Wikipedia Search Result Scraper
Chceš scrapovat data hromadně? Vyzkoušej Thunderbit zdarma.








Collect Wikipedia Search Results Fast
How to Extract Wikipedia Results Using Thunderbit



Learn how to extract structured data from Wikipedia search results
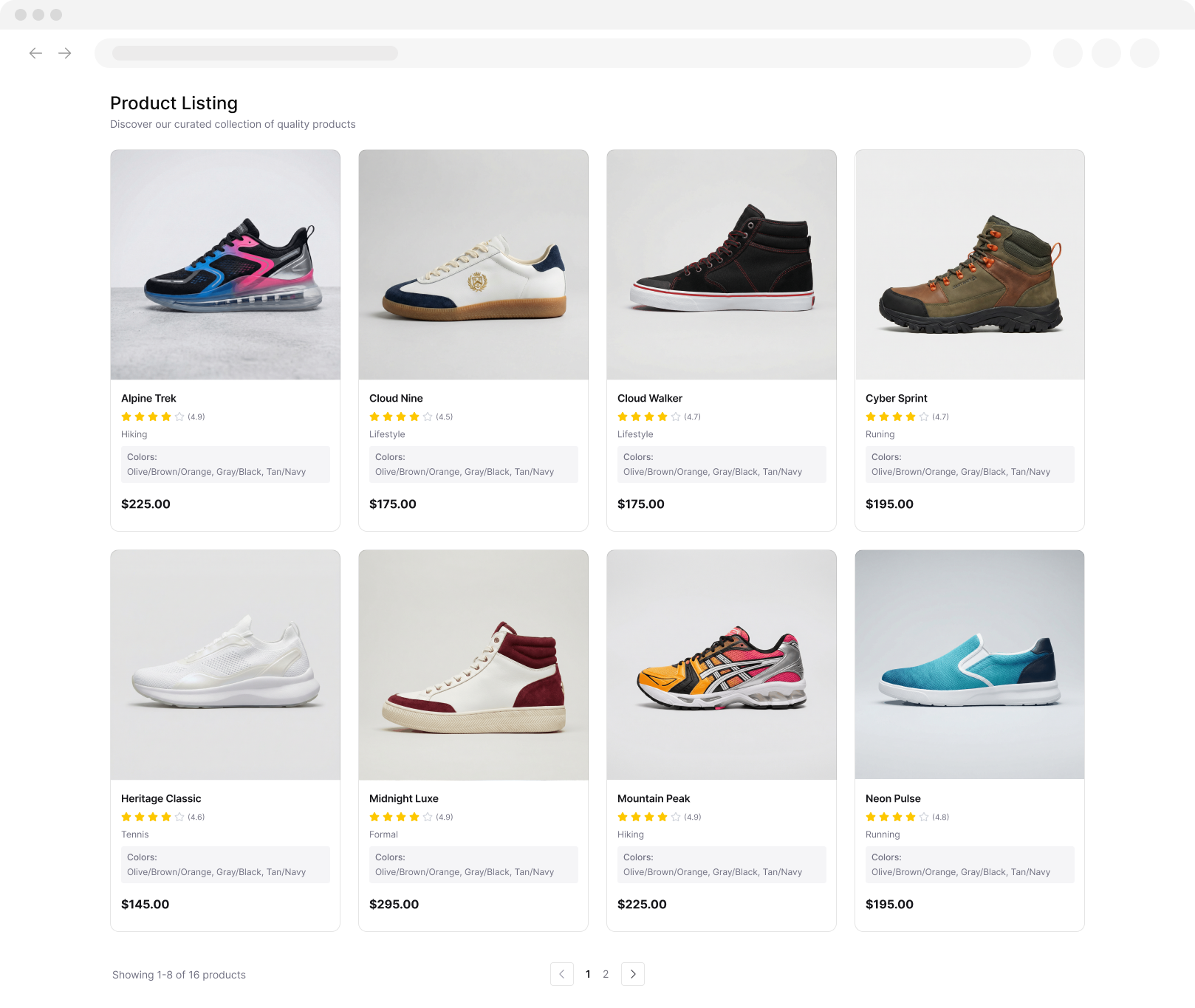
Collect Topic Data from Wikipedia Search Pages

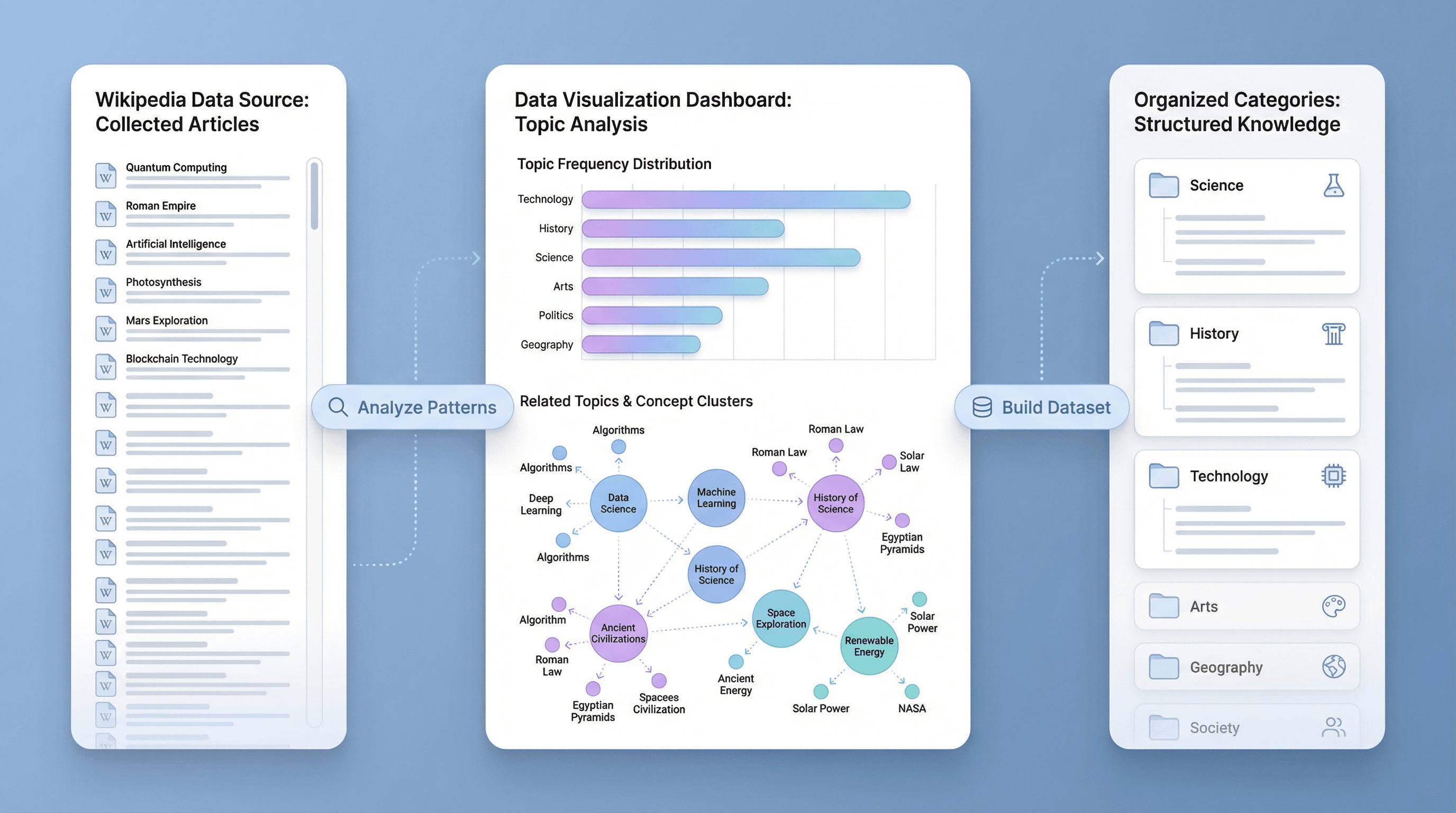
Analyze and Organize Large Sets of Wikipedia Results
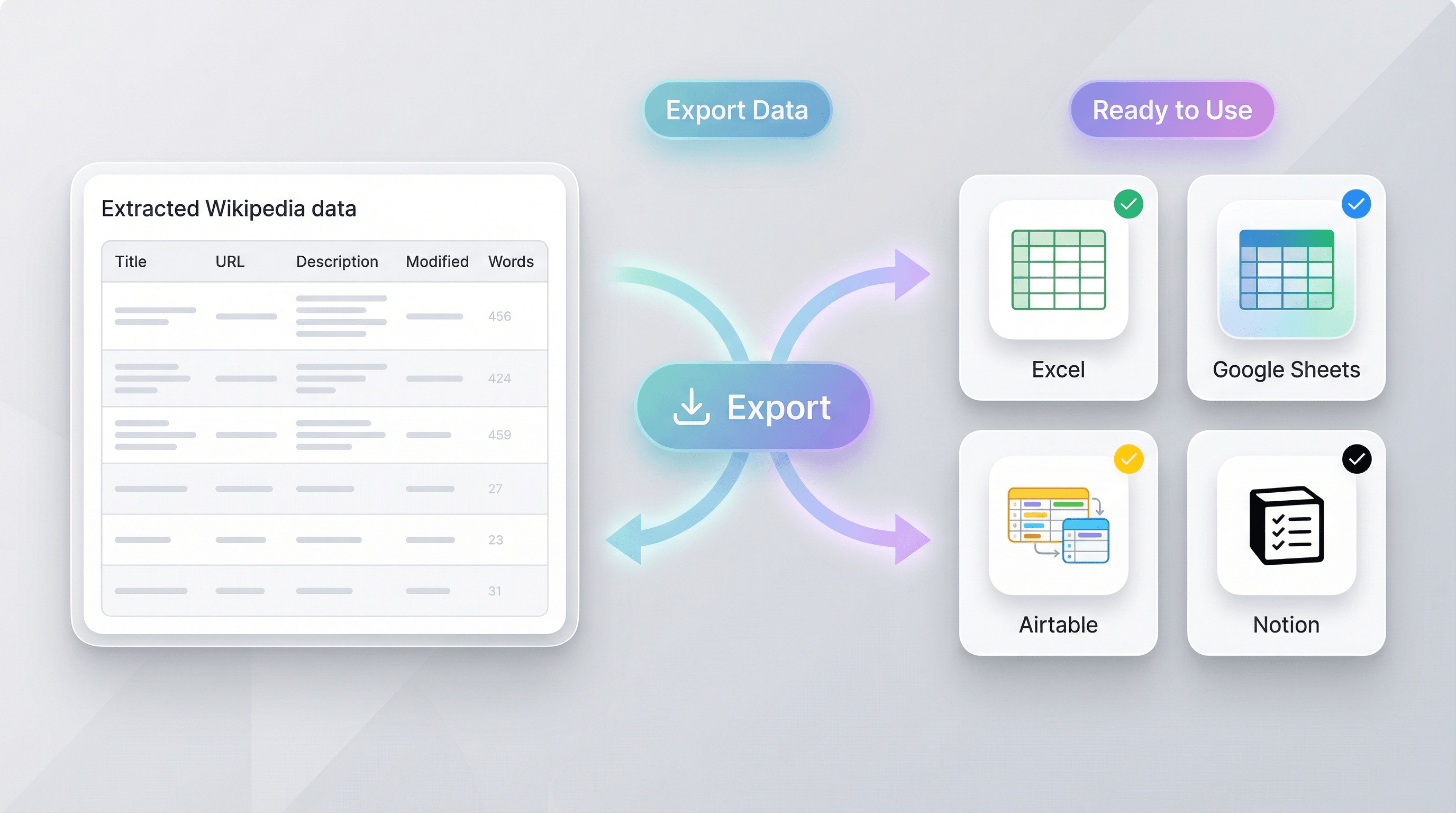
Export Wikipedia Data to Spreadsheets and Databases
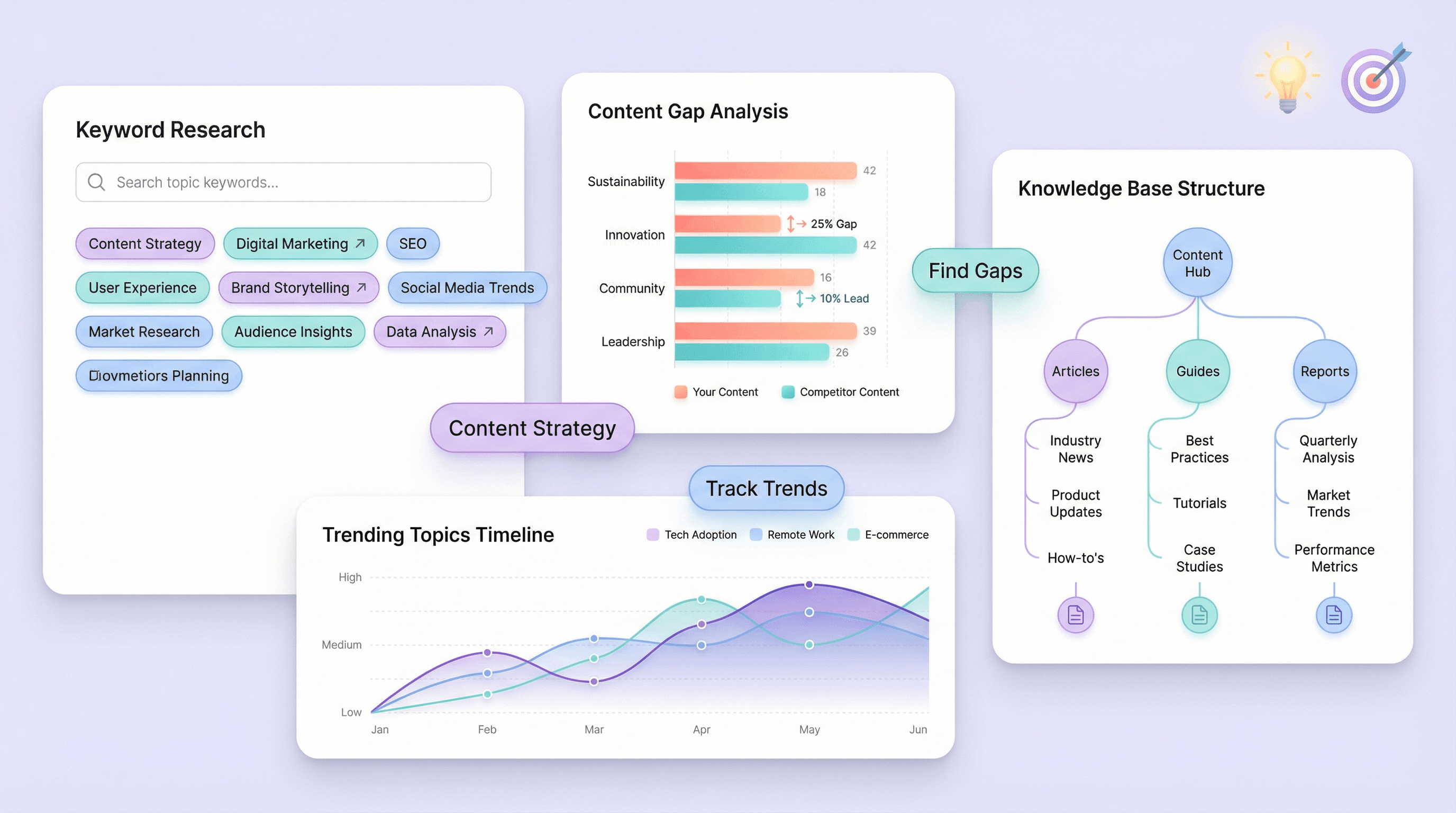
Support Content Strategy and SEO Research
Objev další bezplatné nástroje
Extraktor sitemap
Analyzuje URL XML sitemapu a vypíše každou stránku v přehledné tabulce. Rychle prověří strukturu webu a najde chybějící nebo neočekávané adresy pro SEO a QA.
Extraktor obrázků z webu
Okamžitě vytáhněte všechny obrázky z libovolné webové stránky a stáhněte je během chvilky. Zcela zdarma, rychle a s velmi snadným exportem.
Crawler seznamů
Z webové adresy libovolné stránky extrahuje položky číslovaných i odrážkových seznamů. Přehledně seskupené seznamy v prostém textu vám pomohou rychle zachytit klíčové body.
Google Scholar scraper
Extrahujte odborné výsledky ze stránky Google Scholar a exportujte názvy článků, citace, autory i údaje o publikaci do CSV pro rychlejší výzkum.
G2 Software Product Scraper
Extract structured insights from any G2 software page, including ratings, reviews, and product details, to streamline competitor analysis and market research.
Extraktor URL a hromadné stahování
Extrahujte ze stránky všechny odkazy na webu a stáhněte je jako CSV. Rychle shromážděte URL pro výzkum, analýzu nebo práci s daty.
Text Extractor
Extracts text from images and lets you download the results. Quickly convert scanned documents or pictures into editable text for easy use.
Amazon Products Scraper
Získejte informace o produktech z Amazonu jednoduše vložením URL adres produktů. Získáte názvy, ceny, hodnocení a další údaje v přehledné tabulce, kterou lze rychle exportovat a zkontrolovat.
Převodník obrázků na Excel
Převeďte obrázky tabulek, účtenek nebo seznamů do strukturovaných polí JSON pro snadný export do Excelu. Ušetřete čas při ručním zadávání dat a zajistěte přesnost.
AI Sales Email Generator
Create personalized sales emails in seconds with the free AI Sales Email Generator. Perfect for sales teams and entrepreneurs. Try it now and boost your outreach with Thunderbit’s suite of AI tools.
AI generátor předmětů e-mailů
Vytvářejte přesvědčivé předměty e-mailů z krátkého popisu. Zvyšte míru otevření pomocí návrhů poháněných AI. Rychlé, jednoduché a bez nutnosti registrace.
Extraktor telefonních čísel
Rychle projděte webové stránky, soubory nebo text a najděte telefonní čísla. Získejte čistý, exportovatelný seznam během několika sekund — ideální pro tvorbu kontaktů nebo ověřování dat.
Extraktor a ověřovač e-mailů
Najděte a extrahujte e-mailové adresy pomocí Email Extractor z webových stránek, PDF nebo textu. Rychle, přesně a kdykoli připravené k exportu.
Tester předmětů e-mailů
Ohodnoťte předmět podle délky, srozumitelnosti, naléhavosti, personalizace a rizika spamu. Získejte praktické tipy, jak zvýšit míru otevření.