Substack scraper

Důvěřují mu profesionálové z předních firem














Odemkněte data ze Substacku s Thunderbitem
Posílejte data ze Substacku přímo do svých aplikací
Přestaňte ručně kopírovat a vkládat detaily publikací na Substacku, jako je jméno autora, název článku nebo počet odběratelů. S Thunderbitem stačí jedno kliknutí a extrahovaná data se pošlou přímo do Google Sheets, Notion nebo Airtable. Analyzujte trendy v publikacích a výkon obsahu bez zdlouhavé ruční práce.
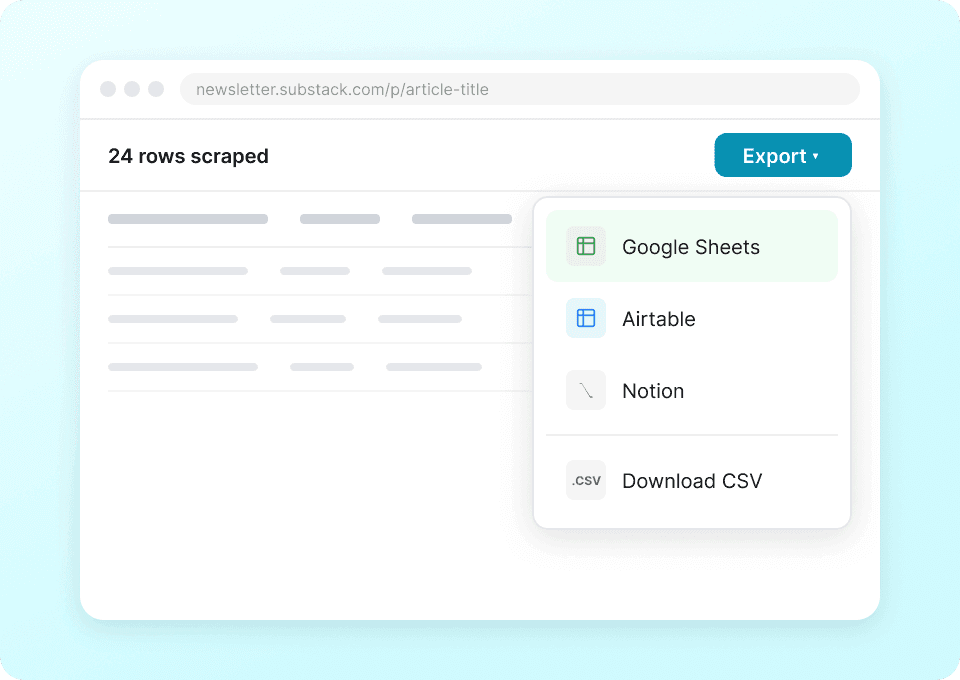
Jeden scraper pro Substack i další weby
Nemusíte používat jiný scraper pro každý web. Thunderbit funguje na Substacku hned po instalaci a obsahuje přes 50 předpřipravených šablon pro další oblíbené platformy. Extrahujte popisy publikací, obsah článků a další data a pak stejný nástroj použijte i jinde.
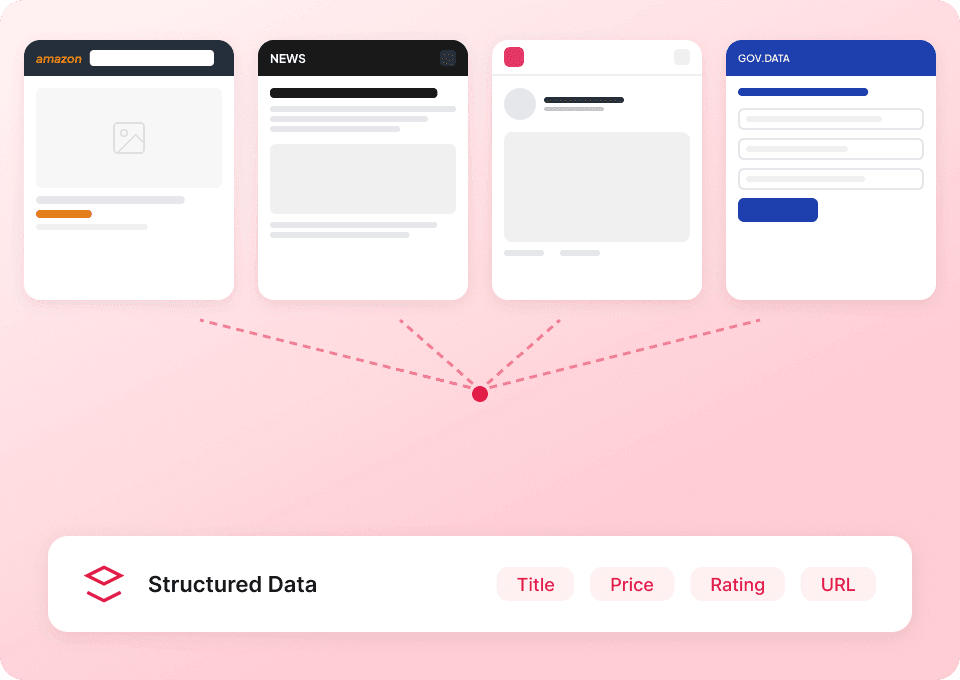
Získejte celý příběh ze Substacku
Stránky seznamu publikací na Substacku zobrazují jen shrnutí. Thunderbit automaticky navštíví každou podstránku článku, aby extrahoval celý obsah, takže získáte kompletní datový soubor. Získejte najednou celý název článku, jméno autora, název publikace i obsah článku.
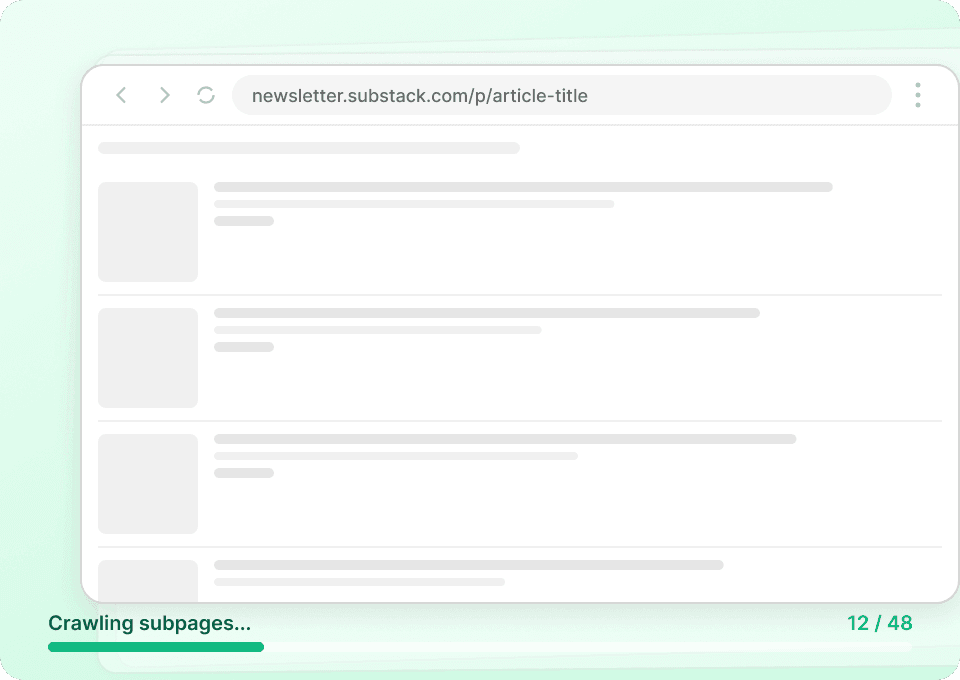
Máte problém efektivně scrapovat Substack?
Podívejte se, proč Thunderbit překonává tradiční scrapery pro data ze Substacku.
Tradiční scrapery
Starý způsob práceThunderbit
Chytřejší přístupNespoléhej jen na naše slova
Podívej se, co uživatelé říkají o Thunderbitu.







Často kladené otázky
Související případy použití
Prozkoumej další případy použití web scraperu Thunderbitu.
Video Scraper
Video Scraper od Thunderbit vám s pomocí AI umožní během pár kliknutí vytěžit data o videích i jejich tvůrcích. Získejte přehledy z výpisů videí, metriky výkonu i detaily profilů a vše pak exportujte do Excelu, Google Sheets, Airtable nebo Notion pro tracking a influencer research.
Zjistit více ->
Trivago scraper
Seškrábejte názvy hotelů, ceny a hodnocení z Trivaga během několika kliknutí — bez kódování a nastavování.
Zjistit více ->
Trustpilot scraper
Proměňte stránky Trustpilot do přehledné tabulky s recenzemi, hodnocením a jmény recenzentů. Stránky za vás přečteme, takže nepotřebujete žádný kód ani kopírování a vkládání.
Zjistit více ->
Priceline scraper
Získejte názvy hotelů, ceny a hodnocení z Priceline jen na pár kliknutí díky AI v Thunderbit.
Zjistit více ->
PlayStation Scraper
Získejte data o hrách pro PlayStation, jako je název, žánr nebo zlevněná cena, na pár kliknutí — bez ručního kopírování a vkládání.
Zjistit více ->Amazon cenový scraper
Dostaňte ceny, hodnocení a ASINy z Amazonu přímo do Google Sheets pomocí klikacího scrapingu — bez složitého nastavování.
Zjistit více ->Připraven posunout extrakci dat na vyšší úroveň?
Přidej se k více než 100 000 profesionálům, kteří už Thunderbit používají k automatizaci svých web scraping procesů.
Zkušební verze nabízí neomezené kredity pro 8 webových stránek.