

يعجّ الويب ببيانات قيّمة — سواء كنت تعمل في المبيعات أو التجارة الإلكترونية أو أبحاث السوق، فإن استخراج بيانات الويب هو السلاح السري لتوليد العملاء المحتملين، ومراقبة الأسعار، والتحليل التنافسي. لكن المفاجأة هنا: مع اعتماد المزيد من الشركات على الاستخراج، أصبحت المواقع تدافع عن نفسها بقوة أكبر من أي وقت مضى. والتغيير حقيقي: إذ وجدت تحليلات ppc.land لعام 2024 أن أكثر من ثلث أكبر 1000 موقع يحظر بالفعل زاحف OpenAI وحده — وأصبحت مجموعة الأدوات الأوسع من حظر عناوين IP، وCAPTCHA، وبصمة المتصفح هي القاعدة لا الاستثناء.
إذا سبق أن شاهدت سكربت Python الخاص بك يعمل بسلاسة لمدة 20 دقيقة — ثم اصطدم فجأة بجدار من أخطاء 403 — فأنت تعرف جيدًا كم يكون ذلك محبطًا.
لقد قضيت سنوات في SaaS والأتمتة، وشاهدت بنفسي كيف يمكن أن تتحول مشاريع الاستخراج من «واو، هذا سهل» إلى «لماذا تم حجبي في كل مكان؟» في لحظة. لذا دعنا ننتقل إلى الجانب العملي: سأشرح لك كيفية القيام باستخراج بيانات الويب دون أن يتم حظرك في Python، وأشارك أفضل التقنيات ومقاطع الشيفرة، وأوضح لك متى يكون الوقت مناسبًا للتفكير في بدائل مدعومة بالذكاء الاصطناعي مثل Thunderbit. سواء كنت محترفًا في Python أو مجرد تحاول النجاة بالمهمة، ستخرج بمجموعة أدوات لاستخراج بيانات موثوق ومن دون حظر.
ما المقصود باستخراج بيانات الويب دون أن يتم حظرك في Python؟
في جوهره، يعني استخراج بيانات الويب دون أن يتم حظرك جمع البيانات من المواقع بطريقة تتجنب تفعيل دفاعاتها المضادة للروبوتات. وفي عالم Python، هذا يعني أكثر من مجرد كتابة حلقة requests.get() — إنه يعني الاندماج في السلوك الطبيعي للمستخدمين الحقيقيين، والبقاء خطوة أمام أنظمة الكشف.
لماذا Python؟ Python هي اللغة الأكثر شيوعًا لاستخراج بيانات الويب — بفضل بساطتها، ونظامها البيئي الضخم (مثل: requests وBeautifulSoup وScrapy وSelenium)، ومرونتها التي تمتد من السكربتات السريعة إلى الزواحف الموزعة. لكن الشعبية لها ثمن: فالكثير من أنظمة مكافحة الروبوتات أصبحت الآن مضبوطة لاكتشاف أنماط الاستخراج المبنية على Python.
لذلك، إذا أردت استخراج البيانات بشكل موثوق، فعليك أن تتجاوز الأساسيات. وهذا يعني فهم طريقة المواقع في كشف الروبوتات، وكيف يمكنك أن تتفوق عليها — دون تجاوز أي خطوط أخلاقية أو قانونية.
لماذا يهم تجنّب الحظر في مشاريع استخراج بيانات الويب باستخدام Python؟
التعرض للحظر ليس مجرد عطل تقني بسيط — بل قد يربك سير عمل أعمال كامل. دعنا نفصّل ذلك:
| حالة الاستخدام | أثر التعرض للحظر |
|---|---|
| توليد العملاء المحتملين | قوائم فرص غير مكتملة أو قديمة، وخسارة في المبيعات |
| مراقبة الأسعار | تفويت تغييرات أسعار المنافسين، وقرارات تسعير سيئة |
| تجميع المحتوى | فجوات في الأخبار أو المراجعات أو بيانات البحث |
| ذكاء السوق | نقاط عمياء في تتبع المنافسين أو القطاع |
| قوائم العقارات | بيانات عقارية غير دقيقة أو قديمة، وفرص ضائعة |
عندما يتم حظر أداة الاستخراج، فأنت لا تفقد البيانات فقط — بل تهدر الموارد، وتعرّض نفسك لمشكلات امتثال محتملة، وقد تتخذ قرارات تجارية خاطئة بناءً على معلومات ناقصة. وفي عالم يعتمد فيه 79% من الشركات على استخراج بيانات الويب لتوليد العملاء المحتملين، تصبح الموثوقية كل شيء.
كيف تكشف المواقع أدوات استخراج بيانات الويب المكتوبة بـ Python وتقوم بحظرها
أصبحت المواقع أذكى بكثير في رصد الروبوتات. إليك أكثر وسائل الدفاع ضد الاستخراج شيوعًا التي ستواجهها (Medium، Bright Data):
- القائمة السوداء لعناوين IP: هل ترسل عددًا كبيرًا من الطلبات من عنوان IP واحد؟ سيتم حظرك.
- فحص User-Agent والرؤوس: الطلبات التي تفتقر إلى الرؤوس أو تستخدم رؤوسًا عامة جدًا (مثل القيمة الافتراضية في Python
python-requests/2.25.1) تبرز بسرعة. - تحديد معدل الطلبات: إرسال عدد كبير من الطلبات خلال وقت قصير يؤدي إلى تقليل السرعة أو الحظر.
- CAPTCHAs: ألغاز «أثبت أنك إنسان» التي لا يستطيع الروبوت حلّها بسهولة.
- التحليل السلوكي: تراقب المواقع الأنماط الآلية — مثل النقر على الزر نفسه كل فترة زمنية ثابتة.
- مصائد Honeypots: روابط أو حقول مخفية لا يتفاعل معها إلا الروبوتات.
- بصمة المتصفح: جمع تفاصيل عن المتصفح والجهاز لاكتشاف أدوات الأتمتة.
- تتبع الكوكيز والجلسات: الروبوتات التي لا تتعامل مع الكوكيز أو الجلسات بشكل صحيح يتم تمييزها.
تخيّل الأمر مثل أمن المطار: إذا كنت تبدو وتتصرف وتتحرك مثل الجميع، فستمرّ بسلاسة. أما إذا حضرت بمعطف طويل ونظارات شمسية، فتوقّع المزيد من الأسئلة.
تقنيات Python الأساسية لاستخراج بيانات الويب دون أن يتم حظرك
لننتقل إلى المهم: كيف تتجنب الحظر فعليًا عند استخراج البيانات باستخدام Python. إليك الاستراتيجيات الأساسية التي يجب أن يعرفها كل من يتعامل مع الاستخراج:

تدوير الوكلاء وعناوين IP
لماذا يهم: إذا جاءت كل طلباتك من عنوان IP نفسه، فأنت هدف سهل لحظر IP. يتيح لك تدوير الوكلاء توزيع الطلبات على عدة عناوين IP، مما يجعل حظرك أصعب بكثير.
كيف تفعل ذلك في Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ... المزيد من الوكلاء
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# معالجة الاستجابة
يمكنك استخدام خدمات وكلاء مدفوعة (مثل الوكلاء السكنيين أو الدوّارين) للحصول على موثوقية أعلى (ScrapingBee).
ضبط User-Agent والرؤوس المخصصة
لماذا يهم: الرؤوس الافتراضية في Python تصرخ «أنا روبوت». قلّد المتصفحات الحقيقية عبر ضبط User-Agent وغيرها من الرؤوس.
مثال شيفرة:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
قم بتدوير قيم User-Agent لمزيد من التخفي (ZenRows).
عشوائية توقيت الطلبات وأنماطها
لماذا يهم: الروبوتات سريعة ويمكن التنبؤ بها؛ البشر أبطأ وعشوائيون. أضف فواصل زمنية وغيّر نمط التصفح.
نصيحة Python:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # الانتظار من 2 إلى 7 ثوانٍ
يمكنك أيضًا عشوائية مسارات النقر وأنماط التمرير إذا كنت تستخدم Selenium.
إدارة الكوكيز والجلسات
لماذا يهم: تتطلب العديد من المواقع الكوكيز أو رموز الجلسة للوصول إلى المحتوى. الروبوتات التي تتجاهل ذلك يتم حظرها.
كيفية الإدارة في Python:
import requests
session = requests.Session()
response = session.get(url)
# ستتعامل الجلسة مع الكوكيز تلقائيًا
أما في التدفقات الأكثر تعقيدًا، فاستخدم Selenium لالتقاط الكوكيز وإعادة استخدامها.
محاكاة السلوك البشري باستخدام المتصفحات بدون واجهة
لماذا يهم: تستخدم بعض المواقع JavaScript أو حركة الفأرة أو التمرير كإشارات على أن المستخدم حقيقي. تستطيع المتصفحات بدون واجهة مثل Selenium أو Playwright محاكاة هذه الأفعال.
مثال باستخدام Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
يساعدك ذلك على تجاوز التحليل السلوكي والمحتوى الديناميكي (ScrapingBee).
استراتيجيات متقدمة: تجاوز CAPTCHA وHoneypots في Python
تم تصميم CAPTCHAs لإيقاف الروبوتات في مسارها. وبينما تستطيع بعض مكتبات Python حلّ CAPTCHAs البسيطة، يعتمد معظم المحترفين في الاستخراج على خدمات خارجية (مثل 2Captcha أو Anti-Captcha) لحلّها مقابل رسوم (Medium).
مثال على الدمج:
# شيفرة شبهية لاستخدام واجهة 2Captcha
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# انتظر الحل، ثم أرسله مع طلبك
أما Honeypots فهي حقول أو روابط مخفية لا يتفاعل معها إلا الروبوت. تجنب النقر أو إرسال أي شيء لا يكون ظاهرًا في المتصفح الحقيقي (ZenRows).
تصميم رؤوس طلبات قوية باستخدام مكتبات Python
إلى جانب User-Agent، يمكنك تدوير وتوليد رؤوس أخرى عشوائيًا (مثل Referer وAccept وOrigin وغيرها) لتبدو أكثر طبيعية.
مع Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# المزيد من الرؤوس
}
}
مع Selenium: استخدم ملفات تعريف المتصفح أو الإضافات لضبط الرؤوس، أو قم بحقنها عبر JavaScript.
حافظ على تحديث قائمة الرؤوس لديك — وارجع إلى طلبات المتصفح الحقيقية عبر أدوات المطور في المتصفح كمصدر إلهام.
عندما لا يكون استخراج Python التقليدي كافيًا: صعود تقنية مكافحة الروبوتات
هذه هي الحقيقة: كلما زاد انتشار الاستخراج، زادت أيضًا ترقيات أنظمة مكافحة الروبوتات. فالمواقع الكبرى لا تحظر الروبوتات الواضحة فقط، بل حتى المتصفحات المتقدمة بدون واجهة والوكلاء الدوّارين. كما أن الكشف المدعوم بالذكاء الاصطناعي، وحدود الطلبات الديناميكية، وبصمة المتصفح تجعل من الصعب أكثر من أي وقت مضى على حتى سكربتات Python المتقدمة أن تبقى غير مكتشفة (Medium).
أحيانًا، مهما كانت شيفرتك ذكية، ستصطدم بجدار. وهنا يصبح من المناسب التفكير في نهج مختلف.
Thunderbit: بديل أداة استخراج ويب بالذكاء الاصطناعي لاستخراج Python
عندما يصل Python إلى حدوده، يتدخل Thunderbit بوصفه أداة استخراج ويب بدون برمجة ومدعومة بالذكاء الاصطناعي، مصممة لمستخدمي الأعمال — وليس المطورين فقط. بدلًا من الصراع مع الوكلاء والرؤوس وCAPTCHAs، يقرأ وكيل Thunderbit الذكي الموقع، ويقترح أفضل الحقول لاستخراجها، ويتولى كل شيء من التنقل بين الصفحات الفرعية إلى تصدير البيانات.
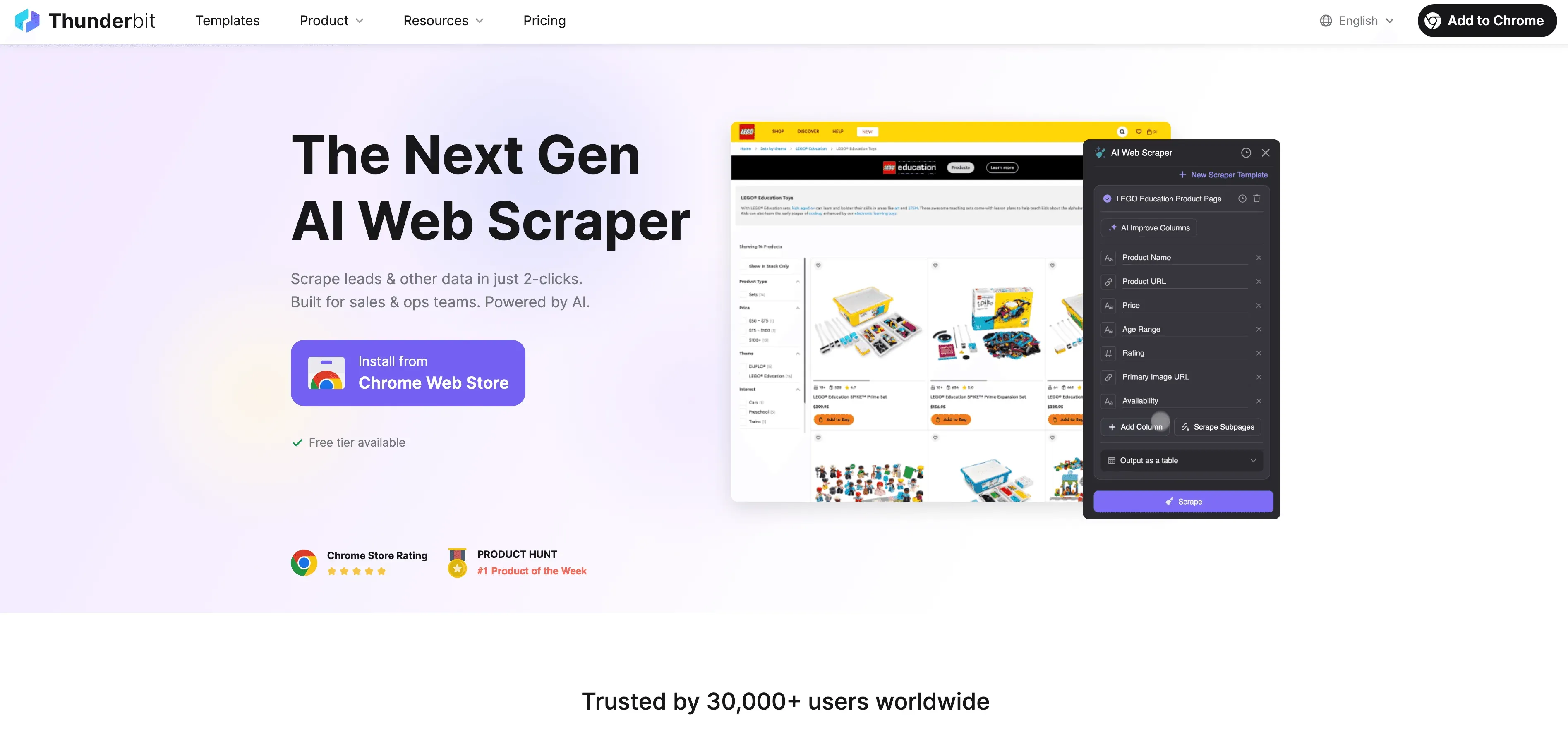
ما الذي يجعل Thunderbit مختلفًا؟
- اقتراح الحقول بالذكاء الاصطناعي: انقر على «اقتراح الحقول بالذكاء الاصطناعي» وسيقوم Thunderbit بمسح الصفحة، ويقترح الأعمدة، بل ويولّد تعليمات الاستخراج.
- استخراج الصفحات الفرعية: يستطيع Thunderbit زيارة كل صفحة فرعية (مثل تفاصيل المنتجات أو ملفات LinkedIn الشخصية) وإغناء جدولك تلقائيًا.
- استخراج سحابي أو عبر المتصفح: اختر الأسرع — السحابي للمواقع العامة، أو المتصفح للصفحات المحمية بتسجيل الدخول.
- استخراج مجدول: اضبطه ثم انسَه — يمكن لـ Thunderbit أن يجري الاستخراج وفق جدول زمني، بحيث تبقى بياناتك محدثة دائمًا.
- قوالب فورية: للمواقع الشائعة (Amazon وZillow وShopify وغيرها)، يوفّر Thunderbit قوالب بنقرة واحدة — دون أي إعداد.
- تصدير بيانات مجاني: صدّر إلى Excel أو Google Sheets أو Airtable أو Notion — من دون رسوم إضافية.
يحظى Thunderbit بثقة أكثر من 100,000 مستخدم حول العالم، ولن تحتاج إلى كتابة سطر واحد من الشيفرة.
استخراج البيانات من أي موقع باستخدام الذكاء الاصطناعي Get Started Free
كيف يساعد Thunderbit المستخدمين على تجنّب الحظر وأتمتة استخراج البيانات
لا يقتصر دور ذكاء Thunderbit على محاكاة السلوك البشري فحسب — بل يتكيف مع كل موقع في الوقت الفعلي، مما يقلل خطر الحظر. إليك كيف:
- يتكيف الذكاء الاصطناعي مع تغييرات التصميم: يقلّل إعادة العمل عندما يحدّث الموقع تصميمه — فلا تضطر إلى إعادة ضبط أدوات الاختيار كل أسبوع.
- معالجة الصفحات الفرعية والصفحات المتعددة: يتتبع Thunderbit الروابط والقوائم المرقمة نيابةً عنك، كما يفعل شخص ينقر ويتنقل يدويًا.
- استخراج سحابي على دفعات: شغّل المهام من سحابة Thunderbit بدلًا من حاسوبك المحمول، مع تحديد أحجام الدفعات حسب الخطة (راجع صفحة التسعير لمعرفة الحدود الحالية).
- صيانة أقل للشيفرة: لست أنت من يطارد أدوات الاختيار المعطلة في منتصف الليل عندما يغيّر الموقع شكله؛ فالذكاء الاصطناعي يعيد قراءة الصفحة.
وللتعمق أكثر، اطّلع على كيفية استخراج أي موقع باستخدام الذكاء الاصطناعي.
مقارنة استخراج Python مع Thunderbit: أيهما تختار؟
لنضعهما جنبًا إلى جنب:
| الميزة | استخراج Python | Thunderbit |
|---|---|---|
| وقت الإعداد | متوسط إلى مرتفع (سكربتات، وكلاء، إلخ) | منخفض (نقرتان، والذكاء الاصطناعي يتولى الباقي) |
| المهارة التقنية | يتطلب برمجة | لا حاجة للبرمجة |
| الموثوقية | متفاوتة (سهل الكسر) | عالية (الذكاء الاصطناعي يتكيف مع التغييرات) |
| خطر الحظر | متوسط إلى مرتفع | منخفض (الذكاء الاصطناعي يحاكي المستخدم ويتكيف) |
| قابلية التوسع | يحتاج إلى شيفرة مخصصة وإعداد سحابي | استخراج سحابي/على دفعات مدمج |
| الصيانة | متكررة (تغييرات الموقع، الحظر) | قليلة جدًا (الذكاء الاصطناعي يضبط نفسه تلقائيًا) |
| خيارات التصدير | يدوي (CSV، قاعدة بيانات) | مباشر إلى Sheets وNotion وAirtable وCSV |
| التكلفة | مجاني (لكن يستغرق وقتًا كبيرًا) | خطة مجانية، وخطط مدفوعة للتوسع |
متى تستخدم Python:
- تحتاج إلى تحكم كامل أو منطق مخصص أو تكامل مع تدفقات عمل Python أخرى.
- تقوم بالاستخراج من مواقع ذات دفاعات محدودة ضد الروبوتات.
متى تستخدم Thunderbit:
- تريد السرعة والموثوقية وعدم الحاجة إلى إعداد.
- تقوم بالاستخراج من مواقع معقدة أو تتغير كثيرًا.
- لا تريد التعامل مع الوكلاء أو CAPTCHAs أو الشيفرة.
جرّب أداة Thunderbit للذكاء الاصطناعي لاستخراج الويب مجانًا
دليل خطوة بخطوة: إعداد استخراج بيانات الويب دون أن يتم حظرك في Python
لنمر عبر مثال عملي: استخراج بيانات منتج من موقع نموذجي، مع تطبيق أفضل ممارسات تجنب الحظر.
1. ثبّت المكتبات المطلوبة
pip install requests beautifulsoup4 fake-useragent
2. جهّز السكربت
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # استبدلها بروابطك
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# استخرج البيانات هنا
print(soup.title.text)
else:
print(f"تم الحظر أو حدث خطأ في {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # تأخير عشوائي
3. أضف تدوير الوكلاء (اختياري)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# المزيد من الوكلاء
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ... بقية الشيفرة
4. التعامل مع الكوكيز والجلسات
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ... بقية الشيفرة
5. نصائح لاستكشاف الأخطاء
- إذا رأيت الكثير من أخطاء 403/429، فخفّض سرعة الطلبات أو جرّب وكلاء جددًا.
- إذا واجهت CAPTCHAs، فكر في استخدام Selenium أو خدمة لحل CAPTCHA.
- تحقّق دائمًا من
robots.txtوشروط الخدمة الخاصة بالموقع.
الخلاصة وأهم النقاط
استخراج بيانات الويب في Python قوي — لكن التعرض للحظر يظل خطرًا دائمًا مع تطور تقنيات مكافحة الروبوتات. أفضل طريقة لتجنّب الحظر؟ اجمع بين أفضل الممارسات التقنية (تدوير الوكلاء، الرؤوس الذكية، التأخيرات العشوائية، التعامل مع الجلسات، والمتصفحات بدون واجهة) وبين احترام قواعد الموقع والأخلاقيات.
لكن أحيانًا، حتى أفضل حيل Python لا تكفي. وهنا تأتي أدوات الذكاء الاصطناعي مثل Thunderbit — بدون برمجة، ومصممة للتعامل مع تغييرات التصميم والصفحات المتعددة التي تربك السكربتات الصارمة، وموجهة إلى مستخدمي الأعمال الذين لا يرغبون في قضاء أمسياتهم في مراقبة مهمة Selenium.
هل تريد أن ترى مدى سهولة الاستخراج؟ نزّل إضافة Thunderbit لمتصفح Chrome وجربها بنفسك — أو اطّلع على المدونة لمزيد من النصائح والشروحات حول الاستخراج.
استخرج البيانات دون أن يتم حظرك
الأسئلة الشائعة
1. لماذا تحظر المواقع أدوات استخراج بيانات الويب المكتوبة بـ Python؟
تحظر المواقع أدوات الاستخراج لحماية بياناتها، ومنع تحميل الخوادم فوق طاقتها، وإيقاف الروبوتات الآلية التي تسيء استخدام خدماتها. يسهل اكتشاف سكربتات Python إذا كانت تستخدم رؤوسًا افتراضية، أو لا تتعامل مع الكوكيز، أو ترسل عددًا كبيرًا جدًا من الطلبات بسرعة.
2. ما أكثر الطرق فعالية لتجنب الحظر عند استخراج البيانات باستخدام Python؟
استخدم الوكلاء الدوّارين، واضبط User-Agent والرؤوس بشكل واقعي، وغيّر توقيت الطلبات بشكل عشوائي، وأدر الكوكيز/الجلسات، وقلّد السلوك البشري باستخدام أدوات مثل Selenium أو Playwright.
3. كيف يساعد Thunderbit على تجنب الحظر مقارنةً بسكربتات Python؟
يستخدم Thunderbit الذكاء الاصطناعي للتكيف مع تخطيطات المواقع، ومحاكاة التصفح البشري، والتعامل تلقائيًا مع الصفحات الفرعية والصفحات المتعددة. وهو يقلل خطر الحظر عبر الاندماج مع السلوك الطبيعي وتحديث أسلوبه في الوقت الفعلي — من دون حاجة إلى برمجة أو وكلاء.
4. متى يجب أن أستخدم Python لاستخراج البيانات ومتى أستخدم أداة ذكاء اصطناعي مثل Thunderbit؟
استخدم Python عندما تحتاج إلى منطق مخصص، أو تكامل مع شيفرة Python أخرى، أو كنت تستخرج من مواقع بسيطة. استخدم Thunderbit للاستخراج السريع والموثوق والقابل للتوسع — خصوصًا عندما تكون المواقع معقدة أو تتغير كثيرًا أو تحظر السكربتات بقوة.
5. هل استخراج بيانات الويب قانوني؟
استخراج بيانات الويب قانوني للبيانات المتاحة للعامة، لكن يجب احترام شروط الخدمة وسياسات الخصوصية والقوانين ذات الصلة لكل موقع. لا تستخرج أبدًا بيانات حساسة أو خاصة، واحرص دائمًا على أن يكون الاستخراج أخلاقيًا ومسؤولًا.
هل أنت مستعد للاستخراج بذكاء أكبر لا بجهد أكبر؟ جرّب Thunderbit واترك الحظر وراءك.
اعرف المزيد:
- استخراج أخبار Google باستخدام Python: دليل خطوة بخطوة
- إنشاء أداة لتتبع أسعار Best Buy باستخدام Python
- 14 طريقة لاستخراج بيانات الويب دون أن يتم حظرك
- أفضل 10 نصائح لعدم التعرض للحظر عند استخراج بيانات الويب
جرّب أداة استخراج الويب بالذكاء الاصطناعي Get Started Free




