

معظم الشروحات الخاصة بـ استخراج eBay باستخدام Python ما بتكملش أكتر من حوالي تلات شهور. أنا عارف كده لأن فريقنا في Thunderbit شاف المطورين بيدوروا في نفس الدايرة: أكواد بتتكسر، وCSS selectors قديمة، ومستودعات GitHub “شغالة” لكن وقفت من غير ما حد ياخد باله من آخر عمليتي redesign في eBay.
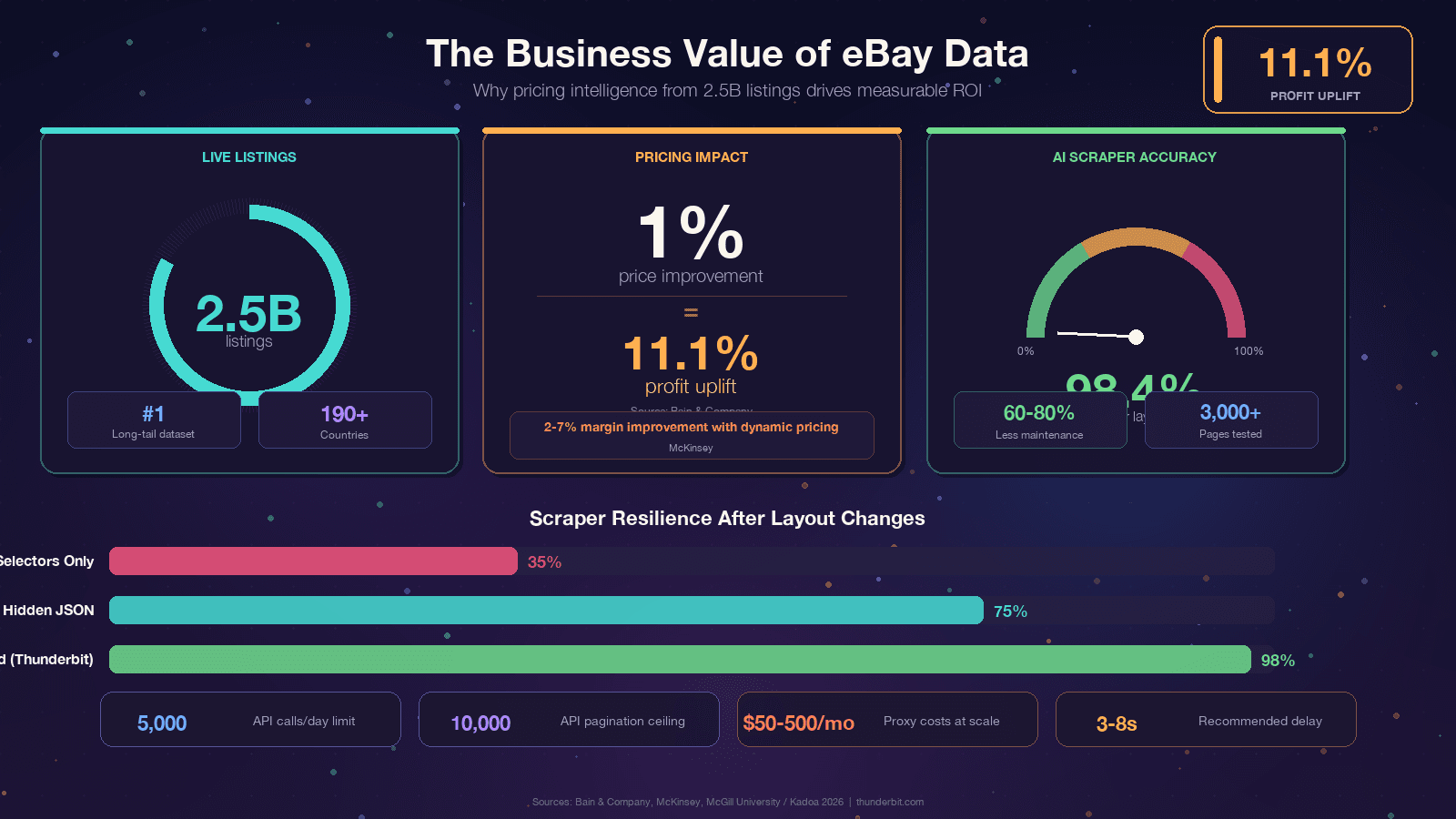
eBay عنده حوالي 2.5 مليار إعلان نشط — وده أكبر مصدر مفتوح لبيانات تسعير المنتجات طويلة الذيل بعد Amazon. البيانات دي بتخدم حاجات كتير: من تسعير البائعين المعيدين للبيع لحد التحليل التنافسي. لكن الوصول ليها برمجيًا هدفه بيتحرك طول الوقت: الواجهة الأمامية المبنية على React في eBay بتغيّر أسماء فئات CSS باستمرار، واختبارات A/B بتعرض هياكل DOM مختلفة لمستخدمين مختلفين، وAkamai Bot Manager واقف ما بينك وبين HTML. الدليل ده هيقدّم لك كود Python شغال النهارده، وهيشرح ليه أدوات الاستخراج بتبوظ وإزاي تبني أدوات أكثر مرونة، وهيقارن بصراحة بين eBay API والاستخراج المباشر، وكمان هيورّيك خيار بلا كود لما Python يبقى مش مستاهل كل الإعداد ده.
ماذا يعني استخراج بيانات eBay باستخدام Python؟
استخراج بيانات eBay باستخدام Python يعني إنك تكتب سكربتات تنزّل صفحات eBay تلقائيًا، وبعد كده تحلل HTML (أو JSON المخفي) وتطلع منه بيانات منظمة — زي العناوين، الأسعار، معلومات البائع، تواريخ البيع، وتفاصيل الخيارات — وتحولها لصيغة تقدر تستخدمها فعلًا، زي CSV أو جدول بيانات أو قاعدة بيانات.
تقدر تستخرج أكتر من نوع من صفحات eBay:
- نتائج البحث (زي كل إعلانات "AirPods Pro")
- صفحات تفاصيل المنتج الفردية (المواصفات الكاملة، الصور، معلومات البائع)
- الإعلانات المباعة/المكتملة (أسعار وتواريخ الصفقات الفعلية)
- ملفات البائعين وتقييماتهم
Python هو الاختيار المفضل للشغل ده. منظومته — Requests وBeautifulSoup وlxml وpandas — بتخلي جلب الصفحات وتحليل HTML وتنضيف البيانات حاجة مباشرة. ومع ذلك، فيه فرق مهم بين استخراج HTML من الموقع واستخدام eBay official API — وده هشرحه بعد شوية.
لماذا نستخدم استخراج بيانات eBay؟ حالات استخدام حقيقية لفرق الأعمال
لو إنت بتقرأ المقال ده، فغالبًا عندك سبب مسبقًا. ومع كده، مفيد جدًا نحط الكلام في إطار قيمة تجارية واضحة، لأن العائد من بيانات eBay كبير فعلًا. Bain لقت إن تحسين 1% في السعر المحقق بيرتبط بزيادة 11.1% في الأرباح عبر آلاف الشركات. وكمان McKinsey بتنسب للتسعير الديناميكي زيادة في المبيعات لحد 5% وتحسن في الهامش بين 2 و7% في قطاع التجزئة.
أشهر حالات الاستخدام اللي بشوفها:
| حالة الاستخدام | البيانات المطلوبة | النتيجة التجارية |
|---|---|---|
| مراقبة الأسعار وإعادة التسعير | أسعار الإعلانات النشطة، الشحن، الحالة | تسعير تنافسي وحماية الهوامش |
| تحليل المنافسين | تشكيلة المنتجات، العروض الترويجية، شروط الشحن | تموضع استراتيجي واكتشاف فجوات التشكيلة |
| أبحاث السوق ورصد الاتجاهات | سرعة إدراج المنتجات، اتجاهات الفئات، أنماط الطلب | تحديد منتجات جديدة والتنبؤ بالطلب |
| تسعير البائعين المعيدين/التقييمات | أسعار البيع، تواريخ البيع، الحالة | تقدير القيمة العادلة واتخاذ قرارات الشراء |
| تحليل المشاعر | التقييمات، النجوم، سياسة الإرجاع | فهم جودة المنتج ورضا العملاء |
| توليد العملاء المحتملين | ملفات البائعين، معلومات المتجر، بيانات الاتصال | التواصل B2B مع بائعين ذوي قيمة إجمالية عالية |
القاسم المشترك هنا: eBay عنده البيانات، لكنها محبوسة جوه صفحات ويب.
والاستخراج هو اللي بيحوّلها لميزة تنافسية.
eBay API الرسمي مقابل استخراج بيانات Python: أيهما تختار؟
ده السؤال اللي نفسي أغلب الشروحات تجاوب عليه بصراحة. eBay بيوفّر APIs رسمية — وعلى رأسها Browse API — وناس كتير بتسأل: أستخدمها ولا أستخرج البيانات مباشرة؟ الإجابة بتعتمد بالكامل على نوع البيانات اللي إنت محتاجها.
| المعيار | eBay Browse/Finding API | استخراج بيانات Python |
|---|---|---|
| الإعلانات المباعة/المكتملة | محدود — فيه Marketplace Insights API لكن الوصول إليها غالبًا مرفوض | وصول كامل عبر معلمات الرابط LH_Sold=1&LH_Complete=1 |
| حدود الطلبات | 5,000 طلب/يوم في الباقة الأساسية | إنت بتديره بنفسك (حسب البروكسي) |
| حقول البيانات | محددة مسبقًا (العنوان، السعر، الفئة، أساسيات البائع) | أي حاجة ظاهرة على الصفحة (التقييمات، المواصفات الكاملة، مصفوفة الخيارات) |
| صعوبة الإعداد | OAuth 2.0، تسجيل التطبيق، مفاتيح API | pip install + كود |
| الثبات | نقاط نهاية مستقرة | بيتكسر لما HTML يتغير |
| التكلفة | فيه باقة مجانية، والمدفوع عند الحاجة لحجم أكبر | الكود مجاني، لكن البروكسي بيكلّف مع التوسع |
| بيانات المتغيرات/MSKU | جزئي — غالبًا SKU الأب فقط | كاملة (عبر تحليل JSON المخفي) |
| عمق الصفحات | سقف صارم 10,000 عنصر | غير محدود نظريًا |
ملاحظة سريعة: واجهة Finding API القديمة (اللي كانت فيها findCompletedItems) اتقفلت نهائيًا في فبراير 2025. لو إنت بتستخدم ebaysdk-python أو أي مكتبة بتستهدف Finding module، فهي دلوقتي بايظة في الإنتاج.
ترشيحي: استخدم Browse API للاستعلامات المستقرة والمتوسطة الحجم عن الإعلانات النشطة. واستخدم استخراج Python لما تحتاج أسعار البيع، أو التقييمات، أو بيانات الخيارات، أو أي حقل مش ظاهر في الـ API. فرق كتير بتستخدم الطريقتين معًا.
الأدوات والمكتبات التي تحتاجها لاستخراج eBay باستخدام Python
قبل ما تكتب أي كود، دي عدة الشغل. إنت مش محتاج متصفح headless لمعظم صفحات eBay — لأن البيانات أصلًا مدمجة في HTML اللي السيرفر بيرسله.
| المكتبة | الغرض |
|---|---|
requests أو httpx | عميل HTTP لتحميل صفحات eBay |
curl_cffi | عميل HTTP ببصمة TLS حقيقية لمتصفح فعلي (مهم لتجاوز Akamai) |
beautifulsoup4 | محلل HTML لاستخراج البيانات عبر selectors |
lxml | محرك تحليل سريع لـ BeautifulSoup |
jmespath | لغة استعلام لتحليل كتل JSON المتداخلة |
pandas | معالجة البيانات وتصدير CSV/Excel |
gspread | التكامل مع Google Sheets |
ثبّت كل حاجة بأمر واحد:
pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspread
استخدم Python 3.11+ — لأن pandas 3.0 بيحتاج 3.10+، وكمان 3.11 بيدي تحسن أداء بين 10 و60% في شغل الإدخال والإخراج.
وفيه مكتبة تستاهل ذكر خاص: curl_cffi هي أهم ترقية scraper ممكن يعملها لـ eBay في 2026. eBay بيستخدم Akamai Bot Manager، وآلية الكشف الأساسية عند Akamai هي بصمة TLS. الطلبات العادية عبر requests بتبعت بصمة JA3 شكلها باين جدًا كإنها Python، فغالبًا بتتمنع فورًا. أما curl_cffi فبتقلّد handshake TLS لمتصفح Chrome حقيقي، وده بيعدّي حوالي 90% من المواقع المحمية بـ Akamai من غير ما تحتاج متصفح headless.
خطوة بخطوة: كيف تستخرج نتائج بحث eBay باستخدام Python
ده هو الدليل الأساسي. هنستخرج صفحات نتائج البحث في eBay الخاصة بالمنتجات.
- المستوى: مبتدئ إلى متوسط
- الوقت المطلوب: حوالي 30 دقيقة لأول عملية استخراج تشتغل بنجاح
- ما تحتاج إليه: Python 3.11+، المكتبات السابقة، الطرفية، ورابط بحث مستهدف في eBay
الخطوة 1: إعداد مشروع Python
اعمل مجلد للمشروع وثبّت الاعتمادات:
mkdir ebay-scraper && cd ebay-scraper
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install requests curl_cffi beautifulsoup4 lxml pandas
اعمل ملف باسم scrape_ebay.py. ده هيكون مكان الشغل.
الخطوة 2: بناء رابط بحث eBay
تركيب رابط البحث في eBay بسيط. المعامل الأساسي هو _nkw (الكلمة المفتاحية):
import urllib.parse
keyword = "airpods pro"
base_url = "https://www.ebay.com/sch/i.html"
params = {
"_nkw": keyword,
"_ipg": "120", # عدد العناصر في الصفحة: 60 أو 120 أو 240 (240 قد يثير تنبيهات البوت)
"_pgn": "1", # رقم الصفحة
}
url = f"{base_url}?{urllib.parse.urlencode(params)}"
print(url)
# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1
معاملات تانية مفيدة:
LH_BIN=1— الشراء الآن فقط_sacat=175673— فئة محددة_sop=12— الفرز حسب أفضل تطابق (10 = الأقل سعرًا مع الشحن، 13 = الأحدث إدراجًا)LH_Complete=1&LH_Sold=1— الإعلانات المباعة/المكتملة (هنغطيها في قسم مستقل تحت)
الخطوة 3: إرسال الطلب والتعامل مع الاستجابة
هنا بيظهر دور curl_cffi. فـ requests.get() العادي غالبًا بيرجع 403 من Akamai. باستخدام curl_cffi، بنقلّد متصفح Chrome حقيقي:
from curl_cffi import requests as cffi_requests
import random, time
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
]
HEADERS = {
"User-Agent": random.choice(USER_AGENTS),
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
}
def fetch_page(url, max_retries=5):
delay = 2
for attempt in range(max_retries):
try:
r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
if r.status_code == 200:
return r.text
if r.status_code in (403, 429, 503):
retry_after = r.headers.get("Retry-After")
sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
print(f" الحالة {r.status_code}، إعادة المحاولة بعد {sleep_for:.1f} ثانية...")
time.sleep(sleep_for)
delay *= 2
continue
r.raise_for_status()
except Exception as e:
print(f" خطأ في الطلب: {e}، إعادة المحاولة...")
time.sleep(delay)
delay *= 2
raise RuntimeError(f"فشل بعد {max_retries} محاولات: {url}")
التراجع الأسي مع إضافة تباين عشوائي مهم — لأن فترات الانتظار الثابتة نفسها بتبقى بصمة بوت.
الخطوة 4: تحليل بطاقات المنتجات من صفحة البحث
eBay حاليًا في نص انتقال بين تخطيطين لنتائج البحث. علشان كده لازم scraper مرن يتعامل مع الاتنين:
| الحقل | التخطيط القديم | التخطيط الجديد |
|---|---|---|
| حاوية البطاقة | li.s-item | li.s-card أو div.su-card-container |
| العنوان | .s-item__title | .s-card__title |
| الرابط | a.s-item__link[href] | a.su-link[href] |
| السعر | span.s-item__price | .s-card__price |
وده كود التحليل اللي بيدعم التخطيطين:
from bs4 import BeautifulSoup
def parse_search_results(html):
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item, li.s-card, div.su-card-container")
results = []
for card in cards:
# العنوان — جرّب التخطيطين
title_el = card.select_one(".s-item__title, .s-card__title")
title = title_el.get_text(strip=True) if title_el else None
# تجاهل بطاقة "Shop on eBay" الوهمية
if not title or "Shop on eBay" in title:
continue
# السعر
price_el = card.select_one("span.s-item__price, .s-card__price")
price = price_el.get_text(strip=True) if price_el else None
# الرابط
link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
url = link_el["href"].split("?")[0] if link_el else None
# الصورة
img_el = card.select_one("img.s-item__image-img, .s-card__image img")
image = None
if img_el:
image = img_el.get("src") or img_el.get("data-src")
# الشحن
ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
shipping = ship_el.get_text(strip=True) if ship_el else None
results.append({
"title": title,
"price": price,
"url": url,
"image": image,
"shipping": shipping,
})
return results
فخ أول بطاقة وهمية هو خطأ شائع جدًا. أول li.s-item في صفحات بحث eBay كتير بيكون عنصر مخفي بعنوان "Shop on eBay" من غير سعر حقيقي. لازم دايمًا تستبعده.
الخطوة 5: التعامل مع الترقيم لاستخراج عدة صفحات
eBay بيستخدم المعامل _pgn لتقسيم الصفحات. ورابط الصفحة التالية بيستخدم a.pagination__next:
import urllib.parse
def scrape_ebay_search(keyword, max_pages=5):
all_results = []
for page_num in range(1, max_pages + 1):
params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"جاري استخراج الصفحة {page_num}: {url}")
html = fetch_page(url)
results = parse_search_results(html)
if not results:
print(f" لا توجد نتائج في الصفحة {page_num}، إيقاف.")
break
all_results.extend(results)
print(f" تم العثور على {len(results)} إعلانًا (الإجمالي: {len(all_results)})")
# تأخير مهذب — من 3 إلى 8 ثوانٍ مع تباين عشوائي
time.sleep(random.uniform(3, 8))
return all_results
التباين العشوائي بين 3 و8 ثوانٍ مش اختياري.
طبقة Akamai الخاصة بـ eBay بتراقب الطلبات المستمرة اللي بتتجاوز 1 طلب/ثانية من نفس عنوان IP.
الخطوة 6: تصدير البيانات إلى CSV أو JSON
import pandas as pd
results = scrape_ebay_search("airpods pro", max_pages=3)
df = pd.DataFrame(results)
df.to_csv("ebay_airpods.csv", index=False)
df.to_json("ebay_airpods.json", orient="records", indent=2)
print(f"تم تصدير {len(df)} إعلانًا إلى CSV وJSON.")
دلوقتي المفروض يكون عندك جدول نظيف لإعلانات eBay. على جهازي، استخراج 3 صفحات (360 إعلانًا) خد حوالي 45 ثانية، بما فيها التأخيرات.
كيف تستخرج صفحات تفاصيل منتجات eBay باستخدام Python
نتائج البحث بتديك ملخص. أما صفحات التفاصيل فبتديك الجزء المفيد: الأوصاف الكاملة، درجات تقييم البائع، مواصفات العنصر، معارض الصور، وبيانات الخيارات.
تحليل صفحة إعلان منتج واحد
صفحات منتجات eBay موجودة تحت المسار /itm/<ITEM_ID>. وأثبت مسار استخراج أكثر ثباتًا هو JSON-LD — لأن eBay بيضم كتلة schema من نوع Product بتصمد قدام أغلب تغييرات CSS:
import json
def parse_item_page(html):
soup = BeautifulSoup(html, "lxml")
item = {}
# 1. JSON-LD — أكثر مسار استخراج ثباتًا
for tag in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(tag.string or "")
except (json.JSONDecodeError, TypeError):
continue
if isinstance(data, dict) and data.get("@type") == "Product":
item["title"] = data.get("name")
item["brand"] = (data.get("brand") or {}).get("name")
item["images"] = data.get("image")
offers = data.get("offers") or {}
item["price"] = offers.get("price")
item["currency"] = offers.get("priceCurrency")
break
# 2. بدائل CSS للحقول غير الموجودة في JSON-LD
def first_text(selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
item.setdefault("title", first_text([
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
]))
item["condition"] = first_text([
".x-item-condition-text .ux-textspans",
])
item["seller"] = first_text([
".x-sellercard-atf__info__about-seller a .ux-textspans",
])
item["shipping"] = first_text([
"div.ux-labels-values--shipping .ux-textspans--BOLD",
])
# 3. مواصفات العنصر
specifics = {}
for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
if k and v:
specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
item["specifics"] = specifics
return item
النمط ده — JSON-LD الأول، وبعده بدائل CSS — هو المفتاح لبناء scrapers ما بتتعطلش كل تلات شهور. هرجع للنقطة دي بعد شوية.
استخراج متغيرات منتج eBay (بيانات MSKU)
بعض إعلانات eBay فيها أكتر من متغير — ألوان مختلفة، أو مقاسات، أو سعات تخزين. الـ DOM الظاهر بيعرض بس نطاق سعري زي "$899 إلى $1,099" لحد ما المستخدم يختار خيار. لكن التسعير الحقيقي لكل متغير موجود جوه كائن JavaScript مخفي اسمه MSKU.
دي واحدة من الحالات اللي فيها الـ API بتاعة eBay محدودة في البيانات (SKU الأب بس)، وده بيخلي الاستخراج المباشر أفضل.
import re, json
def extract_variants(html):
# المطابقة غير الجشعة مهمة جدًا — لأن .+ الجشعة بتبلع الصفحة كلها
m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
if not m:
return []
try:
msku = json.loads(m.group(1))
except json.JSONDecodeError:
return []
item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
skus = []
for combo_key, variation_id in msku.get("variationCombinations", {}).items():
option_ids = combo_key.split("_")
options = [item_labels.get(oid, oid) for oid in option_ids]
var = msku.get("variationsMap", {}).get(str(variation_id), {})
bin_model = var.get("binModel", {})
price_spans = bin_model.get("price", {}).get("textSpans", [{}])
price = price_spans[0].get("text") if price_spans else None
qty = var.get("quantity")
skus.append({
"options": options,
"price": price,
"quantity_available": qty,
"variation_id": variation_id,
})
return skus
التعبير النمطي (.+?) غير الجشع هنا هو المكان اللي أغلب scrapers بتاعة eBay بتغلط فيه. أما .+ الجشع فبيبلع كل حاجة لحد آخر "QUANTITY" في الصفحة، وده بيطلع JSON بايظ. شفت الخطأ ده في تلات شروحات على الأقل بتدّعي إنها “شغالة”.
كيف تستخرج الإعلانات المباعة والمكتملة في eBay باستخدام Python
دي حالة الاستخدام اللي فعلًا بتوضح الفرق بين الاستخراج وواجهة الـ API. بيانات العناصر المباعة — إيه اللي اتباع فعلًا، وبكام، وفي أي تاريخ — هي المعيار الذهبي لأبحاث السوق وتسعير البائعين والتقييمات. Browse API بتاعة eBay ما بتوفّرش ده بشكل صريح. أما Marketplace Insights API فبتوفره نظريًا، لكن الوصول ليها “محدود” وغالبًا بيرفضوه.
معاملات الرابط اللي هتحتاجها هي LH_Complete=1 (الإعلانات المكتملة) وLH_Sold=1 (حصر النتائج في المباعة فعلًا). لازم تستخدمهم معًا. استخدام LH_Sold=1 لوحده بيرجع بصمت الإعلانات النشطة في بعض الفئات — وده أشهر خطأ في المجتمع.
def scrape_sold_listings(keyword, max_pages=3):
all_sold = []
for page_num in range(1, max_pages + 1):
params = {
"_nkw": keyword,
"_ipg": "120",
"_pgn": str(page_num),
"LH_Complete": "1",
"LH_Sold": "1",
}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"جاري استخراج صفحة المبيعات {page_num}...")
html = fetch_page(url)
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item")
for card in cards:
title_el = card.select_one(".s-item__title")
title = title_el.get_text(strip=True) if title_el else None
if not title or "Shop on eBay" in title:
continue
# تضمين العناصر المباعة فعلًا فقط (السعر الأخضر داخل POSITIVE)
sold_tag = card.select_one(
".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
)
if sold_tag is None:
continue # إعلان مكتمل لكنه لم يُبع — تجاهله
price_el = card.select_one("span.s-item__price")
price = price_el.get_text(strip=True) if price_el else None
# تحليل تاريخ البيع
sold_date = None
import re, datetime as dt
card_text = card.get_text()
m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
if m:
sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
link_el = card.select_one("a.s-item__link[href]")
url = link_el["href"].split("?")[0] if link_el else None
all_sold.append({
"title": title,
"sold_price": price,
"sold_date": sold_date,
"url": url,
})
if not cards:
break
time.sleep(random.uniform(3, 8))
return all_sold
الفرق الأساسي في HTML: العناصر المباعة بيتعرض سعرها باللون الأخضر (جوه غلاف .POSITIVE)، بينما العناصر المكتملة غير المباعة بيتعرض سعرها باللون الأحمر مع شطب. لازم دايمًا تعمل فلترة على أساس .POSITIVE.
لماذا تتعطل أدوات استخراج eBay؟ وكيف تبني أدوات أكثر مرونة
لو scraper eBay بتاعك وقف، إنت مش لوحدك. دي أول مشكلة بتظهر في كل موضوع تقريبًا عن استخراج eBay. السؤال مش هل scraper هيتكسر، السؤال إمتى.
ليه ده بيحصل:
- eBay بيستخدم React مع أسماء فئات بتتولد ديناميكيًا وبتتغير مع كل نشر جديد
- اختبارات A/B بتعرض هياكل DOM مختلفة لمستخدمين مختلفين (وتخطيط
s-item/s-cardالمزدوج مثال حي دلوقتي) - عمليات redesign الدورية بتغيّر تداخل HTML حتى لو البيانات نفسها ما اتغيرتش
- المحددات القديمة زي
#itemTitleو#prcIsumاتشالت من سنين، لكن لسه بتظهر في الشروحات
وكما بيقول دليل Scrapfly لعام 2026: “التحدي الحقيقي مع استخراج eBay هو التعامل مع تغييرات محددات CSS في eBay. الواجهة الأمامية بتتحدث بانتظام، وده بيكسر أدوات الاستخراج اللي معتمدة على أسماء فئات محددة.”
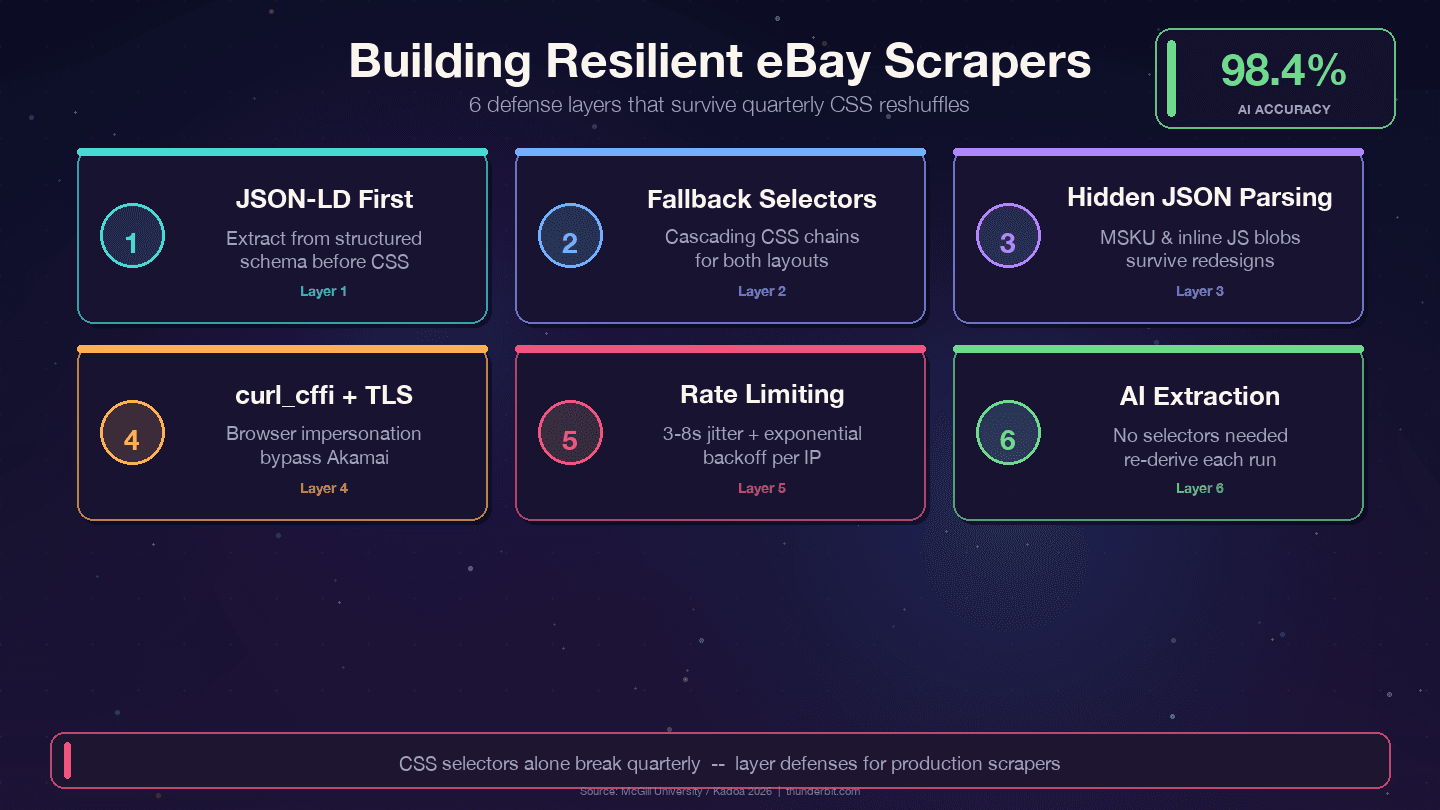
استراتيجيات دفاع لبناء scrapers تدوم طويلًا على eBay
أربع استراتيجيات بتصمد قدام تغييرات eBay الفصلية:
1. خلّي الأولوية لـ JSON-LD بدل CSS selectors. eBay بيضم بيانات schema من نوع Product في كل صفحة منتج. طبقة البيانات بتتغير أقل بكتير من طبقة العرض — المصممين بيغيروا CSS classes كل ربع سنة، لكن أسماء الحقول الخلفية زي price وname وseller مرتبطة بواجهات داخلية ونادرًا ما بتتغير.
2. استخدم selectors بديلة متسلسلة. ما تعتمدش أبدًا على selector واحد بس. لازم يكون عندك بدائل دايمًا:
def first_text(soup, selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
title = first_text(soup, [
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
"[data-testid='x-item-title'] h1",
])
3. حلّل كتل JSON المخفية. كائن MSKU الخاص بالمتغيرات وبيانات JavaScript المضمّنة بتصمد قدام CSS changes لأنها بتتولد من السيرفر. استخراجها بـ regex من <script> بيحتاج مجهود أكتر في البداية، لكنه بيقلل الصيانة جدًا.
4. سجّل فشل الـ selectors. ضيف monitoring عشان تعرف إمتى selector بطل يطابق، بدل ما تكتشف متأخر إن البيانات بقت فاضية:
if title is None:
print(f"WARNING: title selector failed for {url}")
5. استخدم curl_cffi مع انتحال المتصفح. ده بيعالج TLS fingerprint الخاص بـ Akamai من غير ما تحتاج متصفح headless.
البديل المدعوم بالذكاء الاصطناعي: من غير صيانة selectors
لو زهقت من إصلاح الـ selectors كل كام شهر، فيه أسلوب مختلف تمامًا. أدوات زي Thunderbit بتستخدم الذكاء الاصطناعي عشان تقرأ الصفحة من جديد كل مرة وتستنتج منطق الاستخراج ديناميكيًا. دراسة في جامعة McGill اختبرت أدوات استخراج معتمدة على الذكاء الاصطناعي مقابل الأدوات المعتمدة على الـ selectors عبر 3,000 صفحة، ووجدت إن طرق الذكاء الاصطناعي حافظت على دقة 98.4% حتى بعد تغيّر التخطيط، مع ذكر معايير صناعية لـ خفض الصيانة بنسبة 60–80%.
| النهج | هل يتعطل عند تغيّر HTML في eBay؟ | جهد الصيانة |
|---|---|---|
| محددات CSS ثابتة | نعم، كل ربع سنة | مرتفع — ترقيعات مستمرة |
| استخراج JSON المخفي / JSON-LD | نادرًا | منخفض |
| استخراج بالذكاء الاصطناعي (Thunderbit) | لا — الذكاء الاصطناعي يعيد استنتاج المحددات في كل تشغيل | لا شيء |
استخرج بيانات eBay بالذكاء الاصطناعي Get Started Free
هشرح سير عمل Thunderbit بالتفصيل بعد شوية. لكن الخلاصة دلوقتي: لو إنت بتبني scraper ناوي يشغّل لشهور، استثمر في استخراج قائم على JSON الأول، وبعده selectors احتياطية. ولو مش عايز صيانة selectors أصلًا، فالنهج المعتمد على الذكاء الاصطناعي يستاهل التجربة.
أتمتة عمليات الاستخراج المتكررة من eBay لمراقبة الأسعار
الاستخراج مرة واحدة مفيد. لكن مراقبة الأسعار وتتبع المخزون وتحليل المنافسين محتاجين جمع بيانات بشكل متكرر. كل مقال منافس قرأته بيذكر مراقبة الأسعار كحالة استخدام، لكن قليل جدًا بيشرح الأتمتة فعلًا.
الخيار 1: Cron Jobs (Linux/macOS) أو Task Scheduler (Windows)
أبسط طريقة. لفّ سكربت Python داخل cron job. دايمًا استخدم المسار الكامل لـ Python جوه البيئة الافتراضية — لأن cron بيشتغل ببيئة محدودة:
crontab -e
# يوميًا عند 08:15
15 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1
في Windows، استخدم PowerShell:
$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
$T = New-ScheduledTaskTrigger -Daily -At 8:15am
Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $T
ده محتاج جهاز شغال طول الوقت، وكمان إنت اللي بتدير البروكسي وحماية مكافحة البوت بنفسك.
الخيار 2: وظائف سحابية (Serverless)
AWS Lambda أو Google Cloud Functions بيدّوك تشغيل scrapers من غير خادم مخصص. لكن الإعداد أصعب — لازم تحزم الاعتمادات، وتتعامل مع مهلات التنفيذ (Lambda بتقف عند 15 دقيقة)، وتدير البروكسي برضه. بس في المقابل مش هتحتاج تدير سيرفر.
الخيار 3: جدولة بلا كود مع Thunderbit
ميزة Thunderbit المسماة Scheduled Scraper بتخليك توصف التكرار بلغة طبيعية (زي: "كل يوم الساعة 8 صباحًا")، وبعدها تدخل روابط eBay وتضغط Schedule. بيشتغل في السحابة مع معالجة مدمجة لمكافحة البوت.
| النهج | جهد الإعداد | هل يحتاج خادمًا؟ | هل يتعامل مع مكافحة البوت؟ |
|---|---|---|---|
| Cron + سكربت Python | متوسط | نعم (جهاز دائم التشغيل) | أنت تدير البروكسي |
| وظيفة سحابية (Lambda) | مرتفع | لا (Serverless) | أنت تدير البروكسي |
| Thunderbit Scheduled Scraper | منخفض (صفه بالكلمات) | لا (سحابي) | مدمج |
لتخزين بيانات الاستخراج المتكرر، قاعدة SQLite محلية هي الحل المناسب لتاريخ الأسعار. استخدم ON CONFLICT ... DO UPDATE (مش INSERT OR REPLACE، لأنه بيكسر المفاتيح الخارجية ويمسح الأعمدة):
CREATE TABLE IF NOT EXISTS listings (
item_id TEXT PRIMARY KEY,
title TEXT NOT NULL,
price REAL,
last_price REAL,
first_seen_at TEXT DEFAULT (datetime('now')),
last_seen_at TEXT DEFAULT (datetime('now'))
);
CREATE TABLE IF NOT EXISTS price_history (
item_id TEXT NOT NULL,
observed_at TEXT NOT NULL DEFAULT (datetime('now')),
price REAL NOT NULL,
PRIMARY KEY (item_id, observed_at)
);
جرّب Thunderbit Scheduled Scraper
لا تريد البرمجة؟ كيف تستخرج eBay في دقيقتين مع Thunderbit
أنا قضيت 2,000 كلمة على كود Python. والآن لازم أكون صريح في الحالات اللي إنت مش محتاج فيها ده.
لو إنت مستخدم تجاري بتعمل بحث سوقي لمرة واحدة، أو بائع بيعاين مبيعات مشابهة، أو فريق تجارة إلكترونية محتاج البيانات النهارده من غير Sprint تطوير، فـ Python هيبقى زيادة عن اللزوم. الإعداد، وصيانة selectors، وإدارة البروكسي — كل ده عبء كبير جدًا عشان “أنا محتاج الـ 200 إعلان دول في جدول بيانات”.
كيف يستخرج Thunderbit بيانات eBay (خطوة بخطوة)
- ثبّت Thunderbit Chrome Extension — من غير بطاقة ائتمان.
- افتح أي صفحة نتائج بحث أو صفحة منتج على eBay في Chrome.
- اضغط "AI Suggest Fields" في الشريط الجانبي لـ Thunderbit. الذكاء الاصطناعي بيقرأ الصفحة وبيقترح الأعمدة: العنوان، السعر، الحالة، الشحن، البائع، التقييم.
- اضغط "Scrape." الإضافة بتتنقل عبر الصفحات وبتملأ جدول البيانات. وبالنسبة لـ eBay تحديدًا، Thunderbit عنده قوالب استخراج جاهزة بتشتغل بنقرة واحدة.
- صدّر إلى Google Sheets أو Airtable أو Notion أو CSV أو JSON أو Excel — مجانًا.
العملية كلها بتاخد أقل من دقيقتين.
وجربتها بنفسي.
إثراء الصفحات الفرعية: احصل على بيانات صفحة التفاصيل دون كود إضافي
بعد ما تستخرج صفحة نتائج البحث، Thunderbit يقدر يزور صفحة التفاصيل لكل إعلان ويضيف حقول إضافية — المواصفات الكاملة، معلومات البائع، الوصف، وكل الصور. ده بيستبدل أكتر من 20 سطر من كود Python لاستخراج الصفحات الفرعية كتبناه فوق بنقرة واحدة بس.
متى يظل Python هو الأفضل؟
Python بيتفوق لما تحتاج إلى:
- استخراج على نطاق كبير (عشرات الآلاف من الصفحات في التشغيل الواحد)
- منطق تحليل مخصص جدًا أو تحويل بيانات متقدم
- الدمج في خطوط بيانات موجودة (Airflow، dbt، Kafka)
- تحكم دقيق في TLS/الجلسات لشغل مكافحة بوت متقدم
- اقتصاديات الوحدة — عند ملايين الصفوف، غالبًا البنية المُدارة بتتفوق على SaaS القائم على الرصيد
في أغلب المشاريع الفردية أو متوسطة الحجم، Thunderbit أسرع وأسهل. أما لخطوط الإنتاج على نطاق واسع، Python بيديّك تحكم كامل.
نصائح لتجنب الحظر عند استخراج eBay باستخدام Python
طبقة Akamai في eBay حقيقية. وده اللي بيشتغل فعليًا:
- استخدم
curl_cffiمعimpersonate="chrome124"— دي أكبر قفزة مقارنةً بـrequestsالعادي - دوّر User-Agent من قائمة بإصدارات متصفح حديثة (Chrome 143 وFirefox 124 وSafari 26)
- أضف تأخيرات عشوائية بين 3 و8 ثوانٍ بين الطلبات — الفواصل الثابتة بصمة سهلة الرصد
- استخدم بروكسي سكنية أو دوّارة لأي حاجة تتجاوز بضع عشرات من الصفحات. عناوين IP الخاصة بمراكز البيانات (AWS وGCP وDigitalOcean) Akamai بتكتشفها بسرعة.
- احترم
robots.txt— أغلب روابط التصفح المفلترة محظورة صراحةً؛ أما صفحات تفاصيل العناصر (/itm/<id>) فمش كذلك - تعامل مع CAPTCHA بسلاسة — اكتشفها وجرّب تاني بعنوان IP مختلف، أو استخدم خدمة حل CAPTCHA
- ما ترهقش السيرفر. سوابق eBay ضد Bidder's Edge بتشير إن التعدي على المنقولات بينطبق لما الاستخراج يضعف الخوادم فعلًا. البقاء عند 1 طلب/ثانية لكل IP بيخليك بعيد جدًا عن الخط ده.
للاستخدام التجاري عالي الحجم، فكّر تستخدم Browse API للإعلانات النشطة والاستخراج المستهدف فقط للمبيعات المقارنة والبيانات اللي الـ API ما بتعرضهاش. ده نهج هجين أنظف تقنيًا وقانونيًا كمان.
هل استخراج eBay باستخدام Python قانوني؟
أنا مش محامي، والمقال ده مش نصيحة قانونية. فهختصر.
المشهد القانوني مال لصالح استخراج البيانات المتاحة للجمهور. السوابق الأهم:
- hiQ v. LinkedIn (الدائرة التاسعة، 2022): استخراج البيانات المتاحة علنًا لا ينتهك CFAA
- Van Buren v. United States (المحكمة العليا الأمريكية، 2021): ضيّق نطاق بند "تجاوز الوصول المصرح به" في CFAA
- Meta v. Bright Data (المحكمة الفدرالية في كاليفورنيا الشمالية، 2024): استخراج البيانات أثناء تسجيل الخروج لا يخرق شروط استخدام المنصة لأن الأداة مش "مستخدم"
مع ذلك، تحديث اتفاقية مستخدم eBay في فبراير 2026 بيحظر صراحةً "وكلاء الشراء، أو البوتات المعتمدة على LLM، أو أي تدفق end-to-end يحاول إتمام الطلبات من غير مراجعة بشرية." الرسالة واضحة: الاستخراج للقراءة فقط من الصفحات العامة في موقف قانوني أقوى؛ أما أتمتة الدفع فمش كذلك.
أفضل الممارسات: استخرج فقط البيانات الظاهرة علنًا. ما تعملش حسابات وهمية وما تتخطّاش جدران تسجيل الدخول. ما تعيدش بيع صور القوائم المحمية بحقوق الطبع والنشر بالجملة. واستشر مستشارًا قانونيًا في المشاريع التجارية واسعة النطاق.
الخلاصة وأهم النقاط
Python هو أكتر الطرق مرونة لـ استخراج eBay، لكنه محتاج صيانة مستمرة مع تغيّر HTML في الموقع. إطار القرار:
- استخدم eBay Browse API للاستعلامات المستقرة والمتوسطة الحجم عن الإعلانات النشطة
- استخدم استخراج Python للإعلانات المباعة والتقييمات وبيانات المتغيرات وأي حاجة الـ API ما بتعرضهاش
- استخدم Thunderbit لو عايز بيانات eBay من غير كتابة أو صيانة كود
الكود في الدليل ده بيركّز على المرونة: استخراج JSON-LD الأول، ثم بدائل CSS متسلسلة، ثم تحليل JSON المخفي للمتغيرات. الأسلوب الطبقي ده معناه إن scraper بتاعك مش هيموت أول ما فريق الواجهة الأمامية في eBay يطلق تصميم جديد.
لو عايز تجرب المسار بلا كود، فإن الباقة المجانية من Thunderbit تتيح لك تختبره على صفحات eBay دلوقتي. ولو عايز تشوف إزاي قالب eBay scraper بيشتغل، فهو على بعد ضغطة واحدة.
لمزيد من المعلومات حول أدوات استخراج الويب، راجع أدلتنا عن أفضل أدوات استخراج الويب المؤتمتة، استخراج البيانات من المواقع إلى Excel، وأفضل أدوات استخراج الويب باستخدام Python. تقدر كمان تشوف الدروس على قناة Thunderbit على YouTube.
جرّب Thunderbit لاستخراج eBay Get Started Free
الأسئلة الشائعة
1. هل يمكنني استخراج eBay مجانًا باستخدام Python؟
أيوه. كل المكتبات (Requests وBeautifulSoup وcurl_cffi وpandas) مجانية ومفتوحة المصدر. التكاليف بتظهر مع التوسع — فالبروكسي السكنية للاستخراج عالي الحجم بتكلف عادةً 50–500 دولار شهريًا حسب حجم البيانات. أما المشاريع الصغيرة (بضع مئات من الصفحات) فممكن تتعمل من عنوان IP المنزلي مع ضبط معدل الطلبات بعناية.
2. كيف أستخرج العناصر المباعة والإعلانات المكتملة من eBay باستخدام Python؟
ضيف LH_Complete=1&LH_Sold=1 إلى معاملات رابط البحث. لازم تستخدمهم معًا — لأن LH_Sold=1 لوحده بيرجع بصمت الإعلانات النشطة في بعض الفئات. بعد كده صفّي النتائج بالتحقق من فئة CSS .POSITIVE على عنصر السعر، لأنها بتشير إلى عملية بيع فعلية مش إعلان مكتمل غير مباع.
3. هل يحظر eBay استخراج البيانات؟
eBay بيستخدم Akamai Bot Manager، اللي بيكتشف أدوات الاستخراج أساسًا عبر TLS fingerprint والتحليل السلوكي. طلبات requests العادية غالبًا بترجع 403. استخدام curl_cffi مع انتحال المتصفح، وتدوير User-Agent، وإضافة تأخيرات عشوائية بين 3 و8 ثوانٍ بين الطلبات بيشتغل مع أغلب حالات الحظر. والبروكسي السكنية بتساعد لما تكبر.
4. هل يجب أن أستخدم eBay API أم استخراج البيانات؟
استخدم Browse API للاستعلامات المستقرة ومتوسطة الحجم عن الإعلانات النشطة (حتى 5,000 طلب/يوم). واستخدم الاستخراج لما تحتاج سجل أسعار البيع، أو بيانات المتغيرات/MSKU الكاملة، أو التقييمات، أو أي حقل الـ API ما بتعرضوش. وواجهة Marketplace Insights API بتوفر بيانات المبيعات نظريًا، لكنها محدودة الوصول وغالبًا بيرفضوها.
5. ما أسهل طريقة لاستخراج eBay بدون برمجة؟
يعتمد ملحق Thunderbit Chrome على الذكاء الاصطناعي لقراءة صفحات eBay، واقتراح أعمدة البيانات، واستخراج الإعلانات بنقرة واحدة. وكمان بيتعامل مع الترقيم، وإثراء الصفحات الفرعية، والتصدير إلى Google Sheets أو Excel أو Airtable أو Notion. وقوالب eBay scraper الجاهزة بتسرّع الحالات الشائعة أكتر.
اعرف المزيد
- دليل شامل لبناء Web Scraper بـ Python: مثال خطوة بخطوة
- دليل Python لاستخراج بيانات الويب: سحب البيانات من موقع إلكتروني
- كيفية استخدام BeautifulSoup: درس Python لاستخراج بيانات الويب
- دليل Python لاستخراج بيانات الويب: كيفية استخراج موقع إلكتروني
- كيفية كتابة Web Scraper باستخدام Python: من البداية إلى النهاية




