
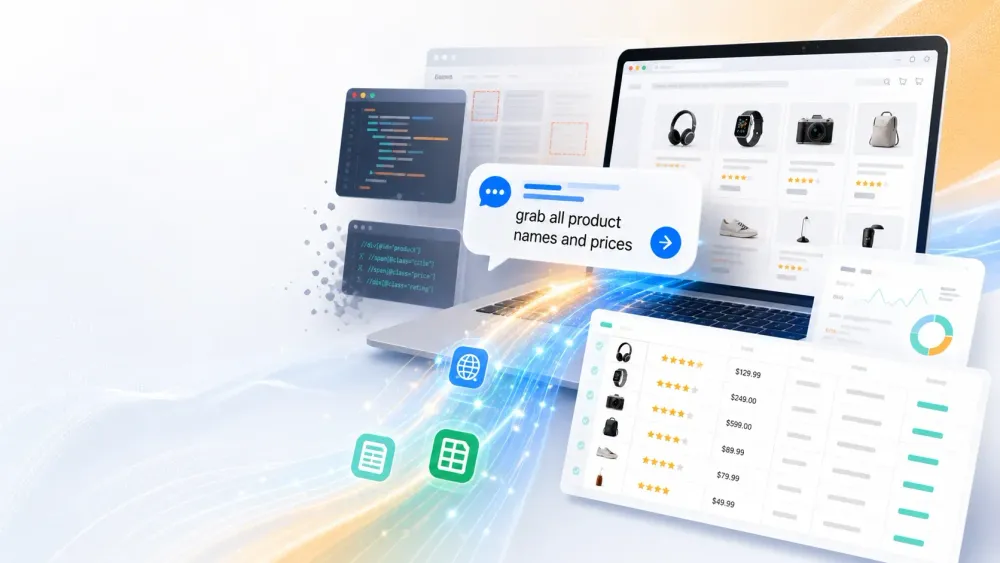
في عام 2015، كان استخراج البيانات يعني أن تتوسل إلى مطوّر ليكتب لك سكربت Python، أو أن تقضي عطلة نهاية الأسبوع تتعلم XPath. أما في 2026، فكل ما عليك هو أن تكتب: «اجلب جميع أسماء المنتجات والأسعار»، ويتكفّل الذكاء الاصطناعي بالباقي.
هذا التحول حدث بسرعة. اليوم تعتمد أكثر من مليوني شركة على استخراج بيانات الويب. كما تجاوزت السوق مليار دولار في 2024، وهي في طريقها إلى التضاعف بحلول 2030.
ما العامل الأكبر وراء ذلك؟ أدوات زحف الويب بالذكاء الاصطناعي. فهي تتكيف مع تغييرات التصميم، وتفهم محتوى الصفحة لا مجرد وسوم HTML. والأهم أنها تعمل حتى لمن لم يكتبوا سطر برمجة واحدًا في حياتهم.
لقد أمضيت أشهرًا في اختبار 15 أداة من هذه الأدوات. وهذه خلاصة ما وجدته — بما في ذلك سبب حصول Thunderbit (نعم، الشركة التي شاركت في تأسيسها) على المركز الأول.
لماذا يغيّر الذكاء الاصطناعي استخراج صفحات الويب: العصر الجديد لأدوات استخراج الويب
استخرج البيانات من أي موقع باستخدام الذكاء الاصطناعي Get Started Free
لنكن صريحين: استخراج الويب التقليدي لم يُبنَ أصلًا للمستخدم العادي في الأعمال. كان كله يدور حول الكود، وselectors، والدعاء ألا ينكسر السكربت كلما غيّر الموقع تصميمه. لكن الذكاء الاصطناعي وLLMs قلبا المعادلة بالكامل.
إليك كيف:
- تعليمات باللغة الطبيعية: بدل التعامل مع الكود، ما عليك سوى أن تخبر الذكاء الاصطناعي بما تريد. أدوات مثل Thunderbit تفهم تعليماتك باللغة الإنجليزية البسيطة وتُعدّ الاستخراج نيابةً عنك (المصدر).
- التعلّم التكيفي: تستطيع أدوات الاستخراج بالذكاء الاصطناعي التكيف مع تغييرات التصميم في المواقع، ما يقلل صداع الصيانة.
- التعامل مع المحتوى الديناميكي: المواقع الحديثة تعشق JavaScript والتمرير اللانهائي. تتفاعل الأدوات المدعومة بالذكاء الاصطناعي مع هذه العناصر وتلتقط بيانات كانت أدوات الجيل القديم ستفوتها.
- مخرجات منظمة عبر تحليل الذكاء الاصطناعي: أدوات الاستخراج القائمة على LLMs تفهم محتوى الصفحة فعلًا وتنتج بيانات نظيفة ومنظمة.
- تجاوز الحظر الآلي تلقائيًا: يمكن لأدوات الاستخراج بالذكاء الاصطناعي تجاوز إجراءات مكافحة الاستخراج واستخدام الوكلاء المتوسطيين والمتصفحات غير المرئية لتفادي حظر عناوين IP.
- تدفقات عمل متكاملة للبيانات: أفضل الأدوات لا تكتفي بجلب البيانات، بل توصلها إلى حيث تحتاجها، مع تصدير بنقرة واحدة إلى Google Sheets وAirtable وNotion وغير ذلك (المصدر).
والنتيجة؟ أصبح استخراج الويب الآن تجربة بنقرة واحدة أو حتى بأسلوب المحادثة، ما يفتح الباب أمام فرق المبيعات والتسويق والعمليات — وليس المطورين فقط — للاستفادة المباشرة من بيانات الويب.
15 أداة زحف ويب بالذكاء الاصطناعي تستحق اهتمامك في 2026
لنستعرض أفضل 15 أداة زحف ويب بالذكاء الاصطناعي، بدءًا من Thunderbit. سأعطيك الزبدة عن الميزات الأساسية لكل أداة، والفئة المستهدفة، والتسعير، وما الذي يميزها. ونعم، سأكون صريحًا أيضًا بشأن نقاط القوة والحدود.
1. Thunderbit: أداة استخراج الويب بالذكاء الاصطناعي للجميع
من الواضح أن لديّ هنا بعض التحيّز، لكن Thunderbit هي أداة استخراج الويب بالذكاء الاصطناعي التي تمنيت لو كانت متاحة لي منذ سنوات. لهذا السبب تحتل المركز الأول في هذه القائمة:
- الاستخراج باللغة الطبيعية: أنت «تتحدث» مع Thunderbit. فقط صف البيانات التي تريدها — مثل: «استخرج جميع أسماء المنتجات والأسعار من هذه الصفحة» — والذكاء الاصطناعي يتولى الباقي (المصدر). لا كود، لا selectors، ولا صداع.
- زحف الصفحات الفرعية ومتعدد المستويات: تستطيع Thunderbit اتباع الروابط واستخراج الصفحات الفرعية. مثلًا، استخرج قائمة منتجات ثم ادخل إلى كل منتج للحصول على التفاصيل، وكل ذلك في عملية واحدة.
- مخرجات منظمة فورية: يقوم الذكاء الاصطناعي بتنسيق البيانات وتنظيفها أثناء العمل، مع اقتراح الحقول ذات الصلة، وتوحيد الصيغ، وحتى تلخيص النصوص أو تصنيفها.
- دعم واسع للمصادر: Thunderbit ليست فقط للـ HTML؛ فهي تستطيع الاستخراج من ملفات PDF والصور باستخدام OCR مدمج وذكاء بصري (المصدر).
- تكاملات للأعمال: تصدير بنقرة واحدة إلى Google Sheets أو Airtable أو Notion أو Excel (المصدر). يمكنك جدولة عمليات الاستخراج وتمرير البيانات مباشرة إلى سير عمل فريقك.
- قوالب جاهزة: لمواقع مثل Amazon وLinkedIn وZillow وغيرها، تقدم Thunderbit وصفات استخراج جاهزة لاستخراج البيانات بنقرة واحدة.
- سهلة الاستخدام ومتاحة للجميع: الواجهة تعمل بالنقر، مع مساعد بديهي. ويذكر المستخدمون أنهم يبدأون العمل خلال دقائق.

تحظى Thunderbit بثقة أكثر من 30,000 مستخدم حول العالم، بما في ذلك فرق في Accenture وGrammarly وPuma. تستخدمها فرق المبيعات لبناء قوائم العملاء المحتملين، ويعتمد عليها الوسطاء العقاريون لتجميع القوائم العقارية، كما يستخدمها المسوّقون لمراقبة المنافسين — وكل ذلك من دون كتابة سطر برمجي واحد.
التسعير: تتوفر خطة مجانية (حتى 100 خطوة شهريًا)، وتبدأ الخطط المدفوعة من 14.99 دولارًا شهريًا. وحتى الخطط الاحترافية تظل في متناول الأفراد والفرق الصغيرة.
Thunderbit أقرب ما رأيته إلى «تحويل الويب إلى قاعدة بيانات» — وهي مصممة للجميع، لا للمهندسين فقط.
جرّب إضافة Thunderbit لمتصفح Chrome
2. Crawl4AI
لمن هي مناسبة: المطورون والفرق التقنية التي تبني خطوط معالجة مخصصة.
Crawl4AI إطار عمل مفتوح المصدر مبني على Python ومُحسّن للسرعة والزحف واسع النطاق، مع أخذ تكامل LLM بعين الاعتبار. وهو سريع جدًا، ويدعم المتصفحات غير المرئية للمحتوى الديناميكي، ويمكنه تنظيم البيانات المستخرجة لتغذيتها بسهولة في تدفقات عمل الذكاء الاصطناعي.
- الأفضل لـ: المطورين الذين يحتاجون إلى محرك زحف قوي وقابل للتخصيص.
- التسعير: مجاني (رخصة MIT). ستحتاج إلى استضافته وتشغيله بنفسك.
3. ScrapeGraphAI
لمن هي مناسبة: المطورون والمحللون الذين يبنون وكلاء ذكاء اصطناعي أو خطوط بيانات معقدة.
ScrapeGraphAI مكتبة Python مفتوحة المصدر تعتمد على الأوامر النصية وتحول المواقع إلى «رسوم بيانية» من البيانات المنظمة باستخدام LLMs. يمكنك كتابة أوامر مثل: «استخرج جميع أسماء المنتجات والأسعار والتقييمات من أول 5 صفحات»، وهي تنشئ لك سير عمل الاستخراج (المصدر).
- الأفضل لـ: المستخدمين المتمرسين تقنيًا الذين يريدون استخراجًا مرنًا قائمًا على الأوامر.
- التسعير: المكتبة مفتوحة المصدر مجانية؛ وتبدأ واجهة السحابة من 20 دولارًا شهريًا.
4. Firecrawl
لمن هي مناسبة: المطورون الذين يبنون وكلاء ذكاء اصطناعي أو خطوط بيانات واسعة النطاق.
Firecrawl منصة وزاحف API يركز على الذكاء الاصطناعي ويحوّل المواقع بأكملها إلى بيانات جاهزة لـ LLM . يخرج النتائج بصيغة Markdown أو JSON، ويتعامل مع المحتوى الديناميكي، ويتكامل مع أطر مثل LangChain وLlamaIndex.
- الأفضل لـ: المطورين الذين يحتاجون إلى تغذية نماذج الذكاء الاصطناعي ببيانات ويب حية.
- التسعير: النواة مفتوحة المصدر مجانية؛ وتبدأ الخطط السحابية من 19 دولارًا شهريًا.
5. Browse AI
لمن هي مناسبة: مستخدمو الأعمال، والهاكرز النمويون، والمحللون.
Browse AI منصة بلا كود بواجهة نقر وسحب. «تدرّب» الروبوت بالنقر على البيانات التي تريدها، ثم يعمّم الذكاء الاصطناعي النمط على عمليات الاستخراج المستقبلية. وهي تتعامل مع تسجيل الدخول، والتمرير اللانهائي، ويمكنها مراقبة المواقع بحثًا عن التغييرات.
- الأفضل لـ: المستخدمين غير التقنيين الذين يريدون أتمتة جمع البيانات والمراقبة.
- التسعير: خطة مجانية (50 رصيدًا شهريًا)؛ وتبدأ الخطط المدفوعة من 19 دولارًا شهريًا.
6. LLM Scraper
لمن هي مناسبة: المطورون الذين يريدون من الذكاء الاصطناعي أن يتولى التحليل.
LLM Scraper مكتبة JavaScript/TypeScript مفتوحة المصدر تتيح لك تعريف مخطط بيانات ثم تطلب من LLM استخراج تلك البيانات من أي صفحة ويب. وهي مبنية على Playwright، وتدعم مزودين متعددين لـ LLM، ويمكنها حتى توليد كود قابل لإعادة الاستخدام.
- الأفضل لـ: المطورين الذين يريدون تحويل أي صفحة ويب إلى بيانات منظمة باستخدام LLMs.
- التسعير: مجاني (رخصة MIT).
7. Reader (Jina Reader)
لمن هي مناسبة: المطورون الذين يبنون تطبيقات LLM أو روبوتات محادثة أو أدوات تلخيص.
Jina Reader هي واجهة API تستخرج نصًا نظيفًا وبيانات منظمة من صفحات الويب (وحتى ملفات PDF/الصور) ، وتعيد Markdown أو JSON جاهزين لـ LLM. وهي مدعومة بنموذج ذكاء اصطناعي مخصص، ويمكنها حتى إضافة وصف للصور.
- الأفضل لـ: جلب محتوى نظيف ومقروء لـ LLMs أو أنظمة الأسئلة والأجوبة.
- التسعير: واجهة API مجانية (لا حاجة إلى مفتاح للاستخدام الأساسي).
8. Bright Data
لمن هي مناسبة: الشركات والمؤسسات والمستخدمون المحترفون الذين يحتاجون إلى النطاق والامتثال والموثوقية.
Bright Data لاعب ثقيل في صناعة بيانات الويب، مع شبكة ضخمة من الوكلاء المتوسطيين وأدوات استخراج مدعومة بالذكاء الاصطناعي. وهي تقدم أدوات استخراج جاهزة، وواجهة عامة لـ Web Scraper API، وتغذيات بيانات «جاهزة لـ LLM».
- الأفضل لـ: المؤسسات التي تحتاج إلى بيانات ويب موثوقة وعلى نطاق واسع.
- التسعير: بنظام الاستخدام، وبفئة سعرية مرتفعة. تتوفر فترات تجريبية مجانية.
9. Octoparse
لمن هي مناسبة: المستخدمون غير التقنيين إلى شبه التقنيين.
Octoparse أداة راسخة بلا كود، مع مصمم سير عمل مرئي واكتشاف تلقائي مدعوم بالذكاء الاصطناعي. تتعامل مع تسجيل الدخول، والتمرير اللانهائي، ويمكنها تصدير البيانات بصيغ مختلفة.
- الأفضل لـ: المحللين وأصحاب الأعمال الصغيرة والباحثين.
- التسعير: تتوفر خطة مجانية؛ وتبدأ الخطط المدفوعة من 119 دولارًا شهريًا.
10. Apify
لمن هي مناسبة: المطورون وفرق التقنية الذين يحتاجون إلى استخراج أو أتمتة مخصصة.
Apify منصة سحابية لتشغيل سكربتات الاستخراج («actors») وتوفر متجرًا لعناصر جاهزة مسبقًا. وهي قابلة للتوسع، وتتضمن تكاملًا مع الذكاء الاصطناعي، وتدعم إدارة الوكلاء المتوسطيين.
- الأفضل لـ: المطورين الذين يريدون تشغيل سكربتات مخصصة في السحابة.
- التسعير: خطة مجانية؛ وتبدأ الخطط المدفوعة بنظام الدفع حسب الاستخدام من 49 دولارًا شهريًا.
11. Zyte (Scrapy Cloud)
لمن هي مناسبة: المطورون والشركات التي تحتاج إلى استخراج بمستوى المؤسسات.
Zyte هي الشركة المطورة لـ Scrapy، وتقدم منصة سحابية واستخراجًا تلقائيًا مدعومًا بالذكاء الاصطناعي. وهي تتعامل مع الجدولة، والوكلاء المتوسطيين، والمشاريع واسعة النطاق.
- الأفضل لـ: فرق التطوير التي تدير مشاريع استخراج طويلة الأجل.
- التسعير: من فترات تجريبية مجانية إلى خطط مؤسسية مخصصة.
12. Webscraper.io
لمن هي مناسبة: المبتدئون، والصحفيون، والباحثون.
Webscraper.io إضافة Chrome شائعة جدًا لاستخراج البيانات بنقرة وسحب. وهي بسيطة، ومجانية للاستخدام المحلي، وتقدم خدمة سحابية للمهام الأكبر.
- الأفضل لـ: مهام الاستخراج السريعة لمرة واحدة.
- التسعير: الإضافة مجانية؛ وتبدأ الخطط السحابية من نحو 50 دولارًا شهريًا.
13. ParseHub
لمن هي مناسبة: المستخدمون غير التقنيين الذين يحتاجون إلى قوة أكبر من الأدوات الأساسية.
ParseHub تطبيق سطح مكتب يحتوي على سير عمل مرئي لاستخراج المحتوى الديناميكي، بما في ذلك الخرائط والنماذج. ويمكنه تشغيل المشاريع في السحابة، كما يوفر واجهة API.
- الأفضل لـ: المسوقين الرقميين، والمحللين، والصحفيين.
- التسعير: خطة مجانية (200 صفحة لكل تشغيل)؛ وتبدأ الخطط المدفوعة من 189 دولارًا شهريًا.
14. Diffbot
لمن هي مناسبة: الشركات والمؤسسات وفرق الذكاء الاصطناعي التي تحتاج إلى بيانات ويب منظمة على نطاق واسع.
يستخدم Diffbot الرؤية الحاسوبية ومعالجة اللغة الطبيعية لاستخراج البيانات تلقائيًا من أي صفحة ويب، ويقدم واجهات API للمقالات والمنتجات، إضافة إلى مخطط معرفة ضخم.
- الأفضل لـ: استخبارات السوق، والتمويل، وبيانات تدريب الذكاء الاصطناعي.
- التسعير: فئة مميزة تبدأ من نحو 299 دولارًا شهريًا.
15. DataMiner
لمن هي مناسبة: المستخدمون غير التقنيين، خصوصًا في المبيعات والتسويق والصحافة.
DataMiner إضافة Chrome لاستخراج بيانات الويب بسرعة وبأسلوب النقر. لديها مكتبة من «الوصفات» الجاهزة، ويمكنها التصدير مباشرة إلى Google Sheets.
- الأفضل لـ: المهام السريعة مثل تصدير الجداول أو القوائم إلى جداول البيانات.
- التسعير: خطة مجانية (500 صفحة يوميًا)؛ وتبدأ النسخة الاحترافية من نحو 19 دولارًا شهريًا.
مقارنة أفضل أدوات استخراج الويب بالذكاء الاصطناعي: أيها يناسب احتياجاتك؟
فيما يلي مقارنة عامة تساعدك على اختيار الأنسب:
| الأداة | استخدام الذكاء الاصطناعي/LLM | سهولة الاستخدام | الإخراج/التكامل | المناسب لـ | التسعير |
|---|---|---|---|---|---|
| Thunderbit | واجهة باللغة الطبيعية؛ يقترح الذكاء الاصطناعي الحقول | الأسهل (محادثة بلا كود) | تصدير إلى Sheets وAirtable وNotion | الفرق غير التقنية | خطة مجانية؛ احترافية بحوالي 30 دولارًا/شهر |
| Crawl4AI | زحف جاهز للذكاء الاصطناعي؛ تكامل مع LLMs | صعب (برمجة Python) | مكتبة/CLI؛ تكامل عبر الكود | المطورون الذين يحتاجون إلى خطوط بيانات سريعة للذكاء الاصطناعي | مجاني |
| ScrapeGraphAI | خطوط استخراج تعتمد على أوامر LLM | متوسط (بعض البرمجة أو API) | API/SDK؛ إخراج JSON | المطورون/المحللون الذين يبنون وكلاء ذكاء اصطناعي | مفتوح المصدر مجاني؛ API من 20 دولارًا/شهر |
| Firecrawl | يزحف إلى Markdown/JSON جاهز لـ LLM | متوسط (استخدام API/SDK) | SDKs (Py, Node وغيرها)؛ تكامل LangChain | المطورون الذين يدمجون بيانات الويب الحية مع الذكاء الاصطناعي | مجاني + سحابي مدفوع |
| Browse AI | نقر وسحب بمساعدة الذكاء الاصطناعي | سهل (بلا كود) | أكثر من 7000 تكامل تطبيقي (Zapier) | المستخدمون غير التقنيين لأتمتة مراقبة الويب | 50 تشغيلًا مجانيًا؛ مدفوع من 19 دولارًا/شهر |
| LLM Scraper | يستخدم LLMs لتحليل الصفحة إلى مخطط | صعب (برمجة TS/JS) | مكتبة كود؛ إخراج JSON | المطورون الذين يريدون من الذكاء الاصطناعي القيام بالتحليل | مجاني (باستخدام API الخاص بك لـ LLM) |
| Reader (Jina) | نموذج ذكاء اصطناعي يستخرج النص/JSON | سهل (نداء API بسيط) | REST API يعيد Markdown/JSON | المطورون الذين يضيفون البحث أو المحتوى إلى LLMs | واجهة API مجانية |
| Bright Data | واجهات استخراج معززة بالذكاء الاصطناعي؛ شبكة وكالات ضخمة | صعب (API، تقني) | APIs/SDKs؛ تدفقات بيانات أو مجموعات بيانات | المؤسسات على نطاق واسع | بنظام الاستخدام |
| Octoparse | اكتشاف تلقائي مدعوم بالذكاء الاصطناعي للقوائم | متوسط (تطبيق بلا كود) | CSV/Excel، وAPI للنتائج | المستخدمون شبه التقنيين | مجاني محدود؛ من 59 إلى 166 دولارًا/شهر |
| Apify | بعض ميزات الذكاء الاصطناعي (Actors، دروس AI) | صعب (برمجة سكربتات) | API شامل؛ يتكامل مع LangChain | المطورون الذين يحتاجون إلى استخراج مخصص في السحابة | خطة مجانية؛ الدفع حسب الاستخدام |
| Zyte (Scrapy) | استخراج تلقائي قائم على التعلم الآلي؛ إطار Scrapy | صعب (برمجة Python) | API، وواجهة Scrapy Cloud؛ JSON/CSV | فرق التطوير، المشاريع طويلة الأجل | تسعير مخصص |
| Webscraper.io | لا يستخدم الذكاء الاصطناعي (قوالب يدوية) | سهل (إضافة متصفح) | تنزيل CSV، وCloud API | المبتدئون، والاستخراج السريع لمرة واحدة | إضافة مجانية؛ السحابة بحوالي 50 دولارًا/شهر |
| ParseHub | بلا LLM صريح؛ منشئ مرئي | متوسط (تطبيق بلا كود) | JSON/CSV؛ API للتشغيل السحابي | غير المطورين الذين يجرون استخراجًا لمواقع معقدة | مجاني لـ 200 صفحة؛ مدفوع من 189 دولارًا/شهر |
| Diffbot | رؤية/لغة طبيعية للذكاء الاصطناعي لأي صفحة؛ مخطط معرفة | سهل (مجرد نداءات API) | APIs (Article/Prod/...) + استعلام Knowledge Graph | المؤسسات، والبيانات المنظمة من الويب | يبدأ من نحو 299 دولارًا/شهر |
| DataMiner | لا يستخدم LLM؛ وصفات مجتمعية | الأسهل (واجهة متصفح) | تصدير إلى Excel/CSV؛ Google Sheets | المستخدمون غير التقنيين الذين يستخرجون إلى جداول البيانات | مجاني محدود؛ الاحترافي بحوالي 19 دولارًا/شهر |
فئات الأدوات: من عمالقة المطورين إلى أدوات استخراج صديقة للأعمال
لفهم هذه القائمة، دعنا نصنّف الأدوات إلى عدة فئات:
1. عمالقة المطورين والمفتوح المصدر
- أمثلة: Crawl4AI، LLM Scraper، Apify، Zyte/Scrapy، Firecrawl
- نقاط القوة: مرونة عالية، وقابلية للتوسع، وإمكانية تخصيص كبيرة. ممتازة لبناء خطوط معالجة مخصصة أو دمجها مع نماذج الذكاء الاصطناعي.
- المقايضات: تتطلب مهارات برمجية وإعدادًا أكبر.
- حالات الاستخدام: بناء خط بيانات مخصص، أو استخراج مواقع معقدة، أو التكامل مع الأنظمة الداخلية.
2. وكلاء استخراج مدمجون بالذكاء الاصطناعي
- أمثلة: Thunderbit، ScrapeGraphAI، Firecrawl، Reader (Jina)، LLM Scraper
- نقاط القوة: تقلل الفجوة بين الاستخراج وفهم البيانات. وتجعلها واجهات اللغة الطبيعية في متناول الجميع.
- المقايضات: لا يزال بعضها في طور التطور؛ وقد لا يقدم تحكمًا تفصيليًا.
- حالات الاستخدام: الحصول على إجابات أو مجموعات بيانات بسرعة، وبناء وكلاء مستقلين، أو تغذية LLMs ببيانات حية.
3. أدوات بلا كود/قليلة الكود صديقة للأعمال
- أمثلة: Thunderbit، Browse AI، Octoparse، ParseHub، Webscraper.io، DataMiner
- نقاط القوة: سهلة الاستخدام، ولا تتطلب برمجة أو تتطلب القليل جدًا منها، ومناسبة للمهام التجارية المتكررة.
- المقايضات: قد تواجه صعوبة مع المواقع شديدة التعقيد أو عند العمل على نطاق ضخم.
- حالات الاستخدام: توليد العملاء المحتملين، ومراقبة المنافسين، ومشاريع البحث، واستخراج البيانات لمرة واحدة.
4. منصات وخدمات بيانات المؤسسات
- أمثلة: Bright Data، Diffbot، Zyte
- نقاط القوة: حلول متكاملة، وخدمات مُدارة، وامتثال، وموثوقية على نطاق واسع.
- المقايضات: تكلفة أعلى، وتتطلب إعدادًا أوليًا أكبر.
- حالات الاستخدام: خطوط بيانات دائمة التشغيل وعلى نطاق واسع، واستخبارات السوق، وبيانات تدريب الذكاء الاصطناعي.
كيف تختار أداة الزحف المناسبة لاحتياجات استخراج صفحات الويب لديك
ما هو استخراج البيانات وكيفية القيام به Get Started Free
قد يبدو اختيار الأداة المناسبة أمرًا مربكًا، لذا إليك دليلي خطوة بخطوة:
- حدّد أهدافك ومتطلبات البيانات بوضوح: ما المواقع والبيانات التي تحتاج إليها؟ كم مرة؟ وما الحجم؟ وماذا ستفعل بها؟
- قيّم قدرتك التقنية: لا تعرف البرمجة؟ جرّب Thunderbit أو Browse AI أو Octoparse. لديك بعض الخبرة بالسكربتات؟ LLM Scraper أو DataMiner. لديك مهارات قوية في التطوير؟ Crawl4AI أو Apify أو Zyte.
- ضع التكرار والنطاق في الاعتبار: هل المهمة لمرة واحدة؟ استخدم الأدوات المجانية. هل هي متكررة؟ ابحث عن ميزات الجدولة. هل النطاق كبير؟ اختر أدوات المؤسسات أو الحلول المفتوحة المصدر على نطاق واسع.
- الميزانية ونموذج التسعير: الخطط المجانية ممتازة للاختبار. والاختيار بين الاشتراك أو التسعير حسب الاستخدام يعتمد على احتياجاتك.
- التجربة والإثبات العملي: اختبر بعض الأدوات على بياناتك الفعلية. معظمها يوفر مستويات مجانية.
- الصيانة والدعم: من سيصلح الأمور إذا تغيّر الموقع؟ أدوات بلا كود مدعومة بالذكاء الاصطناعي قد تصلح التغييرات الصغيرة تلقائيًا؛ أما المفتوحة المصدر فتحتاج إليك أو إلى المجتمع.
- طابق الأدوات مع السيناريوهات: فريق مبيعات يستخرج العملاء المحتملين؟ Thunderbit أو Browse AI. باحث يجمع التغريدات؟ DataMiner أو Webscraper.io. نموذج ذكاء اصطناعي يحتاج مقالات أخبار؟ Jina Reader أو Zyte. تبني موقع مقارنة؟ Apify أو Zyte.
- ضع خطة بديلة: أحيانًا لا تعمل أداة معينة مع موقع محدد. لذلك احتفظ بخيار احتياطي.
الأداة «المناسبة» هي التي تمنحك البيانات التي تحتاجها بأقل قدر من الاحتكاك وضمن ميزانيتك. وأحيانًا تكون مجموعة أدوات لا أداة واحدة.
Thunderbit مقابل أدوات استخراج الويب التقليدية: ما الذي يميزها؟
لنكن محددين بشأن سبب اختلاف Thunderbit:
- واجهة باللغة الطبيعية: لا كود، ولا حركات نقر معقدة. فقط صف ما تريد (المصدر).
- إعداد صفري واقتراحات للقوالب: تكتشف Thunderbit تلقائيًا الترقيم بين الصفحات والصفحات الفرعية، وتقترح أيضًا قوالب للمواقع الشائعة (المصدر).
- تنظيف البيانات وإثراؤها بالذكاء الاصطناعي: لخّص، وصنّف، وترجم، وأثرِ البيانات أثناء استخراجها (المصدر).
- متاعب صيانة أقل: ذكاء Thunderbit أكثر قدرة على الصمود أمام التغييرات الطفيفة في المواقع، ما يقلل الأعطال.
- تكامل مع أدوات الأعمال: تصدير مباشر إلى Google Sheets وAirtable وNotion — لا مزيد من العبث بملفات CSV (المصدر).
- السرعة إلى القيمة: انتقل من الفكرة إلى البيانات في دقائق لا أيام.
- منحنى التعلم: إذا كنت تستطيع تصفح الويب ووصف ما تحتاجه، يمكنك استخدام Thunderbit.
- المرونة: استخرج من المواقع وملفات PDF والصور وغيرها — بالأداة نفسها.
Thunderbit ليست مجرد أداة استخراج؛ إنها مساعد بيانات ينسجم مع سير عملك، سواء كنت تعمل في المبيعات أو التسويق أو التجارة الإلكترونية أو العقارات.
جرّب أداة Thunderbit لاستخراج الويب بالذكاء الاصطناعي
أفضل ممارسات استخراج صفحات الويب باستخدام أدوات الاستخراج بالذكاء الاصطناعي
لتحصل على أقصى استفادة من أدوات استخراج الويب بالذكاء الاصطناعي، إليك أهم نصائحي:
- عرّف احتياجاتك من البيانات بوضوح: اعرف الحقول التي تريدها، وعدد الصفحات، والصيغة المطلوبة.
- استفد من اقتراحات الذكاء الاصطناعي: استخدم اكتشاف الحقول واقتراحات الأداة لالتقاط البيانات المهمة التي قد تفوتك (المصدر).
- ابدأ صغيرًا وتحقق: اختبر على عينة صغيرة، وتحقق من المخرجات، وعدّل عند الحاجة.
- تعامل مع المحتوى الديناميكي: تأكد من أن أداةك تدعم المحتوى الديناميكي والتفاعلات مثل الترقيم بين الصفحات والتمرير اللانهائي.
- احترم سياسات المواقع: راجع robots.txt، وتجنب استخراج البيانات الحساسة، واحترم حدود المعدل.
- ادمجها مع الأتمتة: استخدم ميزات التصدير وwebhooks لتمرير البيانات المستخرجة مباشرة إلى سير عملك.
- حافظ على جودة البيانات: افحص البيانات منطقيًا، واستخدم المعالجة اللاحقة، وراقب الأخطاء.
- كن موجزًا في الأوامر: عند استخدام الأدوات المعتمدة على الذكاء الاصطناعي، تؤدي التعليمات الواضحة والمحددة إلى نتائج أفضل.
- تعلّم من المجتمع: انضم إلى المنتديات والمجتمعات للحصول على النصائح وحل المشكلات.
- ابقَ محدّثًا: تتطور أدوات الذكاء الاصطناعي بسرعة — تابع الميزات والتحسينات الجديدة.
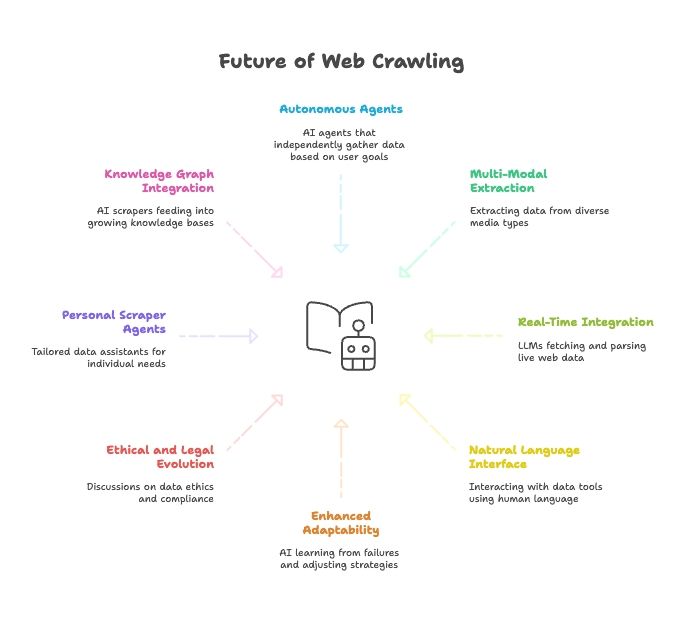
مستقبل استخراج الويب: الذكاء الاصطناعي، وLLMs، وصعود وكلاء استخراج الويب باللغة الطبيعية
عند النظر إلى الأمام، فإن تقارب الذكاء الاصطناعي واستخراج الويب لا يزال يتسارع:
- وكلاء استخراج مستقلون بالكامل: قريبًا ستخبر وكيلًا ذكيًا بهدفك النهائي فقط، وهو سيعرف كيف يحصل على البيانات.
- استخراج بيانات متعدد الوسائط: ستسحب أدوات الاستخراج البيانات من النصوص والصور وملفات PDF وحتى الفيديوهات.
- تكامل لحظي مع نماذج الذكاء الاصطناعي: ستحتوي LLMs على وحدات مدمجة لجلب بيانات الويب الحية وتحليلها.
- اللغة الطبيعية في كل شيء: سنتحدث إلى أدوات البيانات كما نتحدث إلى البشر، ما يجعل جمع البيانات وتحويلها متاحًا للجميع.
- قدرة تكيفية محسّنة: ستتعلم أدوات الاستخراج بالذكاء الاصطناعي من الإخفاقات وتكيّف استراتيجياتها تلقائيًا.
- تطور أخلاقي وقانوني: نتوقع المزيد من النقاش حول أخلاقيات البيانات والامتثال والاستخدام العادل.
- وكلاء استخراج شخصيون: تخيّل مساعد بيانات شخصي يجمع الأخبار وإعلانات الوظائف وغير ذلك بما يناسب احتياجاتك.
- التكامل مع مخططات المعرفة: ستغذي أدوات الاستخراج بالذكاء الاصطناعي باستمرار قواعد معرفة تكبر مع الوقت، ما يدعم ذكاءً اصطناعيًا أذكى.
الخلاصة؟ مستقبل استخراج الويب مرتبط ارتباطًا وثيقًا بمستقبل الذكاء الاصطناعي. الأدوات تزداد ذكاءً واستقلالية وسهولة وصول كل يوم.
الخلاصة: إطلاق قيمة الأعمال مع أداة الزحف المناسبة بالذكاء الاصطناعي
انتقل استخراج الويب من مهارة متخصصة وتقنية إلى قدرة أساسية للأعمال — بفضل الذكاء الاصطناعي. الأدوات الـ 15 التي تناولتها هنا تمثل أفضل ما يمكن فعله في 2026، من أدوات المطورين القوية إلى المساعدات الصديقة للأعمال.
والسر الحقيقي؟ اختيار الأداة المناسبة يمكن أن يزيد بشكل كبير من القيمة التي تحصل عليها من بيانات الويب. بالنسبة للفرق غير التقنية، Thunderbit هي أسهل طريقة لتحويل الويب إلى قاعدة بيانات منظمة وجاهزة للتحليل — بلا كود، بلا عناء، فقط نتائج.
لذلك، سواء كنت تجمع العملاء المحتملين، أو تراقب المنافسين، أو تغذي نموذج الذكاء الاصطناعي من الجيل التالي، خذ وقتك في تقييم احتياجاتك، وجرب بعض الأدوات، وانظر ما الذي يناسبك. وإذا أردت تجربة مستقبل استخراج الويب اليوم، فجرّب Thunderbit. الرؤى التي تحتاجها لا تبعد سوى أمر واحد.
هل تريد المزيد؟ اطلع على مدونة Thunderbit للحصول على تحليلات معمقة، ودروس، وأحدث ما توصل إليه استخراج البيانات المدعوم بالذكاء الاصطناعي.
قراءات إضافية:
- ما هو استخراج البيانات وكيفية القيام به في 2026
- كيفية استخراج بيانات المواقع إلى Excel باستخدام الذكاء الاصطناعي
- أفضل أدوات وبرامج استخراج الويب في 2026
جرّب أداة استخراج الويب بالذكاء الاصطناعي Get Started Free
الأسئلة الشائعة
1. ما هو أداة زحف ويب بالذكاء الاصطناعي وكيف تختلف عن أدوات استخراج الويب التقليدية؟
تستخدم أداة زحف الويب بالذكاء الاصطناعي معالجة اللغة الطبيعية والتعلّم الآلي لفهم بيانات الويب واستخراجها وتنظيمها. وعلى عكس أدوات الاستخراج التقليدية التي تتطلب برمجة يدوية واستخدام محددات XPath، تستطيع الأدوات المدعومة بالذكاء الاصطناعي التعامل مع المحتوى الديناميكي، والتكيف مع تغييرات التصميم، وفهم تعليمات المستخدم بلغة إنجليزية بسيطة.
2. من ينبغي أن يستخدم أدوات استخراج الويب بالذكاء الاصطناعي مثل Thunderbit؟
تم بناء Thunderbit لكل من المستخدمين غير التقنيين والتقنيين. وهي مثالية لمتخصصي المبيعات والتسويق والعمليات والبحث والتجارة الإلكترونية الذين يريدون استخراج بيانات منظمة من المواقع أو ملفات PDF أو الصور — من دون كتابة أي كود.
3. ما الميزات التي تجعل Thunderbit تبرز عن غيرها من أدوات زحف الويب بالذكاء الاصطناعي؟
تقدم Thunderbit واجهة باللغة الطبيعية، وزحفًا متعدد المستويات، وتنظيمًا تلقائيًا للبيانات، ودعم OCR، وتصديرًا سلسًا إلى منصات مثل Google Sheets وAirtable. كما تتضمن اقتراحات للحقول مدعومة بالذكاء الاصطناعي وقوالب جاهزة للمواقع الشائعة.
4. هل توجد خيارات مجانية لاستخراج الويب بالذكاء الاصطناعي في 2026؟
نعم. العديد من الأدوات مثل Thunderbit وBrowse AI وDataMiner تقدم خططًا مجانية مع استخدام محدود. أما للمطورين، فهناك خيارات مفتوحة المصدر مثل Crawl4AI وScrapeGraphAI توفر وظائف كاملة مجانًا، لكنها تتطلب إعدادًا تقنيًا.
5. كيف أختار أداة زحف الويب بالذكاء الاصطناعي المناسبة لاحتياجاتي؟
ابدأ بتحديد أهدافك من البيانات، وقدرتك التقنية، وميزانيتك، ومتطلبات النطاق. إذا كنت تريد حلًا بلا كود وسهل الاستخدام، فـ Thunderbit أو Browse AI خياران ممتازان. أما للاحتياجات الضخمة أو المخصصة، فالأدوات مثل Apify أو Bright Data تكون أكثر ملاءمة.




