

تصل Temu الآن إلى أكثر من 416 مليون مستخدم نشط شهريًا عبر أكثر من 50 سوقًا. يمتد كتالوج منتجاتها من أدوات المطبخ إلى ملحقات الحيوانات الأليفة إلى شرائط LED. إذا كنت تعمل في التجارة الإلكترونية أو الدروبشيبينغ أو استخبارات المنافسين، فربما أردت سحب بيانات Temu إلى جدول بيانات — ثم اكتشفت أن Temu لا تريد ذلك فعلًا، وبشدة.
قضيت وقتًا طويلًا في البحث واختبار أدوات الاستخراج للمواقع التجارية المحمية. Temu من أصعب الأهداف الموجودة. معظم الأدلة على الإنترنت إما تعطيك شرحًا بلغة Python يتعطل خلال أسبوع، أو توجهك إلى واجهات برمجة تطبيقات مؤسسية تكلف أكثر من ميزانية إعلانك الشهرية.
الحقيقة أن معظم مستخدمي الأعمال — من العاملين في الدروبشيبينغ، والمشغلين المستقلين، وفرق التسويق — يريدون فقط جدول بيانات نظيفًا بأسماء المنتجات والأسعار والصور والتقييمات ومعلومات البائع. لا يريدون تصحيح أخطاء Playwright عند الثانية صباحًا.
هذا الدليل مبني على هذه الفجوة: تفكيك عملي ومنظم حسب مستوى المهارة لأفضل أدوات استخراج بيانات Temu التي تعمل فعلًا في 2026، بالإضافة إلى أفضل الممارسات التي تحوّل عملية استخراج خامة إلى استخبارات تنافسية مستمرة. سواء كنت مبتدئًا تمامًا أو مطورًا يبني خط بيانات، فستجد هنا ما يناسبك.
جرّب Thunderbit لاستخراج بيانات Temu
لماذا نستخدم استخراج بيانات Temu؟ أبرز حالات الاستخدام لفرق الأعمال
بيانات Temu ليست مجرد شيء مثير للاهتمام — بل ذات قيمة استراتيجية.
أصبحت المنصة قوة مؤثرة في تسعير المنتجات منخفضة ومتوسطة السعر. حتى لو لم تبيع على Temu، فإن عملاءك يقارنون أسعارك بما يرونه هناك. إليك كيف تستخدم الفرق المختلفة بيانات Temu:
| حالة الاستخدام | البيانات المطلوبة | أهمية ذلك |
|---|---|---|
| أبحاث منتجات الدروبشيبينغ | العنوان، السعر، الصورة، التقييم، عدد المراجعات، عدد المبيعات، المتغيرات | يعثر على منتجات منخفضة التكلفة مع مؤشرات طلب للمقارنة عبر Amazon وShopify وAliExpress وTikTok Shop |
| التسعير التنافسي | السعر الحالي، السعر الأصلي، نسبة الخصم، العملة، الشحن، الطابع الزمني | يبني خط أساس لاستراتيجية التسعير وتخطيط العروض الترويجية |
| توريد المنتجات | المواصفات، الصور، المتغيرات، البائع/المتجر، معرف المنتج، الفئة | يحدد أنواع المنتجات وقوائم الطابع التوريدي التي تستحق تحققًا أعمق |
| تحليل اتجاهات السوق | كلمة البحث، الفئة، عدد المبيعات، عدد المراجعات، التقييم | يوضح أي المنتجات تكتسب زخمًا عبر الفئات |
| التسويق والبحث الإبداعي | العنوان، الصورة، عدد المراجعات، التقييم، الأوصاف، تسميات الفئات | يكشف الرسائل والزاويا البصرية والباقات والادعاءات المستخدمة في القوائم عالية الحجم |
| مراقبة المخزون والتوافر | رابط المنتج، التوافر، تقدير الشحن، السعر، الطابع الزمني | يلتقط نفاد المخزون، وتغيرات المستودع المحلي، وحركات الأسعار بمرور الوقت |
الجمهور الذي يبحث عن "أفضل أدوات استخراج بيانات Temu" ينقسم عادة إلى ثلاث فئات. المستخدمون غير التقنيين يريدون إضافة Chrome تصدّر جدول بيانات. المشغلون شبه التقنيين يريدون أداة مرئية مع قوالب وجدولة. المطورون يريدون واجهة API، ونص Playwright، واستراتيجية بروكسي.
يغطي هذا المقال الفئات الثلاث — لكنه يبدأ بأكبرها: الأشخاص الذين يحتاجون إلى البيانات، لا إلى الكود.
ما الذي يميز أفضل أدوات استخراج بيانات Temu في 2026؟
الأداة التي تتعامل مع Amazon أو Shopify لن تنجو بالضرورة مع Temu. معايير التقييم في هذا المقال هي:
- الاعتمادية على Temu — هل تعيد بيانات نظيفة فعلًا، أم يتم حجبها، أو ترجع صفوفًا فارغة، أو تتعطل بعد تغيير التخطيط؟
- سهولة الاستخدام — هل يمكن لمستخدم أعمال غير تقني أن يبدأ دون كتابة كود؟
- اكتمال البيانات — هل تدعم إثراء الصفحات الفرعية (زيارة صفحة تفاصيل كل منتج للحصول على المواصفات والمتغيرات ومعلومات البائع)؟
- عبء الصيانة — هل تتكيف عندما تغيّر Temu بنية صفحاتها؟
- الجدولة والمراقبة — هل يمكنها تشغيل عمليات استخراج متكررة والتصدير إلى وجهة بيانات حية؟
- وجهات التصدير — CSV، Excel، Google Sheets، Airtable، Notion، JSON؟
- وضوح التكلفة — ما التكلفة الشهرية الواقعية لسير عمل استخراج Temu؟
تشير تقارير المجتمع على r/webscraping في Reddit باستمرار إلى أن Temu من أصعب مواقع التجارة الإلكترونية للاستخراج. كتب أحد المستخدمين أنه "لا يستطيع حتى الحصول على سعر كمشترٍ"، بينما أشار آخر إلى أن Temu وShopee لديهما فرق تعمل باستمرار على تقوية آليات مكافحة الروبوتات. لا توجد بيانات معيارية عامة لمعدل الفشل الخاص بـTemu، لكن تقرير Imperva Bad Bot لعام 2025 وجد أن الزيارات الآلية تجاوزت الزيارات البشرية، حيث شكّلت الروبوتات 51% من إجمالي حركة الإنترنت. هذا هو السياق الذي تدافع Temu ضده.
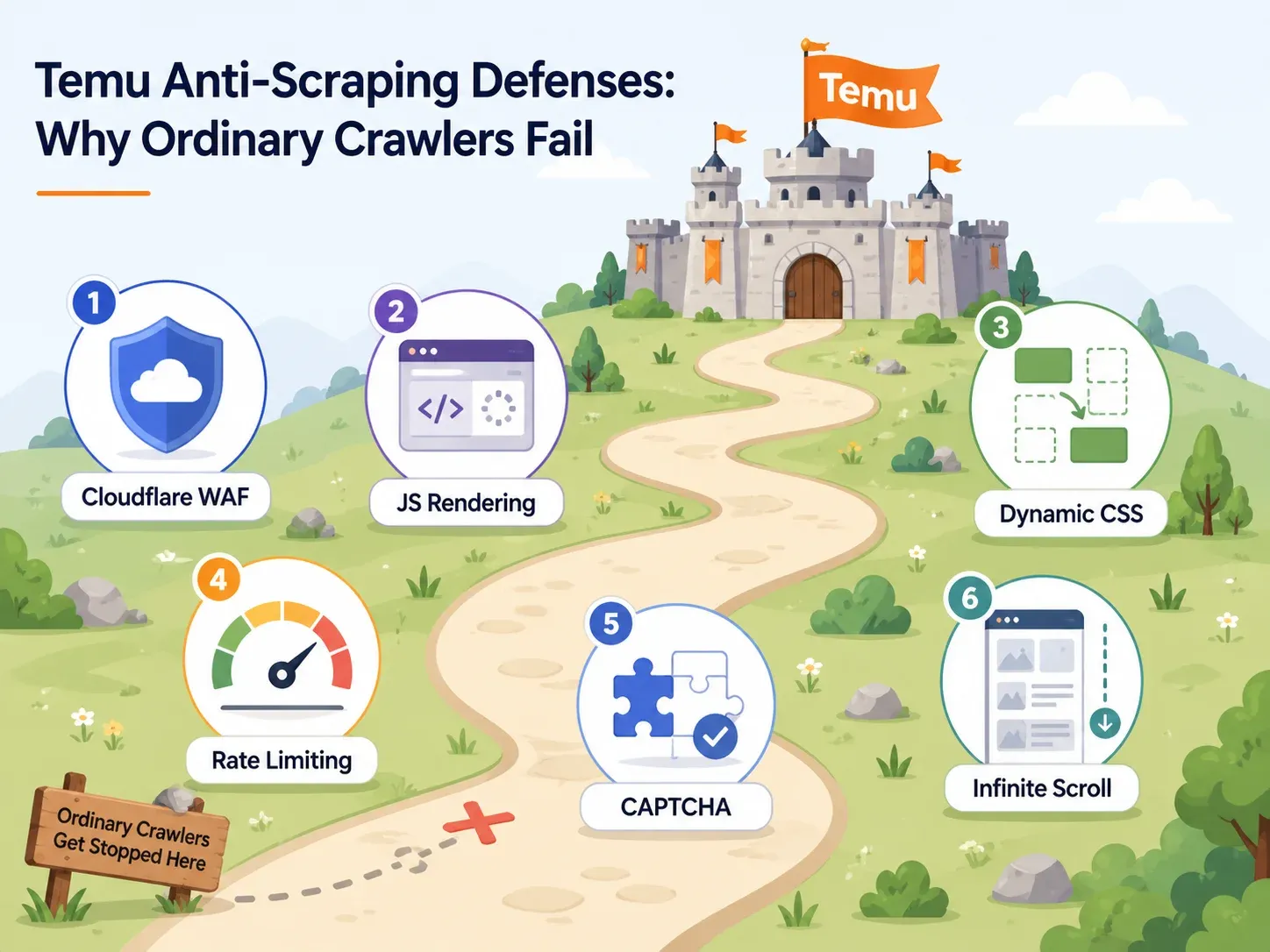
دفاعات Temu ضد الروبوتات: لماذا تفشل معظم أدوات الاستخراج
معظم المقالات عن استخراج بيانات Temu تخصص جملة واحدة فقط لإجراءات مكافحة الروبوتات: "Temu تستخدم مكافحة الروبوتات." هذا غير مفيد.
إذا كنت تختار أداة، فأنت بحاجة إلى معرفة أي الدفاعات تستخدمها Temu وأي قدرات في الأداة تكسر كل واحدة منها. إليك الخريطة العملية:
| دفاع Temu | ما الذي يفعله | القدرة المطلوبة في الأداة | أمثلة على الأدوات |
|---|---|---|---|
| جدار حماية Cloudflare / فحوصات المتصفح | يحجب وكلاء المستخدم الآليين، ويُعرّف بصمة الروبوتات، ويعرض صفحات تحدٍ | بنية سحابية مع عناوين IP سكنية دوّارة وبصمات متصفح حقيقية | Thunderbit (استخراج سحابي)، Bright Data، Oxylabs، ScraperAPI |
| عرض JavaScript المكثف | تُحمّل بيانات المنتج عبر JS؛ يكون HTML الخام فارغًا | متصفح بلا واجهة أو عرض متصفح كامل | Thunderbit (وضع استخراج المتصفح)، Playwright، Selenium، ParseHub، Apify browser actors |
| محددات CSS الديناميكية | تتغير أسماء الأصناف بين عمليات النشر، مما يكسر الأدوات المعتمدة على CSS | اكتشاف حقول بالذكاء الاصطناعي (دون الاعتماد على محددات ثابتة) | Thunderbit (يقرأ الصفحة من جديد كل مرة)، Bright Data AI scraper builder |
| تقييد المعدل | يخفّض سرعة الطلبات المتسلسلة السريعة | طلبات سحابية متزامنة مع تخفيف ذكي للسرعة | Thunderbit (حتى 50 صفحة دفعة واحدة عبر السحابة)، ScraperAPI، Bright Data |
| تحديات CAPTCHA | يقطع الجلسات بعد سلوك مريب | حل CAPTCHA مدمج أو استراتيجية أقل إثارة للتنبيه | Bright Data، Oxylabs، ScraperAPI premium/ultra-premium |
| التمرير اللانهائي / التحميل الكسول | لا تظهر إلا المنتجات الأولى من دون تفاعل | تمرير ذكي، اكتشاف الترقيم، أتمتة التفاعل | Thunderbit pagination، Apify smart scrolling، Octoparse workflow builder |
جدار حماية Cloudflare وحظر عناوين IP
الواجهة الأمامية لـTemu محمية بفحوصات سلامة متصفح على نمط Cloudflare. الطلبات البسيطة عبر HTTP — من النوع الذي يصنعه استدعاء requests.get() في Python — يتم تحدّيها أو إرجاع 403 لها أو إرسال بيانات غير مكتملة.
الأدوات التي تنجح هنا تحتاج إلى عناوين IP سكنية أو جوالة دوّارة وبصمات متصفح حقيقية. أفاد استعراض Cloudflare Radar لعام 2025 أن الروبوتات غير المعتمدة على الذكاء الاصطناعي بدأت 2025 وهي مسؤولة عن نحو نصف طلبات صفحات HTML. هذا هو حجم الأتمتة الذي تدافع منصات مثل Temu ضده.
عرض JavaScript والمحددات الديناميكية
هنا تفشل معظم أدوات الاستخراج للمبتدئين بصمت.
إذا عرضت مصدر صفحة Temu، فغالبًا ستجد غلافًا فارغًا — بطاقات المنتجات والأسعار والصور الحقيقية تُحقن بواسطة JavaScript بعد تحميل الصفحة. أداة لا تقرأ إلا HTML الخام لن تُخرج شيئًا مفيدًا. وفوق ذلك، تتغير أسماء أصناف CSS وبنى DOM في Temu بين عمليات النشر. أداة تعتمد على محدد CSS ثابت مثل .product-card__price ستعمل اليوم، ثم تعود بأعمدة فارغة غدًا.
الأدوات المعتمدة على الذكاء الاصطناعي (مثل Thunderbit) تقرأ الصفحة دلاليًا في كل مرة، لذا لا تعتمد على بقاء أسماء الأصناف نفسها.
تقييد المعدل وتحديات CAPTCHA
إذا ضربت Temu بسرعة كبيرة أو مرات كثيرة من عنوان IP واحد، فستفعّل تقييد المعدل أو تحديات CAPTCHA. بعض الأدوات تتعامل مع ذلك عبر تخفيف ذكي للسرعة وحل CAPTCHA مدمج. أدوات أخرى تتركه عليك — وهذا، بالنسبة لمستخدم غير تقني، طريق مسدود عمليًا.
في الاستخراج السحابي، المفتاح هو طلبات متزامنة موزعة عبر عناوين IP نظيفة مع منطق إعادة المحاولة التلقائي.
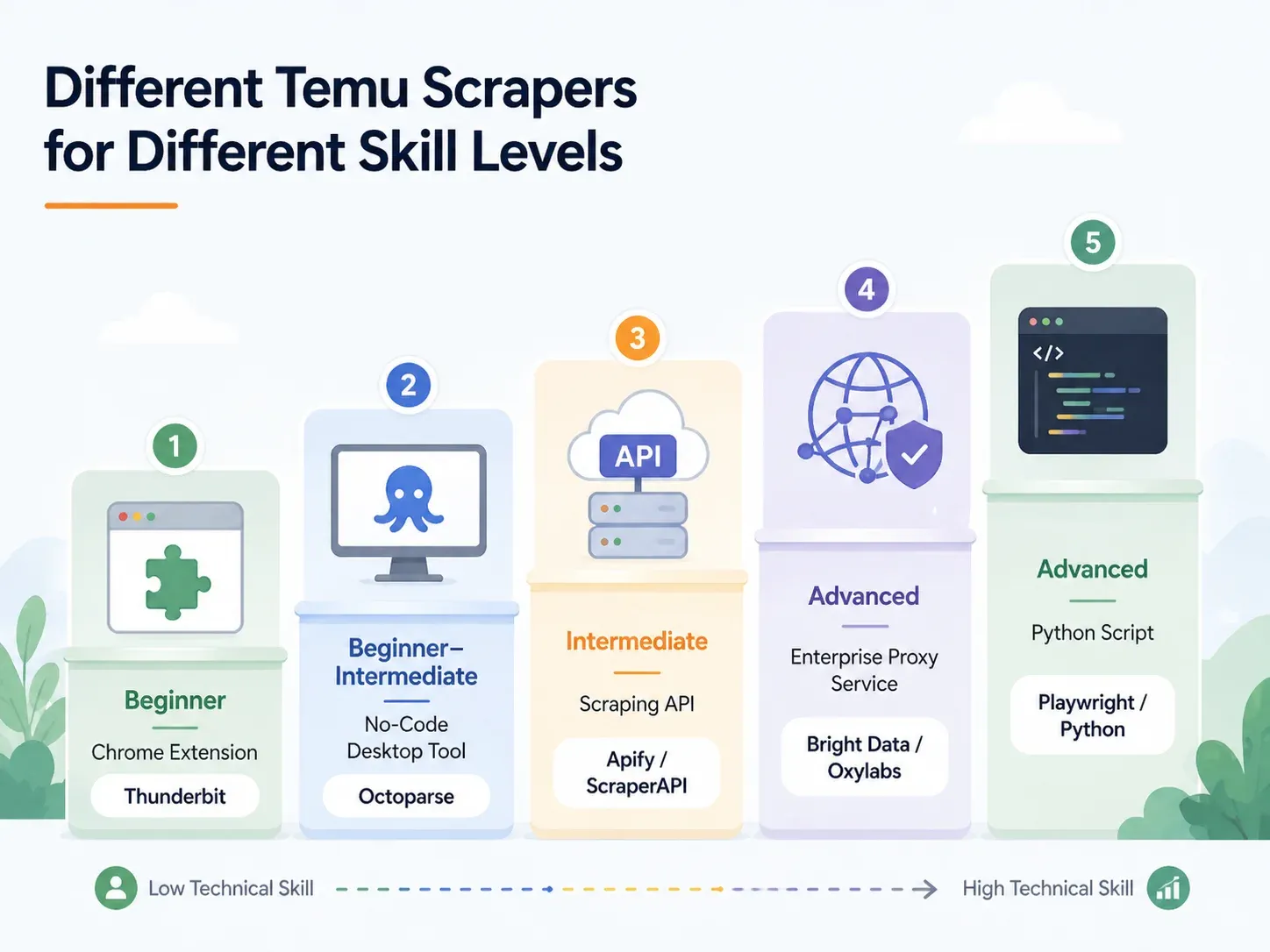
أفضل أدوات استخراج Temu حسب مستوى المهارة: تفصيل كامل
اعثر على السطر المناسب لك وانتقل إلى القسم الملائم:
| النهج | مستوى المهارة | وقت الإعداد | التعامل مع مكافحة الروبوتات | الأفضل لـ |
|---|---|---|---|---|
| إضافة Chrome بالذكاء الاصطناعي (مثل Thunderbit) | مبتدئ | أقل من دقيقتين | مُعالَج (سحابة أو متصفح) | العاملون في الدروبشيبينغ، المسوّقون، عمليات التجارة الإلكترونية |
| أداة سطح مكتب بلا كود (مثل Octoparse، ParseHub) | مبتدئ–متوسط | 10–60 دقيقة | جزئي (تحتاج إعداد بروكسي) | الاستخراج المنتظم مع قوالب |
| واجهة/خدمة استخراج (مثل ScraperAPI، Apify) | متوسط | 15–45 دقيقة | مدمج | المطورون الذين يدمجونها داخل خطوط البيانات |
| بروكسي مُدار/مؤسسي (مثل Bright Data، Oxylabs) | متقدم/مؤسسي | ساعات–أيام | بنية تحتية كاملة | الأحجام العالية، التسليم إلى المستودعات |
| نص Python مخصص (Playwright/Selenium) | متقدم | 1–4 ساعات+ | يدوي (إعداد بروكسي + CAPTCHA) | تحكم كامل، تخصيص للحالات الاستثنائية |
Thunderbit: أفضل أداة استخراج Temu للمستخدمين غير التقنيين
Thunderbit هو امتداد Chrome مدعوم بالذكاء الاصطناعي ومصمم لمستخدمي الأعمال — فرق المبيعات، ومشغلي التجارة الإلكترونية، والعاملين في الدروبشيبينغ، والمسوقين — الذين يحتاجون إلى بيانات منظمة من المواقع دون كتابة كود. أعمل في فريق Thunderbit، لذلك أعرف المنتج جيدًا. سأكون مباشرًا بشأن ما يفعله وأين يناسب.
سير العمل الأساسي خطوتان: افتح صفحة Temu، ثم انقر AI Suggest Fields، راجع الأعمدة المقترحة (اسم المنتج، السعر، الصورة، التقييم، إلخ)، ثم انقر Scrape.
يقرأ الذكاء الاصطناعي في Thunderbit بنية الصفحة ويقترح أسماء الأعمدة وأنواع البيانات تلقائيًا. وهو لا يعتمد على محددات CSS ثابتة، لذلك عندما تغيّر Temu أسماء الأصناف أو تخطيط البطاقات، تتكيف الأداة.
الميزات الأساسية لـTemu:
- وضع الاستخراج السحابي: أسرع للصفحات العامة، ويعالج حتى 50 صفحة في المرة الواحدة. الأفضل لصفحات الفئات، ونتائج البحث، وقوائم المنتجات التي لا تتطلب تسجيل دخول.
- وضع استخراج المتصفح: يستخدم جلسة Chrome الحالية لديك، بما في ذلك ملفات تعريف الارتباط، والمنطقة، وحالة تسجيل الدخول. الأفضل عندما تؤثر المنطقة أو النوافذ المنبثقة أو المحتوى المسجّل الدخول على ما تعرضه الصفحة.
- Scrape Subpages: بعد استخراج صفحة قائمة، انقر "Scrape Subpages" لزيارة صفحة تفاصيل كل منتج وإضافة أعمدة مثل الوصف الكامل، والمتغيرات، ومعلومات البائع، وتقدير الشحن، والمواصفات — من دون أي إعداد إضافي.
- مطالبات AI للحقول: صنّف البيانات أو ترجمها أو أعد تنسيقها أثناء الاستخراج. مثال: "صنّف هذا المنتج ضمن أدوات المطبخ، أو الأجهزة الصغيرة، أو التخزين، أو غير ذلك."
- الاستخراج المجدول: حدّد جدولًا زمنيًا بلغة طبيعية ("كل يوم اثنين الساعة 9 صباحًا"), وأدخل الروابط، ثم يشغّل Thunderbit الاستخراج في السحابة ويصدّره إلى Google Sheets أو Airtable أو وجهة أخرى.
- تصدير مجاني: Excel، CSV، Google Sheets، Airtable، Notion، JSON — من دون حظر على التصدير. تُصدَّر الصور كمرفقات فعلية في Airtable وNotion.
التسعير: خطة مجانية تصل إلى 6 صفحات (أو 10 مع تعزيز تجريبي)؛ وتبدأ الخطط المدفوعة من حوالي $15 شهريًا (شهري) أو $9 شهريًا (سنوي) مقابل 500 رصيد، مع 1 رصيد = 1 صف مخرج.
استخرج بيانات Temu بالذكاء الاصطناعي Get Started Free
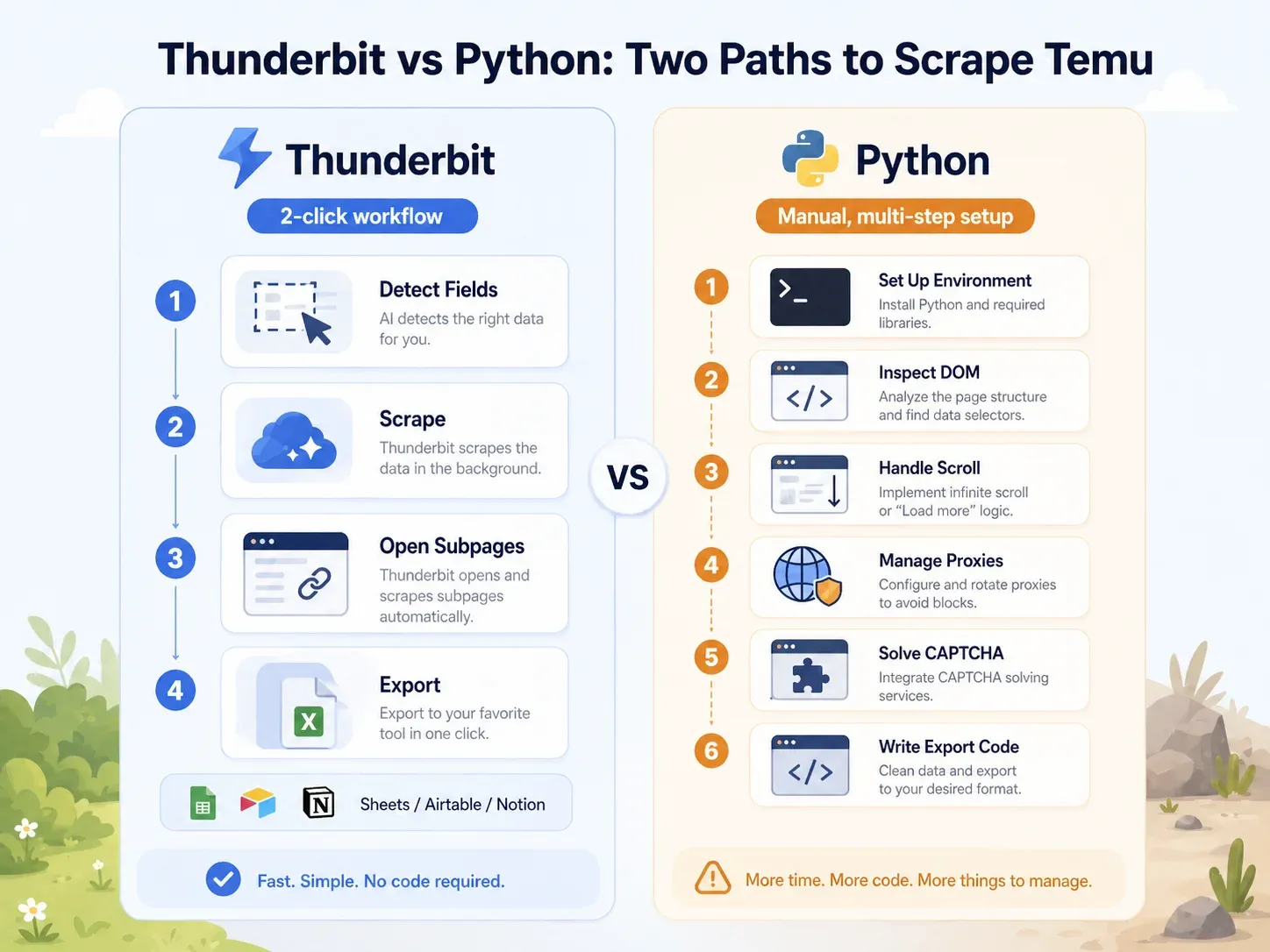
مقارنة مباشرة: Thunderbit مقابل نص Python على الصفحة نفسها في Temu
التباين واضح جدًا:
| المهمة | Thunderbit | Python (Playwright) |
|---|---|---|
| فتح صفحة فئة في Temu | افتح الصفحة في Chrome | إعداد بيئة Python، تثبيت Playwright، تثبيت المتصفحات |
| تحديد الحقول | انقر "AI Suggest Fields" | فحص DOM ونداءات الشبكة وحمولات JSON |
| التعامل مع التحميل الديناميكي | وضع المتصفح/السحابة + الترقيم | كتابة منطق التمرير/الانتظار، واعتراض الطلبات |
| التعامل مع الحظر | جرّب وضع السحابة أو المتصفح | أضف بروكسيات، وترويسات، وبصمة، وإعادة محاولات، وCAPTCHA |
| استخراج حقول القائمة | انقر "Scrape" | اكتب محددات أو منطق تحليل API |
| إثراء صفحات المنتجات | انقر "Scrape Subpages" | ابنِ زاحف PDP منفصلًا |
| التصدير | انقر Sheets/Airtable/Notion/Excel | اكتب كود تكامل CSV/JSON/Sheets |
| الإعداد المعتاد لمستخدم أعمال | أقل من دقيقتين | ساعة إلى 4 ساعات على الأقل؛ وصيانة مستمرة |
قد يبدو نموذج Playwright المبسط لـTemu كما يلي (شبه كود — غير جاهز للإنتاج):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# لا يزال كود الإنتاج بحاجة إلى محددات، وبروكسيات، وإعادة محاولات،
# والتعامل مع CAPTCHA، وزحف PDP، ومنطق التصدير.
print(cards.count())
هذا أكثر من 10 أسطر قبل أن تستخرج حقلًا واحدًا، ولم تقترب بعد من البروكسيات أو CAPTCHA أو إثراء PDP أو التصدير. بالنسبة لمستخدم غير تقني، يختصر Thunderbit هذا السير بالكامل إلى بضع نقرات. أما بالنسبة للمطور، فيوفر مسار Python تحكمًا أكبر — لكن بتكلفة صيانة أعلى بكثير.
Octoparse وParseHub: أدوات Temu لسطح المكتب بلا كود
إذا كنت تريد تحكمًا أكبر من إضافة Chrome لكن لا تريد كتابة كود، فـ Octoparse وParseHub هما الخياران الرئيسيان.
Octoparse لديه قالب عام لـ Temu Details Scraper. يتضمن المخرجات النموذجية معرفات المنتجات، والعناوين، والأسعار، وبيانات البائع/المتجر، وروابط الصور، والخصومات، وروابط المتجر، والمواصفات التفصيلية. هذه ميزة حقيقية — يمكنك البدء بقالب بدلًا من بناء سير عمل من الصفر. كما يدعم Octoparse الاستخراج السحابي، والجدولة، وبناء سير عمل بصري.
التحفظات الخاصة بـTemu:
- إضافات مكافحة الروبوتات (البروكسيات السكنية بسعر $3/GB، وحل CAPTCHA بسعر 1–1.50 دولار لكل ألف) يمكن أن تتراكم تكلفتها.
- قد تتعطل القوالب عندما تغيّر Temu التخطيط. قد تحتاج إلى تحديث المحددات أو انتظار Octoparse ليحافظ على القالب.
- يستغرق الإعداد من 10 إلى 60 دقيقة حسب تعقيد الصفحة.
أسعار Octoparse: خطة مجانية مع 10 مهام و50 ألف تصدير بيانات شهريًا؛ Standard بحوالي 75 دولارًا شهريًا عند الدفع السنوي؛ Professional بحوالي 108 دولارات شهريًا عند الدفع السنوي. الإضافات للبروكسيات وCAPTCHA والخدمات المُدارة تُحسب منفصلة.
ParseHub هو أداة استخراج مرئية لسطح المكتب/الويب تتعامل جيدًا مع الصفحات الديناميكية (تُشغّل متصفح Chromium كاملًا). ومع ذلك، تبدأ الخطط المدفوعة من 189 دولارًا شهريًا، وهو مبلغ مرتفع لمشغل منفرد. لم أجد قالبًا عامًا قويًا خاصًا بـTemu في بحثي. ParseHub أنسب للفرق التي ترتاح أصلًا لبناء مشاريع استخراج مرئية.
| الأداة | نقاط القوة في Temu | نقاط الضعف في Temu | التسعير |
|---|---|---|---|
| Octoparse | قالب Temu عام، سير عمل مرئي، استخراج سحابي، جدولة | صيانة القالب، وإضافات مكافحة الروبوتات ترفع التكلفة | مجاني؛ نحو 75 دولار/شهر عند الدفع السنوي Standard؛ نحو 108 دولار/شهر عند الدفع السنوي Pro؛ الإضافات منفصلة |
| ParseHub | التعامل مع الصفحات الديناميكية، وبناء سير المشاريع، وتدوير IP في الخطط المدفوعة | سعر دخول أعلى، ولم يُعثر على قالب Temu عام | خطط مدفوعة تبدأ من 189 دولارًا/شهر |
واجهات الاستخراج البرمجية: ScraperAPI وApify وBright Data لـTemu
خدمات الاستخراج المعتمدة على API تتولى البروكسيات، والعرض، ومنطق مكافحة الروبوتات، حتى يركز المطورون على تحليل البيانات وتخزينها. تناسبك عندما تبني خط بيانات، لا عندما تنفذ تصدير جدول بيانات لمرة واحدة.
ScraperAPI هو API للمطورين لتدوير البروكسيات والعرض. تذكر صفحة التسعير الخاصة به تجربة لمدة 7 أيام مع 5,000 رصيد، وحزمة Hobby بسعر 49 دولارًا شهريًا مقابل 100,000 رصيد، ثم مستويات أعلى بعد ذلك. المشكلة في Temu: عرض JavaScript وحزم البروكسي المميزة يكلفان 10 إلى 75 رصيدًا لكل طلب حسب المستوى. هذا التضخيم في الأرصدة يعني أن التكلفة الفعلية لكل صف قد تكون أعلى بكثير من السعر المعلن.
Apify منصة تضم سوقًا من "العوامل" المبنية مسبقًا (أدوات استخراج). توجد عدة عوامل لـTemu. أحد أدوات Temu Scraper التي تديرها المجتمع يذكر تسعيرًا على أساس الدفع لكل حدث بحوالي 5 دولارات لكل 1,000 منتج في الخطة المجانية. وأداة أخرى Temu Products Scraper تذكر 4 دولارات لكل 1,000 نتيجة. المخاطرة: جودة العوامل متفاوتة، والصيانة تعتمد على المجتمع، وبعضها قد يصبح قديمًا أو يتعطل عندما تحدث Temu تحديثًا. تحقق دائمًا من تاريخ "آخر تعديل" وتقييمات المستخدمين قبل الالتزام.
Bright Data هو الخيار المؤسسي. تقول صفحة Temu scraper الخاصة به إن المهام تعمل على بنية Bright Data مع تدوير البروكسي، وتحديد الموقع الجغرافي، ومنطق CAPTCHA/إلغاء الحجب، والتوسع التلقائي. تشمل صيغ الإخراج JSON وCSV وParquet والتسليم المباشر إلى S3 وGCS وAzure Blob وBigQuery وSnowflake. تشير المراجعات الصناعية إلى أن Web Scraper API بنظام الدفع حسب الاستخدام يقارب 2.5 دولار لكل 1,000 سجل، مع خطط التزام تبدأ من حوالي 499 دولارًا شهريًا. قوي، لكنه مسعّر للفرق ذات الميزانيات الحقيقية.
Oxylabs لديها أيضًا صفحة مخصصة لـTemu Scraper API. تبدأ الخطط من 49 دولارًا شهريًا، مع تجربة مجانية حتى 2,000 نتيجة. إنها بديل قوي لـBright Data لفرق المطورين التي تريد بيانات Temu منظمة عبر API.
| واجهة/منصة API | دليل خاص بـTemu | نقطة القوة | نقطة الضعف | الأفضل لـ |
|---|---|---|---|---|
| ScraperAPI | لم يُعثر على صفحة خاصة بـTemu، لكن ميزات مكافحة الروبوتات للتجارة الإلكترونية موثقة | نقطة نهاية بسيطة، عرض JS، بروكسيات مميزة | مضاعفات الأرصدة للميزات المميزة؛ على المطورين تحليل البيانات | خطوط المطورين |
| Apify | عدة عوامل Temu في السوق | أسرع طريق للمطور إذا كان العامل مناسبًا ومُحافظًا عليه | جودة العوامل متفاوتة؛ وبعضها قديم | المطورون الذين يريدون سوق عوامل + جدولة |
| Bright Data | صفحة مخصصة لـTemu scraper | بنية مؤسسية، إلغاء حجب، وتسليم إلى المستودعات | مكلف؛ وما زالت مفاهيم استخراج الويب مطلوبة | فرق البيانات على نطاق مؤسسي |
| Oxylabs | صفحة مخصصة لـTemu Scraper API | تسعير واضح لكل نتيجة، ودعم JS، وادعاءات IP/CAPTCHA | سير عمل API للمطورين | فرق التطوير التي تحتاج وصول API إلى Temu |
نصوص Python المخصصة (Playwright/Selenium): تحكم كامل، جهد مرتفع
تمنحك أدوات Python المخصصة أقصى درجات المرونة — وهذه هي الميزة. عادةً ما يكون Playwright نقطة بداية أفضل من Selenium مع Temu بسبب نموذج الانتظار التلقائي والتعامل الأفضل مع الصفحات الثقيلة بـJavaScript.
لكن المقابل قاسٍ.
يستغرق النموذج الأولي من 1 إلى 4 ساعات. أما الأداة الإنتاجية فتحتاج إلى تدوير بروكسي، وبصمات متصفح واقعية، واستراتيجية CAPTCHA، وإعادة محاولات، والتحقق من المخطط، وتخزين المخرجات، والمراقبة، والتنبيهات، ومراجعة قانونية.
وستتعطل. تصف مجتمعات الاستخراج على Reddit باستمرار أن استخراج التجارة الإلكترونية الحديث غير مستقر عندما تستخدم المواقع Cloudflare، وعرض JavaScript، وبصمات مكافحة الروبوتات.
| نمط الفشل | السبب المعتاد | التخفيف |
|---|---|---|
| HTML فارغ / منتجات مفقودة | JS يحمل بطاقات المنتج بعد HTML الأولي | استخدم Playwright، وانتظر الشبكة وDOM |
| أول بضعة منتجات فقط | تمرير لانهائي / تحميل كسول | حلقة تمرير، وانتظار خمول الشبكة، وحدود لعدد البطاقات |
| أسعار مفقودة أو غير متسقة | حالة المنطقة/الجلسة/العملة أو استجابة مكافحة الروبوتات | اضبط المنطقة المحلية، والكوكيز، وبروكسي موجّه جغرافيًا |
| 403 / تحدٍ / CAPTCHA | سمعة IP، وبصمة headless، ومعدل الطلبات | بروكسيات سكنية، ومتصفح متخفي، ومعدل أقل |
| كسر المحددات | تغييرات DOM/الأصناف، واختبارات A/B | استخراج دلالي أو تحليل API إذا توفر |
النصوص المخصصة ليست الخيار "المجاني". إنها تنقل التكلفة من رسوم الاشتراك إلى وقت المطور، وفواتير البروكسي، وتكاليف CAPTCHA، ومخاطر الصيانة. إذا كان لديك مهندس استخراج على الفريق وتحتاج منطقًا غير معتاد، فهذا هو المسار المناسب. أما بالنسبة للجميع، فهو عمليًا الخيار الأغلى.
أفضل ممارسة: استخراج الصفحات الفرعية للحصول على بيانات Temu كاملة
هذه هي أفضل ممارسة ذات الأثر الأكبر في هذا المقال — ولا يغطيها تقريبًا أي دليل آخر.
تعرض لك صفحة الفئة أو البحث في Temu الأساسيات: العنوان، الصورة المصغرة، السعر، والتقييم التقريبي. لكن الحقول التي تجعل الصف قابلًا للاستخدام فعليًا — الأوصاف التفصيلية، وقوائم المتغيرات، وإجمالي المراجعات، وتقديرات الشحن، وأسماء البائعين، وجداول المواصفات — موجودة في صفحة تفاصيل المنتج (PDP).
إذا اكتفيت باستخراج صفحة القائمة، فأنت تعمل بمجموعة بيانات جزئية.
سير العمل المكون من خطوتين:
- الخطوة 1 — استخراج صفحة القائمة (PLP): استخرج اسم المنتج، والسعر، والصورة المصغرة، والتقييم من صفحة بحث أو فئة في Temu.
- الخطوة 2 — الإثراء عبر استخراج الصفحات الفرعية: زر صفحة تفاصيل كل منتج وأضف أعمدة مثل الوصف الكامل، وعدد المراجعات، وخيارات المتغيرات، ووقت الشحن، ومعلومات البائع.
إليك شكل البيانات قبل الإثراء وبعده:
| الحقل | من PLP (الخطوة 1) | مضاف من PDP (الخطوة 2) |
|---|---|---|
| عنوان المنتج | ✅ | — |
| السعر | ✅ | ✅ (مؤكد / نسبة الخصم) |
| الصورة المصغرة | ✅ | — |
| التقييم النجمي | ✅ | ✅ (مع عدد المراجعات) |
| الوصف الكامل | ❌ | ✅ |
| المتغيرات (الأحجام، الألوان) | ❌ | ✅ |
| اسم البائع | ❌ | ✅ |
| تقدير الشحن | ❌ | ✅ |
| المواصفات التفصيلية | ❌ | ✅ |
في Thunderbit، هذا نقرة واحدة: بعد الاستخراج الأولي، انقر "Scrape Subpages". يزور الذكاء الاصطناعي عنوان URL لكل منتج ويضيف الأعمدة الإضافية — من دون أي إعداد إضافي، ولا زاحف منفصل، ولا صيانة للمحددات. يدعم قالب Octoparse Temu Details وعامل Temu في Apify أيضًا حقول PDP، لكن مع إعداد وصيانة أكثر. في Python، ستحتاج إلى بناء زاحف PDP منفصل، وصيانة محدداته، والتعامل مع الترقيم داخل صفحات التفاصيل — وهو استثمار إضافي كبير.
أفضل ممارسة: الاستخراج المجدول لـTemu لمراقبة الأسعار والمخزون المستمرة
عمليات الاستخراج لمرة واحدة مفيدة لاكتشاف المنتجات. أما الاستخبارات التنافسية فتتطلب مراقبة متكررة.
تتغير الأسعار، وتنفد المنتجات من المخزون، وتظهر عناصر جديدة يوميًا، وتتبدل شدة الخصومات مع العروض. الاستخراج الأسبوعي أو اليومي ينشئ جدولًا تاريخيًا يمكن لفريقك العمل عليه فعلًا.
ثلاث حالات استخدام تستحق الأتمتة:
- مراقبة الأسعار: تتبع أفضل 50 SKU لدى منافسك على Temu أسبوعيًا. احصل على الأسعار المحدثة مُصدَّرة تلقائيًا إلى Google Sheets للمقارنة السريعة مع أسعارك.
- مراقبة المخزون والتوافر: اكتشف متى ينفد منتج رائج من المخزون، أو تظهر متغيرات جديدة، أو تتغير تقديرات الشحن.
- اكتشاف المنتجات/الاتجاهات الجديدة: جدولة استخراج يومي لصفحة "New Arrivals" أو صفحة فئة ذات أولوية في Temu. رتّب حسب عدد المبيعات أو المراجعات لاكتشاف المنتجات الصاعدة مبكرًا.
في Thunderbit، تضبط ذلك بوصف الفاصل الزمني بلغة طبيعية ("كل يوم اثنين الساعة 9 صباحًا")، وإدخال الروابط المستهدفة، ثم النقر على "Schedule". يعمل الاستخراج في السحابة ويُصدَّر إلى الوجهة التي تختارها. وبما أن الذكاء الاصطناعي يقرأ الصفحة من جديد في كل مرة، تتكيف عمليات الاستخراج المجدولة تلقائيًا مع تغييرات تخطيط Temu — ولا تحتاج إلى تحديث المحددات عندما تعيد Temu تصميم بطاقة منتج.
البديل: إعداد مهمة cron، وصيانة نص Python، وضبط تدوير البروكسي، وبناء خط إخراج، وإصلاح المحددات كلما غيّرت Temu التخطيط. بالنسبة لفريق غير تقني، هذا غير قابل للتنفيذ من الأساس. بالنسبة للمطور، فهو عبء مستمر. كما تدعم Apify وBright Data أيضًا التشغيل المجدول، لكن مع إعداد تقني أكبر وحدود تكلفة أعلى.
أفضل ممارسة: سير عمل Temu من البداية إلى النهاية (استخراج → تنظيف → تصدير → تنفيذ)
تنتهي معظم أدلة الاستخراج عند "تنزيل CSV".
لكن مستخدمي الأعمال يحتاجون إلى البيانات داخل الأدوات التي يعملون بها فعلًا — Google Sheets للتعاون، وAirtable لقواعد بيانات المنتجات، وNotion للوحات الفريق. أفضل ممارسة الحقيقية هي سير عمل متكامل من البداية إلى النهاية:
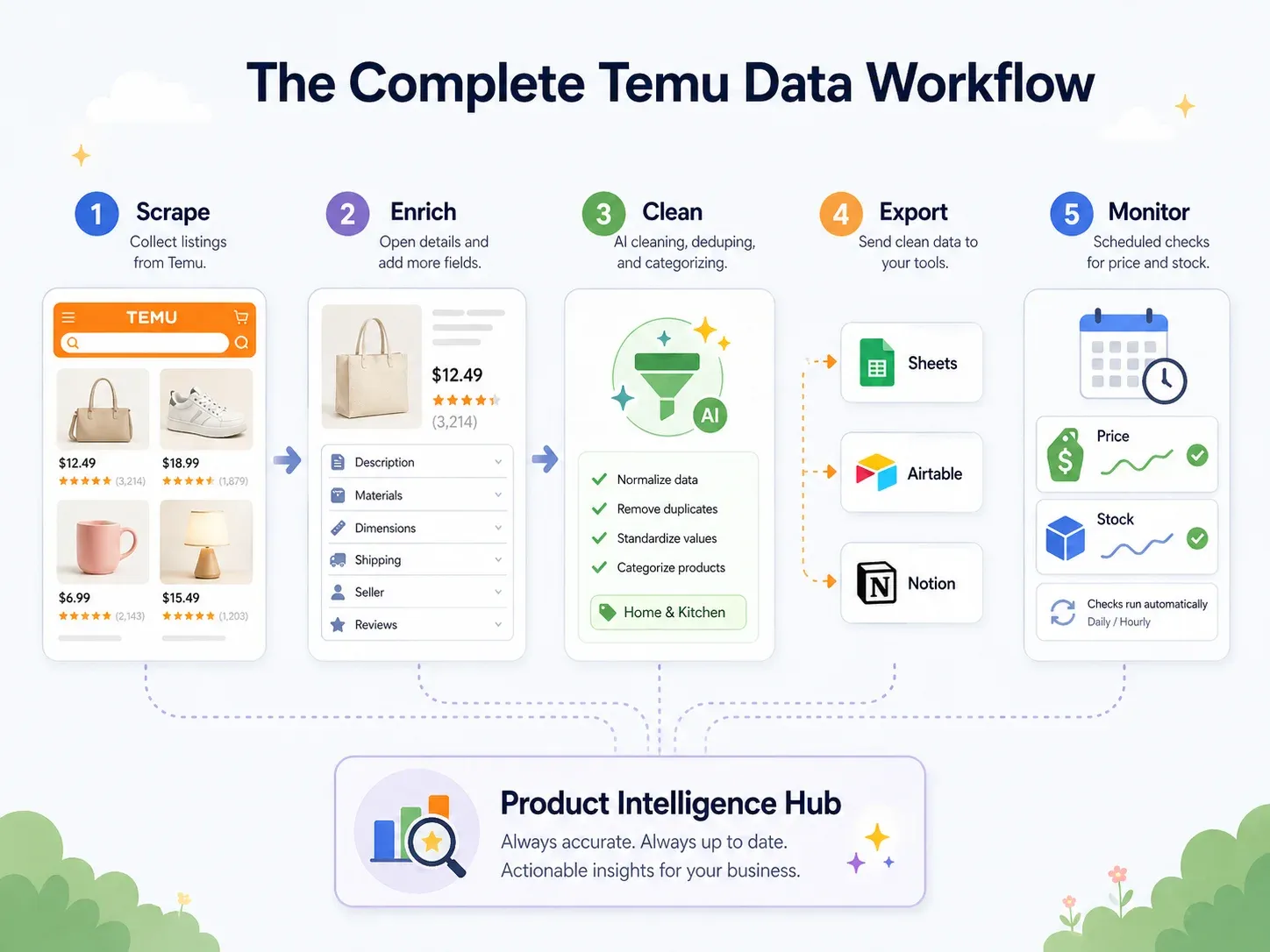
| خطوة سير العمل | ما الذي يحدث | قدرة Thunderbit |
|---|---|---|
| استخراج | استخراج البيانات من صفحات Temu | AI Suggest Fields → Scrape (نقرتان) |
| إثراء | زيارة صفحة تفاصيل كل منتج | Scrape Subpages (نقرة واحدة) |
| تنظيف وتصنيف | تصنيف المنتجات، وتوحيد الأسعار، وترجمة العناوين | Field AI Prompt — التصنيف، والتنسيق، والترجمة أثناء الاستخراج |
| تصدير | دفع البيانات إلى أدوات الأعمال | تصدير مجاني إلى Excel وGoogle Sheets وAirtable وNotion؛ تنزيل CSV/JSON |
| المراقبة | تتبع التغيرات مع الوقت | Scheduled Scraper بفواصل زمنية بلغة طبيعية |
إليك مثالًا عمليًا: تستخرج 200 منتج مطبخ من Temu. أثناء الاستخراج، تقوم مطالبة Field AI بتصنيف كل منتج تلقائيًا إلى "أدوات / أجهزة صغيرة / تخزين / تنظيف / ديكور". تُوحَّد الأسعار إلى قيم USD رقمية. وتُترجم عناوين المنتجات الصينية إلى الإنجليزية. تُصدَّر البيانات مباشرة إلى قاعدة Airtable مع صور المنتجات سليمة (وليس مجرد روابط — بل مرفقات صور فعلية، كما هو موضح في دليل Thunderbit لاستخراج الصور). ثم تُحدَّث البيانات أسبوعيًا عبر استخراج مجدول.
بعض تعليمات Field AI المفيدة لبيانات Temu:
- "صنّف هذا المنتج إلى واحد من: أدوات المطبخ، الأجهزة الصغيرة، التخزين، التنظيف، الديكور، أخرى. أعد فقط اسم الفئة."
- "ترجم عنوان المنتج إلى الإنجليزية المختصرة مع الحفاظ على أسماء العلامات التجارية والكميات والأحجام وأرقام الطراز."
- "وحّد السعر كرقم من دون رموز العملة."
- "ضع علامة على الطلب بأنه مرتفع أو متوسط أو منخفض بناءً على التقييم، وعدد المراجعات، وعدد المبيعات. إذا كانت البيانات مفقودة، فأعد Unknown."
هذا السير يحول عملية استخراج خامة إلى قاعدة بيانات حية لاستخبارات المنتجات — من دون أن يبني مطور خط ETL منفصلًا.
مقارنة أفضل أدوات استخراج Temu: جدول جنبًا إلى جنب
| الأداة | مستوى المهارة | وقت الإعداد | التعامل مع مكافحة الروبوتات | استخراج الصفحات الفرعية | الجدولة | خيارات التصدير | فئة التسعير | الأفضل لـ |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | مبتدئ | دقائق | وضع المتصفح، وضع السحابة، اكتشاف الحقول بالذكاء الاصطناعي | نعم (Scrape Subpages) | نعم (جداول زمنية بلغة طبيعية) | Excel، CSV، Google Sheets، Airtable، Notion، JSON | 6 صفحات مجانًا؛ مدفوع من نحو 9–15 دولار/شهر مقابل 500 رصيد | فرق التجارة الإلكترونية غير التقنية، والعاملون في الدروبشيبينغ |
| Octoparse | مبتدئ–متوسط | 10–60 دقيقة | استخراج سحابي، وإضافات بروكسي/CAPTCHA | نعم (سير عمل بالقوالب) | نعم (خطط مدفوعة/سحابية) | Excel، CSV، JSON، HTML، XML، قاعدة بيانات، Google Sheets | مجاني؛ نحو 75 دولار/شهر Standard سنويًا؛ الإضافات منفصلة | المشغلون الذين يريدون سير عمل مرئيًا + قالب Temu |
| ParseHub | مبتدئ–متوسط | 30–60 دقيقة | عرض ديناميكي، وتدوير IP في الخطط المدفوعة | نعم (تدفقات المشاريع) | الخطط المدفوعة | CSV/JSON، وDropbox/S3 في الخطط المدفوعة | مدفوع من 189 دولارًا/شهر | الفرق التي تبني مشاريع مرئية للمواقع الديناميكية |
| ScraperAPI | مطور | ساعات | تدوير بروكسي، وعرض JS، وحزم مميزة | مبرمج مخصصًا | DataPipeline/الجدولة | HTML/JSON/CSV | تجربة 5K رصيد؛ Hobby بـ49 دولارًا/شهر؛ مستويات أعلى متاحة | المطورون الذين يبنون خطوط Temu مخصصة |
| Apify | متوسط | 10–30 دقيقة إذا كان العامل مناسبًا | منطق متصفح/بروكسي خاص بالعامل | يعتمد على العامل | نعم | JSON، CSV، Excel، API/مجموعات بيانات | منصة مجانية؛ عوامل Temu بنحو 4–5 دولارات/1K منتج | المطورون/المشغلون الذين يستطيعون تقييم جودة العامل |
| Bright Data | متقدم/مؤسسي | ساعات–أيام | بروكسي كامل، CAPTCHA، إلغاء حجب، توسع تلقائي | عبر scraper/API مخصص | نعم | JSON، CSV، Parquet، S3، GCS، Azure، BigQuery، Snowflake | نحو 2.5 دولار/1K سجل بنظام الدفع حسب الاستخدام؛ التعاقد يبدأ من نحو 499 دولارًا/شهر | فرق البيانات المؤسسية، والاستخراج عالي الحجم |
| Oxylabs | متقدم | ساعات | دعم JS، وادعاءات IP/CAPTCHA | عبر API مخصص | نعم | JSON/مخرجات API | من 49 دولارًا/شهر؛ تجربة حتى 2K نتيجة | فرق المطورين التي تحتاج وصول API إلى Temu |
| Python مخصص (Playwright) | متقدم | 1–4 ساعات+؛ صيانة مستمرة | بروكسيات يدوية، CAPTCHA، بصمات | مخصص بالكامل | cron/queue/يدوي | مخصص | وقت المطور + تكاليف البروكسي/CAPTCHA/الاستضافة | الحالات الاستثنائية، والفرق التي لديها مهندسو استخراج |
أي أداة استخراج Temu يجب أن تختار؟ توصيات سريعة
- عامل دروبشيبينغ يحتاج بحثًا سريعًا عن المنتجات؟ ابدأ بـالخطة المجانية في Thunderbit. إنه أسرع طريق من "أريد بيانات Temu" إلى "لدي جدول بيانات". إذا عمل على الصفحات المستهدفة لديك (ويفترض أن يعمل مع معظم صفحات الفئات والمنتجات العامة)، فقد انتهيت.
- مشغل يريد تحكمًا بصريًا وقوالب قابلة لإعادة الاستخدام؟ لدى Octoparse قالب Temu Details عام ومنشئ سير عمل مرئي. توقّع إعدادًا من 10 إلى 30 دقيقة وبعض إعدادات البروكسي/CAPTCHA.
- مطور يبني خط بيانات أو أداة داخلية؟ تمنحك ScraperAPI أو Apify سير عمل عبر API/العوامل يندمج مع الكود والمهام المجدولة. قيّم عوامل Apify بعناية — تحقق من حالة الصيانة وتقييمات المستخدمين.
- فريق مؤسسي يحتاج بيانات Temu عالية الحجم وتسليمًا إلى المستودعات؟ Bright Data هو خيار البنية التحتية. مكلف، لكنه يتعامل مع الحجم، وإلغاء الحجب، والتسليم إلى S3/BigQuery/Snowflake.
- مهندس استخراج يحتاج منطقًا غير معتاد؟ يمنحك Playwright/Selenium المخصص تحكمًا كاملًا. فقط ضع في الحسبان الصيانة المستمرة، وتكاليف البروكسي، والتعامل مع CAPTCHA.
بالنسبة لمعظم مستخدمي الأعمال غير التقنيين، أوصي باختبار الخطة المجانية في Thunderbit أولًا. السؤال الفوري دائمًا هو: "هل يمكنني الحصول على الصفوف التي أحتاجها من صفحة Temu هذه بالذات؟" — ويمكنك الإجابة عن ذلك في أقل من دقيقتين من دون إنفاق أي شيء. بالنسبة للمطورين، شغّل معيار تكلفة لكل صف ناجح عبر Apify وScraperAPI ونموذج Playwright صغير قبل الالتزام بالميزانية.
جرّب Thunderbit مجانًا لاستخراج Temu
أسئلة شائعة حول استخراج Temu
هل من القانوني استخراج بيانات Temu؟
يعتمد ذلك على الولاية القضائية، والبيانات التي تجمعها، وطريقة الوصول، وكيفية استخدامك للبيانات. شروط استخدام Temu تقيد صراحةً الوصول الآلي، بما في ذلك الزحف أو الاستخراج أو spidering للصفحات أو البيانات. قدمت المحاكم الأمريكية بعض السوابق المواتية للوصول إلى البيانات المتاحة للعامة (قرار الدائرة التاسعة في قضية hiQ ضد LinkedIn)، لكن أحكامًا لاحقة أيّدت أيضًا دعاوى خرق العقد والتعدي. الجواب المختصر: قد يكون استخراج البيانات المتاحة للعامة لأغراض البحث قابلًا للدفاع في بعض السياقات، لكن شروط الخدمة وقانون الخصوصية وحقوق النشر وطريقة استخدام البيانات كلها مهمة. هذا ليس نصيحة قانونية — استشر محاميًا للاستخدام التجاري.
كم مرة تغيّر Temu تخطيط موقعها؟
لم يُوثَّق إيقاع عام محدد. تتعامل تقارير المجتمع ومنظومة الأدوات مع Temu بوصفها هدفًا ديناميكيًا يتغير كثيرًا. افترض أن محددات CSS قد تتعطل في أي وقت، وفضّل الاستخراج بالذكاء الاصطناعي/الدلالي أو القوالب المُصانة نشطًا بدلًا من المحددات المبرمجة يدويًا.
هل يمكنني استخراج Temu من دون أن يتم حجبي؟
بالنسبة للصفحات العامة المحدودة وبوتيرة مسؤولة، نعم — خصوصًا باستخدام أدوات تدعم عرض المتصفح الحقيقي، ودعم الجلسات، وتخفيف السرعة. لا توجد أداة ينبغي اعتبارها ضمانًا عالميًا. يعمل الاستخراج السحابي مع عناوين IP دوارة جيدًا لصفحات الكتالوج العامة؛ ويعمل استخراج المتصفح باستخدام جلستك الحالية بشكل أفضل عندما تؤثر المنطقة أو تسجيل الدخول أو النوافذ المنبثقة على البيانات.
ما البيانات التي يمكنني استخراجها من صفحات منتجات Temu؟
الحقول العامة الشائعة تشمل عنوان المنتج، والرابط، والسعر الحالي، والسعر الأصلي، ونسبة الخصم، وروابط الصور، والتقييم النجمي، وعدد المراجعات، وعدد المبيعات، واسم البائع/المتجر، ومعلومات الشحن، والفئة، ومواصفات المنتج، والمتغيرات (الألوان، الأحجام)، وطابع الاستخراج الزمني. الحقول الدقيقة المتاحة تعتمد على نوع الصفحة (قائمة مقابل تفاصيل) والمنطقة.
هل أحتاج إلى بروكسيات لاستخراج Temu؟
لاستخراج يدوي صغير بنمط المتصفح (بضع صفحات في كل مرة)، قد لا تحتاجها. أما للاستخراج السحابي أو المجدول أو عالي الحجم، فعادةً ما تكون البروكسيات أو بنية مكافحة الحجب المُدارة ضرورية. أدوات مثل Thunderbit وBright Data وScraperAPI تجمع إدارة البروكسي داخل منصاتها، فلا تحتاج إلى إعدادها منفصلة.
إذا أردت التعمق أكثر في مواضيع ذات صلة، فاطّلع على أدلتنا حول استخراج الويب لمقارنة الأسعار، وأفضل أدوات استخراج الويب للتجارة الإلكترونية، واستخراج البيانات من المواقع إلى Excel، وكيفية الاستخراج إلى Google Sheets. يمكنك أيضًا مشاهدة الشروحات العملية على قناة Thunderbit على YouTube.
جرّب Thunderbit لاستخراج Temu Get Started Free
اعرف المزيد




