

هناك سحر خاص في أن تفتح الطرفية، وتكتب أمرًا واحدًا، ثم ترى بيانات الويب الخام تتدفق أمامك كأنك فتحت للتو باب المصفوفة. بالنسبة للمطورين والمستخدمين التقنيين المتقدمين، يُعد cURL تلك الأداة السحرية الصغيرة — أداة سطر أوامر متواضعة، لكنها تعمل بصمت على مليارات الأجهزة، من خوادم السحابة إلى الثلاجات الذكية. وحتى في عام 2026، ومع كل أدوات الاستخراج بلا كود وأدوات الذكاء الاصطناعي اللامعة، لا يزال استخراج الويب باستخدام cURL خيارًا أساسيًا لكل من يريد السرعة والتحكم وإمكانية التشغيل عبر السكربتات.
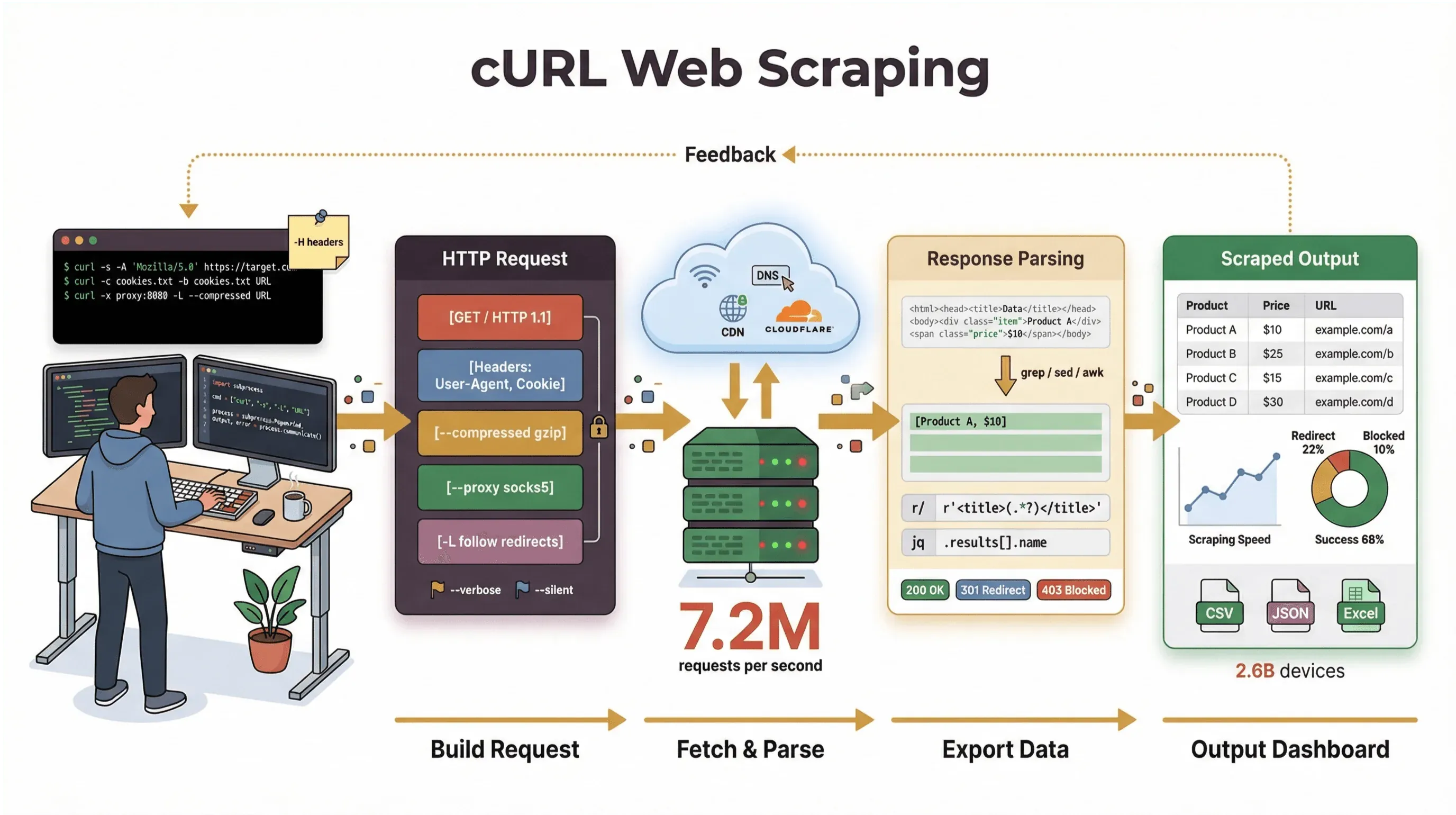 لقد قضيت سنوات في بناء أدوات الأتمتة ومساعدة الفرق على التعامل مع بيانات الويب، وما زلت ألجأ إلى cURL عندما أحتاج إلى جلب صفحة، أو تصحيح خلل في API، أو إعداد نموذج أولي لسير عمل استخراج. في هذا الدليل، سأرشدك إلى شرح عملي لاستخراج الويب باستخدام cURL يغطي الأساسيات والحيل الاحترافية — مع أمثلة أوامر حقيقية، ونصائح عملية، ونظرة واضحة إلى أين يتألق cURL وأين يصطدم بحاجز. وإذا كنت من مستخدمي الأعمال الذين يفضلون عدم لمس سطر الأوامر، فسأريك كيف يمكن لـ Thunderbit — أداة استخراج الويب المدعومة بالذكاء الاصطناعي — أن تنقلك من «أحتاج هذه البيانات» إلى «هذه هي جدولي» في نقرتين فقط، من دون أي برمجة.
لقد قضيت سنوات في بناء أدوات الأتمتة ومساعدة الفرق على التعامل مع بيانات الويب، وما زلت ألجأ إلى cURL عندما أحتاج إلى جلب صفحة، أو تصحيح خلل في API، أو إعداد نموذج أولي لسير عمل استخراج. في هذا الدليل، سأرشدك إلى شرح عملي لاستخراج الويب باستخدام cURL يغطي الأساسيات والحيل الاحترافية — مع أمثلة أوامر حقيقية، ونصائح عملية، ونظرة واضحة إلى أين يتألق cURL وأين يصطدم بحاجز. وإذا كنت من مستخدمي الأعمال الذين يفضلون عدم لمس سطر الأوامر، فسأريك كيف يمكن لـ Thunderbit — أداة استخراج الويب المدعومة بالذكاء الاصطناعي — أن تنقلك من «أحتاج هذه البيانات» إلى «هذه هي جدولي» في نقرتين فقط، من دون أي برمجة.
هيا بنا نغوص في الموضوع ونرى لماذا ما يزال cURL مهمًا لاستخراج الويب في 2026، وكيف تستخدمه بفعالية، ومتى يحين وقت اللجوء إلى أداة أقوى حتى.
ما هو cURL؟ أساس الاستخراج من الويب باستخدام cURL
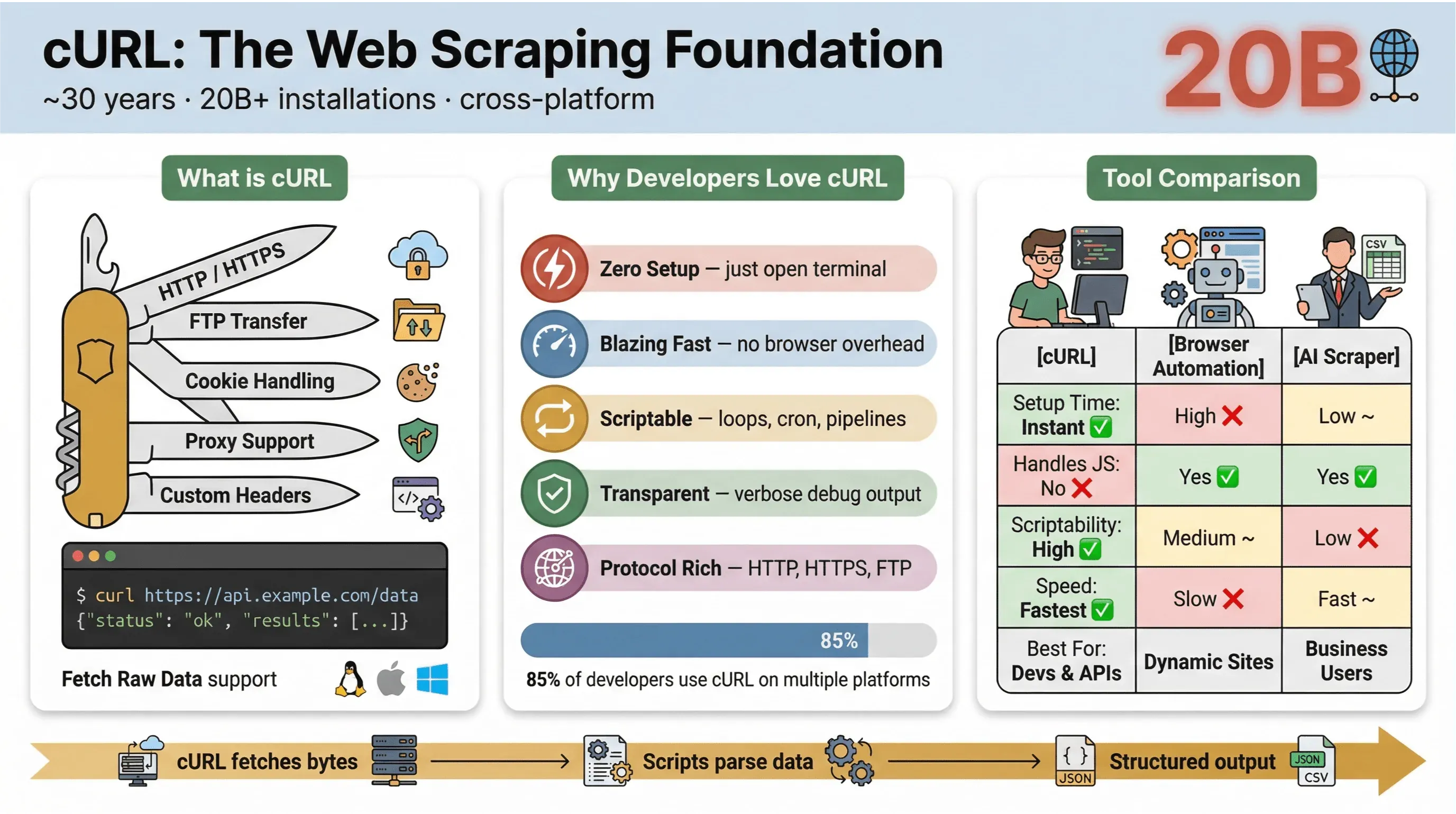
في جوهره، cURL هو أداة سطر أوامر ومكتبة لنقل البيانات عبر عناوين URL. وهو موجود منذ ما يقرب من 30 عامًا (نعم، فعلًا)، ويعمل في كل مكان — مدمجًا في أنظمة التشغيل، ويشغّل السكربتات، ويتولى بهدوء عمليات نقل البيانات في أكثر من عشرين مليار تثبيت. إذا كنت قد شغّلت يومًا أمرًا سريعًا لجلب صفحة ويب، أو اختبار API، أو تنزيل ملف، فهناك احتمال كبير أنك استخدمت cURL بالفعل.
 وهذه أبرز الأسباب التي تجعل cURL شائعًا جدًا في استخراج الويب:
وهذه أبرز الأسباب التي تجعل cURL شائعًا جدًا في استخراج الويب:
- خفيف الوزن ومتعدد المنصات: يعمل على لينكس، وماك أو إس، وويندوز، وحتى الأجهزة المدمجة.
- يدعم بروتوكولات متعددة: يتعامل مع HTTP وHTTPS وFTP وغيرها.
- قابل للسكربتة: مثالي للأتمتة، والمهام المجدولة، وكود الربط.
- لا يتطلب تفاعل المستخدم: مصمم للاستخدام غير التفاعلي — رائع للمهام الدفعية وخطوط المعالجة.
لكن لنتضح الصورة: المهمة الأساسية لـ cURL هي جلب البيانات الخام — HTML، وJSON، والصور، وغير ذلك. فهو لا يفسر البيانات ولا يعرضها ولا ينظمها لك. فكّر في cURL على أنه «الميل الأول» في رحلة استخراج الويب: فهو يجلب البايتات، لكنك ستحتاج إلى أدوات أخرى (مثل سكربتات بايثون، أو grep/sed/awk، أو أداة استخراج ويب بالذكاء الاصطناعي) لتحويلها إلى معلومات منظمة.
إذا أردت الاطلاع على الوثائق الرسمية، فراجع دليل HTTP scripting الخاص بـ cURL.
لماذا تستخدم cURL لاستخراج الويب؟ (شرح استخراج الويب باستخدام cURL)
إذًا، لماذا يعود المطورون والمستخدمون التقنيون إلى cURL مرارًا في استخراج الويب، رغم كل الأدوات الجديدة الموجودة؟ إليك ما يميزه:
- إعداد بسيط جدًا: لا تثبيت، لا تبعيات — فقط افتح الطرفية وابدأ.
- سرعة: جلب فوري للبيانات من دون انتظار تحميل المتصفح.
- قابلية السكربتة: سهولة التكرار على عناوين URL، وأتمتة الطلبات، وربط الأوامر.
- دعم البروتوكولات والميزات: التعامل مع ملفات تعريف الارتباط، والبروكسيات، وإعادة التوجيه، والرؤوس المخصصة، وغير ذلك.
- الشفافية: ترى بدقة ما يحدث من خلال المخرجات التفصيلية/وضع التصحيح.
في استطلاع مستخدمي cURL لعام 2025، قال 85.7% من المشاركين إنهم يستخدمون أداة سطر الأوامر cURL، وذكر 96.2% أنهم يستخدمونه على لينكس — وما يزال المنصة الأولى لـ cURL بفارق كبير.
--- ما يزال السكين السويسري لطلبات HTTP، وجلب البيانات السريع، واستكشاف الأخطاء.
فيما يلي مقارنة سريعة بين cURL وطرق الاستخراج الأخرى:
| الميزة | cURL | أتمتة المتصفح (مثل Selenium) | أداة استخراج ويب بالذكاء الاصطناعي (مثل Thunderbit) |
|---|---|---|---|
| وقت الإعداد | فوري | مرتفع | منخفض |
| قابلية السكربتة | عالية | متوسطة | منخفضة (من دون كود) |
| التعامل مع JavaScript | لا | نعم | نعم (Thunderbit: عبر المتصفح) |
| دعم ملفات الارتباط/الجلسات | يدوي | تلقائي | تلقائي |
| تنظيم البيانات | يدوي (ثم التحليل لاحقًا) | يدوي (ثم التحليل لاحقًا) | يعتمد على الذكاء الاصطناعي/القوالب |
| الأفضل لـ | المطورين، والجلب السريع | المواقع المعقدة والديناميكية | مستخدمي الأعمال، والتصدير المنظم |
باختصار: يتفوق cURL في جلب البيانات بسرعة وبإمكانية التشغيل عبر السكربتات — خاصة للصفحات الثابتة، وواجهات API، أو عندما تريد أتمتة سير عمل بسيط. لكن بمجرد أن تحتاج إلى تحليل HTML معقد، أو التعامل مع JavaScript، أو تصدير بيانات منظمة، فستحتاج إلى أداة أكثر تخصصًا.
البدء: أمثلة أوامر أساسية لاستخراج الويب باستخدام cURL
لننتقل إلى التطبيق العملي. إليك كيفية استخدام cURL في مهام استخراج الويب الأساسية، خطوة بخطوة.
جلب HTML الخام باستخدام cURL
أبسط استخدام: جلب HTML الخاص بصفحة ويب.
curl https://books.toscrape.com/
هذا الأمر يجلب الصفحة الرئيسية لموقع Books to Scrape، وهو موقع تجريبي عام لاستخراج الويب. سترى مخرجات HTML الخام في الطرفية — ابحث عن وسوم مثل <title> أو مقتطفات مثل “In stock.”
حفظ المخرجات في ملف
هل تريد حفظ ذلك الـ HTML لتحليله لاحقًا؟ استخدم الخيار -o:
curl -o page.html https://books.toscrape.com/
الآن سيكون لديك ملف page.html يحتوي على محتوى HTML الكامل. هذا مثالي لإجراء تحليل إضافي أو التفكيك باستخدام أدوات أخرى.
إرسال طلبات POST باستخدام cURL
هل تحتاج إلى إرسال نموذج أو التفاعل مع API؟ استخدم الخيار -d لطلبات POST. إليك مثالًا باستخدام httpbin، وهو موقع مخصص لاختبار HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
ستحصل على استجابة JSON تعكس البيانات التي أرسلتها — ممتاز للاختبار وبناء النماذج الأولية.
فحص الرؤوس وتصحيح الأخطاء
أحيانًا تريد رؤية رؤوس الاستجابة أو تصحيح الطلب:
-
الرؤوس فقط (طلب HEAD):
curl -I https://books.toscrape.com/ -
إظهار الرؤوس مع الجسم:
curl -i https://httpbin.org/get -
مخرجات تفصيلية/تصحيح:
curl -v https://books.toscrape.com/
تساعدك هذه الخيارات على فهم ما يحدث في الخلفية — وهو أمر أساسي لاستكشاف الأخطاء.
فيما يلي جدول مرجعي سريع لهذه الأوامر:
| المهمة | مثال على الأمر | ملاحظات |
|---|---|---|
| جلب HTML | curl URL | يطبع HTML في الطرفية |
| الحفظ في ملف | curl -o file.html URL | يكتب المخرجات إلى ملف |
| فحص الرؤوس | curl -I URL أو curl -i URL | -I للرؤوس فقط، و-i يتضمن الرؤوس مع الجسم |
| إرسال بيانات نموذج | curl -d "a=1&b=2" URL | يرسل بيانات مشفّرة بصيغة نموذج |
| تصحيح الطلب/الاستجابة | curl -v URL | يعرض معلومات تفصيلية عن الطلب/الاستجابة |
لمزيد من الأمثلة، راجع وثائق cURL الرسمية للسكربتات.
مستوى أعلى: استخراج ويب متقدم باستخدام cURL (الاستخراج من الويب باستخدام cURL)
بمجرد أن تصبح مرتاحًا مع الأساسيات، يفتح cURL أمامك عالمًا من الميزات المتقدمة لمهام الاستخراج الأكثر تعقيدًا.
التعامل مع ملفات الارتباط والجلسات
تتطلب العديد من المواقع ملفات تعريف الارتباط للحفاظ على جلسات تسجيل الدخول أو تتبع المستخدمين. مع cURL، يمكنك حفظ ملفات الارتباط وإعادة استخدامها بين الطلبات:
# حفظ ملفات الارتباط بعد تسجيل الدخول
curl -c cookies.txt https://example.com/login
# استخدام ملفات الارتباط في الطلبات اللاحقة
curl -b cookies.txt https://example.com/account
هذا يتيح لك محاكاة جلسات المتصفح والوصول إلى الصفحات المحمية بتسجيل الدخول (طالما لا توجد معضلة JavaScript).
انتحال User-Agent والرؤوس المخصصة
بعض المواقع تعرض محتوى مختلفًا بناءً على User-Agent أو الرؤوس. بشكل افتراضي، يعرّف cURL نفسه على أنه “curl/VERSION”، وهذا قد يؤدي إلى الحظر أو عرض محتوى بديل. لمحاكاة المتصفح:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
يمكنك أيضًا تعيين رؤوس مخصصة، مثل تفضيلات اللغة:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
يساعدك هذا في الحصول على نفس المحتوى الذي يراه متصفح حقيقي.
استخدام البروكسيات في استخراج الويب
هل تحتاج إلى تمرير طلباتك عبر بروكسي (للاختبار الجغرافي أو لتجنب حظر IP)؟ استخدم الخيار -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
فقط تأكد من استخدام البروكسيات بمسؤولية وضمن شروط خدمة الموقع.
أتمتة استخراج صفحات متعددة
هل تريد استخراج عدة صفحات — مثل قوائم المنتجات المرقمة؟ استخدم حلقة shell بسيطة:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
هذا يجلب الصفحات 2 إلى 5 من كتالوج Books to Scrape ويحفظ كل صفحة في ملف منفصل. (الصفحة 1 هي الصفحة الرئيسية.)
حدود الاستخراج من الويب باستخدام cURL: ما الذي ينبغي معرفته
رغم أنني أحب cURL كثيرًا، فهو ليس حلًا سحريًا لكل شيء. هذه هي نقاط ضعفه:
- لا ينفذ JavaScript: لا يستطيع cURL التعامل مع الصفحات التي تتطلب JavaScript لعرض المحتوى أو تجاوز تحديات مكافحة الروبوتات (developers.cloudflare.com).
- يتطلب تحليلًا يدويًا: ستحصل على HTML أو JSON الخام، لكنك ستحتاج إلى تحليله بنفسك — وغالبًا باستخدام سكربتات أو أدوات إضافية.
- إدارة جلسات محدودة: التعامل مع تسجيلات الدخول المعقدة، أو الرموز، أو النماذج متعددة الخطوات يمكن أن يصبح فوضويًا بسرعة.
- لا يوجد تنظيم بيانات مدمج: لا يحول cURL صفحات الويب إلى صفوف أو جداول أو جداول بيانات.
- معرّض لاكتشاف الروبوتات: تستخدم الكثير من المواقع الآن دفاعات متقدمة ضد الروبوتات (JavaScript، وبصمة المتصفح، وCAPTCHA) لا يستطيع cURL تجاوزها ببساطة (datadome.co).
فيما يلي جدول مقارنة سريع:
| الحدّ | cURL وحده | أدوات الاستخراج الحديثة (مثل Thunderbit) |
|---|---|---|
| دعم JavaScript | لا | نعم |
| تنظيم البيانات | يدوي | تلقائي (ذكاء اصطناعي/قوالب) |
| إدارة الجلسات | يدوي | تلقائي |
| تجاوز مكافحة الروبوتات | محدود | متقدم (معتمد على المتصفح/الذكاء الاصطناعي) |
| سهولة الاستخدام | تقني | غير تقني |
للصفحات الثابتة وواجهات API، يعد cURL ممتازًا. أما لأي شيء أكثر ديناميكية أو محمية، فستحتاج إلى الارتقاء في سلسلة الأدوات.
Thunderbit مقابل cURL: أفضل نهج لاستخراج الويب لغير التقنيين
لننتقل الآن إلى Thunderbit، وهي إضافة كروم لاستخراج الويب مدعومة بالذكاء الاصطناعي. إذا كنت مندوب مبيعات، أو مسوقًا، أو محترف عمليات وتريد فقط جلب بيانات من موقع إلى Excel أو Google Sheets أو Notion — من دون لمس سطر الأوامر — فقد صُممت Thunderbit من أجلك.
إليك كيفية مقارنة Thunderbit بـ cURL:
| الميزة | cURL | Thunderbit |
|---|---|---|
| واجهة المستخدم | سطر أوامر | نقر واختيار (إضافة كروم) |
| اقتراح الحقول بالذكاء الاصطناعي | لا | نعم (الذكاء الاصطناعي يقرأ الصفحة ويقترح الأعمدة) |
| التعامل مع الترقيم/الصفحات الفرعية | سكربتة يدوية | تلقائي (يرصد الذكاء الاصطناعي ذلك ويستخرج) |
| تصدير البيانات | يدوي (تحليل + حفظ) | مباشرة إلى Excel وGoogle Sheets وNotion وAirtable |
| صفحات JavaScript/الصفحات المحمية | لا | نعم (استخراج معتمد على المتصفح) |
| عدم الحاجة إلى كود | لا (يتطلب سكربتات) | نعم (يمكن لأي شخص استخدامه) |
| الخطة المجانية | مجانية دائمًا | مجانية حتى 6 صفحات (10 مع تعزيز التجربة) |
مع Thunderbit، ما عليك سوى فتح الإضافة، والنقر على «اقتراح الحقول بالذكاء الاصطناعي»، وترك الذكاء الاصطناعي يحدد البيانات المطلوب استخراجها. يمكنك استخراج الجداول، والقوائم، وتفاصيل المنتجات، وحتى زيارة الصفحات الفرعية تلقائيًا. ثم صدّر بياناتك مباشرة إلى أدوات العمل المفضلة لديك — من دون تحليل، ومن دون صداع.
يثق بـ Thunderbit أكثر من 100,000 مستخدم حول العالم، وهي تحظى بشعبية خاصة بين فرق المبيعات والتجارة الإلكترونية والعقارات التي تحتاج إلى بيانات منظمة بسرعة.
جرّب إضافة Thunderbit للكروم لاستخراج الويب
هل تريد تجربتها؟ حمّل إضافة Chrome من هنا.
الجمع بين cURL وThunderbit: استراتيجيات مرنة لاستخراج الويب
إذا كنت مستخدمًا تقنيًا، فلا داعي لاختيار أداة واحدة فقط. في الواقع، تستخدم العديد من الفرق cURL وThunderbit معًا لتحقيق أقصى قدر من المرونة:
- نمذج أولية باستخدام cURL: استخدم cURL لاختبار نقاط النهاية بسرعة، وفحص الرؤوس، وفهم طريقة استجابة الموقع.
- توسّع باستخدام Thunderbit: عندما تحتاج إلى بيانات منظمة، أو استخراج متعدد الصفحات، أو سير عمل قابل للتكرار، انتقل إلى Thunderbit لاستخراج بنقرة واحدة وتصدير مباشر.
إليك سير عمل نموذجي للبحث السوقي:
- استخدم cURL لجلب بضع صفحات وفحص بنية HTML.
- حدّد حقول البيانات التي تريدها (مثل أسماء المنتجات، والأسعار، والمراجعات).
- افتح Thunderbit، وانقر على «اقتراح الحقول بالذكاء الاصطناعي»، ودع الذكاء الاصطناعي يهيئ أداة الاستخراج.
- استخرج كل الصفحات (بما في ذلك الصفحات الفرعية أو القوائم المرقمة) وصدّر إلى Google Sheets.
- حلل بياناتك وشاركها وتصرف بناءً عليها — من دون الحاجة إلى تحليل يدوي.
إليك جدول قرار سريع:
| الحالة | استخدم cURL | استخدم Thunderbit | استخدم الاثنين معًا |
|---|---|---|---|
| جلب سريع لـ API أو صفحة ثابتة | ✅ | ||
| الحاجة إلى بيانات منظمة في جدول بيانات | ✅ | ||
| تصحيح الرؤوس/ملفات الارتباط | ✅ | ||
| استخراج صفحات ديناميكية/ثقيلة بـ JS | ✅ | ||
| بناء سير عمل متكرر بلا كود | ✅ | ||
| النمذجة أولًا ثم التوسع | ✅ | ✅ | سير عمل هجين |
التحديات الشائعة والمخاطر في استخراج الويب باستخدام cURL
قبل أن تنطلق بحماس مع cURL، لنتحدث عن التحديات الواقعية التي ستواجهها:
- أنظمة مكافحة الروبوتات: تستخدم مواقع كثيرة الآن دفاعات متقدمة (تحديات JavaScript، وCAPTCHA، وبصمة المتصفح) لا يستطيع cURL تجاوزها (developers.cloudflare.com).
- مشكلات جودة البيانات: تغيّر HTML، أو الحقول المفقودة، أو التخطيطات غير المتسقة قد تكسر سكربتاتك.
- عبء الصيانة: كلما تغيّر الموقع، ستحتاج إلى تحديث منطق التحليل لديك.
- مخاطر قانونية ومخاطر امتثال: تحقق دائمًا من شروط خدمة الموقع، وrobots.txt، والقوانين ذات الصلة قبل الاستخراج. كون البيانات عامة لا يعني أنها مجانية الاستخدام (calawyers.org، polsinelli.com).
- حدود التوسع: cURL رائع للمهام الصغيرة، لكن على نطاقات كبيرة ستحتاج إلى إدارة البروكسيات، وحدود المعدل، ومعالجة الأخطاء.
نصائح لاستكشاف الأخطاء والبقاء ضمن الامتثال:
- ابدأ دائمًا بالمواقع المسموح بها أو التجريبية (مثل Books to Scrape).
- احترم حدود المعدل — لا تُغرق نقاط النهاية بالطلبات.
- تجنب استخراج البيانات الشخصية ما لم يكن لديك أساس قانوني.
- إذا واجهت جدران JavaScript أو CAPTCHA، ففكّر في الانتقال إلى أداة معتمدة على المتصفح مثل Thunderbit.
ملخص خطوة بخطوة: كيفية استخراج المواقع باستخدام cURL
إليك قائمة مراجعة سريعة لاستخراج الويب باستخدام cURL:
- حدّد عنوان/عناوين URL المستهدفة: ابدأ بصفحة ثابتة أو نقطة نهاية API.
- اجلب الصفحة:
curl URL - احفظ المخرجات في ملف:
curl -o file.html URL - افحص الرؤوس/صحح الأخطاء:
curl -I URL,curl -v URL - أرسل بيانات POST:
curl -d "a=1&b=2" URL - تعامل مع ملفات الارتباط/الجلسات:
curl -c cookies.txt ...,curl -b cookies.txt ... - اضبط الرؤوس المخصصة/User-Agent:
curl -A "..." -H "..." URL - اتبع إعادة التوجيه:
curl -L URL - استخدم البروكسيات (إذا لزم):
curl -x proxy:port URL - أتمتة استخراج صفحات متعددة: استخدم حلقات shell أو السكربتات.
- حلل ونظّم البيانات: استخدم أدوات/سكربتات إضافية عند الحاجة.
- انتقل إلى Thunderbit للاستخراج المنظم بلا كود أو للصفحات الديناميكية.
الخلاصة وأهم النقاط: اختيار أداة استخراج الويب المناسبة
استخرج البيانات من أي موقع باستخدام الذكاء الاصطناعي Get Started Free
ما يزال استخراج الويب باستخدام cURL مهارة قوية للمستخدمين التقنيين في 2026 — خاصةً للجلب السريع للبيانات، والنمذجة الأولية، والأتمتة. وتجعله سرعته، وقابليته للسكربتة، وانتشاره أداة أساسية في صندوق أدوات كل مطور. لكن مع ازدياد ديناميكية الويب وحمايته، ومع مطالبة مستخدمي الأعمال ببيانات منظمة من دون برمجة، تعيد أدوات مثل Thunderbit تعريف الممكن.
أهم النقاط:
- استخدم cURL للصفحات الثابتة، وواجهات API، والنمذجة السريعة — خصوصًا عندما تريد تحكمًا كاملًا.
- انتقل إلى Thunderbit (أو أدوات استخراج ويب أخرى بالذكاء الاصطناعي) عندما تحتاج إلى بيانات منظمة، أو تتعامل مع صفحات ديناميكية/ثقيلة بـ JavaScript، أو تريد سير عمل بلا كود ومناسبًا للأعمال.
- اجمع بين الاثنين لأقصى مرونة: نمذج باستخدام cURL، ثم وسّع ونظّم باستخدام Thunderbit.
- استخرج البيانات بمسؤولية دائمًا — واحترم شروط الموقع، وحدود المعدل، والحدود القانونية.
هل تشعر بالفضول لترى مدى سهولة استخراج الويب؟ جرّب إضافة Thunderbit المجانية للكروم واختبر استخراج البيانات بالذكاء الاصطناعي بنفسك. وإذا أردت التعمق أكثر، فاطّلع على مدونة Thunderbit لمزيد من الشروحات والنصائح والرؤى الصناعية. وقد يعجبك أيضًا:
- كيفية استخراج أي موقع باستخدام الذكاء الاصطناعي
- كيفية استخراج بيانات المواقع إلى Excel باستخدام الذكاء الاصطناعي
- ما هو استخراج البيانات وكيف تفعله في 2025
استخراجًا سعيدًا — ولتظل بياناتك دائمًا نظيفة ومنظمة وعلى بُعد أمر واحد (أو نقرة واحدة) فقط.
استكشف خطط Thunderbit للاستخراج القابل للتوسع
الأسئلة الشائعة
1. هل يستطيع cURL التعامل مع صفحات الويب المعروضة بواسطة JavaScript؟
لا، لا يمكن لـ cURL تنفيذ JavaScript. فهو يجلب HTML الخام كما يقدمه الخادم. إذا كانت الصفحة تحتاج إلى JavaScript لعرض المحتوى أو لتجاوز تحديات مكافحة الروبوتات، فلن يتمكن cURL من الوصول إلى البيانات. في هذه الحالات، استخدم أدوات معتمدة على المتصفح مثل Thunderbit.
2. كيف أحفظ مخرجات cURL مباشرة في ملف؟
استخدم الخيار -o: curl -o filename.html URL. هذا يكتب نص الاستجابة إلى ملف بدلًا من عرضه في الطرفية.
3. ما الفرق بين cURL وThunderbit في استخراج الويب؟
cURL أداة سطر أوامر لجلب بيانات الويب الخام — ممتازة للمستخدمين التقنيين والأتمتة. أما Thunderbit فهو إضافة كروم مدعومة بالذكاء الاصطناعي ومصممة لمستخدمي الأعمال الذين يريدون استخراج بيانات منظمة من أي موقع، والتعامل مع الصفحات الديناميكية، والتصدير مباشرة إلى أدوات مثل Excel أو Google Sheets — من دون أي كود.
4. هل من القانوني استخراج المواقع باستخدام cURL؟
يُعد استخراج البيانات العامة قانونيًا عمومًا في الولايات المتحدة بعد أحكام قضائية حديثة، لكن تحقق دائمًا من شروط خدمة الموقع وrobots.txt والقوانين ذات الصلة. تجنب استخراج البيانات الشخصية أو المحمية من دون إذن، واحترم حدود المعدل والإرشادات الأخلاقية (calawyers.org، polsinelli.com).
5. متى ينبغي أن أنتقل من cURL إلى أداة أكثر تقدمًا مثل Thunderbit؟
إذا كنت بحاجة إلى استخراج صفحات ديناميكية/ثقيلة بـ JavaScript، أو تريد بيانات منظمة في جدول بيانات، أو تفضّل سير عمل بلا كود، فـ Thunderbit هو الخيار الأفضل. استخدم cURL للمهام السريعة والتقنية؛ واستخدم Thunderbit لاستخراج بيانات متكرر ومناسب للأعمال.
لمزيد من نصائح وشروحات استخراج الويب، زر مدونة Thunderbit أو اطلع على قناة YouTube الخاصة بنا.
جرّب أداة Thunderbit المدعومة بالذكاء الاصطناعي لاستخراج الويب Get Started Free




