
دعني أقول لك «꿀팁» صغير: الإنترنت فعليًا أكبر مكتبة في العالم، بس كثير من «الكتب» فيها كأنها 잠겨 있어 (مقفولة بإحكام). يوميًا أتكلم مع أصحاب بزنس، مسوّقين، وفرق مبيعات يعرفون إن داخل صفحات الويب كنز حقيقي—مواصفات منتجات، أسعار منافسين، 리뷰 العملاء، وبيانات تواصل—لكن لما يجي وقت استخراج النص من موقع؟ هنا تبدأ الدوخة. اشتغلت سنين في عالم SaaS والأتمتة، وشفت كل شيء: من «ماراثون Ctrl+C / Ctrl+V» إلى «تجارب Python البيتية» اللي تنتهي بنص ناقص أو جدول متكسّر. الزين؟ اليوم صار استخراج النص من موقع أسهل بكثير (وأقل وجع راس) من أي وقت مضى، بفضل أدوات Web Scraper المدعومة بالذكاء الاصطناعي وإضافات المتصفح اللي صارت أذكى بفرق.
في هذا الدليل، بشاركك كل الطرق العملية اللي أعرفها—من النسخ واللصق البسيط إلى حلول متقدمة بالذكاء الاصطناعي مثل Thunderbit (إيه، هذا منتج فريقنا، بس بكون صريح معك في المزايا والعيوب). سواء كنت شاطر في الجداول، أو مطوّر يحب يكتب كود، أو شخص طفح الكيل من التحديق في صفحات الويب، بتلقى هنا خطوات واضحة على قدّ احتياجك. يلا نفتح هالـ«كتب الرقمية» ونطلع النص اللي تدور عليه.
ماذا يعني استخراج النص من موقع إلكتروني؟
لما نقول «استخراج النص من موقع»، نقصد سحب المعلومات اللي تشوفها (وأحيانًا اللي ما تشوفها) من صفحة ويب وتحويلها لصيغة تقدر تستخدمها—مثل Spreadsheet، قاعدة بيانات، أو حتى ملف Word مرتب. بس مو كل نص على المواقع نفس الشي:
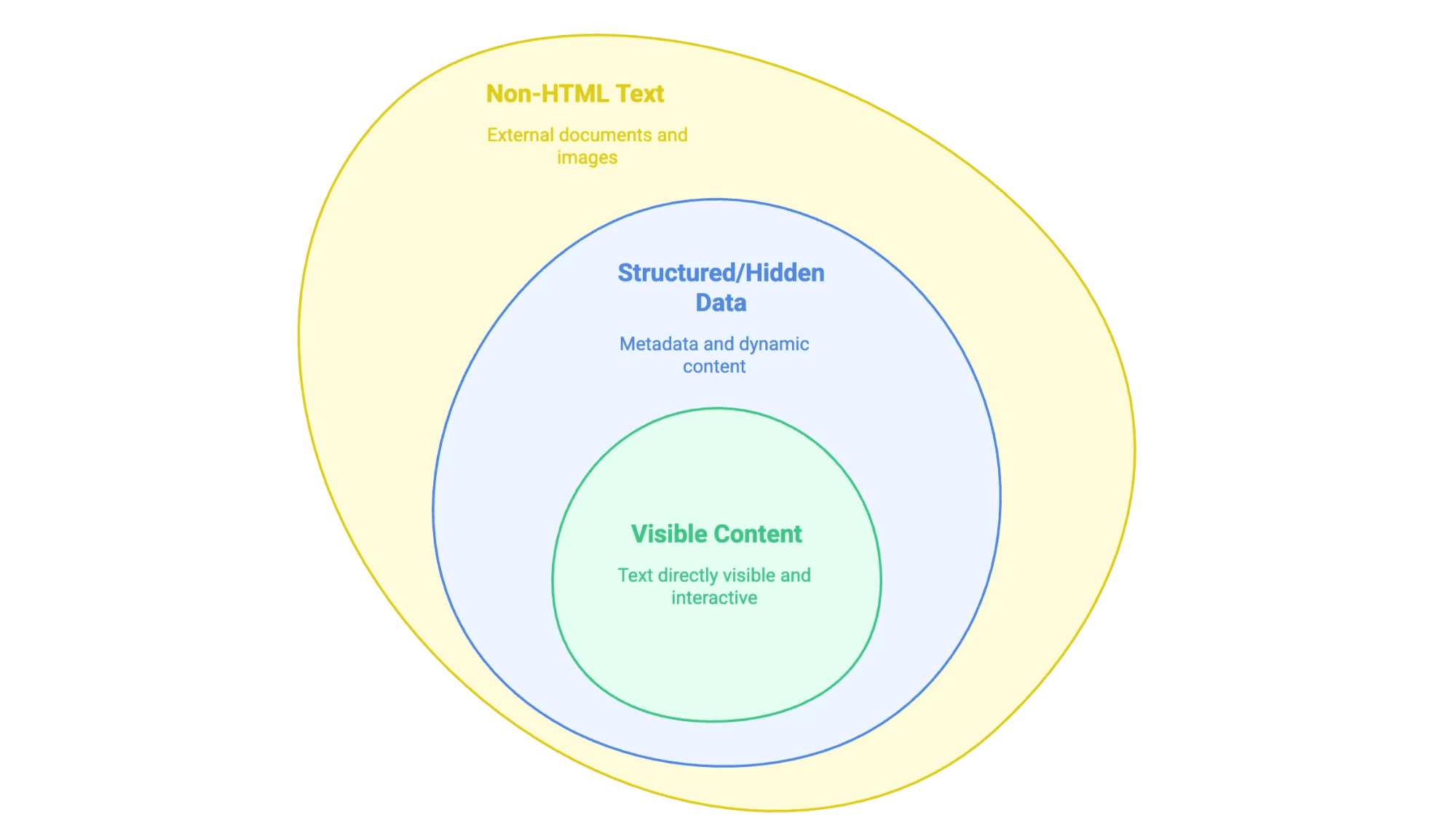
- المحتوى الظاهر: هذا النص اللي تقدر تحدده بالماوس—نصوص المقالات، العناوين، القوائم، الجداول، أوصاف المنتجات، التدوينات… إلخ.
- بيانات منظّمة أو مخفية: مثل البيانات الوصفية داخل وسوم
<meta>، أو سكربتات JSON-LD، أو معلومات تُحمَّل عبر JavaScript وما تبان إلا بعد 클릭 (نقرة) أو 스크롤 (تمرير). - نص خارج HTML: مثل ملفات PDF وWord، وحتى الصور اللي فيها نص (زي العقود الممسوحة ضوئيًا أو الإنفوغرافيك) المرتبطة بالموقع أو المضمّنة فيه.
الخلاصة: لازم تحدد نوع النص اللي تبيه، لأن كل نوع له طريقة استخراج مختلفة.
لماذا نحتاج لاستخراج النص من المواقع؟ فوائد للأعمال وحالات استخدام
خلّنا نكون واقعيين: ما أحد يسوي استخراج نصوص المواقع للتسلية (إلا إذا عندك هوايات غريبة جدًا). الشركات تسويه لأن العائد واضح. سوق برمجيات جمع البيانات من الويب تعدّى مليار دولار في 2024، ولسه يكبر. وهذه أهم الأسباب:
| الفريق | مثال على حالة استخدام | الفائدة |
|---|---|---|
| المبيعات | جمع بيانات الأدلة للحصول على عملاء محتملين ومعلومات تواصل | تنقيب أسرع وأغنى عن العملاء المحتملين |
| التسويق | استخراج مقالات المنافسين وبيانات SEO | تحليل فجوات المحتوى ورصد الاتجاهات |
| العمليات | مراقبة أسعار المنتجات عبر مواقع التجارة الإلكترونية | تسعير ديناميكي وتتبع المخزون |
| العقارات | تجميع الإعلانات وتفاصيل العقارات | تحليل السوق وتوليد العملاء المحتملين |
| الدعم | جمع تقييمات العملاء وأسئلة/أجوبة المنتديات | تحليل المشاعر واكتشاف المشكلات مبكرًا |
بعض النتائج الواقعية:

- توليد العملاء المحتملين: شركة توريد لمستلزمات المطاعم أنشأت قوائم عملاء محتملين خلال دقائق بدلًا من أيام.
- مراقبة المنافسين: تجار تجزئة مثل John Lewis رفعوا المبيعات بنسبة 4% باستخدام بيانات الأسعار المستخرجة.
- تحليل SEO: فرق تستخرج وسوم الميتا والكلمات المفتاحية لـتوجيه الاستراتيجية.
ومع الأدوات المعتمدة على الذكاء الاصطناعي، صارت الشركات توفر 30–40% من وقت جمع البيانات مقارنة بالأساليب التقليدية.
الطرق اليدوية: أساسيات نسخ ولصق نصوص المواقع
نبدأ من الـ기본 (الأساس). أحيانًا كل اللي تحتاجه مقتطف سريع—بدون أي أدوات.
كيفية استخراج النص يدويًا
- النسخ واللصق: افتح الصفحة، حدّد النص، ثم Ctrl+C (أو زر يمين > Copy). بعدها الصقه في مستندك أو جدول البيانات.
- حفظ الصفحة: من المتصفح اختر File > Save Page As. احفظها كـ “Webpage, HTML only” للحصول على HTML الخام، أو أحيانًا كملف .txt لاستخراج النص فقط.
- الطباعة إلى PDF: استخدم نافذة الطباعة واختر “Save as PDF”. ثم افتح ملف PDF وانسخ النص (أو استخدم خيار “Save as Text” في قارئ PDF).
- أدوات المطور: زر يمين > Inspect أو F12 لفتح DevTools. تقدر تشوف مصدر HTML، وتبحث عن وسوم meta أو JSON مخفي، ثم تنسخ اللي تحتاجه.
القيود
الاستخراج اليدوي ينفع للمهام الصغيرة، بس يصير nightmare مع أي شيء أكبر. لأنه يستهلك وقتًا، ويزيد الأخطاء، ولا يمكن توسيعه بسهولة. صدقني، شفت متدربين يقعدون أيام ينسخون الجداول صف صف—ولا أحد يبي هالشغل.
استخدام إضافات المتصفح والأدوات عبر الإنترنت لاستخراج النص من المواقع
تبي خطوة قدّام؟ إضافات المتصفح والأدوات الأونلاين هي الخيار «딱 좋아» لمعظم مستخدمي الأعمال: بدون كود، وبدون تعقيد—بس حدّد وانقر.
لماذا تستخدم هذه الأدوات؟

- أسرع من النسخ واللصق اليدوي
- ما تحتاج خبرة برمجية
- تتعامل مع الجداول والقوائم وأحيانًا الملفات
- تصدير إلى Excel وGoogle Sheets وCSV وغيرها
خلّنا نمر على أشهر الخيارات.
Thunderbit: AI Web Scraper لاستخراج النص بسرعة ودقة
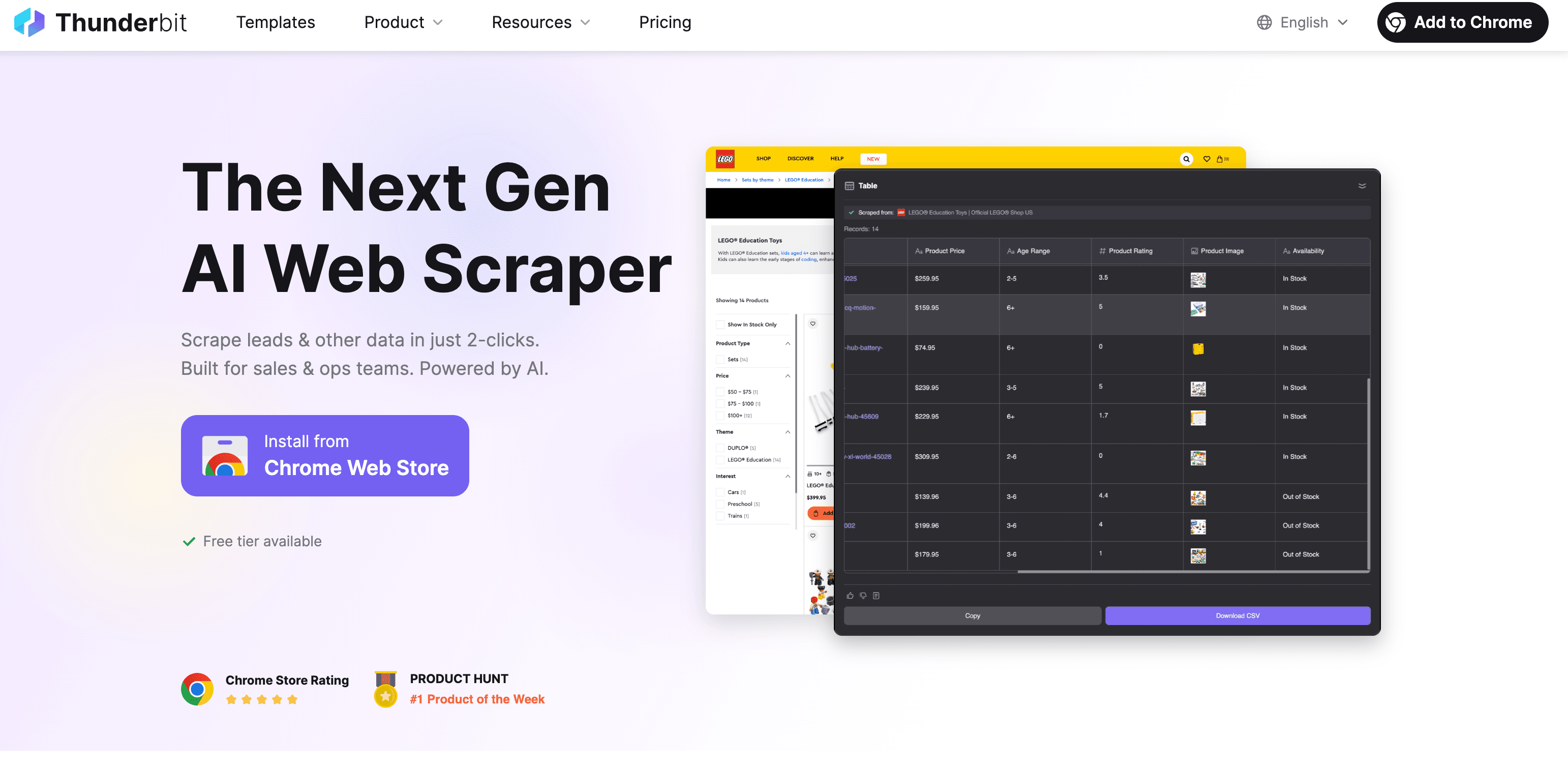
يمكن أكون منحاز شوي، بس Thunderbit فعلًا معمول عشان يخلي استخراج النص من موقع سهل مثل طلب توصيل. الفكرة بسيطة:
خطوة بخطوة: استخراج النص باستخدام Thunderbit
- تثبيت إضافة Chrome: حمّل Thunderbit من متجر Chrome.
- افتح الموقع: روح للصفحة اللي تبي استخراج النص منها.
- انقر “AI Suggest Fields”: الذكاء الاصطناعي في Thunderbit يمسح الصفحة ويقترح الحقول (الأعمدة) المناسبة للاستخراج—مثل اسم المنتج والسعر والوصف…
- راجع وعدّل: تقدر تعدّل الحقول المقترحة أو تضيف حقولك.
- انقر “Scrape”: يجمع Thunderbit البيانات، حتى من الصفحات الفرعية أو القوائم متعددة الصفحات إذا احتجت.
- التصدير: نزّل البيانات إلى Excel أو Google Sheets أو Airtable أو Notion أو بصيغة CSV/JSON. بدون رسوم إضافية على التصدير.
استخرج نصوص المواقع باستخدام Thunderbit
ما الذي يميّز Thunderbit؟
- اقتراح الحقول بالذكاء الاصطناعي: ما تحتاج تتعامل مع selectors ولا تكتب كود. الذكاء الاصطناعي يلقط المهم في الصفحة.
- يدعم الصفحات الفرعية وتعدد الصفحات: تحتاج تفاصيل كل منتج داخل قسم؟ Thunderbit يتنقل تلقائيًا.
- استخراج من PDF والصور والمستندات: عندك دليل PDF أو صورة فيها مواصفات؟ OCR المدمج في Thunderbit يطلع النص منها بعد.
- دعم متعدد اللغات: يشتغل بـ 34 لغة (لسه ننتظر لغة Klingon، بس قاعدين نحاول).
- تصدير البيانات مجانًا: ما فيه «paywall» عشان تطلع بياناتك.
- حالات استخدام: أوصاف المنتجات، معلومات التواصل، محتوى المدونات، قوائم العملاء المحتملين… إلخ.
كيفية Scrape Amazon للمنتجات والمراجعات في 2025 باستخدام الذكاء الاصطناعي Get Started Free
تبي تشوفه على أرض الواقع؟ لف على Thunderbit Blog وبتلقى أدلة مثل How to Scrape Amazon Products and Reviews in 2025 using AI.
إضافات وأدوات أخرى عبر الإنترنت
هذه بعض الأدوات اللي غالبًا بتصادفها:
- Web Scraper (webscraper.io): مجاني ويعتمد على النقر والاختيار، بس يحتاج شوية تعلّم. مناسب للمحللين التقنيين لأنه يتطلب إعداد “sitemaps” وselectors. يدعم تعدد الصفحات، لكنه ما يتعامل مع PDF أو الصور. تفاصيل أكثر هنا.
- CopyTables: بسيط جدًا—ينسخ جداول HTML للحافظة أو Excel. ممتاز إذا تبي تلتقط جدول بسرعة لمرة واحدة، لكنه يشتغل صفحة بصفحة وفقط للجداول. شاهد كيف يعمل.
- ScraperAPI (ScraperAPI Pricing): موجّه للمطورين. ترسل رابط URL ويرجع لك HTML (مع التعامل مع البروكسي والحظر…)، لكن لسه أنت لازم تستخرج النص وتحلله بنفسك. اقرأ المزيد.
متى تستخدم أي أداة؟
- Thunderbit: إذا تبي السرعة، ومساعدة الذكاء الاصطناعي، ودعم صيغ متعددة (بما فيها PDF/الصور).
- Web Scraper: إذا تحب الـ세팅 والتجربة وتبي تحكم أكثر.
- CopyTables: إذا تبي جدول فقط وبسرعة.
- ScraperAPI: إذا بتبني Web Scraper خاص فيك بالكود.
Web Scraping آلي: حلول برمجية لاستخراج نصوص المواقع
إذا كنت مطوّر (أو عندك مطوّر في الفريق)، بناء Web Scraper بالكود يعطيك أعلى مستوى تحكم. سير العمل غالبًا يكون كذا:
- إرسال طلب HTTP: استخدم
requestsفي Python أو غيره لجلب الصفحة. - تحليل HTML: استخدم
BeautifulSoupأوlxmlأوScrapyعشان تحدد النص المطلوب. - الاستخراج والتصدير: استخرج النص، نظّفه، ثم خزّنه في CSV أو JSON أو قاعدة بيانات.
مثال: Python + Beautiful Soup
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
for qt in quotes:
print(qt)
المزايا والعيوب
- المزايا: مرونة قصوى، يقدر يتعامل مع أي موقع أو نوع بيانات، وسهل تدمجه مع أنظمتك.
- العيوب: يحتاج مهارة برمجية، وصيانة مستمرة، والتعامل مع أنظمة منع البوتات.
متى تختار هذا المسار؟
- إذا تحتاج استخراج آلاف (أو ملايين) الصفحات.
- إذا الموقع معقد (تسجيل دخول، نماذج متعددة الخطوات).
- إذا تبي تدمج الاستخراج مباشرة داخل تطبيقك أو سير عملك.
استخراج النص من صيغ غير HTML: ملفات PDF وWord والصور
المواقع مو بس HTML—مليانة PDF وWord وصور فيها نصوص «gold» فعلًا. وهذا كيف توصل لها:
ملفات PDF
- PDF نصي: استخدم أدوات مثل Adobe Acrobat، أو مكتبات مثل
PDFMinerأوPyPDF2لاستخراج النص. - PDF ممسوح ضوئيًا: استخدم OCR (التعرّف الضوئي على الحروف) مثل Tesseract، أو Google Cloud Vision API، أو AWS Textract.
ملفات Word/Excel
- Word: استخدم
python-docxلقراءة ملفات .docx. - Excel: استخدم
openpyxlأوpandasلملفات .xlsx.
الصور
- أدوات OCR: Tesseract خيار مفتوح المصدر، أو خدمات سحابية لدقة أعلى. أفضل النتائج غالبًا مع صور جودة عالية (150–300 DPI).
نهج Thunderbit
ميزة “Image/Document Parser” تخليك ترفع ملف PDF أو صورة أو مستند (أو تحط رابط له)، والذكاء الاصطناعي يستخرج النص (وقد يقترح أعمدة إذا اكتشف جدولًا). بدل ما تتنقل بين أدوات كثيرة—تعامل مع الملفات كأنها صفحة ويب.
مقارنة جميع الطرق: ما الحل الأنسب لك لاستخراج النص؟
هذه مقارنة سريعة تساعدك تختار:
| الطريقة | سهولة الاستخدام | قابلية التوسع | المهارة التقنية المطلوبة | أنواع البيانات المدعومة | الأفضل لـ |
|---|---|---|---|---|---|
| يدوي (نسخ/لصق) | سهل جدًا | منخفضة | لا شيء | نص ظاهر فقط | مهام صغيرة ولمرة واحدة |
| إضافات/أدوات المتصفح | سهل–متوسط | متوسطة | منخفضة–متوسطة | HTML وبعض الجداول | غير التقنيين، مهام صغيرة–متوسطة |
| أدوات الذكاء الاصطناعي (Thunderbit) | سهل جدًا | عالية | لا شيء | HTML وPDF وصور وغيرها | مستخدمو الأعمال، محتوى متنوع |
| البرمجة (كود) | صعب | عالية جدًا | عالية | أي نوع (مع المكتبات المناسبة) | المطورون، المشاريع الضخمة |
| استخراج غير HTML (OCR) | متوسط | منخفضة–متوسطة | متوسطة | PDF وصور ومستندات | عندما تكون الملفات/الصور هي الأساس |
إذا تبي أسرع طريق، وأكثره مرونة، وأقلّه توترًا—خصوصًا للاستخدام التجاري—فأدوات الذكاء الاصطناعي مثل Thunderbit صعب أحد ينافسها. أما إذا تحتاج تحكم 100% أو شغلك على نطاق ضخم، فالحل البرمجي غالبًا هو الأنسب.
أهم الخلاصات: ابدأ استخراج النص من المواقع اليوم
- الويب مليان نصوص وبيانات قيّمة، بس الوصول لها مو دائمًا مباشر.
- الطرق اليدوية تنفع للمهام الصغيرة جدًا، لكنها ما تتوسع.
- إضافات المتصفح وAI Web Scraper مثل Thunderbit تخلي استخراج النص سريع ودقيق ومتاح للجميع—بدون برمجة.
- للمحتوى غير HTML (PDF/الصور)، دور على أدوات فيها OCR وتحليل مستندات.
- اختَر الطريقة اللي تناسب مهارات فريقك، وحجم مشروعك، وأنواع البيانات اللي تحتاجها.
جرّب Thunderbit AI Web Scraper مجانًا
استخراجًا موفقًا—وخَلّ أيام Ctrl+C تقل كثير. مع الأدوات الصح، جمع بيانات الويب يصير عملية سلسة ومؤتمتة وتوفّر وقتك للأهم. لا مزيد من ساعات النسخ واللصق الطويلة—بس حلول ذكية وفعّالة بين يدينك. حان وقت تترك الشغل اليدوي وتدخل على مستقبل أكثر إنتاجية.
الأسئلة الشائعة
س1: هل يمكنني استخراج البيانات من أي موقع؟
ج1: مو دائمًا. بعض المواقع تمنع أدوات الاستخراج أو تحط شروط استخدام تمنع هذا. راجع سياسات الموقع أولًا.
س2: ما مدى دقة أدوات Web Scraper المعتمدة على الذكاء الاصطناعي؟
ج2: أدوات مثل Thunderbit دقيقة جدًا، لكن ممكن تحتاج تعديلات بسيطة إذا الصفحة معقدة أو ديناميكية بشكل قوي.
س3: هل أحتاج مهارات برمجية لاستخدام أدوات Web Scraping؟
ج3: لا. أدوات مثل Thunderbit وإضافات المتصفح الثانية معمولة لغير التقنيين وما تحتاج برمجة.
س4: ما أنواع البيانات التي يمكن استخراجها من PDF أو الصور؟
ج4: أدوات OCR تقدر تستخرج النص والجداول، وأحيانًا بيانات مو ظاهرة من ملفات PDF الممسوحة ضوئيًا والصور، وهذا يخلي الاستخراج أكثر مرونة.
اقرأ المزيد
- الدليل الشامل لاستخراج النصوص
- How to Scrape Any Website Using AI
- Learn How to Use AI for Web Scraping
جرّب AI Web Scraper Get Started Free




