
بعض الناس يجمعون الطوابع، وغيرهم يجمعون السنيكرز. لكن إذا كنت شغال مبيعات أو تسويق أو تجارة إلكترونية أو عمليات في 2025، فغالبًا أنت تجمع شيء أكثر “디지털” من كذا: استخراج بيانات الويب. ومو بس شوية بيانات—اليوم الشركات تصرف بالمعدل 5 ملايين دولار سنويًا على جمع بيانات الويب، وصار استخراج البيانات من المواقع أداة “ستاندرد” تستخدمها فرق كثيرة من الاستراتيجية إلى خدمة العملاء ().
ومع انفجار الطلب، فيه اسمين يطلعون لك في كل 튜토리얼 عن استخراج البيانات بـ Python وفي مشاريع بيانات البزنس: playwright وselenium. الاثنين بدأوا كأدوات أتمتة متصفح للاختبار، لكن اليوم صاروا فريموركات أساسية لأي شخص يبغى يحوّل الويب لبيانات مرتبة وقابلة للاستخدام. الزبدة: الاختيار بينهم مو قرار “تقني” بس—هو قرار أداة تناسب احتياجك الواقعي في استخراج البيانات. وإذا أنت مو مطوّر، أو تبغى نتيجة بسرعة، فيه طريق أسهل بكثير (تلميح: ما يحتاج تكتب ولا سطر Python). يلا نبدأ.
من أدوات اختبار إلى منصات قوية لاستخراج بيانات الويب: شرح Playwright وSelenium
خلّنا نرتّب المشهد. selenium موجود من 2004، وهو “الخيار المضمون” في أتمتة المتصفح. انبنى أساسًا لمختبري الجودة (QA)، ويخليك تتحكم بمتصفحات مثل Chrome وFirefox وحتى Internet Explorer (للي يحبون المغامرة). أما playwright فطلع بقوة في 2020 بدعم من Microsoft، وبفلسفة أحدث لأتمتة المتصفح—تقدر تعتبره الأخ الأصغر والأسرع لـ selenium.
الأداتين يخلّونك تكتب سكربتات (غالبًا بـ Python) تفتح المتصفح، تروح لموقع، تضغط أزرار، تعبي فورمات، والأهم بالنسبة لنا: تستخرج البيانات. ورغم إن جذورهم في الاختبارات الآلية، صاروا اليوم العمود الفقري لاستخراج بيانات الويب في استخدامات مثل مراقبة الأسعار وتوليد العملاء المحتملين (). ومو بس المطورين: حتى ناس البزنس صاروا يحاولون يبنون أدوات استخراج خاصة فيهم—أو على الأقل يحاولون.
بس لما تدخل عالم استخراج البيانات، الأولويات تتبدّل. “تغطية الاختبارات” تصير أقل أهمية، ويصير الأهم: تطلع البيانات بثبات، تتفادى الحظر، وما تضيع الويكند تلاحق أخطاء Python. وهنا تبدأ الفروقات الحقيقية بين playwright و selenium.
الفروقات الأساسية: Playwright مقابل Selenium لاستخراج بيانات الويب

خلّها واضحة: playwright و selenium الاثنين يقدرون يسوون استخراج بيانات الويب، لكن كل واحد يلمع في سيناريوهات مختلفة.
- selenium هو المخضرم: يشتغل مع متصفحات ولغات كثيرة، مجتمعه ضخم، ومناسب لاستخراج البيانات من المواقع القديمة أو الثابتة اللي بنيتها متوقعة.
- playwright هو الجيل الجديد بميزات “مودرن”: معمول لمواقع اليوم الثقيلة بـ JavaScript، ومعاه أدوات مدمجة للتعامل مع تسجيل الدخول، والنوافذ المنبثقة، والتمرير اللانهائي وغيرها. وفوق هذا غالبًا أسرع وأسهل في الإعداد، خصوصًا لمستخدمي Python.
بدل ما نعتمد على الانطباعات، خلّنا نقارن ميزة بميزة.
جدول مقارنة الميزات: Playwright مقابل Selenium
| الميزة | Selenium | Playwright |
|---|---|---|
| دعم اللغات | Python وJava وC# وJS وRuby وغيرها | Python وJS/TS وJava وC# |
| دعم المتصفحات | Chrome وFirefox وEdge وSafari وIE وOpera | Chromium (Chrome/Edge) وFirefox وWebKit |
| تعقيد الإعداد | يحتاج Driver للمتصفح وإعدادًا يدويًا | أمر واحد يثبت كل شيء |
| السرعة/الأداء | أبطأ ويستهلك موارد أكثر | أسرع بنسبة 40–50%، ومصمم للعمل غير المتزامن/المتوازي |
| التعامل مع المحتوى الديناميكي | انتظار يدوي وكود أكثر | انتظار تلقائي ويتعامل بسهولة مع مواقع JS الثقيلة |
| تجاوز أنظمة مكافحة البوت | أسهل في الاكتشاف ويحتاج إضافات | ميزات تخفٍ مدمجة ومحاكاة أفضل لسلوك المستخدم |
| أدوات التصحيح (Debugging) | أساسية (Selenium IDE ولقطات شاشة) | Inspector وتسجيل فيديو وتوليد كود |
| دعم المجتمع | ضخم وناضج ودروس كثيرة | ينمو بسرعة، توثيق حديث ومطورون نشطون |
| سير عمل Python Scraper | إعداد أكثر وكود تمهيدي أكثر | أكثر سلاسة وكود أقل وأسهل للمبتدئين |
اختيار الأداة المناسبة: متى تستخدم Playwright أو Selenium لاستخراج بيانات الويب
طيب، أي واحد تختار لمشروعك الجاي؟ هذا ملخص رأيي بعد سنين من بناء أدوات أتمتة ومساعدة فرق تسحب بيانات من “الغرب المتوحش” حق الويب.
- selenium يناسبك إذا:
- الموقع اللي تسحب منه “قديم ستايل”—HTML ثابت، JavaScript قليل، وما فيه نوافذ منبثقة ترفع الضغط.
- تحتاج دعم متصفحات غريبة (أهلًا Internet Explorer) أو تكامل مع أنظمة قديمة.
- تبغى راحة بال من مجتمع ضخم وإجابات ما تخلص على StackOverflow.
- عندك خبرة سابقة مع selenium في مشاريع الاختبار.
- playwright غالبًا هو الأفضل إذا:
- الموقع حديث وديناميكي ومليان JavaScript (زي التجارة الإلكترونية أو السوشيال أو أي شيء يخلي مروحة اللابتوب تصير “터보”).
- تحتاج تسجيل دخول، والتنقل بين تبويبات، والتعامل مع التمرير اللانهائي أو النوافذ المنبثقة.
- تبغى تبدأ بسرعة بإعداد أقل وكود أقل.
- طفشت من كتابة
time.sleep(5)بكل مكان وتبغى الأداة هي اللي تدير التوقيت بدلًا منك.
قاعدة بسيطة: إذا أول تجربة لك مع selenium مليانة لحظات “ليش ما يحمل؟”، غالبًا جاء وقت playwright.
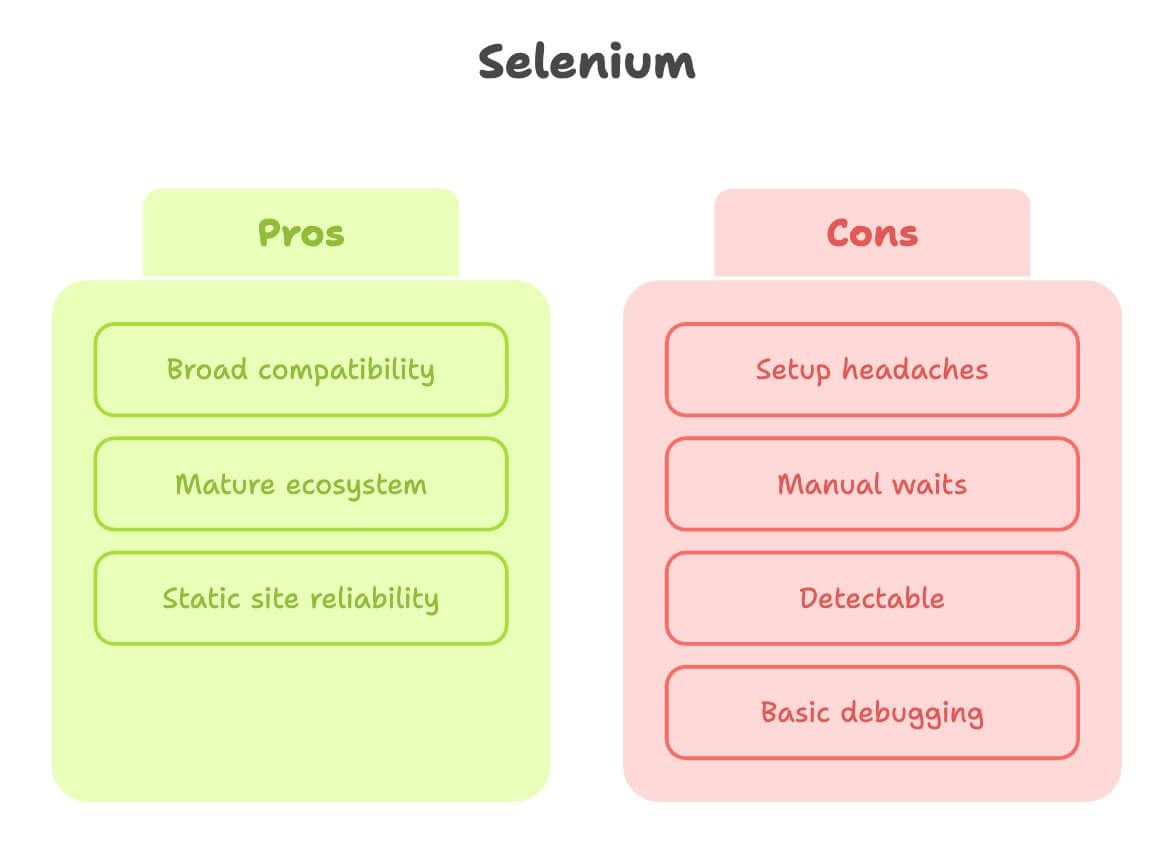
Selenium لاستخراج بيانات الويب: نقاط القوة والقيود
خلّنا نعطي selenium حقه. هو “الجد” في أتمتة المتصفح، وفي كثير من مهام الاستخراج ينجز.
نقاط القوة:
- توافق واسع: يشتغل مع أغلب المتصفحات واللغات.
- منظومة ناضجة: شروحات كثيرة، Q&A، وإضافات.
- ممتاز للمواقع الثابتة: إذا الصفحة ما تتغير كثير، selenium يكون ثابت وموثوق.
القيود:
- وجع رأس في الإعداد: لازم تنزّل Driver للمتصفح (مثل ChromeDriver) وتضبطه وتحدّثه باستمرار. كثير مبتدئين يوقفون هنا ().
- انتظار يدوي: مع المحتوى الديناميكي بتكتب انتظارات صريحة كثير أو—للأسف—أوامر نوم عشوائية.
- أسهل في الاكتشاف: مواقع كثيرة تقدر تميّز متصفح selenium وتحظرك، خصوصًا على سيرفرات سحابية.
- تصحيح محدود: ما فيه تسجيل فيديو مدمج ولا Inspector تفاعلي.
الخلاصة: selenium ممتاز للمواقع البسيطة والمستقرة—بس ممكن يصير متعب جدًا مع صفحات اليوم التفاعلية.
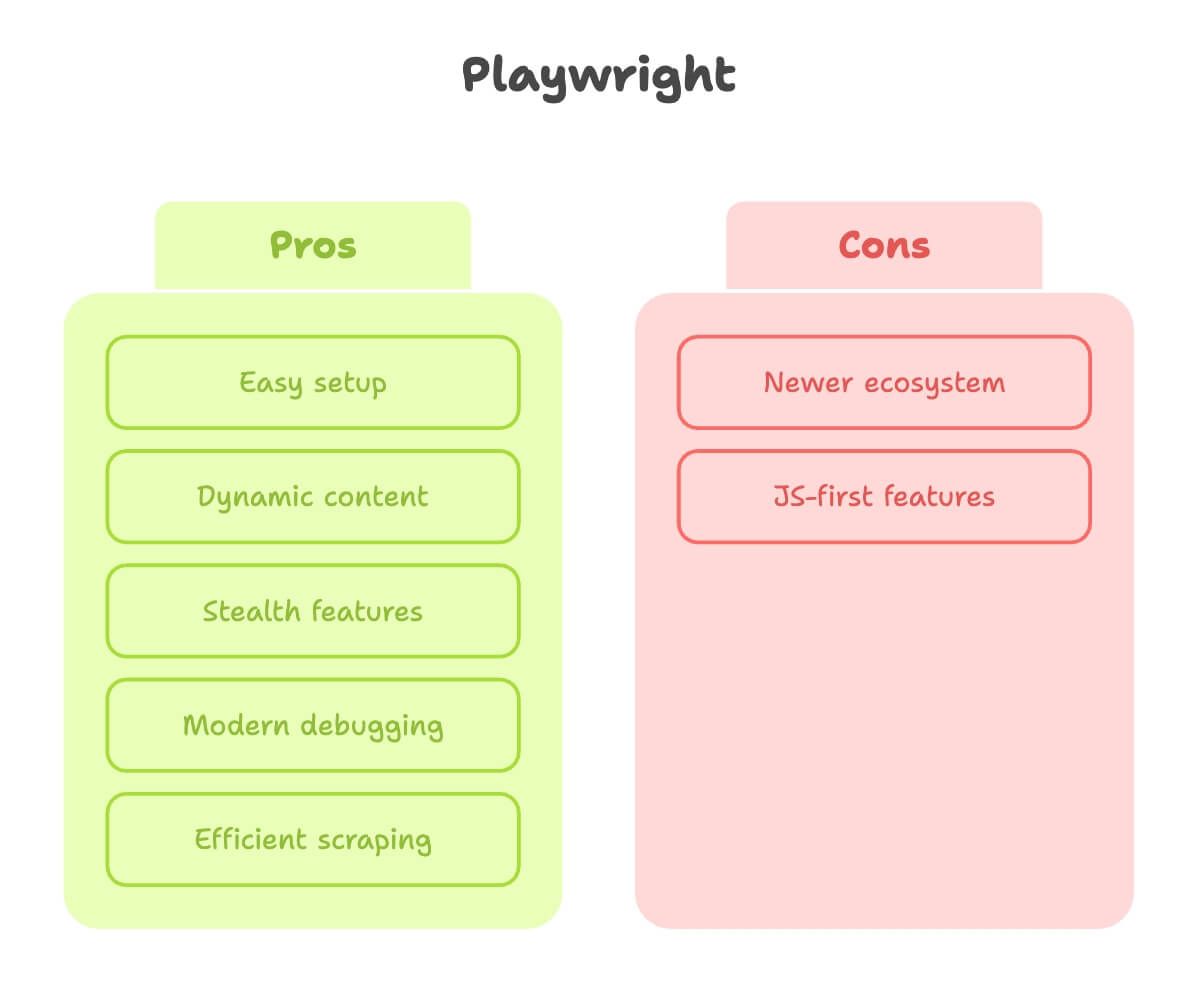
Playwright لاستخراج بيانات الويب: نقاط القوة والقيود
والحين playwright. من تجربة طويلة مع الاثنين، أقدر أقول playwright كأنه معمول من ناس عانوا فعلًا من استخراج بيانات الويب.
نقاط القوة:
- إعداد سهل: تثبيت عبر pip ثم أمر واحد وخلاص. بدون دراما Drivers.
- يتعامل مع المحتوى الديناميكي: ينتظر العناصر تلقائيًا، فما تحتاج تخمّن متى الصفحة صارت جاهزة ().
- ميزات تخفٍ: يحاكي المستخدم الحقيقي بشكل أفضل، مع دعم سياقات متعددة (مفيد لو تبغى تسوي استخراج كأنك عدة “مستخدمين” بنفس الوقت).
- تصحيح حديث: Inspector وتسجيل فيديو وحتى توليد كود من نقراتك.
- أسرع وأكثر كفاءة: خصوصًا مع عدد صفحات كبير أو تشغيل متوازي.
القيود:
- منظومة أحدث: الشروحات أقل شوي، لكن الفجوة قاعدة تقفل بسرعة.
- بعض الميزات موجهة لـ JavaScript أولًا: أغلب الأشياء شغالة في Python، بس أحيانًا تلاقي ميزة مشروحة أفضل في JS.
الزبدة: playwright هو خياري الأول لأي موقع فيه ديناميكية حتى لو بسيطة، أو لما أبغى نتيجة بسرعة بدون صراع إعداد.
تجاوز أنظمة مكافحة البوت: أي Python Scraper يتعامل أفضل مع مواقع اليوم؟
خلّنا نكون صريحين: الحظر. في استخراج بيانات الويب، أصعب جزء مو كتابة الكود—أصعب شيء إن الموقع ما يقفلها بوجهك.
- selenium: افتراضيًا أسهل في الاكتشاف. المواقع تقدر ترصد
webdriverووكيل المستخدم في وضع headless وغيرها. فيه حلول (مثل undetected-chromedriver) بس تحتاج إعداد زيادة وتبقى في سباق مستمر مع أنظمة مكافحة البوت (). - playwright: فيه ميزات تخفٍ مدمجة مثل تقليل بصمات الأتمتة تلقائيًا، ودعم سياقات متعددة، وانتظار تفاعلات أقرب لسلوك المستخدم الحقيقي. مو سحر، لكنه يقلل احتمال الحظر من أول محاولة.
بس الحقيقة: ما فيه أداة “مضادة للحظر 100%”. في الاستخراج عالي المخاطر (زي مواقع إطلاق الأحذية أو التذاكر)، بتحتاج بروكسيات وتدوير IP وربما حل CAPTCHAs. playwright بس يخلي الموضوع أقل ألمًا.
تجربة المطور: الإعداد، منحنى التعلم، والتصحيح
خلّنا نتكلم عن تجربة البداية فعليًا—خصوصًا لو أنت مبتدئ أو تبغى تخلص الشغل بدون “دكتوراه Python”.
- selenium:
- الإعداد: تثبيت Python، ثم selenium، ثم تنزيل Driver المناسب، ثم إضافته إلى PATH، ثم التأكد من توافق الإصدارات. (شفت ناس يتعثرون في خطوة Driver أكثر من تعثرهم في الاستخراج نفسه.)
- منحنى التعلم: مصادر كثيرة، لكن فيها كود قديم وشروحات مو محدثة.
- التصحيح: غالبًا print ولقطات شاشة. فيه Selenium IDE بس محدود.
- playwright:
- الإعداد:
pip install playwrightثمplaywright install. خلصنا. - منحنى التعلم: توثيق حديث وأمثلة كثيرة، وواجهة API “أقرب للبشر”—تقدر تختار العناصر بالنص أو الدور أو حتى placeholder.
- التصحيح: Inspector يخليك تمشي خطوة بخطوة وتشوف المتصفح وتسجيل فيديو لعمليات الاستخراج ().
- الإعداد:
إذا هدفك تشوف نتائج بسرعة وتقلل وقت الإعداد وحل المشاكل، فـ playwright متفوق بوضوح. أما selenium ممتاز إذا أنت متعود على “مزاجه” أو تحتاج توافقه الواسع.
خطوة بخطوة: بناء أول Python Web Scraper باستخدام Playwright أو Selenium
خلّنا نشوف كيف شكل العملية عمليًا مع كل أداة—بدون كود، بس خطوات.
Playwright (Python):
- تثبيت Playwright والمتصفحات:
pip install playwright+playwright install - تشغيل المتصفح: تشغيل Chromium أو Firefox أو WebKit (مخفي headless أو مرئي).
- الانتقال للصفحة: استخدام
page.goto("<https://example.com>") - انتظار المحتوى: Playwright ينتظر العناصر تلقائيًا.
- استخراج البيانات: استخدام محددات سهلة (مثل
get_by_textوlocator("span.price")). - التعامل مع الصفحات المتعددة أو الصفحات الفرعية: التكرار عبر الصفحات أو النقر على الروابط—ويسهل تشغيل عدة صفحات بالتوازي.
- تصدير البيانات: حفظها في CSV أو Excel أو قاعدة بيانات.
- التصحيح: استخدام Inspector أو تسجيل الفيديو عند حدوث مشكلة.
Selenium (Python):
- تثبيت Selenium:
pip install selenium - تنزيل Driver للمتصفح: (مثل ChromeDriver لـ Chrome) ووضعه في PATH.
- تشغيل المتصفح: تشغيل Chrome أو Firefox أو غيره.
- الانتقال للصفحة:
driver.get("<https://example.com>") - انتظار المحتوى: إضافة انتظارات صريحة (
WebDriverWait) أو—إن كنت محظوظًا—time.sleep. - استخراج البيانات: استخدام
find_elementأوfind_elements(محددات CSS/XPath). - التعامل مع الصفحات المتعددة أو الصفحات الفرعية: التكرار عبر الروابط أو النقر على الأزرار، مع إدارة التوقيت والتنقل يدويًا.
- تصدير البيانات: حفظها في CSV أو Excel أو قاعدة بيانات.
- التصحيح: غالبًا يدوي—مراقبة المتصفح، طباعة HTML، أو التقاط لقطات شاشة.
شايف الفرق؟ playwright أقرب لفكرة “설치하고 바로” مع مواقع اليوم.
ما بعد البرمجة: استخراج بيانات الويب بدون كود مع Thunderbit AI Web Scraper
خلّنا نكون واقعيين: مو كل أحد يبغى يصير خبير Python عشان يطلع جدول أسعار منتجات أو لستة عملاء محتملين. يمكن أنت في المبيعات أو التسويق أو العقار أو العمليات، وتبغى البيانات—الحين. هنا يجي دور .
بصفتي الشريك المؤسس لـ Thunderbit، شفت عن قرب قد إيش مستخدمي البزنس يبغون يتجاوزون البرمجة ويروحون للنتيجة مباشرة. عشان كذا بنينا تخليك تستخرج البيانات من أي موقع بنقرتين—بدون Python، وبدون Drivers، وبدون وجع تصحيح أخطاء.
كيف يعمل Thunderbit
- افتح الموقع اللي تبغى تستخرج منه البيانات.
- اضغط “AI Suggest Fields”. ذكاء Thunderbit يمسح الصفحة ويقترح الحقول المناسبة (مثل اسم المنتج، السعر، الصورة، التقييم).
- اضغط “Scrape”. وتطلع لك فورًا بياناتك في جدول مرتب.
- صدّر إلى Excel أو Google Sheets أو Airtable أو Notion أو CSV أو JSON. وخلاص.
لا لعب بالمحددات، ولا محاولات لا تنتهي، ولا كود. أسهل من طلب أكل جاهز (وبصراحة غالبًا أسرع من وصوله).
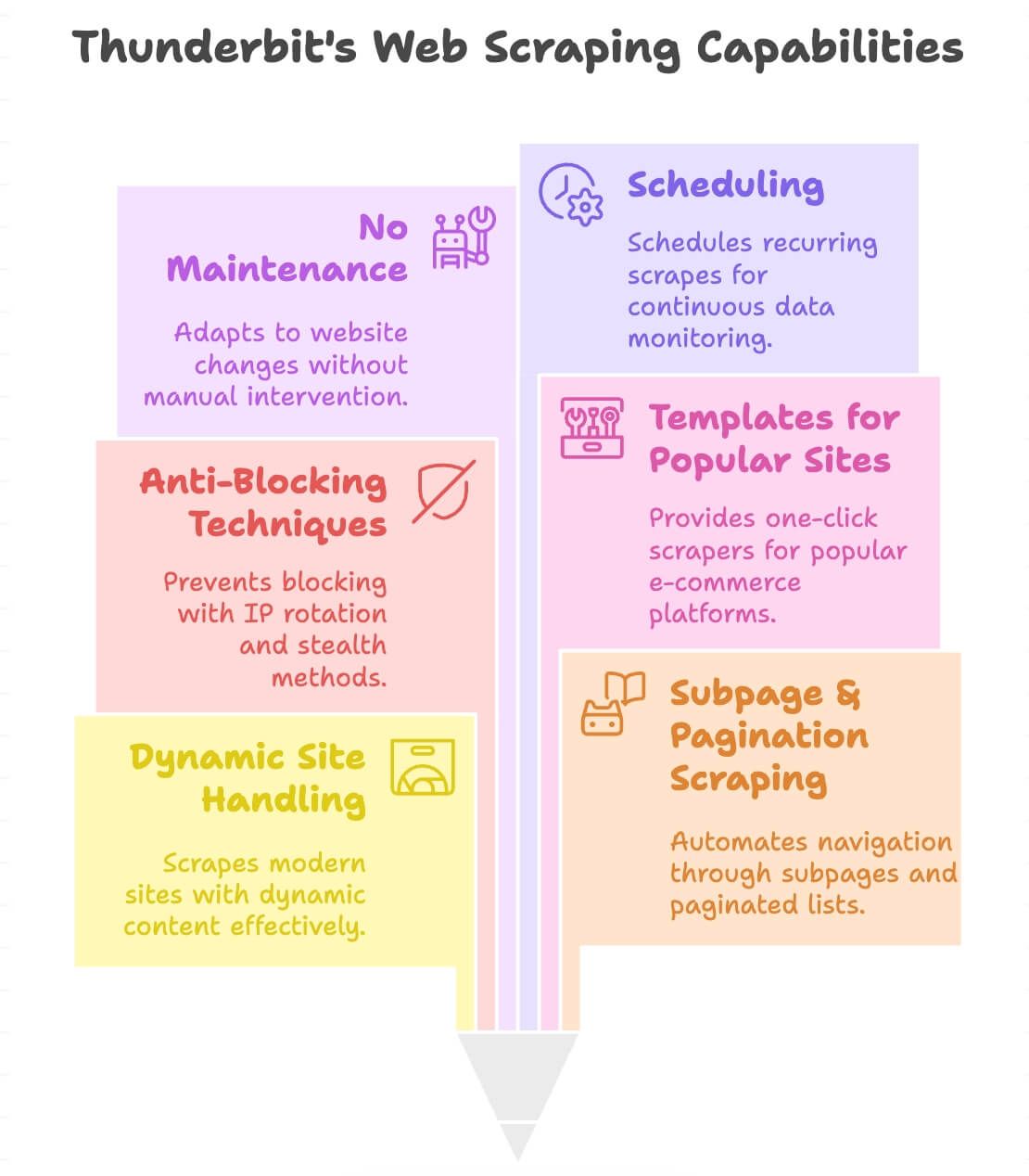
ما الذي يميز Thunderbit؟
- يتعامل مع المواقع الديناميكية: يستخرج من متاجر حديثة ودلائل وحتى مواقع فيها تمرير لانهائي أو نوافذ منبثقة.
- استخراج الصفحات الفرعية والتقسيم (Pagination): ينقر تلقائيًا عبر صفحات المنتجات أو القوائم المقسمة لجمع كل ما تحتاجه.
- مكافحة الحظر مدمجة: يستخدم تدوير IP من الخلفية وتقنيات تخفٍ لتقليل احتمالات الحظر.
- قوالب لمواقع شائعة: أدوات بنقرة واحدة لـ Amazon وeBay وShopify وZillow وغيرها ().
- بدون صيانة: إذا تغيّر الموقع، يتكيف ذكاء Thunderbit الاصطناعي—لا حاجة لإعادة كتابة الأداة.
- الجدولة: إعداد عمليات استخراج متكررة للمراقبة المستمرة (مثل فحص الأسعار يوميًا).
- يدعم 34 لغة: استخرج البيانات وترجمها من أي مكان تقريبًا.
والأهم: ما تحتاج تعرف أي شيء عن HTML أو CSS أو Python. إذا تعرف تستخدم المتصفح، تقدر تستخدم Thunderbit.
أي حل لاستخراج بيانات الويب يناسبك؟
خلّنا نختم بدليل قرار سريع:
| حالتك | أفضل أداة |
|---|---|
| استخراج من موقع ثابت وبسيط؛ ولا تمانع الإعداد | Selenium |
| استخراج من موقع حديث وديناميكي؛ وتريد نتائج سريعة | Playwright |
| تحتاج دعم متصفحات أو لغات قديمة | Selenium |
| تريد إعدادًا سهلًا وتصحيحًا حديثًا وكودًا أقل | Playwright |
| لست مطورًا؛ تريد البيانات الآن بلا كود ولا إعداد | Thunderbit |
| تحتاج استخراج صفحات متعددة/فرعية أو جدولة المهام | Thunderbit |
| تريد التصدير مباشرة إلى Excel وSheets وNotion وAirtable | Thunderbit |
| تكره تتبع أخطاء Python | Thunderbit |
إذا أنت مطوّر أو تحب “تعبث” بالكود، فـ playwright و selenium الاثنين خيارات قوية. لكن إذا هدفك توصل البيانات لجدول بيانات بأسرع وقت ممكن، Thunderbit بيوفر عليك ساعات—وربما أيام—من الشغل.
الخلاصة: استخراج بيانات سريع وموثوق—بالطريقة التي تناسبك
صار استخراج بيانات الويب شيء شائع، ولسبب واضح: الشركات تحتاج البيانات عشان تنافس، وتحتاجها الآن. تطور playwright و selenium من أدوات اختبار بسيطة إلى أطر أساسية لاستخراج البيانات، ولكل واحد نقاط قوة. selenium هو الخيار الموثوق للمواقع الثابتة والبيئات القديمة؛ وplaywright هو الخيار الحديث السريع للصفحات الديناميكية التفاعلية.
لكن نصيحتي الصادقة بعد سنوات في SaaS والأتمتة والذكاء الاصطناعي: إذا أنت مو مهتم بالبرمجة، لا تضيّع وقتك في صراع مع Drivers والمحددات وحيل مكافحة البوت. مع تقدر تنتقل من “أبغى هالبيانات” إلى “هذا ملف Excel” خلال دقائق—مو أيام.
سواء كنت محترف Python أو مستخدم بزنس يبغى النتائج وبس، بتلقى حل يناسب احتياجك—ومستوى صبرك. جرّب الخيارات، واختر اللي يمشي مع سير عملك، وتذكر: أفضل أداة استخراج هي اللي تعطيك البيانات اللي تحتاجها بأقل قدر من المتاعب.
وإذا لقيت نفسك يومًا تلاحق خطأ Driver في selenium الساعة 2 الفجر، تذكّر—Thunderbit موجود دائمًا، جاهز يشتغل بنقرتين. استخراجًا موفقًا.
هل تريد معرفة المزيد عن الاستخراج بدون كود، واستخراج البيانات بالذكاء الاصطناعي، وكيف يمكن لـ Thunderbit مساعدة فريقك؟ تفضل بزيارة ، أو ابدأ اليوم عبر .
ملاحظة: إذا كنت ما زلت غير متأكد من الأداة الأنسب، أو تريد مشاهدة Thunderbit أثناء العمل، زر للعروض والنصائح—وبعض نكات استخراج بيانات الويب أحيانًا. (نعم، لدينا ذلك.)
للمزيد من القراءة: