
روابط مكسورة. صفحات “孤立” ما حدّ يوصّل لها. وصفحة “تجربة” من سنة 2019 وGoogle بطريقة ما قرر يفهرسها. إذا أنت تدير موقع، فأنت أكيد عارف هالوجع.
زاحف مواقع شاطر يلقط كل هالأشياء — ويطلع لك خريطة كاملة لموقعك عشان تقدر تصلّح المشاكل من جذورها. لكن كثير ناس يخلطون بين “زاحف الويب” و“أداة كشط الويب”. وهم بصراحة مو نفس الشي.
أنا جرّبت 10 زواحف مجانية على مواقع حقيقية. بعضها رهيب لتدقيقات SEO. وبعضها الثاني أقوى في استخراج البيانات. هنا اللي ضبط — واللي ما ضبط.
ما هو زاحف المواقع؟ فهم الأساسيات
خلّنا نوضحها من البداية: زاحف المواقع مو هو نفسه Web Scraper. أدري المصطلحين ينقالون كأنهم شيء واحد كثير، بس فعليًا بينهم فرق كبير. تخيّل الزاحف كأنه “رسّام خرائط” لموقعك: يلفّ على كل زاوية، يتبع كل رابط، ويبني خريطة لكل الصفحات. شغلته الأساسية هي الاكتشاف: يلقى الروابط (URLs)، يفهم هيكلة الموقع، ويفهرس المحتوى. وهذا بالضبط اللي تسويه محركات البحث مثل Google عبر روبوتاتها، واللي تعتمد عليه أدوات SEO عشان تقيس صحة موقعك ().
أما Web Scraper فهو أقرب لـ “منقّب بيانات”. ما يهمه يرسم خريطة كاملة؛ اللي يهمه يطلع “الكنز”: أسعار منتجات، أسماء شركات، مراجعات، إيميلات… إلخ. أدوات الكشط تطلع حقول محددة من الصفحات اللي الزاحف يوصل لها ().
تشبيه سريع:
- الزاحف: واحد يمشي كل ممر في السوبرماركت ويسوي قائمة بكل المنتجات.
- الكاشط: واحد يروح مباشرة لرف القهوة ويسجّل سعر كل نوع “أورغانيك”.
ليش يفرق الموضوع؟ لأن لو هدفك بس تكتشف كل صفحات موقعك (مثلًا لتدقيق SEO)، فأنت تحتاج زاحف. لكن لو تبي تسحب أسعار منتجات من موقع منافس، فأنت تحتاج Web Scraper — أو الأفضل: أداة زاحف ويب تجمع الاثنين.
لماذا تستخدم زاحف ويب عبر الإنترنت؟ أهم الفوائد للأعمال
ليش ممكن تهتم بـ زاحف ويب؟ لأن الويب ما قاعد يصغر — بالعكس، يكبر كل يوم. فعليًا، أكثر من لتحسين مواقعها، وبعض أدوات SEO تزحف إلى [7 مليارات] صفحة يوميًا](https://martechvibe.com/article/top-10-web-crawler-platforms/#:~:text=Link%20Assistant%E2%80%99s%20website%20auditor%20SEO,Audi%2C%20Microsoft%2C%20IBM%2C%20and%20MasterCard).
وهذا اللي يقدر يقدمه لك الزاحف:
- تدقيقات SEO: يطلع الروابط المعطلة، العناوين الناقصة، المحتوى المكرر، الصفحات اليتيمة… وغيرها ().
- فحص الروابط وضمان الجودة (QA): يلقط أخطاء 404 وحلقات إعادة التوجيه قبل ما المستخدمين يلاحظونها ().
- إنشاء خرائط الموقع: يولّد ملفات XML تلقائيًا لمحركات البحث وللتخطيط ().
- جرد المحتوى: يبني قائمة بكل الصفحات وتسلسلها الهرمي وبياناتها الوصفية.
- الامتثال وإتاحة الوصول: يفحص كل صفحة حسب WCAG وSEO ومتطلبات الامتثال القانونية ().
- الأداء والأمان: يرصد الصفحات البطيئة، الصور الثقيلة، أو مشاكل أمنية ().
- بيانات للذكاء الاصطناعي والتحليل: يجهّز بيانات الزحف لأدوات التحليلات أو الذكاء الاصطناعي ().
وهذا جدول سريع يربط حالات الاستخدام بالأدوار داخل الشركات:
| حالة الاستخدام | الأنسب لـ | الفائدة / النتيجة |
|---|---|---|
| SEO وتدقيق الموقع | التسويق، SEO، أصحاب الأعمال الصغيرة | اكتشاف المشاكل التقنية، تحسين البنية، رفع الترتيب |
| جرد المحتوى وQA | مدراء المحتوى، مشرفو المواقع | تدقيق/ترحيل المحتوى، اكتشاف الروابط/الصور المعطلة |
| توليد العملاء المحتملين (الكشط) | المبيعات، تطوير الأعمال | أتمتة البحث عن العملاء، تغذية CRM بعملاء جدد |
| ذكاء تنافسي | التجارة الإلكترونية، مدراء المنتجات | مراقبة أسعار المنافسين، المنتجات الجديدة، تغيّر المخزون |
| إنشاء خريطة الموقع واستنساخ البنية | المطورون، DevOps، الاستشاريون | استنساخ البنية لإعادة التصميم أو النسخ الاحتياطي |
| تجميع المحتوى | الباحثون، الإعلام، المحللون | جمع بيانات من مواقع متعددة للتحليل أو رصد الاتجاهات |
| أبحاث السوق | المحللون، فرق تدريب الذكاء الاصطناعي | جمع مجموعات بيانات كبيرة للتحليل أو تدريب النماذج |
()
كيف اخترنا أفضل أدوات زحف المواقع المجانية
قضّيت ليالي طويلة (وكمية قهوة ما ودي أعترف فيها) وأنا أجرّب أدوات الزحف، أقلب الوثائق، وأشغّل زحف تجريبي ورا الثاني. وهذه أهم المعايير اللي مشيت عليها:
- القدرة التقنية: هل يقدر يتعامل مع مواقع حديثة (JavaScript، تسجيل دخول، محتوى ديناميكي)؟
- سهولة الاستخدام: ينفع لغير التقنيين ولا يحتاج “سحر” سطر أوامر؟
- حدود الخطة المجانية: مجاني صدق ولا مجرد تجربة تسويقية؟
- إمكانية الوصول عبر الإنترنت: أداة سحابية، برنامج سطح مكتب، ولا مكتبة برمجية؟
- ميزات فريدة: هل فيه شيء يميّزه مثل استخراج بالذكاء الاصطناعي، خرائط موقع مرئية، أو زحف قائم على الأحداث؟
جرّبت كل أداة، راجعت تقييمات المستخدمين، وقارنت الميزات جنبًا إلى جنب. أي أداة خلتني أفكر أرمي اللابتوب من الشباك… ما دخلت القائمة.
جدول مقارنة سريع: أفضل 10 زواحف مواقع مجانية بنظرة واحدة
| الأداة والنوع | الميزات الأساسية | أفضل حالة استخدام | متطلبات تقنية | تفاصيل الخطة المجانية |
|---|---|---|---|---|
| BrightData (سحابي/API) | زحف بمستوى المؤسسات، بروكسيات، عرض JS، حل CAPTCHA | جمع بيانات على نطاق واسع | يفضّل بعض الخبرة التقنية | تجربة مجانية: 3 كاشطات، 100 سجل لكل منها (حوالي 300 سجل إجمالًا) |
| Crawlbase (سحابي/API) | زحف عبر API، تجاوز الحظر، بروكسيات، عرض JS | مطورون يحتاجون بنية زحف خلفية | تكامل API | مجاني: ~5,000 طلب API لمدة 7 أيام، ثم 1,000/شهر |
| ScraperAPI (سحابي/API) | تدوير بروكسي، عرض JS، زحف غير متزامن، نقاط نهاية جاهزة | مطورون، مراقبة الأسعار، بيانات SEO | إعداد بسيط | مجاني: 5,000 طلب API لمدة 7 أيام، ثم 1,000/شهر |
| Diffbot Crawlbot (سحابي) | زحف + استخراج بالذكاء الاصطناعي، Knowledge Graph، عرض JS | بيانات منظمة على نطاق واسع، AI/ML | تكامل API | مجاني: 10,000 رصيد/شهر (حوالي 10 آلاف صفحة) |
| Screaming Frog (سطح مكتب) | تدقيق SEO، تحليل الروابط/الميتا، خرائط موقع، استخراج مخصص | تدقيقات SEO وإدارة المواقع | تطبيق سطح مكتب، واجهة GUI | مجاني: 500 رابط URL لكل عملية زحف، ميزات أساسية فقط |
| SiteOne Crawler (سطح مكتب) | SEO، أداء، إتاحة وصول، أمان، تصدير دون اتصال، Markdown | مطورون، QA، ترحيل، توثيق | سطح مكتب/CLI، GUI | مجاني ومفتوح المصدر، 1,000 URL في تقرير GUI (قابل للتعديل) |
| Crawljax (Java، مفتوح المصدر) | زحف قائم على الأحداث لمواقع JS الثقيلة، تصدير ثابت | مطورون، QA لتطبيقات ويب ديناميكية | Java، CLI/إعدادات | مجاني ومفتوح المصدر، بلا حدود |
| Apache Nutch (Java، مفتوح المصدر) | موزّع، إضافات، تكامل Hadoop، بحث مخصص | محركات بحث مخصصة، زحف ضخم | Java، سطر أوامر | مجاني ومفتوح المصدر، تكلفة البنية فقط |
| YaCy (Java، مفتوح المصدر) | زحف وبحث بنظام نظير-لنظير، خصوصية، فهرسة ويب/إنترانت | بحث خاص، لامركزية | Java، واجهة عبر المتصفح | مجاني ومفتوح المصدر، بلا حدود |
| PowerMapper (سطح مكتب/SaaS) | خرائط موقع مرئية، إتاحة وصول، QA، توافق المتصفحات | وكالات، QA، رسم خرائط بصري | GUI، سهل | تجربة مجانية: 30 يومًا، 100 صفحة (سطح مكتب) أو 10 صفحات (أونلاين) لكل فحص |
BrightData: زاحف مواقع سحابي بمستوى المؤسسات

BrightData هو “الثقيل” في عالم الزحف. منصة سحابية معها شبكة بروكسي ضخمة، ودعم عرض JavaScript، وحل CAPTCHA، وبيئة تطوير (IDE) تبني فيها زواحف مخصصة. لو تجمع بيانات على نطاق كبير — مثل متابعة أسعار مئات مواقع التجارة الإلكترونية — فبنيته التحتية صعب أحد ينافسها ().
نقاط القوة:
- يتعامل مع المواقع العنيدة وأنظمة منع الروبوتات
- قابل للتوسع لاحتياجات الشركات الكبيرة
- قوالب جاهزة لمواقع معروفة
القيود:
- ما فيه خطة مجانية دائمة (بس تجربة: 3 كاشطات، 100 سجل لكل وحدة)
- ممكن يكون “أوفر” لتدقيقات بسيطة
- يحتاج وقت تعلّم لغير التقنيين
إذا تحتاج زحف على نطاق واسع، BrightData كأنه استئجار سيارة فورمولا 1. بس لا تتوقع يظل مجاني بعد “لفة التجربة” ().
Crawlbase: زاحف ويب مجاني عبر API للمطورين

Crawlbase (كان اسمه ProxyCrawl) مركزه الزحف البرمجي. ترسل URL عبر API، ويرجع لك HTML مع إدارة البروكسيات والاستهداف الجغرافي وCAPTCHA شغّالة بالخلفية ().
نقاط القوة:
- نسب نجاح عالية (99%+)
- مناسب للمواقع الثقيلة بـ JavaScript
- ممتاز للدمج داخل تطبيقاتك أو سير عملك
القيود:
- يحتاج تكامل API أو SDK
- الخطة المجانية: ~5,000 طلب API لمدة 7 أيام، ثم 1,000/شهر
إذا أنت مطور وتبي زحف (وربما كشط الويب) على نطاق واسع بدون صداع إدارة البروكسيات، Crawlbase خيار قوي ().
ScraperAPI: تبسيط زحف الويب الديناميكي

ScraperAPI هو API من نوع “خلّني أجيب الصفحة عنك”. تعطيه URL وهو يتكفل بالبروكسيات والمتصفح الخفي ومنع الروبوتات، ويرجع لك HTML (وأحيانًا بيانات منظمة لبعض المواقع). ممتاز للصفحات الديناميكية وفيه مستوى مجاني كويس ().
نقاط القوة:
- سهل جدًا للمطورين (استدعاء API وخلاص)
- يتعامل مع CAPTCHA وحظر IP وJavaScript
- مجاني: 5,000 طلب API لمدة 7 أيام، ثم 1,000/شهر
القيود:
- ما يعطيك تقارير زحف مرئية
- لو تبي تتبع الروابط، لازم تكتب منطق الزحف بنفسك
إذا تبي تدخل زحف الويب في الكود خلال دقائق، ScraperAPI خيار مباشر وواضح.
Diffbot Crawlbot: اكتشاف بنية المواقع تلقائيًا

مع Diffbot Crawlbot تبدأ “الذكاء” فعليًا. ما يكتفي بالزحف؛ يستخدم الذكاء الاصطناعي لتصنيف الصفحات واستخراج بيانات منظمة (مقالات، منتجات، فعاليات… إلخ) بصيغة JSON. كأنه متدرب روبوت يفهم اللي يقراه مو بس ينسخه ().
نقاط القوة:
- استخراج مدعوم بالذكاء الاصطناعي مو مجرد زحف
- يتعامل مع JavaScript والمحتوى الديناميكي
- مجاني: 10,000 رصيد/شهر (حوالي 10 آلاف صفحة)
القيود:
- موجّه أكثر للمطورين (تكامل API)
- مو أداة SEO مرئية؛ أنسب لمشاريع البيانات
إذا تحتاج بيانات منظمة على نطاق واسع — خصوصًا للتحليلات أو الذكاء الاصطناعي — Diffbot قوي جدًا.
Screaming Frog: زاحف SEO مجاني على سطح المكتب

Screaming Frog هو “الكلاسيك” في تدقيقات SEO على سطح المكتب. يزحف حتى 500 URL لكل فحص (بالنسخة المجانية) ويعطيك كل شيء: روابط مكسورة، وسوم ميتا، محتوى مكرر، خرائط موقع، وأكثر ().
نقاط القوة:
- سريع وشامل وموثوق في عالم SEO
- ما يحتاج برمجة — حط الرابط وابدأ
- مجاني حتى 500 URL لكل عملية زحف
القيود:
- سطح مكتب فقط (ما فيه نسخة سحابية)
- الميزات المتقدمة (عرض JS، الجدولة) تحتاج ترخيص مدفوع
إذا أنت جاد في SEO، Screaming Frog من الأساسيات — بس لا تتوقع يزحف موقع 10,000 صفحة مجانًا.
SiteOne Crawler: تصدير موقع ثابت والتوثيق

SiteOne Crawler كأنه سكين سويسري للتدقيقات التقنية. مفتوح المصدر ويشتغل على أكثر من نظام، ويقدر يزحف ويدقق وحتى يصدّر موقعك إلى Markdown للتوثيق أو للاستخدام بدون إنترنت ().
نقاط القوة:
- يغطي SEO والأداء وإتاحة الوصول والأمان
- يصدّر المواقع للأرشفة أو الترحيل
- مجاني ومفتوح المصدر بدون حدود استخدام
القيود:
- تقني أكثر من بعض أدوات الواجهة الرسومية
- تقرير التدقيق في GUI محدود افتراضيًا بـ 1,000 URL (وتقدر تعدله)
إذا أنت مطور أو شغال QA/استشارات وتحب الأوبن سورس، SiteOne فعلاً “جوهرة” ما ينتبه لها كثير.
Crawljax: زاحف ويب Java مفتوح المصدر للصفحات الديناميكية
Crawljax أداة متخصصة جدًا: معمولة لزحف تطبيقات الويب الحديثة الثقيلة بـ JavaScript عبر محاكاة تفاعل المستخدم (نقرات، تعبئة نماذج… إلخ). شغلها قائم على الأحداث، وتقدر حتى تطلع نسخة ثابتة من موقع ديناميكي ().
نقاط القوة:
- الأفضل لزحف تطبيقات SPA ومواقع AJAX الثقيلة
- مفتوح المصدر وقابل للتوسعة
- بلا حدود استخدام
القيود:
- يحتاج Java وبعض البرمجة/الإعداد
- مو مناسب لغير التقنيين
إذا تبي تزحف تطبيق React أو Angular كأنك مستخدم حقيقي، Crawljax هو خيارك.
Apache Nutch: زاحف مواقع موزّع قابل للتوسع

Apache Nutch هو “الجد الكبير” لزواحف المصادر المفتوحة. مصمم لعمليات زحف ضخمة وموزعة — مثل بناء محرك بحث خاص أو فهرسة ملايين الصفحات ().
نقاط القوة:
- يتوسع لمليارات الصفحات مع Hadoop
- قابل للتهيئة والتوسعة بشكل كبير
- مجاني ومفتوح المصدر
القيود:
- منحنى تعلم قوي (Java، سطر أوامر، إعدادات)
- مو مناسب للمواقع الصغيرة أو الاستخدام الخفيف
إذا تبي زحف الويب على نطاق واسع وما عندك مشكلة مع سطر الأوامر، Nutch مناسب.
YaCy: زاحف ويب ومحرك بحث بنظام نظير-لنظير
YaCy خيار مختلف تمامًا: زاحف ومحرك بحث لامركزي. كل نسخة تزحف وتفهرس، وتقدر تنضم لشبكة نظير-لنظير وتشارك الفهارس مع غيرك ().
نقاط القوة:
- يركز على الخصوصية بدون خادم مركزي
- ممتاز لبحث داخلي خاص أو للإنترانت
- مجاني ومفتوح المصدر
القيود:
- جودة النتائج تعتمد على تغطية الشبكة
- يحتاج شوية إعداد (Java، واجهة عبر المتصفح)
إذا تحب فكرة اللامركزية أو تبي محرك بحث خاص فيك، YaCy خيار ممتع فعلًا.
PowerMapper: مولّد خرائط موقع مرئية لتجربة المستخدم وQA

PowerMapper يركز على عرض هيكلة موقعك بشكل بصري. يزحف الموقع ويطلع خرائط تفاعلية، وبعد يفحص إتاحة الوصول وتوافق المتصفحات وأساسيات SEO ().
نقاط القوة:
- خرائط موقع مرئية ممتازة للوكالات والمصممين
- يفحص إتاحة الوصول والامتثال
- واجهة سهلة وما تحتاج خبرة تقنية
القيود:
- تجربة مجانية فقط (30 يومًا، 100 صفحة على سطح المكتب/10 صفحات أونلاين لكل فحص)
- النسخة الكاملة مدفوعة
إذا تحتاج تقدم خريطة موقع للعميل أو تفحص الامتثال، PowerMapper عملي جدًا.
كيف تختار زاحف الويب المجاني المناسب لاحتياجاتك
مع كل هالخيارات، كيف تختار؟ هذا دليلي السريع:
- لتدقيقات SEO: Screaming Frog (للمواقع الصغيرة)، PowerMapper (للخرائط المرئية)، SiteOne (لتدقيقات عميقة)
- لتطبيقات الويب الديناميكية: Crawljax
- للزحف واسع النطاق أو البحث المخصص: Apache Nutch، YaCy
- للمطورين الذين يحتاجون API: Crawlbase، ScraperAPI، Diffbot
- للتوثيق أو الأرشفة: SiteOne Crawler
- للمؤسسات مع تجربة: BrightData، Diffbot
عوامل مهمة قبل القرار:
- قابلية التوسع: كم حجم موقعك أو مهمة الزحف؟
- سهولة الاستخدام: تفضّل برمجة ولا واجهة “نقطة وانقر”؟
- تصدير البيانات: تحتاج CSV أو JSON أو تكامل مع أدوات ثانية؟
- الدعم: فيه مجتمع/وثائق تساعدك إذا علقت؟
عندما يلتقي الزحف بالكشط: لماذا Thunderbit خيار أذكى
الواقع إن أغلب الناس ما يسوّون زحف الويب بس عشان “خرائط حلوة”. غالبًا الهدف هو بيانات مرتبة وجاهزة — سواء قوائم منتجات، معلومات تواصل، أو جرد محتوى. وهنا يجي دور .
Thunderbit مو مجرد زاحف مواقع ولا Web Scraper — هو إضافة Chrome مدعومة بالذكاء الاصطناعي تجمع الاثنين. وهذا كيف يشتغل:
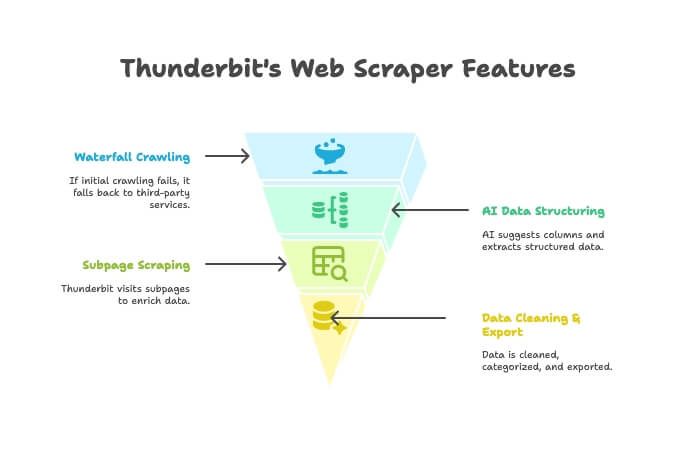
- زاحف بالذكاء الاصطناعي: يستكشف الموقع مثل الزاحف.
- Waterfall Crawling: إذا محرك Thunderbit ما قدر يوصل للصفحة (بسبب جدار منع روبوتات قوي مثلًا)، يحوّل تلقائيًا لخدمات زحف خارجية — بدون إعداد يدوي.
- هيكلة البيانات بالذكاء الاصطناعي: بعد ما يجيب HTML، الذكاء الاصطناعي يقترح الأعمدة المناسبة ويستخرج بيانات منظمة (أسماء، أسعار، إيميلات… إلخ) بدون ما تكتب أي محددات.
- كشط الصفحات الفرعية: تحتاج تفاصيل كل صفحة منتج؟ Thunderbit يزور كل صفحة فرعية تلقائيًا ويغني الجدول.
- تنظيف البيانات وتصديرها: يلخّص ويصنّف ويترجم ويصدّر إلى Excel أو Google Sheets أو Airtable أو Notion بنقرة واحدة.
- بساطة بدون كود: إذا تستخدم المتصفح، تقدر تستخدم Thunderbit. بدون برمجة، بدون بروكسيات، بدون صداع.
متى تختار Thunderbit بدل الزواحف التقليدية؟
- لما يكون هدفك النهائي جدول بيانات نظيف وقابل للاستخدام — مو مجرد قائمة روابط.
- لما تبي أتمت العملية كاملة (زحف، استخراج، تنظيف، تصدير) في مكان واحد.
- لما وقتك وراحة بالك لهم قيمة.
تقدر وتشوف بنفسك ليش كثير من مستخدمي الأعمال قاعدين ينتقلون له.
الخلاصة: كيف تستفيد لأقصى حد من زواحف المواقع المجانية
زواحف المواقع تطورت بشكل كبير. سواء كنت مسوّق، مطور، أو حتى شخص يبي يحافظ على صحة موقعه، بتلقى أداة مجانية (أو على الأقل مجانية للتجربة) تناسبك. من منصات بمستوى المؤسسات مثل BrightData وDiffbot، إلى أدوات مفتوحة المصدر مثل SiteOne وCrawljax، إلى أدوات خرائط مرئية مثل PowerMapper — الخيارات اليوم أوسع من أي وقت.
لكن إذا تدور طريقة أذكى وأكثر تكاملًا تنقلك من “أبي هالبيانات” إلى “هذا جدول البيانات جاهز”، عط Thunderbit فرصة. معمول لمستخدمي الأعمال اللي يبون نتائج، مو بس تقارير.
جاهز تبدأ؟ حمّل أداة، شغّل فحص، وشوف وش كنت تفوّت. وإذا تبي تنتقل من الزحف إلى بيانات قابلة للتنفيذ بنقرتين، .
للمزيد من الشروحات العملية والأدلة المتعمقة، زر .
الأسئلة الشائعة
ما الفرق بين زاحف المواقع وWeb Scraper؟
الزاحف يكتشف كل صفحات الموقع ويرسم خريطتها (مثل إنشاء فهرس محتويات). أما Web Scraper فيستخرج حقول بيانات محددة (مثل الأسعار أو الإيميلات أو المراجعات) من تلك الصفحات. الزواحف تعثر، والكاشطات تستخرج ().
ما أفضل زاحف مجاني لغير التقنيين؟
للمواقع الصغيرة وتدقيقات SEO، Screaming Frog سهل الاستخدام. وللخرائط المرئية، PowerMapper ممتاز خلال فترة التجربة. أما Thunderbit فهو الأسهل إذا كان هدفك بيانات منظمة وتريد تجربة بدون كود داخل المتصفح.
هل توجد مواقع تمنع زواحف الويب؟
نعم — بعض المواقع تستخدم ملفات robots.txt أو إجراءات منع الروبوتات (مثل CAPTCHA أو حظر IP) لمنع الزحف. أدوات مثل ScraperAPI وCrawlbase وThunderbit (مع Waterfall Crawling) تستطيع غالبًا تجاوز ذلك، لكن احرص دائمًا على الزحف بمسؤولية واحترام قواعد الموقع ().
هل لدى زواحف المواقع المجانية حدود للصفحات أو الميزات؟
غالبًا نعم. مثلًا، النسخة المجانية من Screaming Frog محدودة بـ 500 URL لكل عملية زحف؛ وتجربة PowerMapper محدودة بـ 100 صفحة. أما الأدوات المعتمدة على API فعادةً لديها حدود شهرية للرصيد. الأدوات مفتوحة المصدر مثل SiteOne أو Crawljax غالبًا بلا حدود صارمة، لكنك بتظل مقيدًا بقدرات جهازك.
هل استخدام زاحف ويب قانوني ومتوافق مع الخصوصية؟
عمومًا، زحف الصفحات العامة قانوني، لكن راجع دائمًا شروط استخدام الموقع وملف robots.txt. لا تزحف بيانات خاصة أو محمية بكلمة مرور دون إذن، وانتبه لقوانين الخصوصية إذا كنت تستخرج بيانات شخصية ().