

هل استخراج بيانات الويب غير قانوني؟ هذا هو السؤال الذي يسمعه المؤسسون والمسوقون ومحبو البيانات كل أسبوع تقريبًا.
ومع أن 51% من حركة الإنترنت الآن تأتي من الروبوتات—وهي المرة الأولى التي تتجاوز فيها الحركة الآلية النشاط البشري—وأن جزءًا كبيرًا من ذلك يتعلق باستخراج بيانات الويب لأغراض ذكاء الأعمال والمبيعات وتدريب الذكاء الاصطناعي، فلا عجب أن الجميع يحاول فهم أين ترسم الحدود القانونية.
في يومٍ ما سترى عنوانًا عن حكم قضائي يقول إن استخراج البيانات العامة مسموح. وفي اليوم التالي ستصدر الجهات التنظيمية تحذيرات من جمع البيانات «بصورة غير قانونية» من وسائل التواصل الاجتماعي. الأمر مربك حتى لمن مثلي ممن يقضون أيامهم في بناء أدوات استخراج بيانات الويب بالذكاء الاصطناعي في Thunderbit.
إذًا، هل استخراج بيانات الويب غير قانوني؟ الإجابة ليست نعم أو لا ببساطة. فالأمر يعتمد على نوع البيانات التي تستخرجها، والموقع الذي تستخرج منها، وكيف تستخدم البيانات، وما يقوله القانون في بلدك.
في هذا الدليل المتعمق، سأفصّل المشهد القانوني، وأفند بعض الخرافات الشائعة، وأشارك نصائح عملية—إضافة إلى بعض قصص التجربة—للمحافظة على الامتثال، سواء كنت مؤسسًا منفردًا أو فريق بيانات في شركة من قائمة Fortune 500.
استخراج بيانات الويب والقانون: هل يوجد خط واضح؟
إذا كنت تأمل في إجابة من جملة واحدة، فسأوفر عليك الوقت: القانون لم يرسم حتى الآن خطًا واضحًا وحاسمًا بشأن استخراج بيانات الويب.
بدلًا من ذلك، هناك خليط متداخل من القواعد: ملكية البيانات، والخصوصية، والملكية الفكرية، وقوانين مكافحة الاختراق، وشروط الخدمة الشهيرة. يمكن أن يدخل كل واحد منها في الصورة، وغالبًا ما تعتمد الإجابة على حالتك المحددة (multilogin.com).
لنقسّمها إلى ثلاث فئات قانونية رئيسية:
- ملكية البيانات: عمومًا، الحقائق والمعلومات العامة (مثل الأسعار أو أرقام الهواتف) لا تحظى بحماية حقوق النشر. لكن المحتوى الإبداعي (مثل المقالات والصور) وقواعد البيانات المملوكة يمكن أن تتمتع بالحماية—وخاصة في الاتحاد الأوروبي، حيث توجد «حقوق قواعد البيانات» فعلًا (cliffordchance.com).
- الخصوصية: قوانين الخصوصية الحديثة (مثل GDPR في أوروبا وPIPL في الصين) تعامل البيانات الشخصية كأصل منظم—even لو كانت منشورة علنًا. قد يضعك استخراج الأسماء أو البريد الإلكتروني أو الملفات الاجتماعية دون أساس قانوني في موقف قانوني صعب (ico.org.uk).
- العقود (شروط الخدمة): كثير من المواقع تحظر استخراج البيانات صراحة في شروط الخدمة. ورغم أن شروط الخدمة ليست قوانين، فإن المحاكم قد تعتبرها عقودًا ملزمة. مخالفتها قد تعني دعاوى قضائية، وفي بعض الحالات قد تثير حتى قوانين مكافحة الاختراق إذا تجاوزت الحواجز التقنية (cliffordchance.com).
إذًا، هل استخراج بيانات الويب غير قانوني؟ أحيانًا نعم، وأحيانًا لا، وغالبًا «الأمر يعتمد». التفاصيل هي الحاسمة.
مقارنة المنظورات القانونية: الولايات المتحدة، الاتحاد الأوروبي، المملكة المتحدة، الصين
إليك جدولًا سريعًا يوضح كيف تتعامل المناطق الرئيسية مع استخراج بيانات الويب:
هل استخراج بيانات الويب غير قانوني؟ العوامل القانونية الأساسية التي يجب أخذها في الاعتبار
إذًا، ما الذي يحدد فعليًا ما إذا كان مشروعك لاستخراج البيانات قانونيًا أو محفوفًا بالمخاطر؟ إليك أهم العوامل:
- البيانات العامة مقابل الخاصة: استخراج البيانات التي يمكن لأي شخص رؤيتها على الويب المفتوح يكون عمومًا أكثر أمانًا. أما استخراج أي شيء خلف تسجيل دخول أو جدار دفع أو حاجز تقني؟ فذلك على الأرجح غير قانوني (thunderbit.com).
- طبيعة البيانات: البيانات الشخصية (الأسماء، البريد الإلكتروني، الملفات الشخصية) تفعّل قوانين الخصوصية. والمحتوى المحمي بحقوق النشر (المقالات، الصور) لا يمكن نسخه بالكامل. أما الحقائق الصرفة (الأسعار، الطقس) فعادةً فهي متاحة للاستخدام (oxylabs.io).
- الغرض من الاستخدام: يُنظر إلى التحليل الداخلي أو البحث بتسامح أكبر من إعادة نشر البيانات المستخرجة أو بيعها. واستخدام البيانات المستخرجة لمنافسة المصدر مباشرة؟ تلك وصفة لدعوى قضائية (thunderbit.com).
- الالتزام بقواعد الموقع: تحقق دائمًا من robots.txt وشروط الخدمة. robots.txt ليس ملزمًا قانونيًا، لكنه ممارسة جيدة يجب احترامها. مخالفة شروط الخدمة قد تعني دعاوى مدنية أو ما هو أسوأ (promptcloud.com).
- الإجراءات التقنية: من المهم أن تعمل بسرعات تشبه البشر وألا تتجاوز الإجراءات الأمنية. الضغط على الخادم بإفراط أو التحايل على CAPTCHA قد يدخل في نطاق الاختراق (cliffordchance.com).
ما الذي تغيّر في 2024–2026: أهم القضايا القضائية واللوائح
شهد المشهد القانوني لاستخراج بيانات الويب تغيّرًا كبيرًا منذ 2023. إليك التطورات التي يجب على كل من يستخدم أدوات الاستخراج معرفتها:
أبرز الأحكام القضائية
-
Meta v. Bright Data (2024): قضت محكمة اتحادية أمريكية بأن شروط خدمة Meta لا تحظر استخراج البيانات العامة من قبل المستخدمين غير المسجلين دخولًا. ووجد القاضي أن «الزائر لا يُعد ‘مستخدمًا’ ما لم يكن لديه حساب». ثم أسقطت Meta بقية الدعاوى بعد ذلك بقليل. هذا انتصار تاريخي لاستخراج البيانات العامة.
-
X Corp v. Bright Data (2024): خسرت Twitter (الآن X) دعوى مشابهة، مما عزز المبدأ نفسه: استخراج البيانات العامة المتاحة دون تسجيل دخول لا يُعد مخالفة لشروط الخدمة، لأن الأداة لم توافق أصلًا على تلك الشروط.
-
Reddit v. Perplexity AI (أكتوبر 2025): رفعت Reddit دعوى ضد Perplexity AI وعدة مزودي خدمات استخراج، مستندةً إلى DMCA وادعاء تجاوز أنظمة مكافحة الروبوتات. وهذا يشير إلى استراتيجية قانونية جديدة: المنصات تتجه إلى حقوق النشر وادعاءات تجاوز الحماية التقنية بدلًا من CFAA.
-
NYT v. OpenAI (مارس 2025): سمح قاضٍ اتحادي لقضية حقوق النشر التي رفعتها New York Times ضد OpenAI بالاستمرار، رافضًا طلب OpenAI لرفض الدعوى. وقد يضع هذا سابقة مهمة حول ما إذا كان استخراج المحتوى لتدريب نماذج الذكاء الاصطناعي يُعد «استخدامًا عادلًا».
-
تسوية Anthropic (سبتمبر 2025): وافقت Anthropic على دفع 1.5 مليار دولار لتسوية دعوى جماعية في الولايات المتحدة تتعلق باستخدام نصوص محمية بحقوق النشر لتدريب نموذج الذكاء الاصطناعي الخاص بها—وهو ما يوضح أن تكلفة الاستخراج لأغراض الذكاء الاصطناعي حقيقية جدًا.
الاتجاه الكبير: من CFAA إلى قانون العقود وحقوق النشر
النمط واضح: CFAA (قانون الاحتيال وإساءة استخدام الحواسيب) يفقد قوته كسلاح ضد من يستخرجون البيانات العامة. الشركات التي حاولت استخدام CFAA ضد استخراج البيانات العامة—مثل Meta وX وLinkedIn—فشلت إلى حد كبير. وبدلًا من ذلك، يتحول ساحة النزاع القانوني إلى:
- قانون العقود (مخالفات شروط الخدمة—لكن المحاكم تقول إن غير المستخدمين غير ملزمين بالشروط)
- ادعاءات حقوق النشر (وخاصةً لبيانات تدريب الذكاء الاصطناعي)
- قوانين تجاوز الحماية التقنية (DMCA القسم 1201)
بالنسبة لمن يستخدمون أدوات الاستخراج، فهذا يعني أن الخطر القانوني لم يختفِ—إنه فقط انتقل.
التغييرات التنظيمية
- تحديثات CCPA لعام 2026: دخلت لوائح CCPA المعدلة في كاليفورنيا حيز التنفيذ في 1 يناير 2026، مضيفةً قواعد جديدة لتقنية اتخاذ القرار الآلي (ADMT)، وتقييمات المخاطر، والتزامات وسطاء البيانات.
- قوانين خصوصية جديدة في الولايات الأمريكية: أقرّت ولايات إنديانا وكنتاكي ورود آيلاند قوانين خصوصية شاملة دخلت حيّز التنفيذ في 2026.
- قانون الذكاء الاصطناعي الأوروبي: يبدأ الإنفاذ الكامل في 2 أغسطس 2026—مع إلزام مطوري الذكاء الاصطناعي بالكشف عن مصادر بيانات التدريب، واحترام اعتراضات حقوق النشر، وحظر استخراج صور الوجوه لأنظمة الذكاء الاصطناعي.
- قانون مساءلة الذكاء الاصطناعي للناشرين (فبراير 2026): مشروع قانون أمريكي مقترح سيُلزم شركات الذكاء الاصطناعي بالحصول على إذن ودفع مقابل للناشرين قبل استخراج محتواهم.
سياسات الاستخراج في المنصات الكبرى: ما الذي يجب أن تعرفه
لا تتعامل جميع المواقع مع الاستخراج بالطريقة نفسها. إليك نظرة منصة بمنصة على ما تسمح به المواقع الكبرى، وما تحظره، وما قالته المحاكم:
| المنصة | شروط الخدمة بشأن الاستخراج | الدفاعات التقنية | الإنفاذ القانوني | ما هو الآمن عمليًا |
|---|---|---|---|---|
| Google (Search & Maps) | تحظر الوصول الآلي في شروط الخدمة. وتضم منصة Maps بندًا صريحًا «ممنوع الاستخراج». | تحديات SearchGuard JS، وCAPTCHA، وتحديد المعدل. تم تحديث robots.txt في 2025 لحظر زواحف الذكاء الاصطناعي. | رفعت دعاوى ضد من يستخرج البيانات في ديسمبر 2025 باستخدام DMCA. وتمنع زواحف الذكاء الاصطناعي بنشاط (Anthropic وMeta وOpenAI). | استخراج بيانات الأعمال العامة من Google Maps يمكن الدفاع عنه قانونيًا (سوابق hiQ)، لكن توقع حواجز تقنية. استخدم واجهات API الرسمية حيثما أمكن. |
| Amazon | تحظر صراحةً كل أنواع الاستخراج في شروط الاستخدام («لا روبوت، ولا عنكبوت، ولا أداة استخراج، ولا أي وسيلة آلية أخرى»). | كشف عدواني للروبوتات، وCAPTCHA، وحظر IP. ويحظر robots.txt كل الروبوتات باستثناء Googlebot وBingbot. كما يحظر زواحف الذكاء الاصطناعي صراحةً منذ 2025. | رفعت دعوى على Perplexity AI في نوفمبر 2025. وتُرسل خطابات وقف وكف بانتظام. وتم تحديث BSA في مارس 2026 بقواعد لوكلاء الذكاء الاصطناعي. | بيانات المنتجات العامة (الأسعار، القوائم) حقائق ويمكن استخراجها بموجب القانون الأمريكي، لكن Amazon تقاوم بقوة. أبطئ الطلبات وتجنب البيانات الشخصية. |
| تحظر الاستخراج في شروط الخدمة؛ وتتطلب موافقة المستخدم للوصول إلى الخدمات. | جدران تسجيل الدخول لمعظم بيانات الملفات الشخصية، وكشف مضاد للروبوتات، وتحديد معدل. | أكدت قضية hiQ أن استخراج الملفات الشخصية العامة لا يخالف CFAA، لكن LinkedIn ربحت في مطالبات العقد/المنافسة غير العادلة عندما استُخدمت حسابات وهمية. | الملفات الشخصية العامة (المرئية دون تسجيل دخول) يمكن الدفاع عن استخراجها قانونيًا. لا تنشئ حسابات وهمية أبدًا ولا تستخرج بيانات خلف تسجيل الدخول. | |
| Meta (Facebook & Instagram) | تحظر شروط الخدمة الاستخراج؛ مع قواعد منفصلة للبيانات المسجلة الدخول والبيانات غير المسجلة. | جدران تسجيل دخول لمعظم المحتوى، وكشف متقدم للروبوتات. | خسرت أمام Bright Data في 2024—حكمت المحكمة بأن شروط الخدمة لا تنطبق على من يستخرج دون تسجيل دخول. وأسقطت الدعاوى المتبقية. | البيانات العامة (صفحات الأعمال، المنشورات العامة) المرئية دون تسجيل دخول في وضع قانوني أكثر أمانًا. لا تستخرج الملفات الشخصية الخاصة أو البيانات خلف تسجيل الدخول أبدًا. |
| X (Twitter) | عدّلت شروط الخدمة في 2023 لحظر كل استخراج وزحف دون موافقة مكتوبة. وألغت الاستثناء القديم الخاص بـ robots.txt. | يحظر robots.txt جميع الزواحف (Disallow: /). وتوجد تحديات Cloudflare Turnstile. وحدود صارمة للمعدل (300 طلب/ساعة). وتقييم لسمعة IP. | خسرت أمام Bright Data بشأن البيانات العامة، لكنها تفرض قيودًا تقنية قوية جدًا. | التغريدات والملفات الشخصية العامة يمكن الدفاع عن استخراجها قانونيًا، لكن الحواجز التقنية في X من الأصعب في 2026. توقع الحظر ما لم تستخدم بنية وكيل احترافية. |
الخلاصة: قضت المحاكم باستمرار أن استخراج البيانات المرئية للعامة دون تسجيل دخول لا يخالف CFAA. لكن المنصات يمكنها مع ذلك مقاضاتك بموجب قانون العقود أو حقوق النشر أو قوانين تجاوز الحماية التقنية—وستجعل حياتك صعبة تقنيًا أيضًا. استخرج البيانات بمسؤولية دائمًا.
بيانات تدريب الذكاء الاصطناعي واستخراج بيانات الويب: الحدود القانونية الجديدة
إذا كنت تتابع الأخبار في 2026، فأنت تعرف أن استخراج البيانات لتدريب نماذج الذكاء الاصطناعي أصبح أكثر ساحات النزاع القانوني سخونة. إليك ما يحدث:
- تتراكم دعاوى حقوق النشر. رفعت New York Times والكتّاب والناشرون دعاوى ضد OpenAI وAnthropic وغيرهما، مدّعين أن الاستخراج الجماعي للمحتوى المحمي لتدريب نماذج اللغة الكبيرة ليس «استخدامًا عادلًا». وقد سوّت Anthropic دعوى جماعية كبرى مقابل 1.5 مليار دولار في 2025—وهو ما يشير إلى أن تكلفة الاستخراج لأجل الذكاء الاصطناعي حقيقية جدًا.
- حجة «الاستخدام العادل» غير مستقرة. لم تصدر المحاكم الأمريكية بعد حكمًا حاسمًا بشأن ما إذا كان تدريب الذكاء الاصطناعي على البيانات المستخرجة يُعد استخدامًا عادلًا. وتوحي القرارات المبكرة بأن ذلك يعتمد كثيرًا على كيفية الحصول على البيانات وما الذي يُفعل بالمخرجات.
- تشريع جديد في الطريق. يهدف قانون مساءلة الذكاء الاصطناعي للناشرين (المُقدَّم في فبراير 2026) إلى إلزام شركات الذكاء الاصطناعي بالحصول على إذن ودفع مقابل للناشرين قبل استخراج محتواهم.
- قانون الذكاء الاصطناعي الأوروبي (الإنفاذ الكامل أغسطس 2026) يتطلب من مطوري الذكاء الاصطناعي الإفصاح عن مصادر بيانات التدريب، واحترام خيارات الاستثناء من حقوق النشر المقروءة آليًا (ضمن استثناء TDM في توجيه حقوق النشر)، ووضع وسم على المحتوى المُولَّد بالذكاء الاصطناعي. كما يحظر أنظمة الذكاء الاصطناعي التي تستخرج صور الوجوه من الإنترنت.
- زواحف الذكاء الاصطناعي/نماذج اللغة الكبيرة تتضخم بسرعة. تضاعفت حصة زواحف الذكاء الاصطناعي من حركة الويب من 2.6% إلى 10.1% خلال ثمانية أشهر فقط. ونما GPTBot من OpenAI وحده بنسبة 305%. وردًا على ذلك، تقوم مواقع كبرى (Amazon وReddit وNYT) بتحديث robots.txt لحظر زواحف الذكاء الاصطناعي صراحةً.
ما الذي يعنيه هذا لك؟ إذا كنت تستخرج البيانات لأغراض تجارية تقليدية (توليد العملاء المحتملين، مراقبة الأسعار، أبحاث السوق)، فقد لا تنطبق هذه القواعد الخاصة بالذكاء الاصطناعي مباشرةً. لكن إذا كنت تُغذي البيانات المستخرجة في نماذج ذكاء اصطناعي، فكن شديد الحذر—واستشر محاميًا.
قوانين استخراج بيانات الويب حول العالم: مقارنة سريعة
لنبتعد قليلًا ونرى كيف تبدو القواعد عالميًا:
- الولايات المتحدة: لا يوجد حظر شامل. استخراج البيانات من المواقع العامة قانوني عمومًا (hiQ v. LinkedIn)، وقد عززت أحكام Meta وX Corp في 2024 هذا الموقف بشأن البيانات العامة. لكن الاستخراج خلف تسجيل الدخول أو الحواجز التقنية قد يفعّل CFAA. والاتجاه الآن يميل إلى استخدام الشركات قانون العقود وادعاءات حقوق النشر بدلًا من ذلك. كما تتوسع قوانين الخصوصية بسرعة: تلقت CCPA تحديثات كبيرة سارية من 1 يناير 2026، تشمل قواعد جديدة لاتخاذ القرار الآلي والتزامات وسطاء البيانات. كما أصدرت إنديانا وكنتاكي ورود آيلاند قوانين خصوصية شاملة في 2026.
- الاتحاد الأوروبي: قوانين خصوصية صارمة. ينطبق GDPR حتى على البيانات الشخصية العامة. وقد تمنع حقوق قواعد البيانات الاستخراج واسع النطاق للبيانات المهيكلة (cliffordchance.com). جديد: يدخل قانون الذكاء الاصطناعي الأوروبي الإنفاذ الكامل في 2 أغسطس 2026، ما يلزم مطوري الذكاء الاصطناعي بالإفصاح عن مصادر بيانات التدريب واحترام خيارات الاستثناء من حقوق النشر. ويحظر القانون استخراج صور الوجوه من الإنترنت لأنظمة الذكاء الاصطناعي.
- المملكة المتحدة: تتبع قواعد الاتحاد الأوروبي بعد Brexit. يمكن استخراج البيانات العامة، لكن استخراج المعلومات الشخصية منظم بشدة. ويمكن أن يجرّم Computer Misuse Act الوصول غير المصرح به.
- الصين: صارمة جدًا. يتطلب PIPL وقانون أمن البيانات موافقة على البيانات الشخصية. وتستخدم المحاكم قانون المنافسة غير العادلة لإيقاف الاستخراج الذي يضر بالأعمال (malwarebytes.com).
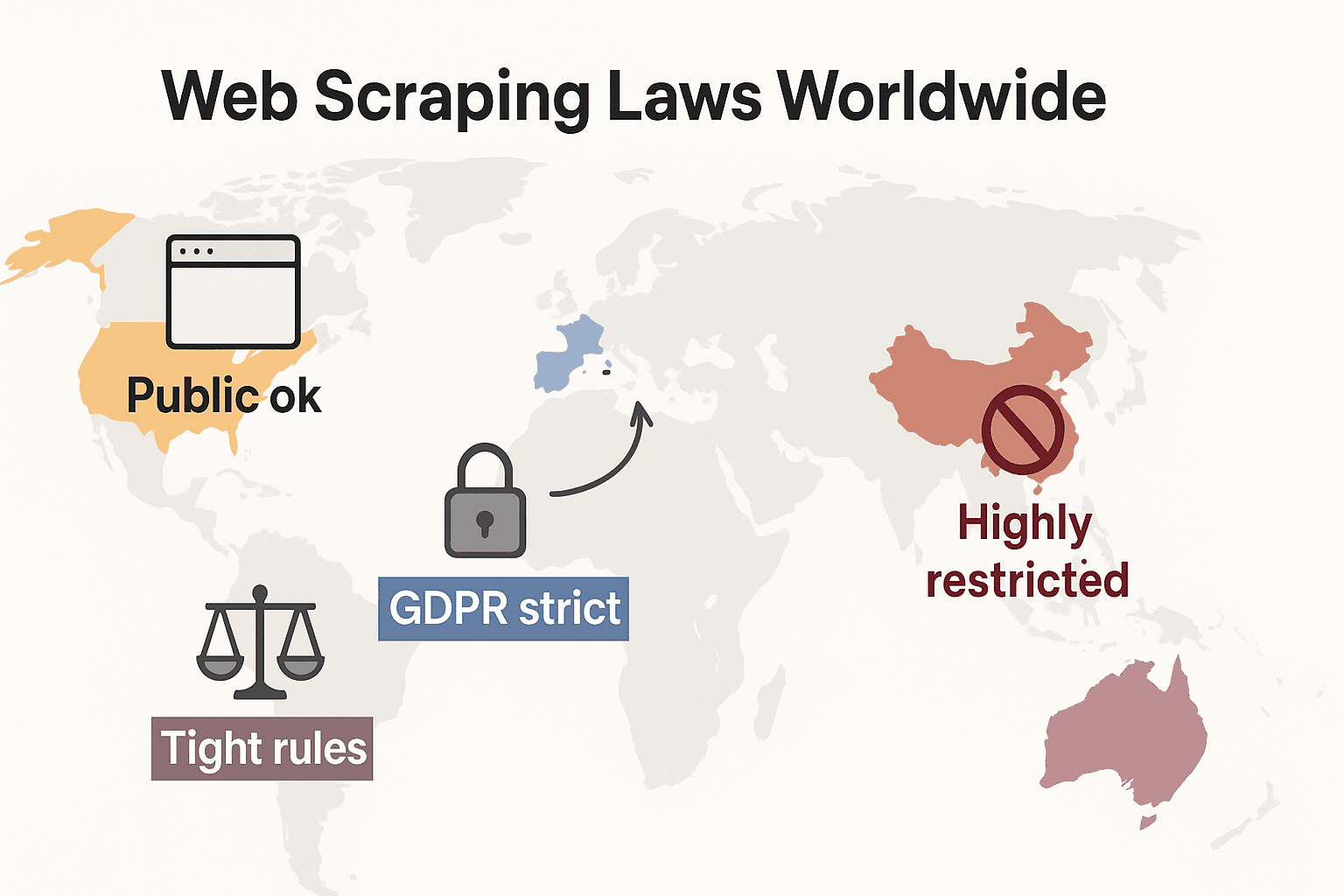
الخلاصة: استخراج البيانات العامة غير الشخصية للاستخدام الداخلي هو عادةً الخيار الأكثر أمانًا. أما غير ذلك؟ فتحقق من القوانين المحلية وتوخَّ الحذر.
خرافات شائعة حول قانونية استخراج بيانات الويب
دعنا نفند بعض الخرافات التي أسمعها طوال الوقت:
- الخرافة 1: «استخراج بيانات الويب غير قانوني تمامًا».
خطأ. لا يوجد قانون يحظر كل أنواع استخراج بيانات الويب. ما يهم هو كيف تستخرج البيانات وما الذي تستخرجه (oxylabs.io). - الخرافة 2: «إذا كانت البيانات عامة، أستطيع فعل ما أريد بها».
ليس تمامًا. فقد تظل البيانات العامة محمية بقوانين الخصوصية أو حقوق النشر، وقد تقيد شروط الخدمة بعض الاستخدامات (ico.org.uk). - الخرافة 3: «استخراج بيانات الويب هو نفسه الاختراق».
لا. استخراج الصفحات العامة ليس اختراقًا. أما تجاوز تسجيل الدخول أو الحواجز التقنية فهذه قصة مختلفة (calawyers.org). - الخرافة 4: «إذا لم أُكتشف، فلا مشكلة».
تفكير خطِر. كثير من المواقع تستخدم تقنيات مكافحة الروبوتات وستلاحظك. الصمت ليس موافقة. - الخرافة 5: «إذا نسبت المصدر أو استخدمت البيانات داخليًا، فهذا يبيح الأمر».
النسب لا يلغي قانون حقوق النشر أو الخصوصية. الاستخدام الداخلي أكثر أمانًا، لكنه ليس تصريحًا مفتوحًا. - الخرافة 6: «كل استخراج بيانات الويب ينتهك الخصوصية».
ليس كل استخراج يتضمن بيانات شخصية. لكن استخراج كميات كبيرة من المعلومات الشخصية دون ضوابط يكون غير قانوني في الغالب (oxylabs.io). - الخرافة 7: «إذا كانت شروط الخدمة تمنع الاستخراج، فهو دائمًا غير قانوني».
ليس بالضرورة. ففي 2024، قضت المحاكم في Meta v. Bright Data وX Corp v. Bright Data بأن شروط الخدمة لا تُلزم من لم يوافق عليها أصلًا—أي إذا كنت تستخرج البيانات دون تسجيل دخول أو إنشاء حساب، فقد لا تنطبق عليك شروط الموقع. لا يزال هذا المجال يتطور، لكنه تحول مهم.
كيفية استخراج البيانات بشكل قانوني: أفضل الممارسات للامتثال
إليك قائمتي المعتادة للاستخراج القانوني والأخلاقي:
- اقرأ شروط الخدمة واحترمها. إذا قالت «لا استخراج»، ففكّر في التوقف أو اطلب إذنًا (ql2.com).
- التزم بالبيانات العامة. إذا كنت بحاجة إلى كلمة مرور، فالبيانات مقيدة—لا تستخرجها (thunderbit.com).
- تحقق من robots.txt وتصرّف بأدب عند الزحف. ليس ملزمًا قانونيًا، لكنه من حسن السلوك. لا تضغط على الخوادم بإفراط—وزّع طلباتك (promptcloud.com).
- تجنّب البيانات الشخصية ما لم يكن لديك أساس قانوني. إذا كان لا بد من جمعها، فالتزم بـ GDPR/CCPA وقلّل ما تجمعه.
- لا تعِد نشر المحتوى المستخرج بالكامل. أضف قيمة أو تحليلًا، أو احصل على إذن (thunderbit.com).
- لا تغذِّ المحتوى المستخرج إلى نماذج الذكاء الاصطناعي دون التحقق من حقوق النشر. المشهد القانوني يتغير بسرعة—اطلب المشورة إذا كان هذا هو استخدامك.
- استخدم واجهات API الرسمية أو تصدير البيانات عندما تكون متاحة. فهي مصممة لهذا الغرض وعادةً أكثر أمانًا (thunderbit.com).
- كن شفافًا ومسؤولًا. إذا جمعت بيانات شخصية، فأعلم الناس واحتفظ بسجل لنشاطك.
- قلّل البيانات وأمّنها. اجمع فقط ما تحتاجه، واحفظه بدقة، وخزّنه بأمان.
- ابقَ مطّلعًا واطلب المشورة القانونية في الحالات الحدّية. القوانين والأحكام تتغير بسرعة—وخاصةً قانون الذكاء الاصطناعي الأوروبي وقوانين الخصوصية في الولايات المتحدة. وعند الشك، اسأل مختصًا.
جرّب إضافة Thunderbit على Chrome للاستخراج المتوافق
استخدام أدوات استخراج بيانات الويب بشكل قانوني: ما الذي تحتاجه الشركات
أدوات استخراج بيانات الويب مثل Thunderbit تجعل جمع البيانات متاحًا لغير المبرمجين، لكن لا يزال عليك استخدامها بمسؤولية:
- اختر أدوات تركّز على الامتثال. على سبيل المثال، Thunderbit يستخرج فقط ما يمكنك رؤيته في متصفحك—من دون حيل API خفية أو وصول غير مصرح به (thunderbit.com).
- التزم بحالات الاستخدام المشروعة. التحليلات الداخلية، وأبحاث السوق، ومراقبة الأسعار التنافسية تكون آمنة عمومًا. أما إعادة نشر البيانات المستخرجة أو بيعها؟ فذلك أكثر خطورة بكثير.
- اضبط الأدوات بما يوافق الامتثال. عيّن فواصل بين الطلبات، والتزم بـ robots.txt، واستخدم القوالب التي تجمع فقط ما تحتاجه.
- احتفظ بها داخل الشركة. استخدام البيانات المستخرجة داخليًا أكثر أمانًا من إعادة نشرها.
- ثقف فريقك. تأكد من أن الجميع يفهم القواعد وأفضل الممارسات.
- استفد من ميزات الامتثال المدمجة. Thunderbit يحذر المستخدمين من المواقع عالية المخاطر، ويستخرج البيانات بسرعات تشبه البشر، ولا يخزن بياناتك على خوادمه.
- لا تفرض الأمر بالقوة. إذا لم يتمكن الأداة من استخراج موقع ما، فلا تحاول التحايل عليه. ليست كل البيانات قابلة للوصول دون مخاطر.
نهج Thunderbit: تمكين استخراج بيانات الويب بالذكاء الاصطناعي بشكل متوافق
في Thunderbit، قضينا وقتًا طويلًا في التفكير في الامتثال. إليك كيف تساعد أداة AI Web Scraper المستخدمين على البقاء في الجانب القانوني الصحيح:
- تستخرج فقط ما يمكنك رؤيته. يعمل Thunderbit داخل جلسة المتصفح لديك، لذلك لا يمكنه الوصول إلى بيانات لا يمكنك نسخها يدويًا.
- يرشد المستخدمين بالتحذيرات. إذا حاولت استخراج موقع بسياسات صارمة ضد الاستخراج، سينبهك Thunderbit.
- سرعات استخراج تشبه البشر. سواء كنت تعمل محليًا أو في السحابة، يتجنب Thunderbit الضغط على الخوادم.
- اختيار بيانات قابل للتخصيص. تقترح AI الأعمدة ذات الصلة، مما يساعدك على جمع ما تحتاجه فقط.
- التعامل مع الصفحات الفرعية والتقسيم إلى صفحات. يتنقل Thunderbit في المواقع كما يفعل المستخدم الحقيقي، مع احترام بنيتها.
- الخصوصية والأمان. تبقى بياناتك معك—Thunderbit لا يخزنها ولا يعيد استخدامها.
- تصدير ملائم للامتثال. صدّر مباشرةً إلى Google Sheets أو Airtable أو Notion أو CSV للاستخدام الآمن الداخلي.
- الجدولة والأتمتة. أنشئ عمليات استخراج متكررة على فترات مسؤولة.
- دعم متعدد اللغات. تدعم واجهة Thunderbit 34 لغة، ما يجعل الامتثال متاحًا عالميًا.
- تحديثات منتظمة للقوالب. تُبقى قوالبنا الفورية للمواقع الشائعة محدثة وفق التغيرات القانونية والتقنية.
ومن خلال دمج الامتثال في المنتج، يساعد Thunderbit الفرق على جمع البيانات التي تحتاجها—من دون الصداع القانوني.
البقاء متقدمًا: التكيف مع التغيرات القانونية والتقنية في استخراج بيانات الويب
استكشف المزيد من أدلة استخراج بيانات الويب Get Started Free
استخراج بيانات الويب ليس لعبة تُضبط مرة واحدة وتُترك. فالقوانين وبنى المواقع تتطور باستمرار. إليك كيف تبقى متقدمًا:
- تابع التطورات القانونية. تسارع وتيرة التغير في 2024–2026—تابع أخبار قانون التقنية، وتحديثات الجهات التنظيمية، ومدونات الصناعة (مثل مدونة Thunderbit). وراقب إنفاذ قانون الذكاء الاصطناعي الأوروبي (أغسطس 2026)، وقوانين الخصوصية الجديدة في الولايات المتحدة، وقضايا حقوق النشر المستمرة المتعلقة بالذكاء الاصطناعي.
- تكيّف مع التغيرات التقنية. تحدّث المواقع تصميماتها ودفاعاتها ضد الروبوتات طوال الوقت. عززت المنصات الكبرى (Amazon وX وGoogle) دفاعاتها بشكل ملحوظ في 2025–2026. وقد صُممت AI والقوالب في Thunderbit للتكيف تلقائيًا.
- اعتمد واجهات API الرسمية عندما تكون متاحة. إذا انتقل موقع ما إلى نموذج API مدفوع، ففكّر في التحول إليه من أجل الاعتمادية والامتثال.
- راجع عمليات الاستخراج بانتظام. وثّق مصادر البيانات، وتحقق من تغير شروط الخدمة أو السياسات، وعدّل استراتيجيتك عند الحاجة.
- استفد من تحديثات قوالب Thunderbit. يحافظ فريقنا على القوالب محدثة، حتى لا تقلق بشأن التغيرات المسببة للأعطال أو متطلبات الامتثال الجديدة.
- ابقَ مرنًا. إذا أصبح مصدر البيانات شديد الخطورة، فانتقل إلى مصدر آخر أو ابحث عن شراكة.
ومع الأدوات والعقلية المناسبتين، يمكنك إبقاء خط بياناتك متدفقًا—من دون الوقوع في حقول ألغام قانونية.
الخلاصة: التنقل في المشهد القانوني لاستخراج بيانات الويب
استخراج بيانات الويب ليس غير قانوني بطبيعته—بل هو أداة قوية للأعمال والبحث والابتكار. لكن مثل أي أداة، له قواعد. المفتاح هو فهم ما الذي تستخرجه، وكيف تستخرجه، وما الذي ستفعله بالبيانات. احترم القوانين المحلية، والتزم بسياسات المواقع، واستخدم أدوات تركز على الامتثال مثل Thunderbit لإبقاء عملياتك ضمن الحدود السليمة.
لقد عززت أحكام المحاكم في 2024–2026 (Meta v. Bright Data، X Corp v. Bright Data) موقف استخراج البيانات العامة، لكن مخاطر جديدة تظهر حول بيانات تدريب الذكاء الاصطناعي، وادعاءات حقوق النشر، وقانون الذكاء الاصطناعي الأوروبي. وتختلف سياسات المنصات بشكل كبير—فكل من Google وAmazon وLinkedIn وMeta وX يطبق قواعده بطريقة مختلفة—لذا تعرف على المشهد قبل أن تبدأ الاستخراج.
إذا كنت غير متأكد يومًا، فاطلب مشورة قانونية—وخاصةً في المشاريع الكبيرة أو الحساسة. وتذكر: المشهد القانوني يتغير دائمًا، لذا ابقَ مطّلعًا وسريع الاستجابة.
هل تريد معرفة المزيد عن استخراج بيانات الويب، والامتثال، والأتمتة؟ اطلع على مدونة Thunderbit لمزيد من الأدلة، أو جرّب إضافة Thunderbit على Chrome بنفسك.
ابدأ استخراج بيانات الويب المتوافق مع Thunderbit
الأسئلة الشائعة
1. هل استخراج بيانات الويب غير قانوني في كل مكان؟
لا. استخراج بيانات الويب ليس غير قانوني بطبيعته، لكن قانونيته تعتمد على ما تستخرجه، وكيف تستخرجه، وأين أنت. استخراج البيانات العامة غير الشخصية للاستخدام الداخلي مسموح عمومًا في معظم المناطق، لكن استخراج البيانات الشخصية أو المحمية بحقوق النشر، أو مخالفة شروط الموقع، قد يكون غير قانوني (oxylabs.io).
2. هل يجعل robots.txt الاستخراج غير قانوني إذا تجاهلته؟
robots.txt ليس ملزمًا قانونيًا، لكنه أفضل ممارسة احترامه. تجاهله لن يؤدي وحده إلى مقاضاتك، لكنه قد يجعلك تبدو كـ«جهة سيئة» إذا وقع نزاع (promptcloud.com).
3. هل يمكنني استخراج Google أو Amazon أو LinkedIn؟
الأمر معقد. هذه المواقع الثلاثة تحظر الاستخراج في شروط الخدمة، لكن المحاكم قضت بأن شروط الخدمة قد لا تُلزم المستخدمين غير المسجلين دخولًا (انظر Meta v. Bright Data وX Corp v. Bright Data، وكلاهما في 2024). استخراج البيانات المرئية للعامة (مثل أسعار المنتجات، وقوائم الأعمال، والملفات الشخصية العامة) يمكن الدفاع عنه قانونيًا في الولايات المتحدة عمومًا. ومع ذلك، تطبق كل منصة قواعدها بشكل مختلف: Amazon هي الأكثر عدوانية في الإجراءات القانونية (وقد رفعت دعوى ضد Perplexity AI في نوفمبر 2025)؛ LinkedIn تعتمد على الحواجز التقنية وادعاءات العقد؛ وGoogle تستخدم بشكل متزايد إنفاذًا قائمًا على DMCA. استخرج البيانات بمسؤولية دائمًا وتوقع إجراءات مضادة تقنية.
4. هل يمكنني استخراج Facebook أو Instagram؟
بعد Meta v. Bright Data (2024)، أصبح استخراج البيانات العامة من Facebook وInstagram دون تسجيل دخول في وضع قانوني أقوى. وقد قضت المحكمة بأن شروط خدمة Meta لا تنطبق على غير المستخدمين. لكن لا تنشئ حسابات وهمية أبدًا ولا تستخرج بيانات خلف جدران تسجيل الدخول—فذلك يتجاوز الحد.
5. هل يمكنني استخراج X (Twitter)؟
عدلت X شروط الخدمة في 2023 لحظر كل استخراج دون موافقة مكتوبة، ونشرت دفاعات تقنية قوية (Cloudflare Turnstile، وحدود 300 طلب/ساعة، وتقييم سمعة IP). ومع ذلك، فازت Bright Data في المحكمة على أسس مشابهة—فالبيانات العامة المستخرجة دون حساب لا تخضع لشروط خدمة X. تقنيًا، X من أصعب المنصات للاستخراج في 2026.
6. هل من القانوني استخراج البيانات لتدريب نماذج الذكاء الاصطناعي؟
هذا أكبر سؤال مفتوح في 2026. وتشير الدعاوى الكبرى (NYT v. OpenAI، وتسوية Anthropic البالغة 1.5 مليار دولار) إلى مخاطر قانونية كبيرة. ويتطلب قانون الذكاء الاصطناعي الأوروبي الإفصاح عن مصادر بيانات التدريب واحترام خيارات الاستثناء من حقوق النشر. كما أن مشروع قانون AI Accountability for Publishers Act المقترح سيتطلب إذنًا ودفعًا. إذا كنت تستخرج البيانات لتدريب الذكاء الاصطناعي، فاستشر محاميًا قبل المضي قدمًا.
7. ما أكثر طريقة أمانًا لاستخدام أدوات استخراج بيانات الويب مثل Thunderbit؟
التزم باستخراج البيانات العامة، واحترم شروط الموقع، وتجنب المعلومات الشخصية ما لم يكن لديك أساس قانوني، واستخدم البيانات داخليًا. صُمم Thunderbit لمساعدتك على الامتثال عبر استخراج ما يظهر فقط في متصفحك وتحذيرك من المواقع عالية المخاطر (thunderbit.com).
8. هل يمكنني استخراج البيانات للاستخدام التجاري؟
يعتمد الأمر. استخدام البيانات المستخرجة في التحليلات الداخلية أو البحث أكثر أمانًا عمومًا. أما إعادة نشر البيانات المستخرجة أو بيعها—وخاصة إذا كانت محمية بحقوق النشر أو تتضمن بيانات شخصية—فهو أكثر خطورة وقد يتطلب إذنًا أو ترخيصًا.
9. كيف أتابع التغيرات القانونية والتقنية في استخراج بيانات الويب؟
تابع أخبار قانون التقنية، وراقب المواقع المستهدفة لأي تغييرات في شروط الخدمة أو السياسات، واستخدم أدوات مثل Thunderbit التي تحدّث قوالبها وميزات الامتثال بانتظام. أهم ما يجب مراقبته في 2026: إنفاذ قانون الذكاء الاصطناعي الأوروبي (أغسطس)، وقضايا حقوق النشر الجارية المتعلقة بالذكاء الاصطناعي، وقوانين الخصوصية الجديدة في الولايات المتحدة. وعند الشك، استشر مختصًا قانونيًا.
جرّب AI Web Scraper Get Started Free




