — ingen opsætning nødvendig.
- Gratis dataeksport: Eksportér dine data til Excel, Google Sheets, Airtable eller Notion. Download som CSV eller JSON. Ingen skjulte gebyrer.
- Scheduled Scraping: Opsæt tilbagevendende scraping, så dine data altid er opdaterede — perfekt til prisovervågning eller opdatering af leads.
- AI Autofill: Lad AI udfylde onlineformularer for dig (ja, selv den 10-siders leverandør-onboardingformular).
- Email-, telefon- og billedudtræk: Hent kontaktoplysninger eller billeder med ét klik.
Og det bedste? Du behøver ikke kunne det mindste kode. Thunderbits Chrome-udvidelse er tilgængelig , og du kan læse mere på vores .
Sammenligning: traditionelle vs. AI Web Scraper-løsninger
Lad os se, hvordan de to tilgange klarer sig:
| Aspekt | Traditionel Web Scraper | AI Web Scraper (Thunderbit) |
|---|---|---|
| Brugervenlighed | Kræver kodning eller kompleks opsætning | No-code, naturligt sprog-interface |
| Tilpasningsevne | Går let i stykker ved ændringer på siden | AI tilpasser sig automatisk ændringer i layoutet |
| Vedligeholdelse | Høj — kræver hyppige opdateringer | Lav — AI håndterer de fleste ændringer |
| Tekniske færdigheder | Kræver programmering og HTML-kendskab | Designet til forretningsbrugere |
| Opsætningshastighed | Timer til dage | Minutter |
| Databehandling | Manuel oprydning nødvendig | AI renser og strukturerer data automatisk |
| Pris | Gratis (open source), men stor tidsinvestering | Prisvenlige planer, gratis eksportmuligheder |
For de fleste forretningsbrugere, især begyndere, er AI-webscrapere som Thunderbit den klare vinder, når det gælder hastighed, enkelhed og pålidelighed. Traditionelle værktøjer har stadig en plads i meget specialtilpassede eller meget store projekter — men til 95 % af brugsscenarierne er AI vejen frem.
Trin-for-trin-guide: Sådan scraper du data fra en hjemmeside som begynder
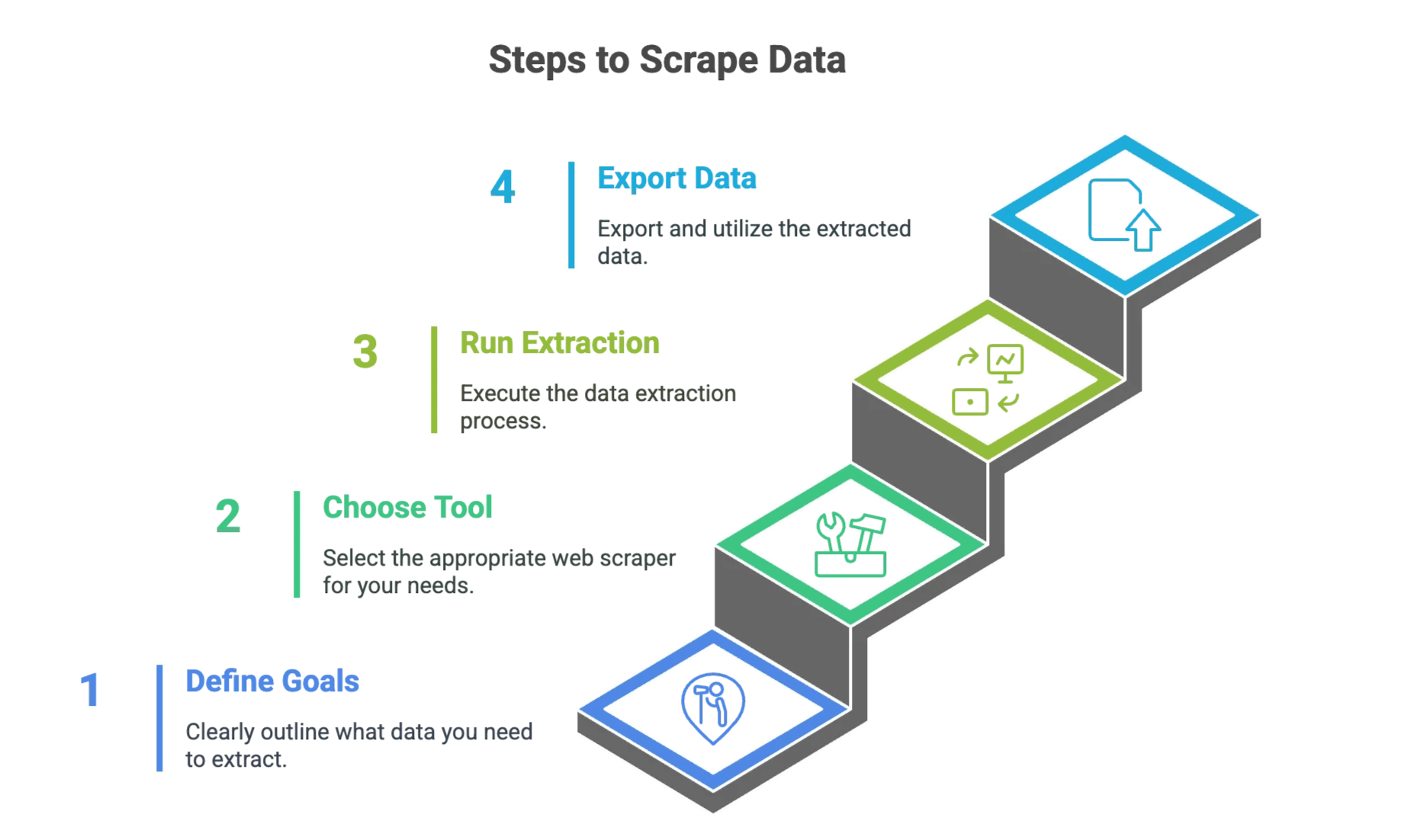
Trin 1: Definér dine mål for dataudtræk
Før du går i gang, skal du være helt klar på, hvad du har brug for. Spørg dig selv:
- Hvilke hjemmeside(r) vil jeg scrape?
- Hvilke datafelter er vigtige? (f.eks. produktnavn, pris, e-mail, telefon)
- Hvor ofte har jeg brug for disse data? (Éngangsudtræk eller tilbagevendende?)
Lav en tjekliste. For eksempel: “Jeg vil indsamle produktnavne, priser og vurderinger fra de første 5 sider på .”
Trin 2: Vælg det rigtige Web Scraper-værktøj
Her er en hurtig beslutningsguide:
- Er du tryg ved kode og vil have fuld kontrol? Prøv et traditionelt værktøj som BeautifulSoup eller Scrapy.
- Vil du have fart, enkelhed og ingen kode? Vælg en AI-webscraper som .
Hvis du er i tvivl, så start med AI. Du kan altid gå mere i dybden senere.
Trin 3: Sæt dit dataudtræk op og kør det
Traditionel tilgang
- Installer dit værktøj: Sæt Python og de nødvendige biblioteker op.
- Inspicér hjemmesiden: Brug browserens DevTools til at finde HTML-strukturen.
- Skriv dit script: Definér, hvordan hvert datafelt skal findes og udtrækkes.
- Test på én side: Sørg for, at du får de rigtige data.
- Skalér op: Tilføj paginering eller loops, så du dækker flere sider.
- Eksportér dine data: Gem som CSV eller JSON.
AI-tilgang (Thunderbit)
- Installer Thunderbit Chrome-udvidelsen: .
- Åbn mål-hjemmesiden: Gå til den side, du vil scrape.
- Klik på “AI Suggest Fields”: Thunderbit læser siden og foreslår kolonner.
- Gennemgå forhåndsvisningen: Tjek, at dataene ser rigtige ud. Justér kolonnerne om nødvendigt.
- Klik på “Scrape”: Thunderbit indsamler dataene for dig.
- Eksportér dine data: Download til Excel, Google Sheets, Airtable eller Notion.
For en visuel gennemgang kan du se vores .
Trin 4: Eksportér og brug dine data
Når du har dine data:
- Eksportér til dit foretrukne værktøj: Excel, Google Sheets, Airtable, Notion, CSV eller JSON.
- Integrér det i dit workflow: Brug det til salgsopsøgende arbejde, prisanalyse, markedsundersøgelser eller hvad din virksomhed nu har brug for.
- Rens og valider: Selv med AI er det klogt at stikprøvekontrollere dine data for nøjagtighed.
Tips til vellykket dataudtræk: Undgå de typiske faldgruber
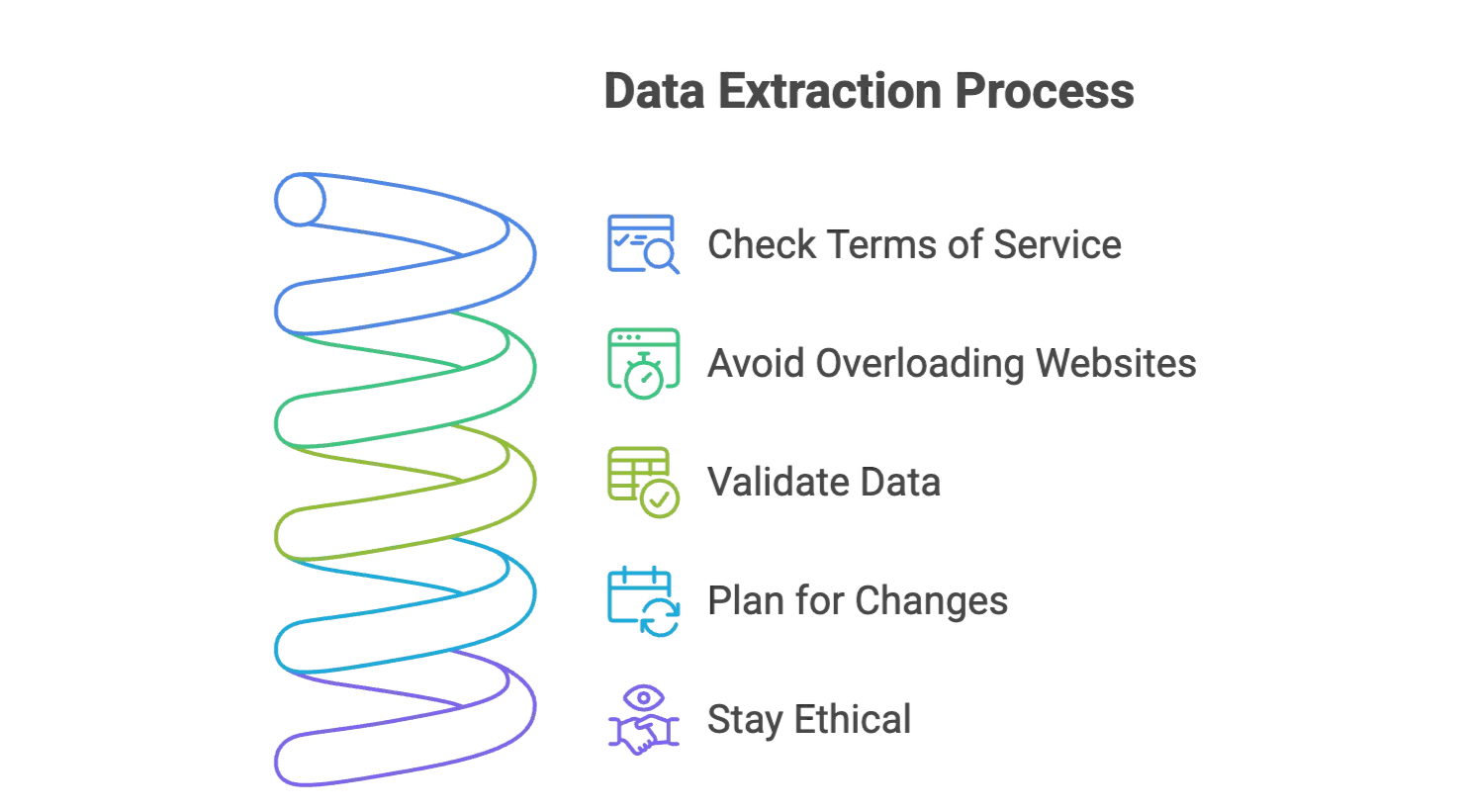
- Tjek hjemmesidens vilkår: Sørg for, at du må scrape dataene. Hold dig til offentligt tilgængelige oplysninger og undgå følsomme persondata.
- Overbelast ikke hjemmesider: Indsæt pauser mellem forespørgsler (ved traditionelle værktøjer), eller lad Thunderbit håndtere det for dig.
- Validér dine data: Kontrollér altid en stikprøve af resultaterne for at sikre nøjagtighed.
- Planlæg for ændringer: Hjemmesider opdateres hele tiden. AI-scrapere som Thunderbit tilpasser sig automatisk, men det er stadig en god idé at holde øje med større ændringer.
- Vær etisk: Scrape kun det, du har brug for, og giv kredit, hvis du bruger dataene i rapporter eller publikationer.
For flere tips, se vores og .
Konklusion og vigtigste pointer
Web scraping er kommet langt — fra dagene med håndkodede scripts til nutidens AI-drevne, begynder-venlige værktøjer. De vigtigste forskelle?

- Traditionelle scrapers giver kontrol, men kræver kodning, vedligeholdelse og tålmodighed.
- AI-webscrapere som gør dataudtræk tilgængeligt for alle med kommandoer i naturligt sprog, øjeblikkelige forhåndsvisninger og stærke funktioner som undersidescraping og planlagt scraping.
Hvis du er ny inden for web scraping, så lad dig ikke skræmme. Værktøjerne har aldrig været nemmere at bruge, og værdien for virksomheder er ubestridelig. Uanset om du vil generere leads, overvåge priser eller bare stoppe med at kopiere og indsætte, er AI-webscrapere din nye bedste ven.
Så næste gang du stirrer på et bjerg af webdata, så husk: du behøver hverken en Ph.d. i datalogi — eller endda en hættetrøje. Bare et klart mål, det rigtige værktøj og måske en god kop kaffe.
Klar til at prøve det selv? og se, hvor nemt dataudtræk fra web kan være.
Fik du lyst til mere? Tjek for dybdegående artikler om scraping af Amazon, Google, PDF’er og meget mere. God scraping!
Ofte stillede spørgsmål
Q1: Er web scraping lovligt? A: Ja, scraping af offentlige data er som udgangspunkt lovligt i mange lande. Tjek dog altid en hjemmesides vilkår, og undgå at scrape følsomme eller personlige data.
Q2: Kan jeg scrape hjemmesider, der kræver login? A: Ja, men det er mere komplekst og kan være i strid med sidens politik. Du skal bruge sessionshåndtering eller værktøjer til autentificeret scraping, og det er vigtigt at vurdere de juridiske konsekvenser.
Q3: Hvordan kan jeg scrape data fra JavaScript-tunge hjemmesider? A: Brug værktøjer, der understøtter dynamisk rendering, som headless-browsere eller AI-scrapere, der simulerer menneskelige interaktioner og parser indhold, der er rendret via JavaScript.
Q4: Hvad er de bedste metoder for at undgå at blive blokeret? A: Brug hastighedsbegrænsning, tilfældige pauser, rotation af user-agent og undgå aggressiv scraping. AI-baserede scrapere håndterer ofte disse strategier automatisk.
Læs mere
-
Oversigt over juridiske retningslinjer, branchestatistik og etiske best practices.
-
Tendenser, markedsvækst og AI’s rolle i dataudtræk fra web (2024–2025).
-
Lær at fortolke robots.txt-filer for at styre etisk og lovligt scraping.