
دراسة قائمة على الزحف حول كيف تنشر المواقع عالية الزيارات إرشادات قابلة للقراءة آليًا موجهة إلى النماذج اللغوية الكبيرة، وما الذي تبدو عليه التطبيقات المبكرة، ولماذا يتطلب قياس الاعتماد أكثر من مجرد عدّ استجابات HTTP 200.
- مجموعة البيانات:
data/llms_probe_results_top_10000.csv - تم تنزيل قائمة Tranco: 6 مايو 2026
- النطاق:
/llms.txtو/llms-full.txtعلى مستوى الجذر
المؤشرات الرئيسية
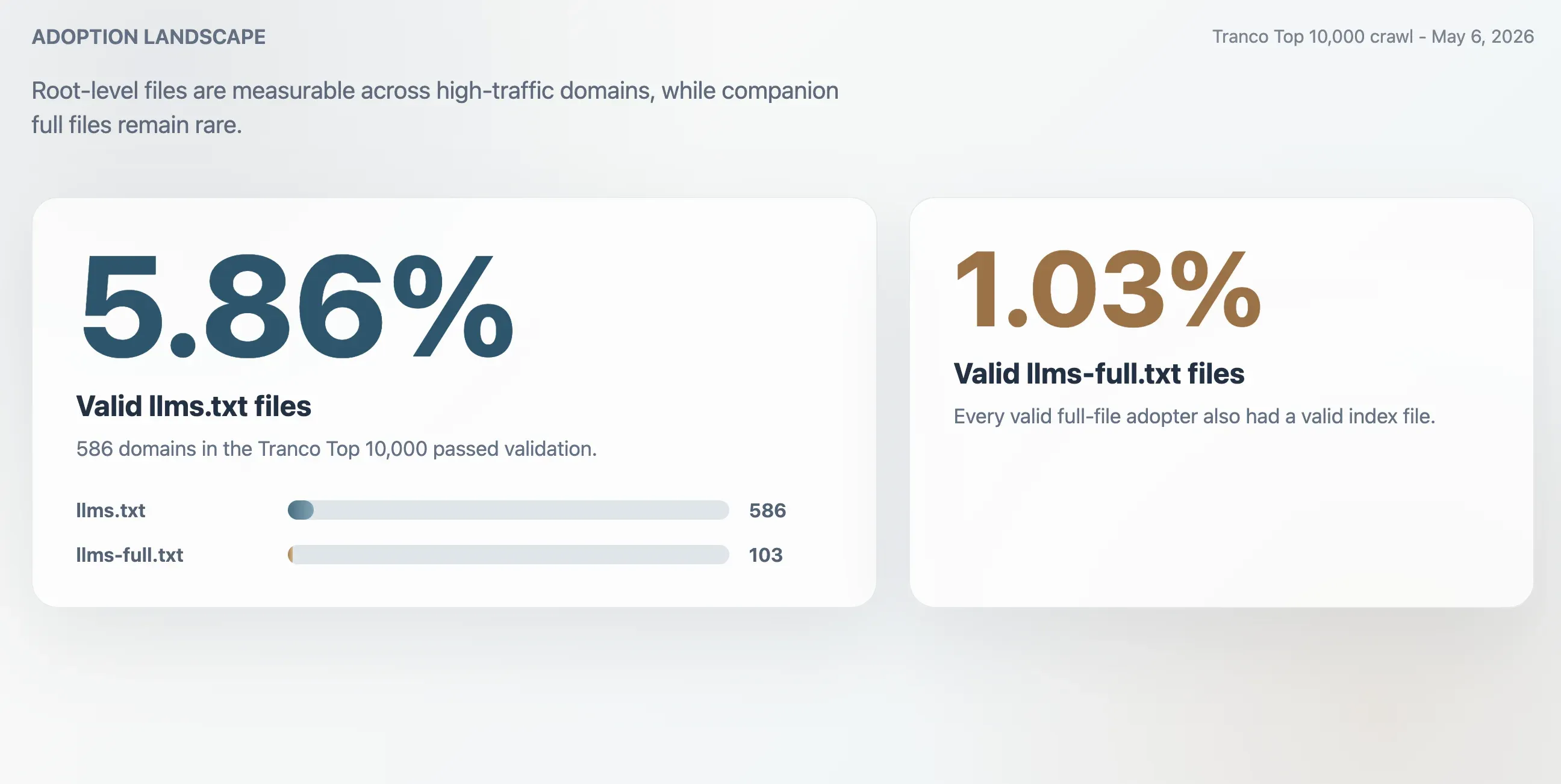
- 5.86%: اعتماد صالح لـ
llms.txtعبر أفضل 10,000 موقع في Tranco، أي ما يعادل 586 نطاقًا. - 1.03%: اعتماد صالح لـ
llms-full.txt، أي ما يعادل 103 نطاقات. وكل نطاق اعتمد ملفًا كاملًا صالحًا كان لديه أيضًا ملف فهرس صالح. - 63.51%: حصة استجابات HTTP 200 لمسار
/llms.txtالتي فشلت في التحقق. - 2.74x: مقدار المبالغة التقريبي إذا جرى قياس الاعتماد اعتمادًا على استجابات HTTP 200 الخام فقط.
الملخص التنفيذي
لا يزال llms.txt عرفًا ويب مبكرًا، لكنه لم يعد مجرد تجربة هامشية. ففي زحف أُجري في 6 مايو 2026 على أفضل 10,000 نطاق في Tranco، وجدت هذه الدراسة 586 ملفًا صالحًا من نوع llms.txt، أي بمعدل اعتماد ملاحظ بلغ 5.86%. أما الملف المرافق llms-full.txt فكان أقل شيوعًا بكثير: 103 نطاقات امتلكت ملفًا كاملًا صالحًا، بمعدل اعتماد قدره 1.03%.
وأهم نتيجة منهجية هي أن رموز الحالة ليست مؤشرًا موثوقًا للاعتماد. فقد رصد الزاحف 1,606 استجابة HTTP 200 لمسار /llms.txt، لكن 586 فقط اجتازت التحقق. أما 1,020 استجابة المتبقية فكانت في الغالب عمليات إعادة توجيه غير مطابقة، أو صفحات HTML عامة، أو أجسامًا فارغة، أو استجابات غير صالحة أخرى. الزاحف الساذج الذي يعدّ كل استجابة 200 على أنها اعتماد سيبالغ في تقدير الاعتماد الصالح بنحو 2.74 مرة.
ومن بين المعتمدين الصالحين، تبدو جودة التنفيذ أعلى مما قد توحي به رواية «مجرد عنصر نائب». كان متوسط حجم الملف الصالح نحو 7.1 كيلوبايت، و61.77% من الملفات الصالحة أكبر من 5 كيلوبايت، و70.82% احتوت على ستة أقسام Markdown أو أكثر، و77.47% احتوت على 11 رابط Markdown أو أكثر. وتضم قائمة المعتمدين الأوائل Cloudflare وAzure وGitHub وDigiCert وWordPress.org وAdobe وDropbox وPayPal وStripe وSalesforce وSlack وZendesk وOkta وDatadog وCloudinary.
يُفهم
llms.txtعلى أفضل وجه بوصفه إشارة توضيحية وإرشادية لأنظمة الذكاء الاصطناعي، لا بديلاً عنrobots.txt. فالقيمة لا تكمن في مجرد وجود الملف، بل في مدى مساعدته للآلات على العثور على معلومات موثوقة ومختصرة وحديثة.
السياق: الويب يضيف إشارات موجهة إلى الذكاء الاصطناعي
تستخدم المواقع منذ زمن طويل robots.txt للتعبير عن تفضيلات الزحف، وsitemap.xml لتحسين اكتشاف الروابط، والبيانات المنظمة لمساعدة أنظمة البحث والمنصات على تفسير الصفحات. لكن الذكاء الاصطناعي التوليدي يطرح مشكلة مختلفة. فقد تُستخدم المحتويات في التدريب، والاسترجاع، والتلخيص، والتصفح الوكيلي، والمساعدة البرمجية، ودعم العملاء، وتوليد الإجابات. وهذا يخلق حاجتين متزامنتين: يريد الناشرون مزيدًا من التحكم في الاستخدام الآلي، لكنهم يريدون أيضًا أن تتمكن أنظمة الذكاء الاصطناعي من العثور على المعلومات المعيارية الصحيحة عندما تتفاعل مع مواقعهم.
تطرح المقترح الأصلي لـllms.txt، الذي قدمه Jeremy Howard في 2024، الملف بوصفه مستند Markdown يوضع في جذر الموقع لتقديم معلومات مناسبة للنماذج اللغوية الكبيرة وقت الاستدلال. ويجادل المقترح بأن صفحات HTML غالبًا ما تتضمن تنقلًا وإعلانات وبرامج نصية وضوضاء أخرى تجعل معالجتها أصعب على النماذج اللغوية. ويمكن لملف Markdown موجز أن يوجّه النماذج نحو أهم الصفحات والمستندات وواجهات API والأمثلة والسياسات ومعلومات المنتج.
وتقدم أبحاث الويب الخارجية خلفية أوسع. فـ«الموافقة في أزمة» لمبادرة Data Provenance Initiative تصف زيادة سريعة في القيود المرتبطة بالذكاء الاصطناعي داخل robots.txt وشروط الخدمة، وتجادل بأن آليات الموافقة الحالية على الويب لم تُصمم لإعادة استخدام بيانات الذكاء الاصطناعي على نطاق واسع. كما جعلت Cloudflare Radar AI Insights أنماط روبوتات الذكاء الاصطناعي وrobots.txt مرئية على مستوى أفضل 10,000 نطاق. وفي هذا السياق، يقف llms.txt في الجانب البنّاء من إشارات الذكاء الاصطناعي: ليس «لا تزحف إلى هذا»، بل «إذا أردت فهم هذا الموقع، فابدأ من هنا».
الأدلة الخارجية وجدال الاعتماد
ينقسم الجدل العام حول llms.txt بين ادعاءين. فالادعاء المتفائل يقول إن الملف يمنح أنظمة الذكاء الاصطناعي مسارًا أنظف وأكثر كفاءة نحو المحتوى الموثوق. أما الادعاء المتشكك فيقول إن أي مزود رئيسي لنماذج LLM لم يلتزم علنًا باستخدامه كإشارة ترتيب أو زحف أو استشهاد، لذا لا ينبغي للناشرين توقع مكاسب زيارات من الملف وحده. وتدعم المراجع الخارجية الثلاث التي راجعناها لهذا التحديث استنتاجًا أكثر دقة: llms.txt بنية تحتية مفيدة، لكن الأدلة على تأثيره المباشر في الزيارات لا تزال محدودة وتعتمد على السياق.
مؤشرات الاعتماد الخارجية تتحرك بسرعة
أفاد متعقّب الاعتماد من Rankability بنسبة اعتماد 0.3% عبر أفضل 1,000 موقع حتى 22 يونيو 2025، أي 3 من أصل 1,000 موقع. ويصف هذا المتعقب فحصًا آليًا شهريًا لـdomain.com/llms.txt، مع تحقق يستبعد عمليات إعادة التوجيه واستجابات HTML. وهذه المنهجية قريبة من نهج التحقق المحافظ المستخدم في هذه الدراسة.
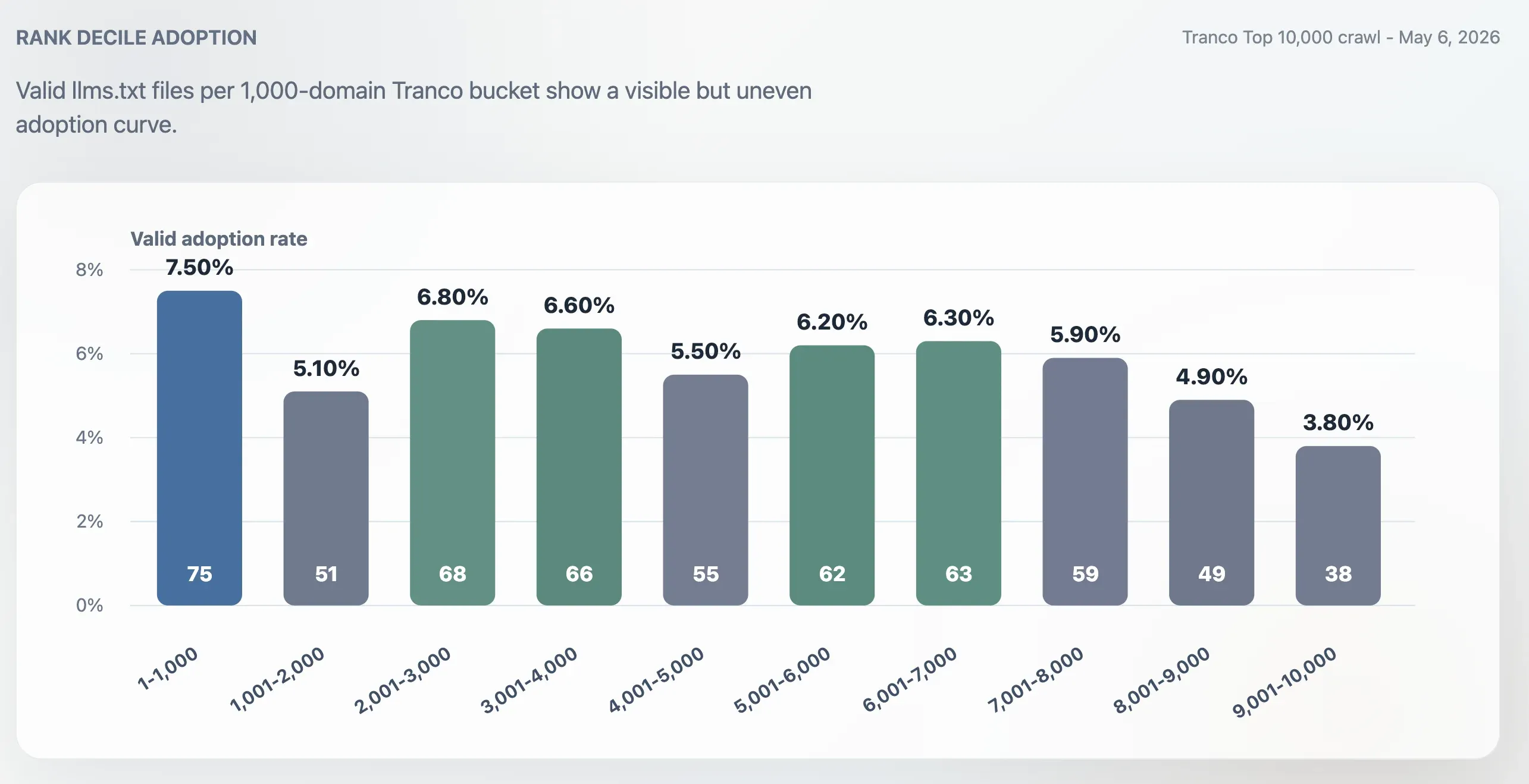
لكن الفرق في النتائج كبير: فقد وجدت هذه الدراسة 75 ملفًا صالحًا من نوع llms.txt ضمن أفضل 1,000 موقع في Tranco في 6 مايو 2026، أي 7.50%. ولا ينبغي التعامل مع الرقمين كسلسلة زمنية صارمة لأن مصدر الترتيب وتفاصيل التنفيذ ومنطق التحقق وتوقيت الزحف قد تختلف. ومع ذلك، يشير التباين إلى أن الاعتماد تغير بصورة ملموسة بين منتصف 2025 ومايو 2026، خصوصًا لدى مواقع المطورين وSaaS والسحابة والأمن والمواقع الغنية بالوثائق.
| المصدر | اللقطة الزمنية | العينة | الاعتماد الصالح المعلن | التفسير |
|---|---|---|---|---|
| Rankability | 22 يونيو 2025 | أفضل 1,000 موقع | 0.3% | مؤشر عام مبكر يُظهر اعتمادًا ضئيلًا في منتصف 2025. |
| هذه الدراسة | 6 مايو 2026 | أفضل 1,000 موقع في Tranco | 7.50% | زحف لاحق يُظهر اعتمادًا ظاهرًا بين المواقع عالية الزيارات. |
| هذه الدراسة | 6 مايو 2026 | أفضل 10,000 موقع في Tranco | 5.86% | عينة أوسع تُظهر أن الاعتماد قابل للقياس لكنه لم يصبح سائدًا بعد. |
تجارب الزيارات لا تزال متباينة
نشرت Search Engine Land تحليلًا لعشرة مواقع في يناير 2026 تتبّع المواقع لمدة 90 يومًا قبل التنفيذ و90 يومًا بعده. وأفاد المقال بأن موقعين شهدا زيادات في زيارات الذكاء الاصطناعي بنسبة 12.5% و25%، بينما لم يظهر على ثمانية مواقع أي تحسن قابل للقياس، وتراجع موقع واحد بنسبة 19.7%. وكان التفسير الرئيسي هو الحذر السببي: فحالات النجاح الظاهرة أطلقت أيضًا قوالب جديدة، وأعادت بناء مراكز الموارد، وأضافت جداول مقارنة قابلة للاستخراج، وحصلت على تغطية صحفية، وأصلحت مشكلات تقنية، أو نشرت محتوى جديدًا بنمط الأسئلة الشائعة. ووفق هذا التصور، وثّق llms.txt عملًا أفضل على مستوى المحتوى والبنية التقنية؛ لكنه لم يبدُ أنه سبب النمو بمفرده.
أما تجربة المدونة الشخصية لـRenat Alimbekov فتوصلت إلى نتيجة أكثر إيجابية من خلال ملاحظة أصغر على مستوى الموقع. فقد قارنت بين فترتين مدة كل منهما أربعة أشهر في Yandex.Metrica بعد إضافة كل من llms.txt وllms-full.txt. ارتفعت جلسات الإحالة من أدوات LLM من 75 إلى 92، أي بزيادة 23%، بينما ارتفع عدد المستخدمين من 51 إلى 64. وزادت جلسات Perplexity من 29 إلى 55، في حين انخفضت جلسات ChatGPT من 31 إلى 26. ويشير المنشور نفسه أيضًا إلى أن إجمالي حركة الإحالة نما بوتيرة أسرع، من 160 إلى 290 جلسة، لذلك انخفضت حصة جلسات LLM من 47% إلى 32%.
| نوع الدليل | النتيجة الملاحظة | الملاحظة الأساسية | كيف يؤثر ذلك في هذا التقرير |
|---|---|---|---|
| دراسة Search Engine Land قبل/بعد على 10 مواقع | موقعان ارتفعا، وثمانية لم تتغير بشكل ملحوظ، وموقع واحد تراجع. | الحالات الإيجابية تزامنت مع تغييرات في المحتوى والعلاقات العامة والبنية التقنية. | يدعم التعامل مع llms.txt كبنية تحتية لا كرافعة نمو مستقلة. |
| ملاحظة قبل/بعد في مدونة شخصية لـAlimbekov | ارتفعت جلسات الإحالة من LLM بنسبة 23% خلال فترة ما بعد الإضافة. | لا توجد مجموعة ضابطة؛ إجمالي حركة الإحالة ارتفع 81%، وانخفضت حصة LLM. | يشير إلى احتمال فائدة للمواقع التقنية، خصوصًا عبر Perplexity، لكن السببية غير معزولة. |
| دراسة الاعتماد القائمة على الزحف هنا | 586 ملفًا صالحًا والعديد من التطبيقات المنظمة. | تقيس الوجود والبنية، لا أثر الزيارات اللاحق. | تُظهر الاعتماد ونضج التنفيذ، لكن ليس العائد على الاستثمار بحد ذاته. |
ما الذي يوضحه الجدل
تُحكم الأدلة الخارجية تفسير هذه البيانات. يمكن لملف llms.txt المنظم جيدًا أن يقلل الاحتكاك في تحليل الآلات، خاصةً لوثائق المطورين ومراجع API ومحتوى قواعد المعرفة. لكن أقوى حالات الزيارات لا تزال تبدو معتمدة على محتوى مفيد وقابل للاستخراج وموثوق ويمكن اكتشافه خارج الملف. لذلك فالسؤال العملي ليس «هل يهم llms.txt؟» بمعزل، بل هل يشكل جزءًا من نظام محتوى أوسع قابل للقراءة آليًا.
التفسير المحدّث: ينبغي تنفيذ
llms.txtبوصفه بنية تحتية منخفضة التكلفة موجهة للذكاء الاصطناعي. ولا ينبغي تقديمه بوصفه بديلًا عن التوثيق الأفضل أو المحتوى المنظم أو سهولة الوصول التقنية أو الاستشهادات أو الروابط أو سلطة العلامة التجارية.
جرّب Thunderbit لاستخراج بيانات الويب بالذكاء الاصطناعي
المنهجية
استخدمت هذه الدراسة نطاقات Tranco أفضل 10,000 كعينة. وTranco هو تصنيف بحثي للمواقع الكبرى مصمم ليكون أكثر استقرارًا ومقاومة للتلاعب من كثير من القوائم التقليدية. تم تنزيل ملف مصدر Tranco في 6 مايو 2026، مع طابع Last-Modified للمصدر بتاريخ 5 مايو 2026 الساعة 22:17:59 بتوقيت GMT.
قام الزاحف بفحص مسارين على مستوى الجذر لكل نطاق:
https://example.com/llms.txt، مع الرجوع إلى HTTP عند الحاجة.https://example.com/llms-full.txt، مع الرجوع إلى HTTP عند الحاجة.
ولكل عملية فحص، سجّل الزاحف رمز الحالة، والعنوان النهائي، وطريقة الجلب، وبايتات الاستجابة، ونوع المحتوى، ورسالة الخطأ، والزمن المنقضي، ونتيجة التحقق. وحُفظت أجسام الاستجابة الناجحة ضمن raw_llms_txt/ للمراجعة والتحليل الثانوي.
قواعد التحقق
عُدّ الرد ملفًا صالحًا فقط إذا أعاد جسمًا ناجحًا ولم يكن يبدو كبديل ويب عام. وكان لا بد أن يبقى مسار العنوان النهائي /llms.txt أو /llms-full.txt. كما رُفضت الأجسام الفارغة. ورُفضت مستندات HTML الواضحة وأغلفة التطبيقات. وعُدّ نوع المحتوى دليلًا مساعدًا لا القاعدة الوحيدة، لأن عددًا صغيرًا من الملفات النصية الصالحة قُدم بأنواع محتوى غير معتادة.
مشهد الاعتماد
وجد الزحف 586 ملفًا صالحًا من نوع llms.txt ضمن أفضل 10,000 موقع في Tranco. وهذا يعطي معدل اعتماد صالحًا قدره 5.86%. أما الملف المرافق الأصغر llms-full.txt فكان حاضرًا وصالحًا على 103 نطاقات، أي 1.03% من العينة.
| المؤشر | العدد | الحصة من أفضل 10,000 |
|---|---|---|
| النطاقات التي جرى الزحف إليها | 10,000 | 100.00% |
| ملفات llms.txt الصالحة | 586 | 5.86% |
| ملفات llms-full.txt الصالحة | 103 | 1.03% |
| استجابات HTTP 200 لمسار /llms.txt | 1,606 | 16.06% |
| استجابات HTTP 200 التي رُفضت لعدم الصلاحية | 1,020 | 10.20% |
الاعتماد ليس متركزًا في القمة فقط
كان الاعتماد أعلى في أفضل 1,000 موقع مقارنةً بأفضل 10,000 كاملين، لكنه لم يقتصر على المواقع الأكبر فقط. فقد بلغ معدل الاعتماد في أفضل 1,000 موقع 7.50%. أما الشريحة الأخيرة من 1,000 نطاق، أي المراتب 9,001-10,000، فانخفضت إلى 3.80%. وظل منتصف الترتيب نشطًا: إذ استقرت شرائح 2,001-3,000 و3,001-4,000 و5,001-6,000 و6,001-7,000 جميعها عند نحو 6%.
المعتمدون الأوائل
كان أعلى معتمد صالح تصنيفًا هو Cloudflare عند المرتبة 4 في Tranco. ومن المعتمدين ذوي التصنيف العالي أيضًا Azure وGitHub وDigiCert وWordPress.org وAdobe وSentry وDropbox وPayPal وShopify وTaboola وAvast وWeather.com وOxylabs وSourceForge وCisco وStripe وSlack وDell وNVIDIA وIndeed وZendesk وCalendly وPalo Alto Networks وOkta وBraze وKlaviyo وIntercom وDatadog وCloudinary وClassLink وOneSignal.
وليس هؤلاء المعتمدون عشوائيين. فهم يميلون إلى امتلاك مساحات وثائق كبيرة، وخطوط منتجات تحتاج إلى شرح، وواجهات API أو منظومات للمطورين، ومحتوى دعم، وصفحات تسعير، ومواد أمن وخصوصية، وما يكفي من سلطة العلامة التجارية للاهتمام بكيفية تفسير أنظمة الذكاء الاصطناعي لمواقعهم.
| المرتبة | النطاق | حجم الملف | النمط الملاحظ |
|---|---|---|---|
| 4 | cloudflare.com | 4,225 B | فهرس موجز للمنتج والمطورين والشركة والتسعير. |
| 26 | azure.com | 47,037 B | أدوات المطورين، والذكاء الاصطناعي، والحوسبة، والتخزين، والأمن، والمراقبة، والموارد الاختيارية. |
| 28 | github.com | 27,108 B | وصول برمجي، وCopilot، وMCP، وREST API، وActions، والمستودعات، وروابط CLI. |
| 248 | stripe.com | 64,229 B | المدفوعات، وConnect، وCheckout، وBilling، وTax، وAtlas، وRadar، ووثائق المطورين. |
| 265 | salesforce.com | 1.02 MB | كتالوج ضخم لروابط المنتجات وAgentforce، من دون عناوين أقسام Markdown. |
فئات المعتمدين ضمن أفضل 1,000
صنّفت هذه الدراسة المعتمدين الـ75 الصالحين ضمن أفضل 1,000 موقع في Tranco باستخدام سياق النطاق، والعناوين الأولى، وبنية الملف الخام، وكلمات المحتوى المفتاحية. وكانت أكبر مجموعة هي التسويق والإعلام وadtech بنسبة 22.67%. وبلغت حصة مواقع السحابة والمطورين والبنية التحتية 20.00%. أما SaaS والإنتاجية وعمليات العملاء فبلغت 17.33%. وبلغت حصة الأمن والهوية والخصوصية 12.00%.
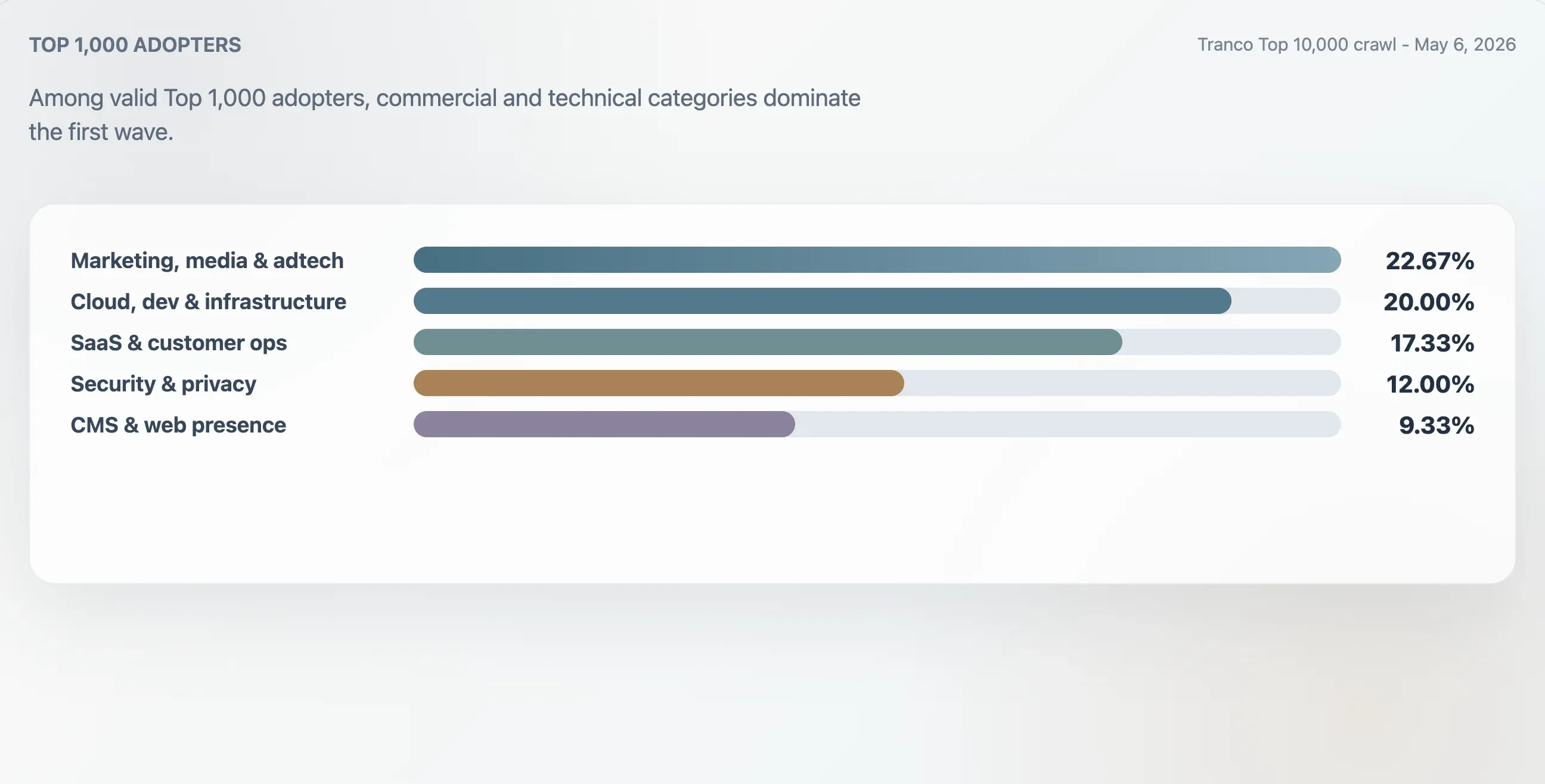
| الفئة | النطاقات | حصة المعتمدين ضمن أفضل 1,000 | وسيط درجة الجودة | وسيط الروابط |
|---|---|---|---|---|
| التسويق والإعلام وadtech | 17 | 22.67% | 94 | 25 |
| السحابة والمطورون والبنية التحتية | 15 | 20.00% | 94 | 62 |
| SaaS والإنتاجية وعمليات العملاء | 13 | 17.33% | 94 | 46 |
| الأمن والهوية والخصوصية | 9 | 12.00% | 98 | 78 |
| CMS والاستضافة والحضور على الويب | 7 | 9.33% | 100 | 24 |
أنماط نطاقات المستوى الأعلى
ليست نطاقات المستوى الأعلى مؤشرات قطاعية، لكنها إشارات اتجاهية مفيدة. ومن بين النطاقات العليا التي تضم ما لا يقل عن 50 نطاقًا في العينة، حقق .io أعلى معدل اعتماد صالح عند 14.44%. وتلاه .com عند 8.19%. أما انخفاض الاعتماد لدى .gov و.edu و.net فيشير إلى أن قاعدة المعتمدين الأوائل تجارية وتقنية أكثر من كونها مؤسسية.
جودة التنفيذ
الاعتماد الصالح لا يعني جودة تنفيذ متجانسة. فبعض الملفات فهارس موجزة ومقسمة جيدًا. وبعضها في الأساس نصوص سردية. وبعضها كتالوجات روابط خام. وبعضها عناصر نائبة شبه فارغة. وبعضها تفريغات محتوى ضخمة قد تكون كاملة لكنها مكلفة في الجلب والتحليل.
ومن بين ملفات llms.txt الصالحة، كان 362 ملفًا أكبر من 5 كيلوبايت، أي 61.77% من المعتمدين الصالحين. وكان حجم الملف الوسيط نحو 7.1 كيلوبايت. وبلغ حجم الملف عند P90 نحو 156 كيلوبايت، وعند P95 356 كيلوبايت، وعند P99 2.54 ميجابايت، وكان أكبر ملف لوحظ 7.97 ميجابايت.
إشارات المحتوى الشائعة
كشف فحص على مستوى الكلمات المفتاحية في الملفات الصالحة أن كثيرًا من المواقع لا تنشر مجرد إعلان، بل توجّه النماذج إلى مواد مفيدة عمليًا. ظهرت مصطلحات الدعم أو المساعدة في 70.31% من الملفات الصالحة. وظهرت مصطلحات المدونة أو الدليل أو البرنامج التعليمي في 67.92%. وظهرت مصطلحات الأمن أو الخصوصية أو الامتثال أو الشروط في 61.43%. وظهرت التسعير في 53.92%، والتوثيق في 52.22%، ومصطلحات API في 33.96%، وإشارات سجل التغييرات أو الإصدارات في 27.30%.
درجات الجودة والأنماط النموذجية
للتقدم من الوجود إلى النضج، أنشأت هذه الدراسة درجة تنفيذ خفيفة الوزن. وتراعي الدرجة نوع المحتوى، وحجم الملف، وبنية Markdown، وعدد الروابط، وتغطية الموضوعات، وعلامات التحذير مثل غياب العناوين، وغياب روابط Markdown، وأنواع المحتوى غير المعتادة، والملفات الصغيرة جدًا، والملفات الكبيرة جدًا، وسلوك تفريغ الروابط. وهذا ليس معيارًا رسميًا، بل نموذج تقييم بحثي لمقارنة التطبيقات المرصودة.
وباستخدام هذا النموذج، صُنّف 416 ملفًا صالحًا على أنها فهارس منظمة قوية، و107 كفهارس قابلة للاستخدام، و24 كملفات رفيعة أو غير منتظمة، و39 كملفات رمزية أو منخفضة الفائدة. وأظهر تحليل منفصل للأنماط النموذجية 296 فهرسًا منظمًا، و113 ملف نص مقسم إلى أقسام، و63 كتالوج روابط، و52 فهرسًا رفيعًا، و50 ملفًا رمزيًا أو عنصرًا نائبًا، و12 تفريغ محتوى ضخمًا.
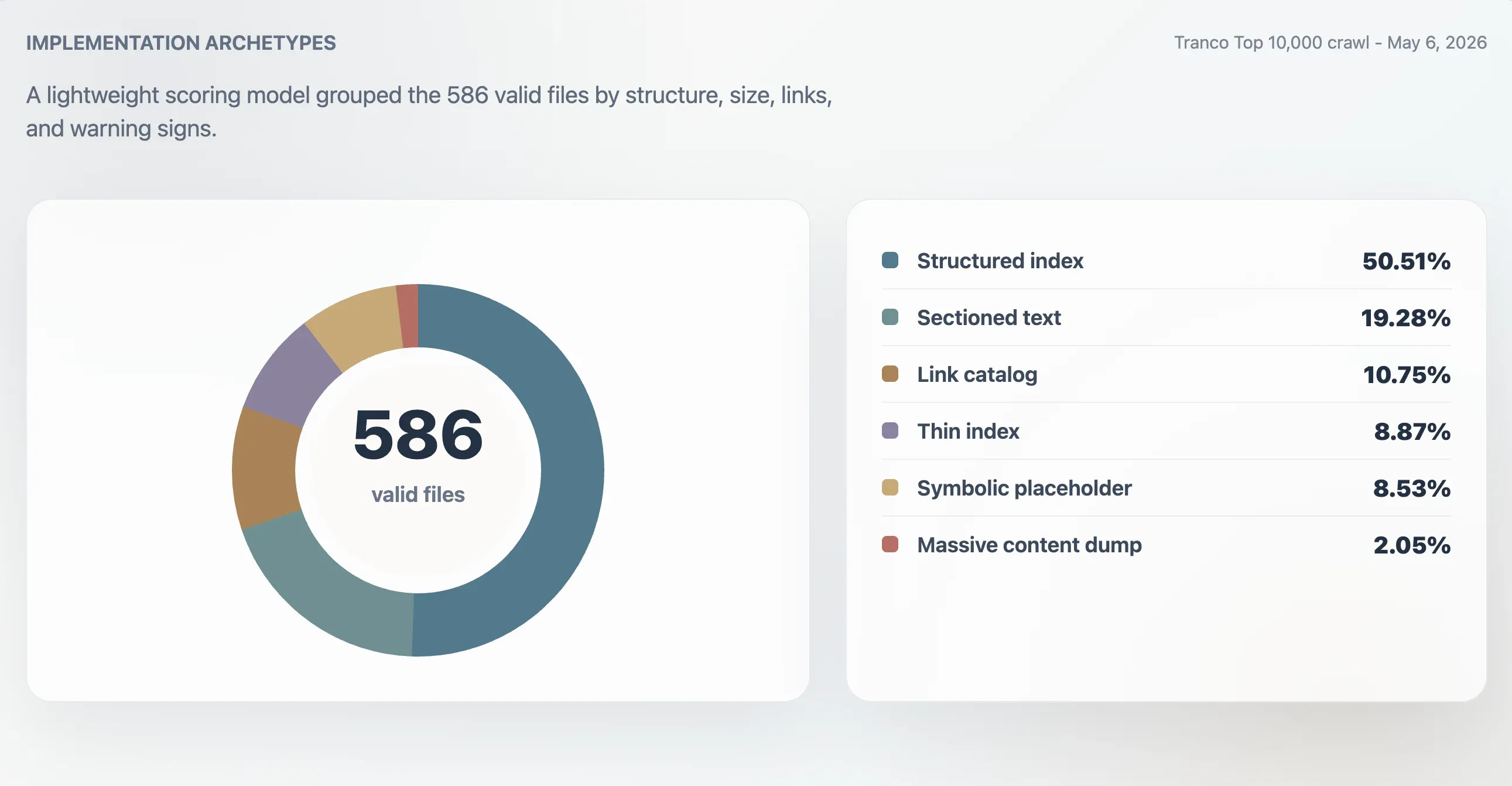
| النمط النموذجي | النطاقات | حصة الملفات الصالحة | وسيط الدرجة | وسيط حجم الملف | وسيط الروابط |
|---|---|---|---|---|---|
| فهرس منظم | 296 | 50.51% | 98 | 11,241 B | 61.5 |
| نص مقسم إلى أقسام | 113 | 19.28% | 78 | 4,718 B | 0 |
| كتالوج روابط | 63 | 10.75% | 86 | 4,160 B | 23 |
| فهرس رفيع | 52 | 8.87% | 66 | 2,814 B | 0 |
| رمزي أو عنصر نائب | 50 | 8.53% | 27 | 15 B | 0 |
| تفريغ محتوى ضخم | 12 | 2.05% | 74 | 2.84 MB | 7,259.5 |
المعتمدون الكبار يمتلكون تنفيذًا أكثر كثافة
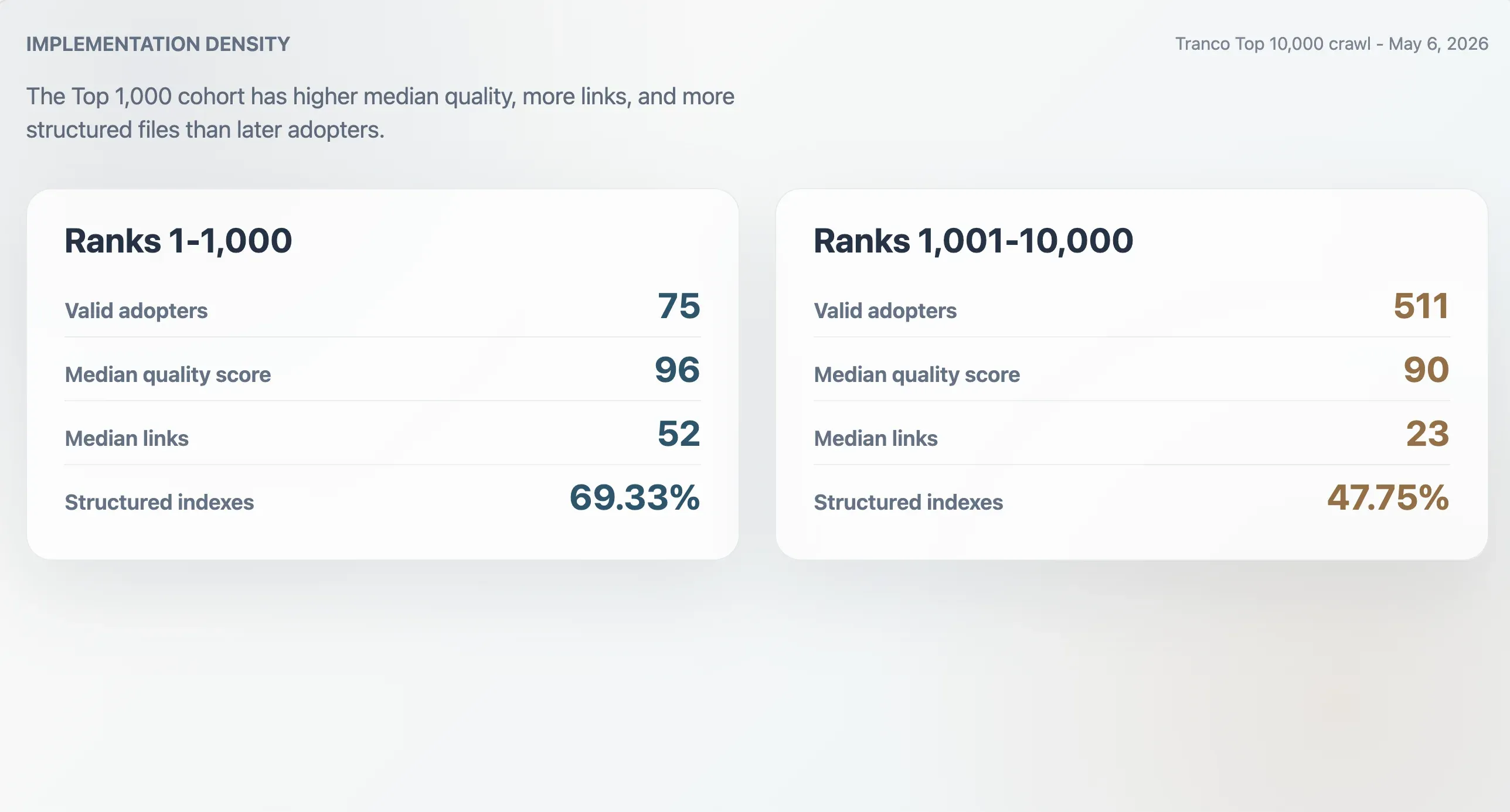
كان لدى المعتمدين الـ75 الصالحين ضمن أفضل 1,000 موقع في Tranco وسيط درجة جودة يبلغ 96، ووسيط حجم ملف 9,068 بايت، ووسيط عدد روابط Markdown قدره 52، ووسيط عدد أقسام قدره 11. أما المعتمدون الـ511 المصنفون بين 1,001 و10,000 فكانت وسائطهم أدنى: 90 للدرجة، و6,506 بايت لحجم الملف، و23 رابط Markdown، و9 أقسام. كما كان معتمدو أفضل 1,000 أكثر احتمالًا لأن يكونوا فهارس منظمة: 69.33% مقابل 47.75% في الفئة اللاحقة.
مشكلة الإيجابيات الكاذبة

أكبر خطر قياسي هو الإيجابيات الكاذبة. فمن بين 1,606 نطاقًا أعادت HTTP 200 لمسار /llms.txt، فشل 1,020 في التحقق. وكان السبب غير الصالح الأكثر شيوعًا هو إعادة التوجيه غير المطابقة، بعدد 618 حالة. كما كانت 367 استجابة أخرى مستندات HTML عامة. و29 استجابة أعادت جسمًا فارغًا، و6 كانت استجابات غير صالحة أخرى أو غير مصنفة.
ويهم هذا لأن كثيرًا من المواقع الكبيرة توجه المسارات المجهولة إلى صفحات تسجيل الدخول أو الصفحات الرئيسية أو أغلفة التطبيقات أو الصفحات الإقليمية أو واجهات الموافقة أو بدائل التسويق. وقد تبدو هذه الاستجابات سليمة لزاحف يعتمد على رمز الحالة، لكنها لا تحتوي على أي إشارة llms.txt صالحة.
llms-full.txt: أندر وأقل اتساقًا
كان الملف المرافق llms-full.txt أقل شيوعًا بكثير من llms.txt. فقد وجد الزحف 103 ملفات كاملة صالحة، أي 17.58% من معتمدي llms.txt الصالحين و1.03% من عينة أفضل 10,000 كاملة.
وكان تنفيذ الملف الكامل غير متسق. فمن بين 103 نطاقات معتمدة على ملفين، كان لدى 57 ملف llms-full.txt أكبر من ملف الفهرس، لكن 46 نطاقًا كان لديهم إما ملف كامل لا يزيد حجمًا على ملف الفهرس أو ملف كامل أقل من 100 بايت. وكان وسيط نسبة الحجم بين الكامل والفهرس 1.43، لكن الحالات المتطرفة كانت أعلى بكثير. فكان ملف Supabase الكامل أكبر بنحو 7,139 مرة من ملف الفهرس. أما Made-in-China.com فكان لديه ملف كامل بحجم 89.89 ميجابايت.
| النطاق | llms.txt | llms-full.txt | النسبة |
|---|---|---|---|
| made-in-china.com | 4.49 MB | 89.89 MB | 20.0x |
| sendbird.com | 281.86 KB | 11.99 MB | 42.5x |
| taboola.com | 286.78 KB | 11.73 MB | 40.9x |
| supabase.co | 1.26 KB | 8.98 MB | 7,139.3x |
| neon.tech | 27.44 KB | 5.01 MB | 182.7x |
التوصية: انشر
llms-full.txtفقط عندما يمتلك الموقع أصلًا خط أنابيب وثائق مستقرًا، وانضباطًا في الإصدارات، وسببًا واضحًا لعرض كميات كبيرة من المحتوى في ملف واحد قابل للقراءة آليًا.
llms.txt وrobots.txt وsitemap.xml
لا ينبغي التعامل مع llms.txt على أنه robots.txt جديد. فكلاهما ملفات قابلة للقراءة آليًا على مستوى الجذر، لكنهما ينقلان أشياء مختلفة. robots.txt إشارة تفضيل زحف وإدارة وصول. وsitemap.xml إشارة لاكتشاف الروابط. أما llms.txt فهو إشارة توضيحية وإرشادية.
| الإشارة | الدور الأساسي | القارئ المعتاد | التفسير في هذه الدراسة |
|---|---|---|---|
robots.txt | إعلان تفضيلات الزحف والقيود على مستوى المسار. | زواحف البحث، وزواحف الذكاء الاصطناعي، وزواحف الأرشفة، والروبوتات العامة. | إشارة حوكمة ووصول. |
sitemap.xml | سرد الروابط القابلة للاكتشاف لأنظمة الفهرسة. | محركات البحث وخطوط فهرسة البيانات. | إشارة اكتشاف. |
llms.txt | توفير سياق مختصر للموقع، وروابط مهمة، ووثائق، وواجهات API، وأمثلة، ومراجع السياسات. | تطبيقات LLM، ووكلاء الذكاء الاصطناعي، وأدوات المطورين، وأنظمة الاسترجاع. | إشارة توضيح وتنقل. |
التوصيات
بالنسبة للمواقع التي تفكر في llms.txt, تشير أقوى التطبيقات في هذه البيانات والأدلة الخارجية المتعلقة بالزيارات إلى نمط عملي:
- انشر
/llms.txtفي الجذر، وابقه متاحًا من دون تسجيل دخول أو تنفيذ JavaScript أو جدران موافقة أو عمليات إعادة توجيه خارج المسار. - قدّمه كـ
text/plainأوtext/markdownعندما يكون ذلك ممكنًا. - ابدأ بوصف قصير للموقع، ثم اجمع الروابط حسب المنتج، والتوثيق، وAPI، والتسعير، وسجل التغييرات، والأمثلة، والدعم، والسياسات، وموارد الشركة.
- فضّل الروابط المعيارية على القوائم الشاملة لكل الروابط.
- تجنب الملفات الرمزية الفارغة؛ فهي لا تعدو أن تكون إشارة ضعيفة في أفضل الأحوال.
- تجنب التفريغات الضخمة غير المميزة إلا إذا كانت هناك حالة استخدام قوية للاستهلاك الآلي وخط توليد موثوق.
- تحقّق من العنوان النهائي، وجسم الاستجابة، ونوع المحتوى، وبنية Markdown، وعدد الروابط، وحجم الملف بعد النشر.
كما ينبغي للفرق ضبط التوقعات بعناية. فالتجارب العامة المتاحة لا تثبت أن llms.txt يزيد وحده زيارات الإحالة من الذكاء الاصطناعي. وإذا أراد فريق ما اختبار الأثر التجاري، فعليه تتبع إحالات LLM، والصفحات المشار إليها، وطلبات الروبوتات، وحداثة الفهرسة، وتغييرات المحتوى معًا. وتجربة مفيدة ستكون مقارنة مجموعات صفحات متطابقة، مع تثبيت تحديثات المحتوى كلما أمكن، وفصل الزيارات الخاصة بكل منصة مثل Perplexity وChatGPT وGemini وClaude وBing/Copilot.
القيود
هذه لقطة قائمة على الزحف، وليست حقيقة نهائية دائمة. يمكن للمواقع إضافة أو إزالة أو تغيير ملفات llms.txt في أي وقت. وقد تحجب بعض النطاقات الطلبات الآلية أو تتصرف بشكل مختلف حسب الجغرافيا أو إعدادات TLS أو منطق إعادة التوجيه أو وكيل المستخدم أو آليات الحماية من الروبوتات. واختبرت الدراسة الملفات على مستوى الجذر فقط ولم تبحث في النطاقات الفرعية أو المسارات غير القياسية.
درجة الجودة والأنماط النموذجية هي أدوات بحثية، وليست تسميات امتثال رسمية. وتحليل الموضوعات قائم على الكلمات المفتاحية، وينبغي قراءته بوصفه توجيهيًا. ولا تثبت الدراسة أن أي منصة ذكاء اصطناعي محددة تقرأ llms.txt أو تحترمه أو تستخدمه حاليًا في بيئة الإنتاج.
كما أن أدلة الزيارات الخارجية التي راجعناها في هذه النسخة لها حدودها أيضًا. فـSearch Engine Land أقوى بوصفه ملاحظة تحذيرية متعددة المواقع منه كونه تجربة عشوائية. أما نتيجة Alimbekov فهي مفيدة بوصفها دراسة حالة شفافة على مستوى الموقع، لكنها تفتقر إلى مجموعة ضابطة وتتضمن فترة ارتفع فيها إجمالي زيارات الإحالة بشكل ملحوظ. وتساعد هذه المراجع في تأطير الجدل، لكنها لا تجعل من هذا الزحف دراسة سببية للزيارات.
الملفات وقابلية إعادة الإنتاج
| الملف | الغرض |
|---|---|
crawl_llms_txt.py | زاحف لـ/llms.txt و/llms-full.txt. |
analyze_llms_txt.py | التحليل الأساسي للاعتماد وتوليد الرسوم البيانية. |
deep_analyze_llms_txt.py | تحليل ثانوي لشرائح الترتيب العشرية، ونطاقات TLD، وإشارات الموضوع، ودرجات الجودة، والأنماط النموذجية، وسلوك الملفين. |
deep_dive_early_quality.py | تصنيف المعتمدين الأوائل وغوص عميق في جودة التنفيذ. |
data/llms_probe_results_top_10000.csv | مجموعة بيانات نتائج الزحف الرئيسية. |
data/deep_analysis_top_10000.json | ملخص التحليل الثانوي. |
data/deep_early_quality_analysis.json | فئات المعتمدين الأوائل، ومقارنة جودة الشرائح، وتفاصيل الأنماط النموذجية، ودراسات الحالة. |
المصادر
- ملف /llms.txt، Jeremy Howard، 2024.
- منهجية HTTP Archive Web Almanac 2024.
- Cloudflare Radar: Expanded AI insights.
- Cloudflare Radar AI Insights.
- الموافقة في أزمة: التراجع السريع عن المشاع البياناتي للذكاء الاصطناعي، Data Provenance Initiative.
- Tranco: ترتيب بحثي للمواقع الكبرى مقاوم للتلاعب.
- هل يهم llms.txt؟، Search Engine Land، يناير 2026.
- حالة اعتماد llms.txt، Rankability، يونيو 2025.
- كيف زاد LLMS.txt زيارات دردشة الذكاء الاصطناعي بنسبة 23%، Renat Alimbekov.
نرحب بتصحيحات المنهجية، ومشكلات البيانات، والتحليلات اللاحقة عبر support@thunderbit.com. يُنشر هذا التقرير بشكل مستقل عن أي موقف تجاري تتخذه Thunderbit. البيانات الواردة في هذا التقرير قائمة بذاتها. — فريق Thunderbit البحثي، مايو 2026.
جرّب Thunderbit لاستخراج وتحليل بيانات الويب Get Started Free




