

أصبحت بيانات الويب هي المدخل الأساسي للمبيعات والتسويق والعمليات. إذا كنت ما زلت تعتمد على النسخ واللصق اليدوي، فبصراحة أنت متأخر.
لكن المشكلة مع أدوات الاستخراج «المجانية» أن أغلبها ليس مجانيًا فعلًا. إما أنها مجرد تجارب بحدود صارمة، أو أنها تخبّي الميزات التي تحتاجها فعلًا خلف اشتراك مدفوع.
لذلك قيّمت 12 أداة لأعرف أيّها يتيح لك فعلًا إنجاز شغل حقيقي ضمن الخطة المجانية. جرّبت استخراج قوائم Google Maps، وصفحات ديناميكية خلف تسجيل الدخول، وملفات PDF. بعضها كان ممتازًا، وبعضها ضيّع وقتي.
هذه هي المراجعة الصريحة — بدءًا بالأدوات التي أنصح بها فعلًا.
لماذا أصبحت أدوات الاستخراج المجانية أهم من أي وقت مضى
خلّنا نكون واقعيين: في 2026، استخراج بيانات الويب لم يعد حكرًا على المخترقين أو علماء البيانات. صار جزءًا أساسيًا من شغل الشركات الحديثة، والأرقام تؤكد ذلك. بلغت قيمة سوق برامج استخراج الويب 1.01 مليار دولار في 2024، وهو في طريقه إلى أكثر من الضعف بحلول 2032. لماذا؟ لأن الجميع، من فرق المبيعات إلى وكلاء العقارات، يستخدمون بيانات الويب للحصول على أفضلية تنافسية.
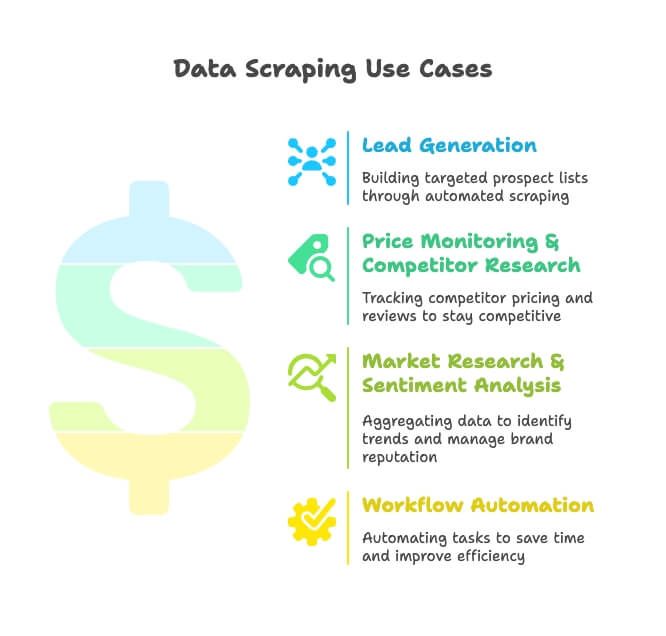
- توليد العملاء المحتملين: فرق المبيعات تستخرج الأدلة التجارية وGoogle Maps ووسائل التواصل لبناء قوائم عملاء مستهدفين — من دون البحث اليدوي المرهق.
- مراقبة الأسعار وتحليل المنافسين: فرق التجارة الإلكترونية والتجزئة تتابع منتجات المنافسين وأسعارهم وتقييماتهم للبقاء في المقدمة (ونعم، 82% من شركات التجارة الإلكترونية تفعل ذلك لهذا السبب تحديدًا).
- أبحاث السوق وتحليل المشاعر: المسوّقون يجمعون المراجعات والأخبار والحديث على الشبكات الاجتماعية لاكتشاف الاتجاهات وإدارة سمعة العلامة.
- أتمتة سير العمل: فرق العمليات تؤتمت كل شيء، من مراجعة المخزون إلى التقارير المجدولة، لتوفير ساعات كل أسبوع.
وهناك معلومة لطيفة: الشركات التي تستخدم أدوات استخراج الويب المدعومة بالذكاء الاصطناعي توفر 30–40% من وقتها مقارنة بالطرق اليدوية. وهذا ليس مجرد توفير بسيط — بل فرق حقيقي بين الخروج من المكتب الساعة 6 مساءً أو 9 مساءً.
كيف اخترنا أفضل أدوات استخراج البيانات المجانية
شفت كثيرًا من قوائم «أفضل أداة استخراج ويب» التي لا تفعل أكثر من إعادة تدوير كلام تسويقي. هنا الوضع مختلف. في هذه القائمة، ركزت على:
- قابلية الاستخدام الفعلي للخطة المجانية: هل الخطة المجانية تسمح لك بإنجاز شغل حقيقي، أم أنها مجرد عرض شكلي؟
- سهولة الاستخدام: هل يستطيع غير المبرمج الحصول على نتائج خلال دقائق، أم تحتاج إلى شهادة دكتوراه في Regex؟
- أنواع المواقع المدعومة: مواقع ثابتة، ديناميكية، متعددة الصفحات، تتطلب تسجيل دخول، ملفات PDF، ووسائل التواصل — هل الأداة تتعامل مع سيناريوهات العالم الحقيقي؟
- خيارات تصدير البيانات: هل يمكنك نقل بياناتك إلى Excel أو Google Sheets أو Notion أو Airtable بسهولة؟
- الميزات الإضافية: استخراج مدعوم بالذكاء الاصطناعي، الجدولة، القوالب، المعالجة اللاحقة، والتكاملات.
- ملاءمة نوع المستخدم: هل الأداة موجهة للمستخدمين التجاريين، أم للمحللين، أم للمطورين؟
كما راجعت وثائق كل أداة، واختبرت تجربة الإعداد الأولى، وقارنت حدود الخطة المجانية — لأن «مجاني» لا يعني دائمًا ما يبدو عليه.
نظرة سريعة: مقارنة 12 أداة مجانية لاستخراج البيانات
إليك مقارنة سريعة جنبًا إلى جنب لتسهيل تضييق الخيارات والوصول إلى الأداة الأنسب لاحتياجك.
| الأداة | المنصة | قيود الخطة المجانية | الأفضل لـ | صيغ التصدير | ميزات فريدة |
|---|---|---|---|---|---|
| Thunderbit | إضافة Chrome | 6 صفحات/شهر | غير المبرمجين، الأعمال | Excel، CSV | أوامر ذكاء اصطناعي، استخراج PDF/الصور، الزحف للصفحات الفرعية |
| Browse AI | سحابي | 50 رصيداً/شهر | مستخدمو no-code | CSV، Sheets | روبوتات بنقرة واحدة، الجدولة |
| Octoparse | سطح مكتب | 10 مهام، 50 ألف صف/شهر | no-code، شبه تقني | CSV، Excel، JSON | سير عمل بصري، دعم المواقع الديناميكية |
| ParseHub | سطح مكتب | 5 مشاريع، 200 صفحة/تشغيل | no-code، شبه تقني | CSV، Excel، JSON | واجهة بصرية، دعم المواقع الديناميكية |
| Webscraper.io | إضافة Chrome | استخدام محلي غير محدود | no-code، المهام البسيطة | CSV، XLSX | يعتمد على sitemap، قوالب مجتمعية |
| Apify | سحابي | 5 دولارات رصيد/شهر | الفرق، شبه التقنيين، المطورين | CSV، JSON، Sheets | سوق Actors، الجدولة، API |
| Scrapy | مكتبة Python | غير محدود (مفتوح المصدر) | المطورون | CSV، JSON، DB | تحكم كامل بالكود، قابلية توسع |
| Puppeteer | مكتبة Node.js | غير محدود (مفتوح المصدر) | المطورون | مخصص (بالكود) | متصفح بدون واجهة، دعم JavaScript الديناميكي |
| Selenium | متعدد اللغات | غير محدود (مفتوح المصدر) | المطورون | مخصص (بالكود) | أتمتة المتصفح، دعم عدة متصفحات |
| Zyte | سحابي | عنكبوت واحد، ساعة واحدة/مهمة، حفظ 7 أيام | المطورون، فرق العمليات | CSV، JSON | Scrapy مستضاف، إدارة البروكسي |
| SerpAPI | API | 100 عملية بحث/شهر | المطورون، المحللون | JSON | واجهات بحث، مقاومة الحظر |
| Diffbot | API | 10,000 رصيد/شهر | المطورون، مشاريع الذكاء الاصطناعي | JSON | استخراج بالذكاء الاصطناعي، knowledge graph |
Thunderbit: الخيار الأول لاستخراج البيانات بالذكاء الاصطناعي وبسلاسة للمستخدم
استخرج البيانات من أي موقع باستخدام الذكاء الاصطناعي Get Started Free
خلّنا نوضح لماذا Thunderbit يتصدر قائمتي. وأنا ما أقول هذا فقط لأنني جزء من الفريق — بل لأنني فعلًا أراه أقرب شيء إلى وجود مساعد ذكي يسمعك من أول مرة، وما يطلب استراحة قهوة كل خمس دقائق.
Thunderbit ليس تجربة «تعلّم الأداة ثم ابدأ الاستخراج» المعتادة. هو أقرب إلى أنك تعطي تعليمات لمساعد ذكي: تصف له ما تريد («اجلب أسماء المنتجات والأسعار والروابط من هذه الصفحة») وهو يتكفل بالباقي. لا XPath، ولا CSS selectors، ولا صداع Regex. وإذا أردت استخراج الصفحات الفرعية، مثل صفحات تفاصيل المنتج أو روابط تواصل الشركات، يمكن لـ Thunderbit أن ينقر تلقائيًا ويثري الجدول لديك — أيضًا بمجرد زر.
لكن الشيء الذي يميز Thunderbit فعلًا هو ما يحدث بعد الاستخراج. تحتاج تلخيص البيانات أو ترجمتها أو تصنيفها أو تنظيفها؟ المعالجة اللاحقة المدمجة بالذكاء الاصطناعي في Thunderbit تغطي كل هذا. أنت لا تحصل على بيانات خام فقط — بل على معلومات منظمة وجاهزة للاستخدام، مناسبة لـ CRM أو جدول البيانات أو مشروعك التالي.
الخطة المجانية: النسخة التجريبية المجانية في Thunderbit تتيح لك استخراج ما يصل إلى 6 صفحات (أو 10 مع تعزيز التجربة)، بما في ذلك ملفات PDF والصور وحتى قوالب وسائل التواصل الاجتماعي. يمكنك التصدير إلى Excel أو CSV مجانًا، وتجربة ميزات مثل استخراج البريد الإلكتروني أو الهاتف أو الصور. وللمهام الأكبر، تفتح الخطط المدفوعة مزيدًا من الصفحات، والتصدير المباشر إلى Google Sheets وNotion وAirtable، والاستخراج المجدول، وقوالب فورية لمواقع مشهورة مثل Amazon وGoogle Maps وInstagram.
إذا أردت تشوف Thunderbit وهو يعمل، تفقد Thunderbit Chrome Extension أو تصفح قناة YouTube لمقاطع البدء السريع.
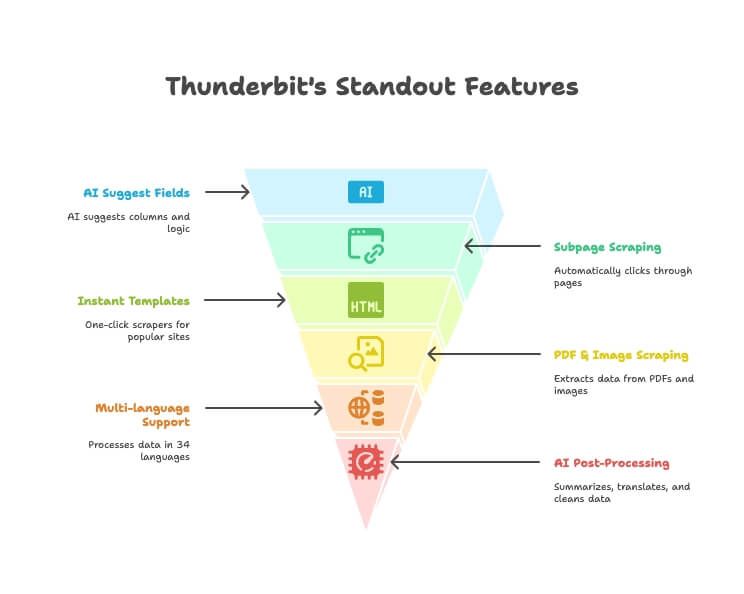
أبرز ميزات Thunderbit
- اقتراح الحقول بالذكاء الاصطناعي: صف البيانات التي تريدها، وسيقترح الذكاء الاصطناعي الأعمدة المناسبة ومنطق الاستخراج.
- استخراج الصفحات الفرعية: ينقر تلقائيًا على صفحات التفاصيل أو الروابط ويثري الجدول الأساسي — من دون إعداد يدوي.
- قوالب فورية: أدوات استخراج بنقرة واحدة لمواقع مثل Amazon وGoogle Maps وInstagram وغيرها.
- استخراج PDF والصور: استخرج الجداول والبيانات من ملفات PDF والصور باستخدام الذكاء الاصطناعي — من دون أدوات إضافية.
- دعم متعدد اللغات: استخرج البيانات وعالجها بـ 34 لغة.
- تصدير مباشر: أرسل بياناتك مباشرة إلى Excel أو Google Sheets أو Notion أو Airtable (في الخطط المدفوعة).
- معالجة لاحقة بالذكاء الاصطناعي: لخص، ترجم، صنّف، ونظّف البيانات أثناء الاستخراج.
- استخراج مجاني للبريد الإلكتروني/الهاتف/الصور: التقط معلومات التواصل أو الصور من أي موقع بنقرة واحدة.
Thunderbit يردم الفجوة بين «مجرد استخراج بيانات» و«الحصول على بيانات يمكنك استخدامها فعلًا». وهو أقرب ما رأيته إلى مساعد بيانات حقيقي بالذكاء الاصطناعي لمستخدمي الأعمال.
بقية أفضل 12 أداة: مراجعة أدوات استخراج البيانات المجانية
خلّنا نقسم بقية الأدوات حسب الفئة الأنسب لها.
للمستخدمين غير التقنيين وفرق الأعمال
Thunderbit
تمت تغطيته أعلاه. أسهل بداية لغير المبرمجين، مع ميزات ذكاء اصطناعي وقوالب فورية.
Webscraper.io
- المنصة: إضافة Chrome
- الأفضل لـ: المواقع البسيطة والثابتة؛ غير المبرمجين الذين لا يمانعون بعض التجربة والخطأ.
- الميزات الأساسية: استخراج يعتمد على sitemap، يدعم الصفحات المتعددة، وتصدير CSV/XLSX.
- الخطة المجانية: استخدام محلي غير محدود، لكن بلا تشغيل سحابي أو جدولة. تشغيل يدوي فقط.
- القيود: لا يوجد تعامل مدمج مع تسجيل الدخول أو ملفات PDF أو المحتوى الديناميكي المعقد. دعم المجتمع فقط.
ParseHub
- المنصة: تطبيق سطح مكتب (Windows وMac وLinux)
- الأفضل لـ: غير المبرمجين والمستخدمين شبه التقنيين المستعدين لاستثمار وقت في التعلم.
- الميزات الأساسية: منشئ سير عمل بصري، يدعم المواقع الديناميكية وAJAX وتسجيل الدخول والصفحات المتعددة.
- الخطة المجانية: 5 مشاريع عامة، 200 صفحة لكل تشغيل، وتشغيل يدوي فقط.
- القيود: المشاريع عامة في الخطة المجانية (انتبه للبيانات الحساسة)، لا توجد جدولة، وسرعة الاستخراج أبطأ.
Octoparse
- المنصة: تطبيق سطح مكتب (Windows/Mac)، وسحابي (مدفوع)
- الأفضل لـ: غير المبرمجين والمحللين الذين يريدون قوة ومرونة.
- الميزات الأساسية: سحب وإفلات بصري، دعم المحتوى الديناميكي، وقوالب للمواقع الشهيرة.
- الخطة المجانية: 10 مهام، حتى 50,000 صف/شهر، وعلى سطح المكتب فقط (بدون سحابة أو جدولة).
- القيود: لا يوجد API أو تدوير IP أو جدولة في الخطة المجانية. وقد يكون منحنى التعلم حادًا مع المواقع المعقدة.
Browse AI
- المنصة: سحابي
- الأفضل لـ: مستخدمي no-code الذين يريدون أتمتة الاستخراج والمراقبة البسيطة.
- الميزات الأساسية: مسجل روبوتات بنقرة واحدة، جدولة، وتكاملات (Sheets، Zapier).
- الخطة المجانية: 50 رصيدًا/شهر، موقع واحد، حتى 5 روبوتات.
- القيود: حجم محدود، وبعض التعلم الأولي للمواقع المعقدة.
للمطورين والمستخدمين التقنيين
Scrapy
- المنصة: مكتبة Python (مفتوح المصدر)
- الأفضل لـ: المطورين الذين يريدون تحكمًا كاملاً وقابلية توسع.
- الميزات الأساسية: قابلية تخصيص عالية، يدعم عمليات الزحف الكبيرة، وmiddleware وpipelines.
- الخطة المجانية: غير محدود (مفتوح المصدر).
- القيود: لا توجد واجهة رسومية، ويتطلب برمجة Python. غير مناسب لغير المبرمجين.
Puppeteer
- المنصة: مكتبة Node.js (مفتوح المصدر)
- الأفضل لـ: المطورين الذين يستخرجون بيانات من مواقع ديناميكية وغنية بـ JavaScript.
- الميزات الأساسية: أتمتة متصفح بدون واجهة، وتحكم كامل في التنقل والاستخراج.
- الخطة المجانية: غير محدود (مفتوح المصدر).
- القيود: يتطلب برمجة JavaScript، ولا توجد واجهة رسومية.
Selenium
- المنصة: متعدد اللغات (Python وJava وغيرها)، مفتوح المصدر
- الأفضل لـ: المطورين الذين يؤتمتون المتصفحات للاستخراج أو الاختبار.
- الميزات الأساسية: دعم عدة متصفحات، وأتمتة النقر والتمرير وتسجيل الدخول.
- الخطة المجانية: غير محدود (مفتوح المصدر).
- القيود: أبطأ من المكتبات التي تعمل بدون واجهة، ويتطلب كتابة سكربتات.
Zyte (Scrapy Cloud)
- المنصة: سحابي
- الأفضل لـ: المطورين وفرق العمليات الذين ينشرون Scrapy spiders على نطاق واسع.
- الميزات الأساسية: Scrapy مستضاف، إدارة البروكسي، وجدولة المهام.
- الخطة المجانية: عنكبوت واحد متزامن، ساعة واحدة لكل مهمة، والاحتفاظ بالبيانات لمدة 7 أيام.
- القيود: لا توجد جدولة متقدمة في الخطة المجانية، ويتطلب معرفة بـ Scrapy.
للاستخدام الجماعي والمؤسسي
Apify
- المنصة: سحابي
- الأفضل لـ: الفرق والمستخدمين شبه التقنيين والمطورين الذين يريدون أدوات جاهزة أو مخصصة.
- الميزات الأساسية: سوق Actors (روبوتات جاهزة)، الجدولة، API، والتكاملات.
- الخطة المجانية: 5 دولارات رصيد/شهر (تكفي للمهام الصغيرة)، مع حفظ البيانات لمدة 7 أيام.
- القيود: بعض التعلم الأولي، والاستخدام محدود بالأرصدة.
SerpAPI
- المنصة: API
- الأفضل لـ: المطورين والمحللين الذين يحتاجون بيانات محركات البحث (Google وBing وYouTube).
- الميزات الأساسية: واجهات بحث، مقاومة الحظر، ومخرجات JSON منظمة.
- الخطة المجانية: 100 عملية بحث/شهر.
- القيود: ليست للمواقع العشوائية، وتعمل عبر API فقط.
Diffbot
- المنصة: API
- الأفضل لـ: المطورين وفرق الذكاء الاصطناعي/التعلم الآلي والمؤسسات التي تحتاج بيانات ويب منظمة على نطاق واسع.
- الميزات الأساسية: استخراج مدعوم بالذكاء الاصطناعي، knowledge graph، وواجهات API للمقالات/المنتجات.
- الخطة المجانية: 10,000 رصيد/شهر.
- القيود: عبر API فقط، ويتطلب مهارات تقنية، مع تقييد في معدل المعالجة.
قيود الخطة المجانية: ماذا يعني «مجاني» فعلًا لكل أداة استخراج بيانات
خلّنا نكون صريحين — كلمة «مجاني» قد تعني أي شيء من «غير محدود للهواة» إلى «يكفي فقط لتبدأ». إليك ما تحصل عليه فعلًا:
| الأداة | الصفحات/الصفوف شهرياً | صيغ التصدير | الجدولة | الوصول إلى API | القيود المجانية البارزة |
|---|---|---|---|---|---|
| Thunderbit | 6 صفحات | Excel، CSV | لا | لا | اقتراح الحقول بالذكاء الاصطناعي محدود، ولا يوجد تصدير مباشر إلى Sheets/Notion في الخطة المجانية |
| Browse AI | 50 رصيداً | CSV، Sheets | نعم | نعم | موقع واحد، 5 روبوتات، والاحتفاظ بالبيانات 15 يوماً |
| Octoparse | 50,000 صف | CSV، Excel، JSON | لا | لا | على سطح المكتب فقط، بلا سحابة أو جدولة |
| ParseHub | 200 صفحة/تشغيل | CSV، Excel، JSON | لا | لا | 5 مشاريع عامة، وسرعة بطيئة |
| Webscraper.io | محلي غير محدود | CSV، XLSX | لا | لا | تشغيل يدوي فقط، بلا سحابة |
| Apify | 5 دولارات رصيد تقريباً (مهام صغيرة) | CSV، JSON، Sheets | نعم | نعم | الاحتفاظ بالبيانات 7 أيام، وحد أرصدة |
| Scrapy | غير محدود | CSV، JSON، DB | لا | غير متاح | يتطلب برمجة |
| Puppeteer | غير محدود | مخصص (بالكود) | لا | غير متاح | يتطلب برمجة |
| Selenium | غير محدود | مخصص (بالكود) | لا | غير متاح | يتطلب برمجة |
| Zyte | عنكبوت واحد، ساعة/مهمة | CSV، JSON | محدود | نعم | حفظ 7 أيام، ومهمة متزامنة واحدة |
| SerpAPI | 100 عملية بحث | JSON | لا | نعم | واجهات البحث فقط |
| Diffbot | 10,000 رصيد | JSON | لا | نعم | عبر API فقط، ومقيد بمعدل الاستخدام |
الخلاصة: بالنسبة للمشاريع الحقيقية، توفر Thunderbit وBrowse AI وApify أكثر التجارب المجانية فائدة للمستخدمين التجاريين. أما للاستخراج المستمر أو واسع النطاق، فستصل بسرعة إلى الحدود، وستحتاج إلى الترقية أو الانتقال إلى الحلول مفتوحة المصدر أو المعتمدة على الكود.
ما هي أداة استخراج البيانات الأنسب لاحتياجاتك؟ (دليل حسب نوع المستخدم)
إليك ورقة غش تساعدك على اختيار الأداة المناسبة وفقًا لدورك ومستوى ارتياحك التقني:
| نوع المستخدم | أفضل الأدوات (مجانية) | لماذا |
|---|---|---|
| غير مبرمج (المبيعات/التسويق) | Thunderbit، Browse AI، Webscraper.io | الأسهل تعلماً، بنقرة واحدة، ومساعدة ذكاء اصطناعي |
| شبه تقني (العمليات/المحلل) | Octoparse، ParseHub، Apify، Zyte | قوة أكبر، يتعامل مع المواقع المعقدة، مع إمكانية بعض البرمجة |
| مطور/مهندس | Scrapy، Puppeteer، Selenium، Diffbot، SerpAPI | تحكم كامل، غير محدود، ومبني على API |
| فريق/مؤسسة | Apify، Zyte | تعاون، جدولة، وتكاملات |
سيناريوهات واقعية لاستخراج الويب: مقارنة قدرة الأدوات على التكيّف
خلّنا نشوف كيف تتفوق هذه الأدوات في خمسة سيناريوهات شائعة لاستخراج البيانات:
| السيناريو | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| قوائم متعددة الصفحات | سهل | سهل | متوسط | متوسط | متوسط | سهل | سهل | سهل | سهل | سهل | غير متاح | متوسط |
| قوائم Google Maps | سهل* | صعب | متوسط | متوسط | صعب | سهل | صعب | صعب | صعب | صعب | سهل | غير متاح |
| صفحات تتطلب تسجيل دخول | سهل | متوسط | متوسط | متوسط | يدوي | متوسط | سهل | سهل | سهل | سهل | غير متاح | غير متاح |
| استخراج بيانات PDF | سهل | لا | لا | لا | لا | متوسط | صعب | صعب | صعب | صعب | لا | محدود |
| محتوى وسائل التواصل الاجتماعي | سهل* | جزئي | صعب | صعب | صعب | سهل | صعب | صعب | صعب | صعب | YouTube | محدود |
- يقدم كل من Thunderbit وApify قوالب/Actors جاهزة لـ Google Maps واستخراج محتوى وسائل التواصل، ما يجعل هذه السيناريوهات أسهل بكثير للمستخدمين غير التقنيين.
إضافة المتصفح vs سطح المكتب vs السحابة: ما أفضل تجربة لأداة استخراج الويب؟
- إضافات Chrome (Thunderbit، Webscraper.io):
- الإيجابيات: سريعة البدء، تعمل داخل المتصفح، وإعدادها محدود.
- السلبيات: تشغيل يدوي، تتأثر بتغييرات الموقع، وأتمتة محدودة.
- ميزة Thunderbit: الذكاء الاصطناعي يتعامل مع تغييرات البنية، والتنقل بين الصفحات الفرعية، وحتى استخراج PDF/الصور — وهذا يجعله أقوى بكثير من الإضافات التقليدية.
- تطبيقات سطح المكتب (Octoparse، ParseHub):
- الإيجابيات: قوية، وسير عمل بصري، وتتعامل مع المواقع الديناميكية وتسجيل الدخول.
- السلبيات: منحنى تعلم أعلى، ولا توجد أتمتة سحابية في الخطط المجانية، وتعتمد على نظام التشغيل.
- المنصات السحابية (Browse AI، Apify، Zyte):
- الإيجابيات: جدولة، تعاون جماعي، قابلية توسع، وتكاملات.
- السلبيات: الخطط المجانية غالبًا محدودة بالأرصدة، وقد تحتاج بعض الإعداد، وربما معرفة بـ API.
- المكتبات مفتوحة المصدر (Scrapy، Puppeteer، Selenium):
- الإيجابيات: غير محدودة، قابلة للتخصيص، ومثالية للمطورين.
- السلبيات: تتطلب برمجة، وليست للمستخدمين التجاريين.
اتجاهات 2026 في استخراج الويب: ما الذي يميز الأدوات الحديثة
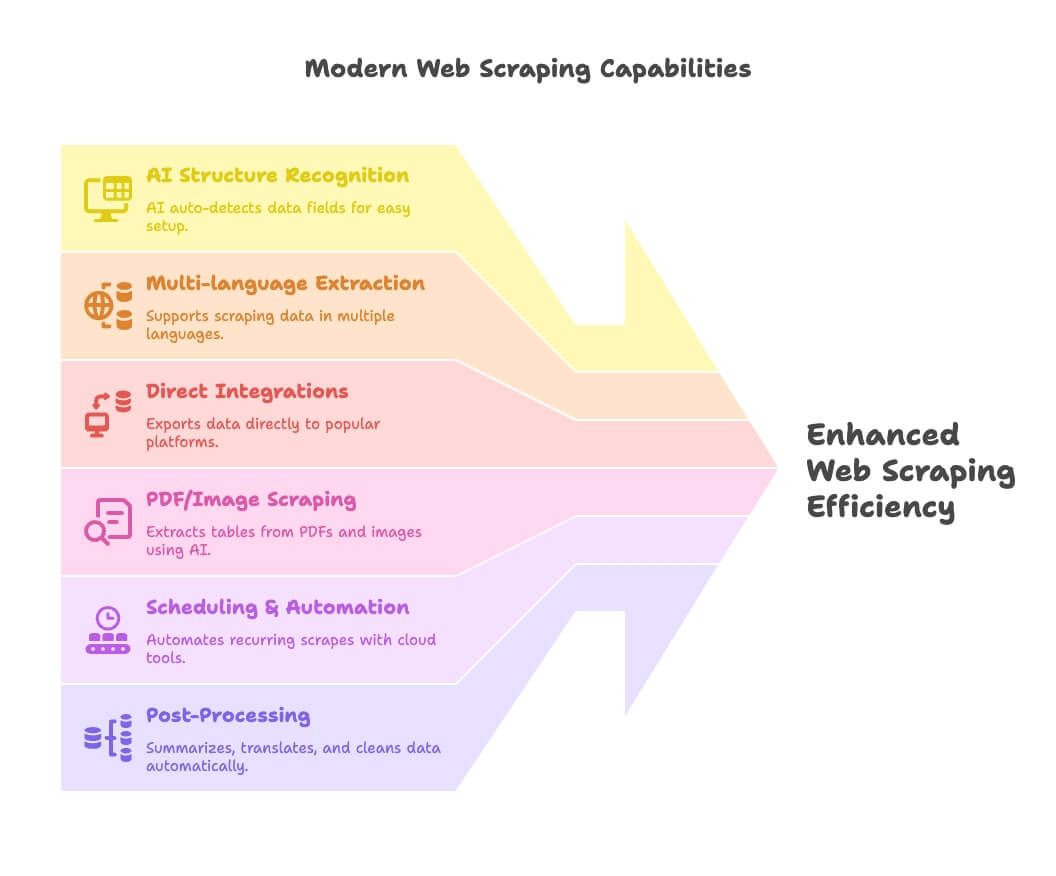
استخراج الويب في 2026 يدور حول الذكاء الاصطناعي والأتمتة والتكامل. إليك الجديد:
- التعرف على البنية بالذكاء الاصطناعي: أدوات مثل Thunderbit تستخدم الذكاء الاصطناعي لاكتشاف حقول البيانات تلقائيًا، ما يجعل الإعداد سهلًا جدًا لغير المبرمجين.
- استخراج متعدد اللغات: Thunderbit وغيرها تدعم استخراج البيانات ومعالجتها بعشرات اللغات.
- تكاملات مباشرة: صدّر البيانات المستخرجة مباشرة إلى Google Sheets أو Notion أو Airtable — من دون عناء CSV.
- استخراج PDF/الصور: Thunderbit يتصدر هنا، إذ يسمح لك باستخراج الجداول من ملفات PDF والصور باستخدام الذكاء الاصطناعي.
- الجدولة والأتمتة: الأدوات السحابية (Apify، Browse AI) تتيح لك ضبط الاستخراج مرة واحدة ثم تنسى الموضوع.
- المعالجة اللاحقة: لخص، ترجم، صنّف، ونظف البيانات أثناء الاستخراج — من دون جداول فوضوية بعد الآن.
Thunderbit وApify وSerpAPI في طليعة هذه الاتجاهات، لكن Thunderbit يبرز لأنه يجعل الاستخراج المدعوم بالذكاء الاصطناعي متاحًا للجميع، وليس للمطورين فقط.
ما بعد الاستخراج: معالجة البيانات والميزات ذات القيمة المضافة
الموضوع لا يقتصر على الحصول على البيانات — بل على جعلها مفيدة. إليك كيف تتفوق الأدوات الكبرى في المعالجة اللاحقة:
| الأداة | التنظيف | الترجمة | التصنيف | التلخيص | ملاحظات |
|---|---|---|---|---|---|
| Thunderbit | نعم | نعم | نعم | نعم | معالجة لاحقة مدمجة بالذكاء الاصطناعي |
| Apify | جزئي | جزئي | جزئي | جزئي | يعتمد على الـ actor المستخدم |
| Browse AI | لا | لا | لا | لا | بيانات خام فقط |
| Octoparse | جزئي | لا | جزئي | لا | بعض معالجة الحقول |
| ParseHub | جزئي | لا | جزئي | لا | بعض معالجة الحقول |
| Webscraper.io | لا | لا | لا | لا | بيانات خام فقط |
| Scrapy | نعم* | نعم* | نعم* | نعم* | إذا برمجها المطور |
| Puppeteer | نعم* | نعم* | نعم* | نعم* | إذا برمجها المطور |
| Selenium | نعم* | نعم* | نعم* | نعم* | إذا برمجها المطور |
| Zyte | جزئي | لا | جزئي | لا | بعض ميزات الاستخراج التلقائي |
| SerpAPI | لا | لا | لا | لا | بيانات بحث منظمة فقط |
| Diffbot | نعم | نعم | نعم | نعم | مدعوم بالذكاء الاصطناعي، لكنه API فقط |
- يجب على المطور تنفيذ منطق المعالجة.
Thunderbit هو الأداة الوحيدة التي تسمح للمستخدمين غير التقنيين بالانتقال من بيانات ويب خام إلى رؤى منظمة قابلة للتنفيذ — وكل ذلك في سير عمل واحد.
المجتمع والدعم وموارد التعلم: كيف تبدأ بسرعة
الوثائق والتأهيل الأولي مهمان جدًا. إليك المقارنة:
| الأداة | الوثائق والدروس | المجتمع | القوالب | منحنى التعلم |
|---|---|---|---|---|
| Thunderbit | ممتازة | في نمو | نعم | منخفض جدًا |
| Browse AI | جيدة | جيد | نعم | منخفض |
| Octoparse | ممتازة | كبير | نعم | متوسط |
| ParseHub | ممتازة | كبير | نعم | متوسط |
| Webscraper.io | جيدة | منتدى | نعم | متوسط |
| Apify | ممتازة | كبير | نعم | متوسط-عالٍ |
| Scrapy | ممتازة | ضخم | غير متاح | عالٍ |
| Puppeteer | جيدة | كبير | غير متاح | عالٍ |
| Selenium | جيدة | ضخم | غير متاح | عالٍ |
| Zyte | جيدة | كبير | نعم | متوسط-عالٍ |
| SerpAPI | جيدة | متوسط | غير متاح | عالٍ |
| Diffbot | جيدة | متوسط | غير متاح | عالٍ |
Thunderbit وBrowse AI هما الأسهل للمبتدئين. Octoparse وParseHub لديهما موارد ممتازة لكنهما يحتاجان إلى بعض الصبر. أما Apify وأدوات المطورين فلديها منحنيات تعلم حادة لكنها موثقة جيدًا.
الخلاصة: اختيار أداة استخراج البيانات المجانية المناسبة في 2026
اطّلع على أفضل أدوات استخراج الويب في 2026 Get Started Free
الخلاصة: ليست كل أدوات استخراج البيانات «المجانية» متساوية في الفائدة، واختيارك يجب أن يعتمد على دورك ومستواك التقني واحتياجاتك الفعلية.
- إذا كنت مستخدمًا تجاريًا أو غير مبرمج وتريد الحصول على البيانات بسرعة — خصوصًا من المواقع المعقدة أو ملفات PDF أو الصور — فإن Thunderbit هو أفضل نقطة بداية. نهجه المعتمد على الذكاء الاصطناعي، والأوامر باللغة الطبيعية، وميزات المعالجة اللاحقة تجعله أقرب ما يكون إلى مساعد بيانات حقيقي بالذكاء الاصطناعي. جرّب Thunderbit Chrome Extension مجانًا، وشاهد كيف تنتقل بسرعة من «أحتاج هذه البيانات» إلى «هذا هو جدولي».
- إذا كنت مطورًا أو تحتاج إلى استخراج غير محدود وقابل للتخصيص، فالأدوات مفتوحة المصدر مثل Scrapy وPuppeteer وSelenium هي خيارك الأفضل.
- للأفراد ضمن الفرق أو المستخدمين شبه التقنيين، يقدم Apify وZyte حلولًا قابلة للتوسع والتعاون مع خطط مجانية سخية للمهام الصغيرة.
أياً كان سير عملك، ابدأ بالأداة التي تناسب مهاراتك واحتياجاتك. وتذكّر: في 2026، لست بحاجة إلى أن تكون مبرمجًا للاستفادة من قوة بيانات الويب — ما تحتاجه فقط هو المساعد المناسب (وربما بعض روح الدعابة عندما تتفوق عليك الروبوتات).
هل تريد التعمق أكثر؟ اطلع على المزيد من الأدلة والمقارنات في Thunderbit Blog، بما في ذلك:
- ما هو استخراج البيانات وكيف تقوم به في 2026
- كيفية استخراج بيانات المواقع إلى Excel باستخدام الذكاء الاصطناعي
- أفضل أدوات وبرامج استخراج الويب في 2026
جرّب AI Web Scraper Get Started Free




