
Lad os være ærlige — Amazon er i praksis hele internettets indkøbscenter, supermarked og elektronikbutik på én gang. Hvis du arbejder med salg, e-handel eller drift, ved du allerede, at det, der sker på Amazon, ikke bliver på Amazon — det påvirker din prissætning, dit lager og endda din næste store produktlancering. Men her er hage: alle de lækre produktdetaljer, priser, ratings og anmeldelser ligger gemt bag en webgrænseflade, der er bygget til kunder, ikke til datatørstige teams. Så hvordan får du fat i de data uden at bruge weekenden på at kopiere og indsætte, som var det 1999?
Det er her web scraping kommer ind i billedet. I denne guide viser jeg dig to måder at udtrække Amazons produktdata på: den klassiske “smøg ærmerne op og kod det i Python”-tilgang og den moderne “lad AI klare det hårde arbejde”-vej med en no-code web scraper som . Jeg gennemgår rigtig Python-kode (med alle faldgruberne og workarounds), og bagefter viser jeg, hvordan Thunderbit kan give dig de samme data med blot et par klik — helt uden kodning. Uanset om du er udvikler, forretningsanalytiker eller bare en, der er træt af manuel dataindtastning, så er du dækket ind.
Hvorfor udtrække Amazons produktdata? (amazon scraper python, web scraping with python)
Amazon er ikke bare verdens største online forhandler — det er også verdens største åbne marked for konkurrenceindsigt. Med og er Amazon en guldmine for alle, der vil:

- Overvåge priser (og justere dine i realtid)
- Analysere konkurrenter (følge deres nye lanceringer, ratings og anmeldelser)
- Generere leads (finde sælgere, leverandører eller potentielle partnere)
- Forudsige efterspørgsel (ved at holde øje med lagerbeholdning og salgssrank)
- Spotte markedstendenser (ved at grave i anmeldelser og søgeresultater)
Og det er ikke bare teori — virksomheder ser faktisk et reelt afkast. For eksempel brugte en elektronikforhandler scraped Amazon-prisdata til at , mens et andet brand så efter at have automatiseret konkurrenternes prisovervågning.
Her er en hurtig tabel over brugsscenarier og den type ROI, du kan forvente:
| Brugsscenarie | Hvem bruger det | Typisk ROI / fordel |
|---|---|---|
| Prisovervågning | E-handel, drift | 15%+ løft i profitmargin, 4% højere salg, 30% mindre analysertid |
| Konkurrentanalyse | Salg, produkt, drift | Hurtigere prisjusteringer, bedre konkurrenceevne |
| Markedsanalyse (anmeldelser) | Produkt, marketing | Hurtigere produktiteration, bedre annoncecopy, SEO-indsigter |
| Leadgenerering | Salg | 3.000+ leads/måned, 8+ timer sparet pr. sælger pr. uge |
| Lager- og efterspørgselsprognoser | Drift, forsyningskæde | 20% reduktion i overlager, færre udsolgte varer |
| Trendopsporing | Marketing, ledelse | Tidlig opdagelse af populære produkter og kategorier |
Og her er det afgørende: rapporterer nu målbar værdi fra dataanalyse. Hvis du ikke scraper Amazon, lader du indsigt — og penge — ligge på bordet.
Overblik: Amazon Scraper Python vs. no-code web scraper-værktøjer
Der er to primære måder at få Amazon-data ud af browseren og ind i dine regneark eller dashboards:
-
Amazon Scraper Python (web scraping with python):
Skriv dit eget script med Python-biblioteker som Requests og BeautifulSoup. Det giver dig fuld kontrol, men du skal kunne kode, håndtere anti-bot-mekanismer og vedligeholde dit script, når Amazon ændrer sit website.
-
No-code web scraper-værktøjer (som Thunderbit):
Brug et værktøj, hvor du peger, klikker og udtrækker data — helt uden programmering. Moderne værktøjer som bruger endda AI til at finde ud af, hvilke data der skal hentes, håndtere undersider og pagination og eksportere direkte til Excel eller Google Sheets.
Sådan klarer de sig side om side:
| Kriterium | Python Scraper | No-code (Thunderbit) |
|---|---|---|
| Opsætningstid | Høj (installere, kode, fejlfinde) | Lav (installer udvidelse) |
| Nødvendige færdigheder | Kræver kodning | Ingen (peg & klik) |
| Fleksibilitet | Ubegrænset | Høj til almindelige use cases |
| Vedligeholdelse | Du retter koden | Værktøjet opdaterer sig selv |
| Håndtering af anti-bot | Du håndterer proxies og headers | Indbygget, håndteres for dig |
| Skalerbarhed | Manuel (threads, proxies) | Cloud-scraping, paralleliseret |
| Dataeksport | Tilpasset (CSV, Excel, DB) | Én klik til Excel, Sheets |
| Pris | Gratis (din tid + proxies) | Freemium, betal for skala |
I de næste afsnit gennemgår jeg begge tilgange — først hvordan du bygger en Amazon scraper i Python (med rigtig kode), og derefter hvordan du gør det samme med Thunderbits AI web scraper.
Kom i gang med Amazon Scraper Python: forudsætninger og opsætning
Før vi dykker ned i koden, skal vi lige have dit miljø sat op.
Du skal bruge:
- Python 3.x (download fra )
- En kodeeditor (jeg kan godt lide VS Code, men alt virker)
- Følgende biblioteker:
requests(til HTTP-forespørgsler)beautifulsoup4(til HTML-parsing)lxml(hurtig HTML-parser)pandas(til datatabeller/eksport)re(regulære udtryk, indbygget)
Installer bibliotekerne:
1pip install requests beautifulsoup4 lxml pandasProjektopsætning:
- Opret en ny mappe til dit projekt.
- Åbn din editor, og opret en ny Python-fil (f.eks.
amazon_scraper.py). - Så er du klar!
Trin for trin: web scraping med Python til Amazons produktdata
Lad os gennemgå, hvordan man scraper en enkelt Amazon-produktside. (Bare rolig, vi kommer snart til at scrape flere produkter og sider.)
1. Send forespørgsler og hent HTML
Først henter vi HTML’en for en produktside. (Erstat URL’en med et hvilket som helst Amazon-produkt.)
1import requests
2url = "<https://www.amazon.com/dp/B0ExampleASIN>"
3response = requests.get(url)
4html_content = response.text
5print(response.status_code)Obs: Denne grundlæggende forespørgsel bliver sandsynligvis blokeret af Amazon. Du kan se en 503-fejl eller en CAPTCHA i stedet for produktsiden. Hvorfor? Fordi Amazon kan se, at du ikke er en rigtig browser.
Håndtering af Amazons anti-bot-mekanismer
Amazon er ikke fan af bots. For at undgå at blive blokeret skal du:
- Sætte en User-Agent-header (lade som om du er Chrome eller Firefox)
- Rullere User-Agents (brug ikke den samme hver gang)
- Throttle dine forespørgsler (tilføj tilfældige pauser)
- Bruge proxies (til scraping i større skala)
Sådan sætter du headers:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4}
5response = requests.get(url, headers=headers)Vil du gøre det mere avanceret? Brug en liste af User-Agents og roter dem for hver forespørgsel. Ved større opgaver vil du gerne bruge en proxy-tjeneste (der findes masser), men til små scraping-opgaver er headers og pauser som regel nok.
Udtræk af centrale produktfelter
Når du har HTML’en, er det tid til at parse den med BeautifulSoup.
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_content, "lxml")Lad os nu hente det vigtigste:
Produkttitel
1title_elem = soup.find(id="productTitle")
2product_title = title_elem.get_text(strip=True) if title_elem else NonePris
Amazons pris kan stå flere steder. Prøv disse:
1price = None
2price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
3if price_elem:
4 price = price_elem.get_text(strip=True)
5else:
6 price_whole = soup.find("span", {"class": "a-price-whole"})
7 price_frac = soup.find("span", {"class": "a-price-fraction"})
8 if price_whole and price_frac:
9 price = price_whole.text + price_frac.textRating og antal anmeldelser
1rating_elem = soup.find("span", {"class": "a-icon-alt"})
2rating = rating_elem.get_text(strip=True) if rating_elem else None
3review_count_elem = soup.find(id="acrCustomerReviewText")
4reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
5reviews_count = reviews_text.split()[0] # f.eks. "1,554 ratings"Hovedbilledets URL
Amazon skjuler nogle gange højopløsningsbilleder i JSON inde i HTML’en. Her er en hurtig regex-tilgang:
1import re
2match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
3main_image_url = match.group(1) if match else NoneEller hent det primære billedtag:
1img_tag = soup.find("img", {"id": "landingImage"})
2img_url = img_tag['src'] if img_tag else NoneProduktdetaljer
Specifikationer som brand, vægt og dimensioner står typisk i en tabel:
1details = {}
2rows = soup.select("#productDetails_techSpec_section_1 tr")
3for row in rows:
4 header = row.find("th").get_text(strip=True)
5 value = row.find("td").get_text(strip=True)
6 details[header] = valueEller hvis Amazon bruger formatet “detailBullets”:
1bullets = soup.select("#detailBullets_feature_div li")
2for li in bullets:
3 txt = li.get_text(" ", strip=True)
4 if ":" in txt:
5 key, val = txt.split(":", 1)
6 details[key.strip()] = val.strip()Udskriv dine resultater:
1print("Titel:", product_title)
2print("Pris:", price)
3print("Rating:", rating, "baseret på", reviews_count, "anmeldelser")
4print("URL til hovedbillede:", main_image_url)
5print("Detaljer:", details)Scraping af flere produkter og håndtering af pagination
Ét produkt er fint, men du vil nok have en hel liste. Sådan scraper du søgeresultater og flere sider.
Hent produktlinks fra en søgeside
1search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
2res = requests.get(search_url, headers=headers)
3soup = BeautifulSoup(res.text, "lxml")
4product_links = []
5for a in soup.select("h2 a.a-link-normal"):
6 href = a['href']
7 full_url = "<https://www.amazon.com>" + href
8 product_links.append(full_url)Håndter pagination
Amazons søgeresultatsider bruger &page=2, &page=3 osv.
1for page in range(1, 6): # scrape de første 5 sider
2 search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
3 res = requests.get(search_url, headers=headers)
4 if res.status_code != 200:
5 break
6 soup = BeautifulSoup(res.text, "lxml")
7 # ... udtræk produktlinks som ovenfor ...Loop gennem produktsider og eksportér til CSV
Saml dine produktdata i en liste af dictionaries, og brug derefter pandas:
1import pandas as pd
2df = pd.DataFrame(product_data_list) # liste af dicts
3df.to_csv("amazon_products.csv", index=False)Eller til Excel:
1df.to_excel("amazon_products.xlsx", index=False)Bedste praksis for Amazon Scraper Python-projekter
Lad os være ærlige — Amazon ændrer konstant sit site og bekæmper scrapers. Sådan holder du dit projekt kørende:
- Roter headers og User-Agents (brug et bibliotek som
fake-useragent) - Brug proxies til scraping i større skala
- Throttle forespørgsler (tilfældig
time.sleep()mellem forespørgsler) - Håndter fejl elegant (prøv igen ved 503, tag farten af hvis du bliver blokeret)
- Skriv fleksibel parsing-logik (led efter flere selektorer pr. felt)
- Hold øje med HTML-ændringer (hvis dit script pludselig returnerer
Nonefor alt, så tjek siden) - Respekter robots.txt (Amazon forbyder scraping af mange sektioner — scrapp ansvarligt)
- Rens data undervejs (fjern valutasymboler, kommaer, mellemrum)
- Hold forbindelsen til fællesskabet (fora, Stack Overflow, Reddits r/webscraping)
Tjekliste til vedligeholdelse af din scraper:
- [ ] Roter User-Agents og headers
- [ ] Brug proxies, hvis du scraper i stor skala
- [ ] Tilføj tilfældige pauser
- [ ] Gør koden modulær for nemme opdateringer
- [ ] Hold øje med bans eller CAPTCHA’er
- [ ] Eksportér data regelmæssigt
- [ ] Dokumentér dine selektorer og din logik
For et dybere dyk kan du se min .
No-code-alternativet: scrap Amazon med Thunderbit AI Web Scraper
Okay, så du har set Python-tilgangen. Men hvad hvis du ikke vil kode — eller bare vil have dataene på to klik og komme videre med livet? Så er det , du skal bruge.
Thunderbit er en AI web scraper Chrome Extension, der lader dig udtrække Amazons produktdata (og data fra stort set enhver hjemmeside) helt uden kodning. Her er, hvorfor jeg elsker det:
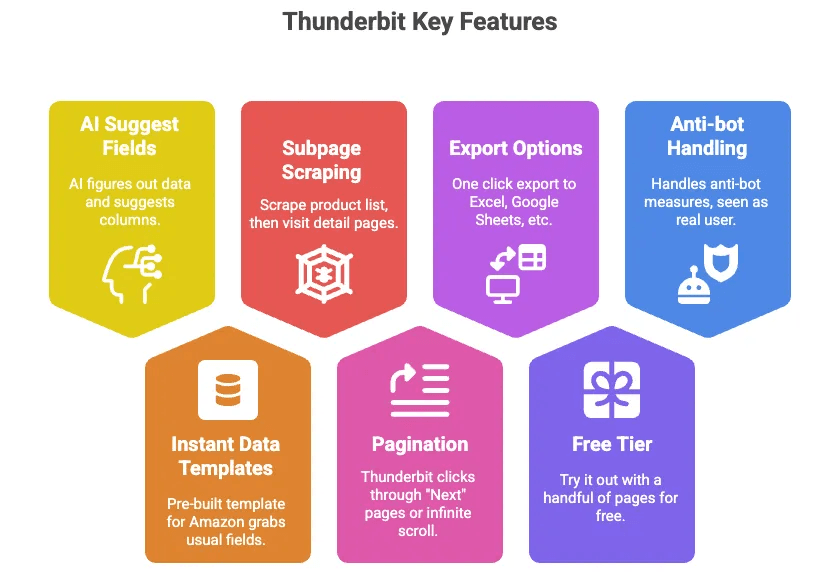
- AI Suggest Fields: Klik blot på en knap, og Thunderbits AI finder ud af, hvilke data der er på siden, og foreslår kolonner (som Titel, Pris, Rating osv.).
- Instant Data Templates: Til Amazon findes der en færdig skabelon, som henter alle de sædvanlige felter — ingen opsætning nødvendig.
- Subpage Scraping: Scrap en liste af produkter, og lad derefter Thunderbit besøge hver produkts detaljeside og hente flere oplysninger automatisk.
- Pagination: Thunderbit kan klikke sig gennem “Næste”-sider eller uendelig scroll for dig.
- Eksport til Excel, Google Sheets, Airtable, Notion: Med ét klik er dine data klar til brug.
- Gratis niveau: Prøv det gratis med nogle få sider.
- Håndterer anti-bot for dig: Da det kører i din browser (eller i skyen), ser Amazon det som en rigtig bruger.
Trin for trin: brug Thunderbit til at scrape Amazon-produktdata
Så nemt er det:
-
Installer Thunderbit:
Download og log ind.
-
Åbn Amazon:
Gå til den Amazon-side, du vil scrape (søgeresultater, produktside, hvad som helst).
-
Klik på “AI Suggest Fields” eller brug en skabelon:
Thunderbit foreslår kolonner, der kan udtrækkes (eller du kan vælge Amazon Product-skabelonen).
-
Gennemgå kolonnerne:
Tilpas kolonnerne, hvis du vil (tilføj/fjern felter, omdøb osv.).
-
Klik på “Scrape”:
Thunderbit henter dataene fra siden og viser dem i en tabel.
-
Håndter undersider og pagination:
Hvis du har scrappet en liste, så klik på “Scrape Subpages” for at besøge hver produkts detaljeside og hente flere oplysninger. Thunderbit kan også automatisk klikke gennem “Næste”-sider.
-
Eksportér dine data:
Klik på “Export to Excel” eller “Export to Google Sheets.” Færdig.
-
(Valgfrit) Planlæg scraping:
Har du brug for disse data hver dag? Brug Thunderbits scheduler til at automatisere det.
Det var det. Ingen kode, ingen fejlfinding, ingen proxies, ingen hovedpine. For en visuel gennemgang kan du tjekke eller siden for .
Amazon Scraper Python vs. no-code web scraper: side om side
Lad os samle det hele:
| Kriterium | Python Scraper | Thunderbit (No-code) |
|---|---|---|
| Opsætningstid | Høj (installere, kode, fejlfinde) | Lav (installer udvidelse) |
| Nødvendige færdigheder | Kræver kodning | Ingen (peg & klik) |
| Fleksibilitet | Ubegrænset | Høj til almindelige use cases |
| Vedligeholdelse | Du retter koden | Værktøjet opdaterer sig selv |
| Håndtering af anti-bot | Du håndterer proxies og headers | Indbygget, håndteres for dig |
| Skalerbarhed | Manuel (threads, proxies) | Cloud-scraping, paralleliseret |
| Dataeksport | Tilpasset (CSV, Excel, DB) | Én klik til Excel, Sheets |
| Pris | Gratis (din tid + proxies) | Freemium, betal for skala |
| Bedst til | Udviklere, skræddersyede behov | Forretningsbrugere, hurtige resultater |
Hvis du er udvikler og elsker at nørkle og har brug for noget meget skræddersyet, er Python din ven. Hvis du vil have fart, enkelhed og nul kode, er Thunderbit vejen frem.
Hvornår skal du vælge Python, no-code eller AI web scraper til Amazon-data?
Vælg Python hvis:
- Du har brug for skræddersyet logik eller vil integrere scraping i dine backend-systemer
- Du scraper i enorm skala (titusindvis af produkter)
- Du vil lære, hvordan scraping fungerer under motorhjelmen
Vælg Thunderbit (no-code, AI web scraper) hvis:
- Du vil have data hurtigt, uden kodning
- Du er forretningsbruger, analytiker eller marketingmedarbejder
- Du vil give dit team mulighed for selv at hente data
- Du vil slippe for besværet med proxies, anti-bot-mekanismer og vedligeholdelse
Brug begge, hvis:
- Du vil prototypere hurtigt med Thunderbit og derefter bygge en skræddersyet Python-løsning til produktion
- Du vil bruge Thunderbit til dataindsamling og Python til datarensning/analyse
For de fleste forretningsbrugere dækker Thunderbit 90% af behovene for Amazon-scraping på en brøkdel af tiden. For de sidste 10% — det super-skræddersyede, storskala eller dybt integrerede — er Python stadig kongen.
Konklusion og vigtigste pointer
At scrape Amazons produktdata er en superkraft for ethvert salg-, e-handels- eller driftsteam. Uanset om du holder øje med priser, analyserer konkurrenter eller bare prøver at spare dit team for endeløs copy-paste, findes der en løsning til dig.
- Python-scraping giver dig fuld kontrol, men kommer med en læringskurve og løbende vedligeholdelse.
- No-code web scrapers som Thunderbit gør udtræk af Amazon-data tilgængeligt for alle — ingen kodning, ingen hovedpine, bare resultater.
- Den bedste tilgang? Brug det værktøj, der passer til dine færdigheder, din tidsplan og dine forretningsmål.
Hvis du er nysgerrig, så prøv Thunderbit — det er gratis at starte med, og du vil blive overrasket over, hvor hurtigt du kan få de data, du har brug for. Og hvis du er udvikler, så vær ikke bange for at blande og matche: nogle gange er den hurtigste vej at bygge at lade AI klare de kedelige dele for dig.
Ofte stillede spørgsmål
1. Hvorfor skulle en virksomhed ville scrape Amazons produktdata?
Scraping af Amazon gør det muligt for virksomheder at overvåge priser, analysere konkurrenter, indsamle anmeldelser til produktresearch, forudsige efterspørgsel og generere salgsemner. Med over 600 millioner produkter og næsten 2 millioner sælgere på Amazon er det en rig kilde til konkurrencemæssig intelligens.
2. Hvad er de vigtigste forskelle mellem at bruge Python og no-code-værktøjer som Thunderbit til at scrape Amazon?
Python-scrapers giver maksimal fleksibilitet, men kræver kodningsfærdigheder, opsætningstid og løbende vedligeholdelse. Thunderbit, en no-code AI web scraper, lader brugere udtrække Amazon-data med det samme via en Chrome-udvidelse — ingen kodning krævet, med indbygget håndtering af anti-bot og eksportmuligheder til Excel eller Sheets.
3. Er det lovligt at scrape data fra Amazon?
Amazons servicevilkår forbyder generelt scraping, og de implementerer aktivt anti-bot-mekanismer. Mange virksomheder scraper dog stadig offentligt tilgængelige data, mens de sørger for at arbejde ansvarligt, f.eks. ved at respektere rate limits og undgå for mange forespørgsler.
4. Hvilken slags data kan jeg udtrække fra Amazon med web scraping-værktøjer?
Typiske datafelter omfatter produkttitler, priser, ratings, antal anmeldelser, billeder, produktspecifikationer, tilgængelighed og endda sælgeroplysninger. Thunderbit understøtter også scraping af undersider og pagination, så du kan indsamle data på tværs af flere lister og sider.
5. Hvornår skal jeg vælge Python-scraping frem for et værktøj som Thunderbit — eller omvendt?
Brug Python, hvis du har brug for fuld kontrol, skræddersyet logik eller planlægger at integrere scraping i backend-systemer. Brug Thunderbit, hvis du vil have hurtige resultater uden kodning, har brug for nem skalering eller er en forretningsbruger, der ønsker en løsning med lav vedligeholdelse.
Vil du gå endnu dybere? Se disse ressourcer:
God scraping — og må dine regneark altid være opdaterede.