
دعني أخبرك بشيء: لو كان لي دولار في كل مرة يرسل إليّ أحدهم ملف PDF مليئًا بـ«بيانات مهمة» ويتوقع مني أن أحوله سحرًا إلى جدول بيانات، لكنت أملك على الأرجح ما يكفي لشراء مخزون لا ينفد من القهوة، وربما بضع إضافات Chrome إضافية. ملفات PDF موجودة في كل مكان—عقود المبيعات، كتالوجات المنتجات، الأوراق البحثية، الفواتير، سمِّ ما شئت. لكن عندما يحين وقت استخدام البيانات داخل هذه الملفات فعلًا؟ هنا تبدأ المتعة (اقرأ: الصداع).
لقد خضت هذه المعركة: نسخ، ولصق، وإعادة تنسيق، وأحيانًا استسلام كامل عندما يختل التنسيق أو تختفي الصور والروابط في الهواء. لكن الخبر الجيد هو أن عالم استخراج البيانات من PDF تغيّر بشكل كبير، خصوصًا مع ظهور الأدوات المدعومة بالذكاء الاصطناعي. إذا سئمت من قضاء ساعات في إعادة إدخال الأرقام يدويًا أو من فقدان صوابك بسبب الجداول المعطوبة، فأنت في المكان الصحيح. لنغص في عالم استخراج البيانات من PDF، ولماذا هو مهم، وكيف تجعل أدوات مثل Thunderbit الأمر سهلًا أخيرًا.
ما هو استخراج البيانات من PDF؟ فهم أساسيات استخراج بيانات PDF
لنبدأ ببساطة: استخراج البيانات من PDF هو مجرد طريقة أنيقة لقول «الحصول على بيانات منظمة من ملفات PDF—تلقائيًا». أما أداة استخراج البيانات من PDF فهي أداة (برنامج، إضافة، أو خدمة) تسحب ما يهمك—النصوص، الجداول، الصور، الروابط، سمِّ ما شئت—وتضعه في صيغة يمكنك استخدامها فعلًا، مثل Excel أو Google Sheets أو قاعدة بيانات.
لكن هنا تكمن المشكلة: ملفات PDF ليست مثل صفحات الويب أو ملفات Excel. هي أقرب إلى نسخ رقمية مطبوعة، صُممت لتبدو متطابقة في كل مكان، لا لكي يفككها الكمبيوتر بسهولة. بعض ملفات PDF تحتوي على نص يمكن تحديده، وأخرى مجرد صور ممسوحة ضوئيًا (وتحتاج إلى OCR—التعرّف الضوئي على الحروف)، وقد يكون التنسيق فيها فوضويًا تمامًا. لذلك فإن استخراج البيانات من PDF لا يعني مجرد نسخ النص، بل فك شيفرة أحجية من التخطيطات والخطوط وأحيانًا حتى البيانات الوصفية المخفية.
ما الذي يمكنك استخراجه من ملف PDF؟
- نص عادي (فقرات، عناوين، إلخ)
- جداول (مثل: البيانات المالية، مواصفات المنتجات، بيانات الاستبيانات)
- صور ورسومات (مخططات، شعارات، توقيعات ممسوحة ضوئيًا)
- روابط تشعبية ومراجع (روابط URL مدمجة، اقتباسات)
- بيانات النماذج (حقول النماذج القابلة للتعبئة)
- البيانات الوصفية (المؤلف، العنوان، تاريخ الإنشاء، الوسوم)
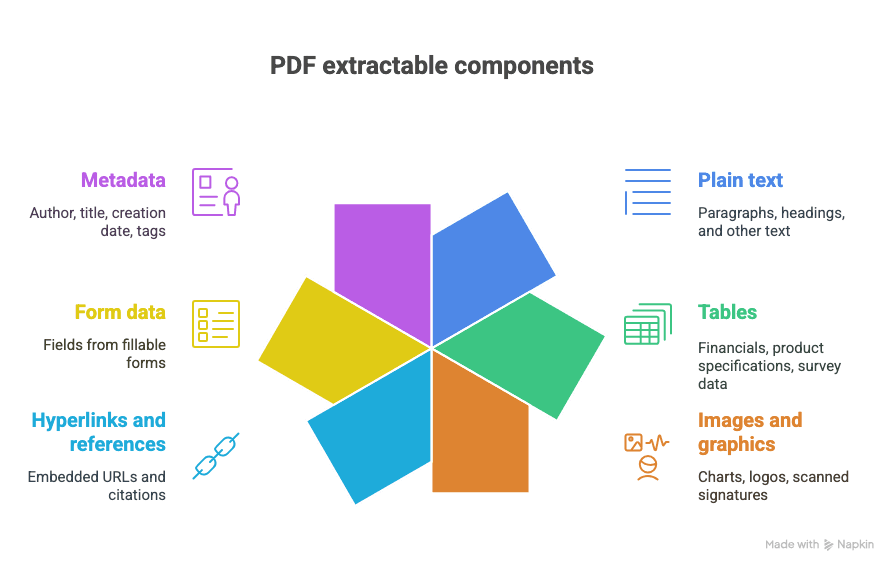
ونعم، أحيانًا تكون كل هذه العناصر مختلطة معًا في مستند واحد رائع وفوضوي.
لماذا يهم استخراج البيانات من PDF: حالات استخدام واقعية وفوائد للأعمال
إذًا، لماذا نتعب أنفسنا في استخراج البيانات من PDF؟ لأن الجميع يستخدمها، ولأن البيانات بداخلها غالبًا حاسمة للأعمال. وهنا يظهر التميّز الحقيقي لاستخراج البيانات من PDF:
| حالة الاستخدام | الجهد اليدوي | مع أداة استخراج PDF | توفير الوقت وتقليل الأخطاء |
|---|---|---|---|
| استخراج العملاء المحتملين للمبيعات | ساعات من نسخ جهات الاتصال من العروض أو ملفات الفعاليات بصيغة PDF، مع خطر فقدان عملاء محتملين | يسحب جميع العملاء المحتملين مباشرة إلى جدول بيانات | أسرع بنسبة 80–90%، وأخطاء أقل |
| بيانات منتجات التجارة الإلكترونية | أيام من إدخال مواصفات المنتجات من ملفات الموردين، ومشاكل تنسيق لا تنتهي | استخراج دفعي إلى CSV أو Sheets | توفير أكثر من 95% من الوقت، وبيانات متسقة |
| تحليل بيانات الأبحاث | أسابيع من تفريغ الجداول من الأوراق الأكاديمية، مع خطر مرتفع للأخطاء المطبعية | يستخرج الجداول والمراجع وحتى النصوص الممسوحة ضوئيًا | توفير 80% من الوقت، ودقة أعلى |
لنضع بعض الأرقام على ذلك:
- يتم إنشاء 2.5 تريليون ملف PDF كل عام.
- 90% من المؤسسات تستخدم PDF كصيغة أساسية لمشاركة المعلومات.
- الأعمال الإدارية اليدوية الرقمية (مثل إدخال بيانات PDF) تلتهم 40% من ساعات العمل.
- الأدوات الآلية يمكنها خفض معدلات الخطأ من 5–10% إلى 1%.
إذا كنت تعمل في المبيعات أو التجارة الإلكترونية أو البحث، فإن أتمتة استخراج بيانات PDF ليست مجرد ميزة لطيفة—بل أفضلية تنافسية.
طرق استخراج البيانات من PDF التقليدية: التحديات والقيود
لنكن صريحين: الطرق القديمة لاستخراج البيانات من PDF ليست… ممتازة. هذا ما حاول معظمنا فعله (ولهذا السبب هو محبط جدًا):

1. النسخ واللصق اليدوي
- نقاط الألم: يختل التنسيق، وتتحول الجداول إلى فوضى، وتختفي الصور والروابط، وتبقى أنت مع صداع حاد.
- تكلفة العمل: مرتفعة. إذا كان لديك 5000 ملف PDF، وحتى لو استغرق كل ملف دقيقة واحدة، فهذا أكثر من 80 ساعة من حياتك لن تعود أبدًا.
- معدل الخطأ: 5–10%. أخطاء إملائية، صفوف مفقودة، حذف غير مقصود—مررت بهذا كله.
2. التحويل إلى Word/Excel ثم التنظيف
- نقاط الألم: قد ينجح أحيانًا مع المستندات البسيطة، لكن التخطيطات المعقدة أو الجداول تتشوه. وستظل مضطرًا إلى تنظيف الفوضى.
- الصور/الروابط: غالبًا تضيع أثناء التحويل.
- الاستخراج الموجه: انسَ الأمر—ستحصل على المستند كاملًا، لا ما تحتاجه فقط.
3. البرامج النصية المخصصة (Python وغيرها)
- نقاط الألم: تحتاج إلى مبرمج (أو مبرمج متفرغ عند الطلب). كل صيغة PDF جديدة تعني تعديلًا في السكربت. وملفات PDF الممسوحة ضوئيًا؟ حظًا موفقًا.
- الصيانة: مرتفعة. في كل مرة يغيّر فيها المورّد قالب الفاتورة، ينكسر السكربت.
- قابلية التوسع: ليست لمن لا يملك صبرًا كبيرًا (ولا لغير التقنيين).
4. المحوّلات عبر الإنترنت
- نقاط الألم: سهلة للمهام الفردية، لكن عليك رفع مستندات حساسة إلى خادم طرف ثالث (مرحبًا بمشكلات الامتثال). كما أن التحكم في ما يتم استخراجه محدود.
- التنسيق: النتيجة قد تصيب وقد تخيب. قد تقضي وقتًا في التنظيف أكثر مما وفّرته.
الخلاصة: الطرق التقليدية بطيئة، عرضة للأخطاء، ولا تتوسع جيدًا. لهذا السبب يكتفي كثير من الفرق بـ«التعايش معها»—لكن بثمن إنتاجية كبير.
حلول حديثة لاستخراج البيانات من PDF: من الكود إلى أدوات بدون كود
لحسن الحظ، لم نعد عالقين في العصور المظلمة. لقد انفجر هذا المجال بخيارات أذكى وأسرع وأسهل استخدامًا لاستخراج البيانات من PDF.
1. مكتبات البرمجة (للمطورين)
- أمثلة: PyPDF2، PDFMiner، Tabula-py.
- نقاط القوة: مرنة جدًا، يمكن أتمتتها على دفعات كبيرة، مجانية (مفتوحة المصدر).
- نقاط الضعف: وقت إعداد مرتفع، تتطلب مهارات برمجية، هشة (تتعطل مع الصيغ الجديدة)، ودعم محدود لـ OCR/الصور.
2. محوّلات PDF عبر الإنترنت
- أمثلة: Smallpdf، PDF2Go، Zamzar.
- نقاط القوة: بلا إعداد تقريبًا، سهلة لغير التقنيين، وسريعة للمهام الصغيرة.
- نقاط الضعف: تخصيص محدود، مخاوف الخصوصية، أخطاء في التنسيق، وحدود على حجم الملف/عدد الصفحات.
3. أدوات استخراج PDF المدعومة بالذكاء الاصطناعي
- أمثلة: Thunderbit، Nanonets، Docparser.
- نقاط القوة: لا حاجة للبرمجة، تتعامل مع النصوص/الجداول/الصور/الروابط، الذكاء الاصطناعي يقترح ما يجب استخراجه، تدعم المهام الدُفعية، وتتصل بـ Sheets وNotion وAirtable.
- نقاط الضعف: بعض الأدوات لديها حدود على الرصيد/الصفحات، وقد تتطلب اتصالًا بالإنترنت، مع منحنى تعلم أحيانًا للمستندات المعقدة.
مقارنة أدوات استخراج PDF: أي نهج يناسب احتياجاتك؟
| الأداة/الطريقة | الإعداد | الأفضل لـ | ما الذي تستخرجه | قابل للتخصيص؟ | التكلفة |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | متوسط (واجهة/برمجة) | الجداول في ملفات PDF | الجداول | إلى حد ما | مجاني |
| PDFMiner | يتطلب برمجة | ملفات PDF الغنية بالنصوص | النص | نعم (بالكود) | مجاني |
| PyPDF2 | يتطلب برمجة | النصوص البسيطة/البيانات الوصفية | النص، البيانات الوصفية | نعم (بالكود) | مجاني |
| Smallpdf/محولات عبر الإنترنت | لا شيء (عبر الويب) | التحويلات السريعة | المستند كاملًا (Word/Excel) | لا | مجاني/مدفوع |
| Thunderbit | تثبيت بنقرتين | مستخدمو الأعمال، والفرق | النص، الجداول، الصور، الروابط | نعم (مطالبات الذكاء الاصطناعي) | مجاني/مدفوع (16.5 دولارًا شهريًا للخطة الاحترافية) |
تعرّف على Thunderbit: إضافة Chrome لاستخراج PDF بالذكاء الاصطناعي
كيفية استخراج البيانات من PDF باستخدام الذكاء الاصطناعي Get Started Free
الآن دعنا نتحدث عن الأداة التي جعلت حياتي—وحياة كثير من مستخدمي الأعمال—أسهل بكثير: Thunderbit.
ما الذي يجعل Thunderbit مختلفًا؟
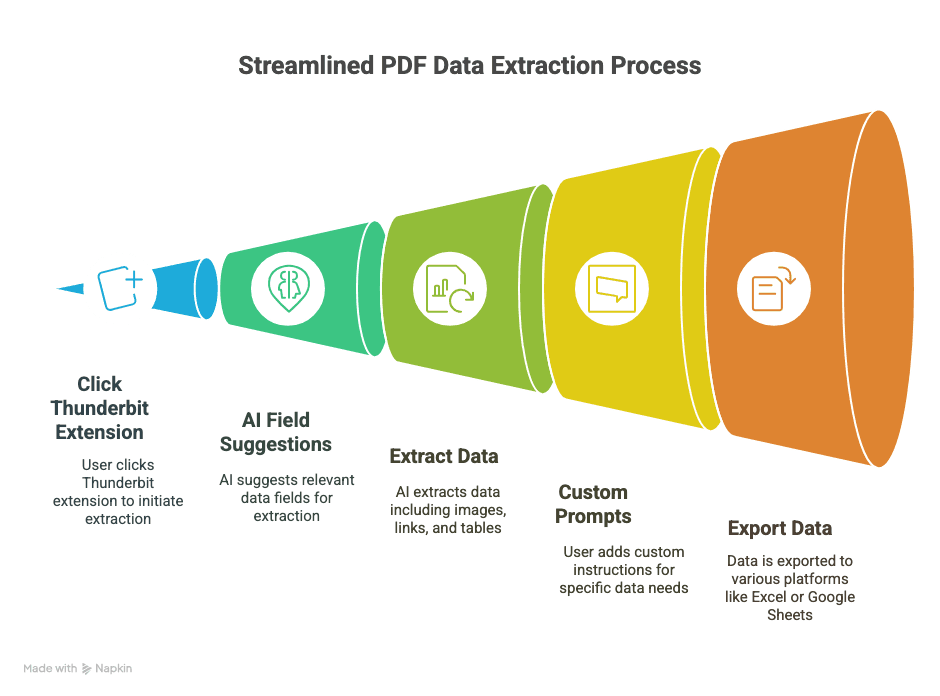
- استخراج بنقرتين: افتح ملف PDF في Chrome، وانقر على إضافة Thunderbit، ودع الذكاء الاصطناعي يتولى الباقي.
- اقتراحات حقول مدفوعة بالذكاء الاصطناعي: ميزة «AI Suggest Fields» في Thunderbit تقرأ ملف PDF وتقترح الأعمدة التي ستحتاجها على الأرجح (مثل «الاسم»، «البريد الإلكتروني»، «السعر»، إلخ).
- التعامل مع الصور والروابط والجداول: ليس النص العادي فقط—يمكن لـ Thunderbit استخراج الصور والروابط التشعبية وحتى تشغيل OCR على المستندات الممسوحة ضوئيًا.
- مطالبات مخصصة: تحتاج فقط إلى أرقام الهواتف أو مواصفات المنتجات؟ أضف تعليمات مخصصة وسيركز Thunderbit على ذلك فقط.
- تصدير إلى كل مكان: أرسل بياناتك مباشرة إلى Excel أو Google Sheets أو Airtable أو Notion. لا مزيد من ألعاب CSV المعقدة.
- استخراج دفعي واستخراج الصفحات الفرعية: لديك قائمة ملفات PDF أو روابط؟ يمكن لـ Thunderbit معالجتها كلها دفعة واحدة.
- موثوقية بمستوى الأعمال: صُمم من أجل الدقة والخصوصية وسير العمل الواقعي.
باختصار، كأنك تملك متدربًا رقميًا يحب فعلًا إدخال البيانات ولا يتعب أبدًا.
كيفية استخراج البيانات من ملف PDF باستخدام Thunderbit: دليل خطوة بخطوة
تنزيل إضافة Thunderbit لـ Chrome Get Started Free
هل أنت مستعد لترى كم يمكن أن يكون الأمر سهلًا؟ هكذا أستخدم Thunderbit لتحويل ملفات PDF إلى بيانات منظمة وقابلة للاستخدام:
1. ثبّت Thunderbit
- احصل على إضافة Thunderbit لـ Chrome.
- سجّل حسابًا (حساب Google أو البريد الإلكتروني—يستغرق ثوانٍ).
2. افتح ملف PDF في Chrome
- افتح ملف PDF من رابط ويب، أو اسحب ملف PDF محليًا إلى تبويب Chrome.
3. شغّل Thunderbit على ملف PDF
- انقر على أيقونة Thunderbit في شريط أدوات المتصفح.
- اختر “AI Web Scraper” — سيتعرّف Thunderbit على ملف PDF ويستعد للعمل.
4. دع الذكاء الاصطناعي يقترح الحقول
- انقر على “AI Suggest Columns”.
- يفحص الذكاء الاصطناعي في Thunderbit ملف PDF ويقترح الأعمدة (مثل «التاريخ»، «المبلغ»، «اسم جهة الاتصال»، إلخ).
- استعرض البيانات المستخرجة في جدول داخل الإضافة نفسها.
5. خصّص عند الحاجة
- أعد تسمية الأعمدة، أو احذف الزائد، أو أضف حقولك الخاصة (مثل «مدة الضمان» أو «رابط المنتج»).
- بالنسبة للبيانات الصعبة، حدّد النص داخل ملف PDF لتدريب الذكاء الاصطناعي على ما تريده.
6. اختر صيغة التصدير
- اختر من CSV أو Google Sheets أو Airtable أو Notion.
- فوض Thunderbit للاتصال (إعداد لمرة واحدة).
7. استخرج وصدّر
- اضغط على “Scrape” أو “Export”.
- يعالج Thunderbit ملف PDF ويرسل البيانات إلى المكان الذي تريده—عادةً خلال ثوانٍ.
جرّب أداة استخراج PDF من Thunderbit الآن
هذا كل شيء. لا برمجة، لا نسخ ولصق، ولا دراما.
نصائح لاستخراج دقيق لبيانات PDF مع Thunderbit
- راجع الحقول المقترحة من الذكاء الاصطناعي: الذكاء الاصطناعي ذكي، لكن نظرة سريعة تضمن أنك تحصل على ما تحتاجه بالضبط.
- تعامل مع الجداول المعقدة: في الجداول متعددة الصفحات أو المنسقة بشكل غريب، استخدم المعاينة لاكتشاف المشكلات وتعديل الأعمدة حسب الحاجة.
- استخرج الصور/الروابط: تأكد من تضمين هذه الحقول إذا كان ملف PDF يحتوي عليها—فـ Thunderbit يستطيع التقاطها أيضًا.
- ملفات PDF الممسوحة ضوئيًا: OCR المدمج في Thunderbit جيد، لكن كلما كانت المسحة أوضح، كانت النتائج أفضل.
- مطالبات مخصصة: تريد فقط البريد الإلكتروني أو أرقام الهواتف؟ أضف مطالبة مثل «استخرج جميع عناوين البريد الإلكتروني» وسيركز Thunderbit عليها.
استخراج متقدم لبيانات PDF: استخراج الصور والروابط والبيانات المخصصة
Thunderbit ليس فقط للنصوص العادية. إليك كيف يمكنك الاستفادة أكثر من ملفات PDF لديك:
- الصور: استخرج الشعارات أو المخططات أو أي رسومات مدمجة. ويمكن لـ Thunderbit حتى تشغيل OCR على النص داخل الصور.
- الروابط التشعبية: اسحب جميع عناوين URL أو المراجع—مفيد جدًا للأوراق البحثية أو السير الذاتية.
- أنواع بيانات مخصصة: استخدم مطالبات الذكاء الاصطناعي لاستخراج ما تحتاجه فقط (مثل: «اعثر على جميع رموز المنتجات وأسعارها»).
- الملخصات والتصنيف: أضف عمودًا واطلب من Thunderbit تلخيص قسم أو تصنيف البيانات أثناء العمل.
تحليل البيانات من PDF لاحتياجات الأعمال المحددة
- المبيعات: استخرج معلومات الاتصال فقط من دفعة من العروض.
- التجارة الإلكترونية: اسحب مواصفات المنتجات والأسعار والصور من كتالوجات الموردين.
- البحث: التقط الجداول والمراجع، بل وأنشئ ملخصات من الأوراق الأكاديمية.
وبمجرد حصولك على البيانات، يمكنك هيكلتها بسهولة للتحليل في Excel أو Google Sheets أو Notion—يتولى Thunderbit العمل الشاق، وأنت فقط تستخدم النتائج.
تصدير بيانات PDF واستخدامها: من الاستخراج إلى التنفيذ
استخراج البيانات ليس سوى البداية. هكذا تجعلها تعمل لصالحك:
- خيارات التصدير: CSV، Excel، Google Sheets، Airtable، Notion—اختر ما تحب.
- نصائح التنسيق: استخدم إعدادات نوع العمود في Thunderbit (رقم، تاريخ، نص) للحصول على بيانات نظيفة وجاهزة للتحليل.
- دمج سير العمل: اربط البيانات المصدّرة بأنظمة CRM أو أنظمة المخزون أو لوحات التحليلات.
- التعاون: شارك أوراق Google Sheets أو قواعد Airtable مع فريقك—ليعمل الجميع من نفس البيانات المحدثة.
والأفضل من ذلك كله؟ لا مزيد من تبادل الجداول عبر البريد الإلكتروني أو التساؤل عمّا إذا كنت قد فاتك صف.
الأخطاء الشائعة في استخراج PDF وكيفية تجنبها
حتى مع أفضل الأدوات، قد تظهر بعض المفاجآت. هذا ما تعلمته (أحيانًا بالطريقة الصعبة):
- أخطاء OCR: قد تربك المسحات الضبابية أو الخطوط الغريبة حتى أفضل أنظمة OCR. حاول استخدام أنظف ملفات PDF ممكنة، وراجع الحقول الحساسة مرتين.
- التخطيطات المعقدة: قد تحتاج الجداول متعددة الأعمدة أو المتداخلة إلى بعض التوجيه اليدوي—استخدم التحديد اليدوي أو المطالبات في Thunderbit.
- أنواع البيانات: أرقام تحتوي على فواصل أو تواريخ بصيغ غير مألوفة؟ اضبط نوع العمود قبل التصدير، أو نظّفها في Excel/Sheets.
- قيود حجم الملف/عدد الصفحات: ملفات PDF ضخمة؟ قسّمها إلى أجزاء أصغر، أو استخدم وضع السحابة في Thunderbit للمهام الدُفعية.
- هلوسة الذكاء الاصطناعي: نادرة، لكن أحيانًا قد يخمّن الذكاء الاصطناعي اسم عمود أو يملأ بيانات مفقودة. راقب النتائج دائمًا، خاصة الأرقام المهمة.
- المراجعة اليدوية: للبيانات الحرجة للغاية، قم بعملية تحقق سريعة—الأدوات الآلية دقيقة، لكن العين البشرية لا تضر أبدًا.
وإذا واجهت طريقًا مسدودًا، فدعم Thunderbit ومجتمعه موجودان للمساعدة.
الخلاصة وأهم النقاط: جعل استخراج PDF يعمل لصالح عملك
لنختتم. كان استخراج البيانات من ملفات PDF كابوسًا—بطيئًا، معرضًا للأخطاء، ومملًا للغاية. لكن مع الأدوات الحديثة مثل Thunderbit، أصبح الآن سريعًا ودقيقًا و(أجرؤ على القول) ممتعًا تقريبًا.
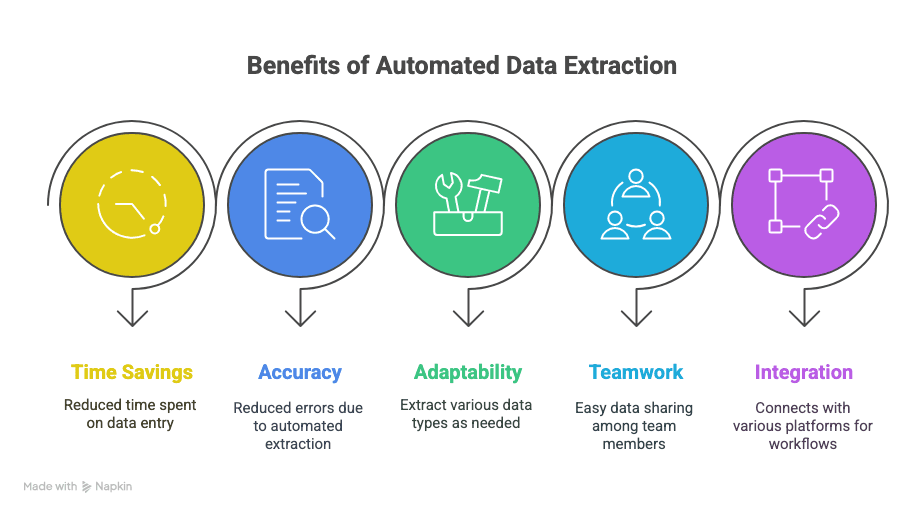
إليك ما ستحصل عليه:
- استعادة الوقت: توفير ساعات—وأحيانًا أسابيع—من إدخال البيانات يدويًا.
- أخطاء أقل: الاستخراج الآلي يعني أخطاء مطبعية أقل وصفوفًا مفقودة أقل.
- مرونة: استخرج بالضبط ما تحتاجه—نصوص، جداول، صور، روابط، سمِّ ما شئت.
- تعاون أفضل: شارك البيانات فورًا مع فريقك، أينما كانوا.
- سير عمل أذكى: تكامل مع Sheets وNotion وAirtable وغيرها.
هل أنت مستعد لتجربته؟ نزّل إضافة Thunderbit لـ Chrome، وشغّلها على ملف PDF التالي، وشاهد كم يمكن أن تصبح الحياة أسهل. نفسك المستقبلية (ومفاصل رسغك) ستشكرك.
لمزيد من النصائح والأدلة، اطلع على مدونة Thunderbit أو تعمّق أكثر في كيفية استخراج البيانات من PDF باستخدام الذكاء الاصطناعي.
لنجعل صداع ملفات PDF يتحول إلى مكاسب إنتاجية—نقرة واحدة في كل مرة.
شواي قوان، الشريك المؤسس والرئيس التنفيذي، Thunderbit
جرّب أداة Thunderbit لاستخراج PDF بالذكاء الاصطناعي Get Started Free




