

PubMed Scraper od Thunderbitu vám pomůže převést stránky PubMedu na čisté, strukturované datové sady pomocí AI. Můžete vytěžit trendy lékařský výzkum, důkazy z klinických studií, abstrakty, autory, afiliace, data publikace, PMID i odkazy na články a následně exportovat do Excelu, Google Sheets, Airtable nebo Notion. Stačí otevřít PubMed v Chromu, nechat AI navrhnout nejlepší sloupce a spustit sběr dat.
🧬 Co je PubMed Scraper
PubMed Scraper je AI Web Scraper vytvořený pro . S rozšířením (AI web scraper pro Chrome) přejdete na libovolnou stránku s výsledky na PubMedu, kliknete na AI Suggest Columns a poté na Scrape — a získáte strukturovaná data bez psaní kódu.
🔎 Co lze z PubMedu získat
PubMed je plný cenných biomedicínských metadat, ale ne vždy jsou hned připravená k analýze. AI Web Scraper od Thunderbitu (https://thunderbit.com/) vám pomůže sesbírat a uspořádat záznamy z výpisů a zároveň je obohatit o detaily na úrovni článku pomocí Subpage Scraping (otevře každou stránku článku a doplní pole jako abstrakt, afiliace, DOI a další).
Níže jsou dva běžné postupy, které zvládnete během pár minut.
📈 Sběr trendujícího lékařského výzkumu na PubMedu
Tento postup využijete pro sledování toho, co je aktuálně „trendy“ ve zdravotnickém výzkumu na stránce PubMed Trending. Hodí se pro udržení přehledu, tvorbu interních přehledů, monitoring publikací konkurence nebo jako vstup do pipeline pro průběžné sledování literatury.
Příklad cílové stránky:
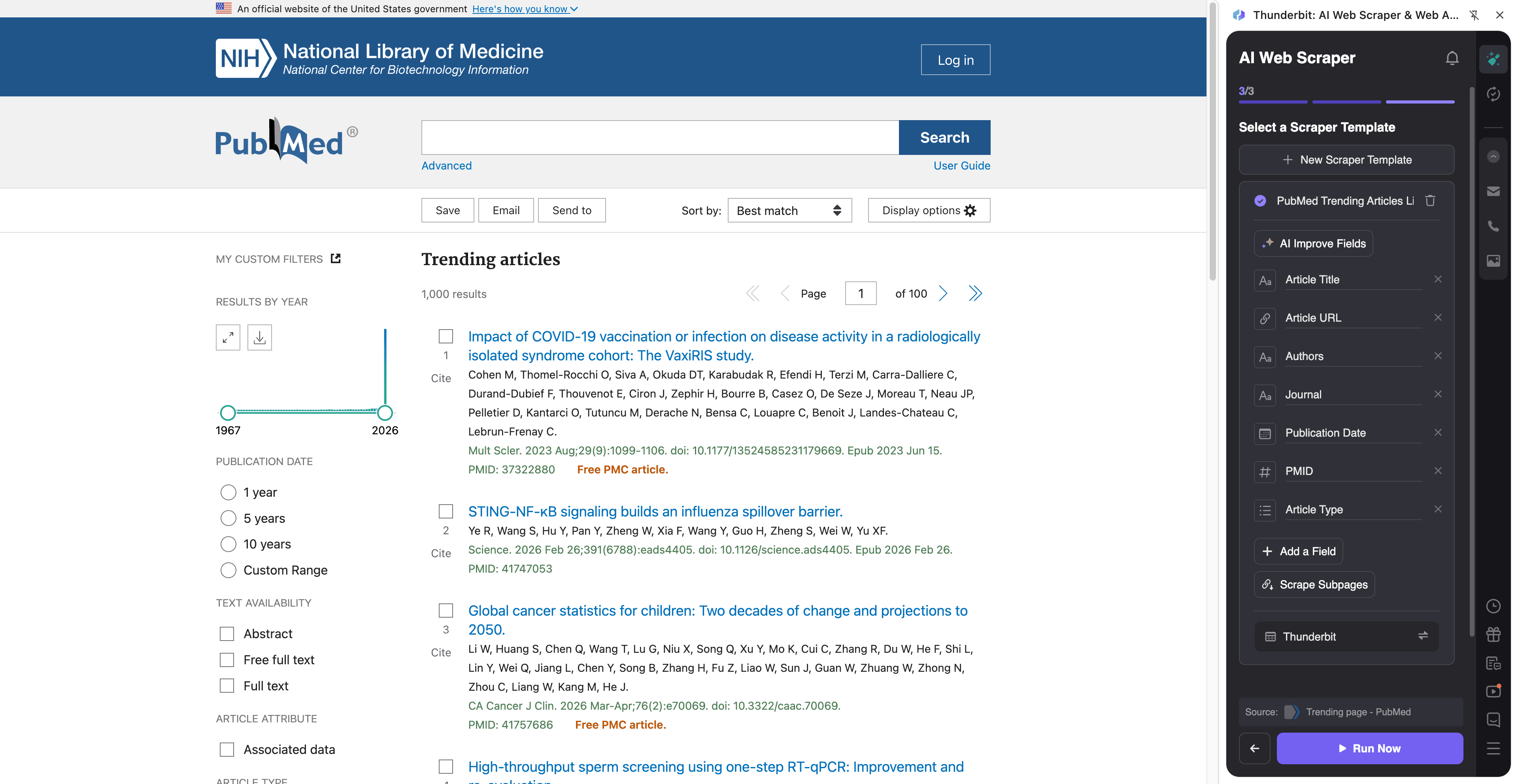
Postup:
- Nainstalujte si a zaregistrujte účet.
- Otevřete cílovou stránku, například: .
- Klikněte na AI Suggest Columns a nechte AI doporučit vhodné názvy sloupců i datové typy.
- Klikněte na Scrape, data vytěžte a poté exportujte do Excelu, Google Sheets, Airtable nebo Notion.
Názvy sloupců
| Sloupec | Popis |
|---|---|
| 🧾 Název článku | Titulek trendujícího článku na PubMedu. |
| 🔗 URL článku | Přímý odkaz na stránku záznamu na PubMedu. |
| 🆔 PMID | Identifikátor záznamu v PubMedu (hodí se jako stabilní klíč). |
| 🏛️ Časopis | Název časopisu, ve kterém byl článek publikován. |
| 📅 Datum publikace | Datum publikace uvedené ve výpisu. |
| ✍️ Autoři | Řetězec autorů zobrazený na kartě výsledku. |
| 🧪 Typ článku | Typ publikace, pokud je k dispozici (např. Review, Clinical Trial). |
| 🏷️ Klíčová slova / témata | Viditelné štítky témat nebo klíčová slova ve výpisu (pokud jsou). |
| 📝 Úryvek / shrnutí | Krátký úryvek textu zobrazený ve výpisu (pokud je). |
| 🧷 DOI | DOI, pokud je k dispozici (často je nejlepší ho získat přes subpage scraping). |
| 🧑🔬 Afiliace | Afiliace autorů (typicky přes subpage scraping). |
| 📄 Abstrakt | Text abstraktu (typicky přes subpage scraping). |
🧫 Sběr důkazů z klinických studií na PubMedu
Tento postup slouží k vytěžení informací souvisejících s klinickými studiemi z výsledků vyhledávání na PubMedu a následnému obohacení každého řádku návštěvou stránky článku — abyste získali abstrakt, signály o typu studie a metadata potřebná pro hodnocení.
Příklad cílové stránky:
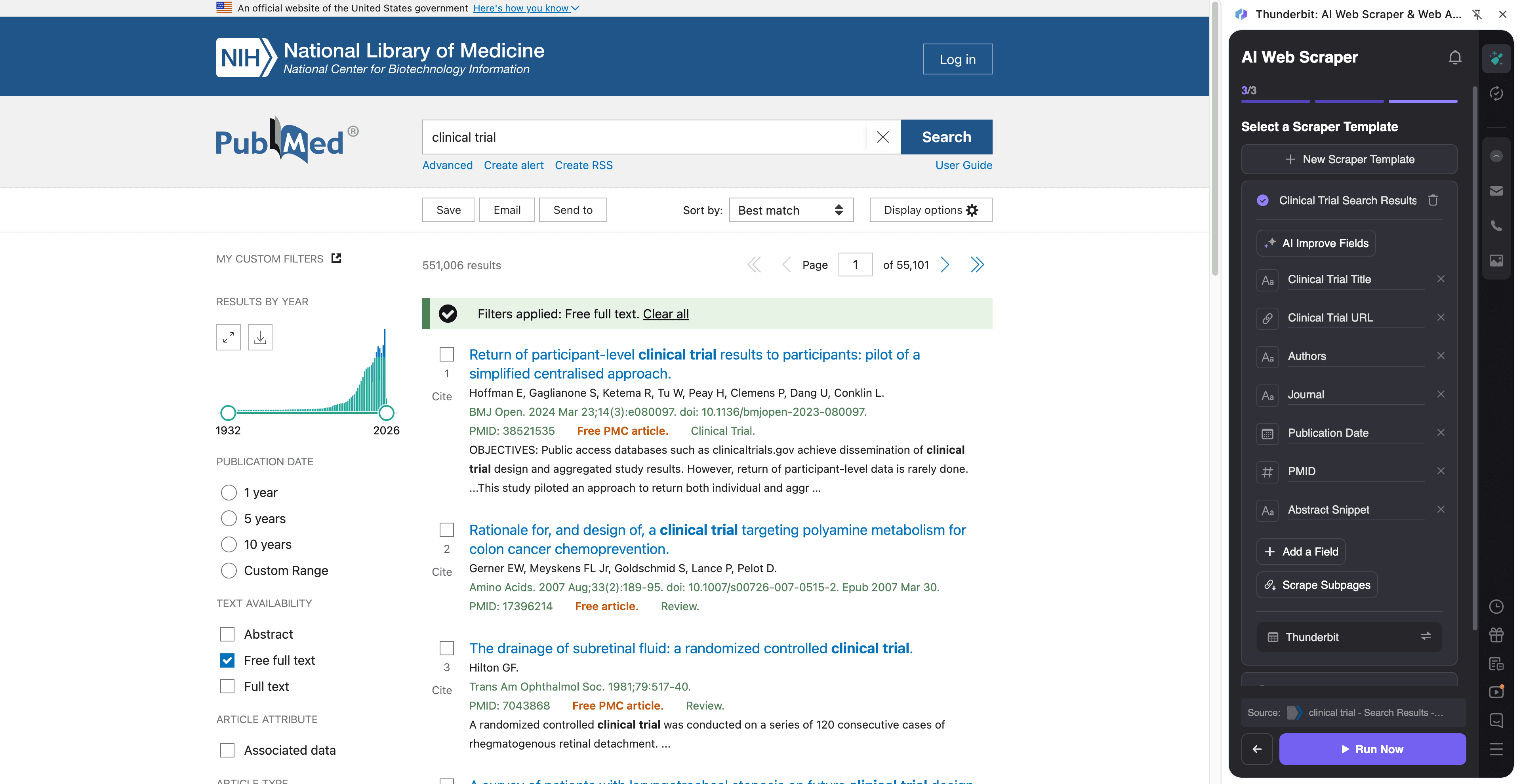
Postup:
- Nainstalujte si a zaregistrujte účet.
- Otevřete cílovou stránku, například: .
- Klikněte na AI Suggest Columns a nechte vygenerovat doporučená pole (můžete je přejmenovat nebo přidat vlastní).
- Klikněte na Scrape pro sběr výsledků a poté použijte Scrape Subpages k obohacení každého řádku o abstrakt, afiliace, DOI a další.
Názvy sloupců
| Sloupec | Popis |
|---|---|
| 🧾 Název | Titulek článku z výsledků vyhledávání. |
| 🔗 PubMed URL | Odkaz na stránku článku na PubMedu pro obohacení přes subpage. |
| 🆔 PMID | Identifikátor PubMedu pro deduplikaci a citování. |
| 🧑⚕️ Autoři | Autoři uvedení v úryvku výsledku. |
| 🏛️ Časopis | Název časopisu a citační informace zobrazené ve výsledcích. |
| 📅 Datum | Datum publikace (nebo ePub) uvedené ve výpisu. |
| 🧪 Typ publikace | Signály jako Clinical Trial, Randomized Controlled Trial, Meta-Analysis (často jasnější na stránce článku). |
| 🧾 Abstrakt | Plný text abstraktu (nejlépe přes subpage scraping). |
| 🧬 MeSH termíny | Medical Subject Headings, pokud jsou k dispozici (často na stránce článku). |
| 🧷 DOI | DOI pro prolinkování na stránky vydavatelů a správce citací. |
| 🏥 Afiliace | Afiliace autorů pro analýzu institucí (subpage scraping). |
| 🌍 Země / instituce | Odvozeno z afiliací pomocí Field AI Prompts (volitelné). |
| 🔍 Klíčová slova ke klinické studii | AI štítky jako „randomized“, „double-blind“, „placebo“ (volitelné přes Field AI Prompt). |
| 📎 Odkazy na plný text | Odkazy na vydavatele nebo volně dostupný plný text, pokud jsou. |
🎯 Proč používat nástroj pro PubMed
Sběr dat z PubMedu je hlavně o rychlosti, konzistenci a o tom, aby se výzkumná data dala snadno použít v dalších krocích. Místo ručního kopírování citací po jedné si vytvoříte strukturovaný dataset, který můžete filtrovat, štítkovat a sdílet.
Typické důvody, proč týmy sbírají data z PubMedu:
- Medical affairs a farmaceutické týmy: Sledují nové publikace v terapeutické oblasti, monitorují studie konkurence a připravují evidence tabulky pro interní přehledy.
- Biotech a klinické operace: Shromažďují publikace související se studiemi, mapují instituce a investigátory a udržují „živou“ bibliografii.
- Healthcare marketing a obsahové týmy: Hledají trendující témata, vysoce impaktované časopisy a nově se objevující klíčová slova pro plánování obsahu.
- Akademičtí výzkumníci a knihovníci: Budují datasety pro literární rešerše, deduplikují podle PMID a exportují do tabulek pro screening.
- Datové týmy: Připravují strukturované vstupy pro analytiku, dashboardy nebo interní znalostní báze.
Thunderbit je obzvlášť užitečný, když potřebujete víc než jen výpis. Díky Subpage Scraping můžete ve velkém získávat abstrakty, afiliace, DOI, MeSH termíny i odkazy na plné texty.
🧩 Jak používat PubMed rozšíření pro Chrome
- Nainstalujte Thunderbit Chrome Extension: Získejte ho z a vytvořte si účet.
- Přejděte na stránku PubMedu: Otevřete , trendující stránku jako nebo dotaz typu .
- Aktivujte scraper s podporou AI: Klikněte na AI Suggest Columns, vygenerujte pole, upravte datové typy (text/datum/url) a případně přidejte Field AI Prompts (pro štítkování, formátování nebo vytěžení signálů o typu studie).
- Vytěžte data a exportujte: Klikněte na Scrape. Pokud potřebujete abstrakty/afiliace/MeSH, spusťte Scrape Subpages pro obohacení každého řádku a poté exportujte do Excelu, Google Sheets, Airtable nebo Notion.
Užitečné čtení, pokud chcete opakovatelný workflow:
💳 Ceny pro PubMed
Thunderbit používá jednoduchý kreditní systém:
- 1 kredit = 1 výstupní řádek ve výsledné tabulce (například jeden záznam z PubMedu).
- Export dat je zdarma: stáhněte CSV/JSON nebo odešlete do Excelu, Google Sheets, Airtable nebo Notion.
Začít můžete takto:
- Free tier: vytěžíte 6 stránek měsíčně (u Free je limit počítaný na stránky).
- Free trial: vytěžíte 10 stránek zdarma, což je ideální pro otestování trendujících stránek PubMedu a několika stránek s výsledky klinických studií.
Pokud sbíráte data pravidelně (týdenní monitoring, aktualizace evidence nebo velké dotazy), placené tarify vám dají více kreditů. Roční plán obvykle vychází výhodněji, protože obsahuje slevu oproti měsíční platbě.
Možnosti najdete na stránce .
❓ FAQ
-
Co je AI Powered PubMed Scraper?
AI Powered PubMed Scraper je workflow v Thunderbitu, který získává strukturovaná data z výsledků vyhledávání na PubMedu i ze stránek jednotlivých článků. AI umí navrhnout sloupce, vytěžit výpisy a obohatit každý řádek návštěvou podstránek článků o abstrakty, afiliace, DOI a další. -
Co je Thunderbit?
je AI web scraper rozšíření pro Chrome určené pro firemní i výzkumné scénáře, kde potřebujete strukturovaná data z webů. Pomáhá rychle získat, označit a exportovat data bez tvorby a údržby scraping skriptů. -
Lze sbírat data z trendujících stránek PubMedu i z běžných výsledků vyhledávání?
Ano. Můžete vytěžit stránku , standardní vyhledávání podle klíčových slov i filtrované výsledky (například dotazy zaměřené na klinické studie). AI v Thunderbitu se přizpůsobí různým rozvržením tím, že stránku „přečte“ a navrhne vhodná pole. -
Umí Thunderbit získat abstrakty, afiliace a MeSH termíny?
Ano — a právě tady nejvíc pomáhá Subpage Scraping. Nejprve vytěžíte seznam výsledků a pak Thunderbit otevře každou stránku záznamu na PubMedu a doplní do stejné tabulky abstrakt, afiliace, MeSH termíny, DOI a další metadata. -
Jak funguje stránkování a nekonečné načítání na PubMedu?
Thunderbit podporuje sběr přes stránkování, včetně navigace typu „další stránka“. Pokud PubMed změní způsob načítání výsledků, AI extrakce bývá odolnější než pevné selektory, protože při každém běhu znovu vyhodnocuje strukturu stránky. -
Do jakých formátů lze data z PubMedu exportovat?
Můžete exportovat do CSV nebo JSON, případně dataset odeslat do Excelu, Google Sheets, Airtable nebo Notion. To se hodí pro screening, evidence tabulky, dashboardy i sdílení s kolegy. -
Kolik záznamů z PubMedu mohu vytěžit zdarma?
Ve Free tarifu můžete vytěžit 6 stránek měsíčně, což často stačí na menší monitoring. V rámci zkušební verze můžete vytěžit 10 stránek zdarma a ověřit si nastavení sloupců i strategii obohacení přes subpages. -
Mohu si sloupce přizpůsobit pro konkrétní potřeby evidence extraction?
Ano. Můžete přejmenovat sloupce, nastavit datové typy (text/datum/url) a přidat Field AI Prompts pro získání nebo označení informací, jako jsou klíčová slova k designu studie, populace, intervence, komparátor, výsledky nebo země z afiliací. Díky tomu se posunete od „surového“ sběru k připraveným podkladům pro evidence. -
Je v pořádku sbírat data z PubMedu?
PubMed je veřejný zdroj a mnoho týmů shromažďuje bibliografická metadata pro výzkum a analýzu. Přesto dodržujte platné zákony, respektujte podmínky webu a používejte zodpovědné postupy, zejména u velkých a častých sběrů.
📚 Další zdroje
- Získejte rozšíření:
- Prozkoumejte návody na
- Základy:
- Listové workflow:
- Export do tabulek:
- Pokud ve výzkumných operacích sbíráte i PDF: